maven的用法
1、maven简介
1.1 完成一个java项目,需要做哪些工作
1.分析项目要做什么,知道项目有哪些组成部分。 2.设计项目,通过哪些步骤,使用哪些技术。需要多少人, 多长的时间。 3.组建团队,招人, 购置设备,服务器, 软件, 笔记本。 4.开发人员写代码。 开发人员需要测试自己写代码。 重复多次的工作。 5.测试人员,测试项目功能是否符合要求。 测试开发人员提交代码-如果测试有问题–需要开发人员修改–在提交代码给测试 –测试人员在测试代码-如果还有问题-在交给开发人员-开发人员在提交-在测试 直到-测试代码通过。
1.2 传统开发项目的问题,没有使用maven【meivn】管理的项目
1)很多模块,模块之间有关系, 手工管理关系,比较繁琐。 2)需要很多第三方功能, 需要很多jar文件,需要手工从网络中获取各个jar 3)需要管理jar的版本, 你需要的是mysql.5.1.5.jar 拿你不能给给一个mysql.4.0.jar 4)管理jar文件之间的依赖, 你的项目要使用a.jar 需要使用b.jar里面的类。 必须首先获取到b.jar才可以, 然后才能使用a.jar.
a.jar需要b.jar这个关系叫做依赖, 或者你的项目中要使用mysql的驱动, 也可以叫做项目依赖mysql驱动。 a.class使用b.class, a依赖b类
1.3 需要改进项目的开发和管理,需要maven
1)maven可以管理jar文件 2)自动下载jar和他的文档,源代码 3)管理jar直接的依赖, a.jar需要b.jar , maven会自动下载b.jar 4)管理你需要的jar版本 5)帮你编译程序,把java编译为class 6)帮你测试你的代码是否正确。 7)帮你打包文件,形成jar文件,或者war文件 8)帮你部署项目
2、 构建:项目的构建
构建是面向过程的,就是一些步骤,完成项目代码的编译,测试,运行,打包,部署等等,maven支持的构建包括有:
1.清理, 把之前项目编译的东西删除掉,我新的编译代码做准备。 2.编译, 把程序源代码编译为执行代码, java-class文件 批量的,maven可以同时把成千上百的文件编译为class。 javac 不一样,javac一次编译一个文件。 3.测试, maven可以执行测试程序代码,验证你的功能是否正确。 批量的,maven同时执行多个测试代码,同时测试很多功能。 4.报告, 生成测试结果的文件, 测试通过没有。 5.打包, 把你的项目中所有的class文件,配置文件等所有资源放到一个压缩文件中。 这个压缩文件就是项目的结果文件, 通常java程序,压缩文件是jar扩展名的。 对于web应用,压缩文件扩展名是.war 6.安装, 把5中生成的文件jar,war安装到本机仓库 7.部署, 把程序安装好可以执行。
3、 maven核心概念
①POM : 一个文件 名称是pom.xml , pom翻译过来叫做项目对象模型。 maven把一个项目当做一个模型使用。控制maven构建项目的过程,管理jar依赖。
②约定的目录结构 : maven项目的目录和文件的位置都是规定的。
③坐标 : 是一个唯一的字符串,用来表示资源的。
④依赖管理 : 管理你的项目可以使用jar文件
⑤仓库管理(了解) :你的资源存放的位置
⑥生命周期 (了解) : maven工具构建项目的过程,就是生命周期。 ⑦插件和目标(了解):执行maven构建的时候用的工具是插件 ⑧继承 ⑨聚合
讲maven的使用,先难后易的。 难是说使用maven的命令,完成maven使用 , 在idea中直接使用maven,代替命令。
4、maven工具的安装和配置
1)需要从maven的官网下载maven的安装包 apache-maven-3.3.9-bin.zip 2)解压安装包,解压到一个目录,非中文目录。 子目录 bin :执行程序,主要是mvn.cmd conf :maven工具本身的配置文件 settings.xml 3)配置环境变量 在系统的环境变量中,指定一个M2_HOME的名称, 指定它的值是maven工具安装目录,bin之前的目录
M2_HOME=D:\work\maven_work\apache-maven-3.3.9
再把M2_HOME加入到path之中,在所有路径之前加入 %M2_HOME%\bin;
4)验证,新的命令行中,执行mvn -v
注意:需要配置JAVA_HOME ,指定jdk路径
C:\Users\Administrator>mvn -v 出现如下内容,maven安装,配置正确。 Apache Maven 3.3.9 (bb52d8502b132ec0a5a3f4c09453c07478323dc5; 2015-11-11T00:41:4 Maven home: D:\work\maven_work\apache-maven-3.3.9 Java version: 1.8.0_40, vendor: Oracle Corporation Java home: C:\java\JDK8-64\jre Default locale: zh_CN, platform encoding: GBK OS name: “windows 7”, version: “6.1”, arch: “amd64”, family: “dos”
4.1 maven约定的目录结构,约定是大家都遵循的一个规则
每一个maven项目在磁盘中都是一个文件夹(项目-Hello)
每一个maven项目在磁盘中都是一个文件夹(项目-Hello) Hello/ —/src ——/main #放你主程序java代码和配置文件 ———-/java #你的程序包和包中的java文件 ———-/resources #你的java程序中要使用的配置文件
——/test #放测试程序代码和文件的(可以没有) ———-/java #测试程序包和包中的java文件
———/resources #测试java程序中要使用的配置文件
---/pom.xml #maven的核心文件(maven项目必须有)
4.2 通过mvn compile 编译src/main目录下的所有java文件
1)为什么要下载
maven工具执行的操作需要很多插件(java类--jar文件)完成的
2)下载什么东西了
jar文件--叫做插件--插件是完成某些功能
3)下载的东西存放到哪里了。
默认仓库(本机仓库):
C:\Users\(登录操作系统的用户名)Administrator\.m2\repository
Downloading: https://repo.maven.apache.org/maven2/org/apache/maven/maven-plugin-parameter-documenter-2.0.9.pom
https://repo.maven.apache.org :中央仓库的地址
执行mvn compile, 结果是在项目的根目录下生成target目录(结果目录),
maven编译的java程序,最后的class文件都放在target目录中
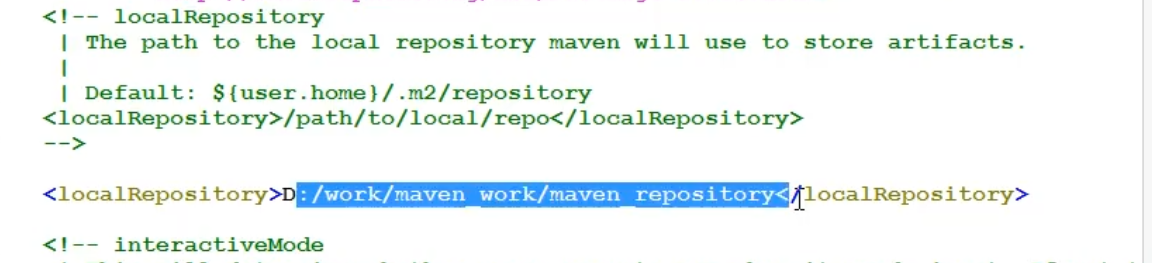
4.3 设置本机存放资源的目录位置(设置本机仓库):
1. 修改maven的配置文件, maven安装目录/conf/settings.xml
先备份 settings.xml
2. 修改 <localRepository> 指定你的目录(不要使用中文目录)
D:\work\maven_work\maven_repository
5、maven仓库
1)仓库是什么: 仓库是存放东西的, 存放maven使用的jar 和 我们项目使用的jar
> maven使用的插件(各种jar)
> 我项目使用的jar(第三方的工具)
2)仓库的分类
>本地仓库, 就是你的个人计算机上的文件夹,存放各种jar
>远程仓库, 在互联网上的,使用网络才能使用的仓库
①:中央仓库,最权威的, 所有的开发人员都共享使用的一个集中的仓库,
https://repo.maven.apache.org :中央仓库的地址
②:中央仓库的镜像:就是中央仓库的备份, 在各大洲,重要的城市都是镜像。
③:私服,在公司内部,在局域网中使用的, 不是对外使用的。
3)仓库的使用,maven仓库的使用不需要人为参与。
开发人员需要使用mysql驱动--->maven首先查本地仓库--->私服--->镜像--->中央仓库
6、pom:项目对象模型,是一个pom.xml文件
1)坐标:唯一值, 在互联网中唯一标识一个项目的
<groupId>公司域名的倒写</groupId>
<artifactId>自定义项目名称</artifactId>
<version>自定版本号</version>
https://mvnrepository.com/ 搜索使用的中央仓库, 使用groupId 或者 artifactId作为搜索条件
2) packaging: 打包后压缩文件的扩展名,默认是jar ,web应用是war
packaging 可以不写, 默认是jar
3) 依赖
dependencies 和dependency ,相当于是 java代码中import
你的项目中要使用的各种资源说明, 比我的项目要使用mysql驱动
<dependencies>
<!--依赖 java代码中 import -->
<dependency> (这样指定依赖项之后,如果在本机仓库中找到这个 jar包,加到你的项目中就可以使用了)
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.9</version>
</dependency>
</dependencies>
4)properties:设置属性
5)build : maven在进行项目的构建时, 配置信息,例如指定编译java代码使用的jdk的版本等
坐标
Maven把 任何一个 插件 都作为 仓库中 的一个项目进行管理 用 一组 (三个 )向量 组成的坐标 来 表示。 坐标 在仓库 中 可以 唯一定位一个 Maven项目。 groupId 组织名 ,通常是 公司或组织域名倒序 +项目名 artifactId 模块名 ,通常是工程名 version 版本号 需要特别指出的是, 项目在仓库中的位置是由坐标来决定的: groupId、 artifactId和 version决定项目在仓库中 的路径, artifactId和 version决定 jar包的名称
这样可以定位到你拥有的那个jar包,原先定义的那些类都可以来使用,其他项目中就可以使用仓库中的资源

依赖
一个 Maven项目正常运行 需要其它项目的支持, Maven会根据坐标 自动 到 本地 仓库中进行查找。 对于程序员自己的 Maven项目需要进行安装,才能保存到仓库中。 不用 不用maven的时候所有的的时候所有的jar都不是你的,需要去各个地方下载拷贝,用了都不是你的,需要去各个地方下载拷贝,用了maven所有的所有的jar包都是你的,想包都是你的,想要谁,叫谁的名字就行。要谁,叫谁的名字就行。maven帮你下载。帮你下载。 pom.xml加入依赖的方式:
log4j日志依赖
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
junit单元测试依赖
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
7、maven的生命周期
对项目的构建是建立在生命周期模型上的, 它明确定义项目生命 周期各个阶段, 并且对于每一个阶段提供相对应的命令,对开发者而言仅仅需要掌握 一小堆 的 命令 就可以 完成 项目 各个阶段的构建工作。
构建项目时按照生命周期顺序构建,每一个阶段都有特定的插件来完成。不论现在要执行生命周期中的哪个阶段,都是从这个生命周期的最初阶段开始的。 对于我们程序员而言,无论我们要进行哪个阶段的构建,直接执行相应的命令即可,无需担心它前边阶段是否构建, Maven都会自动构建。这也就是 Maven这种自动化构建工具给我们带来的好处。
8、Maven的常用命令
Maven对所有的功能都提供相对应的命令,要想知道 maven都 有哪些命令,那要看 maven有哪些功能。 一开 始就跟大家说了, maven三大功能: 管理依赖、构建项目、管理项目信息。 管理依赖,只需要声明就可以自 动到仓库下载;管理项目信息其实就是生成一个站点文档,一个命令就可以解决,最后再说;那 maven功能的 主体其实就是项目构建。 Maven提供一个项目构建的模型,把编译、测试、打包、部署等都对应成一个个的生命周期阶段, 并对 每一个阶段提供相应的命令,程序员只需要掌握一小堆命令,就可以完成项目的构建过程。 mvn clean 清理 (会删除原来编译和测试的目录,即 target目录,但是已经 install到仓库里的包不会删除 )
mvn compile 编译主程序 (会在当前目录下生成一个 target,里边存放编译主程序之后生成的字节码文件 )
mvn test-compile 编译测试程序 (会在当前目录下生成一个 target,里边存放编译测试程序之后生成的字节码文件 )
mvn test 测试 (会生成一个目录 surefire reports,保存测试结果 )
mvn package 打包主程序 (会编译、编译测试、测试、并且按照 pom.xml配置把主程序打包生成 jar包或者 war包 )
mvn install 安装主程序 (会把本工程打包,并且按照本工程的坐标保存到本地仓库中 )
mvn deploy 部署主程序 (会把本工程打包,按照本工程的坐标保存到本地库中,并且还会保存到私服仓库中。 还会自动把项目部署到 web容器中 )。 注意:执行以上命令必须在命令行进入pom.xml所在目录!
9、Maven的插件
maven过程构建周期,由maven的插件plugin来执行完成
官方插件说明:http://maven.apache.org/plugins/
在项目根目录下执行:mvn clean install

常用插件
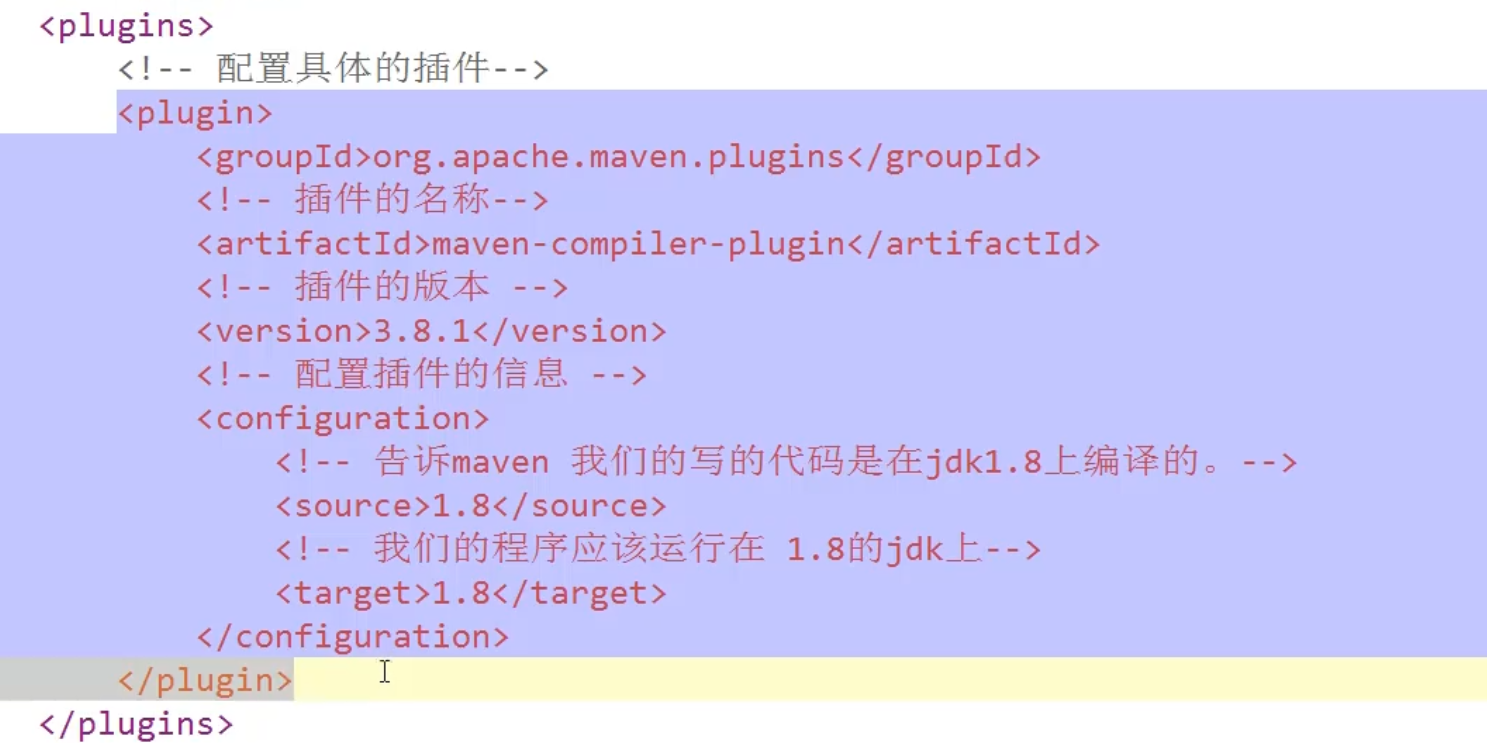
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven compiler plugin</artifactId> <version>3.8.13.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
10、在idea中配置maven
1、在idea中设置maven,让idea和maven结合使用
idea中内置了maven,一般不使用内置的,因为用内置修改maven的设置不方便
使用自己安装的maven,需要覆盖idea中的默认的设置,让idea指定maven安装位置信息
setting配置当前
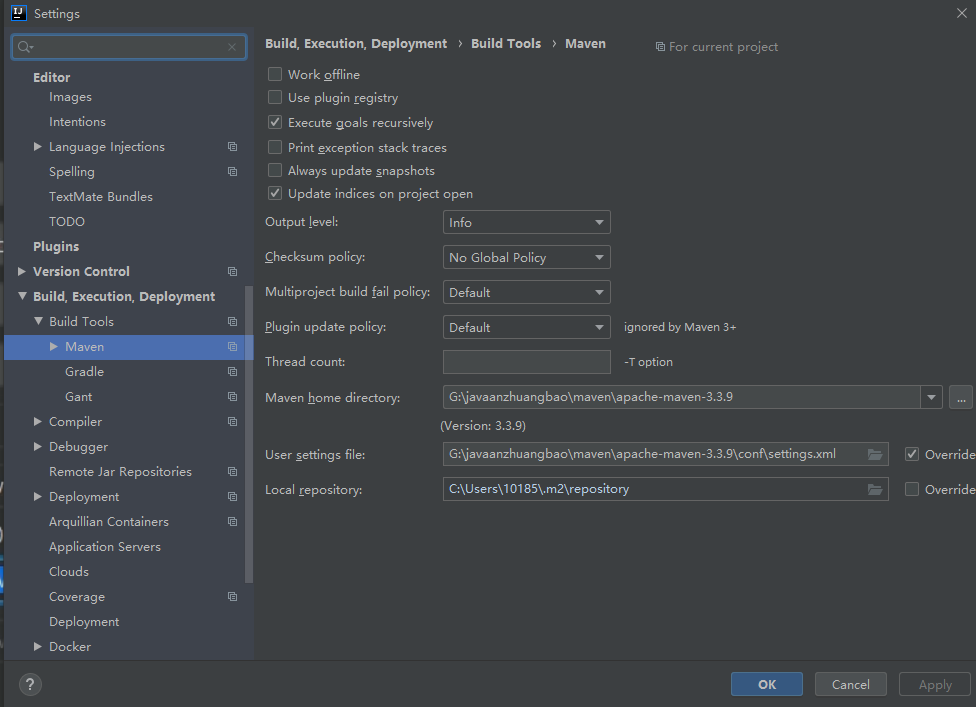
配置的入口 ①:配置当前工程的设置, file–settings —Build, Excution,Deployment–Build Tools –Maven
Maven Home directory: maven的安装目录
User Settings File : 就是maven安装目录conf/setting.xml配置文件
Local Repository : 本机仓库的目录位置
--Build Tools--Maven--Runner
VM Options : -DarchetypeCatalog=internal
JRE: 你项目的jdk
-DarchetypeCatalog=internal , maven项目创建时,会联网下载模版文件,
比较大, 使用-DarchetypeCatalog=internal,不用下载, 创建maven项目速度快。
②:配置以后新建工程的设置, file--other settings--Settings for New Project
为以后工程配置
其他步骤一样
11、idea新建maven工程
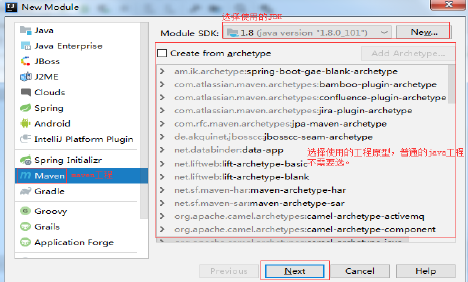
11.1 创建maven版java工程
File—>New—>Modual…:
11.2 填写maven工程坐标
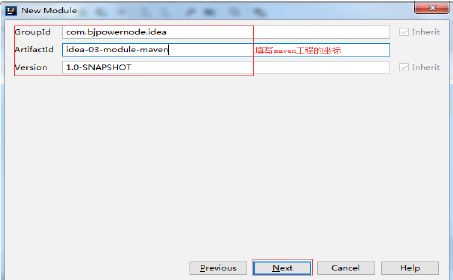
11.3 填写工程名和存储路径
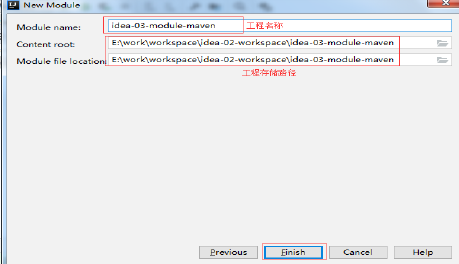
11.4 改变pom.xml中编译Java的版本
<properties>
<!--设置你的文件编码-->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!--编译java代码使用的jdk版本--><!--改成1.8-->
<maven.compiler.source>1.8</maven.compiler.source>
<!--你的java项目应该运行在什么样的jdk版本-->
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
11.5 pom.xml里面插件可以不写,这个idea为了方便你进行配置写上去的,如果不要,可以删除
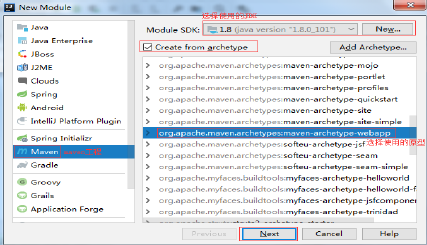
12、idea创建web工程
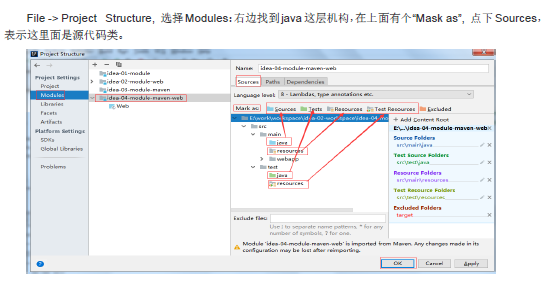
12.1 创建Maven版web工程
file->new->Module:
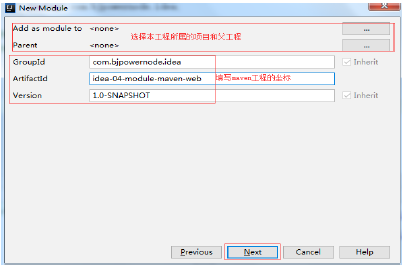
12.2 设置module信息
12.3 设置所使用的maven
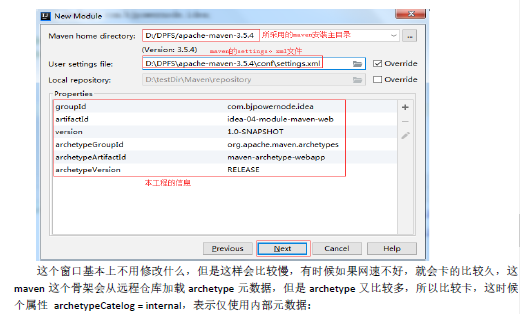
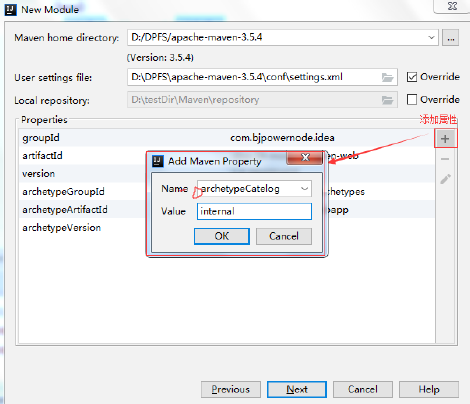
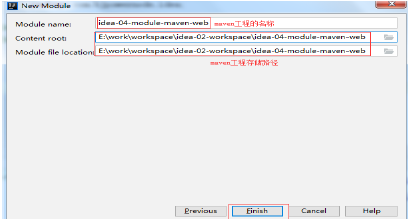
12.4 填写maven工程名称和存储路径‘
12.5 创建后视图
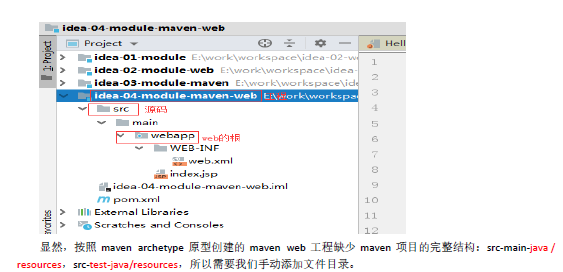
12.6 把文件夹标识为源码文件夹
12.7 pom.xml添加依赖
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.servlet.jsp</groupId>
<artifactId>jsp-api</artifactId>
<version>2.1</version>
<scope>provided</scope>
</dependency>
进行配置
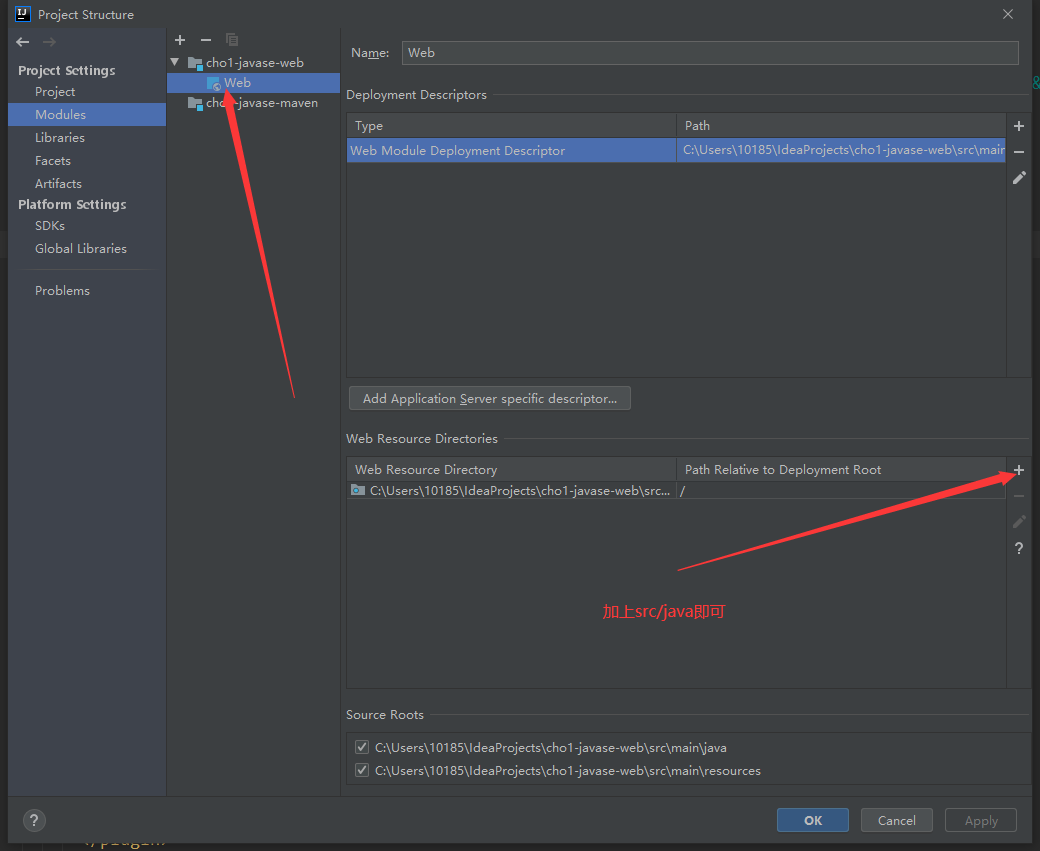
12.8 怎么让src也可以创建jsp页面
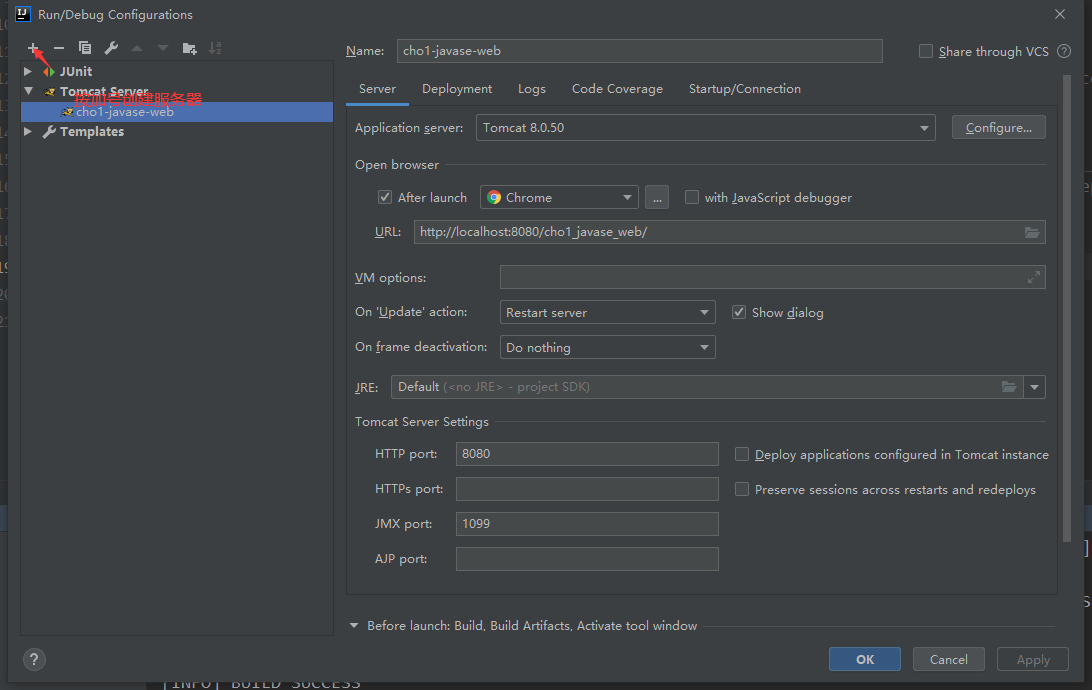
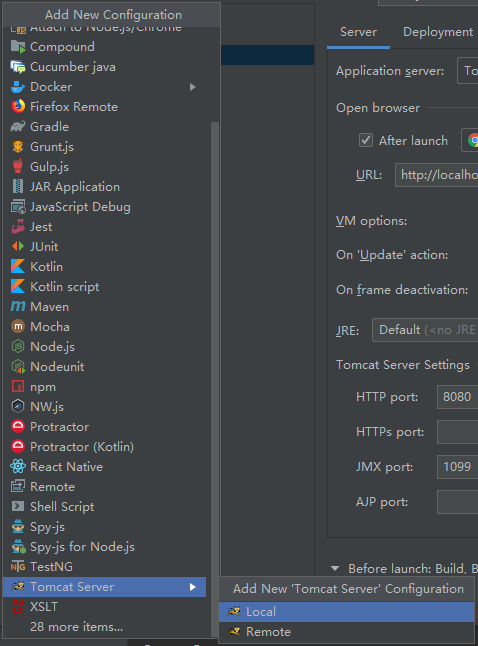
12.9 web项目打包
把打包的项目放在
然后
发现生成
用http://localhost:8080/myweb/访问
13、导入工程
13.1 新建一个空的project作为工作空间
13.2 在项目结构中导入或移除module
File–>project Structure
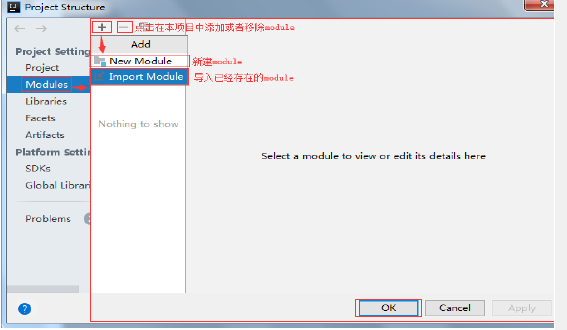
13.3 选择要导入的Module
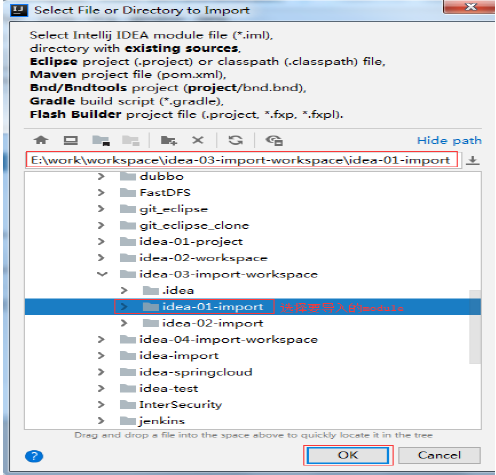
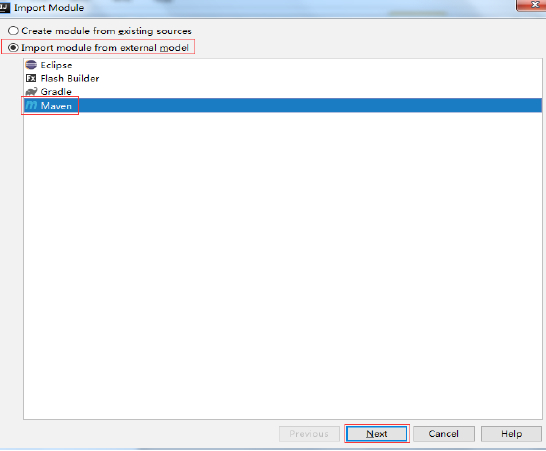
13.4 选择导入的方式
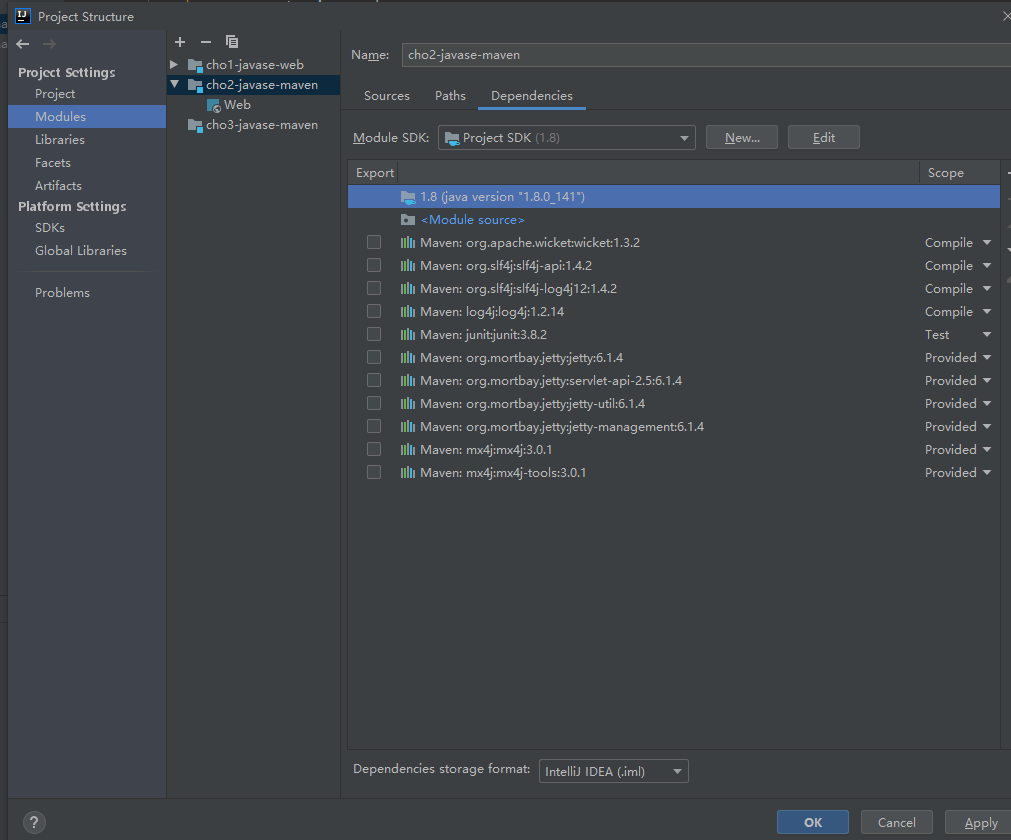
13.5 配置导入的jdk
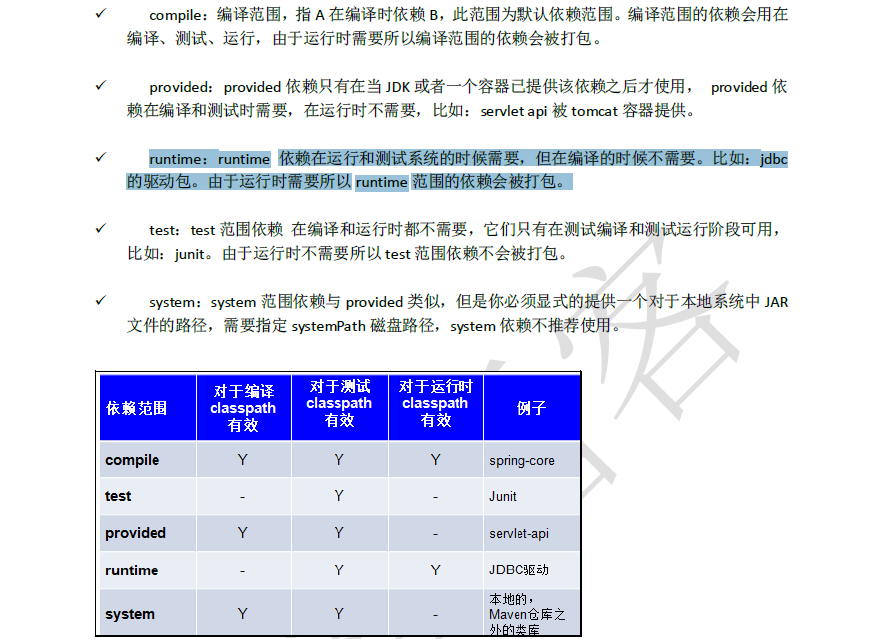
14、依赖管理
| compile | test | provided | |
|---|---|---|---|
| 对主程序是否有效 | 是 | 否 | 是 |
| 对测试程序是否有效 | 是 | 是 | 是 |
| 是否参与打包 | 是 | 否 | 否 |
| 是否参与部署 | 是 | 否 | 否 |
provided表示已经提供,比如说servled类你设置了依赖,但是servletd在tomcat服务器已经有了,因此在部署的时候不需要用到这个包。
runtime:runtime依赖在运行和测试系统的时候需要,但在编译的时候不需要。比如:jdbc的驱动包。由于运行时需要所以runtime范围的依赖会被打包。
15、maven常用设置
15.1 全局变量
在Maven的 pom.xml文件中, ,用于定义全局变量, POM中通过 ${property_name}的形式引用变量的值。 定义全局变量:
自定义的属性,1.在<properties> 通过自定义标签声明变量(标签名就是变量名)
2.在pom.xml文件中的其它位置,使用 ${标签名} 使用变量的值
自定义全局变量一般是定义 依赖的版本号, 当你的项目中要使用多个相同的版本号,
先使用全局变量定义, 在使用${变量名}
<properties>
<spring.version>4.3.10.RELEASE</spring.version>
</properties>
引用全局变量
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring context</artifactId>
<version>${spring.version}</version>
</dependency>
maven系统采用的变量:
<properties>
<maven.compiler.source>1.8</maven.compiler.source> 源码编译 jdk版本
<maven.compiler.target>1.8</maven.compiler.target> 运行代码的 jdk版本
<project.build.sourceEncoding>UTF 8</project.build.sourceEncoding> 项目构建使用的编码,避免中文乱
码
<project.reporting.outputEncoding>UTF 8</project.reporting.outputEncoding> 生成报告的编码
</properties>
15.2 指定资源位置
译结果分别放到了 target/classes和 targe/test classes目录中,但是这两个目录中的其他文件都会被忽略掉,如果需 要把 src目录下的文件包放到 target/classes目录,作为输出的 jar一部分。需要指定资源文件位置。 以下内容放到 标签中。
<build>
<resources>
<resource>
<directory>src/main/java</directory><!--所在的目录-->
<includes><!--包括目录下的.properties,.xml 文件都会扫描到-->
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<!-—filtering 选项 false 不启用过滤器, *.property 已经起到过滤的作用了 -->
<filtering>false</filtering>
</resource>
</resources>
</build>
16、添加tomcat7的插件
<build>
<plugins>
<plugin>
<groupId>org.apache.tomcat.maven</groupId>
<artifactId>tomcat7-maven-plugin</artifactId>
<version>2.2</version>
<configuration>
<port>8080</port>
<path>/</path>
</configuration>
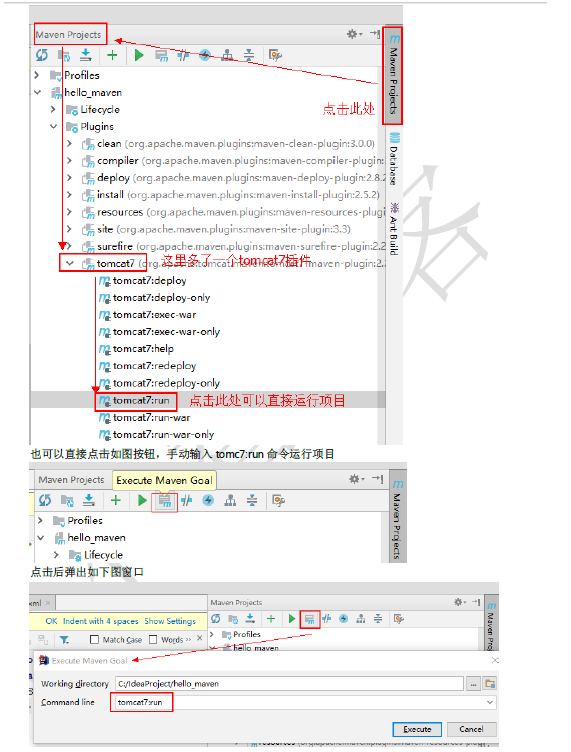
<!--此时点击idea最右侧Maven Projects,
就可以看到我们新添加的tomcat7插件
双击tomcat7插件下tomcat7:run命令直接运行项目-->
</plugin>
</plugins>
注意不同版本的tomcat需要搭配不同的servlet
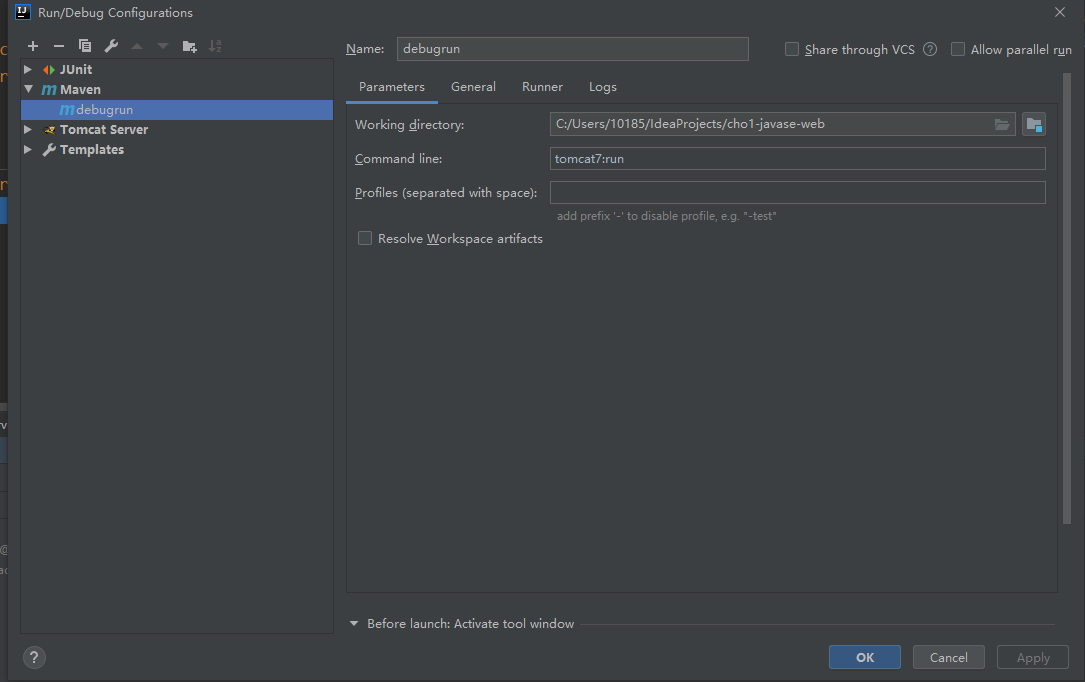
通过插件配置怎么进行debug
17、添加阿里云镜像
<!-- mirrors
| This is a list of mirrors to be used in downloading artifacts from remote repositories.
|
| It works like this: a POM may declare a repository to use in resolving certain artifacts.
| However, this repository may have problems with heavy traffic at times, so people have mirrored
| it to several places.
|
| That repository definition will have a unique id, so we can create a mirror reference for that
| repository, to be used as an alternate download site. The mirror site will be the preferred
| server for that repository.
|-->
<mirrors>
<!-- mirror
| Specifies a repository mirror site to use instead of a given repository. The repository that
| this mirror serves has an ID that matches the mirrorOf element of this mirror. IDs are used
| for inheritance and direct lookup purposes, and must be unique across the set of mirrors.
|
<mirror>
<id>mirrorId</id>
<mirrorOf>repositoryId</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://my.repository.com/repo/path</url>
</mirror>
-->
<!-- 阿里云仓库 -->
<mirror>
<id>alimaven</id>
<mirrorOf>central</mirrorOf>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/repositories/central/</url>
</mirror>
<!-- 中央仓库1 -->
<mirror>
<id>repo1</id>
<mirrorOf>central</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://repo1.maven.org/maven2/</url>
</mirror>
<!-- 中央仓库2 -->
<mirror>
<id>repo2</id>
<mirrorOf>central</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://repo2.maven.org/maven2/</url>
</mirror>
</mirrors>
18、idea创建模板
18.1 setting找到live Templates
19 继承
19.1 为什么需要继承机制
由于非compile范围的依赖信息是不能在“依赖链”中传递的,所以有需要的工程只能单独配置。例如:
| Hello | junit junit 4.9 test |
|---|---|
| HelloFriend | junit junit 4.9 test |
| MakeFriend | junit junit 4.9 test |
此时如果项目需要将各个模块的junit版本统一为4.9,那么到各个工程中手动修改无疑是非常不可取的。使用继承机制就可以将这样的依赖信息统一提取到父工程模块中进行统一管理。
19.2 创建父工程
创建父工程和创建一般的Java工程操作一致,唯一需要注意的是:打包方式处要设置为pom。
19.3 在子工程中引用父工程
… … … 从当前目录到父项目的pom.xml文件的相对路径
com.atguigu.maven Parent 0.0.1-SNAPSHOT ../Parent/pom.xml
此时如果子工程的groupId和version如果和父工程重复则可以删除。
19.4 在父工程中管理依赖
将Parent项目中的dependencies标签,用dependencyManagement标签括起来
junit junit 4.9 test
在子项目中重新指定需要的依赖,删除范围和版本号
junit junit
20 聚合
20.1 为什么要使用聚合
将多个工程拆分为模块后,需要手动逐个安装到仓库后依赖才能够生效。修改源码后也需要逐个手动进行clean操作。而使用了聚合之后就可以批量进行Maven工程的安装、清理工作。
20.2 如何配置聚合
在总的聚合工程中使用modules/module标签组合,指定模块工程的相对路径即可
../Hello ../HelloFriend ../MakeFriends
redis
概念:redis是一款高性能的NOSQL系列的非关系型数据库
1.1 什么是NOSQL
NoSQL(NoSQL = Not Only SQL),意即“不仅仅是SQL”,是一项全新的数据库理念,泛指非关系型的数据库。
随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
1.1.1 NOSQL和关系型数据库比较
优点: 1)成本:nosql数据库简单易部署,基本都是开源软件,不需要像使用oracle那样花费大量成本购买使用,相比关系型数据库价格便宜。
2)查询速度:nosql数据库将数据存储于缓存之中,关系型数据库将数据存储在硬盘中,自然查询速度远不及nosql数据库。
3)存储数据的格式:nosql的存储格式是key,value形式、文档形式、图片形式等等,所以可以存储基础类型以及对象或者是集合等各种格式,而数据库则只支持基础类型。
4)扩展性:关系型数据库有类似join这样的多表查询机制的限制导致扩展很艰难。
缺点: 1)维护的工具和资料有限,因为nosql是属于新的技术,不能和关系型数据库10几年的技术同日而语。 2)不提供对sql的支持,如果不支持sql这样的工业标准,将产生一定用户的学习和使用成本。 3)不提供关系型数据库对事务的处理。
1.1.2 非关系型数据库的优势
1)性能NOSQL是基于键值对的,可以想象成表中的主键和值的对应关系,而且不需要经过SQL层的解析,所以性能非常高。 2)可扩展性同样也是因为基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
1.1.3 关系型数据库的优势:
1)复杂查询可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询。 2)事务支持使得对于安全性能很高的数据访问要求得以实现。对于这两类数据库,对方的优势就是自己的弱势,反之亦然。
1.1.4 总结
关系型数据库与NoSQL数据库并非对立而是互补的关系,即通常情况下使用关系型数据库,在适合使用NoSQL的时候使用NoSQL数据库, 让NoSQL数据库对关系型数据库的不足进行弥补。 一般会将数据存储在关系型数据库中,在nosql数据库中备份存储关系型数据库的数据
1.2 主流的NOSQL产品
• 键值(Key-Value)存储数据库 相关产品: Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley DB 典型应用: 内容缓存,主要用于处理大量数据的高访问负载。 数据模型: 一系列键值对 优势: 快速查询 劣势: 存储的数据缺少结构化 • 列存储数据库 相关产品:Cassandra, HBase, Riak 典型应用:分布式的文件系统 数据模型:以列簇式存储,将同一列数据存在一起 优势:查找速度快,可扩展性强,更容易进行分布式扩展 劣势:功能相对局限 • 文档型数据库 相关产品:CouchDB、MongoDB 典型应用:Web应用(与Key-Value类似,Value是结构化的) 数据模型: 一系列键值对 优势:数据结构要求不严格 劣势: 查询性能不高,而且缺乏统一的查询语法 • 图形(Graph)数据库 相关数据库:Neo4J、InfoGrid、Infinite Graph 典型应用:社交网络 数据模型:图结构 优势:利用图结构相关算法。 劣势:需要对整个图做计算才能得出结果,不容易做分布式的集群方案。
1.3 什么是Redis
Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库,官方提供测试数据,50个并发执行100000个请求,读的速度是110000次/s,写的速度是81000次/s ,且Redis通过提供多种键值数据类型来适应不同场景下的存储需求,目前为止Redis支持的键值数据类型如下: 1) 字符串类型 string 2) 哈希类型 hash 3) 列表类型 list 4) 集合类型 set 5) 有序集合类型 sortedset
1.3.1 redis的应用场景
• 缓存(数据查询、短连接、新闻内容、商品内容等等) • 聊天室的在线好友列表 • 任务队列。(秒杀、抢购、12306等等) • 应用排行榜 • 网站访问统计 • 数据过期处理(可以精确到毫秒) • 分布式集群架构中的session分离
1.4 下载安装
- 官网:https://redis.io 2. 中文网:http://www.redis.net.cn/ 3. 解压直接可以使用: * redis.windows.conf:配置文件 * redis-cli.exe:redis的客户端 * redis-server.exe:redis服务器端 * redis-server.exe redis.windows.conf在redis文件夹的页面下cmd后输入前面命令
1.5 命令操作
1.5.1 redis的数据结构
redis存储的是:key,value格式的数据,其中key都是字符串,value有5种不同的数据结构
value的数据结构:
- 字符串类型 string
- 哈希类型 hash : map格式
- 列表类型 list : linkedlist格式。支持重复元素
- 集合类型 set : 不允许重复元素
- 有序集合类型 sortedset:不允许重复元素,且元素有顺序
key
| keys * | 查看当前库的所有键 |
|---|---|
| exists | 判断某个键是否存在 |
| type | 查看键的类型 |
| del | 删除某个键 |
| expire | 为键值设置过期时间,单位秒 |
| ttl | 查看还有多久过期,-1表示永不过期,-2表示已过期 |
| dbsize | 查看当前数据库中key的数量 |
| flushdb | 清空当前库 |
| Flushall | 通杀全部库 |
字符串类型string的存储
| get | 查询对应键值 |
|---|---|
| set | 添加键值对 |
| append | 将给定的追加到原值的末尾 |
| strlen | 获取值的长度 |
| setnx | 只有在key 不存在时设置key的值 |
| incr | 将key中存储的数字值增1 只能对数字值操作,如果为空,新增值为1 |
| decr | 将key中存储的数字值减1 只能对数字之操作,如果为空,新增值为-1 |
| incrby /decrby 步长 | 将key中存储的数字值增减,自定义步长 |
| mset | 同时设置一个或多个key-value对 |
| mget | 同时获取一个或多个value |
| msetnx | 同时设置一个或多个key-value对,当且仅当所有给定的key都不存在 |
| getrange <起始位置> <结束位置> | 获得值的范围,类似java中的substring |
| setrange <起始位置> | 用覆盖所存储的字符串值,从<起始位置>开始 |
| setex <过期时间> | 设置键值的同时,设置过去时间,单位秒 |
| getset | 以新换旧,设置了新值的同时获取旧值 |
1.存储:set key value
127.0.0.1:6379> set username zhangsan
2.获取: get key
127.0.0.1:6379> get username
3.删除: del key
127.0.0.1:6379> del age (integer) 1
哈希类型 hash的存储
-
Redis hash 是一个键值对集合 -
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。 -
类似Java里面的Map<String,Object> -
分析一个问题: 现有一个JavaBean对象,在Redis中如何存?
l 第一种方案: 用户ID为key ,VALUE为JavaBean序列化后的字符串
缺点: 每次修改用户的某个属性需要,先反序列化改好后再序列化回去。开销较大
l 第二种方案: 用户ID+属性名作为key, 属性值作为Value.
缺点: 用户ID数据冗余
l 第三种方案: 通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题
-
常用操作
| hset | 给集合中的 键赋值 |
|---|---|
| hget | 从集合 取出 value |
| hmset … | 批量设置hash的值 |
| hexists key | 查看哈希表 key 中,给定域 field 是否存在。 |
| hkeys | 列出该hash集合的所有field |
| hvals | 列出该hash集合的所有value |
| hincrby | 为哈希表 key 中的域 field 的值加上增量 increment |
| hsetnx | 将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在 |
1.存储:hset key field value
127.0.0.1:6379> hset myhash username lisi (integer) 1 127.0.0.1:6379> hset myhash password 123 (integer) 1
2、获取:
* hget key field: 获取指定的field对应的值
127.0.0.1:6379> hget myhash username
"lisi"
* hgetall key:获取所有的field和value
127.0.0.1:6379> hgetall myhash
1) "username"
2) "lisi"
3) "password"
4) "123"
3. 删除: hdel key field
127.0.0.1:6379> hdel myhash username
(integer) 1
列表类型list 的存储(允许重复)
-
单键多值 -
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素导列表的头部(左边)或者尾部(右边)。 -
它的底层实际是个**双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差** -

-
常用操作
| lpush/rpush | 从左边/右边插入一个或多个值。 |
|---|---|
| lpop/rpop | 从左边/右边吐出一个值。 值在键在,值光键亡。 |
| rpoplpush | 从列表右边吐出一个值,插到列表左边 |
| lrange | 按照索引下标获得元素(从左到右) |
| lindex | 按照索引下标获得元素(从左到右) |
| llen | 获得列表长度 |
| linsert before | 在的后面插入 插入值 |
| lrem | 从左边删除n个value(从左到右) |
可以添加一个元素到列表的头部(左边)或者尾部(右边)
1、添加:
1. lpush key value: 将元素加入列表左表
2. rpush key value:将元素加入列表右边
127.0.0.1:6379> lpush myList a
(integer) 1
127.0.0.1:6379> lpush myList b
(integer) 2
127.0.0.1:6379> rpush myList c
(integer) 3
2、获取:
* lrange key start end :范围获取
127.0.0.1:6379> lrange myList 0 -1
1) "b"
2) "a"
3) "c"
3、删除:
* lpop key: 删除列表最左边的元素,并将元素返回
* rpop key: 删除列表最右边的元素,并将元素返回
集合类型set的存储:不允许重复元素
-
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的 -
Redis的Set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)。 -
常用操作
| sadd …. | 将一个或多个 member 元素加入到集合 key 当中,已经存在于集合的 member 元素将被忽略。 |
|---|---|
| smembers | 取出该集合的所有值。 |
| sismember | 判断集合是否为含有该值,有返回1,没有返回0 |
| scard | 返回该集合的元素个数。 |
| srem …. | 删除集合中的某个元素。 |
| spop | 随机从该集合中吐出一个值。 |
| srandmember | 随机从该集合中取出n个值。 不会从集合中删除 |
| sinter | 返回两个集合的交集元素。 |
| sunion | 返回两个集合的并集元素。 |
| sdiff | 返回两个集合的差集元素。 |
1. 存储:sadd key value
127.0.0.1:6379> sadd myset a
(integer) 1
127.0.0.1:6379> sadd myset a
(integer) 0
2. 获取:smembers key:获取set集合中所有元素
127.0.0.1:6379> smembers myset
1) "a"
3. 删除:srem key value:删除set集合中的某个元素
127.0.0.1:6379> srem myset a
(integer) 1
有序集合类型sortedset:不允许重复元素,且元素有顺序.每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
-
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。不同之处是有序集合的每个成员都关联了一个评分(score) ,这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。 -
因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。 -
常用操作
| zadd … | 将一个或多个 member 元素及其 score 值加入到有序集 key 当中 |
|---|---|
| zrange [WITHSCORES] zrevrange反转同 | 返回有序集 key 中,下标在 之间的元素 带WITHSCORES,可以让分数一起和值返回到结果集。 (0- -1)代表全部 |
| zrangebyscore key min max [withscores] [limit offset count] | 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。 |
| zrevrangebyscore key max min [withscores] [limit offset count] | 同上,改为从大到小排列。 |
| zincrby | 为元素的score加上增量 |
| zrem | 删除该集合下,指定值的元素 |
| zcount | 统计该集合,分数区间内的元素个数 |
| zrank | 返回该值在集合中的排名,从0开始。 |
-
思考: 如何利用zset实现一个文章访问量的排行榜? 1. 存储:zadd key score value 127.0.0.1:6379> zadd mysort 60 zhangsan (integer) 1 127.0.0.1:6379> zadd mysort 50 lisi (integer) 1 127.0.0.1:6379> zadd mysort 80 wangwu (integer) 1 2. 获取:zrange key start end [withscores] 127.0.0.1:6379> zrange mysort 0 -1 1) "lisi" 2) "zhangsan" 3) "wangwu" 127.0.0.1:6379> zrange mysort 0 -1 withscores 1) "zhangsan" 2) "60" 3) "wangwu" 4) "80" 5) "lisi" 6) "500" 3. 删除:zrem key value 127.0.0.1:6379> zrem mysort lisi (integer) 1
1.6 Redis的相关配置
-
计量单位说明,大小写不敏感
-
include 类似jsp中的include,多实例的情况可以把公用的配置文件提取出来
-
ip地址的绑定 bind 默认情况bind=127.0.0.1只能接受本机的访问请求 不写的情况下,无限制接受任何ip地址的访问 生产环境肯定要写你应用服务器的地址 如果开启了protected-mode,那么在没有设定bind ip且没有设密码的情况下,Redis只允许接受本机的相应
-
tcp-backlog 可以理解是一个请求到达后至到接受进程处理前的队列. backlog队列总和=未完成三次握手队列 + 已经完成三次握手队列 高并发环境tcp-backlog 设置值跟超时时限内的Redis吞吐量决定
-
timeout 一个空闲的客户端维持多少秒会关闭,0为永不关闭。
-
tcp keepalive 对访问客户端的一种心跳检测,每个n秒检测一次,官方推荐设置为60秒
-
daemonize 是否为后台进程
-
pidfile 存放pid文件的位置,每个实例会产生一个不同的pid文件
-
log level 四个级别根据使用阶段来选择,生产环境选择notice 或者warning
-
log level 日志文件名称
-
syslog 是否将Redis日志输送到linux系统日志服务中
-
syslog-ident 日志的标志
-
syslog-facility 输出日志的设备
-
database 设定库的数量 默认16
-
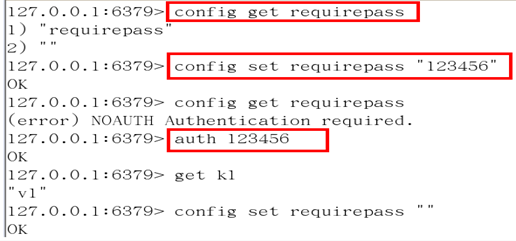
security 在命令行中设置密码
- maxclient 最大客户端连接数
- maxmemory 设置Redis可以使用的内存量。一旦到达内存使用上限,Redis将会试图移除内部数据,移除规则可以通过maxmemory-policy来指定。如果Redis无法根据移除规则来移除内存中的数据,或者设置了“不允许移除”, 那么Redis则会针对那些需要申请内存的指令返回错误信息,比如SET、LPUSH等。
- Maxmemory-policy volatile-lru:使用LRU算法移除key,只对设置了过期时间的键 allkeys-lru:使用LRU算法移除key volatile-random:在过期集合中移除随机的key,只对设置了过期时间的键 allkeys-random:移除随机的key volatile-ttl:移除那些TTL值最小的key,即那些最近要过期的key noeviction:不进行移除。针对写操作,只是返回错误信息
- Maxmemory-samples 设置样本数量,LRU算法和最小TTL算法都并非是精确的算法,而是估算值,所以你可以设置样本的大小。 一般设置3到7的数字,数值越小样本越不准确,但是性能消耗也越小。
1.7 持久化
RDB
-
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。 -
备份是如何执行的
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
-
关于fork
在Linux程序中,fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,Linux中引入了“写时复制技术”,一般情况父进程和子进程会共用同一段物理内存,只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。
-
RDB保存的文件
在redis.conf中配置文件名称,默认为dump.rdb

-
RDB文件的保存路径
默认为Redis启动时命令行所在的目录下,也可以修改

-
RDB的保存策略


-
手动保存快照
save: 只管保存,其它不管,全部阻塞
bgsave:按照保存策略自动保存
-
RDB的相关配置
l stop-writes-on-bgsave-error yes
当Redis无法写入磁盘的话,直接关掉Redis的写操作
l rdbcompression yes
进行rdb保存时,将文件压缩
l rdbchecksum yes
在存储快照后,还可以让Redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能
-
RDB的备份 与恢复
l 备份:先通过config get dir 查询rdb文件的目录 , 将*.rdb的文件拷贝到别的地方
l 恢复: 关闭Redis,把备份的文件拷贝到工作目录下,启动redis,备份数据会直接加载。
- RDB的优缺点
l 优点: 节省磁盘空间,恢复速度快.
l 缺点: 虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大时还是比较消耗性能。 在备份周期在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就
会丢失最后一次快照后的所有修改
1. redis是一个内存数据库,当redis服务器重启,获取电脑重启,数据会丢失,我们可以将redis内存中的数据持久化保存到硬盘的文件中。
2. redis持久化机制:
1. RDB:默认方式,不需要进行配置,默认就使用这种机制
* 在一定的间隔时间中,检测key的变化情况,然后持久化数据
1. 编辑redis.windwos.conf文件
# after 900 sec (15 min) if at least 1 key changed
save 900 1
# after 300 sec (5 min) if at least 10 keys changed
save 300 10
# after 60 sec if at least 10000 keys changed
save 60 10000
2. 重新启动redis服务器,并指定配置文件名称
D:\JavaWeb2018\day23_redis\资料\redis\windows-64\redis-2.8.9>redis-server.exe redis.windows.conf
AOF
-
以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,Redis启动之初会读取该文件重新构建数据,换言之,Redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。 -
AOF默认不开启,需要手动在配置文件中配置 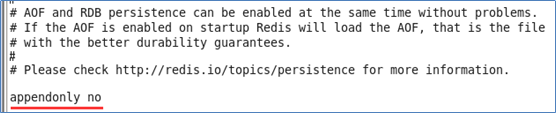 -
可以在redis.conf中配置文件名称,默认为 appendonly.aof
AOF文件的保存路径,同RDB的路径一致
-
AOF和RDB同时开启,redis听谁的? -
AOF文件故障备份
AOF的备份机制和性能虽然和RDB不同, 但是备份和恢复的操作同RDB一样,都是拷贝备份文件,需要恢复时再拷贝到Redis工作目录下,启动系统即加载
-
AOF文件故障恢复
如遇到AOF文件损坏,可通过
redis-check-aof –fix appendonly.aof 进行恢复
-
AOF同步频率设置
l 始终同步,每次Redis的写入都会立刻记入日志
l 每秒同步,每秒记入日志一次,如果宕机,本秒的数据可能丢失。
l 把不主动进行同步,把同步时机交给操作系统。
-
Rewrite
l AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制,当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集.可以使用命令bgrewriteaof。
l Redis如何实现重写
AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename),遍历新进程的内存中数据,每条记录有一条的Set语句。重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
l 何时重写
重写虽然可以节约大量磁盘空间,减少恢复时间。但是每次重写还是有一定的负担的,因此设定Redis要满足一定条件才会进行重写。

系统载入时或者上次重写完毕时,Redis会记录此时AOF大小,设为base_size,如果Redis的AOF当前大小>= base_size +base_size*100% (默认)且当前大小>=64mb(默认)的情况下,Redis会对AOF进行重写。
-
AOF的优缺点
l 优点:
备份机制更稳健,丢失数据概率更低。
可读的日志文本,通过操作AOF稳健,可以处理误操作。
l 缺点:
比起RDB占用更多的磁盘空间
恢复备份速度要慢
每次读写都同步的话,有一定的性能压力。
2. AOF:日志记录的方式,可以记录每一条命令的操作。可以每一次命令操作后,持久化数据
1. 编辑redis.windwos.conf文件
appendonly no(关闭aof) --> appendonly yes (开启aof)
# appendfsync always : 每一次操作都进行持久化
appendfsync everysec : 每隔一秒进行一次持久化
# appendfsync no : 不进行持久化
1.8 jedis
如果redis在虚拟机上面
-
使用Windows环境下Eclipse连接虚拟机中的Redis注意事项
l 禁用Linux的防火墙:Linux(CentOS7)里执行命令 : systemctl stop firewalld.service
l redis.conf中注释掉bind 127.0.0.1 ,然后 protect-mode no。
然后jedis中的地址改成连接虚拟机上面的网络地址
jedis:一款java操作redis数据库的工具
使用步骤:
1、下载jedis的jar包
2、使用
1.8.1 jedis中操作string
set
get
public class JedisTest {
public static void main(String[] args) {
//Jedis localhost = new Jedis("localhost", 6379);
//1、获取连接(如果使用无参构造,默认使用new Jedis("localhost", 6379);)
Jedis jedis = new Jedis();
//2、存储
jedis.set("xiaodidi", "12321");
//3、获取
String xiaodidi = jedis.get("xiaodidi");
System.out.println(xiaodidi);
//存进去一个字符串,20秒以后销毁,常用于:比如发一个连接,提示20秒之内有效,超过这个时间无效
jedis.setex("actioncode", 20, "heeh");
//关闭连接
jedis.close();
}
}
1.8.2 Jedis中操作hash:map格式
hset
hget
hgetAll
//1. 获取连接
Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口
//2. 操作
// 存储hash
jedis.hset("user","name","lisi");
jedis.hset("user","age","23");
jedis.hset("user","gender","female");
// 获取hash
String name = jedis.hget("user", "name");
System.out.println(name);
// 获取hash的所有map中的数据
Map<String, String> user = jedis.hgetAll("user");
// keyset
Set<String> keySet = user.keySet();
for (String key : keySet) {
//获取value
String value = user.get(key);
System.out.println(key + ":" + value);
}
//3. 关闭连接
jedis.close();
1.8.3 jedis中操作list:linkedlist格式
lpush/rpush
lpop/rpop
lrange start end:范围获取
//1. 获取连接
Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口
//2. 操作
// list 存储
jedis.lpush("mylist","a","b","c");//从左边存
jedis.rpush("mylist","a","b","c");//从右边存
// list 范围获取
List<String> mylist = jedis.lrange("mylist", 0, -1);
System.out.println(mylist);
// list 弹出
String element1 = jedis.lpop("mylist");//c
System.out.println(element1);
String element2 = jedis.rpop("mylist");//c
System.out.println(element2);
// list 范围获取
List<String> mylist2 = jedis.lrange("mylist", 0, -1);
System.out.println(mylist2);
//3. 关闭连接
jedis.close();
1.8.4 jedis操作set:不允许重复元素
sadd
smembers:获取所有元素
//1. 获取连接
Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口
//2. 操作
// set 存储
jedis.sadd("myset","java","php","c++");
// set 获取
Set<String> myset = jedis.smembers("myset");
System.out.println(myset);
//3. 关闭连接
jedis.close();
1.8.5 有序集合类型 sortedset:不允许重复元素,且元素有顺序
zadd
zrange
//1. 获取连接
Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口
//2. 操作
// sortedset 存储
jedis.zadd("mysortedset",3,"亚瑟");
jedis.zadd("mysortedset",30,"后裔");
jedis.zadd("mysortedset",55,"孙悟空");
// sortedset 获取
Set<String> mysortedset = jedis.zrange("mysortedset", 0, -1);
System.out.println(mysortedset);
//3. 关闭连接
jedis.close();
1.9 jedis工具类的编写
package com.atguigu.utils;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;
public class JedisUtils {
private static JedisPool jedisPool;
static{
InputStream resourceAsStream = JedisPool.class.getClassLoader().getResourceAsStream("jedis.properties");
Properties properties = new Properties();
try {
properties.load(resourceAsStream);
} catch (IOException e) {
e.printStackTrace();
}
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(Integer.parseInt(properties.getProperty("maxIdle")));
jedisPoolConfig.setMaxTotal(Integer.parseInt(properties.getProperty("maxTotal")));
jedisPool = new JedisPool(jedisPoolConfig,properties.getProperty("host"),Integer.parseInt(properties.getProperty("port")));
}
public static Jedis getjedisPool() {
return jedisPool.getResource();
}
}
测试代码
public static void main(String[] args) {
//Jedis localhost = new Jedis("localhost", 6379);
//1、获取连接(如果使用无参构造,默认使用new Jedis("localhost", 6379);)
Jedis jedis = JedisUtils.getjedisPool();
jedis.hset("myMap", "xiao", "gege");
String hget = jedis.hget("myMap", "xiao");
System.out.println(hget);
jedis.hset("myMap", "gege", "didi");
Map<String, String> myMap = jedis.hgetAll("myMap");
System.out.println(myMap);
//关闭连接
jedis.close();
}
1.10 jedis的案例(用ajax和json和sql加redis的省份下拉列表)
index.html中的代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- 上述3个meta标签*必须*放在最前面,任何其他内容都*必须*跟随其后! -->
<title>Bootstrap 101 Template</title>
<!-- Bootstrap -->
<link href="css/bootstrap.min.css" rel="stylesheet">
<!-- jQuery (necessary for Bootstrap's JavaScript plugins) -->
<script src="js/jquery-3.3.1.min.js"></script>
<!-- Include all compiled plugins (below), or include individual files as needed -->
<script src="js/bootstrap.min.js"></script>
<script>
$(function () {
//发送ajax请求,加载所有省份数据
$.getJSON("provinceServlet",{},function (data) {
console.log(data);
//[{"id":1,"name":"北京"},{"id":2,"name":"上海"},{"id":3,"name":"广州"},{"id":4,"name":"陕西"}]
var $province = $("#province");
$(data).each(function () {
console.log(this);
$("<option>'"+this.name+"'</option>").appendTo($province)
})
});
});
</script>
</head>
<body>
<select id="province" class="form-control">
<option>--请选择省份--</option>
</select>
<script>
var jsjf = {"name":"1q231"}
</script>
</body>
</html>
service里面的代码
package cn.itcast.service.impl;
import cn.itcast.dao.ProvinceDao;
import cn.itcast.dao.impl.ProvinceDaoImpl;
import cn.itcast.domain.Province;
import cn.itcast.jedis.util.JedisPoolUtils;
import cn.itcast.service.ProvinceService;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.google.gson.Gson;
import redis.clients.jedis.Jedis;
import java.util.List;
public class ProvinceServiceImpl implements ProvinceService {
//声明dao
private ProvinceDao dao = new ProvinceDaoImpl();
@Override
public List<Province> findAll() {
return dao.findAll();
}
/**
使用redis缓存
*/
@Override
public String findAllJson() {
//1.先从redis中查询数据
//1.1获取redis客户端连接
Jedis jedis = JedisPoolUtils.getJedis();
String province_json = jedis.get("province");
//2判断 province_json 数据是否为null
if(province_json == null || province_json.length() == 0){
//redis中没有数据
System.out.println("redis中没数据,查询数据库...");
//2.1从数据中查询
List<Province> ps = dao.findAll();
//2.2将list序列化为json
Gson gson = new Gson();
try {
province_json = gson.toJson(ps);
} catch (Exception e) {
e.printStackTrace();
}
//2.3 将json数据存入redis
jedis.set("province",province_json);
//归还连接
jedis.close();
}else{
System.out.println("redis中有数据,查询缓存...");
}
return province_json;
}
}
Servlet程序
@WebServlet("/provinceServlet")
public class ProvinceServlet extends HttpServlet {
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
/* //1.调用service查询
ProvinceService service = new ProvinceServiceImpl();
List<Province> list = service.findAll();
//2.序列化list为json
ObjectMapper mapper = new ObjectMapper();
String json = mapper.writeValueAsString(list);*/
//1.调用service查询
ProvinceService service = new ProvinceServiceImpl();
String json = service.findAllJson();
System.out.println(json);
//3.响应结果
response.setContentType("application/json;charset=utf-8");
response.getWriter().write(json);
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
this.doPost(request, response);
}
}
1.11 redis在linux的安装
把安装包放到/opt目录下面,tar -zxvf 文件 解压文件,进入redis-3.2.5文件下面,执行
make命令,可能会报错误,因为是由c语言编写的
yum install gcc
yum install gcc-c++
注意:如果第一次报错,没有安装成功,当下载好了文件,再次执行make命令,会报错,因为原先有残留文件,因此,运行make distclean之后再make
1.11.1 详细步骤:
-
下载获得redis-3.2.5.tar.gz后将它放入我们的Linux目录/opt -
解压命令:tar -zxvf redis-3.2.5.tar.gz -
解压完成后进入目录:cd redis-3.2.5 -
在redis-3.2.5目录下执行make命令
l 运行Make命令时出现错误,提示 gcc:命令未找到 ,原因是因为当前Linux环境中并没有安装gcc 与 g++ 的环境
-
安装gcc与g++
l 能上网的情况:
yum install gcc
yum install gcc-c++
l 不能上网[建议]
参考Linux课程中«03_在VM上安装CentOS7»中的第40步骤
-
重新进入到Redis的目录中执行 make distclean后再执行make 命令. -
执行完make后,可跳过Redis test步骤,直接执行 make install
1.11.2 查看默认安装路径/usr/local/bin
-
Redis-benchmark:性能测试工具,可以在自己本子运行,看看自己本子性能如何(服务启动起来后执行) -
Redis-check-aof:修复有问题的AOF文件,rdb和aof后面讲 -
Redis-check-dump:修复有问题的dump.rdb文件 -
Redis-sentinel:Redis集群使用 -
redis-server:Redis服务器启动命令 -
redis-cli:客户端,操作入口
1.11.3 Redis的启动
-
默认前台方式启动
l 直接执行redis-server 即可.启动后不能操作当前命令窗口
-
推荐后台方式启动
l 拷贝一份redis.conf配置文件到其他目录,例如根目录下的myredis目录 /myredis
l 修改redis.conf文件中的一项配置 daemonize 将no 改为yes,代表后台启动
l 执行配置文件进行启动 执行 redis-server /myredis/redis.conf
1.11.4 客户端的访问
-
使用redis-cli 命令访问启动好的Redis
l 如果有多个Redis同时启动,则需指定端口号访问 redis-cli -p 端口号
-
测试验证,通过 ping 命令 查看是否 返回 PONG
1.11.4 关闭Redis服务
-
单实例关闭
l 如果还未通过客户端访问,可直接 redis-cli shutdown
l 如果已经进入客户端,直接 shutdown即可.
-
多实例关闭
l 指定端口关闭 redis-cli -p 端口号 shutdown
1.11.5 Redis默认16个库
1)Redis默认创建16个库,每个库对应一个下标,从0开始
通过客户端连接后默认进入到0号库,推荐只使用0号库
2)使用命令select库的下标,来切换数据库,例如select 8
1.11.6 Redis的单线程+多路IO复用技术
-
多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)。 -
Memcached 是 多线程 + 锁.
Redis 是 单线程 + 多路IO复用.
1.12 Redis事务
1.12.1 Redis中事务的定义
Redis事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断
Redis事务的主要作用就是串联多个命令防止别的命令插队
1.12.2 multi,exec,discard
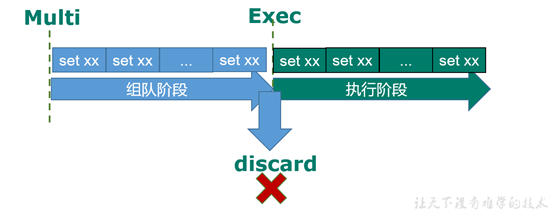
-
从输入Multi命令开始,输入的命令都会依次进入命令队列中,但不会执行,至到输入Exec后,Redis会将之前的命令队列中的命令依次执行。**注意:只要在Exec中,如果又命令执行失败,不会导致其他其他命令执行** -
组队的过程中可以通过discard来放弃组队。
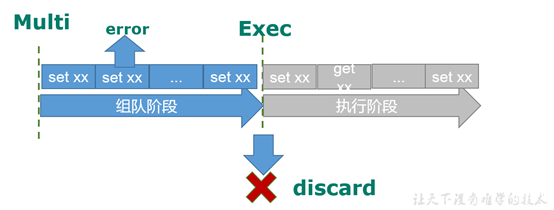
1.12.3 事务中的错误处理
1)组队中某个命令出现了报告错误,执行时整个的所有队列都会被取消
2)如果执行阶段某个命令报出了错误,则只有报错的命令不会被执行,而其他的命令都会执行,不会回滚
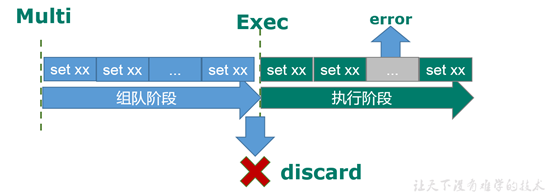
1.12.4 Redis事务的使用
1)WATCH key[key….]
在执行multi之前,先执行watch key1 [key2],可以监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。注意:只要开启watch,无论还有没有开启事务,进行第一次事务的时候之前或者之后如果watch的key发生遍化exec的结果都为null

-
unwatch
取消 WATCH 命令对所有 key 的监视。
如果在执行 WATCH 命令之后, EXEC 命令或 DISCARD 命令先被执行了的话,那么就不需要再执行 UNWATCH 了。
-
三特性
l 单独的隔离操作
事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
l 没有隔离级别的概念
队列中的命令没有提交之前都不会实际的被执行,因为事务提交前任何指令都不会被实际执行,也就不存在“事务内的查询要看到事务里的更新,在事务外查询不能看到”这个让人万分头痛的问题
l 不保证原子性
Redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚
1.12.5 Redis事务秒杀案例
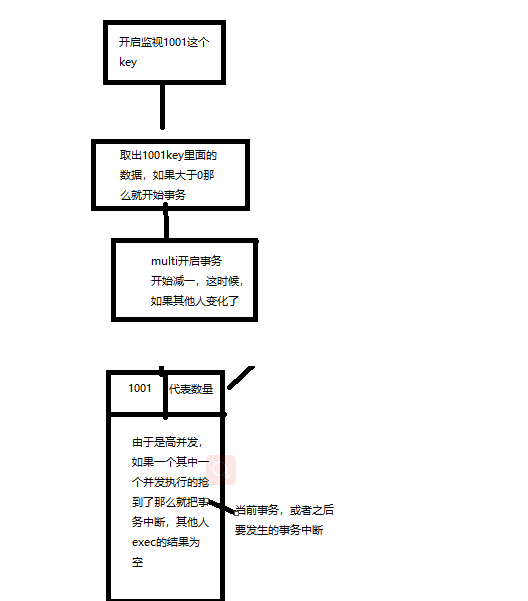
@RequestMapping("seckill")
public void seckill(HttpServletResponse response,@RequestParam("itemId") String itemId) throws IOException {
Jedis jedis = new Jedis("192.168.241.168",6379);
//用来监听key为itemId的事件,只要事件的值变化了,其他事务的执行就取消
jedis.watch(itemId);
jedis.incr("1001number");
int s = Integer.parseInt(jedis.get(itemId));
if (s > 0) {
//这个用来执行事务,减少一个
//建立一个multi的事务
Transaction multi = jedis.multi();
multi.decr(itemId);
//提交事务
List<Object> exec = multi.exec();
if (exec == null || exec.size() == 0) {
System.out.println("秒杀失败");
response.getWriter().write("false");
} else {
System.out.println("秒杀成功");
response.getWriter().write("true");
}
} else {
System.out.println("秒杀失败");
}
}
1.12.6 模拟高并发执行
1) 秒杀并发模拟 ab工具
l CentOS6 默认安装 ,CentOS7需要手动安装
l 联网: yum install httpd-tools
无网络: 进入cd /run/media/root/CentOS 7 x86_64/Packages
顺序安装
apr-1.4.8-3.el7.x86_64.rpm
apr-util-1.5.2-6.el7.x86_64.rpm
httpd-tools-2.4.6-67.el7.centos.x86_64.rpm
l ab –n 请求数 -c 并发数 -p 指定请求数据文件
-T “application/x-www-form-urlencoded” 测试的请求
ab -n 1000 -c 200 -p myRequest -T “application/x-www-form-urlencoded” 192.168.241.1:8080/firstssm3/seckill
myRequest里面写你的请求,注意后面一定要带&
itemId=1001&
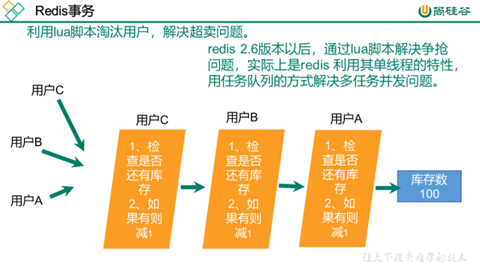
1.12.7 LUA脚本(可以高效实现redis的超卖问题)
l LUA脚本
Lua 是一个小巧的脚本语言,Lua脚本可以很容易的被C/C++ 代码调用,也可以反过来调用C/C++的函数,Lua并没有提供强大的库,一个完整的Lua解释器不过200k,所以Lua不适合作为开发独立应用程序的语言,而是作为嵌入式脚本语言。
很多应用程序、游戏使用LUA作为自己的嵌入式脚本语言,以此来实现可配置性、可扩展性。这其中包括魔兽争霸地图、魔兽世界、博德之门、愤怒的小鸟等众多游戏插件或外挂
l LUA脚本在Redis中的优势
将复杂的或者多步的redis操作,写为一个脚本,一次提交给redis执行,减少反复连接redis的次数。提升性能。
LUA脚本是类似redis事务,有一定的原子性,不会被其他命令插队,可以完成一些redis事务性的操作
但是注意redis的lua脚本功能,只有在2.6以上的版本才可以使用。
l 利用lua脚本淘汰用户,解决超卖问题。
1.13 Redis主从复制
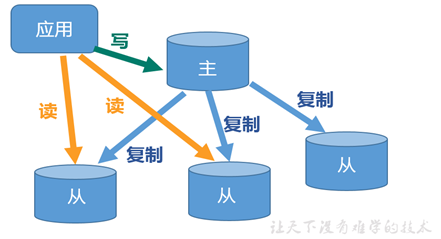
1.13.1 什么是主从复制
主从复制,就是主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主。
1.13.2 主从复制的目的
-
读写分离,性能扩展 -
容灾快速恢复 -
1.13.3 主从配置
-
原则: 配从不配主 -
步骤: 准备三个Redis实例,一主两从拷贝多个redis.conf文件include
开启daemonize yes
Pid文件名字pidfile
指定端口port
Log文件名字
Dump.rdb名字dbfilename
Appendonly 关掉或者换名字
-
info replication 打印主从复制的相关信息 -
slaveof <ip> <port> 成为某个实例的从服务器
1.13.4 实际操作
写一个配置文件
include /myredis/redis.conf
pidfile /var/run/redis6379.pid
port 6379
dbfilename dump6379.rdb
Appendonly no
复制三个取不同名字,最好用redis+端口号命名
把配置文件里面的端口号进行替换
redis-server 你刚刚进行的配置文件 (用来开启不同的三个服务)
然后进入客户端
redis-cli -h 127.0.0.1 -p 6379
redis-cli -h 127.0.0.1 -p 6380
redis-cli -h 127.0.0.1 -p 6381
然后再6380和6381的服务端
slaveof 127.0.0.1 6379(成为端口号为6379的从服务器)
info replication 查看关系
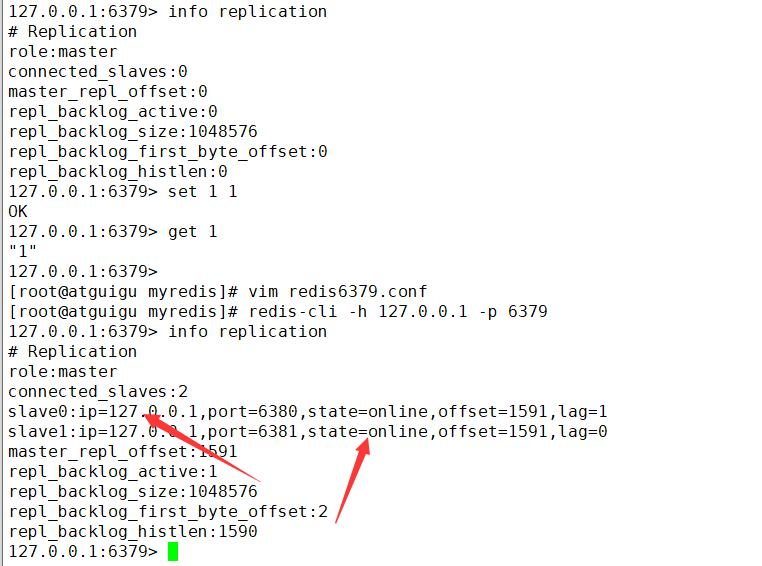
注意:如果主机被切断了,重新回来,数据还是在的
**如果从机被切断了,重新回来,但是需要在slaveof 127.0.0.1 6379,才会变成从服务器**
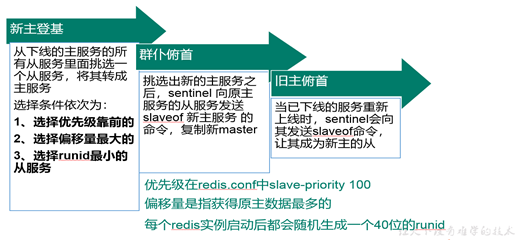
1.13.5 薪火相传模式演示
-
上一个slave可以是下一个slave的Master,slave同样可以接收其他slaves的连接和同步请求,那么该slave作为了链条中下一个的master, 可以有效减轻master的写压力,去中心化降低风险.中途变更转向:会清除之前的数据,重新建立拷贝最新的
风险是一旦某个slave宕机,后面的slave都没法备份

-
反客为主(小弟上位)
当一个master宕机后,后面的slave可以立刻升为master,其后面的slave不用做任何修改。
用 slaveof no one 将从机变为主机。
配置:
在6381服务器上面slaveof 127.0.0.1 6380 ,可以间接同步主服务器
如果主服务器down了,那么6380服务器只要slaveof no one 就可升级为主服务器
1.13.6 哨兵模式
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库.
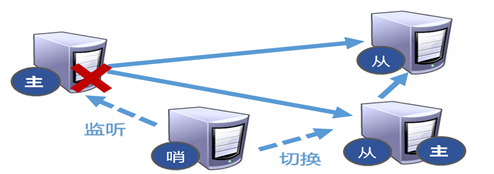
配置哨兵
l 调整为一主二从模式
l 自定义的/myredis目录下新建sentinel.conf文件
l 在配置文件中填写内容
sentinel monitor mymaster 127.0.0.1 6379 1
其中mymaster为监控对象起的服务器名称, 1 为 至少有多少个哨兵同意迁移的
数量。
l 启动哨兵
执行redis-sentinel /myredis/sentinel.conf
1.14 配置集群
1.14.1 安装ruby环境
1)能上网:
执行yum install ruby
执行yum install rubygems
注意:用yum中的rubygems版本过低,后面可能会报错
因此用javaanzhuangbao中的redis-gems3.2.0
复制到/opt中,然后通过gem install –local redis-3.2.0.gem
进行安装
1.14.2 准备6个Redis实例
-
准备6个实例 6379,6380,6381,6389,6390,6391拷贝多个redis.conf文件
开启daemonize yes
Pid文件名字
指定端口
Log文件名字
Dump.rdb名字
Appendonly 关掉或者换名字
-
再加入如下配置
cluster-enabled yes 打开集群模式
cluster-config-file nodes-端口号.conf 设定节点配置文件名
cluster-node-timeout 15000 设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换
include /myredis/redis.conf
pidfile "/var/run/redis6379.pid"
port 6379
dbfilename "dump6379.rdb"
appendonly no
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 15000
1.14.3 合体
-
将6个实例全部启动,nodes-端口号.conf文件都生成正常 -
合体
l 进入到 cd /opt/redis-3.2.5/src
l 执行
./redis-trib.rb create --replicas 1 192.168.241.168:6379 192.168.241.168:6380 192.168.241.168:6381 192.168.241.168:6382 192.168.241.168:6383 192.168.241.168:6384
l 注意: IP地址修改为当前服务器的地址,端口号为每个Redis实例对应的端口号.
1.14.4 集群操作
-
以集群的方式进入客户端
redis-cli -c -p 端口号
-
通过cluster nodes 命令查看集群信息  -
redis cluster 如何分配这六个节点
一个集群至少要有三个主节点。
选项 –replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
-
什么是slots
l 一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。
l 集群中的每个节点负责处理一部分插槽。 举个例子, 如果一个集群可以有主节点, 其中:
节点 A 负责处理 0 号至 5500 号插槽。
节点 B 负责处理 5501 号至 11000 号插槽。
节点 C 负责处理 11001 号至 16383 号插槽
-
在集群中录入值
l 在redis-cli每次录入、查询键值,redis都会计算出该key应该送往的插槽,如果不是该客户端对应服务器的插槽,redis会报错,并告知应前往的redis实例地址和端口.
l redis-cli客户端提供了 –c 参数实现自动重定向。
如 redis-cli -c –p 6379 登入后,再录入、查询键值对可以自动重定向。
l 不在一个slot下的键值,是不能使用mget,mset等多键操作。
l 可以通过{}来定义组的概念,从而使key中{}内相同内容的键值对放到一个slot中去
-
查询集群中的值
l CLUSTER KEYSLOT 计算键 key 应该被放置在哪个槽上。
l CLUSTER COUNTKEYSINSLOT 返回槽 slot 目前包含的键值对数量
l CLUSTER GETKEYSINSLOT 返回 count 个 slot 槽中的键
-
故障恢复
l 如果主节点下线?从节点能否自动升为主节点?
l 会。
l 主节点恢复后,主从关系会如何?
l 原先的主节点变从节点。
l 如果所有某一段插槽的主从节点都当掉,redis服务是否还能继续?
redis.conf中的参数 cluster-require-full-coverage
不能
1.14.5 集群的jedis开发
public static void main(String[] args) {
HashSet<HostAndPort> hostAndPorts = new HashSet<>();
hostAndPorts.add(new HostAndPort( "192.168.241.168",6379));
JedisCluster jedis = new JedisCluster(hostAndPorts);
String set = jedis.set("xiao", "gegehaoshuai");
System.out.println(jedis.get("xiao"));
System.out.println(jedis.get("mars"));
}
}
1.14.6 Redis集群的优缺点
l 优点
实现扩容
分摊压力
无中心配置相对简单
l 缺点
多键操作是不被支持的
多键的Redis事务是不被支持的。lua脚本不被支持。
由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。
Linux
0 总结和一些操作
1 tee命令的用法
tee [-ai][--help][--version][文件...]
参数:
- -a或–append 附加到既有文件的后面,而非覆盖它.
- -i或–ignore-interrupts 忽略中断信号。
- –help 在线帮助。
- –version 显示版本信息。

表示在文件中写入’我是’同时按abc结束(也可以把-去掉)
//一般配合管道符使用
sh -c 'exec mysqldump --all-databases -uroot -p"123456"' | tee /test
2 $ 和 | 的用法
$的用法
docker rmi -f $(docker images -qa)
$(docker images -qa)代表先在容器中取出
| 的用法
比如查找命令
ps -ef | grep 3306
代表把ps -ef 查询出来的所有内容通过放到 grep 3306 里面来执行
3 < > « » 的用法
< 的用法 和 cat a.txt 用法相同

«的用法定义结束标志
[tee命令的用法那里有](##1 tee命令的用法)
1 >的用法
覆盖输出到文本
会把文本中的内容覆盖

sh -c 'exec mysqldump --all-databases -uroot -p"123456"' > /c.txt
将查询出来的命令里面的所有内容存放到/c.txt文件中去
echo "信息" > test.asc
2 »的用法
追加
linux常用快捷键
第1章 vm的安装和linux的安装
1.1 vm的安装
一直点击下一步最后到
许可证 5A02H-AU243-TZJ49-GTC7K-3C61N
点击完成
1.2 虚拟机的安装
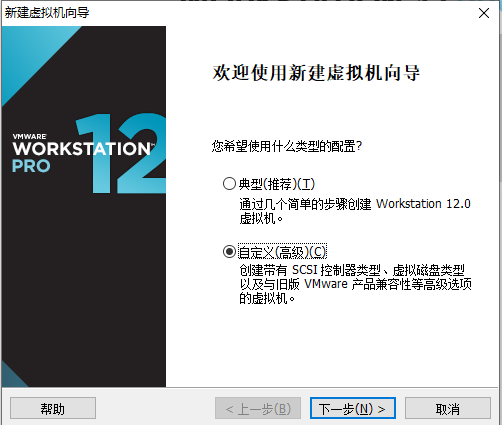
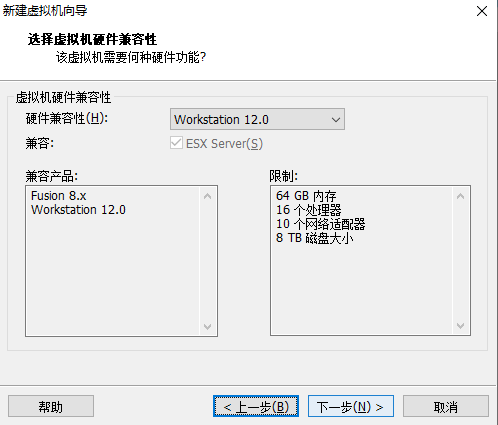
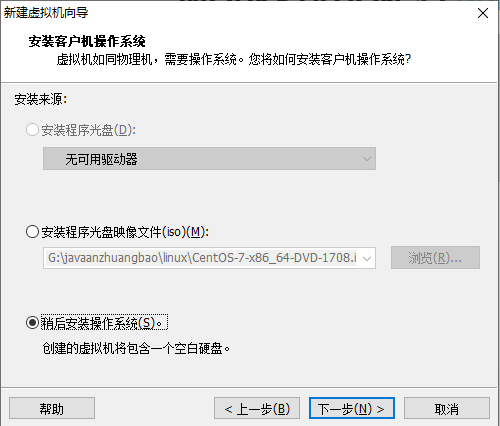
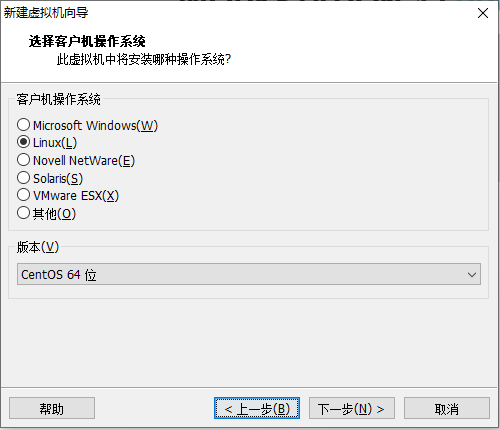
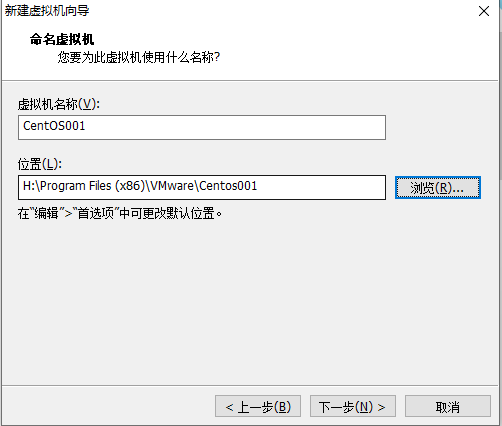
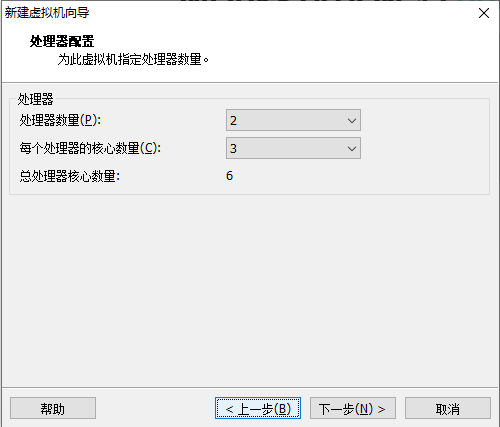
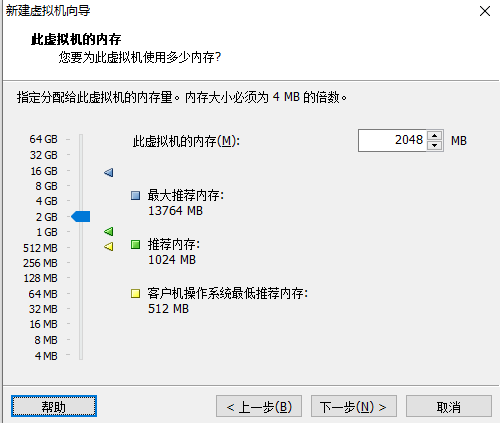
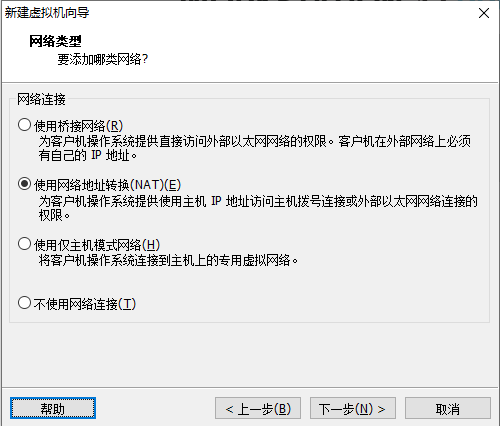
当使用桥接方式,会和主机在同一个网段,会出现ip地址不够用的情况,同时会被其他任何一台主机访问到linux,会出现不安全的情况
使用桥接模式,会自动分配当前ip地址,如果和别的电脑自动分配的ip地址相同,就会出现不能用的情况
当使用NAT网络转换模式 当使用虚拟机的时候,虚拟机会给我们使用两个虚拟网卡,其中的一个一定是和你的linux在同一个网段的,通信主机上的那个虚拟网卡,就可以使用虚拟网卡和主机进行通信了,所以虚拟机虽然不在同一个网段,但是可以通过虚拟网卡和主机进行通信‘
虚拟网卡里面的ip地址一定和linux相同
当使用仅主机模式网络的时候linux会和你所在的主机公用一个网络,相当于只和主机连接,linux不能上网
1.3 安装linux
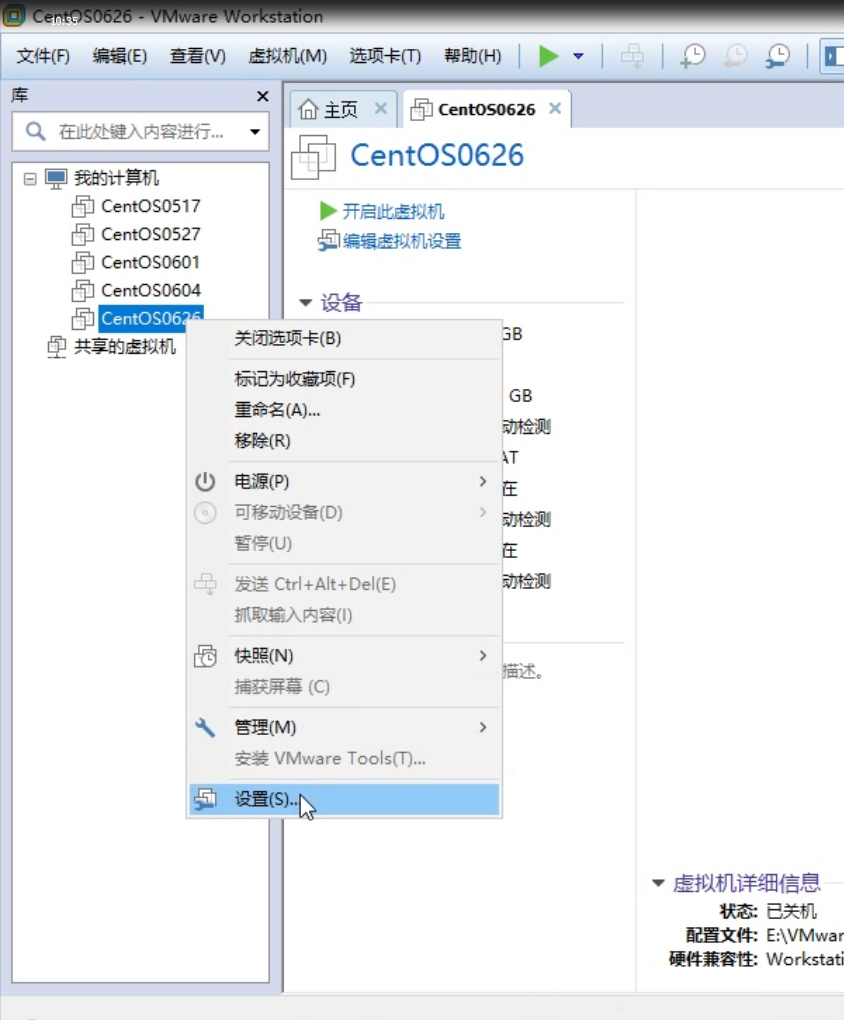
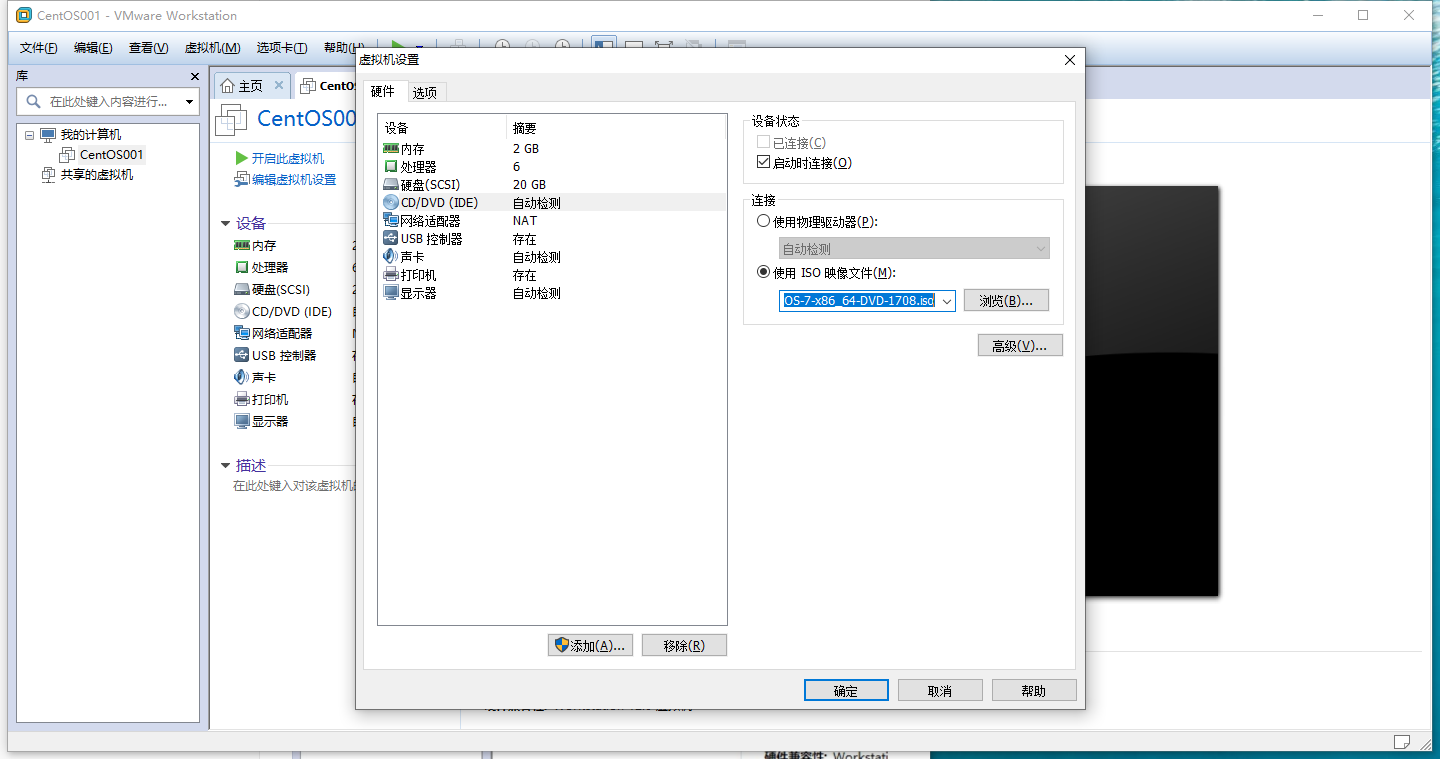
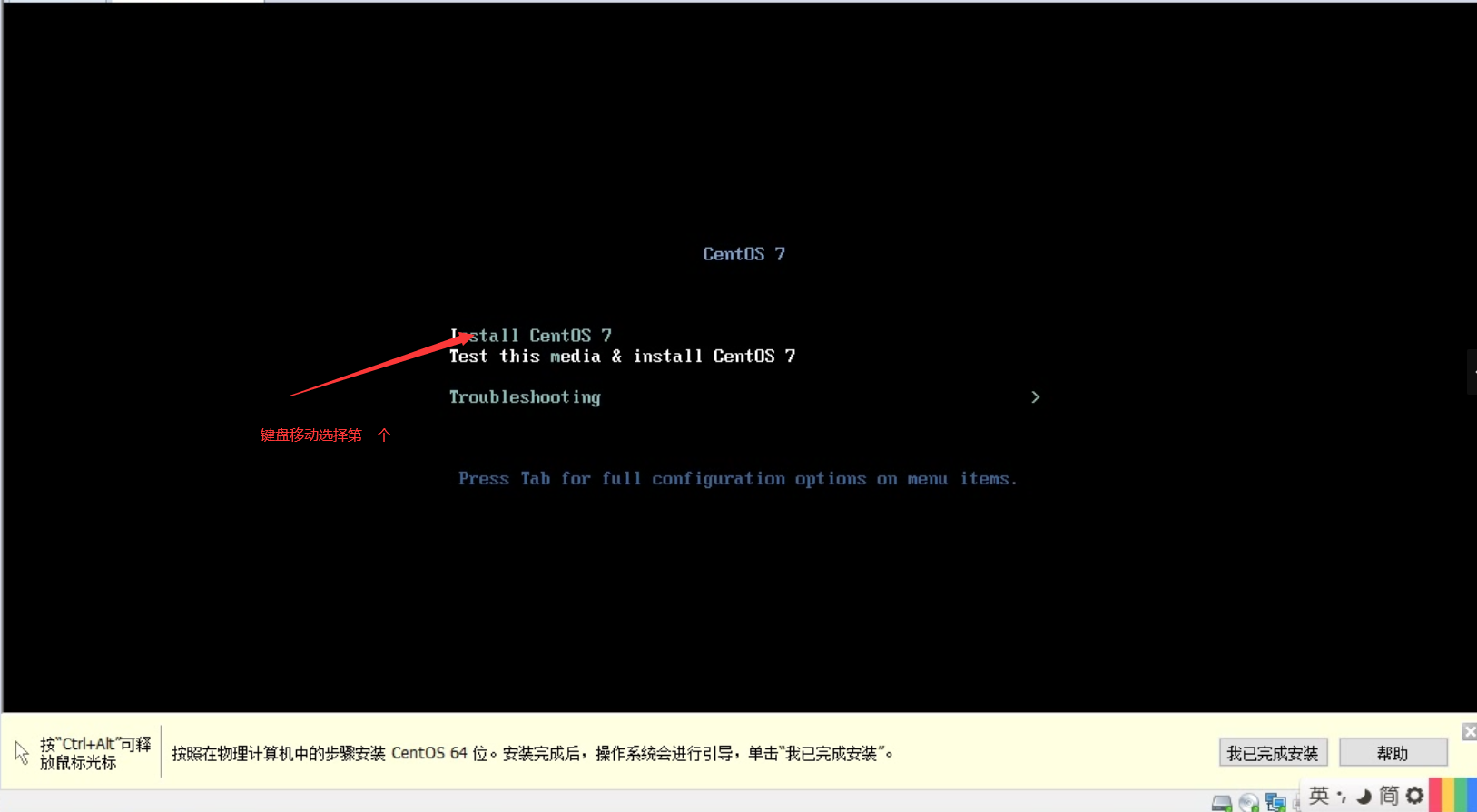
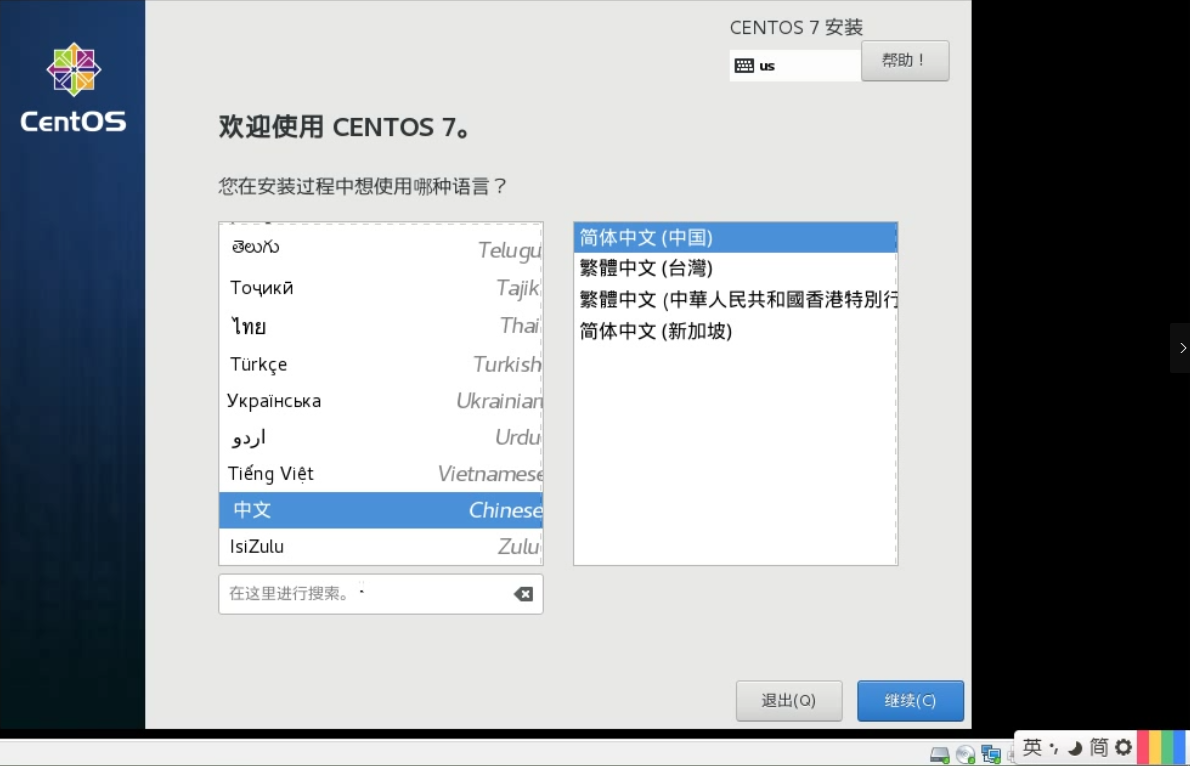
点击开启虚拟机
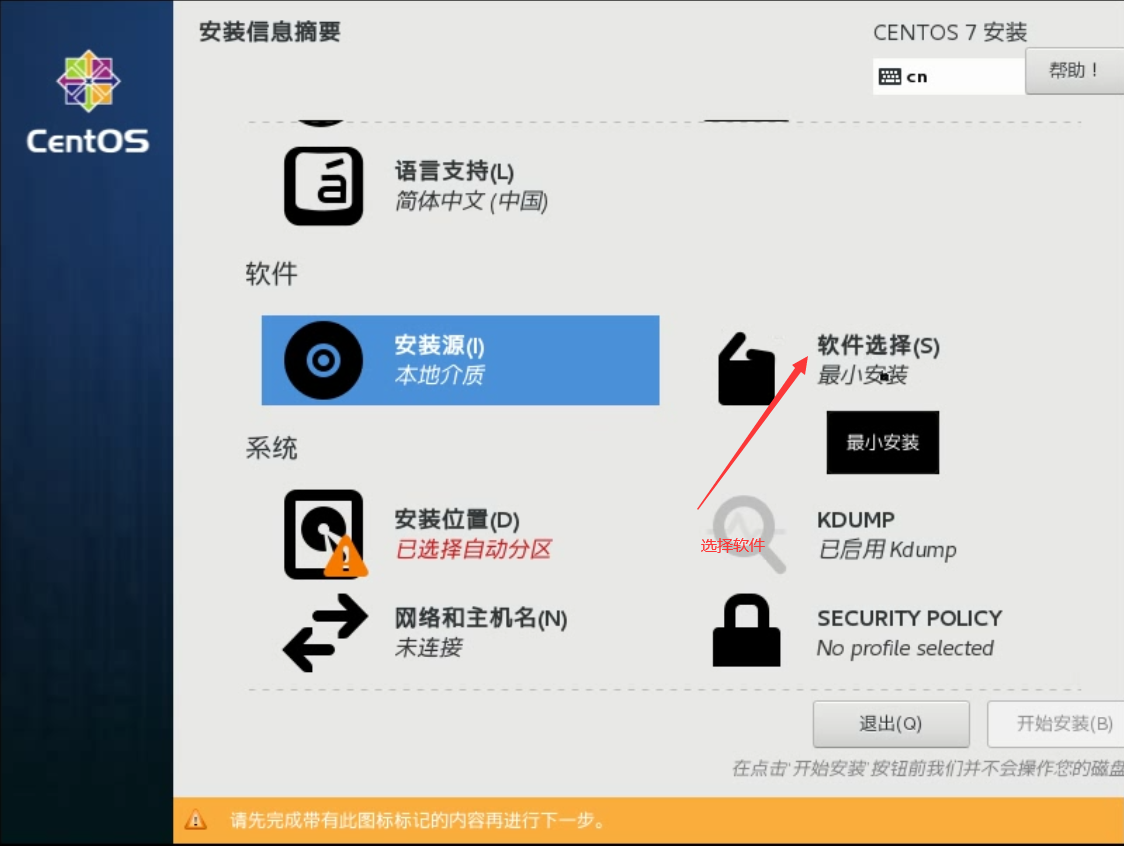
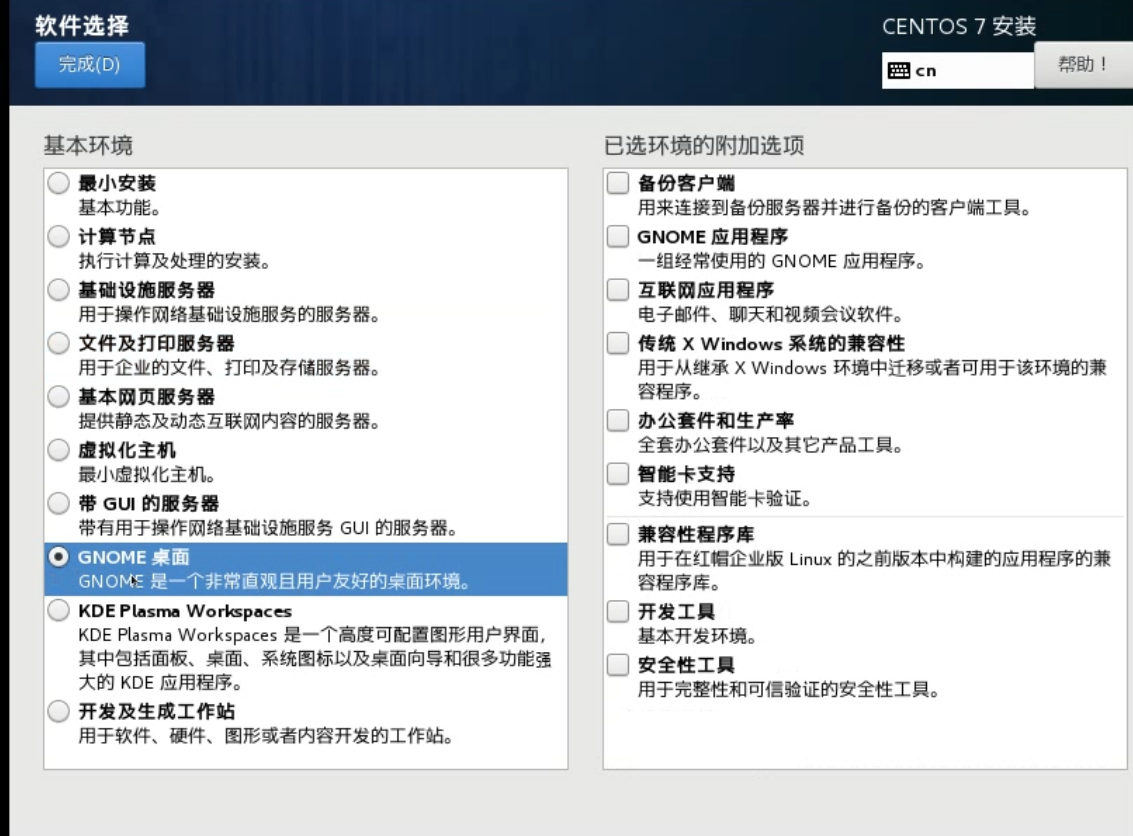
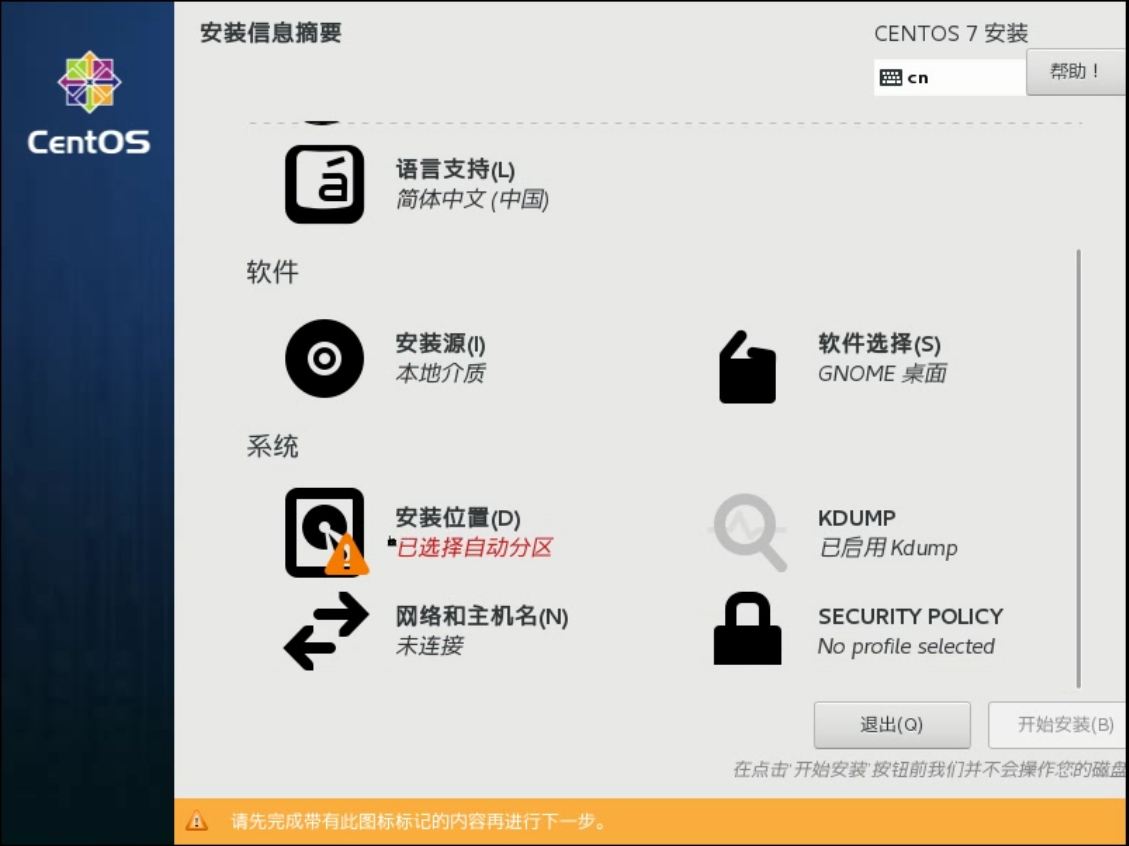
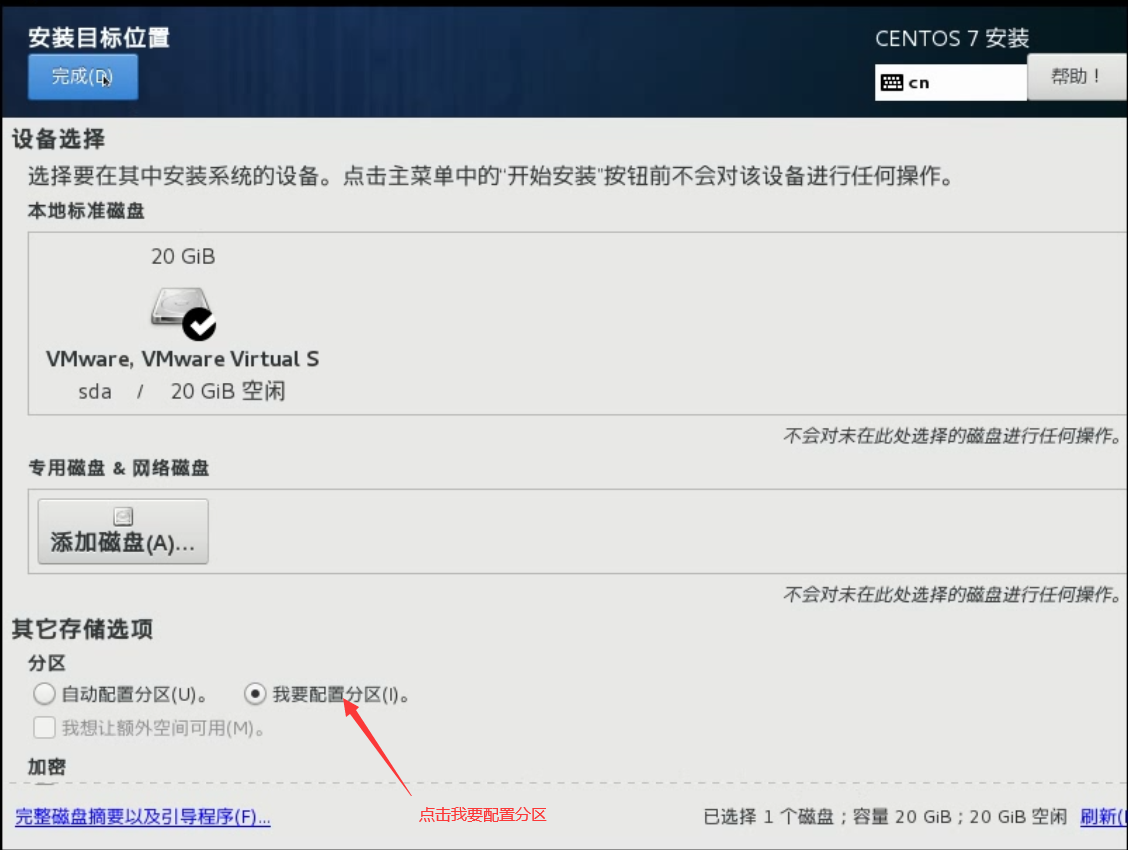
点击完成跳转手动分区
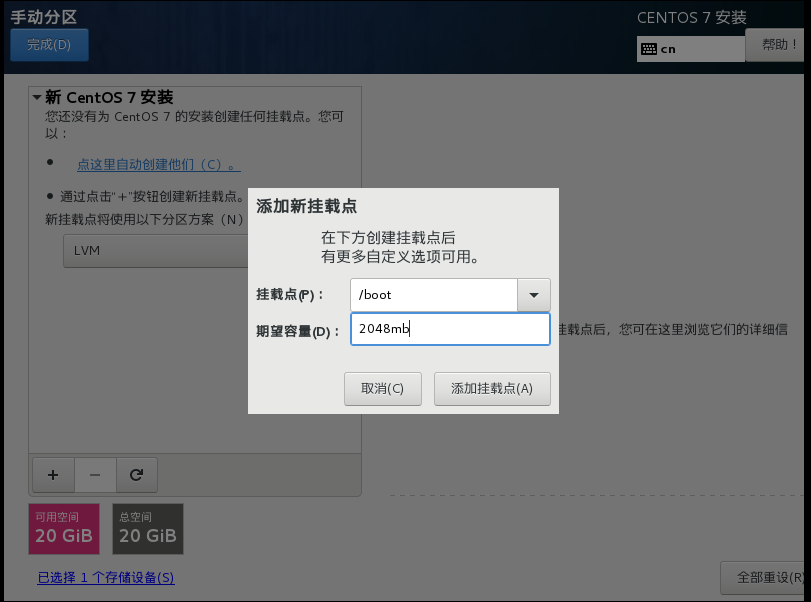
/boot 内含启动文件和内核。 启动文件:用于决断你需要启动哪个百操作系统或者启动哪个内核。 内核:简单的讲,程序与硬件度间的桥梁,你使用应用程序通过内核,控制整个计算机。
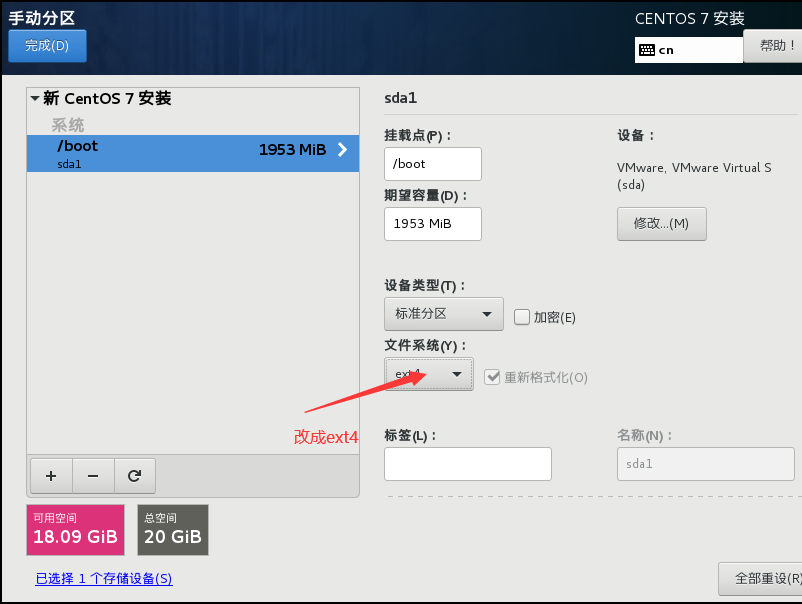
你所设置的文件系统不一样,它所能存储的文件类型也不一样
ext2,ext3 创建的文件数量有限
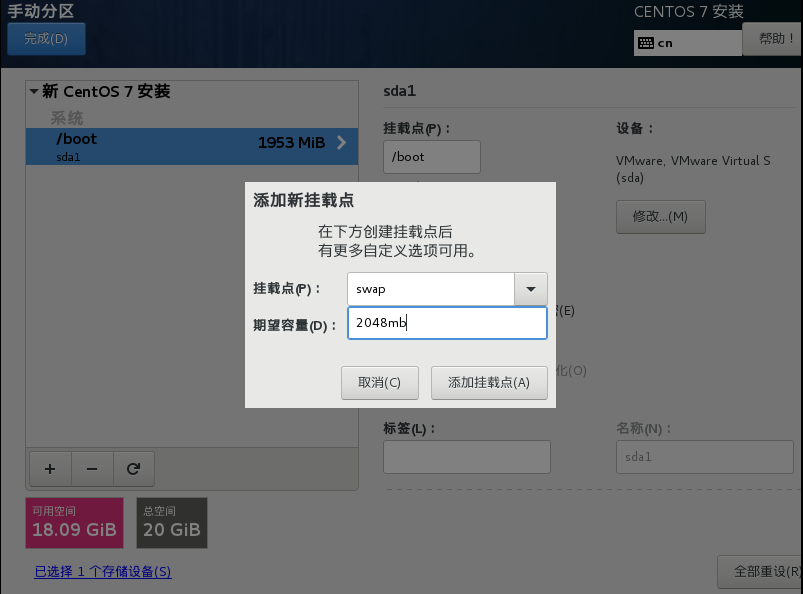
当linux内存不够用的时候,会把swap当成内存进行使用,在linux万物皆是文件
相当于虚拟内存
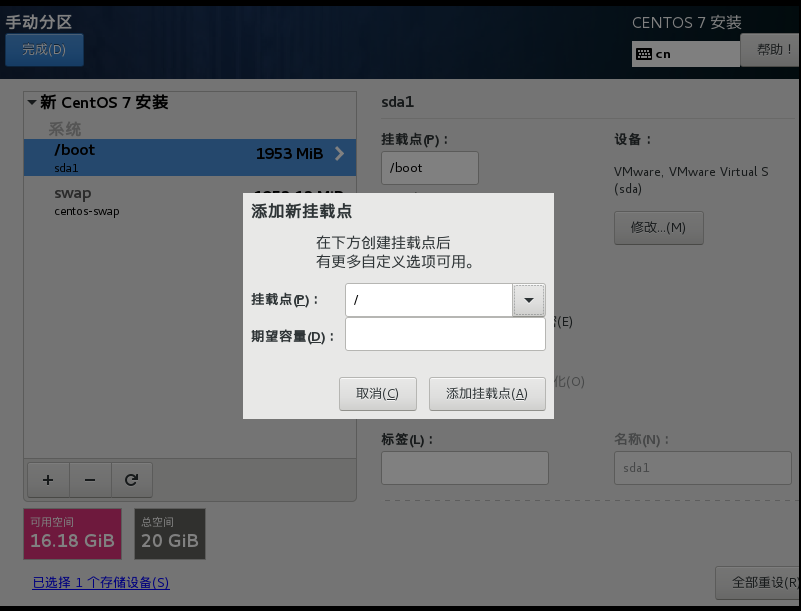
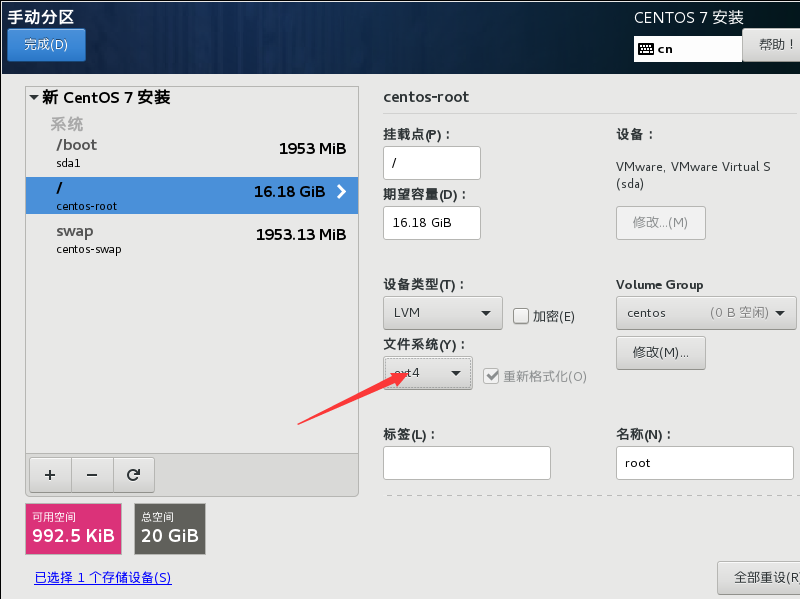
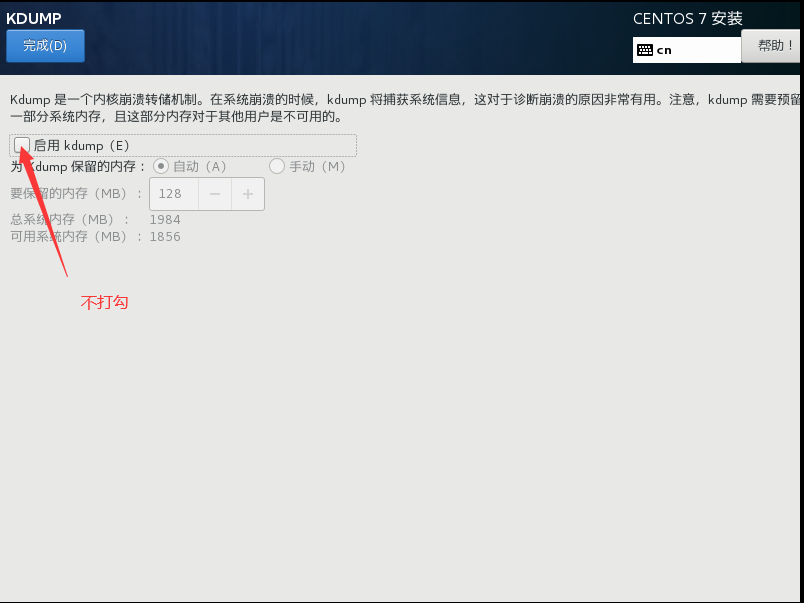
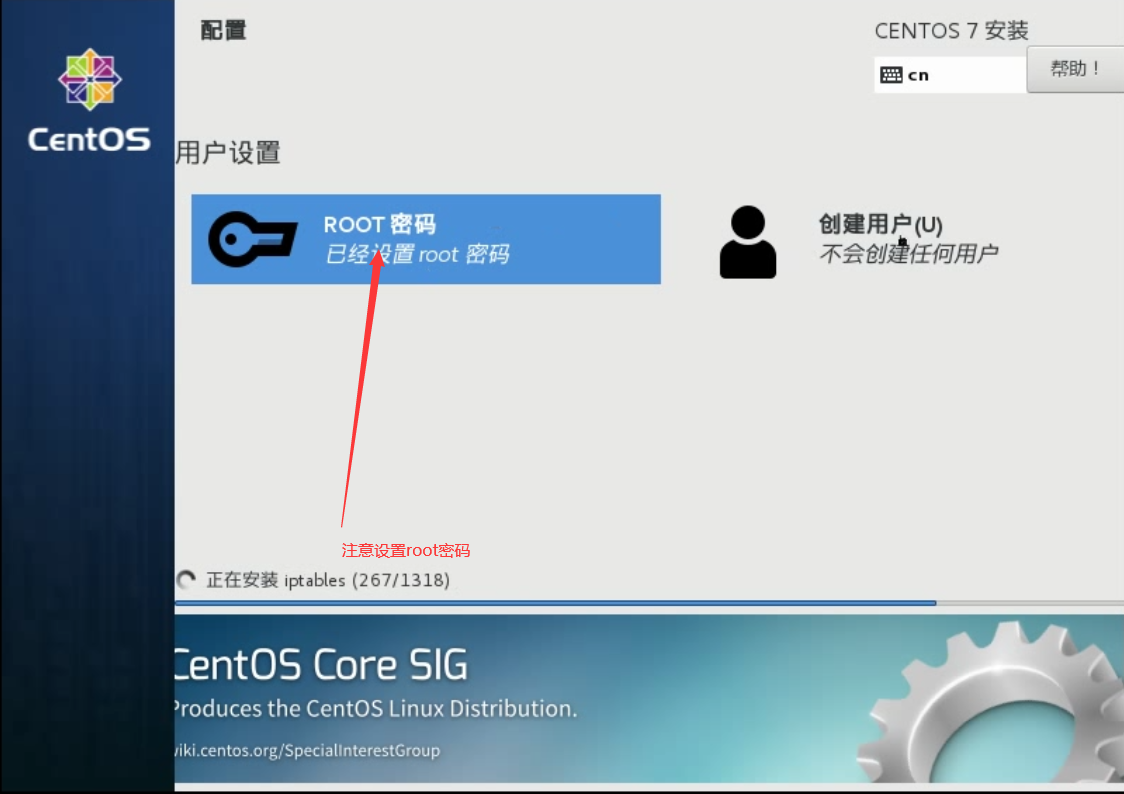
点击安装
同时需要安装xftp和Xshell

第2章 xftp的用法和xshell的用法
xftp的用法
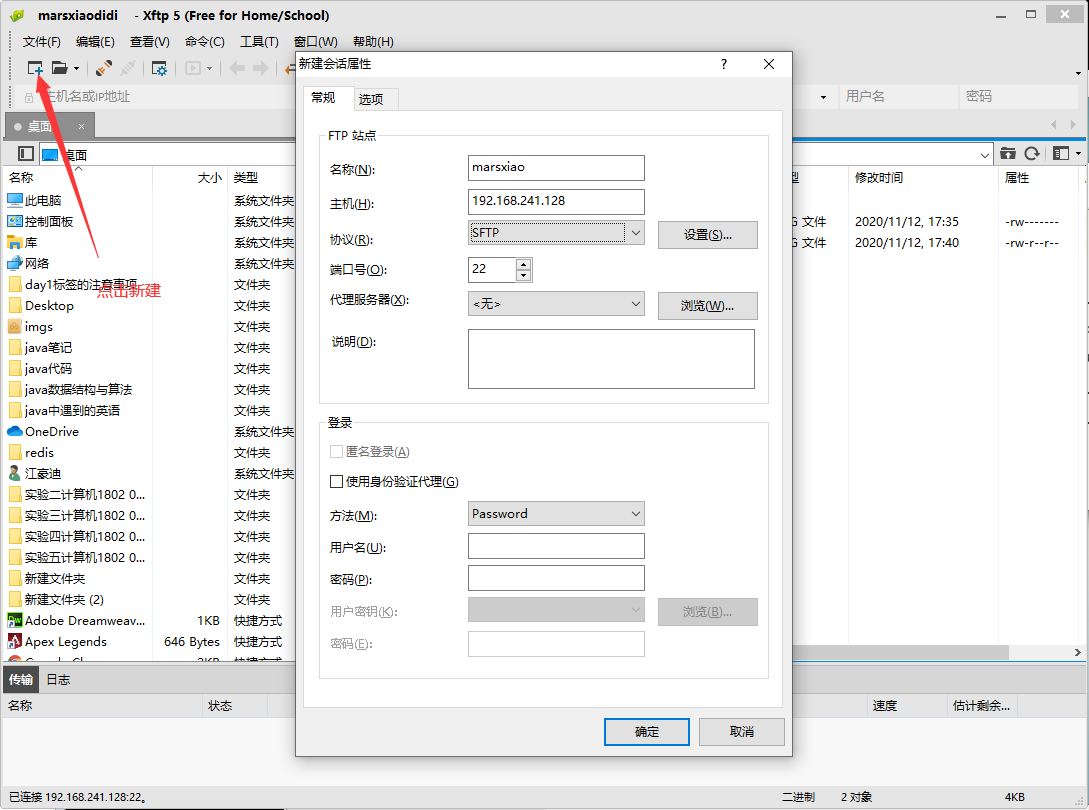
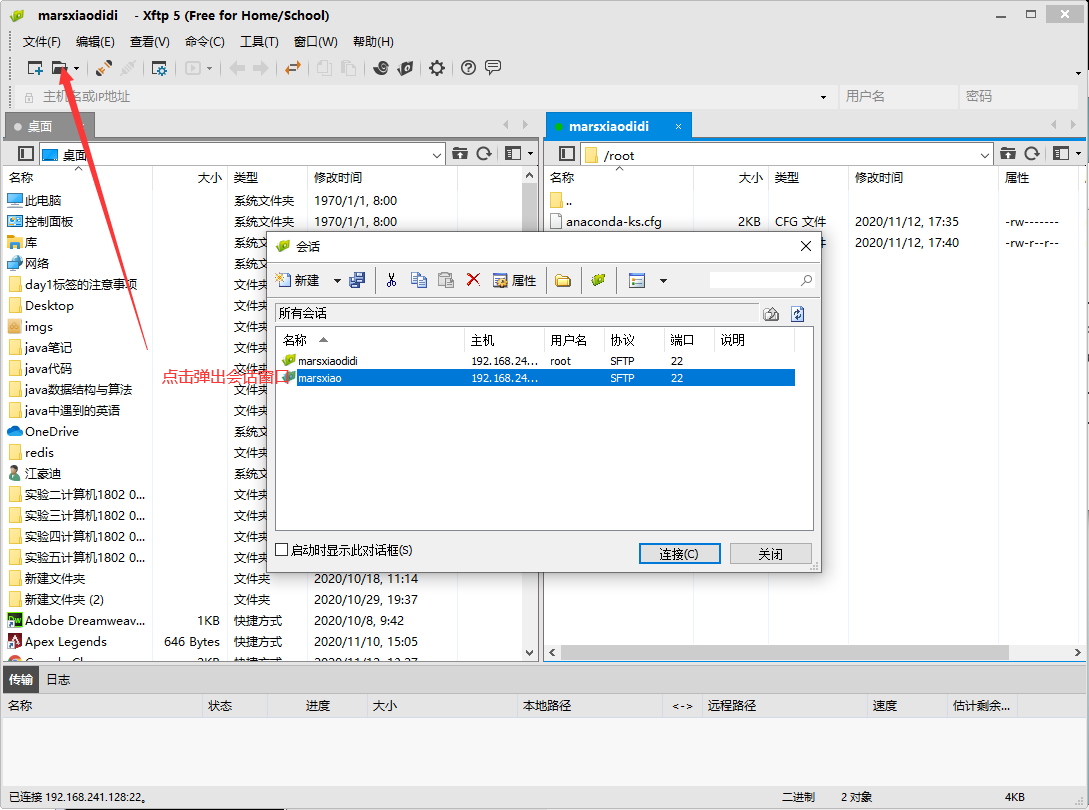
注意用户名和密码需要和linux一致,否则连接失败
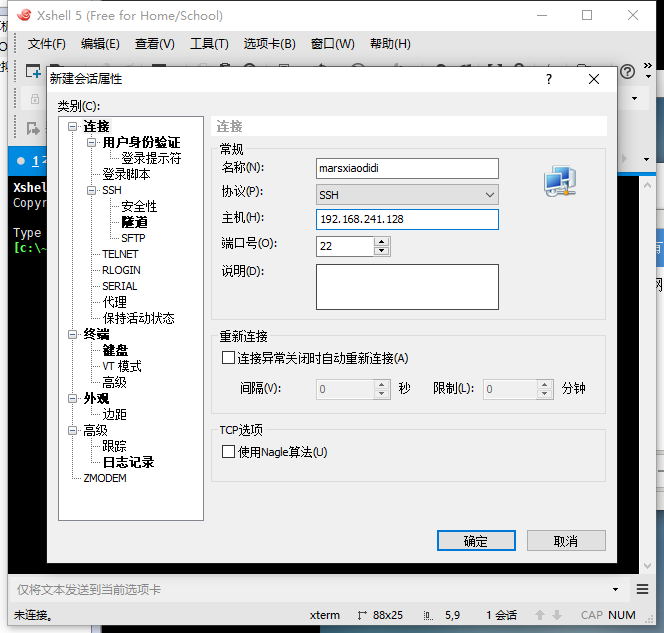
xshell的用法
第3章 linux文件系统
3.1 Linux文件与目录结构
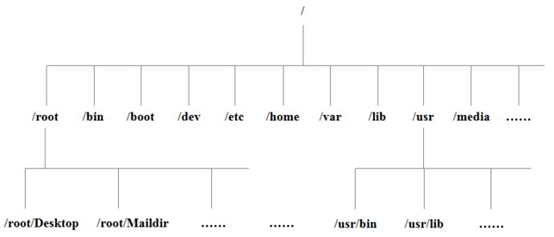
| /bin (/usr/bin、/usr\local\bin) | 是Binary的缩写, 这个目录存放着最经常使用的命令 |
|---|---|
| /sbin(/usr/sbin 、/usr/local/sbin) | s就是Super User的意思,这里存放的是系统管理员使用的系统管理程序。 |
| /home | 存放普通用户的主目录,在Linux中每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的。 |
| /root | 该目录为系统管理员,也称作超级权限者的用户主目录。 |
| /lib | 系统开机所需要最基本的动态连接共享库,其作用类似于Windows里的DLL文件。几乎所有的应用程序都需要用到这些共享库。 |
| /lost+found | 这个目录一般情况下是空的,当系统非法关机后,这里就存放了一些文件 |
| /etc | 所有的系统管理所需要的配置文件和子目录 |
| /usr | 这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似与windows下的program files目录。 |
| /boot | 这里存放的是启动Linux时使用的一些核心文件,包括一些连接文件以及镜像文件,自己的安装别放这里 |
| /proc | 这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息。 |
| /srv | service缩写,该目录存放一些服务启动之后需要提取的数据 |
| /sys | 这是linux2.6内核的一个很大的变化。该目录下安装了2.6内核中新出现的一个文件系统 sysfs |
| /tmp | 这个目录是用来存放一些临时文件的。 |
| /dev | 类似于windows的设备管理器,把所有的硬件用文件的形式存储 |
| /media**(centos6)** | linux系统会自动识别一些设备,例如U盘、光驱等等,当识别后,linux会把识别的设备挂载到这个目录下。 |
| /run | 进程产生的临时文件,虚拟机加载光盘映像在:/run/media/root/ 目录下 |
| /mnt | 系统提供该目录是为了让用户临时挂载别的文件系统的,我们可以将外部的存储挂载在/mnt/上,然后进入该目录就可以查看里的内容了。 |
| /opt | 这是给主机额外安装软件所摆放的目录。比如你安装一个ORACLE数据库则就可以放到这个目录下。默认是空的。 |
| /usr/local | 这是另一个给主机额外安装软件所摆放的目录。一般是通过编译源码方式安装的程序。 |
| /var | 这个目录中存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件。 |
第4章 VI、VIM编辑器
VI、VIM是Linux系统命令下的文本编辑器
通过命令vi文件名 或者是vim文件名来使用
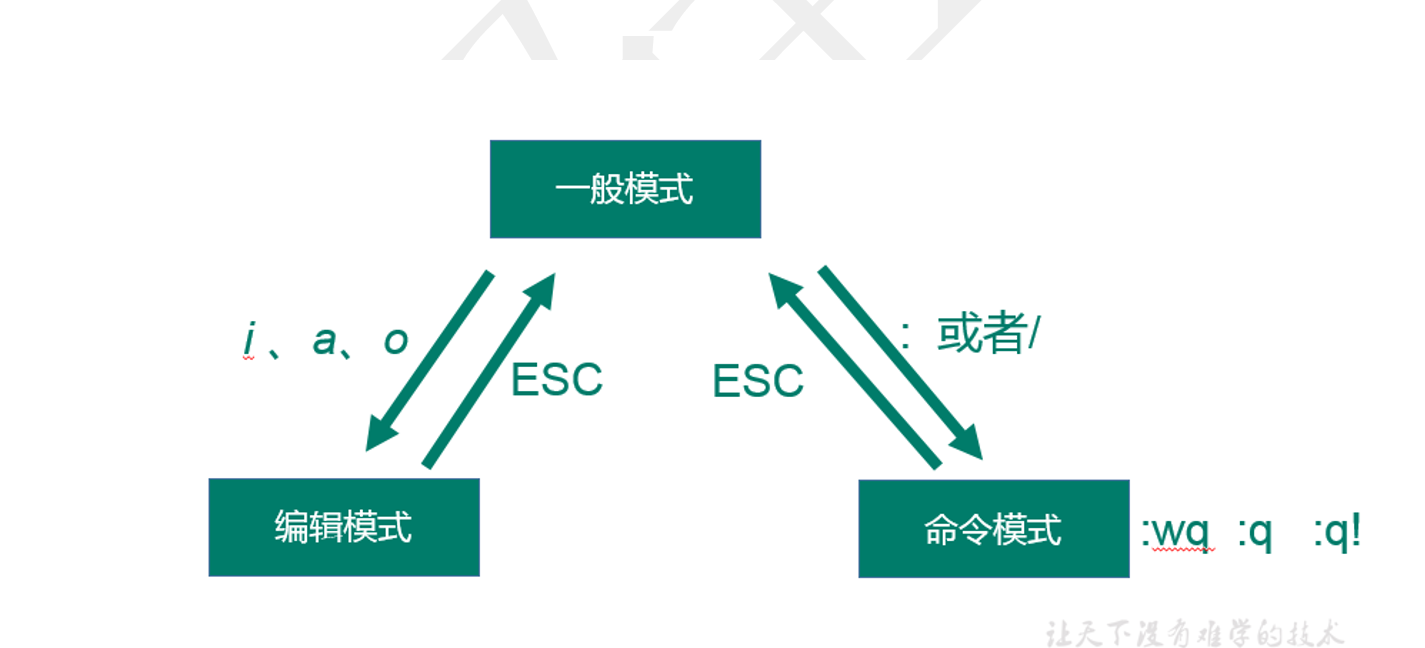
4.1 三种模式
一般模式(默认模式)
1 通过vi或者是vim打开文档后默认进入到一般模式,该模式下主要负责查看和一些基础的修剪工作
2 常用的操作
| dd | 删除光标当前行 |
|---|---|
| d数字nd | 删除n行 |
| u | 撤销上一步 |
| x | 删除一个字母,类似于键盘上Delete功能 |
| X | 删除一个字母,类似于键盘Backspace功能 |
| yy | 复制光标当前行 |
| p | 粘贴 |
| dw | 删除一个词 |
| yw | 复制一个词 |
| Shift+g | 移动到页尾 |
| 1+Shift+g | 移动到目标行 |
| N+shift+g | 移动到第N行 |
| Shift+6 | 移动到行头 |
| Shift+4 | 移动到行尾 |
编辑模式
1 在一般模式下通过字母i、a、o进入到编辑模式,进入后左下角会有【插入】的字样,如想退出编辑模式,需要按下【ESC】按键
2 常用的操作
| i | 当前光标前录入 |
|---|---|
| a | 当前光标后录入 |
| o | 当前光标行的下一行录入 |
| I | 行首录入 |
| A | 行尾录入 |
| O | 当前光标行的上一行录入 |
| S,s | s:删除当前字符并进入编辑 S:删除整行并进入编辑 |
| R | 进入交替模式,替换光标后内容 |
命令模式
在一般模式下输入/或者:进入命令模式,命令模式一般用于存盘、退出VIM、显示行号,搜索、批量替换等操作
常用的操作
| :w | 保存 |
|---|---|
| :q | 退出 |
| :! | 强制执行 |
| :%s/old字符/new字符 | 批量替换 |
| /要查找的词 | 搜索,n查找下一个,N查找上一个 |
| :set nu | 显示行号 |
| :set nonu | 关闭行号 |
| noh | 取消高亮显示 |
4.2 三种模式之间的切换关系
4.3 VI、VIM键盘图

第5章 常用命令
5.1 基本命令
| man | 帮助手册 |
|---|---|
| –help | 帮助手册 |
| date | 日期date +%Y-%m-%d’ ‘%H:%M:%S 或者 # date +%F’ ‘%T |
| cal | 日历 |
| pwd | 显示当前所在目录 |
| cd | 切换目录 cd/ 返回根目录 cd ./sysconfig 通过相对路径去访问 cd或cd~返回家目录 |
| ls | 显示当前目录下的内容 •-a 全部文件,连同隐藏的文件 •-l 列出详细列表 别名 |
| grep | 通过|管道符,配置grep进行过滤筛选 类似模糊查询 ll |grep 2017 |
| mkdir | 创建目录 -p :同时创建多级目录 |
| Touch | 创建文件 |
| rmdir | 删除一个空目录 |
| rm | 删除文件或者目录 -rvf:递归删除所有目录内容,有提示 -rf:递归删除所有目录内容,无提示[慎用] |
| cp | 复制 -r : 递归复制整个目录 -v:显示复制过程中文件的列表 \cp:强制覆盖不提示 |
| mv | 重命名或者移动文件 mv oldFileName newFileName 重命名 mv /原目录/原文件 /新目录 移动文件 |
| cat | 查看文件 cat 文件名 查看轻量级的文本文件 cat 文件1 文件2 连接显示多个文件 cat 文件1 > 文件2 合并为新文件 cat 文件1 » 文件2 追加 |
| more | 查看比较长的文件 空格键: 向下翻一页 回车键: 向下翻一行 q:代表立刻离开more ctrl+F 向下滚动一屏 ctrl+B 向上滚动一屏 |
| less | 同more类似,比more功能更多 pageDown:向下滚动一页 pageUp:向上滚动一页 /字符串: 向下搜索指定字符串 ?字符串:向上搜索执行字符串 n:重复前一个搜索 N:反向重复前一个搜索 |
| tail | 从尾部开始查看文件,比较适合看日志 -f:跟随查看 |
| history | 查看历史命令 |
| echo | 回显,输出 一般在shell脚本中使用较多 |
| find | 查找文件,提供了丰富的模糊搜索及条件搜索 Find+搜索路径+参数+搜索关键字 按文件名: find /目录/… -name “*.txt” |
| locate | 查找文件,基于索引,查询速度更快 通过updatedb来更新索引(是查询保存在内存中的文件,因此在虚拟机打开之后创建的文件无法查看,需要updatedb来更新索引) locate /文件路径/*.conf |
| ln | 软链接 Ln -s 原文件或者目录 软链接名 |
| tar | 压缩文件 、解压缩文件 tar -zcvf xxx.tar.gz xxxx 压缩文件 tar -zxvf xxx.tar.gz 解压缩文件 -c:创建一个新归档 -x:从归档中解出文件 -v:显示详细信息 -f:指定压缩后的文件名 -z:通过gzip过滤归档 |
| zip | 压缩文件 zip xxx.zip xxxx zip -r xxx.zip 目录/* |
| unzip | 解压缩文件 upzip xxx.zip |
| reboot | 重启虚拟机 |
| ps-ef | 查看父进程子进程id |
| yum provides (tree) | 看哪个yum哪个软件包提供了yum的命令 |
| top | 查看系统的进程 |
| free -h | 查看剩余内存 |
| df -h | 查看磁盘分区大小的 |
| du -h /opt/module | 查看文件夹用了多少 |
| iotop | 查看io性能的 |
| sz/rz | sz hdfs.cmd 下载文件到你需要的目录 |
pwd 显示当前工作目录的绝对路径
pwd:print working directory 打印工作目录
1.基本语法
pwd (功能描述:显示当前工作目录的绝对路径)
2.案例实操
(1)显示当前工作目录的绝对路径
[root@hadoop101 ~]# pwd
/root
ls 列出目录的内容
ls:list 列出目录内容
1.基本语法
ls [选项] [目录或是文件]
2.选项说明
表1-8 选项说明
| 选项 | 功能 |
|---|---|
| -a | 全部的文件,连同隐藏档( 开头为 . 的文件) 一起列出来(常用) |
| -l | 长数据串列出,包含文件的属性与权限等等数据;(常用) |
3.显示说明
每行列出的信息依次是: 文件类型与权限 链接数 文件属主 文件属组 文件大小用byte来表示 建立或最近修改的时间 名字
4.案例实操
(1)查看当前目录的所有内容信息
[atguigu@hadoop101 ~]$ ls -al
总用量 44
drwx——. 5 atguigu atguigu 4096 5月 27 15:15 .
drwxr-xr-x. 3 root root 4096 5月 27 14:03 ..
drwxrwxrwx. 2 root root 4096 5月 27 14:14 hello
-rwxrw-r–. 1 atguigu atguigu 34 5月 27 14:20 test.txt
cd 切换目录
cd:Change Directory切换路径
1.基本语法
cd [参数]
2.参数说明
表1-9 参数说明
| 参数 | 功能 |
|---|---|
| cd 绝对路径 | 切换路径 |
| cd相对路径 | 切换路径 |
| cd ~或者cd | 回到自己的家目录 |
| cd - | 回到上一次所在目录 |
| cd .. | 回到当前目录的上一级目录 |
| cd -P | 跳转到实际物理路径,而非软连接路径 |
3.案例实操
(1)使用绝对路径切换到root目录
[root@hadoop101 ~]# cd /root/
(2)使用相对路径切换到“公共的”目录
[root@hadoop101 ~]# cd 公共的/
(3)表示回到自己的家目录,亦即是 /root 这个目录
[root@hadoop101 公共的]# cd ~
(4)cd- 回到上一次所在目录
[root@hadoop101 ~]# cd -
(5)表示回到当前目录的上一级目录,亦即是 “/root/公共的”的上一级目录的意思;
[root@hadoop101 公共的]# cd ..
mkdir 创建一个新的目录
mkdir:Make directory 建立目录
1.基本语法
mkdir [选项] 要创建的目录
2.选项说明
表1-10 选项说明
| 选项 | 功能 |
|---|---|
| -p | 创建多层目录 |
3.案例实操
(1)创建一个目录
[root@hadoop101 ~]# mkdir xiyou
[root@hadoop101 ~]# mkdir xiyou/mingjie
(2)创建一个多级目录
[root@hadoop101 ~]# mkdir -p xiyou/dssz/meihouwang
rmdir 删除一个空的目录
rmdir:Remove directory 移动目录
1.基本语法:
rmdir 要删除的空目录
2.案例实操
(1)删除一个空的文件夹
[root@hadoop101 ~]# rmdir xiyou/dssz/meihouwang
touch 创建空文件
1.基本语法
touch 文件名称
2.案例实操
[root@hadoop101 ~]# touch xiyou/dssz/sunwukong.txt
cp 复制文件或目录
1.基本语法
cp [选项] source dest (功能描述:复制source文件到dest)
2.选项说明
表1-11 选项说明
| 选项 | 功能 |
|---|---|
| -r | 递归复制整个文件夹 |
3.参数说明
表1-12 参数说明
| 参数 | 功能 |
|---|---|
| source | 源文件 |
| dest | 目标文件 |
4.经验技巧
强制覆盖不提示的方法:\cp
5.案例实操
(1)复制文件
[root@hadoop101 ~]# cp xiyou/dssz/suwukong.txt xiyou/mingjie/
(2)递归复制整个文件夹
[root@hadoop101 ~]# cp -r xiyou/dssz/ ./
rm 移除文件或目录
1.基本语法
rm [选项] deleteFile (功能描述:递归删除目录中所有内容)
2.选项说明
表1-13 选项说明
| 选项 | 功能 |
|---|---|
| -r | 递归删除目录中所有内容 |
| -f | 强制执行删除操作,而不提示用于进行确认。 |
| -v | 显示指令的详细执行过程 |
\3. 案例实操
(1)删除目录中的内容
[root@hadoop101 ~]# rm xiyou/mingjie/sunwukong.txt
(2)递归删除目录中所有内容
[root@hadoop101 ~]# rm -rf dssz/
mv 移动文件与目录或重命名
1.基本语法
(1)mv oldNameFile newNameFile (功能描述:重命名)
(2)mv /temp/movefile /targetFolder (功能描述:移动文件)
2.案例实操
(1)重命名
[root@hadoop101 ~]# mv xiyou/dssz/suwukong.txt xiyou/dssz/houge.txt
(2)移动文件
[root@hadoop101 ~]# mv xiyou/dssz/houge.txt ./
cat 查看文件内容
查看文件内容,从第一行开始显示。
1.基本语法
cat [选项] 要查看的文件
2.选项说明
表1-14
| 选项 | 功能描述 |
|---|---|
| -n | 显示所有行的行号,包括空行。 |
3.经验技巧
一般查看比较小的文件,一屏幕能显示全的。
4.案例实操
(1)查看文件内容并显示行号
[atguigu@hadoop101 ~]$ cat -n houge.txt
more 文件内容分屏查看器
more指令是一个基于VI编辑器的文本过滤器,它以全屏幕的方式按页显示文本文件的内容。more指令中内置了若干快捷键,详见操作说明。
1.基本语法
more 要查看的文件
2.操作说明
表1-15 操作说明
| 操作 | 功能说明 |
|---|---|
| 空白键 (space) | 代表向下翻一页; |
| Enter | 代表向下翻『一行』; |
| q | 代表立刻离开 more ,不再显示该文件内容。 |
| Ctrl+F | 向下滚动一屏 |
| Ctrl+B | 返回上一屏 |
| = | 输出当前行的行号 |
| :f | 输出文件名和当前行的行号 |
3.案例实操
(1)采用more查看文件
[root@hadoop101 ~]# more smartd.conf
less 分屏显示文件内容
less指令用来分屏查看文件内容,它的功能与more指令类似,但是比more指令更加强大,支持各种显示终端。less指令在显示文件内容时,并不是一次将整个文件加载之后才显示,而是根据显示需要加载内容,对于显示大型文件具有较高的效率。
1.基本语法
less 要查看的文件
2.操作说明
表1-16 操作说明
| 操作 | 功能说明 |
|---|---|
| 空白键 | 向下翻动一页; |
| [pagedown] | 向下翻动一页 |
| [pageup] | 向上翻动一页; |
| /字串 | 向下搜寻『字串』的功能;n:向下查找;N:向上查找; |
| ?字串 | 向上搜寻『字串』的功能;n:向上查找;N:向下查找; |
| q | 离开 less 这个程序; |
4.案例实操
(1)采用less查看文件
[root@hadoop101 ~]# less smartd.conf
echo
echo输出内容到控制台
\1. 基本语法
echo [选项] [输出内容]
选项:
-e: 支持反斜线控制的字符转换
| 控制字符 | 作用 |
|---|---|
| \ | 输出\本身 |
| \n | 换行符 |
| \t | 制表符,也就是Tab键 |
\2. 案例实操
[atguigu@hadoop101 ~]$ echo “hello\tworld”
hello\tworld
[atguigu@hadoop101 ~]$ echo -e “hello\tworld”
hello world
head 显示文件头部内容
head用于显示文件的开头部分内容,默认情况下head指令显示文件的前10行内容。
\1. 基本语法
head 文件 (功能描述:查看文件头10行内容)
head -n 5 文件 (功能描述:查看文件头5行内容,5可以是任意行数)
2.选项说明
表1-18
| 选项 | 功能 |
|---|---|
| -n <行数> | 指定显示头部内容的行数 |
3.案例实操
(1)查看文件的头2行
[root@hadoop101 ~]# head -n 2 smartd.conf
tail 输出文件尾部内容
tail用于输出文件中尾部的内容,默认情况下tail指令显示文件的后10行内容。
\1. 基本语法
(1)tail 文件 (功能描述:查看文件后10行内容)
(2)tail -n 5 文件 (功能描述:查看文件后5行内容,5可以是任意行数)
(3)tail -f 文件 (功能描述:实时追踪该文档的所有更新)
2. 选项说明
表1-19
| 选项 | 功能 |
|---|---|
| -n<行数> | 输出文件尾部n行内容 |
| -f | 显示文件最新追加的内容,监视文件变化 |
3.案例实操
(1)查看文件头1行内容
[root@hadoop101 ~]# tail -n 1 smartd.conf
(2)实时追踪该档的所有更新
[root@hadoop101 ~]# tail -f houge.txt
> 覆盖 和 » 追加
1.基本语法
(1)ll >文件 (功能描述:列表的内容写入文件a.txt中(覆盖写))
(2)ll »文件 (功能描述:列表的内容追加到文件aa.txt的末尾)
(3)cat 文件1 > 文件2 (功能描述:将文件1的内容覆盖到文件2)
(4)echo “内容” » 文件
2.案例实操
(1)将ls查看信息写入到文件中
[root@hadoop101 ~]# ls -l>houge.txt
(2)将ls查看信息追加到文件中
[root@hadoop101 ~]# ls -l»houge.txt
(3)采用echo将hello单词追加到文件中
[root@hadoop101 ~]# echo hello»houge.txt
ln 软链接
软链接也成为符号链接,类似于windows里的快捷方式,有自己的数据块,主要存放了链接其他文件的路径。
1.基本语法
ln -s [原文件或目录] [软链接名] (功能描述:给原文件创建一个软链接)
2.经验技巧
删除软链接: rm -rf 软链接名,而不是rm -rf 软链接名/
查询:通过ll就可以查看,列表属性第1位是l,尾部会有位置指向。
3.案例实操
(1)创建软连接
[root@hadoop101 ~]# mv houge.txt xiyou/dssz/
[root@hadoop101 ~]# ln -s xiyou/dssz/houge.txt ./houzi
[root@hadoop101 ~]# ll
lrwxrwxrwx. 1 root root 20 6月 17 12:56 houzi -> xiyou/dssz/houge.txt
(2)删除软连接
[root@hadoop101 ~]# rm -rf houzi
(3)进入软连接实际物理路径
[root@hadoop101 ~]# ln -s xiyou/dssz/ ./dssz
[root@hadoop101 ~]# cd -P dssz/
history 查看已经执行过历史命令
1.基本语法
history (功能描述:查看已经执行过历史命令)
2.案例实操
(1)查看已经执行过的历史命令
[root@hadoop101 test1]# history
时间日期类
date 显示当前时间
1.基本语法
(1)date (功能描述:显示当前时间)
(2)date +%Y (功能描述:显示当前年份)
(3)date +%m (功能描述:显示当前月份)
(4)date +%d (功能描述:显示当前是哪一天)
(5)date “+%Y-%m-%d %H:%M:%S” (功能描述:显示年月日时分秒)
2.案例实操
(1)显示当前时间信息
[root@hadoop101 ~]# date
2017年 06月 19日 星期一 20:53:30 CST
(2)显示当前时间年月日
[root@hadoop101 ~]# date +%Y%m%d
20170619
(3)显示当前时间年月日时分秒
[root@hadoop101 ~]# date "+%Y-%m-%d %H:%M:%S"
2017-06-19 20:54:58
date 显示非当前时间
1.基本语法
(1)date -d ‘1 days ago’ (功能描述:显示前一天时间)
(2)date -d ‘-1 days ago’ (功能描述:显示明天时间)
2.案例实操
(1)显示前一天
[root@hadoop101 ~]# date -d '1 days ago'
2017年 06月 18日 星期日 21:07:22 CST
(2)显示明天时间
[root@hadoop101 ~]#date -d '-1 days ago'
2017年 06月 20日 星期日 21:07:22 CST
date 设置系统时间
1.基本语法
date -s 字符串时间
尚硅谷大数据技术之 Linux
—————————————————————————————
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
2.案例实操
(1)设置系统当前时间
[root@hadoop101 ~]# date -s "2017-06-19 20:52:18"
cal 查看日历
1.基本语法
cal [选项] (功能描述:不加选项,显示本月日历)
2.选项说明
表1-22
选项
功能
具体某一年
显示这一年的日历
3.案例实操
(1)查看当前月的日历
[root@hadoop101 ~]# cal
(2)查看2017年的日历
[root@hadoop101 ~]# cal 2017
第5章 压缩和解压类
5.1 gzip/gunzip 压缩
1.基本语法
gzip 文件 (功能描述:压缩文件,只能将文件压缩为*.gz文件)
gunzip 文件.gz (功能描述:解压缩文件命令)
2.经验技巧
(1)只能压缩文件不能压缩目录
(2)不保留原来的文件
3.案例实操
(1)gzip压缩
[root@hadoop101 ~]# ls
test.java
[root@hadoop101 ~]# gzip houge.txt
[root@hadoop101 ~]# ls
houge.txt.gz
(2)gunzip解压缩文件
[root@hadoop101 ~]# gunzip houge.txt.gz
[root@hadoop101 ~]# ls
houge.txt
5.2 zip/unzip 压缩
1.基本语法
zip [选项] XXX.zip 将要压缩的内容 (功能描述:压缩文件和目录的命令)
unzip [选项] XXX.zip (功能描述:解压缩文件)
2.选项说明
表1-29
| zip选项 | 功能 |
|---|---|
| -r | 压缩目录 |
表1-30
| unzip选项 | 功能 |
|---|---|
| -d<目录> | 指定解压后文件的存放目录 |
3.经验技巧
zip 压缩命令在window/linux都通用,可以压缩目录且保留源文件。
4.案例实操
(1)压缩 1.txt 和2.txt,压缩后的名称为mypackage.zip
[root@hadoop101 opt]# touch bailongma.txt
[root@hadoop101 ~]# zip houma.zip houge.txt bailongma.txt
adding: houge.txt (stored 0%)
adding: bailongma.txt (stored 0%)
[root@hadoop101 opt]# ls
houge.txt bailongma.txt houma.zip
(2)解压 mypackage.zip
[root@hadoop101 ~]# unzip houma.zip
Archive: houma.zip
extracting: houge.txt
extracting: bailongma.txt
[root@hadoop101 ~]# ls
houge.txt bailongma.txt houma.zip
(3)解压mypackage.zip到指定目录-d
[root@hadoop101 ~]# unzip houma.zip -d /opt
[root@hadoop101 ~]# ls /opt/
5.3 tar 打包
1.基本语法
tar [选项] XXX.tar.gz 将要打包进去的内容 (功能描述:打包目录,压缩后的文件格式.tar.gz)
2.选项说明
表1-31
| 选项 | 功能 |
|---|---|
| -z | 打包同时压缩 |
| -c | 产生**.tar****打包文件** |
| -v | 显示详细信息 |
| -f | 指定压缩后的文件名 |
| -x | 解包**.tar****文件** |
3.案例实操
(1)压缩多个文件
[root@hadoop101 opt]# tar -zcvf houma.tar.gz houge.txt bailongma.txt
houge.txt
bailongma.txt
[root@hadoop101 opt]# ls
houma.tar.gz houge.txt bailongma.txt
(2)压缩目录
[root@hadoop101 ~]# tar -zcvf xiyou.tar.gz xiyou/
xiyou/
xiyou/mingjie/
xiyou/dssz/
xiyou/dssz/houge.txt
(3)解压到当前目录
[root@hadoop101 ~]# tar -zxvf houma.tar.gz
(4)解压到指定目录
[root@hadoop101 ~]# tar -zxvf xiyou.tar.gz -C /opt
[root@hadoop101 ~]# ll /opt/
时间日期类
1.基本语法
date [OPTION]… [+FORMAT]
2.选项说明
表1-20
| 选项 | 功能 |
|---|---|
| -d<时间字符串> | 显示指定的“时间字符串”表示的时间,而非当前时间 |
| -s<日期时间> | 设置系统日期时间 |
3.参数说明
表1-21
| 参数 | 功能 |
|---|---|
| <+日期时间格式> | 指定显示时使用的日期时间格式 |
date 显示当前时间
1.基本语法
(1)date (功能描述:显示当前时间)
(2)date +%Y (功能描述:显示当前年份)
(3)date +%m (功能描述:显示当前月份)
(4)date +%d (功能描述:显示当前是哪一天)
(5)date “+%Y-%m-%d %H:%M:%S” (功能描述:显示年月日时分秒)
2.案例实操
(1)显示当前时间信息
[root@hadoop101 ~]# date
2017年 06月 19日 星期一 20:53:30 CST
(2)显示当前时间年月日
[root@hadoop101 ~]# date +%Y%m%d
20170619
(3)显示当前时间年月日时分秒
[root@hadoop101 ~]# date “+%Y-%m-%d %H:%M:%S”
2017-06-19 20:54:58
date 显示非当前时间
1.基本语法
(1)date -d ‘1 days ago’ (功能描述:显示前一天时间)
(2)date -d ‘-1 days ago’ (功能描述:显示明天时间)
2.案例实操
(1)显示前一天
[root@hadoop101 ~]# date -d ‘1 days ago’
2017年 06月 18日 星期日 21:07:22 CST
(2)显示明天时间
[root@hadoop101 ~]#date -d ‘-1 days ago’
2017年 06月 20日 星期日 21:07:22 CST
date 设置系统时间
1.基本语法
date -s 字符串时间
2.案例实操
(1)设置系统当前时间
[root@hadoop101 ~]# date -s “2017-06-19 20:52:18”
cal 查看日历
1.基本语法
cal [选项] (功能描述:不加选项,显示本月日历)
2.选项说明
表1-22
| 选项 | 功能 |
|---|---|
| 具体某一年 | 显示这一年的日历 |
3.案例实操
(1)查看当前月的日历
[root@hadoop101 ~]# cal
(2)查看2017年的日历
[root@hadoop101 ~]# cal 2017
第6章 添加硬盘
查看所有设备挂载情况
命令:lsblk或者lsblk -f
如何添加一块硬盘
1 .虚拟机插硬盘
2 .分区
3 .格式化
5 .挂载
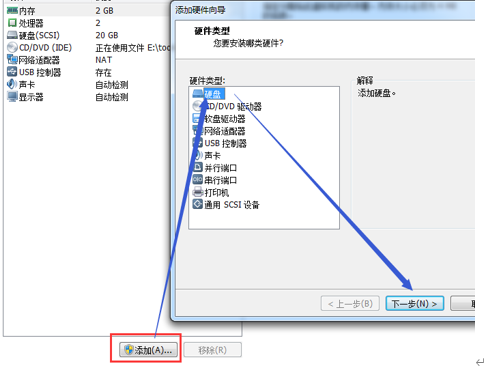
虚拟机插入新硬盘
在【虚拟机】菜单中,选择【设置】,然后设备列表里添加硬盘,然后一路【下一步】中间只有选择磁盘大小的地方需要修改,直到完成,然后重启系统
进行分区
分区命令 fdisk /dev/sdb
开始对/sdb分区
m 显示命令列表
p 显示磁盘
n 新增分区
d 删除分区
w 写入并退出分区
分区步骤如下: 开始分区后输入n,新增分区,然后选择p ,分区类型为主分区。两次回车默认剩余全部空间。最后输入w写入分区并退出,若不保存退出输入q。


格式化磁盘
mkfs -t ext4 /dev/sdb1
挂载
将一个分区和一个目录联系起来(相当于u盘)
mount 设备名称 挂载目录
例如:mount /dev/sdb1 /newdisk
umount 设备名称或者 挂载目录
例如:umount /dev/sdb1 或者umount /newdisk
注意:用命令行挂载重启后会失效
永久挂载
通过修改/etc/fstab实现挂载
添加完成后执行mount -a 即刻生效
/etc/fatab文件参数介绍
第一列:磁盘设备文件或者该设备的Label或者UUID
第二列: 设备的挂载点,就是你要挂载到哪个目录下
第三列: 磁盘文件系统的格式,
包括ext2、ext3、reiserfs、nfs、vfat等
第四列: 文件系统的参数 ,defaults代表同时具有
rw,suid,dev,exec,auto,nouser,async等默认参数的设置
第五列: 能否被dump备份命令作用
0 代表不要做dump备份
1 代表要每天进行dump的操作
2 代表不定日期的进行dump操作
第六列: 是否检验扇区
0 不要检验
1 最早检验(一般根目录会选择)
2 1级别检验完成之后进行检验
/dev/sdb1 newDisk ext4 defaults 0 0
注意配置完成需要mount -a
磁盘情况查询
df -h 查询系统整体磁盘使用情况
du -h /目录
查询指定目录的磁盘占用情况,默认为当前目录
-s 只当目录占用大小汇总
-h 带计量单位
-a 含文件
–max-depth=1 子目录深度
-c 列出明细的同时,增加汇总值
例: du -ach –max-depth=1 /opt
第7章 网络配置和修改ip
查看网络IP和网关
5.1 查看网络IP和网关
1.查看虚拟网络编辑器,如图1-95所示
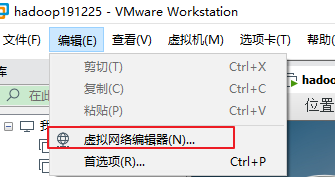
图1-95 查看虚拟网络编辑器
2.修改ip地址,如图1-96所示
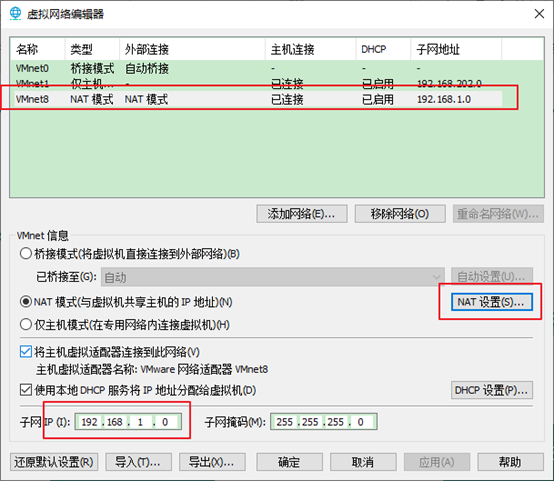
图1-96 修改ip地址
3.查看网关,如图1-97所示
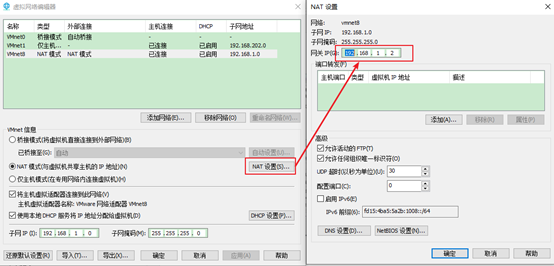
图1-97 查看网关
\4. 查看windows环境的中VMnet8网络配置,如图1-98所示
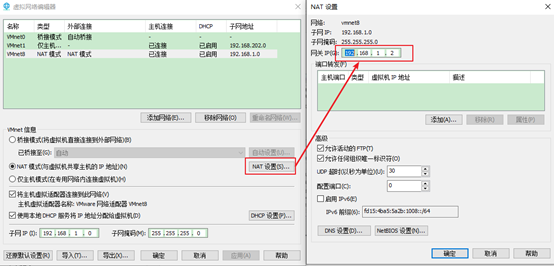
图1-98 windows中VMnet8网络配置
ifconfig 查看网络配置
通过图形化页面进行网络配置
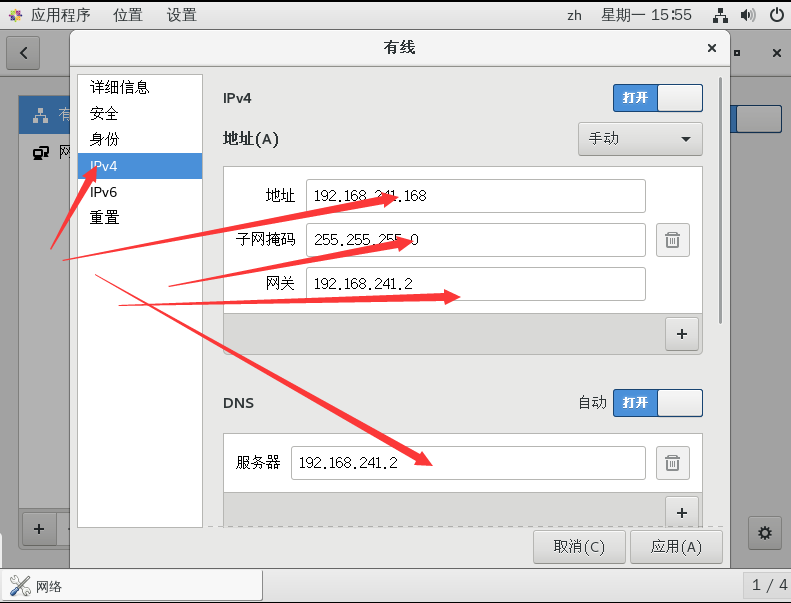
用命令行的方式进行网络配置
命令行的方式 vi /etc/sysconfig/network-scripts/ifcfg-ens33
加入BOOTPROTO=static
#IP地址
IPADDR=192.168.1.100
#网关
GATEWAY=192.168.1.2
#域名解析器
DNS1=192.168.1.2
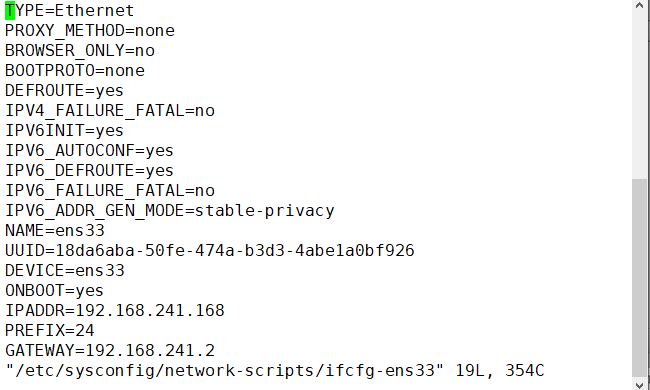
DEVICE=eth0 #接口名(设备,网卡)
BOOTPROTO=none # IP的配置方法[none|static|bootp|dhcp](引导时不使用协
议|静态分配IP|BOOTP协议|DHCP 协议)
BROADCAST=192.168.1.255 #广播地址
HWADDR=00:0C:2x:6x:0x:xx #MAC地址
IPADDR=192.168.1.23 #IP地址
NETMASK=255.255.255.0 # 网络掩码
NETWORK=192.168.1.0 #网络地址
ONBOOT=yes #系统启动的时候网络接口是否有效(yes/no)
TYPE=Ethernet #网络类型(通常是Ethemet)
systemctl restart network
重启网络服务
第8章 进程类
ps(process)
ps显示的信息选项
| 字段 | 说明 |
|---|---|
| PID | 进程识别号 |
| TTY | 终端机号 |
| TIME | 此进程所消耗的CPU时间 |
| CMD | 正在执行的命令或进程名 |
-
ps -aux
-a : 显示当前总段的所有进行信息
-u : 以用户的格式显示进程信息
-x : 显示后台进程运行的参数
l 详细内容解释
ps –aux|grep xxx
System V展示风格
USER:用户名称
PID:进程号
%CPU:进程占用CPU的百分比
%MEM:进程占用物理内存的百分比
VSZ:进程占用的虚拟内存大小(单位:KB)
RSS:进程占用的物理内存大小(单位:KB)
TT:终端名称,缩写
STAT:进程状态,其中S-睡眠,s-表示该进程是会话的先导进程,N-表示进程拥有比普通优先级更低的优先级,R-正在运行,D-短期等待,Z-僵死进程,T-被跟踪或者被停止等等
STARTED:进程的启动时间
TIME:CPU时间,即进程使用CPU的总时间
COMMAND:启动进程所用的命令和参数,如果过长会被截断显示
-
ps -ef
ps -ef是以全格式显示当前所有的进程
-e 显示所有进程。-f 全格式。
ps -ef|grep xxx
是BSD风格
UID:用户ID
PID:进程ID
PPID:父进程ID
C:CPU用于计算执行优先级的因子。数值越大,表明进程是CPU密集型运算,执行优先级会降低;数值越小,表明进程是I/O密集型运算,执行优先级会提高
STIME:进程启动的时间
TTY:完整的终端名称
TIME:CPU时间
CMD:启动进程所用的命令和参数
-
kill pid 杀死指定pid对应的进程.
-9: 强行杀死进程
4) killall
•killall name 通过进程名称杀死进程
第9章 服务类
注册在系统中的标准化程序
有方便统一的管理方式(常用的方法)
service 服务名 start
service 服务名 stop
service 服务名 restart
service 服务名 reload
service 服务名 status
查看服务的方法 /etc/init.d/服务名
通过chkconfig命令设置自启动
查看服务chkconfig –list|grep xxx
chkconfig –level 5 服务名 on
运行级别:
开机 -> bios ->/boot -> init进程 -> 运行级别 -> 运行级对应的服务
查看默认级别 vi /etc/inittab
linux系统有7种运行级别(runlevel):常用的是级别3和5
运行级别0:系统停机状态,系统默认运行级别不能设为0,否则不能正常启动
运行级别1:单用户工作状态,root权限,用于系统维护,禁止远程登陆
运行级别2:多用户状态(没有NFS),不支持网络
运行级别3:完全的多用户状态(有NFS),登陆后进入控制台命令行模式
运行级别4:系统未使用,保留
运行级别5:X11控制台,登陆后进入图形GUI模式
运行级别6:系统正常关闭并重启,默认运行级别不能设为6,否则不能正常启动
2)systemctl(CentOS7)
注册在系统中的标准化程序
有方便统一的管理方式(常用的方法
systemctl start 服务名(xxxx.service)
systemctl restart 服务名(xxxx.service)
systemctl stop 服务名(xxxx.service)
systemctl reload 服务名(xxxx.service)
systemctl status 服务名(xxxx.service)
查看服务的方法 /usr/lib/systemd/system
查看服务的命令
systemctl list-unit-files
systemctl list-unit-files |grep firewalld 查看防火墙的服务
systemctl –type service
通过systemctl 命令设置自启动
自启动 systemctl enable xxxx.service
不自启动 sysyemctl disable xxxx.service
运行级别
开机 -> bios ->/boot -> systemd进程 -> 运行级别 -> 运行级对应的服务
查看默认级别 : vim /etc/linittab
第10章 查看端口号占用情况
netstat
查看系统的网络情况
-an 按一定顺序排列输出
-p 显示哪个进程在调用
netstat -anp|grep 8080 查看占用8080端口
第11章 Linux用户与权限管理
useradd 添加新用户
1.基本语法
useradd 用户名 (功能描述:添加新用户)
useradd -g 组名 用户名 (功能描述:添加新用户到某个组)
2.案例实操
(1)添加一个用户
[root@hadoop101 ~]# useradd tangseng
[root@hadoop101 ~]#ll /home/
passwd 设置用户密码
1.基本语法
passwd 用户名 (功能描述:设置用户密码)
2.案例实操
(1)设置用户的密码
[root@hadoop101 ~]# passwd tangseng
id 查看用户是否存在
1.基本语法
id 用户名
2.案例实操
(1)查看用户是否存在
[root@hadoop101 ~]#id tangseng
cat /etc/passwd 查看创建了哪些用户
1)基本语法
[root@hadoop101 ~]# cat /etc/passwd
su 切换用户
su: swith user 切换用户
1.基本语法
su 用户名称 (功能描述:切换用户,只能获得用户的执行权限,不能获得环境变量)
su - 用户名称 (功能描述:切换到用户并获得该用户的环境变量及执行权限)
2.案例实操
(1)切换用户
[root@hadoop101 ~]#su tangseng
[root@hadoop101 ~]#echo $PATH
/usr/lib64/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
[root@hadoop101 ~]#exit
[root@hadoop101 ~]#su - tangseng
[root@hadoop101 ~]#echo $PATH
/usr/lib64/qt-3.3/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/tangseng/bin
userdel 删除用户
1.基本语法
(1)userdel 用户名 (功能描述:删除用户但保存用户主目录)
(2)userdel -r 用户名 (功能描述:用户和用户主目录,都删除)
2.选项说明
表1-23
| 选项 | 功能 |
|---|---|
| -r | 删除用户的同时,删除与用户相关的所有文件。 |
3.案例实操
(1)删除用户但保存用户主目录
[root@hadoop101 ~]#userdel tangseng
[root@hadoop101 ~]#ll /home/
(2)删除用户和用户主目录,都删除
[root@hadoop101 ~]#useradd zhubajie
[root@hadoop101 ~]#ll /home/
[root@hadoop101 ~]#userdel -r zhubajie
[root@hadoop101 ~]#ll /home/
who 查看登录用户信息
1.基本语法
(1)whoami (功能描述:显示自身用户名称)
(2)who am i (功能描述:显示登录用户的用户名)
2.案例实操
(1)显示自身用户名称
[root@hadoop101 opt]# whoami
(2)显示登录用户的用户名
[root@hadoop101 opt]# who am i
sudo 设置普通用户具有root权限
1.添加atguigu用户,并对其设置密码。
[root@hadoop101 ~]#useradd atguigu
[root@hadoop101 ~]#passwd atguigu
2.修改配置文件
[root@hadoop101 ~]#vi /etc/sudoers
修改 /etc/sudoers 文件,找到下面一行(91行),在root下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
atguigu ALL=(ALL) ALL
或者配置成采用sudo命令时,不需要输入密码
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
atguigu ALL=(ALL) NOPASSWD:ALL
修改完毕,现在可以用atguigu帐号登录,然后用命令 sudo ,即可获得root权限进行操作。
3.案例实操
(1)用普通用户在/opt目录下创建一个文件夹
[atguigu@hadoop101 opt]$ sudo mkdir module
[root@hadoop101 opt]# chown atguigu:atguigu module/
usermod 修改用户
1.基本语法
usermod -g 用户组 用户名
2.选项说明
表1-24
| 选项 | 功能 |
|---|---|
| -g | 修改用户的初始登录组,给定的组必须存在 |
3.案例实操
(1)将用户加入到用户组
[root@hadoop101 opt]#usermod -g root zhubajie
groupadd 新增组
1.基本语法
groupadd 组名
2.案例实操
(1)添加一个xitianqujing组
[root@hadoop101 opt]#groupadd xitianqujing
groupdel 删除组
1.基本语法
groupdel 组名
2.案例实操
(1)删除xitianqujing组
[root@hadoop101 opt]# groupdel xitianqujing
groupmod 修改组
1.基本语法
groupmod -n 新组名 老组名
2.选项说明
表1-25
| 选项 | 功能描述 |
|---|---|
| -n<新组名> | 指定工作组的新组名 |
3.案例实操
(1)修改atguigu组名称为atguigu1
[root@hadoop101 ~]#groupadd xitianqujing
[root@hadoop101 ~]# groupmod -n xitian xitianqujing
cat /etc/group 查看创建了哪些组
1.基本操作
[root@hadoop101 atguigu]# cat /etc/group
第12章 文件权限管理
-
再说 ls -l

l 0-9位说明
第0位确定文件类型(d, - , l , c , b)
第1-3位确定所有者(该文件的所有者)拥有该文件的权限。—User
第4-6位确定所属组(同用户组的)拥有该文件的权限,—Group
第7-9位确定其他用户拥有该文件的权限 —Other
l 作用到文件
[ r ]代表可读(read): 可以读取,查看
[ w ]代表可写(write): 可以修改,但是不代表可以删除该文件,删除一个文件的前提条件 是对该文件所在的目录有写权限,才能删除该文件.
[ x ]代表可执行(execute):可以被系统执行
l 作用到目录
[ r ]代表可读(read): 可以读取,ls查看目录内容
[ w ]代表可写(write): 可以修改,目录内创建+删除+重命名目录
[ x ]代表可执行(execute):可以进入该目录
-
chmod
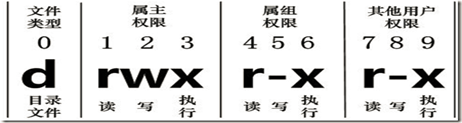
l 第一种方式:+ 、-、= 变更权限
u:所有者 g:所有组 o:其他人
a:所有人(u、g、o的总和)
chmod u=rwx,g=rx,o=x 文件目录名
chmod o+w 文件目录名
chmod a-x 文件目录名
l 第二种方式:通过数字变更权限
r=4 w=2 x=1 rwx=4+2+1=7
chmod u=rwx,g=rx,o=x 文件目录名
相当于 chmod 751 文件目录名
-
chown
chown newowner file 改变文件的所有者
chown newowner:newgroup file 改变用户的所有者和所有组
-R 如果是目录 则使其下所有子文件或目录递归生效
-
chgrp
chgrp newgroup file 改变文件的所有组
第13章 rpm与yum
rpm
-
RPM(RedHat Package Manager),Rethat软件包管理工具,类似windows里面的setup.exe
是Linux这系列操作系统里面的打包安装工具,它虽然是RedHat的标志,但理念是通
用的。
-
查询已安装的rpm列表 rpm –qa|grep xx -
rpm包的名称:firefox-52.5.0-1.el7.centos.x86_64
名称:firefox
版本号:52.6.0-1
适用操作系统: el7.centos.x86_64
表示centos7.x的64位系统。
-
安装rpm
rpm –ivh rpm的包名
-i 安装 install
-v 查看信息
-h 查看进度条
-
卸载rpm
rpm -e RPM软件包
yum
YUM(全称为 Yellow dog Updater, Modified)是一个在Fedora和RedHat以及CentOS中的Shell前端软件包管理器。基于RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包,无须繁琐地一次次下载、安装,如图1-163所示
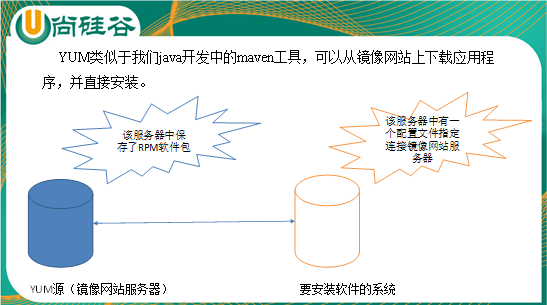
图1-163 YUM概述
1.基本语法
yum [选项] [参数]
2.选项说明
表1-52
| 选项 | 功能 |
|---|---|
| -y | 对所有提问都回答“yes” |
3.参数说明
表1-53
| 参数 | 功能 |
|---|---|
| install | 安装rpm软件包 |
| update | 更新rpm软件包 |
| check-update | 检查是否有可用的更新rpm软件包 |
| remove | 删除指定的rpm软件包 |
| list | 显示软件包信息 |
| clean | 清理yum过期的缓存 |
| deplist | 显示yum软件包的所有依赖关系 |
4.案例实操实操
(1)采用yum方式安装firefox
[root@hadoop101 ~]#yum -y install firefox.x86_64
修改网络YUM源
默认的系统YUM源,需要连接国外apache网站,网速比较慢,可以修改关联的网络YUM源为国内镜像的网站,比如网易163。
1.前期文件准备
(1)前提条件linux系统必须可以联网
(2)在Linux环境中访问该网络地址:http://mirrors.163.com/.help/centos.html,在使用说明中点击CentOS6->再点击保存,如图1-164所示
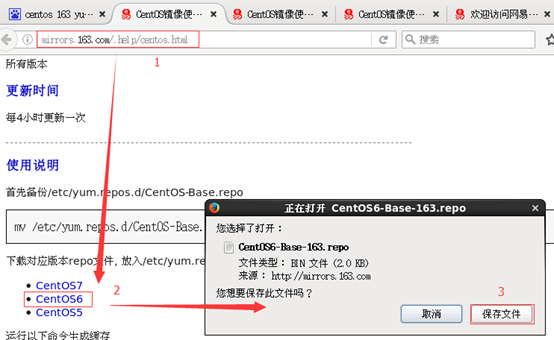
图1-164 下载CentOS6
(3)查看文件保存的位置,如图1-165,1-166所示
图1-165 图1-166
在打开的终端中输入如下命令,就可以找到文件的保存位置。
[atguigu@hadoop101 下载]$ pwd
/home/atguigu/下载
2.替换本地yum文件
(1)把下载的文件移动到/etc/yum.repos.d/目录
[root@hadoop101 下载]# mv CentOS6-Base-163.repo /etc/yum.repos.d/
(2)进入到/etc/yum.repos.d/目录
[root@hadoop101 yum.repos.d]# pwd
/etc/yum.repos.d
(3)用CentOS6-Base-163.repo替换CentOS-Base.repo
[root@hadoop101 yum.repos.d]# mv CentOS6-Base-163.repo CentOS-Base.repo
3.安装命令
(1)[root@hadoop101 yum.repos.d]#yum clean all
(2)[root@hadoop101 yum.repos.d]#yum makecache
yum makecache就是把服务器的包信息下载到本地电脑缓存起来
4.测试
[root@hadoop101 yum.repos.d]#yum list | grep firefox
[root@hadoop101 ~]#yum -y install firefox.x86_64
第14章 搭建开发环境
首先通过xftp5复制文件到虚拟机opt目录上面
14.1 安装JDK
-
将JDK解压缩到opt目录下 -
配置环境变量 , vim /etc/profile
JAVA_HOME=/opt/jdk1.8.0_152
PATH=/opt/jdk1.8.0_152/bin:$PATH
export JAVA_HOME PATH
-
配置完成后执行如下操作
安装完成注销重新登录一下
source /etc/profile
重启系统[最靠谱]
(注意如果javac没有效果是因为虚拟机只安装了jre没有安装)
yum install java-devel 安装原生的就行了
14.2 安装Tomcat
-
解压缩到/opt
注意环境变量一定要配置正确,否则无法启动
-
进入到Tomcat目录下的bin目录中,启动tomcat ./startup.sh
14.3 安装MySql
14.3.1 检查工作(卸载mariadb和检查tmp文件夹权限)
l CentOS6
rpm -qa|grep -i mysql
如果存在mysql-libs的旧版本包如下:

请先执行卸载命令:rpm -e –nodeps mysql-libs
l CentOS7
rpm -qa|grep -i mariadb
如果存在如下:

请先执行卸载命令:rpm -e –nodeps mariadb-libs (nodeps 把关联的文件全部去掉)
l 检查/tmp文件夹权限
执行 :chmod -R 777 /tmp (-R代表目录下全部文件都生效)
14.3.2 安装MySQL
l 拷贝安装包到opt目录下
MySQL-client-5.5.54-1.linux2.6.x86_64.rpm
MySQL-server-5.5.54-1.linux2.6.x86_64.rpm
l 执行如下命令进行安装
rpm -ivh MySQL-client-5.5.54-1.linux2.6.x86_64.rpm
rpm -ivh MySQL-server-5.5.54-1.linux2.6.x86_64.rpm
-
检查安装是否成功
l 安装完成后查看MySQL的版本
执行 mysqladmin –-version,如果打印出消息,即为成功

或者通过rpm查询
rpm –qa|grep –i mysql(-i 表示忽略大小写)
-
MySQL服务的启停
启动: service mysql start
停止: service mysql stop
-
设置root用户的密码
mysqladmin -u root password ‘123123’
-
登录MySQL
mysql -uroot -p123123
-
建库
create database 库名
-
建表
create table 表名 (字段名 字段类型(长度)约束 …)
7)字符集问题
查看字符集 show variables like ‘character%’;
查看MySQL的安装位置
修改字符集
将/usr/share/mysql/中的my-huge.cnf拷贝到/etc/下,改名为my.cnf()
mv my-huge.cnf /etc/
mv my-huge.cnf my.cnf
tips:mysql启动时,会优先读取/etc/my.cnf文件
vim my.cof
在[client] [musqld] [mysql]中添加相关的字符集设置
[client]
default-character-set=utf8
[mysqld]
character_set_server=utf8
character_set_client=utf8
collation-server=utf8_general_ci
[mysql]
default-character-set=utf8
重启MySQL服务,查看字符集
查看某个数据库的编码
show create database mydb;
service mysql restart
修改库的字符集
alter database 库名 character set ‘utf8’
修改表的字符集
alter table 表名 convert to character set ‘utf8’;
(注意:原先写的数据库无法在进行修改)
- 远程访问
l MySQL默认的root用户只允许本机登录,远程通过SQLyog工具不能登录.
l 查看MySQL mysql库中的用户表
列显示: select * from user\G;
查询常用字段: select host,user,password,select_priv from mysql.user;
l 创建可以远程访问的root用户并授予所有权限
grant all privileges on * . * to root@’%’ identified by ‘123123‘;
然后使用这个刷新
flush privileges
l 修改用户的密码
修改当前用户的密码
set password =password(‘123456’)
修改某个用户的密码
update mysql.user set password=password(‘123456’) where user=‘li4’;
l 注意: 所有通过user表的修改,必须使用flush privileges 命令才能生效.
第15章 修改主机名称
5.3.1 hostname 显示和设置系统的主机名称
\1. 基本语法
hostname (功能描述:查看当前服务器的主机名称)
\2. 案例实操
(1)查看当前服务器主机名称
[root@hadoop100 桌面]# hostname
5.3.2 修改主机名称
\1. 修改linux的主机映射文件(hosts文件)
(1)进入Linux系统查看本机的主机名。通过hostname命令查看
[root@hadoop100 桌面]# hostname
hadoop100
(2)如果感觉此主机名不合适,我们可以进行修改。通过编辑/etc/hostname文件
[root@hadoop100 桌面]# vim /etc/hostname
文件中内容
localhost.localdomain
(3)打开此文件后,可以看到主机名。修改此主机名为我们想要修改的主机名hadoop100。
(4)保存退出。
(5)打开/etc/hosts
[root@hadoop100 桌面]# vim /etc/hosts
添加如下内容
192.168.241.100 hadoop100 192.168.241.101 hadoop101 192.168.241.102 hadoop102 192.168.241.103 hadoop103 192.168.241.104 hadoop104 192.168.241.105 hadoop105 192.168.241.106 hadoop106 192.168.241.107 hadoop107 192.168.241.108 hadoop108
(6)并重启设备,重启后,查看主机名,已经修改成功
\2. 修改window7的主机映射文件(hosts文件)
(1)进入C:\Windows\System32\drivers\etc路径
(2)打开hosts文件并添加如下内容
192.168.241.100 hadoop100 192.168.241.101 hadoop101 192.168.241.102 hadoop102 192.168.241.103 hadoop103 192.168.241.104 hadoop104 192.168.241.105 hadoop105 192.168.241.106 hadoop106 192.168.241.107 hadoop107 192.168.241.108 hadoop108
\3. 修改window10的主机映射文件(hosts文件)
(1)进入C:\Windows\System32\drivers\etc路径
(2)拷贝hosts文件到桌面
(3)打开桌面hosts文件并添加如下内容
(注意你的主机名是什么就是什么)
192.168.241.100 hadoop100 192.168.241.101 hadoop101 192.168.241.102 hadoop102 192.168.241.103 hadoop103 192.168.241.104 hadoop104 192.168.241.105 hadoop105 192.168.241.106 hadoop106 192.168.241.107 hadoop107 192.168.241.108 hadoop108
(4)将桌面hosts文件覆盖C:\Windows\System32\drivers\etc路径hosts文件
测试:(相当于添加了Hadoop和192.168.241.100的映射关系,相当于localhost 就是 127.0.0.1)
第16章 crond系统定时任务
16.1 croud服务管理
重新启动crond服务
[root@hadoop101 ~]# service crond restart
16.2 crontab定时任务设置
1.基本语法
crontab [选项]
2.选项说明
| 选项 | 功能 |
|---|---|
| -e | 编辑crontab定时任务 |
| -l | 查询crontab任务 |
| -r | 删除当前用户所有的crontab任务 |
3.参数说明
[root@hadoop101 ~]# crontab -e
(1)进入crontab编辑界面。会打开vim编辑你的工作。
* * * * * 执行的任务
表1-47
| 项目 | 含义 | 范围 |
|---|---|---|
| 第一个“*” | 一小时当中的第几分钟 | 0-59 |
| 第二个“*” | 一天当中的第几小时 | 0-23 |
| 第三个“*” | 一个月当中的第几天 | 1-31 |
| 第四个“*” | 一年当中的第几月 | 1-12 |
| 第五个“*” | 一周当中的星期几 | 0-7(0和7都代表星期日) |
(2)特殊符号
表1-48
| 特殊符号 | 含义 |
|---|---|
| * | 代表任何时间。比如第一个“*”就代表一小时中每分钟都执行一次的意思。 |
| , | 代表不连续的时间。比如“0 8,12,16 * * * 命令”,就代表在每天的8点0分,12点0分,16点0分都执行一次命令 |
| - | 代表连续的时间范围。比如“0 5 * * 1-6命令”,代表在周一到周六的凌晨5点0分执行命令 |
| */n | 代表每隔多久执行一次。比如“*/10 * * * * 命令”,代表每隔10分钟就执行一遍命令 |
(3)特定时间执行命令
表1-49
| 时间 | 含义 |
|---|---|
| 45 22 * * * 命令 | 在22点45分执行命令 |
| 0 17 * * 1 命令 | 每周1 的17点0分执行命令 |
| 0 5 1,15 * * 命令 | 每月1号和15号的凌晨5点0分执行命令 |
| 40 4 * * 1-5 命令 | 每周一到周五的凌晨4点40分执行命令 |
| */10 4 * * * 命令 | 每天的凌晨4点,每隔10分钟执行一次命令 |
| 0 0 1,15 * 1 命令 | 每月1号和15号,每周1的0点0分都会执行命令。注意:星期几和几号最好不要同时出现,因为他们定义的都是天。非常容易让管理员混乱。 |
4.案例实操
(1)每隔1分钟,向/root/bailongma.txt文件中添加一个11的数字
*/1 * * * * /bin/echo ”11” » /root/bailongma.txt
shell命令
Shell是一个命令行解释器,它接受应用程序/用户命令,然后调用操作系统内核
Shell还是一个功能相当强大的编程语言,易编写,易调试,灵活性强.
Linux提供的Shell解析器有:
[atguigu@hadoop101 ~]$ cat /etc/shells
/bin/sh
/bin/bash
/sbin/nologin
/bin/dash
/bin/tcsh
/bin/csh
- bash和sh的关系
[atguigu@hadoop101 bin]$ ll | grep bash
-rwxr-xr-x. 1 root root 941880 5月 11 2016 bash
lrwxrwxrwx. 1 root root 4 5月 27 2017 sh -> bash
3)Centos默认的解析器是bash
[atguigu@hadoop102 bin]$ echo $SHELL
/bin/bash
1 Shell 脚本入门
1.1 脚本格式
脚本以#!/bin/bash开头(指定解析器)
1.2 第一个Shell脚本:helloworld
(1)需求: 创建一个Shell脚本,输出helloworld
(2)案例实操:
[atguigu@hadoop101 datas]$ touch helloworld.sh
[atguigu@hadoop101 datas]$ vi helloworld.sh
在helloworld.sh中输入如下内容
#!/bin/bash
echo "helloworld"
(3)脚本的常用执行方式
第一种:采用bash或sh+脚本的相对路径或绝对路径(不用赋予脚本+权限)
sh+脚本的相对路径
[atguigu@hadoop101 datas]$ sh helloworld.sh
Helloworld
sh+脚本的绝对路径
[atguigu@hadoop101 datas]$ sh /home/atguigu/datas/helloworld.sh
helloworld
bash+脚本的相对路径
[atguigu@hadoop101 datas]$ bash helloworld.sh
Helloworld
bash+脚本的绝对路径
[atguigu@hadoop101 datas]$ bash /home/atguigu/datas/helloworld.sh
Helloworld
第二种,采用输入脚本的绝对路径或相对路径执行脚本(必须具有可执行权限+x)
(a)首先要赋予helloworld.sh脚本的+x权限
[atguigu@hadoop101 datas]$ chmod +x helloworld.sh
(b)执行脚本
相对路径
[atguigu@hadoop101 datas]$ ./helloworld.sh
Helloworld
绝对路径
[atguigu@hadoop101 datas]$ /home/atguigu/datas/helloworld.sh
Helloworld
注意:第一种执行方法,本质是bash解析器帮你执行脚本,所有脚本本身不需要执行权限,第二种执行方法,本质是脚本需要自己执行,所以需要执行权限
2 变量
2.1 系统预定义变量
常用预定义变量
$HOME,$PWD,$SHELL,$USER等
案例实操:
(1)查看系统变量的值
[atguigu@hadoop101 datas]$ echo $HOME
/home/atguigu
(2)显示当前Shell中所有变量:set
[atguigu@hadoop101 datas]$ set // ($相当于#)
BASH=/bin/bash
BASH_ALIASES=()
BASH_ARGC=()
BASH_ARGV=()
2.2 自定义变量
1**)基本语法**
(1)定义变量:变量=值
(2)撤销变量:unset 变量
(3)声明静态变量:readonly变量,注意:不能unset
2**)变量定义规则**
(1)变量名称可以由字母、数字和下划线组成,但是不能以数字开头,环境变量名建议大写。
(2)等号两侧不能有空格
(3)在bash中,变量默认类型都是字符串类型,无法直接进行数值运算。
(4)变量的值如果有空格,需要使用双引号或单引号括起来。
3**)案例实操**
(1)定义变量A
[atguigu@hadoop101 datas]$ A=5
[atguigu@hadoop101 datas]$ echo $A
5
(2)给变量A重新赋值
[atguigu@hadoop101 datas]$ A=8
[atguigu@hadoop101 datas]$ echo $A
8
(3)撤销变量A
[atguigu@hadoop101 datas]$ unset A
[atguigu@hadoop101 datas]$ echo $A
(4)声明静态的变量B=2,不能unset
[atguigu@hadoop101 datas]$ readonly B=2
[atguigu@hadoop101 datas]$ echo $B
2
[atguigu@hadoop101 datas]$ B=9
-bash: B: readonly variable
(5)在bash中,变量默认类型都是字符串类型,无法直接进行数值运算
[atguigu@hadoop102 ~]$ C=1+2
[atguigu@hadoop102 ~]$ echo $C
1+2
(6)变量的值如果有空格,需要使用双引号或单引号括起来
[atguigu@hadoop102 ~]$ D=I love banzhang
-bash: world: command not found
[atguigu@hadoop102 ~]$ D="I love banzhang"
[atguigu@hadoop102 ~]$ echo $D
I love banzhang
(7)可把变量提升为全局环境变量,可供其他Shell程序使用
export 变量名
[atguigu@hadoop101 datas]$ vim helloworld.sh
在helloworld.sh文件中增加echo $B
#!/bin/bash
echo "helloworld"
echo $B
[atguigu@hadoop101 datas]$ ./helloworld.sh
Helloworld
发现并没有打印输出变量B的值。
[atguigu@hadoop101 datas]$ export B
[atguigu@hadoop101 datas]$ ./helloworld.sh
helloworld
2
export B 就可以使用了
2.3 特殊变量
1**)基本语法**
$n (功能描述:n为数字,$0代表该脚本名称,$1-$9代表第一到第九个参数,十以上的参数,十以上的参数需要用大括号包含,如${10})
2**)案例实操**
[atguigu@hadoop101 datas]$ touch parameter.sh
[atguigu@hadoop101 datas]$ vim parameter.sh
\#!/bin/bash
echo "$0 $1 $2"
[atguigu@hadoop101 datas]$ chmod 777 parameter.sh
[atguigu@hadoop101 datas]$ ./parameter.sh cls xz
./parameter.sh cls xz
3.3.2 $#
1**)基本语法**
$# (功能描述:获取所有输入参数个数,常用于循环)。
2**)案例实操**
[atguigu@hadoop101 datas]$ vim parameter.sh
#!/bin/bash
echo "$0 $1 $2"
echo $#
[atguigu@hadoop101 datas]$ chmod 777 parameter.sh
[atguigu@hadoop101 datas]$ ./parameter.sh cls xz
parameter.sh cls xz
2
3.3.3 $*、$@
1**)基本语法**
$* (功能描述:这个变量代表命令行中所有的参数,$*把所有的参数看成一个整体)
$@ (功能描述:这个变量也代表命令行中所有的参数,不过$@把每个参数区分对待)
2**)案例实操**
[atguigu@hadoop101 datas]$ vim parameter.sh
\#!/bin/bash
echo "$0 $1 $2"
echo $#
echo $*
echo $@
[atguigu@hadoop101 datas]$ bash parameter.sh 1 2 3
parameter.sh 1 2
3
1 2 3
1 2 3
3.3.4 $?
1**)基本语法**
$? (功能描述:最后一次执行的命令的返回状态。如果这个变量的值为0,证明上一个命令正确执行;如果这个变量的值为非0(具体是哪个数,由命令自己来决定),则证明上一个命令执行不正确了。)
2**)案例实操**
判断helloworld.sh脚本是否正确执行
[atguigu@hadoop101 datas]$ ./helloworld.sh
hello world
[atguigu@hadoop101 datas]$ echo $?
0
3 运算符
1**)基本语法**
“$((运算式))”或“$[运算式]”
expr +,-,\*,/,% 加 减 乘 除 取余
2**)案例实操:**
计算(2+3)X4的值
[atguigu@hadoop101 datas]# S=$[(2+3)*4]
[atguigu@hadoop101 datas]# echo $S
或者
[root@hadoop101 datas]# expr `expr 2 + 3` \* 4
20
计算(2+3)的值
[root@hadoop101 datas]# expr 2 + 3
5
4 条件判断
1)基本语法
(1)test condition
(2)[condition] (注意condition前后要有空格)
注意:条件非空即为true,【atguigu]返回true,【】返回false
2)常用判断条件
(1)两个整数之间比较
== 字符串比较
-lt 小于(less than)
-le 小于等于(less equal)
-eq 等于(equal)
-gt 大于(greater than)
-ge 大于等于(greater equal)
-ne 不等于(Not equal)
(2)按照文件权限进行判断
-r 有读的权限(read)
-w 有写的权限(write)
-x 有执行的权限(execute)
(3)按照文件类型进行判断
-f 文件存在并且是一个常规的文件(file)
-e 文件存在(existence)
-d 文件存在并是一个目录(directory)
3)案例实操
(1)23是否大于等于22
[root@hadoop101 ~]# [ 23 -ge 22 ] && echo "江豪迪最帅"
江豪迪最帅
(2)helloworld.sh是否具有写的权限
[root@hadoop101 datas]# [ -x helloworld.sh ] && echo "有执行权限"
有执行权限
(3) 判断helloworld.sh是否存在
[root@hadoop101 datas]# [ -e helloworld.sh ] && echo "文件存在"
文件存在
4)多条件判断(&& 表示前一条命令执行成功时,才执行后一条命令,|| 表示上一条命令执行失败后,才执行下一条命令)
[root@hadoop101 datas]# [ -d helloworld.sh ] || echo "不是目录"
不是目录
5 流程控制(重点)
5.1 if判断
if [ 条件判断式 ];then
程序
fi
或者
if [ 条件判断式 ]
then
程序
elif [ 条件判断式 ]
then
程序
else
程序
fi
注意事项:
(1)[ 条件判断式 ],中括号和条件判断式之间必须有空格
(2)if后要有空格
案例实操:
输入一个数,如果是1就输出输入的数字是1,如果输入的数字是2,就输入输入的数字是2,如果输入的数字是别的,就输出,输入的个数不是1也不是2
#!/bin/bash
if [ $1 -eq 1 ]
then
echo "输入的数是1"
elif [ $1 -eq 2 ]
then
echo "输入的数是2"
else
echo "输入的数不是1也不是2"
fi
5.2 case语句
基本语法
case $变量名 in
“值1”)
如果变量的值等于值1,则执行程序1
;;
“值2”)
如果变量的值等于值2,则执行程序2
;;
…省略其他分支…
*)
如果变量的值都不是以上的值,则执行此程序
;;
esac
注意事项:
(1)case行尾必须为单词“in”,每一个模式匹配必须以右括号“)”结束。
(2)双分号“;;”表示命令序列结束,相当于java中的break。
(3)最后的“*)”表示默认模式,相当于java中的default。
案例实操
#!/bin/bash
case $1 in
1)
echo "小迪迪最帅"
;;
2)
echo "小迪迪天下第一帅"
;;
*)
echo "小迪迪变成一个土豪"
esac
5.3 for循环
for (( 初始值;循环控制条件;变量变化 )) do 程序 done
案例实操
(1)从1加到100
#!/bin/bash
s=0
for ((i=0;i<=100;i++))
do
s=$[$s+$i]
done
echo $s
(2)比较$*和$@区别
$*和$@都表示传递给函数或脚本的所有参数,不被双引号“”包含时,都以$1 $2 …$n的形式输出所有参数
当它们被双引号“”包含时,“$*”会将所有的参数作为一个整体,以“$1 $2 …$n”的形式输出所有参数;“$@”会将各个参数分开,以“$1” “$2”…”$n”的形式输出所有参数。
#!/bin/bash
for i in $*
do
echo $i
done
for i in $@
do
echo $i
done
for i in "$*"
do
echo $i
done
for i in "$@"
do
echo $i
done
输出结果
[root@hadoop101 datas]# bash test3.sh 1 2 3 4 5
1
2
3
4
5
1
2
3
4
5
1 2 3 4 5
1
2
3
4
5
5.4 while循环
基本语法
while [ 条件判断式 ]
do
程序
done
案例实操 从1加到100
#!/bin/bash
a=0
b=1
while [ $b -le 100 ]
do
a=$[$a+$b]
b=$[$b+1]
done
echo $a
6 read读取控制台输入
基本语法
read(选项)(参数)
选项:
-p:指定读取值时的提示符
-t:指定读取值时等待的时间(秒)
参数:
变量:指定读取值的变量名
案例实操
提示7秒内,读取控制台输入的名称
#!/bin/bash
read -t 5 -p "请输入你的用户名" name
echo $name
7 函数
7.1 系统函数
basename
基本语法
basename[string/pathname] [suffix](功能描述:basename命令会删掉所有的前缀包括最后一个(‘/’)字符,然后将字符串显示出来。
选项;
suffix为后缀,如果suffix被指定了,basename会将pathname或string中的suffix去掉。
案例实操
截取/datas/helloworld.sh路径的文件名称(suffix被指定的情况)
[root@hadoop101 datas]# basename /datas/helloworld.sh .sh
helloworld
截取/datas/helloworld.sh路径的文件名称(suffix未被指定的情况)
[root@hadoop101 datas]# basename /datas/helloworld.sh
helloworld.sh
dirname
基本语法 dirname 文件绝对路径 (功能描述:从给定的包含绝对路径的文件名中去除文件名(非目录的部分),然后返回剩下的路径(目录的部分))
案例实操
[root@hadoop101 datas]# dirname /datas/helloworld.sh
/datas
7.2 自定义函数
基本语法
[function]funname[()]
{
Action;
[return int;]
}
funname
经验技巧
(1)必须在调用函数地方之前,先声明函数,shell脚本是逐行运行。不会像其它语言一样先编译。
(2)函数返回值,只能通过$?系统变量获得,可以显示加:return返回,如果不加,将以最后一条命令运行结果,作为返回值。return后跟数值n(0-255)
案例实操
计算两个输入参数的和
#!/bin/bash
function sum(){
sum=0
for i in $*
do
sum=$[$sum+$i]
done
echo $sum
}
read -p "请输入你要进行求和的值" num1
read -p "请输入你要进行求和的值" num2
sum $num1 $num2
8 Shell 工具
8.1 cut
cut的工作就是“剪”,具体的说就是在文件中负责剪切数据用的。cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段输出。
基本用法
cut[选项参数] filename
说明:默认分隔符是制表符
选项参数说明
| 选项参数 | 功能 |
|---|---|
| -f | 列号,提取第几列 |
| -d | 分隔符,按照指定分隔符分割列 |
| -c | 指定具体的字符 |
案例实操
(1)数据准备
[root@hadoop101 datas]# touch test.txt
[root@hadoop101 datas]# head -n 5 /etc/passwd > test.txt
[root@hadoop101 datas]# cat test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
[root@hadoop101 datas]# cut -c 1
(2)切割当前数据源的第一个字符
[root@hadoop101 datas]# cut -c 1 test.txt
r
b
d
a
l
(3)以:切割后获取第一列的内容
[root@hadoop101 datas]# cut -d : -f 1 test.txt
root
bin
daemon
adm
lp
(4)以:切割后获取第二三列的内容
[root@hadoop101 datas]# cut -d : -f 1,3 test.txt
root:0
bin:1
daemon:2
adm:3
lp:4
(5)选取系统PATH变量值,第2个“:”开始后的所有路径:
[atguigu@hadoop101 datas]$ echo $PATH
/usr/lib64/qt-3.3/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/atguigu/bin
[atguigu@hadoop102 datas]$ echo $PATH | cut -d: -f 2-
/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/atguigu/bin
(6)获取带有root字符串的第一个root字符
[root@hadoop101 datas]# cat test.txt | grep root
root:x:0:0:root:/root:/bin/bash
[root@hadoop101 datas]# cat test.txt | grep root | cut -d : -f 1
root
8.2 sed(了解)
sed是一种流编辑器,它一次处理一行内容,处理时,把当前处理的行存储在临时缓存区中,称为“模式空间”,接着用sed命令处理缓冲区的内容,处理完成后,把缓冲区的内容送往屏幕,接着处理下一行,这样不断重复,直到文件末尾,文件内容并没有改变,除非你是用重定向存储输出
基本语法
2**)选项参数说明**
| 选项参数 | 功能 |
|---|---|
| -e | 直接在指令列模式上进行sed的动作编辑。 |
| -i | 直接编辑文件 |
3**)命令功能描述**
| 命令 | 功能描述 |
|---|---|
| a | 新增,a的后面可以接字串,在下一行出现 |
| d | 删除 |
| s | 查找并替换 |
4 案例实操
(1)数据准备
[root@hadoop101 datas]# cat test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
(2)将"mei nv"这个单词插入到test.txt第二行下,打印(源文件并没有改变 )
[root@hadoop101 datas]# sed '2a mei nv' test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
mei nv
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
(3)删除test.txt文件所有包含root的行(用的正则表达式)
[root@hadoop101 datas]# sed '/root/d' test.txt
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
(4)将test.txt文件中的第一个root替换成小迪迪最帅
[root@hadoop101 datas]# sed 's/root/小迪迪最帅/' test.txt
小迪迪最帅:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
(5)将test.txt文件中的全部root替换成小迪迪最帅
[root@hadoop101 datas]# sed 's/root/小迪迪最帅/g' test.txt
小迪迪最帅:x:0:0:小迪迪最帅:/小迪迪最帅:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
(6)将sed.txt文件中的第二行删除并将root替换成小迪迪最帅
[root@hadoop101 datas]# sed -e '2d' -e 's/root/小迪迪最帅/g' test.txt
小迪迪最帅:x:0:0:小迪迪最帅:/小迪迪最帅:/bin/bash
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
8.3 awk
一个强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理
1**)基本用法**
awk [选项参数] ‘pattern1{action1} pattern2{action2}…’ filename
pattern:表示AWK在数据中查找的内容,就是匹配模式
action:在找到匹配内容时所执行的一系列命令
2**)选项参数说明**
| 选项参数 | 功能 |
|---|---|
| -F | 指定输入文件折分隔符 |
| -v | 赋值一个用户定义变量 |
8.3 awk
一个强大的文本分析工具,把文件逐行读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理
1**)基本用法**
awk [选项参数] ‘pattern1{action1} pattern2{action2}…’ filename
pattern:表示AWK在数据中查找的内容,就是匹配模式
action:在找到匹配内容时所执行的一系列命令
2**)选项参数说明**
| 选项参数 | 功能 |
|---|---|
| -F | 指定输入文件折分隔符 |
| -v | 赋值一个用户定义变量 |
案例实操
(1)数据准备
[root@hadoop101 datas]# cat test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
(2)搜索passwd文件以root关键字开头的所有行,并输出该行的第7列
[root@hadoop101 datas]# awk -F : '/^root/{print $7}' test.txt
/bin/bash
(3)搜索passwd文件以root关键字开头的所有行,并输出该行的第1列和第7列,中间以“,”号分割。
[root@hadoop101 datas]# awk -F : '/^root/{print $1","$7}' test.txt
root,/bin/bash
(4)只显示/etc/passwd的第一列和第七列,以逗号分割,且在所有行前面添加列名user,shell在最后一行添加"dahaige,/bin/zuishuai"。
[root@hadoop101 datas]# awk -F : 'BEGIN{print "user,shell"}{print $1","$7}END{print "dahaige,/bin/zuishua"}' test.txt
user,shell
root,/bin/bash
bin,/sbin/nologin
daemon,/sbin/nologin
adm,/sbin/nologin
lp,/sbin/nologin
dahaige,/bin/zuishua
注意:BEGIN 在所有数据读取行之前执行;END 在所有数据执行之后执行。
(5)将passwd文件中的用户id增加数值1并输出
[root@hadoop101 datas]# awk -v i=1 -F : '{print $3+i}' test.txt
1
2
3
4
5
[root@hadoop101 datas]# cat test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
4**)awk****的内置变量**
| 变量 | 说明 |
|---|---|
| FILENAME | 文件名 |
| NR | 已读的记录数 |
| NF | 浏览记录的域的个数(切割后,列的个数) |
案例实操
(1)统计passwd文件名,每行的行号,每行的列数
[root@hadoop101 datas]# awk -F : '{print "文件名是" FILENAME "每行的行号是" NR "列的个数是" NF}' test.txt
文件名是test.txt每行的行号是1列的个数是7
文件名是test.txt每行的行号是2列的个数是7
文件名是test.txt每行的行号是3列的个数是7
文件名是test.txt每行的行号是4列的个数是7
文件名是test.txt每行的行号是5列的个数是7
(2)切割ip
[root@hadoop101 datas]# ifconfig ens33 | grep "inet" | sed '2d'| awk -F " " '{print $2}'
192.168.241.101
(3)查询sed.txt中空行所在的行号
[atguigu@hadoop102 datas]$ awk '/^$/{print NR}' sed.txt
5
8.4 sort
sort 命令是在Linux里非常有用,它将文件进行排序,并将排序结果标准输出
1**)基本语法**
sort(选项)(参数)
| 选项 | 说明 |
|---|---|
| -n | 依照数值的大小排序 |
| -r | 以相反的顺序来排序 |
| -t | 设置排序时所用的分隔字符 |
| -k | 指定需要排序的列 |
参数:指定待排序的文件列表
案例实操:
按照“:” 分割后的第1列倒序排序
[root@hadoop101 datas]# sort -t : -nrk 1 test.txt
root:x:0:0:root:/root:/bin/bash
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
乐观锁与悲观锁
悲观锁 以为世界上都是坏人 把每一个都加锁 适用于写的比较多的情况
乐观锁 以为世界上都是好人 不加锁,但是用者版本号来进行验证,如果得到锁后有人修改了数据,那么锁的版本号就会发生变化,那么就无法进行修改。适用于写的情况比较少的情况
git
0 总结
上传一个项目的完整步骤
1 新创建一个仓库
2 如果第一次下载创建全局config名字
git config --global user.name "xiaodidi"
git config --global user.email "7860282+xiaodidi66666@user.noreply.gitee.com"
3 创建一个新目录
4 执行 git init
4 把需要的文件放到这个目录里面
5 注意把添加的文件中有.git的去掉不然无法添加
6 执行git add *
7 执行git commit -m “注释”
8 添加远程仓库
git remote add origin https://gitee.com/xiaodidi66666/all-items.git
git push -u origin master
上传一个新项目完整步骤
git config --global user.name "xiaodidi"
git config --global user.email "7860282+xiaodidi66666@user.noreply.gitee.com"
配置用户信息
创建一个新目录
把需要的文件放到这个目录里面
拉取一个项目完整步骤
从项目中拉一个新项目,然后创建新的
1 git的安装
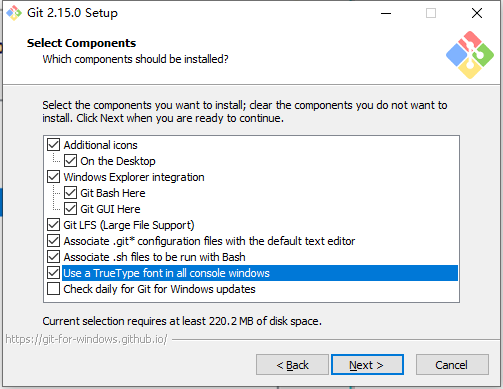
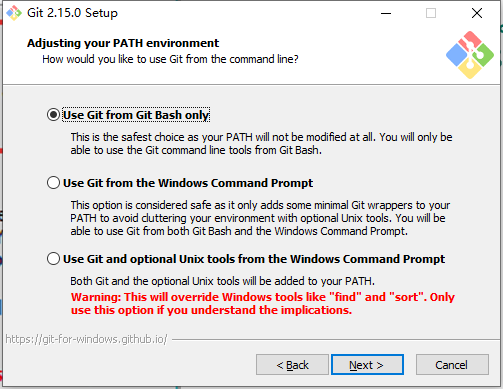
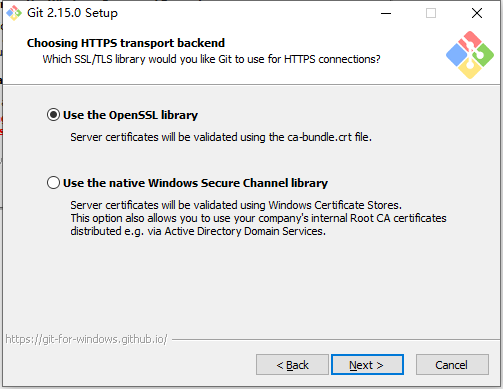
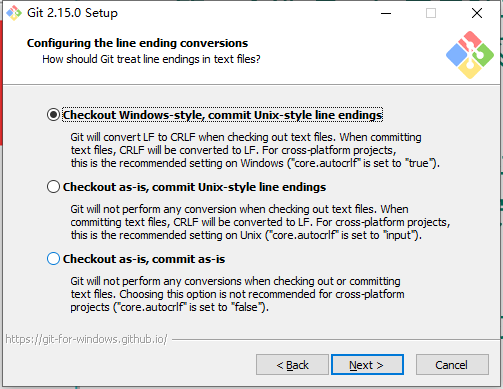
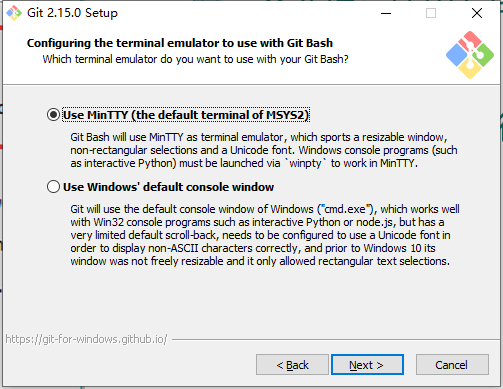
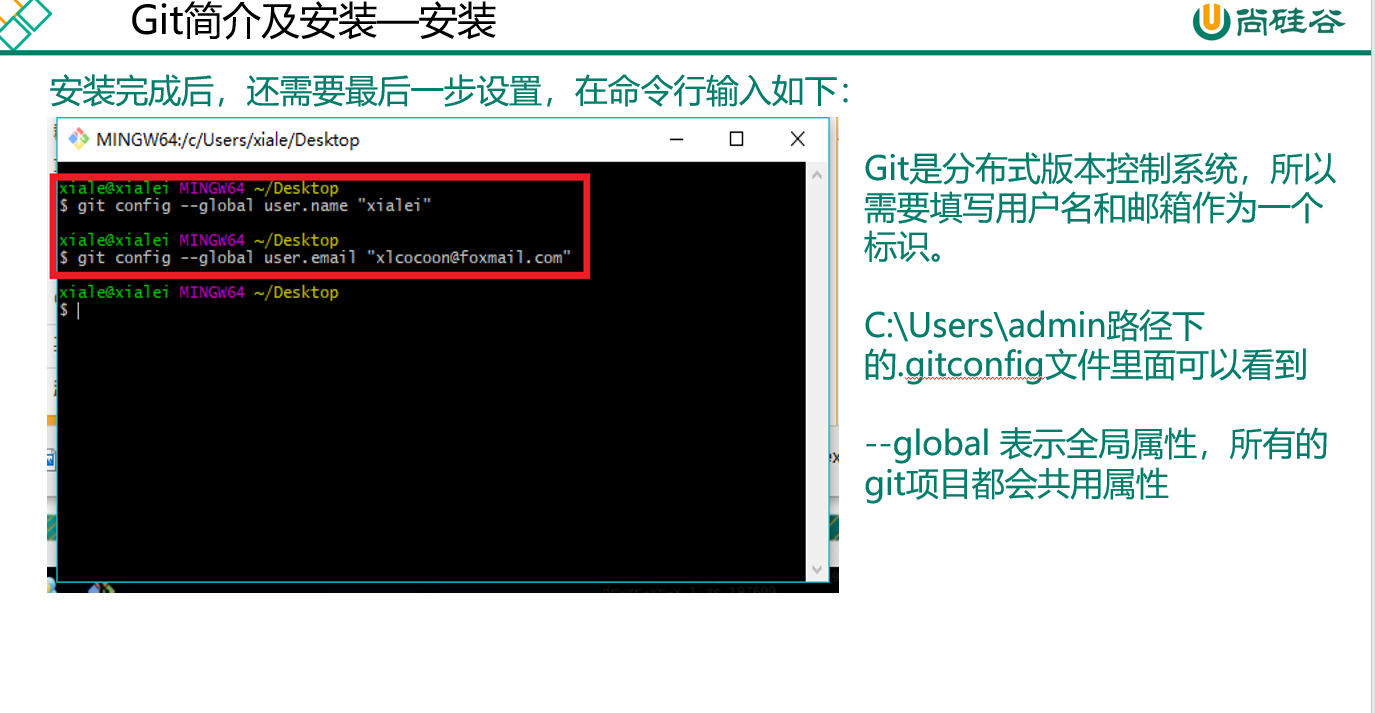
2 git的使用
1.创建版本库:在你的项目文件夹下面,执行:git init
2.提交文件
1 新建文件后,通过git status进行查看文件状态
2 将文件添加到缓存区 git add 文件名
3 提交文件 git commit 文件名
4 添加注释
或者3,4可以连接在一起
git commit -m “注释内容”
3.查看文件
执行git log 文件名 查看历史记录
git log –pretty=oneline 文件名 简易信息查看
4.回退历史
git reset –hard HEAD^ 回退到上一次提交
git reset –hard HEAD~n 回退n次操作
5 版本穿越
进行查看历史记录的版本号,执行git reflog 文件名
执行 git reset –hard 版本号
6 还原文件(保存但是没有add,没有commit之前)
git checkout – 文件名
7 删除某个文件
rm -rvf 文件 然后 git add 文件
git commit -m “注释”
可以通过版本穿越进行还原文件
3 git 工作区+暂存区+本地库图解
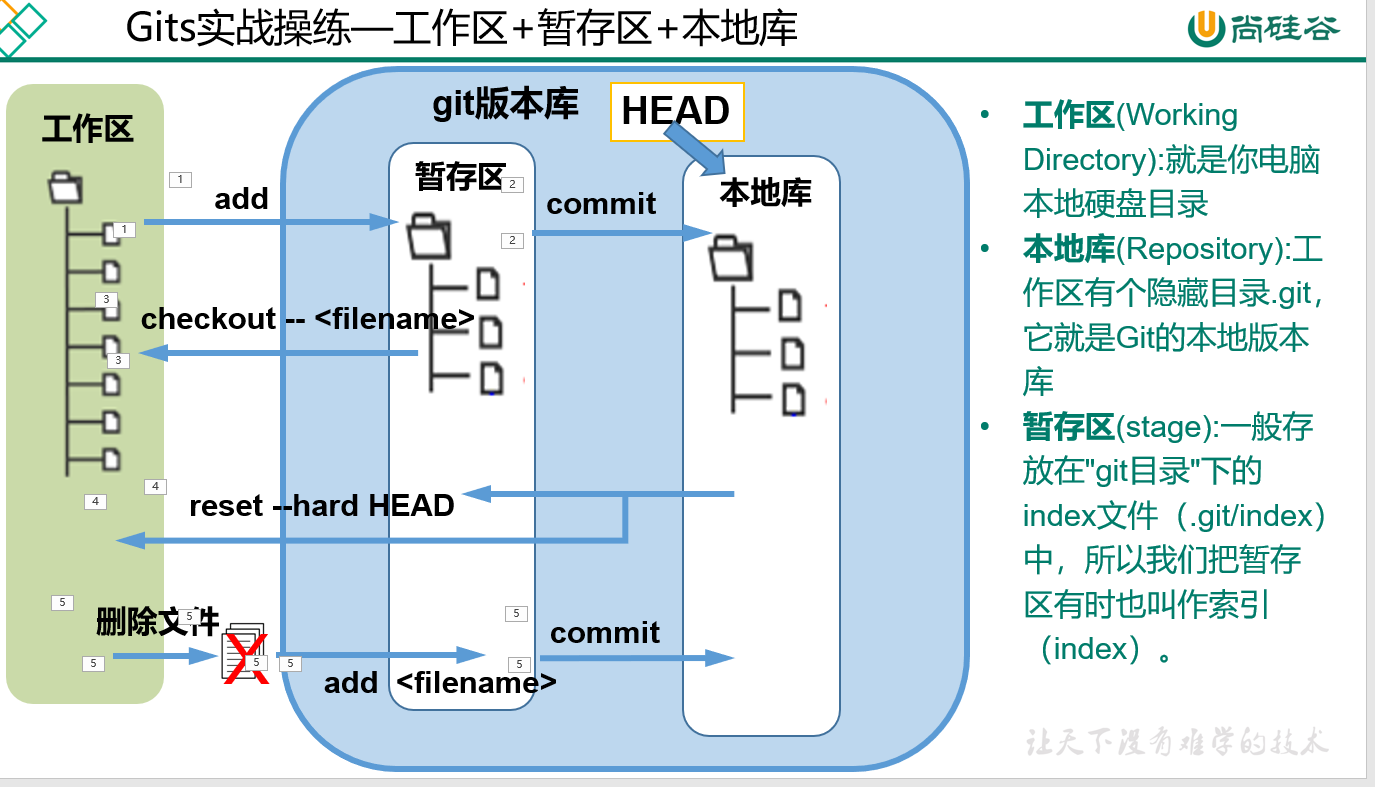
4 git 分支
创建分支
git branch <分支名>
切换分支
git checkout <分支名>
一步完成: git checkout -b <分支名>
合并分支
先切换到主干 git checkout master
git merge <分支名>
删除分支
先切换到主干 git checkout master
git branch -D <分支名>
冲突
冲突一般指同一个文件同一位置的代码,在两种版本合并时版本管理软件无法判断到底应该保留哪个版本,因此会提示该文件发生冲突,需要程序员来手工判断解决冲突。
合并时冲突
•程序合并时发生冲突系统会提示CONFLICT关键字,命令行后缀会进入MERGING状态,表示此时是解决冲突的状态。
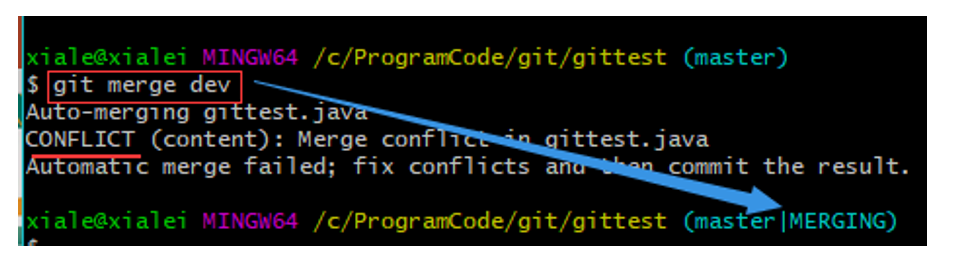
5 github的使用
5.1 登入github并创建一个repository
5.2 github思维导图
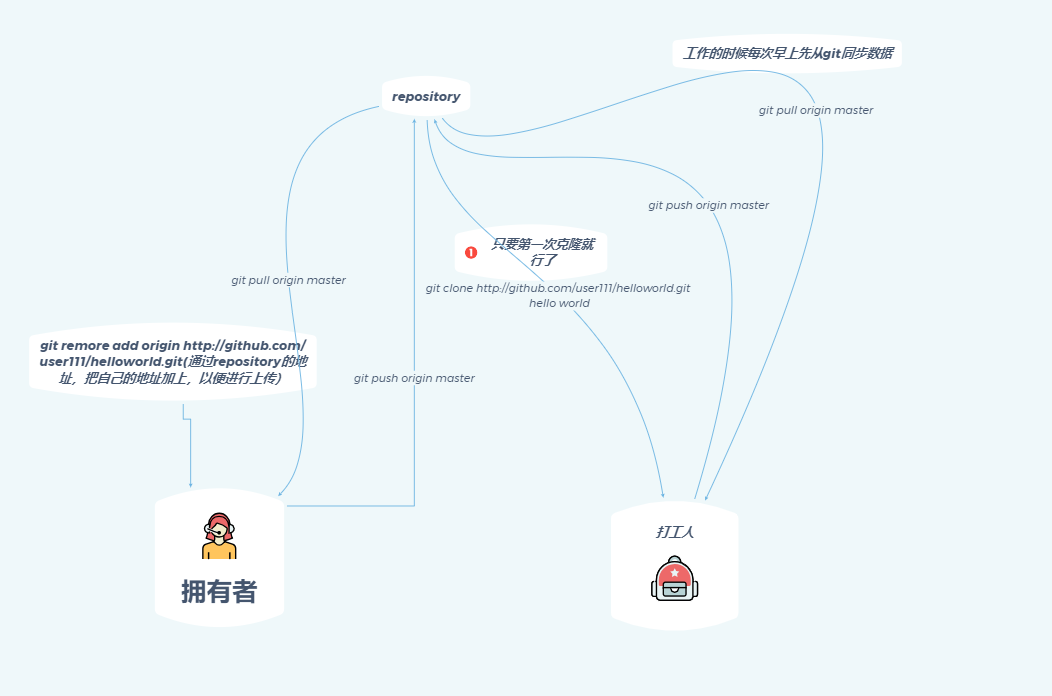
5.3 主要步骤
拥有者:
搭建代码库:
1.git init
2.git config
提交代码
1.git add xxx
2.git commit


除创建者对项目要进行上传的化,首先要先得到权限,需要获得创造者的认可,创建者通过发送邮件来邀请进行上传
5.4 协作冲突
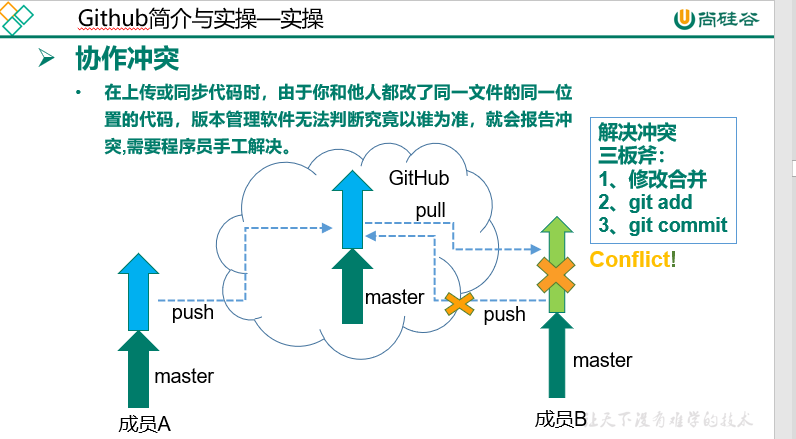
5.5 让不别人帮忙完成请求
5.5.1 在别的账号上面点击fork命令
5.5.2 点击new pull request
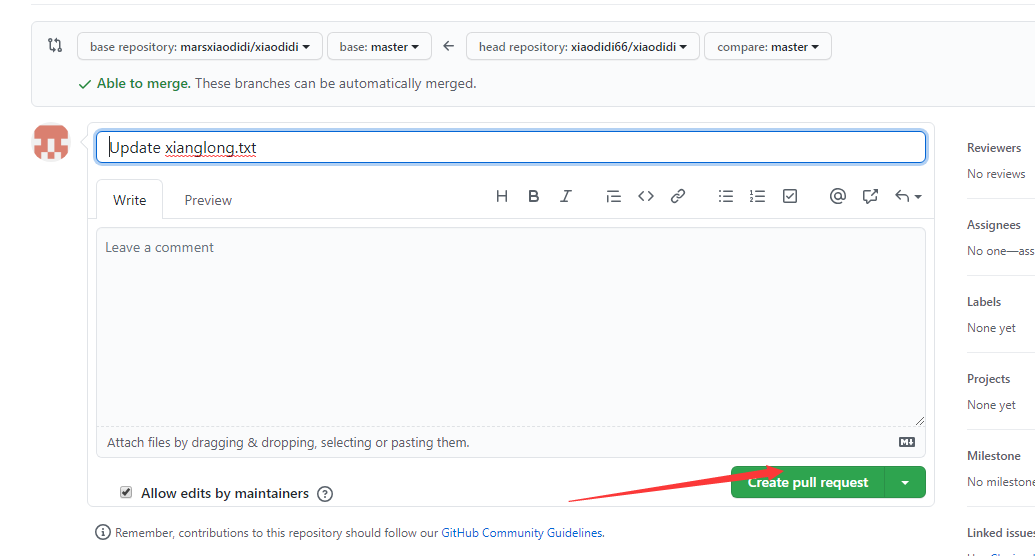
5.5.3 让文件可以修改者pull requests请求
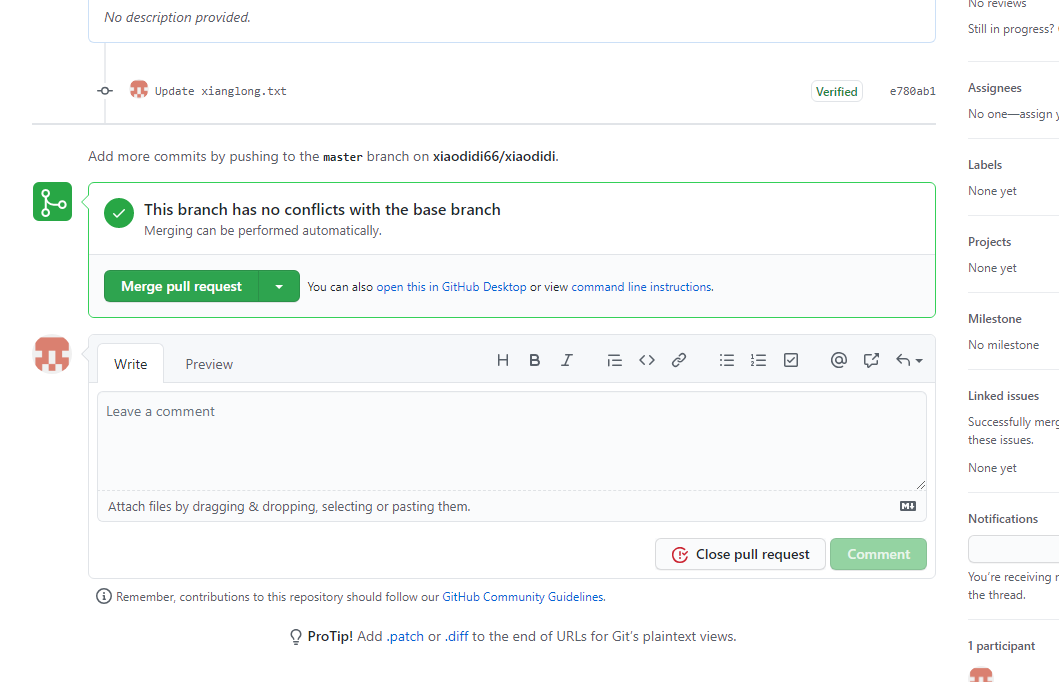
6 ssh的配置
6.1 建立公钥和私钥
cd ~
cd .ssh (看一下有没有这个文件,如果存在这个文件就删除)
ssh-keygen -t rsa -C 1018576890@qq.com
cd .ssh
然后把公钥给复制出来
6.2 复制公钥到github
6.3 复制ssh地址
6.4 加入originssh
git remote add originssh git@github.com:marsxiaodidi/xiaodidi.git
6.5 git push originssh master
6.6 多免密配置
6.6.1 编写config
Host one.github.com #这个要不同
User xiaodidi #和用户名对应
HostName github.com
PreferredAuthentications publickey
IdentityFile ~/.ssh/id_rsa #代表你建立的私密
Host two.github.com
User xiaodidi66
HostName github.com
PreferredAuthentications publickey
IdentityFile ~/.ssh/mine3_rsa
$ ssh-keygen -t rsa -f ~/.ssh/mine3_rsa -C "1455824027@qq.com"
-f 指定私密文件名
7 idea git和github的配置
7.1 git的配置
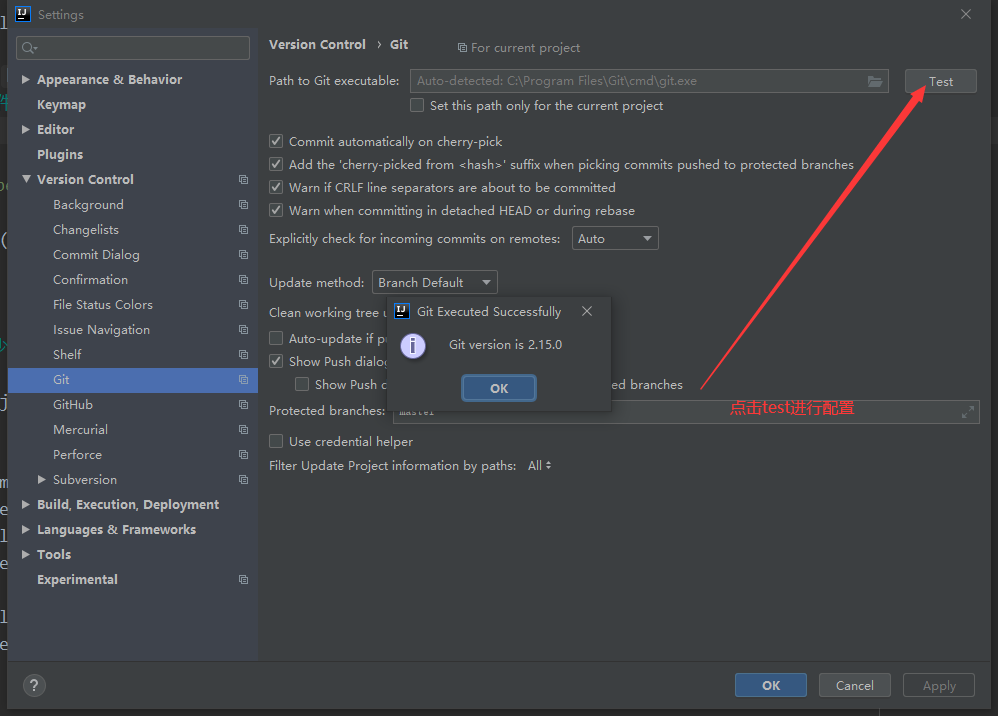
7.2 github的配置
然后在github中获取token
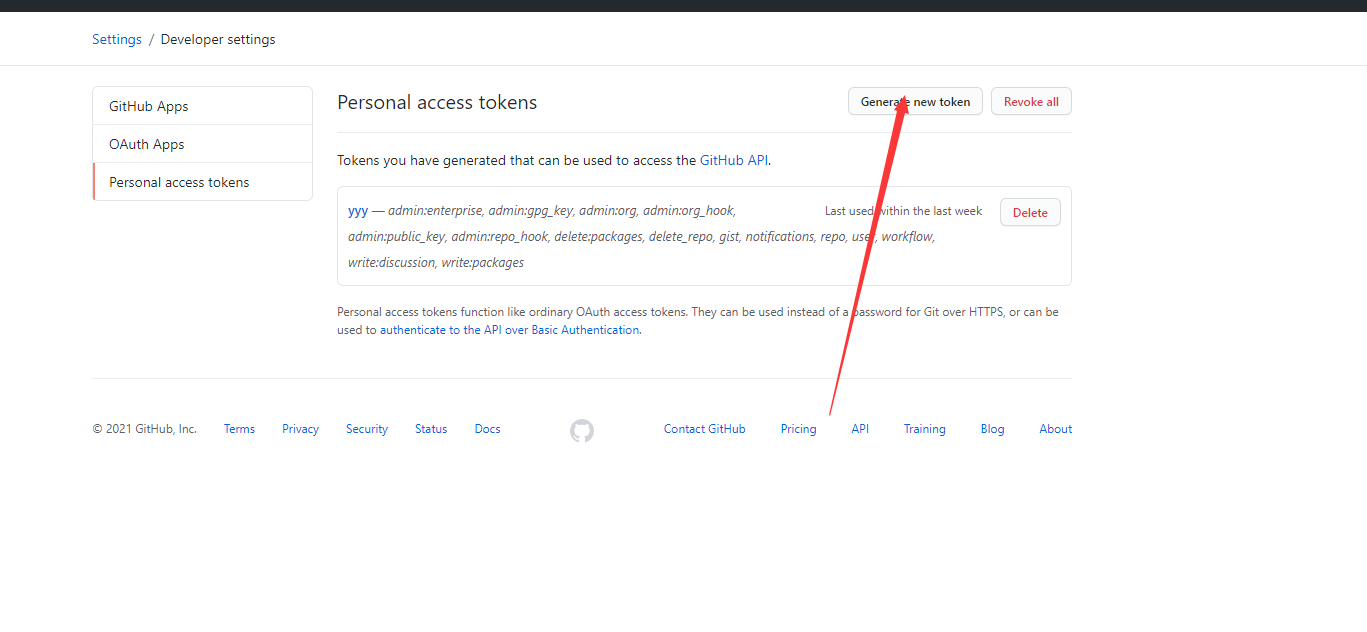
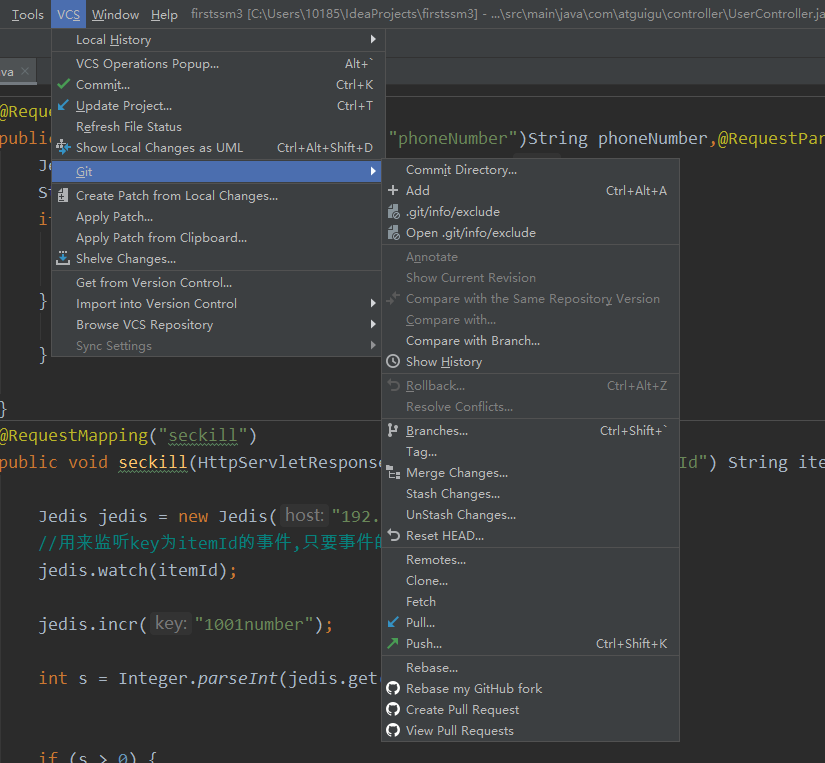
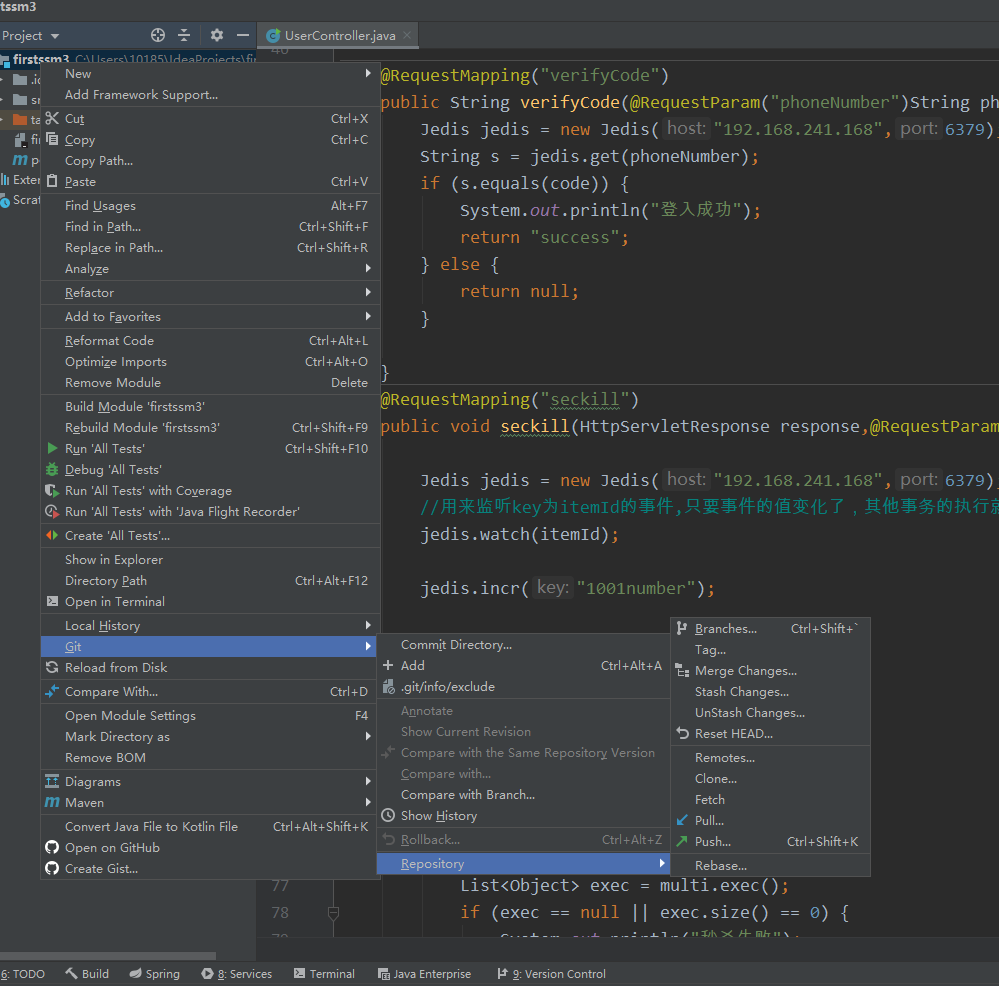
activeMQ
0 课程的大纲
1. 入门概述
1.1 MQ的产品种类和对比
MQ就是消息中间件。MQ是一种理念,ActiveMQ是MQ的落地产品。不管是哪款消息中间件,都有如下一些技术维度:
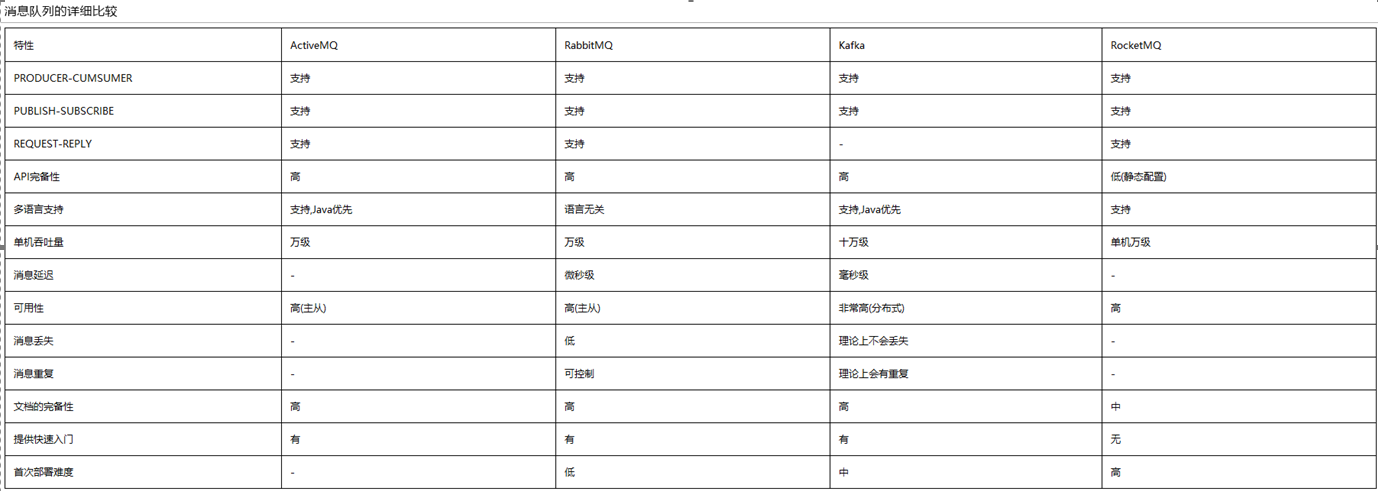
(1) kafka
编程语言:scala。
大数据领域的主流MQ。
(2) rabbitmq
编程语言:erlang
基于erlang语言,不好修改底层,不要查找问题的原因,不建议选用。
(3) rocketmq
编程语言:java
适用于大型项目。适用于集群。
(4) activemq
编程语言:java
适用于中小型项目。
1.2 MQ的产生背景
系统之间直接调用存在的问题?
微服务架构后,链式调用是我们在写程序时候的一般流程,为了完成一个整体功能会将其拆分成多个函数(或子模块),比如模块A调用模块B,模块B调用模块C,模块C调用模块D。但在大型分布式应用中,系统间的RPC交互繁杂,一个功能背后要调用上百个接口并非不可能,从单机架构过渡到分布式微服务架构的通例。这些架构会有哪些问题?
(1) 系统之间接口耦合比较严重
每新增一个下游功能,都要对上游的相关接口进行改造;
举个例子:如果系统A要发送数据给系统B和系统C,发送给每个系统的数据可能有差异,因此系统A对要发送给每个系统的数据进行了组装,然后逐一发送;
当代码上线后又新增了一个需求:把数据也发送给D,新上了一个D系统也要接受A系统的数据,此时就需要修改A系统,让他感知到D系统的存在,同时把数据处理好再给D。在这个过程你会看到,每接入一个下游系统,都要对系统A进行代码改造,开发联调的效率很低。其整体架构如下图:
(1) 面对大流量并发时,容易被冲垮
每个接口模块的吞吐能力是有限的,这个上限能力如果是堤坝,当大流量(洪水)来临时,容易被冲垮。
举个例子秒杀业务:上游系统发起下单购买操作,就是下单一个操作,很快就完成。然而,下游系统要完成秒杀业务后面的所有逻辑(读取订单,库存检查,库存冻结,余额检查,余额冻结,订单生产,余额扣减,库存减少,生成流水,余额解冻,库存解冻)。
(2) 等待同步存在性能问题
RPC接口上基本都是同步调用,整体的服务性能遵循“木桶理论”,即整体系统的耗时取决于链路中最慢的那个接口。比如A调用B/C/D都是50ms,但此时B又调用了B1,花费2000ms,那么直接就拖累了整个服务性能。
根据上述的几个问题,在设计系统时可以明确要达到的目标:
1,要做到系统解耦,当新的模块接进来时,可以做到代码改动最小;能够解耦
2,设置流量缓冲池,可以让后端系统按照自身吞吐能力进行消费,不被冲垮;能削峰
3,强弱依赖梳理能将非关键调用链路的操作异步化并提升整体系统的吞吐能力;能够异步
1.3 MQ的主要作用
(1) 异步。调用者无需等待。
(2) 解耦。解决了系统之间耦合调用的问题。
(3) 消峰。抵御洪峰流量,保护了主业务。
1.4 MQ的定义
面向消息的中间件(message-oriented middleware)MOM能够很好的解决以上问题。是指利用高效可靠的消息传递机制与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息排队模型在分布式环境下提供应用解耦,弹性伸缩,冗余存储、流量削峰,异步通信,数据同步等功能。
大致的过程是这样的:发送者把消息发送给消息服务器,消息服务器将消息存放在若干队列/主题topic中,在合适的时候,消息服务器回将消息转发给接受者。在这个过程中,发送和接收是异步的,也就是发送无需等待,而且发送者和接受者的生命周期也没有必然的关系;尤其在发布pub/订阅sub模式下,也可以完成一对多的通信,即让一个消息有多个接受者。
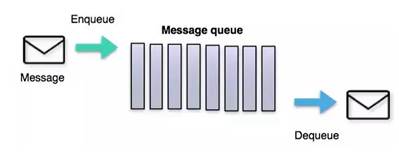
1.5 MQ的特点
(1)采用异步处理模式
消息发送者可以发送一个消息而无须等待响应。消息发送者将消息发送到一条虚拟的通道(主题或者队列)上;
消息接收者则订阅或者监听该爱通道。一条消息可能最终转发给一个或者多个消息接收者,这些消息接收者都无需对消息发送者做出同步回应。整个过程都是异步的。
案例:
也就是说,一个系统跟另一个系统之间进行通信的时候,假如系统A希望发送一个消息给系统B,让他去处理。但是系统A不关注系统B到底怎么处理或者有没有处理好,所以系统A把消息发送给MQ,然后就不管这条消息的“死活了”,接着系统B从MQ里面消费出来处理即可。至于怎么处理,是否处理完毕,什么时候处理,都是系统B的事儿,与系统A无关。
(1) 应用系统之间解耦合
发送者和接受者不必了解对方,只需要确认消息。
发送者和接受者不必同时在线。
(2) 整体架构
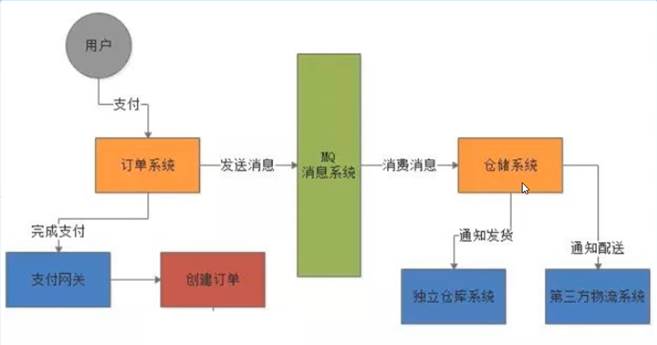
(1) MQ的缺点
两个系统之间不能同步调用,不能实时回复,不能响应某个调用的回复。
2 ActiveMQ安装和控制台
2 ActiveMQ安装和控制台
2.1 ActiveMQ安装
(1)官网下载
官网地址: http://activemq.apache.org/
2.2 安装步骤
2.3.1 安装java环境
2.3.2 通过文件传输,把文件传输到虚拟机
2.3.3 进入activemq的安装包./activemq start/stop 进行开启
2.3.4 启动时指定日志输出文件(重要)
activemq日志默认的位置是在:%activemq安装目录%/data/activemq.log
这是我们启动时指定日志输出文件:
[root@VM_0_14_centos raohao]# service activemq start > /opt/activemq.log
2.3.5 查看程序是否成功的三种方式
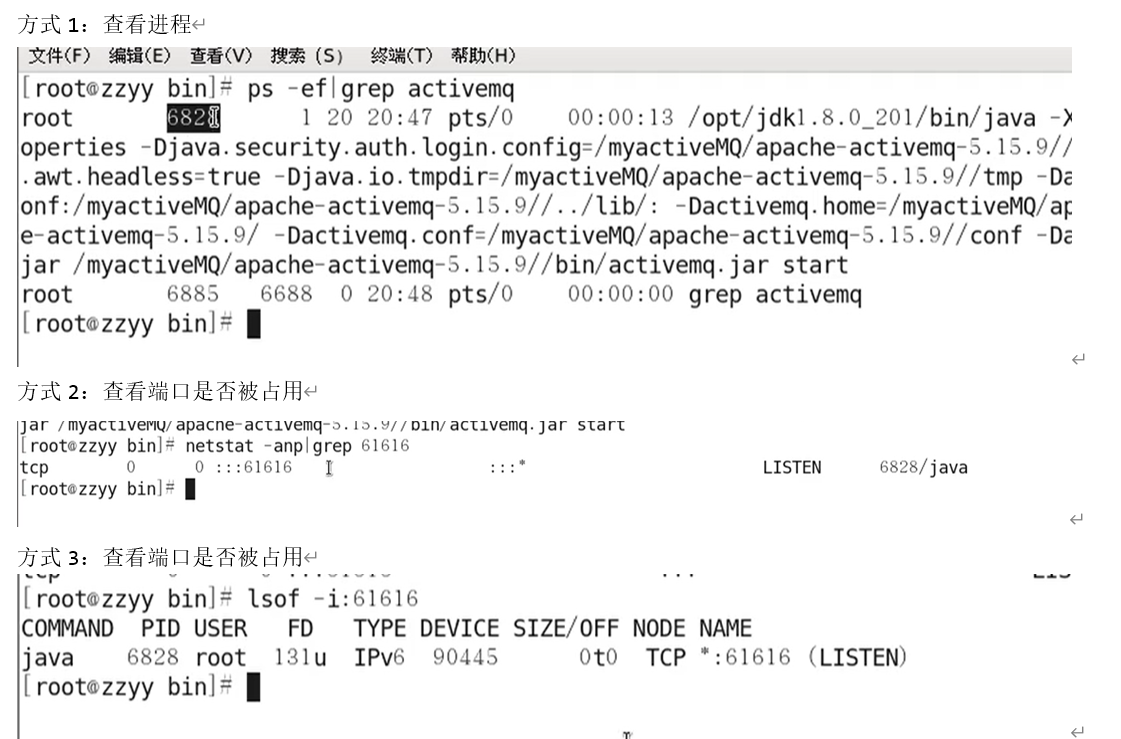
2.3 查看ActiveMQ控制台
http://192.168.241.168:8161 (账号admin 密码 admin)
3 入门案例
3.1 pom的导入
<dependencies>
<!-- activemq 所需要的jar 包-->
<dependency>
<groupId>org.apache.activemq</groupId>
<artifactId>activemq-all</artifactId>
<version>5.15.9</version>
</dependency>
<!-- activemq 和 spring 整合的基础包 -->
<dependency>
<groupId>org.apache.xbean</groupId>
<artifactId>xbean-spring</artifactId>
<version>3.16</version>
</dependency>
</dependencies>
public static void main(String[] args) throws JMSException {
//创建一个工厂//把连接的地址传进去
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(ACTIVEMQ_URL);
//建立一个连接
Connection connection = activeMQConnectionFactory.createConnection();
// 3 创建会话session 。第一参数是是否开启事务, 第二参数是消息签收的方式
Session session = connection.createSession(false,Session.AUTO_ACKNOWLEDGE);
//通过会话创建一个队列
Queue xiaodidi = session.createQueue("xiaodidi");
//通过队列创建一个生产者
MessageProducer producer = session.createProducer(xiaodidi);
//通过会话建立一个消息
TextMessage textMessage = session.createTextMessage("我是一个小天才");
//生产者进行发送消息
producer.send(textMessage);
//关闭连接
connection.close();
producer.close();
session.close();
System.out.println("发送成功");
}
rabbitmq环境搭建
1 安装erlang环境
全点击下一步
环境变量path中配置安装目录/bin
2 安装rabbltmq环境
全点击下一步
3 启动服务
C:\Program Files\RabbitMQ Server\rabbitmq_server-3.8.14\sbin\
cmd中输入下面命令
rabbitmq-plugins enable rabbitmq_management
然后点击
http://localhost:15672/#/
账号\密码
quest
nginx
0 Nginx注意点
nginx指定文件路径有两种方式root和alias,这两者的用法区别,使用方法总结了下,方便大家在应用过程中,快速响应。root与alias主要区别在于nginx如何解释location后面的uri,这会使两者分别以不同的方式将请求映射到服务器文件上。
[root] 语法:root path 默认值:root html 配置段:http、server、location、if
[alias] 语法:alias path 配置段:location
root实例:
location ^~ /t/ {
root /www/root/html/;
}
如果一个请求的URI是/t/a.html时,web服务器将会返回服务器上的/www/root/html/t/a.html的文件。 alias实例:
location ^~ /t/ {
alias /www/root/html/new_t/;
}
如果一个请求的URI是/t/a.html时,web服务器将会返回服务器上的/www/root/html/new_t/a.html的文件。注意这里是new_t,因为alias会把location后面配置的路径丢弃掉,把当前匹配到的目录指向到指定的目录。 注意:
- 使用alias时,目录名后面一定要加"/"。
- alias在使用正则匹配时,必须捕捉要匹配的内容并在指定的内容处使用。
- alias只能位于location块中。(root可以不放在location中)
内容介绍 1、nginx基本概念。
(1) nginx是什么,能做什么事情
(2) 反向代理。
(3) 负载均衡。
(4) 动静分离
2、nginx 安装、常用命令和配置文件
(1)在liunx系统中安装nginx.
(2) nginx常用命令。
(3) nginx 配置文件。
3、nginx 配置实例 1-反向代理
4、nginx 配置实例 2-负载均衡
5、nginx 配置实例 3-动静分离。
6、nginx配置高可用集群
7、nginx 原理。
1 Nginx 简介
1.1 什么是NGINX
Nginx ("engine x")是一个高性能的HTTP和反向代理服务器,特点是占有内存少,并发能
力强,事实上nginx的并发能力确实在同类型的网页服务器中表现较好
Nginx专为性能优化而开发,性能是其最重要的考量,实现上非常注重效率,能经受高负载
的考验,有报告表明能支持高达50000个并发连接数。
1.2 反向代理
a. 正向代理 在客户端(浏览器)配置代理服务器,通过代理服务器进行互联网访问
{% asset_img image-20200606144302429.png 正向代理 %}
b. 反向代理 反向代理,其实客户端对代理是无感知的,因为客户端不需要任何配置就可以访问,我们只 需要将请求发送到反向代理服务器,由反向代理服务器去选择目标服务器获取数据后,在返 回给客户端,此时反向代理服务器和目标服务器对外就是一个服务器,暴露的是代理服务器 地址,隐藏了真实服务器IP地址。
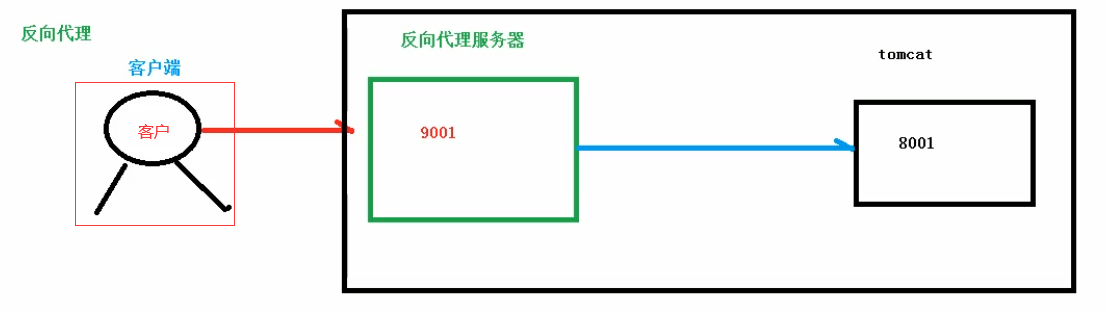
1.3 负载均衡
单个服务器解决不了,我们增加服务器的数量,然后将请求分发到各个服务器上,将原先 请求集中到单个服务器上的情况改为将请求分发到多个服务器上,将负载分发到不同的服 务器,也就是我们所说的负载均衡
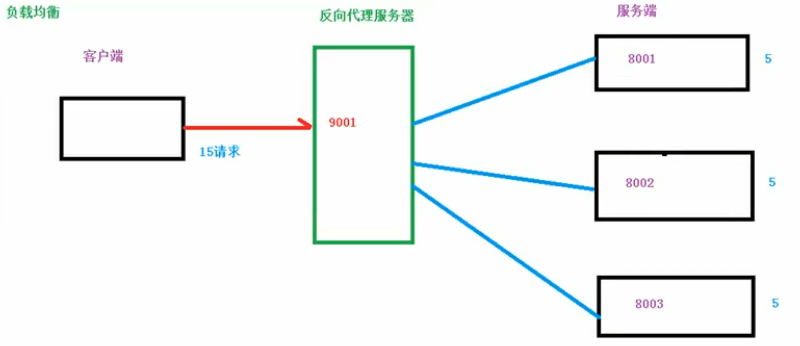
1.4 动静分离
为了加快网站的解析速度,可以把动态页面和静态页面由不同的服务器来解析,加快解析速 度。降低原来单个服务器的压力。
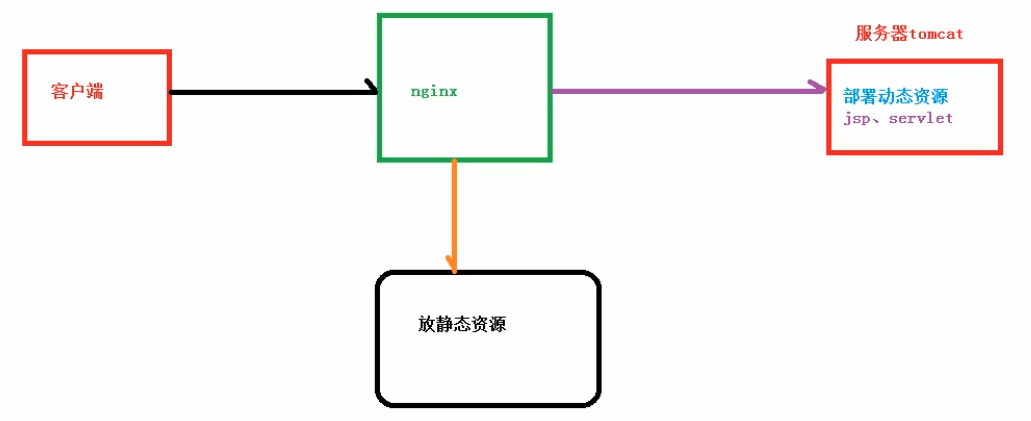
2 Nginx 安装
下面的操作是以Centos7为例
1. 使用远程连接工具连接Centos7操作系统 2. 安装nginx相关依赖
gcc
pcre
openssl
zlib
① 安装 nginx 需要先将官网下载的源码进行编译,编译依赖 gcc 环境,如果没有 gcc 环境,则需要安装:
$ yum install gcc-c++
② PCRE(Perl Compatible Regular Expressions) 是一个Perl库,包括 perl 兼容的正则表达式库。nginx 的 http 模块使用 pcre 来解析正则表达式,所以需要在 linux 上安装 pcre 库,pcre-devel 是使用 pcre 开发的一个二次开发库。nginx也需要此库。命令:
$ yum install -y pcre pcre-devel
③ zlib 库提供了很多种压缩和解压缩的方式, nginx 使用 zlib 对 http 包的内容进行 gzip ,所以需要在 Centos 上安装 zlib 库。
$ yum install -y zlib zlib-devel
④ OpenSSL 是一个强大的安全套接字层密码库,囊括主要的密码算法、常用的密钥和证书封装管理功能及 SSL 协议,并提供丰富的应用程序供测试或其它目的使用。 nginx 不仅支持 http 协议,还支持 https(即在ssl协议上传输http),所以需要在 Centos 安装 OpenSSL 库。
$ yum install -y openssl openssl-devel
3. 安装Nginx
① 下载nginx,两种方式
a. 直接下载
.tar.gz安装包,地址:https://nginx.org/en/download.htmlb. 使用
wget命令下载(推荐)。确保系统已经安装了wget,如果没有安装,执行 yum install wget 安装。
$ wget -c https://nginx.org/download/nginx-1.19.0.tar.gz
② 依然是直接命令:
$ tar -zxvf nginx-1.19.0.tar.gz
$ cd nginx-1.19.0
③ 配置:
其实在 nginx-1.12.0 版本中你就不需要去配置相关东西,默认就可以了。当然,如果你要自己配置目录也是可以的。 1.使用默认配置
$ ./configure
2.自定义配置(不推荐)
$ ./configure \
--prefix=/usr/local/nginx \
--conf-path=/usr/local/nginx/conf/nginx.conf \
--pid-path=/usr/local/nginx/conf/nginx.pid \
--lock-path=/var/lock/nginx.lock \
--error-log-path=/var/log/nginx/error.log \
--http-log-path=/var/log/nginx/access.log \
--with-http_gzip_static_module \
--http-client-body-temp-path=/var/temp/nginx/client \
--http-proxy-temp-path=/var/temp/nginx/proxy \
--http-fastcgi-temp-path=/var/temp/nginx/fastcgi \
--http-uwsgi-temp-path=/var/temp/nginx/uwsgi \
--http-scgi-temp-path=/var/temp/nginx/scgi
注:将临时文件目录指定为/var/temp/nginx,需要在/var下创建temp及nginx目录
④ 编辑安装
$ make && make install
查看版本号(使用nginx操作命令前提条件:必须进入nginx的目录/usr/local/nginx/sbin.)
$ ./nginx -v
查找安装路径:
$ whereis nginx
⑤ 启动,停止nginx
$ cd /usr/local/nginx/sbin/
$ ./nginx
$ ./nginx -s stop
$ ./nginx -s quit
$ ./nginx -s reload
查询nginx进程:
$ ps aux|grep nginx
3 Nginx.conf配置文件
3.1 位置
vim /usr/local/nginx/conf/nginx.conf
3.2 配置文件中的内容(包含三部分)
1、位置
vim /usr/local/nginx/conf/nginx.conf
2、配置文件中的内容(包含三部分)
(1)全局块:配置服务器整体运行的配置指令
从配置文件开始到 events 块之间的内容,主要会设置一些影响 nginx 服务器整体运行的配置指令,主要包括配
置运行 Nginx 服务器的用户(组)、允许生成的 worker process 数,进程 PID 存放路径、日志存放路径和类型以
及配置文件的引入等。
比如上面第一行配置的:
这是 Nginx 服务器并发处理服务的关键配置,worker_processes 值越大,可以支持的并发处理量也越多,但是
会受到硬件、软件等设备的制约

(2)events 块:影响 Nginx 服务器与用户的网络连接
events 块涉及的指令主要影响 Nginx 服务器与用户的网络连接,常用的设置包括是否开启对多 work process
下的网络连接进行序列化,是否允许同时接收多个网络连接,选取哪种事件驱动模型来处理连接请求,每个 word
process 可以同时支持的最大连接数等。
上述例子就表示每个 work process 支持的最大连接数为 1024.
这部分的配置对 Nginx 的性能影响较大,在实际中应该灵活配置。

(3)http 块
这算是 Nginx 服务器配置中最频繁的部分,代理、缓存和日志定义等绝大多数功能和第三方模块的配置都在这里。
需要注意的是:http 块也可以包括 http 全局块、server 块。
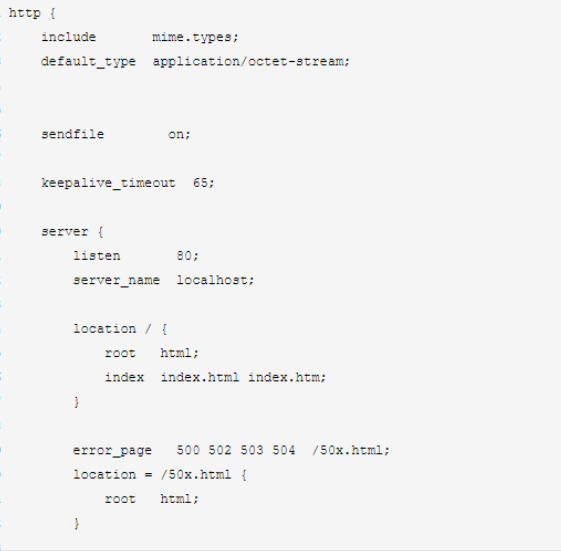
①、http 全局块
http 全局块配置的指令包括文件引入、MIME-TYPE 定义、日志自定义、连接超时时间、单链接请求数上限等。
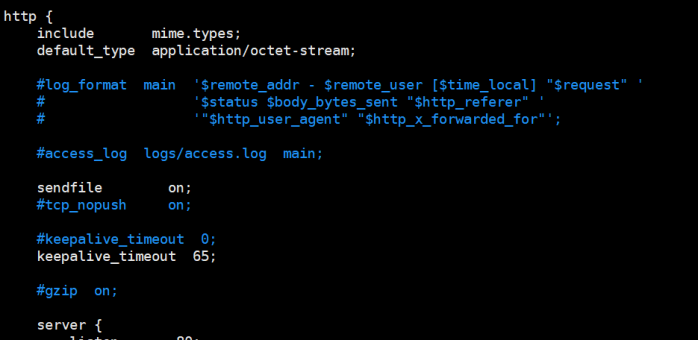
②、server 块
这块和虚拟主机有密切关系,虚拟主机从用户角度看,和一台独立的硬件主机是完全一样的,该技术的产生是为了
节省互联网服务器硬件成本。
每个 http 块可以包括多个 server 块,而每个 server 块就相当于一个虚拟主机。
而每个 server 块也分为全局 server 块,以及可以同时包含多个 locaton 块。
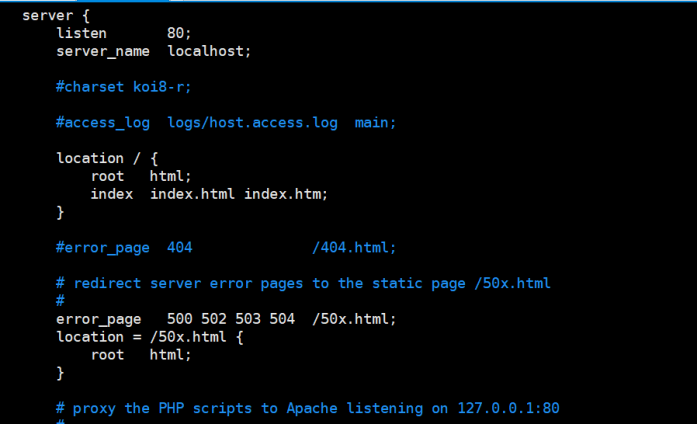
全局 server 块
最常见的配置是本虚拟机主机的监听配置和本虚拟主机的名称或 IP 配置。
location 块
一个 server 块可以配置多个 location 块。
这块的主要作用是基于 Nginx 服务器接收到的请求字符串(例如 server_name/uri-string),对虚拟主机名称
(也可以是 IP 别名)之外的字符串(例如 前面的 /uri-string)进行匹配,对特定的请求进行处理。地址定向、数据缓
存和应答控制等功能,还有许多第三方模块的配置也在这里进行。
4 Nginx 反向代理实例 1
1、实现效果
打开浏览器,在浏览器地址栏输入地址 www.123.com,跳转到 liunx 系统 tomcat 主页
面中
2、准备工作
(1)在 liunx 系统安装 tomcat,使用默认端口 8080
* tomcat 安装文件放到 liunx 系统中,解压
* 进入 tomcat 的 bin 目录中,./startup.sh 启动 tomcat 服务器
(2)对外开放访问的端口
firewall-cmd –add-port=8080/tcp –permanent
firewall-cmd –reload
查看已经开放的端口号
firewall-cmd –list-all
(3)在 windows 系统中通过浏览器访问 tomcat 服务器
3、访问过程的分析
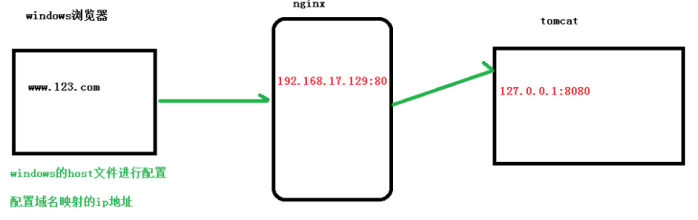
4、具体配置
第一步 在 windows 系统的 host 文件进行域名和 ip 对应关系的配置
添加内容在 host 文件中

第二步 在 nginx 进行请求转发的配置(反向代理配置)
5、最终测试
5、Nginx 反向代理实例 2
1、实现效果
使用 nginx 反向代理,根据访问的路径跳转到不同端口的服务中
nginx 监听端口为 9001,
访问 http://192.168.17.129:9001/edu/ 直接跳转到 127.0.0.1:8080
访问 http:// 192.168.17.129:9001/vod/ 直接跳转到 127.0.0.1:8081
2、准备工作
(1)准备两个 tomcat 服务器,一个 8080 端口,一个 8081 端口
(2)创建文件夹和测试页面
3、具体配置
(1)找到 nginx 配置文件,进行反向代理配置
(2)开放对外访问的端口号 9001 8080 8081
6 Nginx配置实例-负载均衡
1、实现效果
(1)浏览器地址栏输入地址 http://192.168.17.129/edu/a.html,负载均衡效果,平均 8080
和 8081 端口中
2、准备工作
(1)准备两台 tomcat 服务器,一台 8080,一台 8081
(2)在两台 tomcat 里面 webapps 目录中,创建名称是 edu 文件夹,在 edu 文件夹中创建
页面 a.html,用于测试
3、在 nginx 的配置文件中进行负载均衡的配置
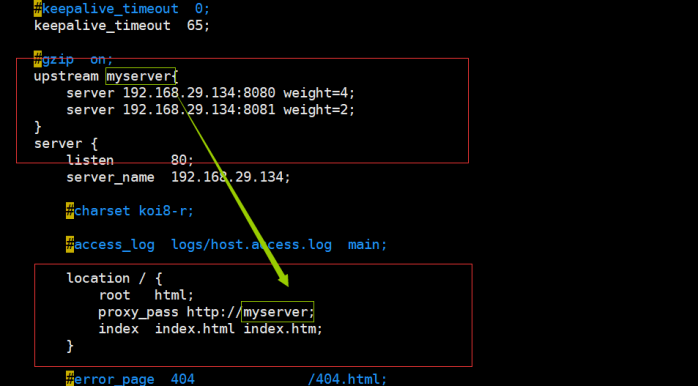
4、nginx 分配服务器策略
第一种 轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器 down 掉,能自动剔除。
第二种 weight
weight 代表权重默认为 1,权重越高被分配的客户端越多

第三种 ip_hash
每个请求按访问 ip 的 hash 结果分配,这样每个访客固定访问一个后端服务器
第四种 fair(第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。

7 Nginx配置实例-动静分离
1 什么是动静分离
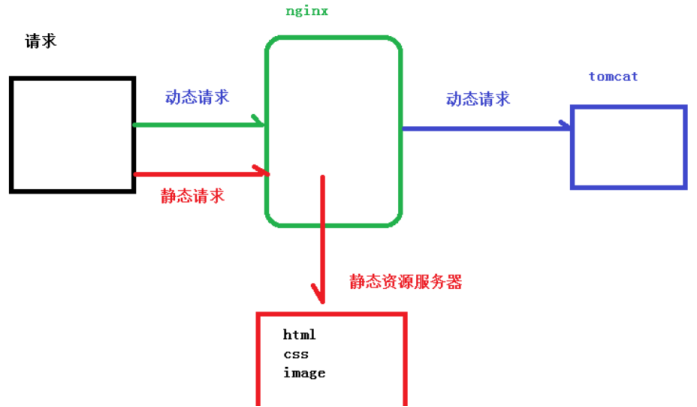
Nginx 动静分离简单来说就是把动态跟静态请求分开,不能理解成只是单纯的把动态页面和
静态页面物理分离。严格意义上说应该是动态请求跟静态请求分开,可以理解成使用 Nginx
处理静态页面,Tomcat 处理动态页面。动静分离从目前实现角度来讲大致分为两种,
一种是纯粹把静态文件独立成单独的域名,放在独立的服务器上,也是目前主流推崇的方案;
另外一种方法就是动态跟静态文件混合在一起发布,通过 nginx 来分开。
通过 location 指定不同的后缀名实现不同的请求转发。通过 expires 参数设置,可以使浏
览器缓存过期时间,减少与服务器之前的请求和流量。具体 Expires 定义:是给一个资源
设定一个过期时间,也就是说无需去服务端验证,直接通过浏览器自身确认是否过期即可,
所以不会产生额外的流量。此种方法非常适合不经常变动的资源。(如果经常更新的文件,
不建议使用 Expires 来缓存),我这里设置 3d,表示在这 3 天之内访问这个 URL,发送一
个请求,比对服务器该文件最后更新时间没有变化,则不会从服务器抓取,返回状态码 304,
如果有修改,则直接从服务器重新下载,返回状态码 200。
2 准备工作
3 具体配置
在nginx配置文件中进行配置
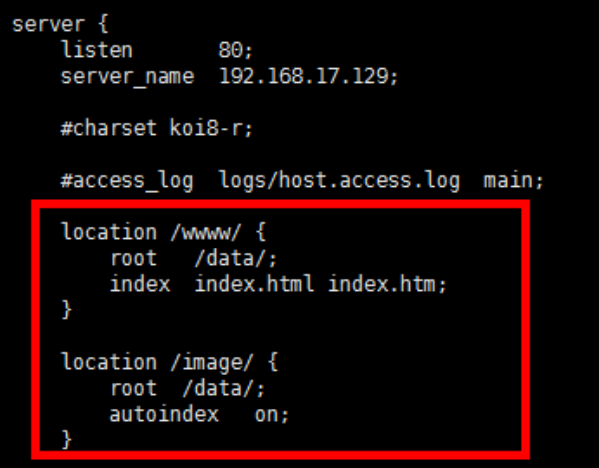
配置文件中进行拼接
root /data/相当于从linux/目录下data文件夹下面拦截wwww文件获取data文件夹下面的wwww的文件夹里面的静态资源进行映射
详情见0 Nginx注意点
4 最终测试
(1) 浏览器中输入地址
http://192.168.17.129/image/01.jpg
重点是添加 location,
最后检查 Nginx 配置是否正确即可,然后测试动静分离是否成功,之需要删除后端 tomcat
服务器上的某个静态文件,查看是否能访问,如果可以访问说明静态资源 nginx 直接返回
了,不走后端 tomcat 服务器
8 完成高可用配置(主从配置)
(1)修改keepalived的配置文件keepalived.conf为:
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_ server 192.168.17.129
smtp_connect_timeout 30
router_id LVS_DEVEL # LVS_DEVEL这字段在/etc/hosts文件中看;通过它访问到主机
}
vrrp_script chk_http_ port {
script "/usr/local/src/nginx_check.sh"
interval 2 # (检测脚本执行的间隔)2s
weight 2 #权重,如果这个脚本检测为真,服务器权重+2
}
vrrp_instance VI_1 {
state BACKUP # 备份服务器上将MASTER 改为BACKUP
interface ens33 //网卡名称
virtual_router_id 51 # 主、备机的virtual_router_id必须相同
priority 100 #主、备机取不同的优先级,主机值较大,备份机值较小
advert_int 1 #每隔1s发送一次心跳
authentication { # 校验方式, 类型是密码,密码1111
auth type PASS
auth pass 1111
}
virtual_ipaddress { # 虛拟ip
192.168.17.50 // VRRP H虛拟ip地址
}
}
(2)在路径/usr/local/src/ 下新建检测脚本 nginx_check.sh
nginx_check.sh
#! /bin/bash
A=`ps -C nginx -no-header | wc - 1`
if [ $A -eq 0];then
/usr/local/nginx/sbin/nginx
sleep 2
if [`ps -C nginx --no-header| wc -1` -eq 0 ];then
killall keepalived
fi
fi
(3) 把两台服务器上nginx和keepalived启动
$ systemctl start keepalived.service #keepalived启动
$ ps -ef I grep keepalived #查看keepalived是否启动
5、最终测试
(1) 在浏览器地址栏输入虚拟ip地址192.168.17.50
(2) 把主服务器(192.168.17.129) nginx和keealived停止,再输入192.168.17.50.
$ systemctl stop keepalived.service #keepalived停止
七、Nginx原理解析
1、master和worker
2、worker如何进行工作的
3、一个master和多个woker的好处 (1) 可以使用nginx -s reload热部署。
首先,对于每个worker进程来说,独立的进程,不需要加锁,所以省掉了锁带来的开销,
同时在编程以及问题查找时,也会方便很多。其次,采用独立的进程,可以让互相之间不会
影响,一个进程退出后,其它进程还在工作,服务不会中断,master进程则很快启动新的
worker进程。当然,worker进程的异常退出,肯定是程序有bug了,异常退出,会导致当
前worker.上的所有请求失败,不过不会影响到所有请求,所以降低了风险。
4、设置多少个woker合适
Nginx同redis类似都采用了io多路复用机制,每个worker都是一个独立的进程, 但每个进
程里只有一个主线程,通过异步非阻塞的方式来处理请求,即使是 千上万个请求也不在话
下。每个worker的线程可以把一个cpu的性能发挥到极致。所以worker数和服务器的cpu
数相等是最为适宜的。设少了会浪费cpu,设多了会造成cpu频繁切换上下文带来的损耗。
# 设置worker数量
worker.processes 4
# work绑定cpu(4work绑定4cpu)
worker_cpu_affinity 0001 0010 0100 1000
# work绑定cpu (4work绑定8cpu中的4个)
worker_cpu_affinity 0000001 00000010 00000100 00001000
5、连接数worker_ connection
这个值是表示每个worker进程所能建立连接的最大值,所以,一个nginx 能建立的最大连接数,应该是worker.connections * worker processes。当然,这里说的是最大连接数,对于HTTP 请求本地资源来说,能够支持的最大并发数量是worker.connections * worker processes,如果是支持http1.1的浏览器每次访问要占两个连接,所以普通的静态访问最大并发数是: worker.connections * worker.processes / 2, 而如果是HTTP作为反向代理来说,最大并发数量应该是worker.connections * worker_proceses/4. 因为作为反向代理服务器,每个并发会建立与客户端的连接和与后端服务的连接,会占用两个连接.
第一个: 发送请求,占用了woker的几个连接数? 答案: 2或者4个。
第二个: nginx有一个master,有四个woker,每个woker支持最大的连接数1024,支持的最大并发数是多少? 答案:普通的静态访问最大并发数是: worker connections * worker processes /2, 而如果是HTTP作为反向代理来说,最大并发数量应该是worker connections * worker processes/4
mysql高级
1 视图
基本的增删改查
#视图
/*
含义:虚拟表,和普通表一样使用
mysql5.1版本出现的新特性,是通过表动态生成的数据
比如:舞蹈班和普通班级的对比
创建语法的关键字 是否实际占用物理空间 使用
视图 create view 只是保存了sql逻辑 增删改查,只是一般不能增删改
表 create table 保存了数据 增删改查
*/
#案例:查询姓张的学生名和专业名
SELECT stuname,majorname
FROM stuinfo s
INNER JOIN major m ON s.`majorid`= m.`id`
WHERE s.`stuname` LIKE '张%';
CREATE VIEW v1
AS
SELECT stuname,majorname
FROM stuinfo s
INNER JOIN major m ON s.`majorid`= m.`id`;
SELECT * FROM v1 WHERE stuname LIKE '张%';
#一、创建视图
/*
语法:
create view 视图名
as
查询语句;
*/
USE myemployees;
#1.查询姓名中包含a字符的员工名、部门名和工种信息
#①创建
CREATE VIEW myv1
AS
SELECT last_name,department_name,job_title
FROM employees e
JOIN departments d ON e.department_id = d.department_id
JOIN jobs j ON j.job_id = e.job_id;
#②使用
SELECT * FROM myv1 WHERE last_name LIKE '%a%';
#2.查询各部门的平均工资级别
#①创建视图查看每个部门的平均工资
CREATE VIEW myv2
AS
SELECT AVG(salary) ag,department_id
FROM employees
GROUP BY department_id;
#②使用
SELECT myv2.`ag`,g.grade_level
FROM myv2
JOIN job_grades g
ON myv2.`ag` BETWEEN g.`lowest_sal` AND g.`highest_sal`;
#3.查询平均工资最低的部门信息
SELECT * FROM myv2 ORDER BY ag LIMIT 1;
#4.查询平均工资最低的部门名和工资
CREATE VIEW myv3
AS
SELECT * FROM myv2 ORDER BY ag LIMIT 1;
SELECT d.*,m.ag
FROM myv3 m
JOIN departments d
ON m.`department_id`=d.`department_id`;
#二、视图的修改
#方式一:
/*
create or replace view 视图名
as
查询语句;
*/
SELECT * FROM myv3
CREATE OR REPLACE VIEW myv3
AS
SELECT AVG(salary),job_id
FROM employees
GROUP BY job_id;
#方式二:
/*
语法:
alter view 视图名
as
查询语句;
*/
ALTER VIEW myv3
AS
SELECT * FROM employees;
#三、删除视图
/*
语法:drop view 视图名,视图名,...;
*/
DROP VIEW emp_v1,emp_v2,myv3;
#四、查看视图
DESC myv3;
SHOW CREATE VIEW myv3;
#五、视图的更新
CREATE OR REPLACE VIEW myv1
AS
SELECT last_name,email,salary*12*(1+IFNULL(commission_pct,0)) "annual salary"
FROM employees;
CREATE OR REPLACE VIEW myv1
AS
SELECT last_name,email
FROM employees;
SELECT * FROM myv1;
SELECT * FROM employees;
#1.插入
INSERT INTO myv1 VALUES('张飞','zf@qq.com');
#2.修改
UPDATE myv1 SET last_name = '张无忌' WHERE last_name='张飞';
#3.删除
DELETE FROM myv1 WHERE last_name = '张无忌';
#具备以下特点的视图不允许更新
#①包含以下关键字的sql语句:分组函数、distinct、group by、having、union或者union all
CREATE OR REPLACE VIEW myv1
AS
SELECT MAX(salary) m,department_id
FROM employees
GROUP BY department_id;
SELECT * FROM myv1;
#更新
UPDATE myv1 SET m=9000 WHERE department_id=10;
#②常量视图
CREATE OR REPLACE VIEW myv2
AS
SELECT 'john' NAME;
SELECT * FROM myv2;
#更新
UPDATE myv2 SET NAME='lucy';
#③Select中包含子查询
CREATE OR REPLACE VIEW myv3
AS
SELECT department_id,(SELECT MAX(salary) FROM employees) 最高工资
FROM departments;
#更新
SELECT * FROM myv3;
UPDATE myv3 SET 最高工资=100000;
#④join
CREATE OR REPLACE VIEW myv4
AS
SELECT last_name,department_name
FROM employees e
JOIN departments d
ON e.department_id = d.department_id;
#更新
SELECT * FROM myv4;
UPDATE myv4 SET last_name = '张飞' WHERE last_name='Whalen';
INSERT INTO myv4 VALUES('陈真','xxxx');
#⑤from一个不能更新的视图
CREATE OR REPLACE VIEW myv5
AS
SELECT * FROM myv3;
#更新
SELECT * FROM myv5;
UPDATE myv5 SET 最高工资=10000 WHERE department_id=60;
#⑥where子句的子查询引用了from子句中的表
CREATE OR REPLACE VIEW myv6
AS
SELECT last_name,email,salary
FROM employees
WHERE employee_id IN(
SELECT manager_id
FROM employees
WHERE manager_id IS NOT NULL
);
#更新
SELECT * FROM myv6;
UPDATE myv6 SET salary=10000 WHERE last_name = 'k_ing';
注意增删改查视图,原始的表也会发生变化
案例视图
#一、创建视图emp_v1,要求查询电话号码以‘011’开头的员工姓名和工资、邮箱
CREATE OR REPLACE VIEW emp_v1
AS
SELECT last_name,salary,email
FROM employees
WHERE phone_number LIKE '011%';
#二、创建视图emp_v2,要求查询部门的最高工资高于12000的部门信息
CREATE OR REPLACE VIEW emp_v2
AS
SELECT MAX(salary) mx_dep,department_id
FROM employees
GROUP BY department_id
HAVING MAX(salary)>12000;
SELECT d.*,m.mx_dep
FROM departments d
JOIN emp_v2 m
ON m.department_id = d.`department_id`;
练习
建立事务创建表并赋值
set autocommit = 0;
insert into book (bid,bname,price,btypeId)
values(1,'小李飞刀',100,1);
COMMIT;
#创建视图查询价格大于100的书名和类型名
create VIEW bookv1
as
SELECT bname,`name`
from book b
JOIN
booktype
on
b.btypeId = booktype.id
where
b.price > 100
#修改视图,实现查询价格在90-120之间的书名和价格
create or replace view bookv1
as
select bname,price from book
where price BETWEEN 90 AND 120
#删除刚才键的视图
drop view bookv1;
2 级联删除和级联置空
级联删除
ALTER TABLE stuinfo ADD CONSTRAINT fk_stu_major FOREIGN KEY(major) REFERENCES major(id) ON DELETE CASCADE
级联置空
ALTER TABLE stuinfo ADD CONSTRAINT fk_stu_major FOREIGN KEY(majorid) REFERENCES major(id) ON DELETE SET NULL;
3 变量
#变量
/*
系统变量:
全局变量
会话变量
自定义变量:
用户变量
局部变量
*/
#一、系统变量
/*
说明:变量由系统定义,不是用户定义,属于服务器层面
注意:全局变量需要添加global关键字,会话变量需要添加session关键字,如果不写,默认会话级别
使用步骤:
1、查看所有系统变量
show global|【session】variables;
2、查看满足条件的部分系统变量
show global|【session】 variables like '%char%';
3、查看指定的系统变量的值
select @@global|【session】系统变量名;
4、为某个系统变量赋值
方式一:
set global|【session】系统变量名=值;
方式二:
set @@global|【session】系统变量名=值;
*/
#1》全局变量
/*
作用域:针对于所有会话(连接)有效,但不能跨重启
*/
#①查看所有全局变量
SHOW GLOBAL VARIABLES;
#②查看满足条件的部分系统变量
SHOW GLOBAL VARIABLES LIKE '%char%';
#③查看指定的系统变量的值
SELECT @@global.autocommit;
#④为某个系统变量赋值
SET @@global.autocommit=0;
SET GLOBAL autocommit=0;
#2》会话变量
/*
作用域:针对于当前会话(连接)有效
*/
#①查看所有会话变量
SHOW SESSION VARIABLES;
#②查看满足条件的部分会话变量
SHOW SESSION VARIABLES LIKE '%char%';
#③查看指定的会话变量的值
SELECT @@autocommit;
SELECT @@session.tx_isolation;
#④为某个会话变量赋值
SET @@session.tx_isolation='read-uncommitted';
SET SESSION tx_isolation='read-committed';
#二、自定义变量
/*
说明:变量由用户自定义,而不是系统提供的
使用步骤:
1、声明
2、赋值
3、使用(查看、比较、运算等)
*/
#1》用户变量
/*
作用域:针对于当前会话(连接)有效,作用域同于会话变量
*/
#赋值操作符:=或:=
#①声明并初始化
SET @变量名=值;
SET @变量名:=值;
SELECT @变量名:=值;
#②赋值(更新变量的值)
#方式一:
SET @变量名=值;
SET @变量名:=值;
SELECT @变量名:=值;
#方式二:
SELECT 字段 INTO @变量名
FROM 表;
#③使用(查看变量的值)
SELECT @变量名;
#2》局部变量
/*
作用域:仅仅在定义它的begin end块中有效
应用在 begin end中的第一句话
*/
#①声明
DECLARE 变量名 类型;
DECLARE 变量名 类型 【DEFAULT 值】;
#②赋值(更新变量的值)
#方式一:
SET 局部变量名=值;
SET 局部变量名:=值;
SELECT 局部变量名:=值;
#方式二:
SELECT 字段 INTO 具备变量名
FROM 表;
#③使用(查看变量的值)
SELECT 局部变量名;
#案例:声明两个变量,求和并打印
#用户变量
SET @m=1;
SET @n=1;
SET @sum=@m+@n;
SELECT @sum;
#局部变量
DECLARE m INT DEFAULT 1;
DECLARE n INT DEFAULT 1;
DECLARE SUM INT;
SET SUM=m+n;
SELECT SUM;
#用户变量和局部变量的对比
作用域 定义位置 语法
用户变量 当前会话 会话的任何地方 加@符号,不用指定类型
局部变量 定义它的BEGIN END中 BEGIN END的第一句话 一般不用加@,需要指定类型
4 存储过程
#存储过程和函数
/*
存储过程和函数:类似于java中的方法
好处:
1、提高代码的重用性
2、简化操作
*/
#存储过程
/*
含义:一组预先编译好的SQL语句的集合,理解成批处理语句
1、提高代码的重用性
2、简化操作
3、减少了编译次数并且减少了和数据库服务器的连接次数,提高了效率
*/
#一、创建语法
CREATE PROCEDURE 存储过程名(参数列表)
BEGIN
存储过程体(一组合法的SQL语句)
END
#注意:
/*
1、参数列表包含三部分
参数模式 参数名 参数类型
举例:
in stuname varchar(20)
参数模式:
in:该参数可以作为输入,也就是该参数需要调用方传入值
out:该参数可以作为输出,也就是该参数可以作为返回值
inout:该参数既可以作为输入又可以作为输出,也就是该参数既需要传入值,又可以返回值
2、如果存储过程体仅仅只有一句话,begin end可以省略
存储过程体中的每条sql语句的结尾要求必须加分号。
存储过程的结尾可以使用 delimiter 重新设置
语法:
delimiter 结束标记
案例:
delimiter $
*/
#二、调用语法
CALL 存储过程名(实参列表);
#--------------------------------案例演示-----------------------------------
#1.空参列表
#案例:插入到admin表中五条记录
SELECT * FROM admin;
DELIMITER $
CREATE PROCEDURE myp1()
BEGIN
INSERT INTO admin(username,`password`)
VALUES('john1','0000'),('lily','0000'),('rose','0000'),('jack','0000'),('tom','0000');
END $
#调用
CALL myp1()$
#2.创建带in模式参数的存储过程
#案例1:创建存储过程实现 根据女神名,查询对应的男神信息
CREATE PROCEDURE myp2(IN beautyName VARCHAR(20))
BEGIN
SELECT bo.*
FROM boys bo
RIGHT JOIN beauty b ON bo.id = b.boyfriend_id
WHERE b.name=beautyName;
END $
#调用
CALL myp2('柳岩')$
#案例2 :创建存储过程实现,用户是否登录成功
CREATE PROCEDURE myp4(IN username VARCHAR(20),IN PASSWORD VARCHAR(20))
BEGIN
DECLARE result INT DEFAULT 0;#声明并初始化
SELECT COUNT(*) INTO result#赋值
FROM admin
WHERE admin.username = username
AND admin.password = PASSWORD;
SELECT IF(result>0,'成功','失败');#使用
END $
#调用
CALL myp3('张飞','8888')$
#3.创建out 模式参数的存储过程
#案例1:根据输入的女神名,返回对应的男神名
CREATE PROCEDURE myp6(IN beautyName VARCHAR(20),OUT boyName VARCHAR(20))
BEGIN
SELECT bo.boyname INTO boyname
FROM boys bo
RIGHT JOIN
beauty b ON b.boyfriend_id = bo.id
WHERE b.name=beautyName ;
END $
#案例2:根据输入的女神名,返回对应的男神名和魅力值
CREATE PROCEDURE myp7(IN beautyName VARCHAR(20),OUT boyName VARCHAR(20),OUT usercp INT)
BEGIN
SELECT boys.boyname ,boys.usercp INTO boyname,usercp
FROM boys
RIGHT JOIN
beauty b ON b.boyfriend_id = boys.id
WHERE b.name=beautyName ;
END $
#调用
CALL myp7('小昭',@name,@cp)$
SELECT @name,@cp$
#4.创建带inout模式参数的存储过程
#案例1:传入a和b两个值,最终a和b都翻倍并返回
CREATE PROCEDURE myp8(INOUT a INT ,INOUT b INT)
BEGIN
SET a=a*2;
SET b=b*2;
END $
#调用
SET @m=10$
SET @n=20$
CALL myp8(@m,@n)$
SELECT @m,@n$
#三、删除存储过程
#语法:drop procedure 存储过程名
DROP PROCEDURE p1;
DROP PROCEDURE p2,p3;#×
#四、查看存储过程的信息
DESC myp2;×
SHOW CREATE PROCEDURE myp2;
注意:都需要加上 DELIMITER $
5 存储过程案例
#一、创建存储过程实现传入用户名和密码,插入到admin表中
CREATE PROCEDURE test_pro1(IN username VARCHAR(20),IN loginPwd VARCHAR(20))
BEGIN
INSERT INTO admin(admin.username,PASSWORD)
VALUES(username,loginpwd);
END $
#二、创建存储过程实现传入女神编号,返回女神名称和女神电话
CREATE PROCEDURE test_pro2(IN id INT,OUT NAME VARCHAR(20),OUT phone VARCHAR(20))
BEGIN
SELECT b.name ,b.phone INTO NAME,phone
FROM beauty b
WHERE b.id = id;
END $
#三、创建存储存储过程或函数实现传入两个女神生日,返回大小
CREATE PROCEDURE test_pro3(IN birth1 DATETIME,IN birth2 DATETIME,OUT result INT)
BEGIN
SELECT DATEDIFF(birth1,birth2) INTO result;
END $
#四、创建存储过程或函数实现传入一个日期,格式化成xx年xx月xx日并返回
CREATE PROCEDURE test_pro4(IN mydate DATETIME,OUT strDate VARCHAR(50))
BEGIN
SELECT DATE_FORMAT(mydate,'%y年%m月%d日') INTO strDate;
END $
CALL test_pro4(NOW(),@str)$
SELECT @str $
#五、创建存储过程或函数实现传入女神名称,返回:女神 and 男神 格式的字符串
如 传入 :小昭
返回: 小昭 AND 张无忌
DROP PROCEDURE test_pro5 $
CREATE PROCEDURE test_pro5(IN beautyName VARCHAR(20),OUT str VARCHAR(50))
BEGIN
SELECT CONCAT(beautyName,' and ',IFNULL(boyName,'null')) INTO str
FROM boys bo
RIGHT JOIN beauty b ON b.boyfriend_id = bo.id
WHERE b.name=beautyName;
SET str=
END $
CALL test_pro5('柳岩',@str)$
SELECT @str $
#六、创建存储过程或函数,根据传入的条目数和起始索引,查询beauty表的记录
DROP PROCEDURE test_pro6$
CREATE PROCEDURE test_pro6(IN startIndex INT,IN size INT)
BEGIN
SELECT * FROM beauty LIMIT startIndex,size;
END $
CALL test_pro6(3,5)$
6 函数
#函数
/*
含义:一组预先编译好的SQL语句的集合,理解成批处理语句
1、提高代码的重用性
2、简化操作
3、减少了编译次数并且减少了和数据库服务器的连接次数,提高了效率
区别:
存储过程:可以有0个返回,也可以有多个返回,适合做批量插入、批量更新
函数:有且仅有1 个返回,适合做处理数据后返回一个结果
*/
#一、创建语法
CREATE FUNCTION 函数名(参数列表) RETURNS 返回类型
BEGIN
函数体
END
/*
注意:
1.参数列表 包含两部分:
参数名 参数类型
2.函数体:肯定会有return语句,如果没有会报错
如果return语句没有放在函数体的最后也不报错,但不建议
return 值;
3.函数体中仅有一句话,则可以省略begin end
4.使用 delimiter语句设置结束标记
*/
#二、调用语法
SELECT 函数名(参数列表)
#------------------------------案例演示----------------------------
#1.无参有返回
#案例:返回公司的员工个数
CREATE FUNCTION myf1() RETURNS INT
BEGIN
DECLARE c INT DEFAULT 0;#定义局部变量
SELECT COUNT(*) INTO c#赋值
FROM employees;
RETURN c;
END $
SELECT myf1()$
#2.有参有返回
#案例1:根据员工名,返回它的工资
CREATE FUNCTION myf2(empName VARCHAR(20)) RETURNS DOUBLE
BEGIN
SET @sal=0;#定义用户变量
SELECT salary INTO @sal #赋值
FROM employees
WHERE last_name = empName;
RETURN @sal;
END $
SELECT myf2('k_ing') $
#案例2:根据部门名,返回该部门的平均工资
CREATE FUNCTION myf3(deptName VARCHAR(20)) RETURNS DOUBLE
BEGIN
DECLARE sal DOUBLE ;
SELECT AVG(salary) INTO sal
FROM employees e
JOIN departments d ON e.department_id = d.department_id
WHERE d.department_name=deptName;
RETURN sal;
END $
SELECT myf3('IT')$
#三、查看函数
SHOW CREATE FUNCTION myf3;
#四、删除函数
DROP FUNCTION myf3;
#案例
#一、创建函数,实现传入两个float,返回二者之和
CREATE FUNCTION test_fun1(num1 FLOAT,num2 FLOAT) RETURNS FLOAT
BEGIN
DECLARE SUM FLOAT DEFAULT 0;
SET SUM=num1+num2;
RETURN SUM;
END $
SELECT test_fun1(1,2)$
7 流程控制结构
#流程控制结构
/*
顺序、分支、循环
*/
#一、分支结构
#1.if函数
/*
语法:if(条件,值1,值2)
功能:实现双分支
应用在begin end中或外面
*/
#2.case结构
/*
语法:
情况1:类似于switch
case 变量或表达式
when 值1 then 语句1;
when 值2 then 语句2;
...
else 语句n;
end
情况2:
case
when 条件1 then 语句1;
when 条件2 then 语句2;
...
else 语句n;
end
应用在begin end 中或外面
*/
#3.if结构
/*
语法:
if 条件1 then 语句1;
elseif 条件2 then 语句2;
....
else 语句n;
end if;
功能:类似于多重if
只能应用在begin end 中
*/
#案例1:创建函数,实现传入成绩,如果成绩>90,返回A,如果成绩>80,返回B,如果成绩>60,返回C,否则返回D
CREATE FUNCTION test_if(score FLOAT) RETURNS CHAR
BEGIN
DECLARE ch CHAR DEFAULT 'A';
IF score>90 THEN SET ch='A';
ELSEIF score>80 THEN SET ch='B';
ELSEIF score>60 THEN SET ch='C';
ELSE SET ch='D';
END IF;
RETURN ch;
END $
SELECT test_if(87)$
#案例2:创建存储过程,如果工资<2000,则删除,如果5000>工资>2000,则涨工资1000,否则涨工资500
CREATE PROCEDURE test_if_pro(IN sal DOUBLE)
BEGIN
IF sal<2000 THEN DELETE FROM employees WHERE employees.salary=sal;
ELSEIF sal>=2000 AND sal<5000 THEN UPDATE employees SET salary=salary+1000 WHERE employees.`salary`=sal;
ELSE UPDATE employees SET salary=salary+500 WHERE employees.`salary`=sal;
END IF;
END $
CALL test_if_pro(2100)$
#案例1:创建函数,实现传入成绩,如果成绩>90,返回A,如果成绩>80,返回B,如果成绩>60,返回C,否则返回D
CREATE FUNCTION test_case(score FLOAT) RETURNS CHAR
BEGIN
DECLARE ch CHAR DEFAULT 'A';
CASE
WHEN score>90 THEN SET ch='A';
WHEN score>80 THEN SET ch='B';
WHEN score>60 THEN SET ch='C';
ELSE SET ch='D';
END CASE;
RETURN ch;
END $
SELECT test_case(56)$
#二、循环结构
/*
分类:
while、loop、repeat
循环控制:
iterate类似于 continue,继续,结束本次循环,继续下一次
leave 类似于 break,跳出,结束当前所在的循环
*/
#1.while
/*
语法:
【标签:】while 循环条件 do
循环体;
end while【 标签】;
联想:
while(循环条件){
循环体;
}
*/
#2.loop
/*
语法:
【标签:】loop
循环体;
end loop 【标签】;
可以用来模拟简单的死循环
*/
#3.repeat
/*
语法:
【标签:】repeat
循环体;
until 结束循环的条件
end repeat 【标签】;
*/
#1.没有添加循环控制语句
#案例:批量插入,根据次数插入到admin表中多条记录
DROP PROCEDURE pro_while1$
CREATE PROCEDURE pro_while1(IN insertCount INT)
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i<=insertCount DO
INSERT INTO admin(username,`password`) VALUES(CONCAT('Rose',i),'666');
SET i=i+1;
END WHILE;
END $
CALL pro_while1(100)$
/*
int i=1;
while(i<=insertcount){
//插入
i++;
}
*/
#2.添加leave语句
#案例:批量插入,根据次数插入到admin表中多条记录,如果次数>20则停止
TRUNCATE TABLE admin$
DROP PROCEDURE test_while1$
CREATE PROCEDURE test_while1(IN insertCount INT)
BEGIN
DECLARE i INT DEFAULT 1;
a:WHILE i<=insertCount DO
INSERT INTO admin(username,`password`) VALUES(CONCAT('xiaohua',i),'0000');
IF i>=20 THEN LEAVE a;
END IF;
SET i=i+1;
END WHILE a;
END $
CALL test_while1(100)$
#3.添加iterate语句
#案例:批量插入,根据次数插入到admin表中多条记录,只插入偶数次
TRUNCATE TABLE admin$
DROP PROCEDURE test_while1$
CREATE PROCEDURE test_while1(IN insertCount INT)
BEGIN
DECLARE i INT DEFAULT 0;
a:WHILE i<=insertCount DO
SET i=i+1;
IF MOD(i,2)!=0 THEN ITERATE a;
END IF;
INSERT INTO admin(username,`password`) VALUES(CONCAT('xiaohua',i),'0000');
END WHILE a;
END $
CALL test_while1(100)$
/*
int i=0;
while(i<=insertCount){
i++;
if(i%2==0){
continue;
}
插入
}
*/
8 MySql用户组管理
| 路径 | 解释 |
|---|---|
| /var/lib/mysql/ | mysql 数据库文件的存放路径 |
| /usr/share/mysql | 配置文件目录 |
| /usr/bin | 相关命令目录 |
| /etc/init.d/mysql | 服务启停相关 |
8.1 用户管理相关命令
1 创建用户
创建一个用户,密码设置为123123
create user zhang3 identified by '123123'
2 查看用户的权限和相关的Sql指令
select host,user,password,select_priv,drop_priv from mysql.user
1 host :表示连接类型 % 表示所有远程通过 TCP 方式的连接 IP 地址 如 (192.168.1.2,127.0.0.1) 通过制定 ip 地址进行的 TCP 方式的连接 机器名 通过制定 i 网络中的机器名进行的 TCP 方式的连接 ::1 IPv6 的本地 ip 地址 等同于 IPv4 的 127.0.0.1 localhost 本地方式通过命令行方式的连接 , 比如 mysql -u xxx -p 123xxx 方式的连接。
2 user:表示用户名
同一个用户通过不同方式链接的权限是不一样的
3 password:密码
- 所有密码串通过 password(明文字符串) 生成的密文字符串。 加密算法为 MYSQLSHA1 , 不可逆 。
- mysql 5.7 的密码保存到 authentication_string 字段中不再使用 password 字段。
4 select_priv ,insert_priv 等
- 为该用户所拥有的权限。
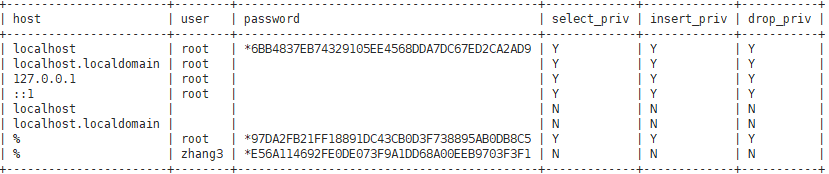
3 修改当前用户的密码
set password =password('123456');
4 修改其他用户的密码
修改李四用户的密码
update mysql.user set password=password('123456') where user = 'li4';
注意:所有通过user表的修改,必须用flush privileges;命令才能生效
5 修改用户名
- 将王五的用户名修改为李四
update mysql.user set user='li4' where user='wang5';
- 注意:所有通过 user 表的修改, 必须 用
flush privileges;命令才能生 效
6 删除用户
删除李四用户
drop user li4
- 注意:不要通过
delete from user u where user='li4'进行删除, 系 统会有残留信息保留。
8.2 Mysql的权限管理
改权限如果发现没有该用户,则回直接新建一个用户
grant 权限 1,权限 2,…权限 n on 数据库名称.表名称 to 用户名@用户地址 identified by '连接口令'
用户地址有%代表在别处登录,localhost代表在本机工作,如果设置了%就不能在本机工作
示例给 li4 用户用本地命令行方式下, 授予 atguigudb 这个库下的所有 表的插删改查的权限。
grant select,insert,delete,drop on atguigudb.* to li4@localhost ;
-
授予通过网络方式登录的的 joe 用户,对所有库所有表的全部权 限, 密码设为 123
grant all privileges on *.* to joe@'%' identified by '123';
查看当前用户的权限
show grants
收回权限
revoke [权限 1,权限 2,…权限 n] on 库名.表名 from 用户名@用户地址;
收回全库全表的所有权限
REVOKE ALL PRIVILEGES ON mysql.* FROM joe@localhost;
-
收回 mysql 库下的所有表的插删改查 权限
REVOKE select,insert,update,delete ON mysql.* FROM joe@localhost;
-
注意:权限收回后, 必须用户重新登录后, 才能生效。
注意:所有通过 user 表的修改, 必须 用 flush privileges; 命令才能生 效
查看权限
show grants
查看所有用户权限 select * from user;
9 Mysql配置文件
二进制日志文件log-bin
二进制日志文件 log-bin :用于主重复制
错误日志 log-error
默认是关闭的,记录严重的警告和错误信息,每次启动和关闭的详细信息等
查询日志 log
默认关闭,记录查询的sql语句,如果开启会减低mysql的整体性能,因为记录日志也是需要消耗系统资源的
数据文件
数据文件
- 数据库文件:默认路径:/var/lib/mysql
- frm文件:存放表结构
- myd文件:存放表数据
- myi文件:存放表索引
如何配置
- Windows 系统下:my.ini文件
- Linux 系统下:etc/my.cnf
10 MySql逻辑架构介绍
mysql的分层思想
- 和其它数据库相比,MySQL有点与众不同,它的架构可以在多种不同场景中应用并发挥良好作用。主要体现在存储引擎的架构上。
- 插件式的存储引擎架构将查询处理和其它的系统任务以及数据的存储提取相分离。这种架构可以根据业务的需求和实际需要选择合适的存储引擎。
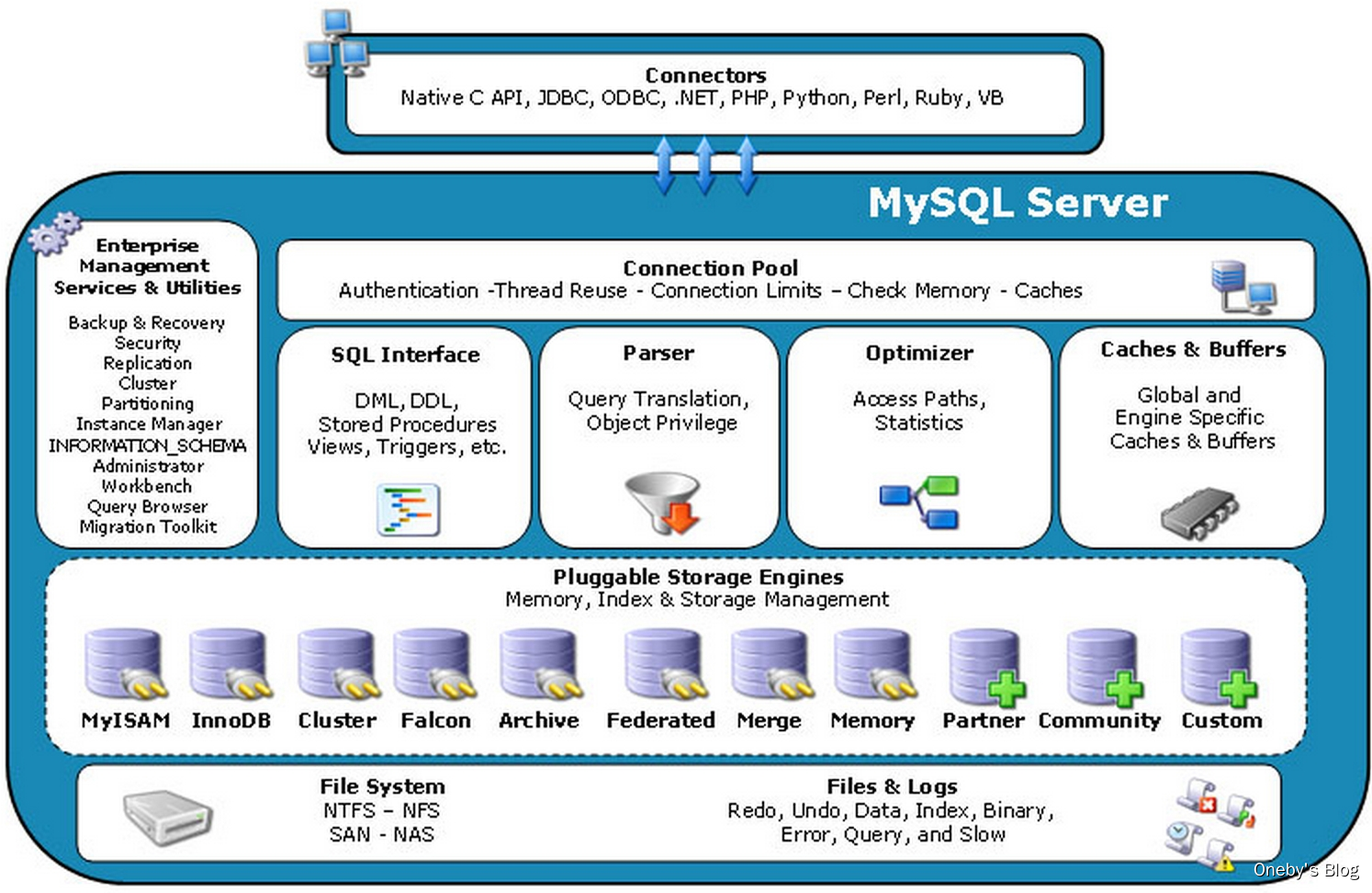
mysql四层架构
连接层:最上层是一些客户端和连接服务,包含本地sock通信和大多数基于客户端/服务端工具实现的类似于tcp/ip的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
服务层:第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化及部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如过程、函数等。在该层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化如确定查询表的顺序,是否利用索引等,最后生成相应的执行操作。如果是select语句,服务器还会查询内部的缓存。如果缓存空间足够大,这样在解决大量读操作的环境中能够很好的提升系统的性能。
引擎层:存储引擎层,存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过APl与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取。后面介绍MyISAM和InnoDB
存储层:数据存储层,主要是将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互。
mySql部件
Sql大致的查询流程
mysql 的查询流程大致是:
1 mysql 客户端通过协议与 mysql 服务器建连接, 发送查询语句, 先检查查询缓存, 如果命中, 直接返回结果,否则进行语句解析,也就是说, 在解析查询之前, 服务器会先访问查询缓存(query cache)——它存储 SELECT 语句以及相应的查询结果集。 如果某个查询结果已经位于缓存中, 服务器就不会再对查询进行解析、 优化、 以及执行。 它仅仅将缓存中的结果返回给用户即可, 这将大大提高系统的性能。 2 语法解析器和预处理: 首先 mysql 通过关键字将 SQL 语句进行解析, 并生成一颗对应的“解析树”。 mysql 解析器将使用 mysql 语法规则验证和解析查询; 预处理器则根据一些 mysql 规则进一步检查解析数是否合法。 3 查询优化器当解析树被认为是合法的了, 并且由优化器将其转化成执行计划。 一条查询可以有很多种执行方式,最后都返回相同的结果。 优化器的作用就是找到这其中最好的执行计划。 4 然后, mysql 默认使用的 BTREE 索引, 并且一个大致方向是:无论怎么折腾 sql, 至少在目前来说, mysql 最多只用到表中的一个索引。
查看 mysql 存储引擎
查看 mysql 支持的存储引擎
show engines;
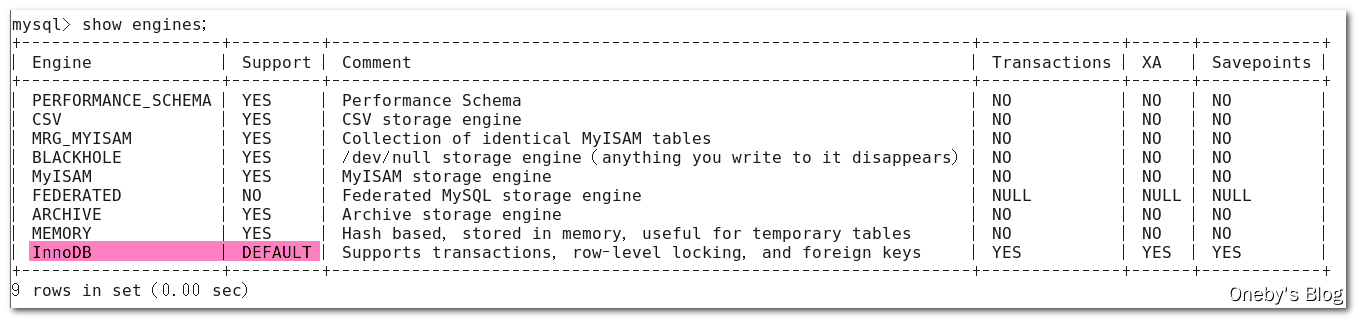
查看 mysql 默认的存储引擎
show variables like '%storage_engine%';
MyISAM 引擎和 InnoDb 引擎的对比
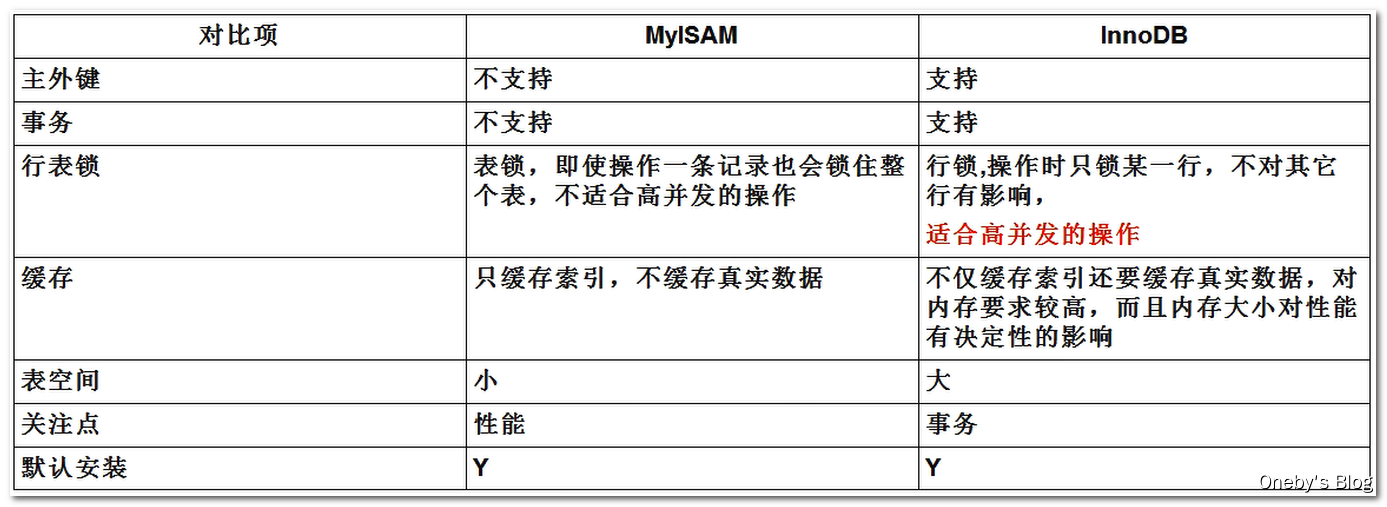
阿里巴巴用的是啥数据库?
Percona为MySQL数据库服务器进行了改进,在功能和性能上较MySQL有着很显著的提升。该版本提升了在高负载情况下的InnoDB的性能、为DBA提供一些非常有用的性能诊断工具;另外有更多的参数和命令来控制服务器行为。 该公司新建了一款存储引擎叫xtradb完全可以替代innodb,并且在性能和并发上做得更好,阿里巴巴大部分mysql数据库其实使用的percona的原型加以修改。

11 索引优化分析
https://blog.csdn.net/oneby1314/article/details/107938325
11.1 慢SQL
性能下降,SQL慢,执行时间长,等待时间长的原因分析
1.查询语句写的烂
2.索引失效
1.单值索引:在user表中给name属性建个索引,
create index idx_user_name on user(name)
2.复合索引:在user表中给name,email属性建个索引
create index idx_user_nameEmail on user(name,email)
3 关联查询太多join(设计缺陷或不得已的需求)
4 服务器调优及各个参数设置(缓冲,线程数等)
11.2 SQL执行顺序
我们手写的SQL顺序

MySQL实际执行SQL顺序
- mysql 执行的顺序:随着 Mysql 版本的更新换代, 其优化器也在不断的升级, 优化器会分析不同执行顺序产生的性能消耗不同而动态调整执行顺序。
- 下面是经常出现的查询顺序:

总结:mysql从FROM开始执行~
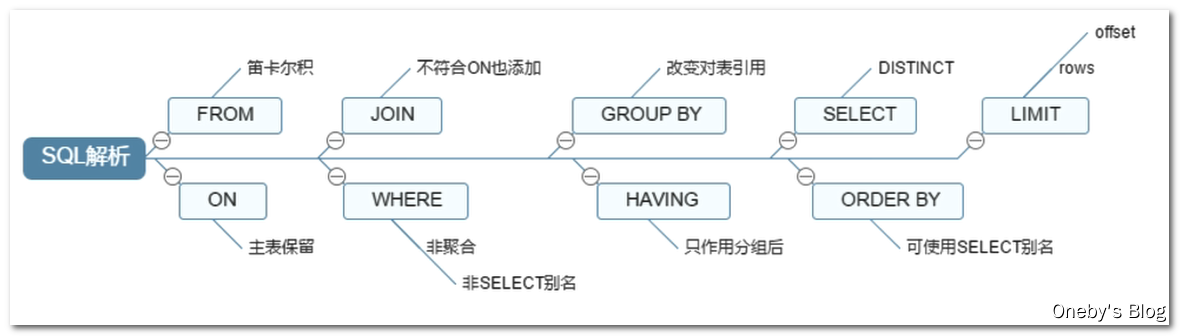
11.3 JOIN连接查询
常见的JOIN查询图
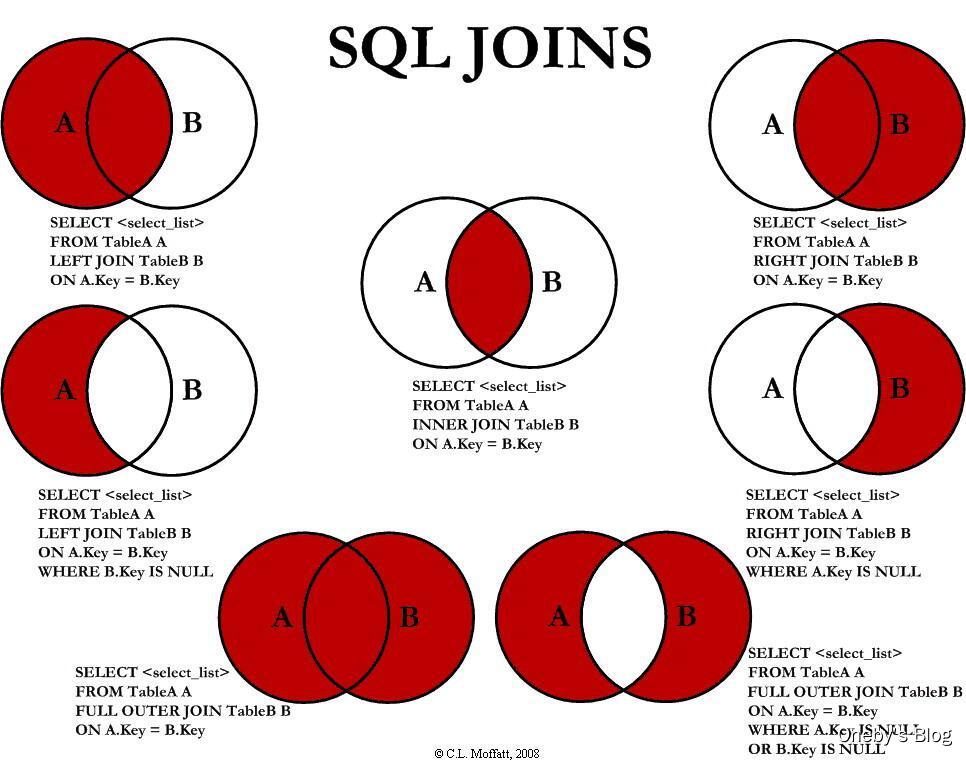
由于mysql不支持全连接,因此可以使用
mysql> select * from tbl_emp e left join tbl_dept d on e.deptId = d.id
-> union
-> select * from tbl_emp e right join tbl_dept d on e.deptId = d.id;
全连接但是没有两个表都有的连接
mysql> select * from tbl_emp e left join tbl_dept d on e.deptId = d.id where d.id is null
-> union
-> select * from tbl_emp e right join tbl_dept d on e.deptId = d.id where e.id is null;
11.4 索引简介
4.1 索引是什么
索引是什么
1 MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。可以得到索引的本质:索引是数据结构 2 你可以简单理解为"排好序的快速查找数据结构",即索引 = 排序 + 查找 3 一般来说索引本身占用内存空间也很大,不可能全部存储在内存中,因此索引往往以文件形式存储在硬盘上 4 我们平时所说的索引,如果没有特别指明,都是指B树(多路搜索树,并不一定是二叉树)结构组织的索引。 5 聚集索引,次要索引,覆盖索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引,统称索引。当然,除了B+树这种类型的索引之外,还有哈希索引(hash index)等
4.2 索引原理
将索引理解为"排列好的快速查找数据结构"
就是把这个表中的频繁查找的字段给列出来,相当于建一张包含id和需要建立索引的字段的数据结构
当进行查询这个字段的时候,这个字段被找到的同时,当前字段对应的行也被查找出来,实现了快速查找数据
下图就是一种可能的索引方式示例: 左边是数据表,一共有两列七条记录,最左边的十六进制数字是数据记录的物理地址 为了加快col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在一定的复杂度内获取到相应数据,从而快速的检索出符合条件的记录。
索引的优势
- 类似大学图书馆的书目索引,提高数据检索效率,降低数据库的IO成本
- 通过索引列对数据进行排序,降低数据排序成本,降低了CPU的消耗
索引的劣势
1 实际上索引也是一张表,该表保存了主键和索引字段,并指向实体表的记录,所以索引列也是要占用空间的 2 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如果对表INSERT,UPDATE和DELETE。因为更新表时,MySQL不仅要不存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息 3 索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立优秀的索引,或优化查询语句
11.5 索引的分类
1.普通索引
是最基本的索引,它没有任何限制。它有以下几种创建方式: (1)直接创建索引
CREATE INDEX index_name ON table(column(length))
(2)修改表结构的方式添加索引
ALTER TABLE table_name ADD INDEX index_name ON (column(length))
(3)创建表的时候同时创建索引
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER NOT NULL ,
`content` text CHARACTER NULL ,
`time` int(10) NULL DEFAULT NULL ,
PRIMARY KEY (`id`),
INDEX index_name (title(length))
)
(4)删除索引
DROP INDEX index_name ON table
2.唯一索引
与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。它有以下几种创建方式: (1)创建唯一索引
CREATE UNIQUE INDEX indexName ON table(column(length))
(2)修改表结构
ALTER TABLE table_name ADD UNIQUE indexName ON (column(length))
(3)创建表的时候直接指定
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER NOT NULL ,
`content` text CHARACTER NULL ,
`time` int(10) NULL DEFAULT NULL ,
UNIQUE indexName (title(length))
);
3.主键索引
是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引:
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) NOT NULL ,
PRIMARY KEY (`id`)
);
4.组合索引
指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合
ALTER TABLE `table` ADD INDEX name_city_age (name,city,age);
5.全文索引
主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。fulltext索引配合match against操作使用,而不是一般的where语句加like。它可以在create table,alter table ,create index使用,不过目前只有char、varchar,text 列上可以创建全文索引。值得一提的是,在数据量较大时候,现将数据放入一个没有全局索引的表中,然后再用CREATE index创建fulltext索引,要比先为一张表建立fulltext然后再将数据写入的速度快很多。 (1)创建表的适合添加全文索引
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER NOT NULL ,
`content` text CHARACTER NULL ,
`time` int(10) NULL DEFAULT NULL ,
PRIMARY KEY (`id`),
FULLTEXT (content)
);
(2)修改表结构添加全文索引
ALTER TABLE article ADD FULLTEXT index_content(content)
(3)直接创建索引
CREATE FULLTEXT INDEX index_content ON article(content)
查看指定表的索引
mysql> show index from tbl_emp;
+---------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| tbl_emp | 0 | PRIMARY | 1 | id | A | 8 | NULL | NULL | | BTREE | | |
| tbl_emp | 1 | fk_dept_Id | 1 | deptId | A | 8 | NULL | NULL | YES | BTREE | | |
+---------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec)
11.6 MySQL的索引结构
6.1 Btree索引
Btree索引搜索过程
【初始化介绍】
1 一颗 b 树, 浅蓝色的块我们称之为一个磁盘块, 可以看到每个磁盘块包含几个数据项(深蓝色所示) 和指针(黄色所示) 2 如磁盘块 1 包含数据项 17 和 35, 包含指针 P1、 P2、 P3 3 P1 表示小于 17 的磁盘块, P2 表示在 17 和 35 之间的磁盘块, P3 表示大于 35 的磁盘块 4 真实的数据存在于叶子节点和非叶子节点中
【查找过程】
如果要查找数据项 29, 那么首先会把磁盘块 1 由磁盘加载到内存, 此时发生一次 IO, 在内存中用二分查找确定 29在 17 和 35 之间, 锁定磁盘块 1 的 P2 指针, 内存时间因为非常短(相比磁盘的 IO) 可以忽略不计 通过磁盘块 1的 P2 指针的磁盘地址把磁盘块 3 由磁盘加载到内存, 发生第二次 IO, 29 在 26 和 30 之间, 锁定磁盘块 3 的 P2 指针 通过指针加载磁盘块 8 到内存, 发生第三次 IO, 同时内存中做二分查找找到 29, 结束查询, 总计三次 IO。
6.2 B+tree索引
B+tree索引搜索过程
[B+Tree与BTree的区别]
B-树的关键字(数据项)和记录是放在一起的; B+树的非叶子节点中只有关键字和指向下一个节点的索引, 记录只放在叶子节点中。
【B+Tree 与 BTree 的查找过程】
在 B 树中, 越靠近根节点的记录查找时间越快, 只要找到关键字即可确定记录的存在; 而 B+ 树中每个记录的查找时间基本是一样的, 都需要从根节点走到叶子节点, 而且在叶子节点中还要再比较关键字。 从这个角度看 B 树的性能好像要比 B+ 树好, 而在实际应用中却是 B+ 树的性能要好些。 因为 B+ 树的非叶子节点不存放实际的数据,这样每个节点可容纳的元素个数比 B 树多, 树高比 B 树小, 这样带来的好处是减少磁盘访问次数。 尽管 B+ 树找到一个记录所需的比较次数要比 B 树多, 但是一次磁盘访问的时间相当于成百上千次内存比较的时间, 因此实际中B+ 树的性能可能还会好些, 而且 B+树的叶子节点使用指针连接在一起, 方便顺序遍历(范围搜索), 这也是很多数据库和文件系统使用 B+树的缘故。 【性能提升】
真实的情况是, 3 层的 B+ 树可以表示上百万的数据, 如果上百万的数据查找只需要三次 IO, 性能提高将是巨大的,如果没有索引, 每个数据项都要发生一次 IO, 那么总共需要百万次的 IO, 显然成本非常非常高。
【思考: 为什么说 B+树比 B-树更适合实际应用中操作系统的文件索引和数据库索引?】
B+树的磁盘读写代价更低:B+树的内部结点并没有指向关键字具体信息的指针。 因此其内部结点相对 B 树更小。 如果把所有同一内部结点的关键字存放在同一盘块中, 那么盘块所能容纳的关键字数量也越多。 一次性读入内存中的需要查找的关键字也就越多。 相对来说 IO 读写次数也就降低了。 B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点, 而只是叶子结点中关键字的索引。 所以任何关键字的查找必须走一条从根结点到叶子结点的路。 所有关键字查询的路径长度相同, 导致每一个数据的查询效率相当。
11.7 何时需要建索引
下列情况需要创建索引
1 主键自动建立唯一索引 2 频繁作为查询的条件的字段应该创建索引 3 查询中与其他表关联的字段,外键关系建立索引 4 频繁更新的字段不适合创建索引 5 Where 条件里用不到的字段不创建索引 6 单间/组合索引的选择问题,Who?(在高并发下倾向创建组合索引) 7 查询中排序的字段,排序字段若通过索引去访问将大大提高排序的速度 8 查询中统计或者分组字段
下列情况不要创建索引
表记录太少
经常增删改的表
数据重复且分布平均的表字段,因此应该只为经常查询和经常排序的数据列建立索引。注意,如果某个数据包含许多重复的内容,为它建立索引就没有太大的实际效果
案例分析:
假如一个表有10万行记录,有一个字段A只有T和F两种值,且每个值的分布概率大约为50%,那么对这种表A字段建索引一般不会提高数据库的查询速度。 索引的选择性是指索引列中不同值的数目与表中记录数的比。如果一个表中有2000条记录,表索引列有1980个不同的值,那么这个索引的选择性就是1980/2000=0.99。 一个索引的选择性越接近于1,这个索引的效率就越高。
11.8 性能分析
MySql Query Optimizer的作用
- MySQL 中有专门负责优化SELECT语句的优化器模块,主要功能:通过计算分析系统中收集到的统计信息,为客户端请求的Query提供他认为最优的执行计划(MySQL认为最优的数据检索方式,但不见得是DBA认为是最优的,这部分最耗费时间)
- 当客户端向MySQL 请求一条Query,命令解析器模块完成请求分类,区别出是SELECT并转发给MySQL Query Optimizer时,MySQL Query Optimizer 首先会对整条Query进行优化,处理掉一些常量表达式的预算,直接换算成常量值。并对Query中的查询条件进行简化和转换,如去掉一些无用或显而易见的条件、结构调整等。然后分析 Query中的Hint信息(如果有),看显示Hint信息是否可以完全确定该Query的执行计划。如果没有Hint 或Hint 信息还不足以完全确定执行计划,则会读取所涉及对象的统计信息,根据Query进行写相应的计算分析,然后再得出最后的执行计划。
MySQL常见瓶颈
- CPU 瓶颈:CPU在饱和的时候一般发生在数据装入在内存或从磁盘上读取数据时候
- IO 瓶颈:磁盘I/O瓶颈发生在装入数据远大于内存容量时
- 服务器硬件的性能瓶颈:top、free、iostat和vmstat来查看系统的性能状态
11.9 Explain
11.9.1 Explain概述
Explain
是什么?Explaion是查看执行计划
- 使用EXPLAIN关键字可以模拟优化器执行SQL语句,从而知道MySQL是如何处理你的SQL语句。分析你的查询语句或是结构的性能瓶颈
- 官方地址:https://dev.mysql.com/doc/refman/8.0/en/explain-output.html
能干嘛?
- 表的读取顺序(id 字段)
- 数据读取操作的操作类型(select_type 字段)
- 哪些索引可以使用(possible_keys 字段)
- 哪些索引被实际使用(keys 字段)
- 表之间的引用(ref 字段)
- 每张表有多少行被优化器查询(rows 字段)
- Explain + SQL语句
explain select * from tbl_emp;
11.9.2 Explain详解
id: select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
id取值的三种情况:
1.id相同,执行顺序由上至下
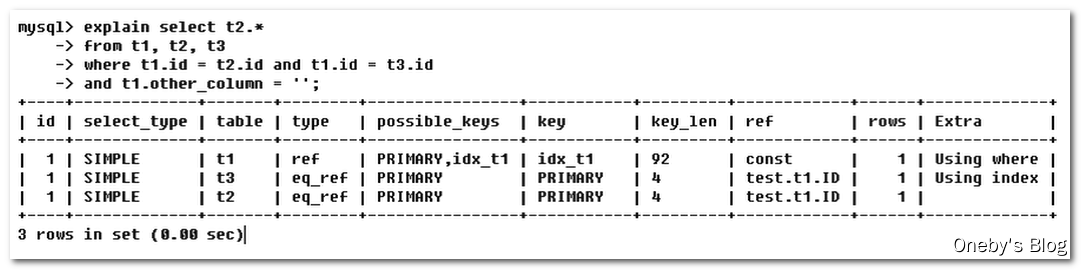
2 id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
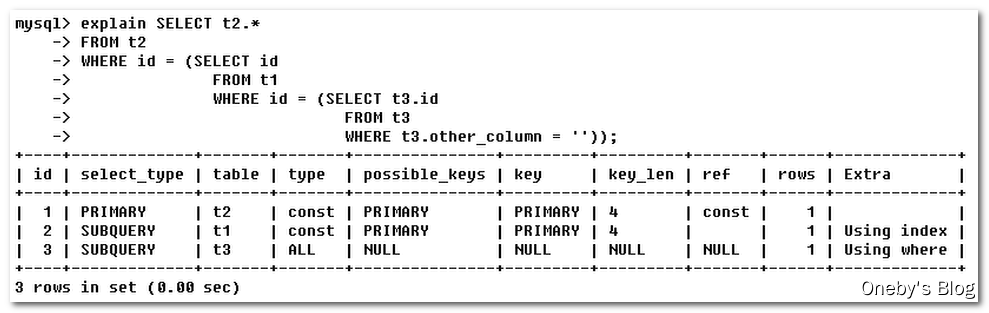
3 id相同不同,同时存在:id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行;衍生=DERIVED
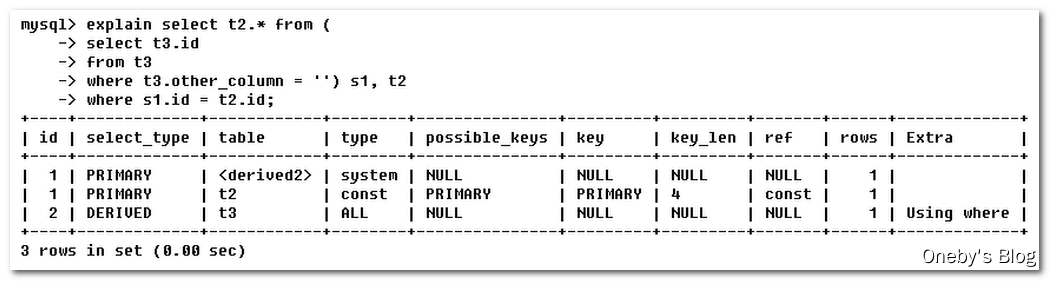
select_type:查询的类型,主要用于区别普通查询、联合查询、子查询等复杂查询
SIMPLE:简单的select查询,查询中不包含子查询或者UNION PRIMARY:查询中若包含任何复杂的子部分,最外层查询则被标记为PRIMARY SUBQUERY:在SELECT或者WHERE列表中包含了子查询 DERIVED:在FROM列表中包含的子查询被标记为DERIVED(衍生)MySQL会递归执行这些子查询,把结果放在临时表里 UNION:若第二个SELECT出现在UNION之后,则被标记为UNION;若UNION包含在FROM子句的子查询中,外层SELECT将被标记为:DERIVED UNION RESULT:从UNION表获取结果的SELECT

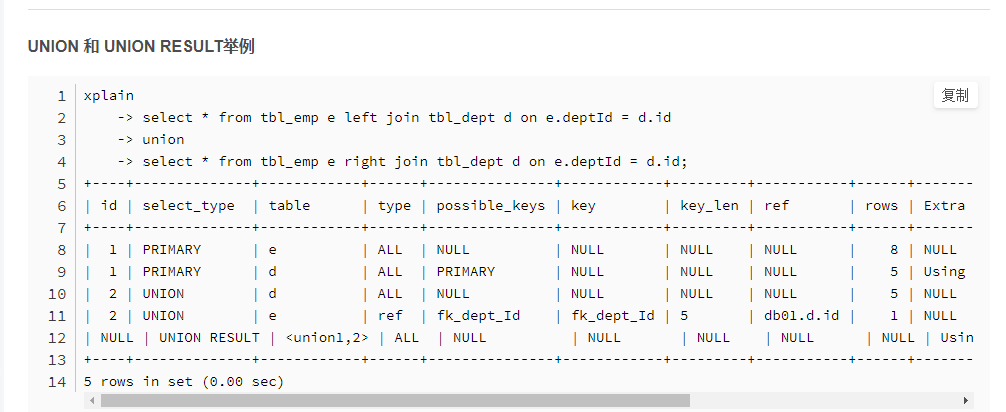
table:显示这一行的数据是关于哪张表的
type:访问类型排列,显示查询使用了何种类型
type显示的是访问类型,是较为重要的一个指标,结果值从最好到最坏依次是:system>const>eq_ref>ref>fultext>ref_or_null>index_merge>unique_subquery>index_subquery>range>index>ALL 挑重要的来说:system>const>eq_ref>ref>range>index>ALL,一般来说,得保证查询至少达到range级别,最好能达到ref。
从最好到最差依次是:system>const>eq_ref>ref>range>index>ALL
system:表只有一行记录(等于系统表),这是const类型的特例,平时不会出现,这个也可以忽略不计
const:表示通过索引一次就找到了,const用于比较primary key或者unique索引。因为只匹配一行数据,所以很快。如将主键置于where列表中,MySQL就能将该查询转换为一个常量

eq_ref:唯一性索引,对于每个索引键,表中只有一条记录与之匹配,常见于主键或唯一索引扫描

ref:非唯一索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体
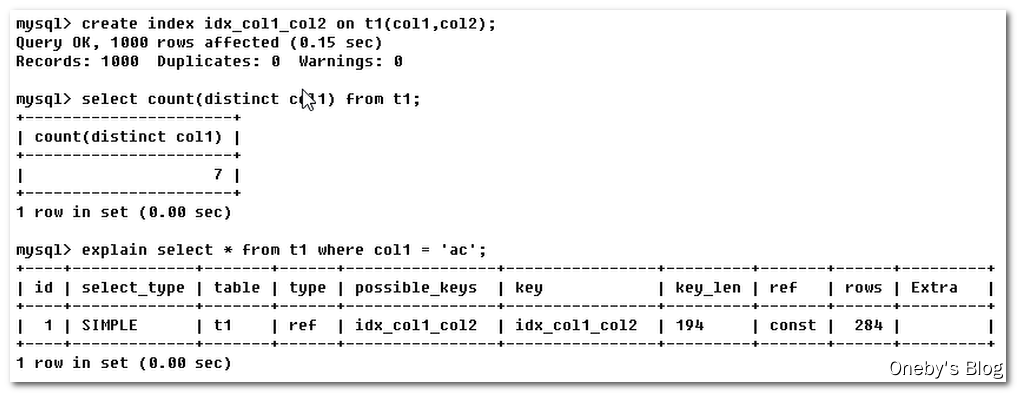
range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引一般就是在你的where语句中出现了between、<、>、in等的查询这种范围扫描索引扫描比全表扫描要好,因为他只需要开始索引的某一点,而结束于另一点,不用扫描全部索引
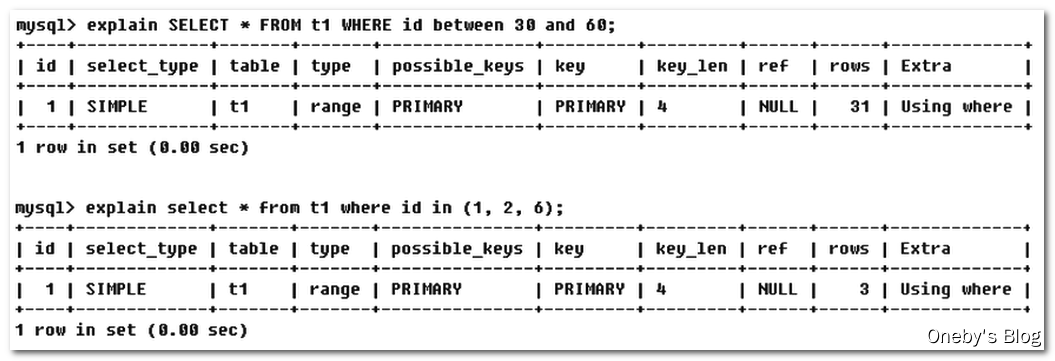
index:Full Index Scan,index与ALL区别为index类型只遍历索引树。这通常比ALL快,因为索引文件通常比数据文件小。(也就是说虽然all和index都是读全表,但index是从索引中读取的,而all是从硬盘数据库文件中读的)

all:FullTable Scan,将遍历全表以找到匹配的行(全表扫描)

备注:一般来说,得保证查询只是达到range级别,最好达到ref
possible_keys
- 显示可能应用在这张表中的索引,一个或多个
- 若查询涉及的字段上存在索引,则该索引将被列出,但不一定被查询实际使用
key
- 实际使用的索引,如果为null,则没有使用索引
- 若查询中使用了覆盖索引,则该索引仅出现在key列表中
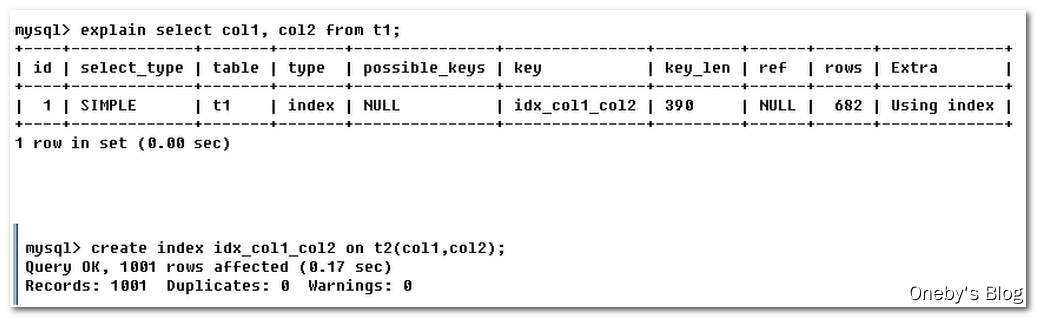
key_len
- 表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好
- key_len显示的值为索引最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的

在查看MYSQL执行计划的时候,有一列 key_len 表示索引中使用的字节数,我们可以用它来判断使用了几个索引,我们使用最常用的utf-8编码按如下几点可以进行判断: 1、字段类型 int为4个,date为3,datetime为4,char(n)为3n,varchar(n)为3n+2(更多字段类型自己测试下就知道了) 2、如果字段可为 null,则需要额外再加1
按如上方法计算: char(1)可为空的情况下key_len=4,不可为空的情况下key_len=3 varchar(100)可为空的情况下key_len=302,不可为空的情况下key_len=302+1=303
再假设一个字段char(1) not null 和一个字段int not null 进行了组合索引,那么当你写的SQL的执行计划中的 key_len=3+4=7 时,则可以说明这2个字段在这个SQL查询中都使用了索引。
所以我们就可以根据执行计划中的 key_len 的长度来判断使用了几个索引了。
补充: possible_keys:显示当前SQL可能应用到的索引,一个或多个。查询涉及到的字段上若存在索引,则该索引将会被列出,但不一定被当前查询实际使用。 key:实际使用的索引,若为null,则没有使用到索引。(可能因为 ①没建立索引;②建立了索引但没有使用上)。查询中若使用了覆盖索引,则该索引仅出现在key列表中。
ref
- 显示索引哪一列被使用了,如果可能的话,最好是一个常数。哪些列或常量被用于查找索引列上的值
- 由key_len可知t1表的索引idx_col1_col2被充分使用,t1表的col1匹配t2表的col1,t1表的col2匹配了一个常量,即’ac’

rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数

Extra:包含不适合在其他列中显示但十分重要的额外信息
Using filesort(文件排序):
MySQL中无法利用索引完成排序操作成为“文件排序” 说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取 出现 Using filesort 不好(九死一生),需要尽快优化 SQL 示例中第一个查询只使用了 col1 和 col3,原有索引派不上用场,所以进行了外部文件排序 示例中第二个查询使用了 col1、col2 和 col3,原有索引派上用场,无需进行文件排序
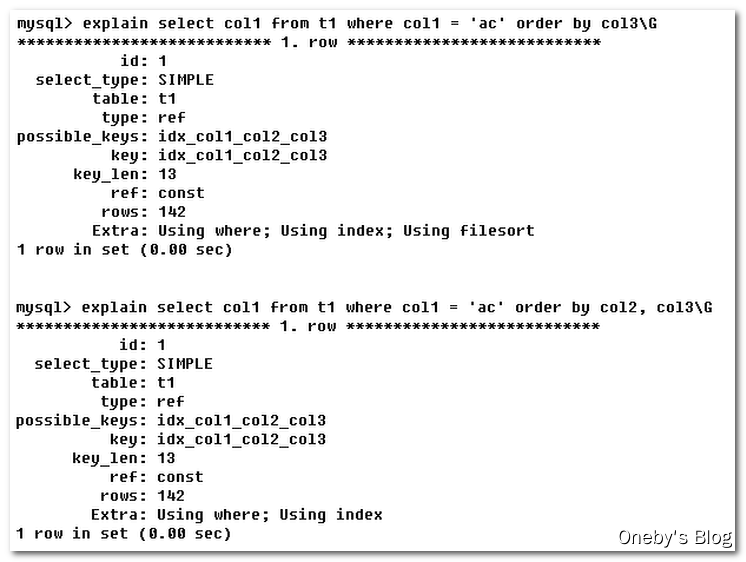
Using temporary(创建临时表):
使用了临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序 order by 和分组查询 group by 出现 Using temporary 超级不好(十死无生),需要立即优化 SQL 示例中第一个查询只使用了 col1,原有索引派不上用场,所以创建了临时表进行分组 示例中第二个查询使用了 col1、col2,原有索引派上用场,无需创建临时表
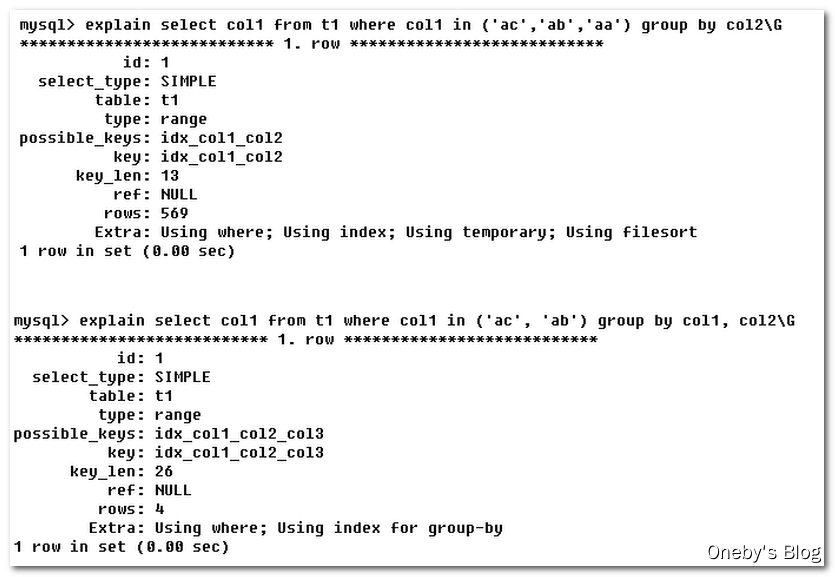
Using index(覆盖索引
- 表示相应的select操作中使用了覆盖索引(Coveing Index),避免访问了表的数据行,效率不错!
- 如果同时出现using where,表明索引被用来执行索引键值的查找
- 如果没有同时出现using where,表明索引用来读取数据而非执行查找动作

理解:表示要查找的数据刚好是这张表索引表中的数据,直接通过索引进行查询数据,不经过表
**Using where:**表明使用where过滤
**Using join buffer:**表明使用了连接缓存
impossible where : where 子句的值总是false,不能用来获取任何元组
select tables optimized away:在没有GROUPBY子句的情况下,基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。
distinct:优化distinct,在找到第一匹配的元组后即停止找同样值的工作
11.10 单表索引优化分析
1 单表索引优化
建表sql
建表 SQL
CREATE TABLE IF NOT EXISTS article(
id INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
author_id INT(10) UNSIGNED NOT NULL,
category_id INT(10) UNSIGNED NOT NULL,
views INT(10) UNSIGNED NOT NULL,
comments INT(10) UNSIGNED NOT NULL,
title VARCHAR(255) NOT NULL,
content TEXT NOT NULL
);
INSERT INTO article(author_id,category_id,views,comments,title,content)
VALUES
(1,1,1,1,'1','1'),
(2,2,2,2,'2','2'),
(1,1,3,3,'3','3');
表中的测试数据
查询案例
- 查询category_id为1且comments 大于1的情况下,views最多的article_id。
mysql> SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
+----+-----------+
| id | author_id |
+----+-----------+
| 3 | 1 |
+----+-----------+
1 row in set (0.00 sec)
使用explain分析SQL语句的执行效率:
EXPLAIN SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
mysql> EXPLAIN SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
+----+-------------+---------+------+---------------+------+---------+------+------+-----------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+------+---------------+------+---------+------+------+-----------------------------+
| 1 | SIMPLE | article | ALL | NULL | NULL | NULL | NULL | 3 | Using where; Using filesort |
+----+-------------+---------+------+---------------+------+---------+------+------+-----------------------------+
1 row in set (0.00 sec)
结论:
- 很显然,type是ALL,即最坏的情况。
- Extra 里还出现了Using filesort,也是最坏的情况。
- 优化是必须的。
开始优化
创建索引的SQL命令
- 在 category_id 列、comments 列和 views 列上建立联合索引
# ALTER TABLE article ADD INDEX idx_article_ccv('category_id', 'comments', 'views');
create index idx_article_ccv on article(category_id, comments, views);
mysql> SHOW INDEX FROM article;
+---------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| article | 0 | PRIMARY | 1 | id | A | 3 | NULL | NULL | | BTREE | | |
| article | 1 | idx_article_ccv | 1 | category_id | A | 3 | NULL | NULL | | BTREE | | |
| article | 1 | idx_article_ccv | 2 | comments | A | 3 | NULL | NULL | | BTREE | | |
| article | 1 | idx_article_ccv | 3 | views | A | 3 | NULL | NULL | | BTREE | | |
+---------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
4 rows in set (0.00 sec)
- 再次执行查询:type变成了range,这是可以忍受的。但是extra里使用Using filesort仍是无法接受的。
mysql> EXPLAIN SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
+----+-------------+---------+-------+-----------------+-----------------+---------+------+------+---------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+-------+-----------------+-----------------+---------+------+------+---------------------------------------+
| 1 | SIMPLE | article | range | idx_article_ccv | idx_article_ccv | 8 | NULL | 1 | Using index condition; Using filesort |
+----+-------------+---------+-------+-----------------+-----------------+---------+------+------+---------------------------------------+
1 row in set (0.00 sec)
分析:
但是我们已经建立了索引,为啥没用呢? 这是因为按照B+Tree索引的工作原理,先排序 category_id,如果遇到相同的 category_id 则再排序comments,如果遇到相同的 comments 则再排序 views。 当comments字段在联合索引里处于中间位置时,因为comments>1条件是一个范围值(所谓 range),MySQL 无法利用索引再对后面的views部分进行检索,即 range 类型查询字段后面的索引无效。 将查询条件中的 comments > 1 改为 comments = 1 ,发现 Use filesort 神奇地消失了,从这点可以验证:范围后的索引会导致索引失效
mysql> EXPLAIN SELECT id, author_id FROM article WHERE category_id = 1 AND comments = 1 ORDER BY views DESC LIMIT 1;
+----+-------------+---------+------+-----------------+-----------------+---------+-------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+------+-----------------+-----------------+---------+-------------+------+-------------+
| 1 | SIMPLE | article | ref | idx_article_ccv | idx_article_ccv | 8 | const,const | 1 | Using where |
+----+-------------+---------+------+-----------------+-----------------+---------+-------------+------+-------------+
1 row in set (0.00 sec)
删除索引再次优化
创建索引的 SQL 指令
ALTER TABLE article ADD INDEX idx_article_ccv('category_id', 'views');
create index idx_article_ccv on article(category_id, views); 由于 range 后(comments > 1)的索引会失效,这次我们建立索引时,直接抛弃 comments 列,先利用 category_id 和 views 的联合索引查询所需要的数据,再从其中取出 comments > 1 的数据(我觉着应该是这样的)
mysql> create index idx_article_ccv on article(category_id, views);
Query OK, 0 rows affected (0.30 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> SHOW INDEX FROM article;
+---------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| article | 0 | PRIMARY | 1 | id | A | 3 | NULL | NULL | | BTREE | | |
| article | 1 | idx_article_ccv | 1 | category_id | A | 3 | NULL | NULL | | BTREE | | |
| article | 1 | idx_article_ccv | 2 | views | A | 3 | NULL | NULL | | BTREE | | |
+---------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
3 rows in set (0.00 sec)
再次执行查询:可以看到,type变为了ref,Extra中的Using filesort也消失了,结果非常理想
ysql> EXPLAIN SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
+----+-------------+---------+------+-----------------+-----------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+------+-----------------+-----------------+---------+-------+------+-------------+
| 1 | SIMPLE | article | ref | idx_article_ccv | idx_article_ccv | 4 | const | 2 | Using where |
+----+-------------+---------+------+-----------------+-----------------+---------+-------+------+-------------+
1 row in set (0.00 sec)
为了不影响之后的测试,删除该表的 idx_article_ccv 索引
mysql> DROP INDEX idx_article_ccv ON article;
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> SHOW INDEX FROM article;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| article | 0 | PRIMARY | 1 | id | A | 3 | NULL | NULL | | BTREE | | |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.01 sec)
2 双表查询优化
mysql> EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;
+----+-------------+-------+------+---------------+------+---------+------+------+----------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+----------------------------------------------------+
| 1 | SIMPLE | class | ALL | NULL | NULL | NULL | NULL | 21 | NULL |
| 1 | SIMPLE | book | ALL | NULL | NULL | NULL | NULL | 20 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------+---------------+------+---------+------+------+----------------------------------------------------+
2 rows in set (0.00 sec)
结论:
- type 有 All ,rows 为表中数据总行数,说明 class 和 book 进行了全表检索
- 即每次 class 表对 book 表进行左外连接时,都需要在 book 表中进行一次全表检索
添加索引:在右表添加索引,添加索引的SQL指令
ALTER TABLE 'book' ADD INDEX Y ('card');
- 测试结果:可以看到第二行的type变为了ref,rows也变成了优化比较明显。
mysql> EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;
+----+-------------+-------+------+---------------+------+---------+-----------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+-----------------+------+-------------+
| 1 | SIMPLE | class | ALL | NULL | NULL | NULL | NULL | 21 | NULL |
| 1 | SIMPLE | book | ref | Y | Y | 4 | db01.class.card | 1 | Using index |
+----+-------------+-------+------+---------------+------+---------+-----------------+------+-------------+
2 rows in set (0.00 sec)
分析:
- 这是由左连接特性决定的。LEFT JOIN条件用于确定如何从右表搜索行,左边一定都有,所以右边是我们的关键点,一定需要建立索引。
- 左表连接右表,则需要拿着左表的数据去右表里面查,索引需要在右表中建立索引
如果把索引建立在左表上面,没能充分利用索引
mysql> EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;
+----+-------------+-------+-------+---------------+------+---------+------+------+----------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+------+---------+------+------+----------------------------------------------------+
| 1 | SIMPLE | class | index | NULL | X | 4 | NULL | 21 | Using index |
| 1 | SIMPLE | book | ALL | NULL | NULL | NULL | NULL | 20 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+-------+---------------+------+---------+------+------+----------------------------------------------------+
2 rows in set (0.00 sec)
分析: 这是因为RIGHT JOIN条件用于确定如何从左表搜索行,右边一定都有,所以左边是我们的关键点,一定需要建立索引。 class RIGHT JOIN book :book 里面的数据一定存在于结果集中,我们需要拿着 book 表中的数据,去 class 表中搜索,所以索引需要建立在 class 表中 为了不影响之后的测试,删除该表的 idx_article_ccv 索引
尽可能减少Join语句中的NestedLoop的循环总次数; 永远用小结果集驱动大的结果集(在大结果集中建立索引,在小结果集中遍历全表); 优先优化NestedLoop的内层循环; 保证Join语句中被驱动表上Join条件字段已经被索引; 当无法保证被驱动表的Join条件字段被索引且内存资源充足的前提下,不要太吝惜JoinBuffer的设置;
11.11 索引优化失效
mysql> EXPLAIN SELECT * FROM staffs WHERE name is not null; +—-+————-+——–+——+————————-+——+———+——+——+————-+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +—-+————-+——–+——+————————-+——+———+——+——+————-+ | 1 | SIMPLE | staffs | ALL | index_staffs_nameAgePos | NULL | NULL | NULL | 3 | Using where | +—-+————-+——–+——+————————-+——+———+——+——+————-+ 1 row in set (0.00 sec)
INSERT INTO tbl_user(`name`,`age`,`email`)VALUES('1aa1',21,'a@163.com'); INSERT INTO tbl_user(`name`,`age`,`email`)VALUES('2bb2',23,'b@163.com'); INSERT INTO tbl_user(`name`,`age`,`email`)VALUES('3cc3',24,'c@163.com'); INSERT INTO tbl_user(`name`,`age`,`email`)VALUES('4dd4',26,'d@163.com');
EXPLAIN SELECT name FROM tbl_user WHERE NAME LIKE '%aa%'; EXPLAIN SELECT age FROM tbl_user WHERE NAME LIKE '%aa%';
EXPLAIN SELECT id FROM tbl_user WHERE NAME LIKE '%aa%'; EXPLAIN SELECT id, name FROM tbl_user WHERE NAME LIKE '%aa%'; EXPLAIN SELECT id, age FROM tbl_user WHERE NAME LIKE '%aa%'; EXPLAIN SELECT id, name, age FROM tbl_user WHERE NAME LIKE '%aa%';
mysql> EXPLAIN SELECT id, name, age, email FROM tbl_user WHERE NAME LIKE '%aa%'; +—-+————-+———-+——+—————+——+———+——+——+————-+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +—-+————-+———-+——+—————+——+———+——+——+————-+ | 1 | SIMPLE | tbl_user | ALL | NULL | NULL | NULL | NULL | 4 | Using where | +—-+————-+———-+——+—————+——+———+——+——+————-+ 1 row in set (0.00 sec)
11.12 索引优化面试题
create index idx_test03_c1234 on test03(c1,c2,c3,c4);
mysql> EXPLAIN SELECT * FROM test03 WHERE c1=‘a1’ AND c2 like ‘%kk%’ AND c3=‘a3’; +—-+————-+——–+——+——————+——————+———+——-+——+———————–+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +—-+————-+——–+——+——————+——————+———+——-+——+———————–+ | 1 | SIMPLE | test03 | ref | idx_test03_c1234 | idx_test03_c1234 | 31 | const | 1 | Using index condition | +—-+————-+——–+——+——————+——————+———+——-+——+———————–+ 1 row in set (0.00 sec)
12 查询截取优化
1、查询优化
1.1、MySQL 优化原则
mysql 的调优大纲
- 慢查询的开启并捕获
- explain+慢SQL分析
- show profile查询SQL在Mysql服务器里面的执行细节和生命周期情况
- SQL数据库服务器的参数调优
永远小表驱动大表,类似嵌套循环 Nested Loop
- EXISTS 语法:
SELECT ... FROM table WHERE EXISTS(subquery)- 该语法可以理解为:将查询的数据,放到子查询中做条件验证,根据验证结果(TRUE或FALSE)来决定主查询的数据结果是否得以保留。
- EXISTS(subquery) 只返回TRUE或FALSE,因此子查询中的
SELECT *也可以是SELECT 1或其他,官方说法是实际执行时会忽略SELECT清单,因此没有区别 - EXISTS子查询的实际执行过程可能经过了优化而不是我们理解上的逐条对比,如果担忧效率问题,可进行实际检验以确定是否有效率问题。
- EXISTS子查询往往也可以用条件表达式、其他子查询或者JOIN来替代,何种最优需要具体问题具体分析

结论:
- 永远记住小表驱动大表
- 当 B 表数据集小于 A 表数据集时,使用 in
- 当 A 表数据集小于 B 表数据集时,使用 exist
in 和 exists 的用法
- tbl_emp 表和 tbl_dept 表
mysql> select * from tbl_emp;
+----+------+--------+
| id | NAME | deptId |
+----+------+--------+
| 1 | z3 | 1 |
| 2 | z4 | 1 |
| 3 | z5 | 1 |
| 4 | w5 | 2 |
| 5 | w6 | 2 |
| 6 | s7 | 3 |
| 7 | s8 | 4 |
| 8 | s9 | 51 |
+----+------+--------+
8 rows in set (0.00 sec)
mysql> select * from tbl_dept;
+----+----------+--------+
| id | deptName | locAdd |
+----+----------+--------+
| 1 | RD | 11 |
| 2 | HR | 12 |
| 3 | MK | 13 |
| 4 | MIS | 14 |
| 5 | FD | 15 |
+----+----------+--------+
5 rows in set (0.00 sec)
- in 的写法
mysql> select * from tbl_emp e where e.deptId in (select id from tbl_dept);
+----+------+--------+
| id | NAME | deptId |
+----+------+--------+
| 1 | z3 | 1 |
| 2 | z4 | 1 |
| 3 | z5 | 1 |
| 4 | w5 | 2 |
| 5 | w6 | 2 |
| 6 | s7 | 3 |
| 7 | s8 | 4 |
+----+------+--------+
7 rows in set (0.00 sec)
- exists 的写法
mysql> select * from tbl_emp e where exists (select 1 from tbl_dept d where e.deptId = d.id);
+----+------+--------+
| id | NAME | deptId |
+----+------+--------+
| 1 | z3 | 1 |
| 2 | z4 | 1 |
| 3 | z5 | 1 |
| 4 | w5 | 2 |
| 5 | w6 | 2 |
| 6 | s7 | 3 |
| 7 | s8 | 4 |
+----+------+--------+
7 rows in set (0.00 sec)
1.2、ORDER BY 优化
ORDER BY子句,尽量使用Index方式排序,避免使用FileSort方式排序
创建表
- 建表 SQL
create table tblA(
#id int primary key not null auto_increment,
age int,
birth timestamp not null
);
insert into tblA(age, birth) values(22, now());
insert into tblA(age, birth) values(23, now());
insert into tblA(age, birth) values(24, now());
create index idx_A_ageBirth on tblA(age, birth);
- tblA 表中的测试数据
mysql> select * from tblA;
+------+---------------------+
| age | birth |
+------+---------------------+
| 22 | 2020-08-05 10:36:32 |
| 23 | 2020-08-05 10:36:32 |
| 24 | 2020-08-05 10:36:32 |
+------+---------------------+
3 rows in set (0.00 sec)
- tbl 中的索引
mysql> SHOW INDEX FROM tblA;
+-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| tblA | 1 | idx_A_ageBirth | 1 | age | A | 3 | NULL | NULL | YES | BTREE | | |
| tblA | 1 | idx_A_ageBirth | 2 | birth | A | 3 | NULL | NULL | | BTREE | | |
+-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec)
CASE1:能使用索引进行排序的情况
- 只有带头大哥 age
mysql> EXPLAIN SELECT * FROM tblA where age>20 order by age;
+----+-------------+-------+-------+----------------+----------------+---------+------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+----------------+----------------+---------+------+------+--------------------------+
| 1 | SIMPLE | tblA | index | idx_A_ageBirth | idx_A_ageBirth | 9 | NULL | 3 | Using where; Using index |
+----+-------------+-------+-------+----------------+----------------+---------+------+------+--------------------------+
1 row in set (0.01 sec)
mysql> EXPLAIN SELECT * FROM tblA where birth>'2016-01-28 00:00:00' order by age;
+----+-------------+-------+-------+---------------+----------------+---------+------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------------+---------+------+------+--------------------------+
| 1 | SIMPLE | tblA | index | NULL | idx_A_ageBirth | 9 | NULL | 3 | Using where; Using index |
+----+-------------+-------+-------+---------------+----------------+---------+------+------+--------------------------+
1 row in set (0.00 sec)
- 带头大哥 age + 小弟 birth
mysql> EXPLAIN SELECT * FROM tblA where age>20 order by age,birth;
+----+-------------+-------+-------+----------------+----------------+---------+------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+----------------+----------------+---------+------+------+--------------------------+
| 1 | SIMPLE | tblA | index | idx_A_ageBirth | idx_A_ageBirth | 9 | NULL | 3 | Using where; Using index |
+----+-------------+-------+-------+----------------+----------------+---------+------+------+--------------------------+
1 row in set (0.00 sec)
- mysql 默认升序排列,全升序或者全降序,都扛得住
mysql> EXPLAIN SELECT * FROM tblA ORDER BY age ASC, birth ASC;
+----+-------------+-------+-------+---------------+----------------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------------+---------+------+------+-------------+
| 1 | SIMPLE | tblA | index | NULL | idx_A_ageBirth | 9 | NULL | 3 | Using index |
+----+-------------+-------+-------+---------------+----------------+---------+------+------+-------------+
1 row in set (0.00 sec)
mysql> EXPLAIN SELECT * FROM tblA ORDER BY age DESC, birth DESC;
+----+-------------+-------+-------+---------------+----------------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------------+---------+------+------+-------------+
| 1 | SIMPLE | tblA | index | NULL | idx_A_ageBirth | 9 | NULL | 3 | Using index |
+----+-------------+-------+-------+---------------+----------------+---------+------+------+-------------+
1 row in set (0.01 sec)
CASE2:不能使用索引进行排序的情况
- 带头大哥 age 挂了
mysql> EXPLAIN SELECT * FROM tblA where age>20 order by birth;
+----+-------------+-------+-------+----------------+----------------+---------+------+------+------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+----------------+----------------+---------+------+------+------------------------------------------+
| 1 | SIMPLE | tblA | index | idx_A_ageBirth | idx_A_ageBirth | 9 | NULL | 3 | Using where; Using index; Using filesort |
+----+-------------+-------+-------+----------------+----------------+---------+------+------+------------------------------------------+
1 row in set (0.01 sec)
- 小弟 birth 居然敢在带头大哥 age 前面
mysql> EXPLAIN SELECT * FROM tblA where age>20 order by birth,age;
+----+-------------+-------+-------+----------------+----------------+---------+------+------+------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+----------------+----------------+---------+------+------+------------------------------------------+
| 1 | SIMPLE | tblA | index | idx_A_ageBirth | idx_A_ageBirth | 9 | NULL | 3 | Using where; Using index; Using filesort |
+----+-------------+-------+-------+----------------+----------------+---------+------+------+------------------------------------------+
1 row in set (0.00 sec)
- mysql 默认升序排列,如果全升序或者全降序,都 ok ,但是一升一降 mysql 就扛不住了
mysql> EXPLAIN SELECT * FROM tblA ORDER BY age ASC, birth DESC;
+----+-------------+-------+-------+---------------+----------------+---------+------+------+-----------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------------+---------+------+------+-----------------------------+
| 1 | SIMPLE | tblA | index | NULL | idx_A_ageBirth | 9 | NULL | 3 | Using index; Using filesort |
+----+-------------+-------+-------+---------------+----------------+---------+------+------+-----------------------------+
1 row in set (0.00 sec)
结论
- MySQL支持二种方式的排序,FileSort和Index,Index效率高,它指MySQL扫描索引本身完成排序,FileSort方式效率较低。
- ORDER BY满足两情况(最佳左前缀原则),会使用Index方式排序
- ORDER BY语句使用索引最左前列
- 使用where子句与OrderBy子句条件列组合满足索引最左前列
- 尽可能在索引列上完成排序操作,遵照索引建的最佳左前缀
如果未在索引列上完成排序,mysql 会启动 filesort 的两种算法:双路排序和单路排序
- 双路排序
- MySQL4.1之前是使用双路排序,字面意思是两次扫描磁盘,最终得到数据。读取行指针和将要进行orderby操作的列,对他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取对应的数据传输
- 从磁盘取排序字段,在buffer进行排序,再从磁盘取其他字段。
- 单路排序
- 取一批数据,要对磁盘进行两次扫描,众所周知,I/O是很耗时的,所以在mysql4.1之后,出现了改进的算法,就是单路排序。
- 从磁盘读取查询需要的所有列,按照将要进行orderby的列,在sort buffer对它们进行排序,然后扫描排序后的列表进行输出,它的效率更快一些,避免了第二次读取数据,并且把随机IO变成顺序IO,但是它会使用更多的空间,因为它把每一行都保存在内存中了。
- 结论及引申出的问题:
- 由于单路是改进的算法,总体而言好过双路
- 在sort_buffer中,方法B比方法A要多占用很多空间,因为方法B是把所有字段都取出,所以有可能取出的数据的总大小超出了sort_buffer的容量,导致每次只能取sort_buffer容量大小的数据,进行排序(创建tmp文件,多路合并),排完再取取sort_buffer容量大小,再排…… 从而会导致多次I/O。
- 结论:本来想省一次I/O操作,反而导致了大量的/O操作,反而得不偿失。
- 更深层次的优化策略:
- 增大sort_buffer_size参数的设置
- 增大max_length_for_sort_data参数的设置
遵循如下规则,可提高Order By的速度
- Order by时select *是一个大忌,只Query需要的字段,这点非常重要。在这里的影响是:
- 当Query的字段大小总和小于max_length_for_sort_data,而且排序字段不是TEXT|BLOB类型时,会用改进后的算法——单路排序,否则用老算法——多路排序。
- 两种算法的数据都有可能超出sort_buffer的容量,超出之后,会创建tmp文件进行合并排序,导致多次I/O,但是用单路排序算法的风险会更大一些,所以要提高sort_buffer_size。
- 尝试提高 sort_buffer_size不管用哪种算法,提高这个参数都会提高效率,当然,要根据系统的能力去提高,因为这个参数是针对每个进程的
- 尝试提高max_length_for_sort_data提高这个参数,会增加用改进算法的概率。但是如果设的太高,数据总容量超出sort_buffer_size的概率就增大,明显症状是高的磁盘I/O活动和低的处理器使用率。
Order By 排序索引优化的总结

1.3、GROUP BY 优化
group by关键字优化
- group by实质是先排序后进行分组,遵照索引的最佳左前缀
- 当无法使用索引列,增大max_length_for_sort_data参数的设置+增大sort_buffer_size参数的设置
- where高于having,能写在where限定的条件就不要去having限定了
- 其余的规则均和 order by 一致
2、慢查询日志
2.1、慢查询日志介绍
慢查询日志是什么?
- MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。
- long_query_time的默认值为10,意思是运行10秒以上的SQL语句会被记录下来
- 由他来查看哪些SQL超出了我们的最大忍耐时间值,比如一条sql执行超过5秒钟,我们就算慢SQL,希望能收集超过5秒的sql,结合之前explain进行全面分析。
2.2、慢查询日志开启
怎么玩?
说明:
- 默认情况下,MySQL数据库没有开启慢查询日志,需要我们手动来设置这个参数。
- 当然,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志记录写入文件
查看是否开启及如何开启
- 查看慢查询日志是否开启:
- 默认情况下slow_query_log的值为OFF,表示慢查询日志是禁用的
- 可以通过设置slow_query_log的值来开启
- 通过
SHOW VARIABLES LIKE '%slow_query_log%';查看 mysql 的慢查询日志是否开启
mysql> SHOW VARIABLES LIKE '%slow_query_log%';
+---------------------+-------------------------------+
| Variable_name | Value |
+---------------------+-------------------------------+
| slow_query_log | OFF |
| slow_query_log_file | /var/lib/mysql/Heygo-slow.log |
+---------------------+-------------------------------+
2 rows in set (0.00 sec)
- 如何开启开启慢查询日志:
set global slow_query_log = 1;开启慢查询日志- 使用
set global slow_query_log=1开启了慢查询日志只对当前数据库生效,如果MySQL重启后则会失效。
mysql> set global slow_query_log = 1;
Query OK, 0 rows affected (0.07 sec)
mysql> SHOW VARIABLES LIKE '%slow_query_log%';
+---------------------+-------------------------------+
| Variable_name | Value |
+---------------------+-------------------------------+
| slow_query_log | ON |
| slow_query_log_file | /var/lib/mysql/Heygo-slow.log |
+---------------------+-------------------------------+
2 rows in set (0.00 sec)
-
如果要永久生效,就必须修改配置文件my.cnf(其它系统变量也是如此)
- 修改my.cnf文件,[mysqld]下增加或修改参数:slow_query_log和slow_query_log_file后,然后重启MySQL服务器。
- 也即将如下两行配置进my.cnf文件
[mysqld] slow_query_log =1 slow_query_log_file=/var/lib/mysql/Heygo-slow.log- 关于慢查询的参数slow_query_log_file,它指定慢查询日志文件的存放路径,系统默认会给一个缺省的文件host_name-slow.log(如果没有指定参数slow_query_log_file的话)
那么开启慢查询日志后,什么样的SQL参会记录到慢查询里面?
- 这个是由参数long_query_time控制,默认情况下long_query_time的值为10秒,命令:
SHOW VARIABLES LIKE 'long_query_time%';查看慢 SQL 的阈值
mysql> SHOW VARIABLES LIKE 'long_query_time%';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set (0.01 sec)
- 可以使用命令修改,也可以在my.cnf参数里面修改。
- 假如运行时间正好等于long_query_time的情况,并不会被记录下来。也就是说,在mysql源码里是判断大于long_query_time,而非大于等于。
2.3、慢查询日志示例
案例讲解
- 查看慢 SQL 的阈值时间,默认阈值时间为 10s
mysql> SHOW VARIABLES LIKE 'long_query_time%';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set (0.00 sec)
- 设置慢 SQL 的阈值时间,我们将其设置为 3s
mysql> set global long_query_time=3;
Query OK, 0 rows affected (0.00 sec)
- 为什么设置后阈值时间没变?
- 需要重新连接或者新开一个回话才能看到修改值。
- 查看全局的 long_query_time 值:
show global variables like 'long_query_time';发现已经生效
mysql> set global long_query_time=3;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW VARIABLES LIKE 'long_query_time%';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set (0.00 sec)
mysql> show global variables like 'long_query_time';
+-----------------+----------+
| Variable_name | Value |
+-----------------+----------+
| long_query_time | 3.000000 |
+-----------------+----------+
1 row in set (0.00 sec)
-
记录慢 SQL 以供后续分析
- 怼个 select sleep(4); 超过 3s ,肯定会被记录到日志中
mysql> select sleep(4); +----------+ | sleep(4) | +----------+ | 0 | +----------+ 1 row in set (4.00 sec)- 慢查询日志文件在 /var/lib/mysql/ 下,后缀为 -slow.log
[root@Heygo mysql]# cd /var/lib/mysql/ [root@Heygo mysql]# ls -l 总用量 176156 -rw-rw----. 1 mysql mysql 56 8月 3 19:08 auto.cnf drwx------. 2 mysql mysql 4096 8月 5 10:36 db01 -rw-rw----. 1 mysql mysql 7289 8月 3 22:38 Heygo.err -rw-rw----. 1 mysql mysql 371 8月 5 12:58 Heygo-slow.log -rw-rw----. 1 mysql mysql 79691776 8月 5 10:36 ibdata1 -rw-rw----. 1 mysql mysql 50331648 8月 5 10:36 ib_logfile0 -rw-rw----. 1 mysql mysql 50331648 8月 3 19:08 ib_logfile1 drwx------. 2 mysql mysql 4096 8月 3 19:08 mysql srwxrwxrwx. 1 mysql mysql 0 8月 3 22:38 mysql.sock drwx------. 2 mysql mysql 4096 8月 3 19:08 performance_schema- 查看慢查询日志中的内容
[root@Heygo mysql]# cat Heygo-slow.log /usr/sbin/mysqld, Version: 5.6.49 (MySQL Community Server (GPL)). started with: Tcp port: 3306 Unix socket: /var/lib/mysql/mysql.sock Time Id Command Argument # Time: 200805 12:58:01 # User@Host: root[root] @ localhost [] Id: 11 # Query_time: 4.000424 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0 SET timestamp=1596603481; select sleep(4);- 查询当前系统中有多少条慢查询记录:
show global status like '%Slow_queries%';
mysql> show global status like '%Slow_queries%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Slow_queries | 1 |
+---------------+-------+
1 row in set (0.00 sec)
配置版的慢查询日志
在 /etc/my.cnf 文件的 [mysqld] 节点下配置
slow_query_log=1;
slow_query_log_file=/var/lib/mysql/Heygo-slow.log
long_query_time=3;
log_output=FILE
日志分析命令 mysqldumpslow
mysqldumpslow是什么?
在生产环境中,如果要手工分析日志,查找、分析SQL,显然是个体力活,MySQL提供了日志分析工具mysqldumpslow。
查看 mysqldumpslow的帮助信息
[root@Heygo mysql]# mysqldumpslow --help
Usage: mysqldumpslow [ OPTS... ] [ LOGS... ]
Parse and summarize the MySQL slow query log. Options are
--verbose verbose
--debug debug
--help write this text to standard output
-v verbose
-d debug
-s ORDER what to sort by (al, at, ar, c, l, r, t), 'at' is default
al: average lock time
ar: average rows sent
at: average query time
c: count
l: lock time
r: rows sent
t: query time
-r reverse the sort order (largest last instead of first)
-t NUM just show the top n queries
-a don't abstract all numbers to N and strings to 'S'
-n NUM abstract numbers with at least n digits within names
-g PATTERN grep: only consider stmts that include this string
-h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard),
default is '*', i.e. match all
-i NAME name of server instance (if using mysql.server startup script)
-l don't subtract lock time from total time
mysqldumpshow 参数解释
- s:是表示按何种方式排序
- c:访问次数
- l:锁定时间
- r:返回记录
- t:查询时间
- al:平均锁定时间
- ar:平均返回记录数
- at:平均查询时间
- t:即为返回前面多少条的数据
- g:后边搭配一个正则匹配模式,大小写不敏感的
常用参数手册
-
得到返回记录集最多的10个SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/Heygo-slow.log -
得到访问次数最多的10个SQL
mysqldumpslow -s c- t 10/var/lib/mysql/Heygo-slow.log -
得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/Heygo-slow.log -
另外建议在使用这些命令时结合 | 和more使用,否则有可能出现爆屏情况
mysqldumpslow -s r -t 10 /var/lib/mysql/Heygo-slow.log | more
3、批量数据脚本
创建表
- 建表 SQL
CREATE TABLE dept
(
deptno int unsigned primary key auto_increment,
dname varchar(20) not null default "",
loc varchar(8) not null default ""
)ENGINE=INNODB DEFAULT CHARSET=utf8;
CREATE TABLE emp
(
id int unsigned primary key auto_increment,
empno mediumint unsigned not null default 0,
ename varchar(20) not null default "",
job varchar(9) not null default "",
mgr mediumint unsigned not null default 0,
hiredate date not null,
sal decimal(7,2) not null,
comm decimal(7,2) not null,
deptno mediumint unsigned not null default 0
)ENGINE=INNODB DEFAULT CHARSET=utf8;
设置参数
-
创建函数,假如报错:This function has none of DETERMINISTIC………
-
由于开启过慢查询日志,因为我们开启了bin-log,我们就必须为我们的function指定一个参数。
log_bin_trust_function_creators = OFF,默认必须为 function 传递一个参数
mysql> show variables like 'log_bin_trust_function_creators'; +---------------------------------+-------+ | Variable_name | Value | +---------------------------------+-------+ | log_bin_trust_function_creators | OFF | +---------------------------------+-------+ 1 row in set (0.00 sec)- 通过
set global log_bin_trust_function_creators=1;我们可以不用为 function 传参
mysql> set global log_bin_trust_function_creators=1; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'log_bin_trust_function_creators'; +---------------------------------+-------+ | Variable_name | Value | +---------------------------------+-------+ | log_bin_trust_function_creators | ON | +---------------------------------+-------+ 1 row in set (0.00 sec) -
这样添加了参数以后,如果mysqld重启,上述参数又会消失,永久方法在配置文件中修改‘
- windows下:my.ini –> [mysqld] 节点下加上
log_bin_trust_function_creators=1 - linux下:/etc/my.cnf –> [mysqld] 节点下加上
log_bin_trust_function_creators=1
- windows下:my.ini –> [mysqld] 节点下加上
创建函数,保证每条数据都不同
- 随机产生字符串的函数
delimiter $$ # 两个 $$ 表示结束
create function rand_string(n int) returns varchar(255)
begin
declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyz';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
set return_str = concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i=i+1;
end while;
return return_str;
end $$
- 随机产生部门编号的函数
delimiter $$
create function rand_num() returns int(5)
begin
declare i int default 0;
set i=floor(100+rand()*10);
return i;
end $$
创建存储过程
- 创建往emp表中插入数据的存储过程
delimiter $$
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i+1;
insert into emp(empno,ename,job,mgr,hiredate,sal,comm,deptno) values((start+i),rand_string(6),'salesman',0001,curdate(),2000,400,rand_num());
until i=max_num
end repeat;
commit;
end $$
- 创建往dept表中插入数据的存储过程
delimiter $$
create procedure insert_dept(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i+1;
insert into dept(deptno,dname,loc) values((start+i),rand_string(10),rand_string(8));
until i=max_num
end repeat;
commit;
end $$
调用存储过程
- 向 dept 表中插入 10 条记录
DELIMITER ;
CALL insert_dept(100, 10);
mysql> select * from dept;
+--------+---------+--------+
| deptno | dname | loc |
+--------+---------+--------+
| 101 | aowswej | syrlhb |
| 102 | uvneag | pup |
| 103 | lps | iudgy |
| 104 | jipvsk | ihytx |
| 105 | hrpzhiv | vjb |
| 106 | phngy | yf |
| 107 | uhgd | lgst |
| 108 | ynyl | iio |
| 109 | daqbgsh | mp |
| 110 | yfbrju | vuhsf |
+--------+---------+--------+
10 rows in set (0.00 sec)
- 向 emp 表中插入 50w 条记录
DELIMITER ;
CALL insert_emp(100001, 500000);
mysql> select * from emp limit 20;
+----+--------+-------+----------+-----+------------+---------+--------+--------+
| id | empno | ename | job | mgr | hiredate | sal | comm | deptno |
+----+--------+-------+----------+-----+------------+---------+--------+--------+
| 1 | 100002 | ipbmd | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 101 |
| 2 | 100003 | bfvt | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 107 |
| 3 | 100004 | | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 109 |
| 4 | 100005 | cptas | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 101 |
| 5 | 100006 | ftn | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 108 |
| 6 | 100007 | gzh | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 102 |
| 7 | 100008 | rji | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 100 |
| 8 | 100009 | | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 106 |
| 9 | 100010 | tms | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 100 |
| 10 | 100011 | utxe | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 101 |
| 11 | 100012 | vbis | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 104 |
| 12 | 100013 | qgfv | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 104 |
| 13 | 100014 | wrvb | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 105 |
| 14 | 100015 | dyks | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 109 |
| 15 | 100016 | hpcs | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 101 |
| 16 | 100017 | fxb | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 108 |
| 17 | 100018 | vqxq | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 102 |
| 18 | 100019 | rq | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 102 |
| 19 | 100020 | l | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 106 |
| 20 | 100021 | lk | salesman | 1 | 2020-08-05 | 2000.00 | 400.00 | 100 |
+----+--------+-------+----------+-----+------------+---------+--------+--------+
20 rows in set (0.00 sec)
4、Show Profile
Show Profile 是什么?
- 是mysql提供可以用来分析当前会话中语句执行的资源消耗情况。可以用于SQL的调优测量
- 官网:http://dev.mysql.com/doc/refman/5.5/en/show-profile.html
- 默认情况下,参数处于关闭状态,并保存最近15次的运行结果
分析步骤
查看是当前的SQL版本是否支持Show Profile
- show variables like ‘profiling%’; 查看 Show Profile 是否开启
mysql> show variables like 'profiling%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| profiling | OFF |
| profiling_history_size | 15 |
+------------------------+-------+
2 rows in set (0.01 sec)
开启功能 Show Profile ,默认是关闭,使用前需要开启
set profiling=on;开启 Show Profile
mysql> set profiling=on;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> show variables like 'profiling%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| profiling | ON |
| profiling_history_size | 15 |
+------------------------+-------+
2 rows in set (0.00 sec)
运行SQL
- 正常 SQL
select * from tbl_emp;
select * from tbl_emp e inner join tbl_dept d on e.deptId = d.id;
select * from tbl_emp e left join tbl_dept d on e.deptId = d.id;
- 慢 SQL
select * from emp group by id%10 limit 150000;
select * from emp group by id%10 limit 150000;
select * from emp group by id%20 order by 5;
查看结果
- 通过 show profiles; 指令查看结果
mysql> show profiles;
+----------+------------+----------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+----------------------------------------------------------------------+
| 1 | 0.00052700 | show variables like 'profiling%' |
| 2 | 0.00030300 | select * from tbl_emp |
| 3 | 0.00010650 | select * from tbl_emp e inner join tbl_dept d on e.'deptId' = d.'id' |
| 4 | 0.00031625 | select * from tbl_emp e inner join tbl_dept d on e.deptId = d.id |
| 5 | 0.00042100 | select * from tbl_emp e left join tbl_dept d on e.deptId = d.id |
| 6 | 0.38621875 | select * from emp group by id%20 limit 150000 |
| 7 | 0.00014900 | select * from emp group by id%20 order by 150000 |
| 8 | 0.38649000 | select * from emp group by id%20 order by 5 |
| 9 | 0.06782700 | select COUNT(*) from emp |
| 10 | 0.35434400 | select * from emp group by id%10 limit 150000 |
+----------+------------+----------------------------------------------------------------------+
10 rows in set, 1 warning (0.00 sec)
诊断SQL
show profile cpu, block io for query SQL编号;查看 SQL 语句执行的具体流程以及每个步骤花费的时间
mysql> show profile cpu, block io for query 2;
+----------------------+----------+----------+------------+--------------+---------------+
| Status | Duration | CPU_user | CPU_system | Block_ops_in | Block_ops_out |
+----------------------+----------+----------+------------+--------------+---------------+
| starting | 0.000055 | 0.000000 | 0.000000 | 0 | 0 |
| checking permissions | 0.000007 | 0.000000 | 0.000000 | 0 | 0 |
| Opening tables | 0.000011 | 0.000000 | 0.000000 | 0 | 0 |
| init | 0.000024 | 0.000000 | 0.000000 | 0 | 0 |
| System lock | 0.000046 | 0.000000 | 0.000000 | 0 | 0 |
| optimizing | 0.000018 | 0.000000 | 0.000000 | 0 | 0 |
| statistics | 0.000008 | 0.000000 | 0.000000 | 0 | 0 |
| preparing | 0.000019 | 0.000000 | 0.000000 | 0 | 0 |
| executing | 0.000003 | 0.000000 | 0.000000 | 0 | 0 |
| Sending data | 0.000089 | 0.000000 | 0.000000 | 0 | 0 |
| end | 0.000004 | 0.000000 | 0.000000 | 0 | 0 |
| query end | 0.000003 | 0.000000 | 0.000000 | 0 | 0 |
| closing tables | 0.000005 | 0.000000 | 0.000000 | 0 | 0 |
| freeing items | 0.000006 | 0.000000 | 0.000000 | 0 | 0 |
| cleaning up | 0.000006 | 0.000000 | 0.000000 | 0 | 0 |
+----------------------+----------+----------+------------+--------------+---------------+
15 rows in set, 1 warning (0.00 sec)
- 参数备注:
- ALL:显示所有的开销信息
- BLOCK IO:显示块IO相关开销
- CONTEXT SWITCHES:上下文切换相关开销
- CPU:显示CPU相关开销信息
- IPC:显示发送和接收相关开销信息
- MEMORY:显示内存相关开销信息
- PAGE FAULTS:显示页面错误相关开销信息
- SOURCE:显示和Source_function,Source_file,Source_line相关的开销信息
- SWAPS:显示交换次数相关开销的信息
日常开发需要注意的结论
- converting HEAP to MyISAM:查询结果太大,内存都不够用了往磁盘上搬了。
- Creating tmp table:创建临时表,mysql 先将拷贝数据到临时表,然后用完再将临时表删除
- Copying to tmp table on disk:把内存中临时表复制到磁盘,危险!!!
- locked:锁表
举例
奇了怪了。。。老师的慢 SQL 我怎么复现不了,下面是老师的例子
5、全局查询日志
永远不要在生产环境开启这个功能。
配置启用全局查询日志
- 在mysql的my.cnf中,设置如下:
## 开启
general_log=1
## 记录日志文件的路径
general_log_file=/path/logfile
## 输出格式
log_output=FILE
编码启用全局查询日志
- 执行如下指令开启全局查询日志
set global general_log=1;
set global log_output='TABLE';
- 此后,你所执行的sql语句,将会记录到mysql库里的general_log表,可以用下面的命令查看
select * from mysql.general_log;
mysql> select * from mysql.general_log;
+---------------------+---------------------------+-----------+-----------+--------------+-----------------------------------------------+
| event_time | user_host | thread_id | server_id | command_type | argument |
+---------------------+---------------------------+-----------+-----------+--------------+-----------------------------------------------+
| 2020-08-05 14:41:07 | root[root] @ localhost [] | 14 | 0 | Query | select * from emp group by id%10 limit 150000 |
| 2020-08-05 14:41:12 | root[root] @ localhost [] | 14 | 0 | Query | select COUNT(*) from emp |
| 2020-08-05 14:41:30 | root[root] @ localhost [] | 14 | 0 | Query | select * from mysql.general_log |
+---------------------+---------------------------+-----------+-----------+--------------+-----------------------------------------------+
3 rows in set (0.00 sec)
13 MySql锁机制
1、概述
1.1、锁的定义
锁的定义
- 锁是计算机协调多个进程或线程并发访问某一资源的机制。
- 在数据库中,除传统的计算资源(如CPU、RAM、I/O等)的争用以外,数据也是一种供许多用户共享的资源。
- 如何保证数据并发访问的一致性、有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。
- 从这个角度来说,锁对数据库而言显得尤其重要,也更加复杂。
1.2、锁的分类
锁的分类
- 从数据操作的类型(读、写)分
- 读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会互相影响
- 写锁(排它锁):当前写操作没有完成前,它会阻断其他写锁和读锁。
- 从对数据操作的颗粒度
- 表锁
- 行锁
2、表锁
表锁的特点
偏向MyISAM存储引擎,开销小,加锁快,无死锁,锁定粒度大,发生锁冲突的概率最高,并发最低
2.1、表锁案例
表锁案例分析
创建表
- 建表 SQL:引擎选择 myisam
create table mylock (
id int not null primary key auto_increment,
name varchar(20) default ''
) engine myisam;
insert into mylock(name) values('a');
insert into mylock(name) values('b');
insert into mylock(name) values('c');
insert into mylock(name) values('d');
insert into mylock(name) values('e');
select * from mylock;
- mylock 表中的测试数据
mysql> select * from mylock;
+----+------+
| id | name |
+----+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
| 5 | e |
+----+------+
5 rows in set (0.00 sec)
手动加锁和释放锁
- 查看当前数据库中表的上锁情况:
show open tables;,0 表示未上锁
mysql> show open tables;
+--------------------+----------------------------------------------------+--------+-------------+
| Database | Table | In_use | Name_locked |
+--------------------+----------------------------------------------------+--------+-------------+
| performance_schema | events_waits_history | 0 | 0 |
| performance_schema | events_waits_summary_global_by_event_name | 0 | 0 |
| performance_schema | setup_timers | 0 | 0 |
| performance_schema | events_waits_history_long | 0 | 0 |
| performance_schema | events_statements_summary_by_digest | 0 | 0 |
| performance_schema | mutex_instances | 0 | 0 |
| performance_schema | events_waits_summary_by_instance | 0 | 0 |
| performance_schema | events_stages_history | 0 | 0 |
| mysql | db | 0 | 0 |
| performance_schema | events_waits_summary_by_host_by_event_name | 0 | 0 |
| mysql | user | 0 | 0 |
| mysql | columns_priv | 0 | 0 |
| performance_schema | events_statements_history_long | 0 | 0 |
| performance_schema | performance_timers | 0 | 0 |
| performance_schema | file_instances | 0 | 0 |
| performance_schema | events_stages_summary_by_user_by_event_name | 0 | 0 |
| performance_schema | events_stages_history_long | 0 | 0 |
| performance_schema | setup_actors | 0 | 0 |
| performance_schema | cond_instances | 0 | 0 |
| mysql | proxies_priv | 0 | 0 |
| performance_schema | socket_summary_by_instance | 0 | 0 |
| performance_schema | events_statements_current | 0 | 0 |
| mysql | event | 0 | 0 |
| performance_schema | session_connect_attrs | 0 | 0 |
| mysql | plugin | 0 | 0 |
| performance_schema | threads | 0 | 0 |
| mysql | time_zone_transition_type | 0 | 0 |
| mysql | time_zone_name | 0 | 0 |
| performance_schema | file_summary_by_event_name | 0 | 0 |
| performance_schema | events_waits_summary_by_user_by_event_name | 0 | 0 |
| performance_schema | socket_summary_by_event_name | 0 | 0 |
| performance_schema | users | 0 | 0 |
| mysql | servers | 0 | 0 |
| performance_schema | events_waits_summary_by_account_by_event_name | 0 | 0 |
| db01 | tbl_emp | 0 | 0 |
| performance_schema | events_statements_summary_by_host_by_event_name | 0 | 0 |
| db01 | tblA | 0 | 0 |
| performance_schema | table_io_waits_summary_by_index_usage | 0 | 0 |
| performance_schema | events_waits_current | 0 | 0 |
| db01 | user | 0 | 0 |
| mysql | procs_priv | 0 | 0 |
| performance_schema | events_statements_summary_by_thread_by_event_name | 0 | 0 |
| db01 | emp | 0 | 0 |
| db01 | tbl_user | 0 | 0 |
| db01 | test03 | 0 | 0 |
| mysql | slow_log | 0 | 0 |
| performance_schema | file_summary_by_instance | 0 | 0 |
| db01 | article | 0 | 0 |
| performance_schema | objects_summary_global_by_type | 0 | 0 |
| db01 | phone | 0 | 0 |
| performance_schema | events_waits_summary_by_thread_by_event_name | 0 | 0 |
| performance_schema | setup_consumers | 0 | 0 |
| performance_schema | socket_instances | 0 | 0 |
| performance_schema | rwlock_instances | 0 | 0 |
| db01 | tbl_dept | 0 | 0 |
| performance_schema | events_statements_summary_by_user_by_event_name | 0 | 0 |
| db01 | staffs | 0 | 0 |
| db01 | class | 0 | 0 |
| mysql | general_log | 0 | 0 |
| performance_schema | events_stages_summary_global_by_event_name | 0 | 0 |
| performance_schema | events_stages_summary_by_account_by_event_name | 0 | 0 |
| performance_schema | events_statements_summary_by_account_by_event_name | 0 | 0 |
| performance_schema | table_lock_waits_summary_by_table | 0 | 0 |
| performance_schema | hosts | 0 | 0 |
| performance_schema | setup_objects | 0 | 0 |
| performance_schema | events_stages_current | 0 | 0 |
| mysql | time_zone | 0 | 0 |
| mysql | tables_priv | 0 | 0 |
| performance_schema | table_io_waits_summary_by_table | 0 | 0 |
| mysql | time_zone_leap_second | 0 | 0 |
| db01 | book | 0 | 0 |
| performance_schema | session_account_connect_attrs | 0 | 0 |
| db01 | mylock | 0 | 0 |
| mysql | func | 0 | 0 |
| performance_schema | events_statements_summary_global_by_event_name | 0 | 0 |
| performance_schema | events_statements_history | 0 | 0 |
| performance_schema | accounts | 0 | 0 |
| mysql | time_zone_transition | 0 | 0 |
| db01 | dept | 0 | 0 |
| performance_schema | events_stages_summary_by_host_by_event_name | 0 | 0 |
| performance_schema | events_stages_summary_by_thread_by_event_name | 0 | 0 |
| mysql | proc | 0 | 0 |
| performance_schema | setup_instruments | 0 | 0 |
| performance_schema | host_cache | 0 | 0 |
+--------------------+----------------------------------------------------+--------+-------------+
84 rows in set (0.00 sec)
- 添加锁
lock table 表名1 read(write), 表名2 read(write), ...;
- 释放表锁
unlock tables;
2.1.1、读锁示例
读锁示例
- 在 session 1 会话中,给 mylock 表加个读锁
mysql> lock table mylock read;
Query OK, 0 rows affected (0.00 sec)
- 在 session1 会话中能不能读取 mylock 表:可以读
################## session1 中的操作 #################
mysql> select * from mylock;
+----+------+
| id | name |
+----+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
| 5 | e |
+----+------+
5 rows in set (0.00 sec)
- 在 session1 会话中能不能读取 book 表:并不行。。。
################## session1 中的操作 #################
mysql> select * from book;
ERROR 1100 (HY000): Table 'book' was not locked with LOCK TABLES
- 在 session2 会话中能不能读取 mylock 表:可以读
################## session2 中的操作 #################
mysql> select * from mylock;
+----+------+
| id | name |
+----+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
| 5 | e |
+----+------+
5 rows in set (0.00 sec)
- 在 session1 会话中能不能修改 mylock 表:并不行。。。
################## session1 中的操作 #################
mysql> update mylock set name='a2' where id=1;
ERROR 1099 (HY000): Table 'mylock' was locked with a READ lock and can't be updated
- 在 session2 会话中能不能修改 mylock 表:阻塞,一旦 mylock 表锁释放,则会执行修改操作
################## session2 中的操作 #################
mysql> update mylock set name='a2' where id=1;
## 在这里阻塞着呢~~~
结论
- 当前 session 和其他 session 均可以读取加了读锁的表
- 当前 session 不能读取其他表,并且不能修改加了读锁的表
- 其他 session 想要修改加了读锁的表,必须等待其读锁释放
2.1.2、写锁示例
写锁示例
- 在 session 1 会话中,给 mylock 表加个写锁
mysql> lock table mylock write;
Query OK, 0 rows affected (0.00 sec)
- 在 session1 会话中能不能读取 mylock 表:阔以
################## session1 中的操作 #################
mysql> select * from mylock;
+----+------+
| id | name |
+----+------+
| 1 | a2 |
| 2 | b |
| 3 | c |
| 4 | d |
| 5 | e |
+----+------+
5 rows in set (0.00 sec)
- 在 session1 会话中能不能读取 book 表:不阔以
################## session1 中的操作 #################
mysql> select * from book;
ERROR 1100 (HY000): Table 'book' was not locked with LOCK TABLES
- 在 session1 会话中能不能修改 mylock 表:当然可以啦,加写锁就是为了修改呀
################## session1 中的操作 #################
mysql> update mylock set name='a2' where id=1;
Query OK, 0 rows affected (0.00 sec)
Rows matched: 1 Changed: 0 Warnings: 0
- 在 session2 会话中能不能读取 mylock 表:
################## session2 中的操作 #################
mysql> select * from mylock;
## 在这里阻塞着呢~~~
结论
- 当前 session 可以读取和修改加了写锁的表
- 当前 session 不能读取其他表
- 其他 session 想要读取加了写锁的表,必须等待其读锁释放
案例结论
- MyISAM在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁,在执行增删改操作前,会自动给涉及的表加写锁。
- MySQL的表级锁有两种模式:
- 表共享读锁(Table Read Lock)
- 表独占写锁(Table Write Lock)

结论:结合上表,所以对MyISAM表进行操作,会有以下情况:
- 对MyISAM表的读操作(加读锁),不会阻塞其他进程对同一表的读请求,但会阻塞对同一表的写请求。只有当读锁释放后,才会执行其它进程的写操作。
- 对MyISAM表的写操作(加写锁),会阻塞其他进程对同一表的读和写操作,只有当写锁释放后,才会执行其它进程的读写操作
- 简而言之,就是读锁会阻塞写,但是不会堵塞读。而写锁则会把读和写都堵塞。
2.2、表锁分析
表锁分析
- 查看哪些表被锁了,0 表示未锁,1 表示被锁
show open tables;
【如何分析表锁定】可以通过检查table_locks_waited和table_locks_immediate状态变量来分析系统上的表锁定,通过 show status like 'table%'; 命令查看
-
Table\_locks\_immediate:产生表级锁定的次数,表示可以立即获取锁的查询次数,每立即获取锁值加1; -
Table\_locks\_waited:出现表级锁定争用而发生等待的次数(不能立即获取锁的次数,每等待一次锁值加1),此值高则说明存在着较严重的表级锁争用情况;
mysql> show status like 'table%';
+----------------------------+--------+
| Variable_name | Value |
+----------------------------+--------+
| Table_locks_immediate | 500440 |
| Table_locks_waited | 1 |
| Table_open_cache_hits | 500070 |
| Table_open_cache_misses | 5 |
| Table_open_cache_overflows | 0 |
+----------------------------+--------+
5 rows in set (0.00 sec)
- 此外,Myisam的读写锁调度是写优先,这也是myisam不适合做写为主表的引擎。因为写锁后,其他线程不能做任何操作,大量的更新会使查询很难得到锁,从而造成永远阻塞
3、行锁
行锁的特点
- 偏向InnoDB存储引擎,开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- InnoDB与MyISAM的最大不同有两点:一是支持事务(TRANSACTION);二是采用了行级锁
3.1、事务复习
行锁支持事务,复习下老知识
事务(Transation)及其ACID属性
事务是由一组SQL语句组成的逻辑处理单元,事务具有以下4个属性,通常简称为事务的ACID属性。
- 原子性(Atomicity):事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
- 一致性(Consistent):在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性;事务结束时,所有的内部数据结构(如B树索引或双向链表)也都必须是正确的。
- 隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
- 持久性(Durability):事务院成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
并发事务处理带来的问题
- 更新丢失(Lost Update):
- 当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题一一最后的更新覆盖了由其他事务所做的更新。
- 例如,两个程序员修改同一java文件。每程序员独立地更改其副本,然后保存更改后的副本,这样就覆盖了原始文档。最后保存其更改副本的编辑人员覆盖前一个程序员所做的更改。
- 如果在一个程序员完成并提交事务之前,另一个程序员不能访问同一文件,则可避免此问题。
- 脏读(Dirty Reads):
- 一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些“脏”数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被形象地叫做”脏读”。
- 一句话:事务A读取到了事务B已修改但尚未提交的的数据,还在这个数据基础上做了操作。此时,如果B事务回滚,A读取的数据无效,不符合一致性要求。
- 不可重复读(Non-Repeatable Reads):
- 一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现其读出的数据已经发生了改变、或某些记录已经被删除了!这种现象就叫做“不可重复读”。
- 一句话:事务A读取到了事务B已经提交的修改数据,不符合隔离性
- 幻读(Phantom Reads)
- 一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为“幻读一句话:事务A读取到了事务B体提交的新增数据,不符合隔离性。
- 多说一句:幻读和脏读有点类似,脏读是事务B里面修改了数据,幻读是事务B里面新增了数据。
事物的隔离级别
- 脏读”、“不可重复读”和“幻读”,其实都是数据库读一致性问题,必须由数据库提供一定的事务隔离机制来解决。
- 数据库的事务隔离越严格,并发副作用越小,但付出的代价也就越大,因为事务隔离实质上就是使事务在一定程度上“串行化”进行,这显然与“并发”是矛盾的。
- 同时,不同的应用对读一致性和事务隔离程度的要求也是不同的,比如许多应用对“不可重复读”和“幻读”并不敏感,可能更关心数据并发访问的能力。
- 查看当前数据库的事务隔离级别:
show variables like 'tx_isolation';mysql 默认是可重复读
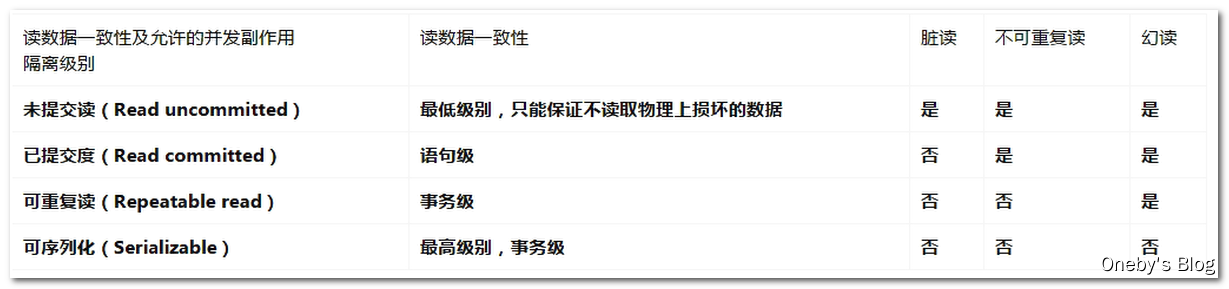
3.2、行锁案例
行锁案例分析
创建表
- 建表 SQL
CREATE TABLE test_innodb_lock (a INT(11),b VARCHAR(16))ENGINE=INNODB;
INSERT INTO test_innodb_lock VALUES(1,'b2');
INSERT INTO test_innodb_lock VALUES(3,'3');
INSERT INTO test_innodb_lock VALUES(4, '4000');
INSERT INTO test_innodb_lock VALUES(5,'5000');
INSERT INTO test_innodb_lock VALUES(6, '6000');
INSERT INTO test_innodb_lock VALUES(7,'7000');
INSERT INTO test_innodb_lock VALUES(8, '8000');
INSERT INTO test_innodb_lock VALUES(9,'9000');
INSERT INTO test_innodb_lock VALUES(1,'b1');
CREATE INDEX test_innodb_a_ind ON test_innodb_lock(a);
CREATE INDEX test_innodb_lock_b_ind ON test_innodb_lock(b);
- test_innodb_lock 表中的测试数据
mysql> select * from test_innodb_lock;
+------+------+
| a | b |
+------+------+
| 1 | b2 |
| 3 | 3 |
| 4 | 4000 |
| 5 | 5000 |
| 6 | 6000 |
| 7 | 7000 |
| 8 | 8000 |
| 9 | 9000 |
| 1 | b1 |
+------+------+
9 rows in set (0.00 sec)
- test_innodb_lock 表中的索引
mysql> SHOW INDEX FROM test_innodb_lock;
+------------------+------------+------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+------------------+------------+------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| test_innodb_lock | 1 | test_innodb_a_ind | 1 | a | A | 9 | NULL | NULL | YES | BTREE | | |
| test_innodb_lock | 1 | test_innodb_lock_b_ind | 1 | b | A | 9 | NULL | NULL | YES | BTREE | | |
+------------------+------------+------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec)
操作同一行数据
- session1 开启事务,修改 test_innodb_lock 中的数据
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> update test_innodb_lock set b='4001' where a=4;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
- session2 开启事务,修改 test_innodb_lock 中同一行数据,将导致 session2 发生阻塞,一旦 session1 提交事务,session2 将执行更新操作
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> update test_innodb_lock set b='4002' where a=4;
## 在这儿阻塞着呢~~~
## 时间太长,会报超时错误哦
mysql> update test_innodb_lock set b='4001' where a=4;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
操作不同行数据
- session1 开启事务,修改 test_innodb_lock 中的数据
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> update test_innodb_lock set b='4001' where a=4;
Query OK, 0 rows affected (0.00 sec)
Rows matched: 1 Changed: 0 Warnings: 0
- session2 开启事务,修改 test_innodb_lock 中不同行的数据
- 由于采用行锁,session2 和 session1 互不干涉,所以 session2 中的修改操作没有阻塞
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> update test_innodb_lock set b='9001' where a=9;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
无索引导致行锁升级为表锁
- session1 开启事务,修改 test_innodb_lock 中的数据,varchar 不用 ’ ’ ,导致系统自动转换类型,导致索引失效
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> update test_innodb_lock set a=44 where b=4000;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
- session2 开启事务,修改 test_innodb_lock 中不同行的数据
- 由于发生了自动类型转换,索引失效,导致行锁变为表锁
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> update test_innodb_lock set b='9001' where a=9;
## 在这儿阻塞着呢~~~
注意:一定在有索引的地方才会使用行锁,不然就是表锁
set autocommit = 0;
update t_menu set name = '我有改变了' where name='我改变了'
如果没有name的索引
那么就是表锁
如果有name的索引
那么mysql就会根据name的索引找到对应的表记录,并进行了加锁,把那一行全锁了,但是如果修改了没有索引的字段,那就是全部表都进行了加锁了
3.3、间隙锁
什么是间隙锁
- 当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”
- InnoDB也会对这个“间隙”加锁,这种锁机制是所谓的间隙锁(Next-Key锁)
间隙锁的危害
- 因为Query执行过程中通过过范围查找的话,他会锁定整个范围内所有的索引键值,即使这个键值并不存在。
- 间隙锁有一个比较致命的弱点,就是当锁定一个范围键值之后,即使某些不存在的键值也会被无辜的锁定,而造成在锁定的时候无法插入锁定键值范围内的任何数据。在某些场景下这可能会对性能造成很大的危害
间隙锁示例
- test_innodb_lock 表中的数据
mysql> select * from test_innodb_lock;
+------+------+
| a | b |
+------+------+
| 1 | b2 |
| 3 | 3 |
| 4 | 4000 |
| 5 | 5000 |
| 6 | 6000 |
| 7 | 7000 |
| 8 | 8000 |
| 9 | 9000 |
| 1 | b1 |
+------+------+
9 rows in set (0.00 sec)
- session1 开启事务,执行修改 a > 1 and a < 6 的数据,这会导致 mysql 将 a = 2 的数据行锁住(虽然表中并没有这行数据)
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> update test_innodb_lock set b='Heygo' where a>1 and a<6;
Query OK, 3 rows affected (0.00 sec)
Rows matched: 3 Changed: 3 Warnings: 0
- session2 开启事务,修改 test_innodb_lock 中不同行的数据,也会导致阻塞,直至 session1 提交事务
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> update test_innodb_lock set b='9001' where a=9;
## 在这儿阻塞着呢~~~
3.4、手动行锁
如何锁定一行
select xxx ... for update锁定某一行后,其它的操作会被阻塞,直到锁定行的会话提交- session1 开启事务,手动执行 for update 锁定指定行,待执行完指定操作时再将数据提交
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from test_innodb_lock where a=8 for update;
+------+------+
| a | b |
+------+------+
| 8 | 8000 |
+------+------+
1 row in set (0.00 sec)
- session2 开启事务,修改 session1 中被锁定的行,会导致阻塞,直至 session1 提交事务
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> update test_innodb_lock set b='XXX' where a=8;
## 在这儿阻塞着呢~~~
3.5、行锁分析
案例结论
- Innodb存储引擎由于实现了行级锁定,虽然在锁定机制的实现方面所带来的性能损耗可能比表级锁定会要更高一些,但是在整体并发处理能力方面要远远优于MyISAM的表级锁定的。
- 当系统并发量较高的时候,Innodb的整体性能和MyISAM相比就会有比较明显的优势了。
- 但是,Innodb的行级锁定同样也有其脆弱的一面,当我们使用不当的时候(索引失效,导致行锁变表锁),可能会让Innodb的整体性能表现不仅不能比MyISAM高,甚至可能会更差。
行锁分析
如何分析行锁定
- 通过检查InnoDB_row_lock状态变量来分析系统上的行锁的争夺情况
show status like 'innodb_row_lock%';
mysql> show status like 'innodb_row_lock%';
+-------------------------------+--------+
| Variable_name | Value |
+-------------------------------+--------+
| Innodb_row_lock_current_waits | 0 |
| Innodb_row_lock_time | 212969 |
| Innodb_row_lock_time_avg | 42593 |
| Innodb_row_lock_time_max | 51034 |
| Innodb_row_lock_waits | 5 |
+-------------------------------+--------+
5 rows in set (0.00 sec)
对各个状态量的说明如下:
- Innodb_row_lock_current_waits:当前正在等待锁定的数量;
- Innodb_row_lock_time:从系统启动到现在锁定总时间长度;
- Innodb_row_lock_time_avg:每次等待所花平均时间;
- Innodb_row_lock_time_max:从系统启动到现在等待最常的一次所花的时间;
- Innodb_row_lock_waits:系统启动后到现在总共等待的次数;
对于这5个状态变量,比较重要的主要是
- Innodb_row_lock_time_avg(等待平均时长)
- Innodb_row_lock_waits(等待总次数)
- Innodb_row_lock_time(等待总时长)
尤其是当等待次数很高,而且每次等待时长也不小的时候,我们就需要分析系统中为什么会有如此多的等待,然后根据分析结果着手指定优化计划。
3.6、行锁优化
优化建议
- 尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁
- 合理设计索引,尽量缩小锁的范围
- 尽可能较少检索条件,避免间隙锁
- 尽量控制事务大小,减少锁定资源量和时间长度
- 尽可能低级别事务隔离
4、页锁
- 开销和加锁时间界于表锁和行锁之间:会出现死锁;
- 锁定粒度界于表锁和行锁之间,并发度一般。
- 了解即可
14 主从复制
1、复制的基本原理
复制的基本原理
slave会从master读取binlog来进行数据同步,主从复制的三步骤
- master将改变记录到二进制日志(binary log)。这些记录过程叫做二进制日志事件(binary log events)
- slave将master的binary log events拷贝到它的中继日志(relay log)
- slave重做中继日志中的事件,将改变应用到自己的数据库中。MySQL复制是异步的且串行化的
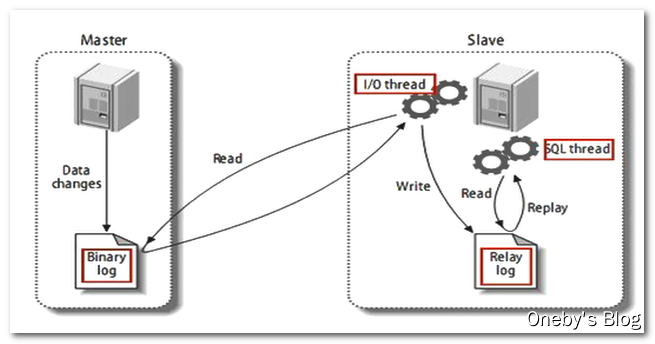
2、复制的基本原则
- 每个slave只有一个master
- 每个slave只能有一个唯一的服务器ID
- 每个master可以有多个salve
3、复制最大问题
因为发生多次 IO, 存在延时问题
4、一主一从常见配置
前提:mysql 版本一致,主从机在同一网段下
ping 测试
- Linux 中 ping Windows
[root@Heygo 桌面]# ping 10.206.207.131
PING 10.206.207.131 (10.206.207.131) 56(84) bytes of data.
64 bytes from 10.206.207.131: icmp_seq=1 ttl=128 time=1.27 ms
64 bytes from 10.206.207.131: icmp_seq=2 ttl=128 time=0.421 ms
64 bytes from 10.206.207.131: icmp_seq=3 ttl=128 time=1.12 ms
64 bytes from 10.206.207.131: icmp_seq=4 ttl=128 time=0.515 ms
^C
--- 10.206.207.131 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3719ms
rtt min/avg/max/mdev = 0.421/0.835/1.279/0.373 ms
[root@Heygo 桌面]#
- Windows 中 ping Linux
C:\Users\Heygo>ping 192.168.152.129
正在 Ping 192.168.152.129 具有 32 字节的数据:
来自 192.168.152.129 的回复: 字节=32 时间<1ms TTL=64
来自 192.168.152.129 的回复: 字节=32 时间<1ms TTL=64
来自 192.168.152.129 的回复: 字节=32 时间=1ms TTL=64
来自 192.168.152.129 的回复: 字节=32 时间<1ms TTL=64
192.168.152.129 的 Ping 统计信息:
数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失),
往返行程的估计时间(以毫秒为单位):
最短 = 0ms,最长 = 1ms,平均 = 0ms
主机修改 my.ini 配置文件(Windows)
主从都配置都在 [mysqld] 节点下,都是小写,以下是老师的配置文件

以下两条为必须配置
- 配置主机 id
server-id=1
- 启用二进制日志
log-bin=C:/Program Files (x86)/MySQL/MySQL Server 5.5/log-bin/mysqlbin
以下为非必须配置
- 启动错误日志
log-err=C:/Program Files (x86)/MySQL/MySQL Server 5.5/log-bin/mysqlerr
- 根目录
basedir="C:/Program Files (x86)/MySQL/MySQL Server 5.5/"
- 临时目录
tmpdir="C:/Program Files (x86)/MySQL/MySQL Server 5.5/"
- 数据目录
datadir="C:/Program Files (x86)/MySQL/MySQL Server 5.5/Data/"
- 主机,读写都可以
read-only=0
- 设置不要复制的数据库
binlog-ignore-db=mysql
- 设置需要复制的数据
binlog-do-db=需要复制的主数据库名字
从机修改 my.cnf 配置文件(Linux)
vim /etc/my.cnf
- 【必须】从服务器唯一ID
server-id=2
- 【可选】启用二进制文件
修改配置文件后的准备工作
因修改过配置文件,主机+从机都重启 mysql 服务
- Windows
- cmd用管理员方式启动
net stop mysql
net start mysql
- Linux
systemctl start mysql.service
主机从机都关闭防火墙
- Windows 手动关闭防火墙
- 关闭虚拟机 linux 防火墙
service iptables stop
在 Windows 主机上简历账户并授权 slave
- 创建用户, 并赋予从机
REPLICATION权限(从主机的数据库表中复制表)
GRANT REPLICATION SLAVE ON *.* TO '备份账号'@'从机器数据库 IP' IDENTIFIED BY '账号密码';
GRANT REPLICATION SLAVE ON *.* TO 'root'@'%' IDENTIFIED BY '123456';
- 刷新权限信息
flush privileges;
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
- 通过
select * from mysql.user where user='Heygo'\G;命令可查看:从机只有Repl_slave_priv权限为Y,其余权限均为N
mysql> select * from mysql.user where user='Heygo'\G;
*************************** 1. row ***************************
Host: %
User: Heygo
Password: *6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
Select_priv: N
Insert_priv: N
Update_priv: N
Delete_priv: N
Create_priv: N
Drop_priv: N
Reload_priv: N
Shutdown_priv: N
Process_priv: N
File_priv: N
Grant_priv: N
References_priv: N
Index_priv: N
Alter_priv: N
Show_db_priv: N
Super_priv: N
Create_tmp_table_priv: N
Lock_tables_priv: N
Execute_priv: N
Repl_slave_priv: Y
Repl_client_priv: N
Create_view_priv: N
Show_view_priv: N
Create_routine_priv: N
Alter_routine_priv: N
Create_user_priv: N
Event_priv: N
Trigger_priv: N
Create_tablespace_priv: N
ssl_type:
ssl_cipher:
x509_issuer:
x509_subject:
max_questions: 0
max_updates: 0
max_connections: 0
max_user_connections: 0
plugin:
authentication_string: NULL
1 row in set (0.00 sec)
- 查询 master 的状态,将 File 和 Position 记录下来,在启动 Slave 时需要用到这两个参数
show master status;
mysql> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000001 | 107 | mysql | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
在 Linux 从机上配置需要复制的主机
- 从机进行认证
CHANGE MASTER TO
MASTER_HOST='主机 IP',
MASTER_USER='创建用户名',
MASTER_PASSWORD='创建的密码',
MASTER_LOG_FILE='File 名字',
MASTER_LOG_POS=Position数字;
CHANGE MASTER TO
MASTER_HOST='192.168.1.223',
MASTER_USER='root',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=107;
- 启动从服务器复制功能
start slave;
- 查看从机复制功能是否启动成功:使用
show slave status\G;命令查看Slave_SQL_Running:Yes和Slave_IO_Running:Yes说明从机连接主机成功
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.206.207.131
Master_User: Heygo
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000052
Read_Master_Log_Pos: 4274
Relay_Log_File: mysqld-relay-bin.000063
Relay_Log_Pos: 2998
Relay_Master_Log_File: mysql-bin.000052
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 4274
Relay_Log_Space: 4749
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID:
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
1 row in set (0.00 sec)
- 如何停止从服务复制功能
stop slave;
JUC
1.卖票复习
老版写法
class Ticket{//资源类
//票
private int number = 30;
public synchronized void saleTicket(){
if (number > 0){
System.out.println(Thread.currentThread().getName()+"\t卖出第:"+(number--)+"\t还剩下:"+number);
}
}
}
/**
*题目:三个售票员 卖出 30张票
* 多线程编程的企业级套路+模板
* 1.在高内聚低耦合的前提下,线程 操作(对外暴露的调用方法) 资源类
*/
public class SaleTicket {
public static void main(String[] args) {
Ticket ticket = new Ticket();
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= 40; i++) {
ticket.saleTicket();
}
}
},"A").start();
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= 40; i++) {
ticket.saleTicket();
}
}
},"B").start();
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= 40; i++) {
ticket.saleTicket();
}
}
},"C").start();
}
}
新版写法,效果一样
//资源类 = 实例变量 + 实例方法
class Ticket{
//票
private int number = 30;
Lock lock = new ReentrantLock();
public void sale(){
lock.lock();
try {
if (number > 0){
System.out.println(Thread.currentThread().getName()+"\t卖出第:"+(number--)+"\t还剩下:"+number);
}
}catch (Exception e){
e.printStackTrace();
}finally {
lock.unlock();
}
}
}
/**
*题目:三个售票员 卖出 30张票
* 笔记:如何编写企业级的多线程
* 固定的编程套路+模板
* 1.在高内聚低耦合的前提下,线程 操作(对外暴露的调用方法) 资源类
* 1.1先创建一个资源类
*/
public class SaleTicketDemo1 {
//主线程,一切程序的入口
public static void main(String[] args) {
Ticket ticket = new Ticket();
new Thread(()->{for (int i = 1; i <= 40; i++) ticket.sale();},"A").start();
new Thread(()->{for (int i = 1; i <= 40; i++) ticket.sale();},"B").start();
new Thread(()->{for (int i = 1; i <= 40; i++) ticket.sale();},"C").start();
}
}
SaleTicket拆分


2.LambdaExpress

1
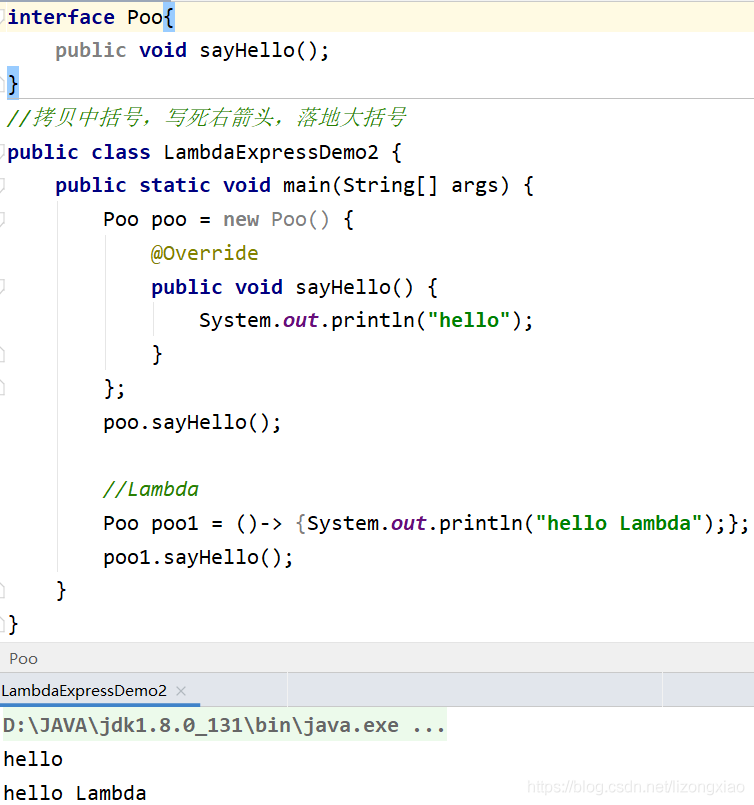
2
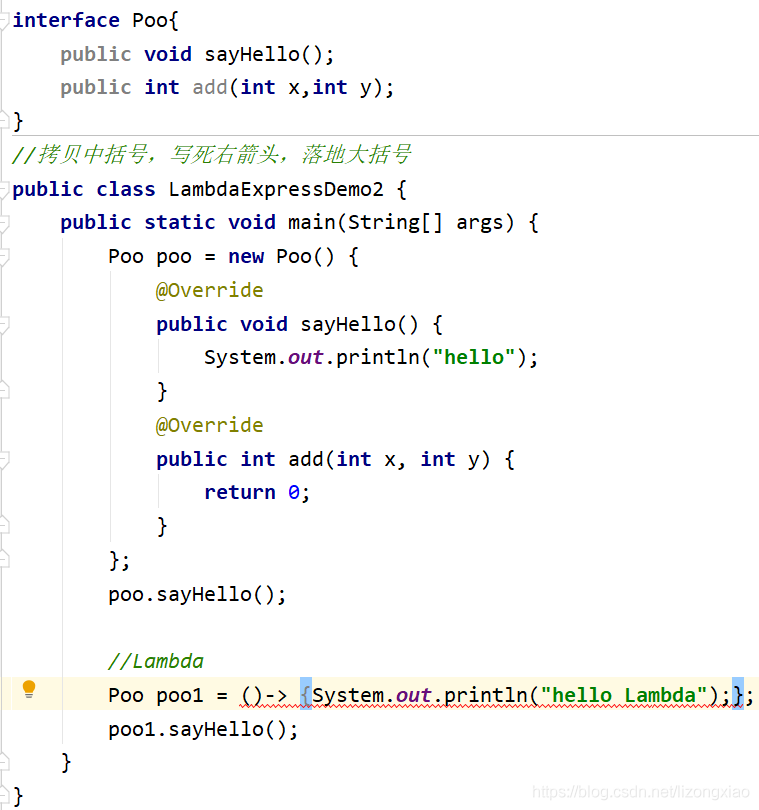
3
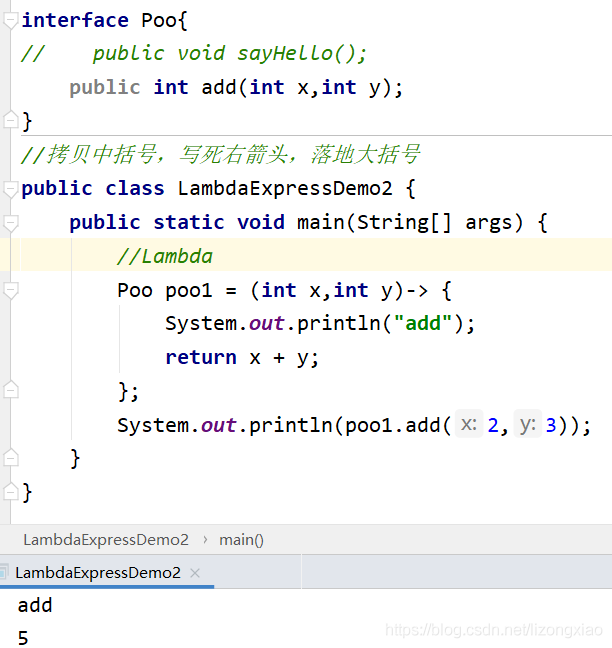
4
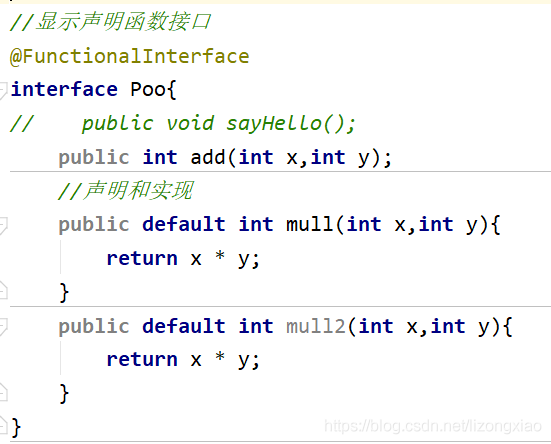
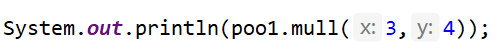

5
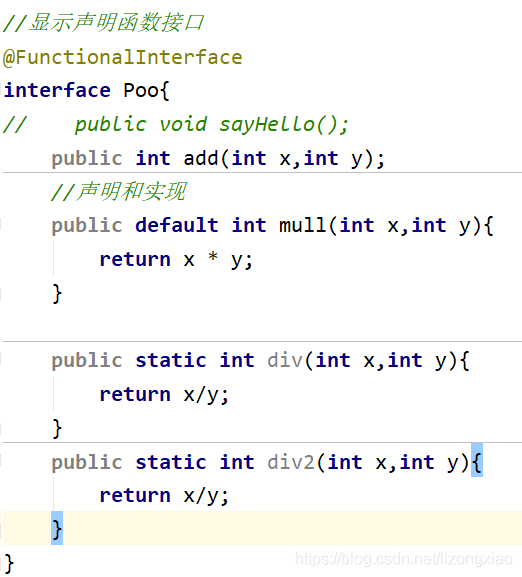

3.生产者消费者
老版写法
class Aircondition{
private int number = 0;
//老版写法
public synchronized void increment() throws Exception{
//1.判断
while (number != 0){
this.wait();
}
//2.干活
number++;
System.out.println(Thread.currentThread().getName()+"\t"+number);
//3通知
this.notifyAll();
}
public synchronized void decrement() throws Exception{
//1.判断
while (number == 0){
this.wait();
}
//2.干活
number--;
System.out.println(Thread.currentThread().getName()+"\t"+number);
//3通知
this.notifyAll();
}
}
/**
* 题目:现在两个线程,可以操作初始值为零的一个变量,
* 实现一个线程对该变量加1,一个线程对该变量-1,
* 实现交替,来10轮,变量初始值为0.
* 1.高内聚低耦合前提下,线程操作资源类
* 2.判断/干活/通知
* 3.防止虚假唤醒(判断只能用while,不能用if)
* 知识小总结:多线程编程套路+while判断+新版写法
*/
public class ProdConsumerDemo4 {
public static void main(String[] args) {
Aircondition aircondition = new Aircondition();
new Thread(()->{
for (int i = 1; i <= 10; i++) {
try {
aircondition.increment();
} catch (Exception e) {
e.printStackTrace();
}
}
},"A").start();
new Thread(()->{
for (int i = 1; i <= 10; i++) {
try {
aircondition.decrement();
} catch (Exception e) {
e.printStackTrace();
}
}
},"B").start();
new Thread(()->{
for (int i = 1; i <= 10; i++) {
try {
aircondition.increment();
} catch (Exception e) {
e.printStackTrace();
}
}
},"C").start();
new Thread(()->{
for (int i = 1; i <= 10; i++) {
try {
aircondition.decrement();
} catch (Exception e) {
e.printStackTrace();
}
}
},"D").start();
}
}
新版写法
class Aircondition{
private int number = 0;
private Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
//注意需要配套unlock使用
//新版decrease方法
public void increment() throws Exception{
lock.lock();
try {
//1.判断
while (number != 0){
condition.await();
}
//2.干活
number++;
System.out.println(Thread.currentThread().getName()+"\t"+number);
//3通知
condition.signalAll();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void decrement() throws Exception{
lock.lock();
try {
//1.判断
while (number == 0){
condition.await();
}
//2.干活
number--;
System.out.println(Thread.currentThread().getName()+"\t"+number);
//3通知
condition.signalAll();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
/**
* 题目:现在两个线程,可以操作初始值为零的一个变量,
* 实现一个线程对该变量加1,一个线程对该变量-1,
* 实现交替,来10轮,变量初始值为0.
* 1.高内聚低耦合前提下,线程操作资源类
* 2.判断/干活/通知
* 3.防止虚假唤醒(判断只能用while,不能用if)
* 知识小总结:多线程编程套路+while判断+新版写法
*/
public class ProdConsumerDemo4 {
public static void main(String[] args) {
Aircondition aircondition = new Aircondition();
new Thread(()->{
for (int i = 1; i <= 10; i++) {
try {
aircondition.increment();
} catch (Exception e) {
e.printStackTrace();
}
}
},"A").start();
new Thread(()->{
for (int i = 1; i <= 10; i++) {
try {
aircondition.decrement();
} catch (Exception e) {
e.printStackTrace();
}
}
},"B").start();
new Thread(()->{
for (int i = 1; i <= 10; i++) {
try {
aircondition.increment();
} catch (Exception e) {
e.printStackTrace();
}
}
},"C").start();
new Thread(()->{
for (int i = 1; i <= 10; i++) {
try {
aircondition.decrement();
} catch (Exception e) {
e.printStackTrace();
}
}
},"D").start();
}
}
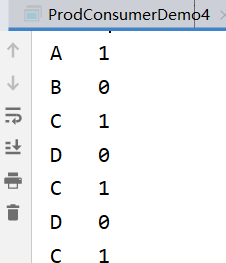
注意:新版的消费者和生产者需要搭配lock,unlock来使用,不然会报IllegalMonitorStateException
4.精确通知顺序访问
class ShareData{
private int number = 1;//A:1,B:2,C:3
private Lock lock = new ReentrantLock();
private Condition c1 = lock.newCondition();
private Condition c2 = lock.newCondition();
private Condition c3 = lock.newCondition();
public void printc1(){
lock.lock();
try {
//1.判断
while (number != 1){
c1.await();
}
//2.干活
for (int i = 1; i <= 5; i++) {
System.out.println(Thread.currentThread().getName()+"\t"+i);
}
//3.通知
number = 2;
//通知第2个
c2.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void printc2(){
lock.lock();
try {
//1.判断
while (number != 2){
c2.await();
}
//2.干活
for (int i = 1; i <= 10; i++) {
System.out.println(Thread.currentThread().getName()+"\t"+i);
}
//3.通知
number = 3;
//如何通知第3个
c3.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void printc3(){
lock.lock();
try {
//1.判断
while (number != 3){
c3.await();
}
//2.干活
for (int i = 1; i <= 15; i++) {
System.out.println(Thread.currentThread().getName()+"\t"+i);
}
//3.通知
number = 1;
//如何通知第1个
c1.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
/**
* 备注:多线程之间按顺序调用,实现A->B->C
* 三个线程启动,要求如下:
* AA打印5次,BB打印10次,CC打印15次
* 接着
* AA打印5次,BB打印10次,CC打印15次
* 来10轮
* 1.高内聚低耦合前提下,线程操作资源类
* 2.判断/干活/通知
* 3.多线程交互中,防止虚假唤醒(判断只能用while,不能用if)
* 4.标志位
*/
public class ConditionDemo {
public static void main(String[] args) {
ShareData shareData = new ShareData();
new Thread(()->{
for (int i = 1; i <= 10; i++) {
shareData.printc1();
}
},"A").start();
new Thread(()->{
for (int i = 1; i <= 10; i++) {
shareData.printc2();
}
},"B").start();
new Thread(()->{
for (int i = 1; i <= 10; i++) {
shareData.printc3();
}
},"C").start();
}
}

5.八锁理论
class Phone{
public static synchronized void sendEmail() throws Exception{
try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); }
System.out.println("*******sendEmail");
}
public synchronized void sendMs() throws Exception{
TimeUnit.SECONDS.sleep(2);
System.out.println("*******sendMs");
}
public void sayHello() throws Exception{
TimeUnit.SECONDS.sleep(3);
System.out.println("*****sayHello");
}
}
/**
* 1.标准访问,先打印邮件
* 2.邮件设置暂停4秒方法,先打印邮件
* 对象锁
* 一个对象里面如果有多个synchronized方法,某一个时刻内,只要一个线程去调用其中的一个synchronized方法了,
* 其他的线程都只能等待,换句话说,某一个时刻内,只能有唯一一个线程去访问这些synchronized方法,
* 锁的是当前对象this,被锁定后,其他的线程都不能进入到当前对象的其他的synchronized方法
* 3.新增sayHello方法,先打印sayHello
* 加个普通方法后发现和同步锁无关
* 4.两部手机,先打印短信
* 换成两个对象后,不是同一把锁了,情况立刻变化
* 5.两个静态同步方法,同一部手机,先打印邮件
* 6.两个静态同步方法,同两部手机,先打印邮件,锁的同一个字节码对象
* 全局锁
* synchronized实现同步的基础:java中的每一个对象都可以作为锁。
* 具体表现为一下3中形式。
* 对于普通同步方法,锁是当前实例对象,锁的是当前对象this,
* 对于同步方法块,锁的是synchronized括号里配置的对象。
* 对于静态同步方法,锁是当前类的class对象
* 7.一个静态同步方法,一个普通同步方法,同一部手机,先打印短信
* 8.一个静态同步方法,一个普通同步方法,同二部手机,先打印短信
* 当一个线程试图访问同步代码块时,它首先必须得到锁,退出或抛出异常时必须释放锁。
* 也就是说如果一个实例对象的普通同步方法获取锁后,该实例对象的其他普通同步方法必须等待获取锁的方法释放锁后才能获取锁,
* 可是别的实例对象的普通同步方法因为跟该实例对象的普通同步方法用的是不同的锁,
* 所以无需等待该实例对象已获取锁的普通同步方法释放锁就可以获取他们自己的锁。
*
* 所有的静态同步方法用的也是同一把锁--类对象本身,
* 这两把锁(this/class)是两个不同的对象,所以静态同步方法与非静态同步方法之间是不会有静态条件的。
* 但是一旦一个静态同步方法获取锁后,其他的静态同步方法都必须等待该方法释放锁后才能获取锁,
* 而不管是同一个实例对象的静态同步方法之间,
* 还是不同的实例对象的静态同步方法之间,只要它们同一个类的实例对象
*/
public class LockBDemo05 {
public static void main(String[] args) throws InterruptedException {
Phone phone = new Phone();
Phone phone2 = new Phone();
new Thread(()->{
try {
phone.sendEmail();
} catch (Exception e) {
e.printStackTrace();
}
},"A").start();
Thread.sleep(100);
new Thread(()->{
try {
phone.sendMs();
} catch (Exception e) {
e.printStackTrace();
}
},"B").start();
Thread.sleep(100);
new Thread(()->{
try {
phone.sayHello();
} catch (Exception e) {
e.printStackTrace();
}
},"c").start();
}
}
6.集合不安全类
当高并发的情况下,线程数增大,既要读又要写,线程不安全,arraylist不是线程安全的,就不干了,报错了
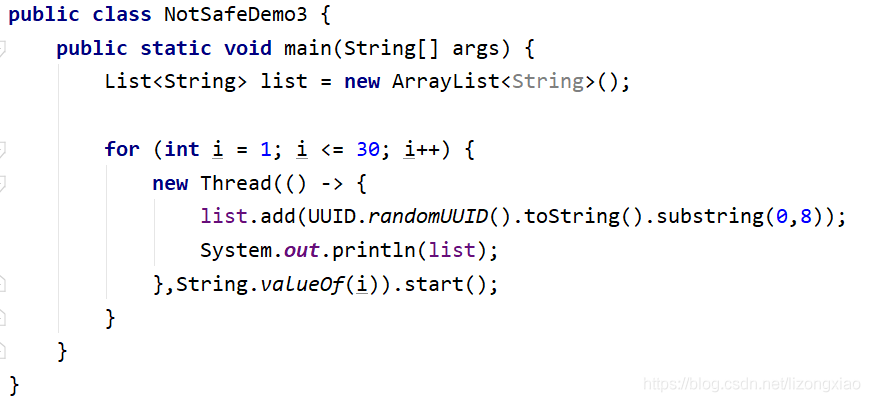
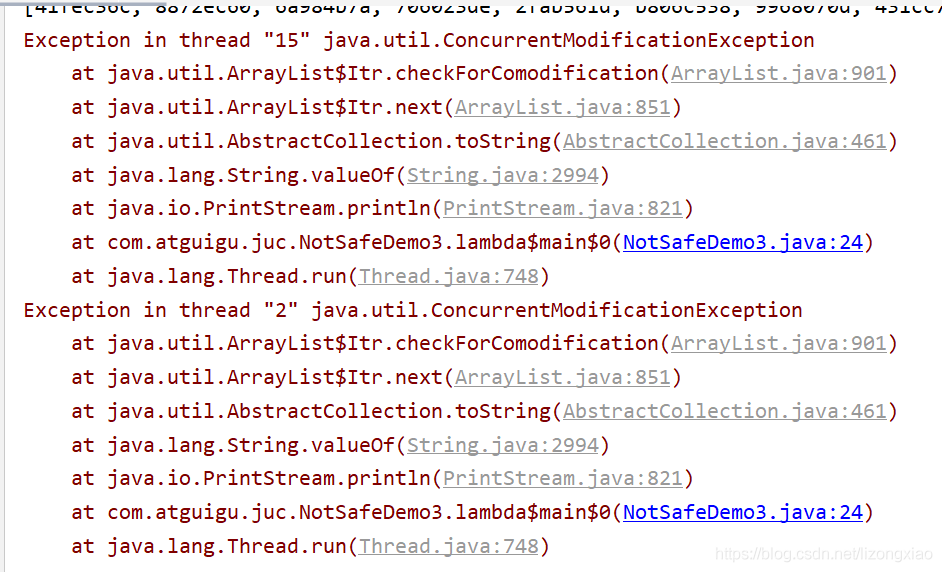
1.new Vector<>();
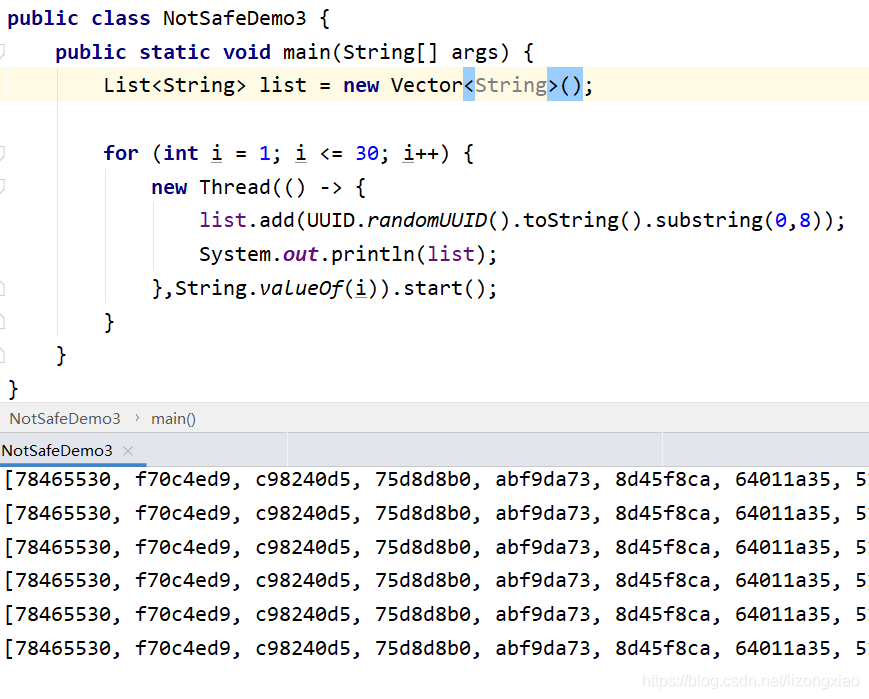
2.Collections.synchronizedList(new ArrayList());
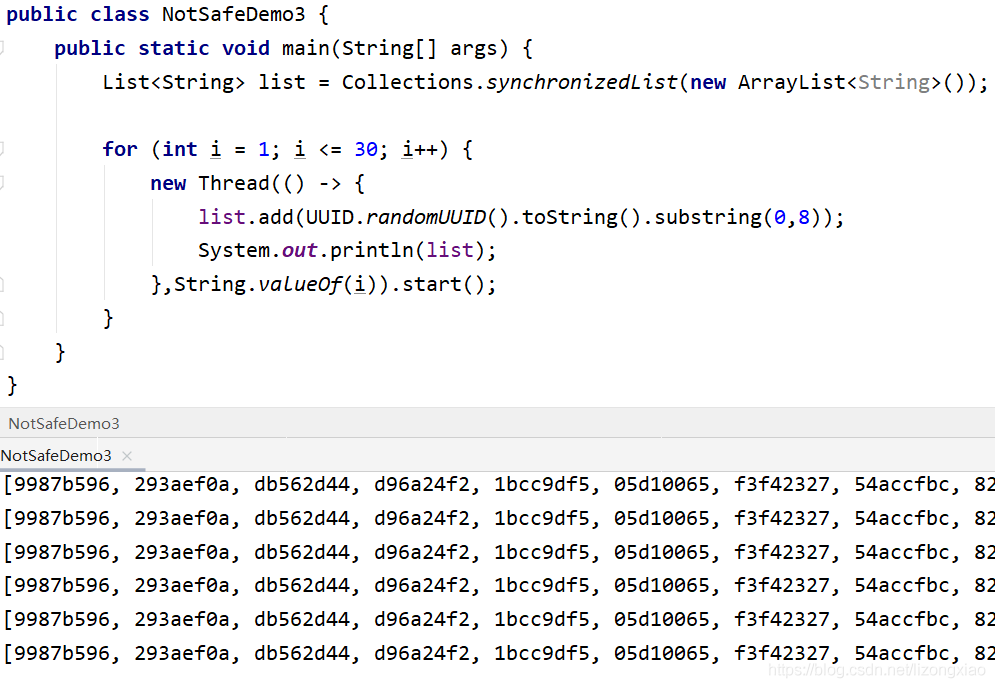
3.new CopyOnWriteArrayList(); //写时复制
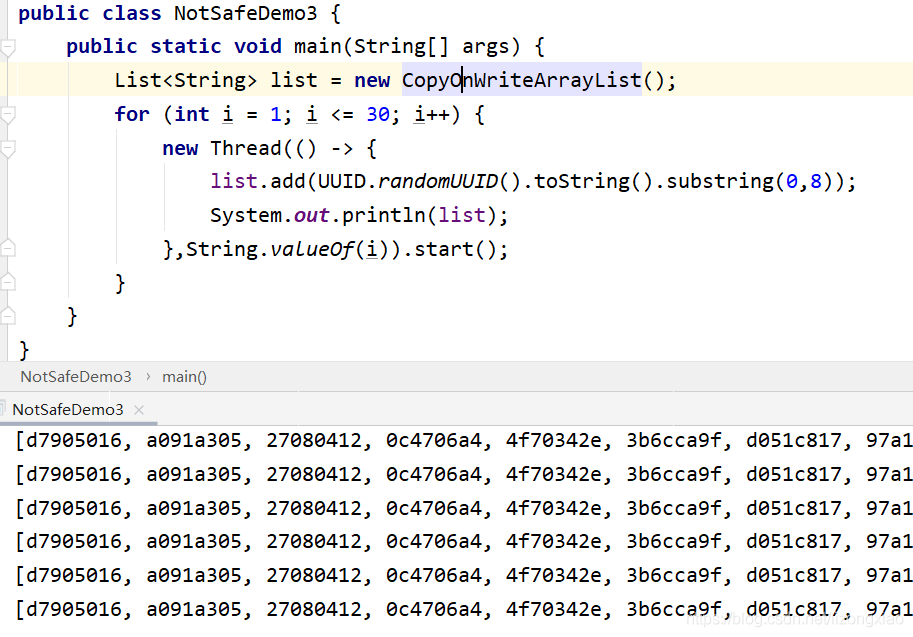
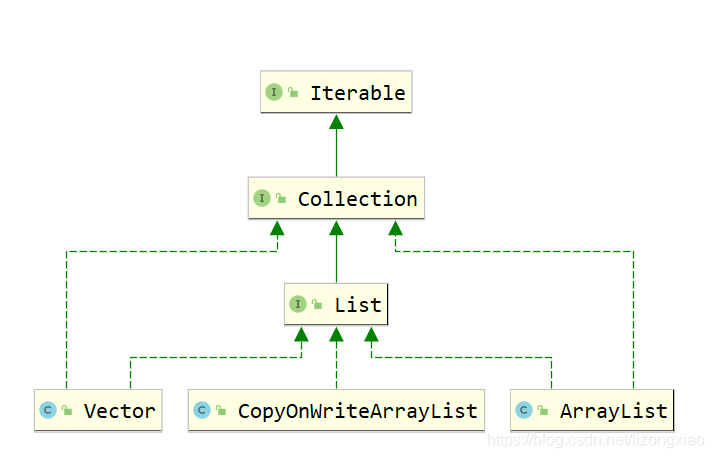
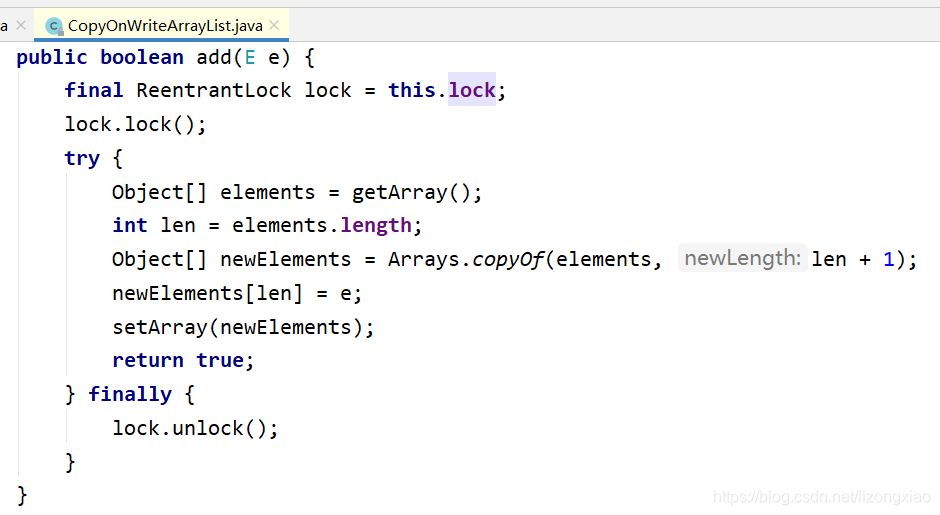
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable {
private static final Object PRESENT = new Object();
//调用HashMap
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
//value为Object类型的常量
return map.put(e, PRESENT)==null;
}
}
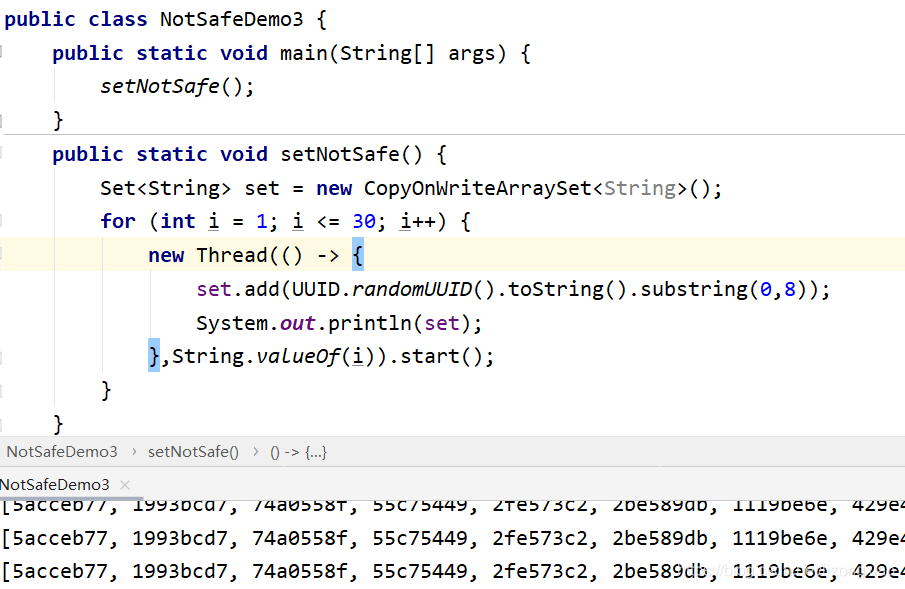
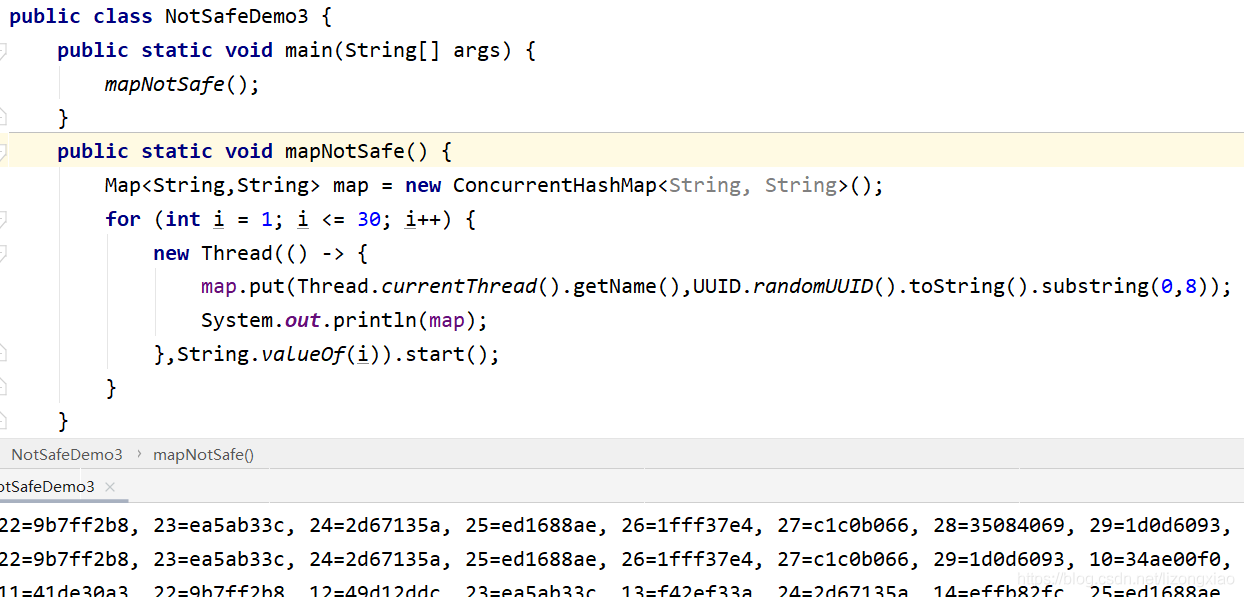
/**
* 1.故障现象
* 并发修改异常
* java.util.ConcurrentModificationException
* 2.导致原因
* 3.解决方法
* 3.1 new Vector<>();
* 3.2 Collections.synchronizedList(new ArrayList<String>());
* 3.3 new CopyOnWriteArrayList(); //写时复制
* 4.优化建议(同样的错误不犯第二次)
*
* 写时复制:
* CopyOnWrite容器即写时复制的容器。往一个容器添加元素的时候,不直接往当前容器Object[]添加,而是现将当前容器Object[]进行Copy,
* 复制出一个新的容器Object[] newElements,然后新的容器Object[] newElements里添加元素,添加完元素之后,
* 再将原容器的引用指向新的容器setArray(newElements);。这样做的好处是可以对CopyOnWrite容器进行并发的读,
* 而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器
*/
public class NotSafeDemo3 {
public static void main(String[] args) {
mapNotSafe();
}
public static void mapNotSafe() {
Map<String,String> map = new ConcurrentHashMap<String, String>();
for (int i = 1; i <= 30; i++) {
new Thread(() -> {
map.put(Thread.currentThread().getName(),UUID.randomUUID().toString().substring(0,8));
System.out.println(map);
},String.valueOf(i)).start();
}
}
public static void setNotSafe() {
Set<String> set = new CopyOnWriteArraySet<String>();
for (int i = 1; i <= 30; i++) {
new Thread(() -> {
set.add(UUID.randomUUID().toString().substring(0,8));
System.out.println(set);
},String.valueOf(i)).start();
}
}
public static void listNotSafe() {
List<String> list = new CopyOnWriteArrayList();
for (int i = 1; i <= 30; i++) {
new Thread(() -> {
list.add(UUID.randomUUID().toString().substring(0,8));
System.out.println(list);
},String.valueOf(i)).start();
}
}
}
7.Callable


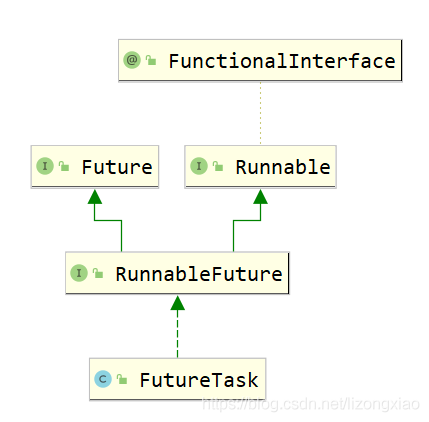
public class CallableThread implements Callable<Integer> {
@Override
public Integer call() throws Exception {
System.out.println("我是通过callable的多线程");
return 1024;
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
CallableThread callableThread = new CallableThread();
FutureTask<Integer> integerFutureTask = new FutureTask<>(callableThread);
new Thread(integerFutureTask).start();
/*Integer integer = integerFutureTask.get();
System.out.println(integer);*/
Thread.sleep(300);
System.out.println(Thread.currentThread().getName() + "通过了这里");
Integer integer = integerFutureTask.get();
System.out.println(integer);
}
}
只要线程完成,那么才会把值赋值给integer;
如果当两个线程同时使用一个integerFutureTask
那么就会产生缓存,方法只会执行一次
import java.util.Queue;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* @author 10185
* @create 2021/4/17 15:55
*/
public class CallableThread implements Callable<Integer> {
@Override
public Integer call() throws Exception {
System.out.println("我是通过callable的多线程");
Thread.sleep(3000);
return 1024;
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
CallableThread callableThread = new CallableThread();
FutureTask<Integer> integerFutureTask = new FutureTask<>(callableThread);
new Thread(integerFutureTask).start();
new Thread(integerFutureTask).start();
/*Integer integer = integerFutureTask.get();
System.out.println(integer);*/
Integer integer = integerFutureTask.get();
System.out.println(integer);
System.out.println(Thread.currentThread().getName() + "通过了这里");
}
}
结果:
发现只执行了一次
8.CountDownLatchDemo

/**
* CountDownLatch主要有两个方法,当一个或多个线程调用await方法时,这些线程会阻塞。
* 其他线程调用countDown方法会将计数器减1(调用countDown方法的线程不会阻塞),
* 当计数器的值变为0时,因await方法阻塞的线程会被唤醒,继续执行
*/
public class CountDownLatchDemo8 {
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(6);
for (int i = 1; i <= 6; i++) {
new Thread(()->{
System.out.println(Thread.currentThread().getName()+"\t离开教室");
countDownLatch.countDown();
},String.valueOf(i)).start();
}
countDownLatch.await();
System.out.println(Thread.currentThread().getName()+"\t关门走人");
}
private static void closeDoor(){
for (int i = 1; i <= 6; i++) {
new Thread(()->{
System.out.println(Thread.currentThread().getName()+"\t离开教室");
},String.valueOf(i)).start();
}
}
}
9.CyclicBarrierDemo
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
/**
* @author 10185
* @create 2021/4/17 20:17
*/
public class CyclicBarrierDemo {
public static void main(String[] args) {
CyclicBarrier barrier = new CyclicBarrier(7, () -> System.out.println("集齐了7个召唤神龙"));
//集齐七龙珠才能召唤神龙
for (int i = 0; i < 8; i++) {
new Thread(()->{
//每召唤一个进程就召唤一个神龙
System.out.println(Thread.currentThread().getName()+"召唤了神龙");
//阻塞进程
try {
barrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
},String.valueOf(i)).start();
}
}
}
只要有new CyclicBarrier(7, () -> System.out.println(“召唤神龙”));代表7个进程阻塞就进行召唤神龙

或者

只要阻塞了7个才会执行 CyclicBarrier标注的进程
10.Semaphore的用法
acquire(获取)当一个线程调用acquire操作时,他要么通过成功获取信号量,执行下面的语句,获取失败就一直等待
release(归还),归还信号值
- 等待下去,等待别的进程释放
import java.util.concurrent.Semaphore;
/**
* @author 10185
* @create 2021/4/17 20:27
*/
/**
* acquire(获取)当一个线程调用acquire操作时,他要么通过成功获取信号量,执行下面的语句,获取失败就一直
* 等待下去,等待别的进程释放
release,归还信号值
*
*/
public class SemaphoreDemo {
//演示车位占用不能超过三个
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(3);
//模拟有个线程进行抢夺车位
for (int i = 0; i < 100; i++) {
new Thread(()->{
try {
semaphore.acquire();
System.out.println(Thread.currentThread().getName()+"抢夺了车位" +
",剩余"+semaphore.availablePermits()+"个车位");
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
semaphore.release();
}
},String.valueOf(i)).start();
}
}
}
18归还了车位,剩余1个车位 22抢夺了车位,剩余0个车位 17归还了车位,剩余0个车位 24抢夺了车位,剩余0个车位 24归还了车位,剩余1个车位 29抢夺了车位,剩余0个车位 28抢夺了车位,剩余0个车位 30抢夺了车位,剩余0个车位 23归还了车位,剩余1个车位 22归还了车位,剩余0个车位 34抢夺了车位,剩余0个车位 30归还了车位,剩余0个车位 35抢夺了车位,剩余0个车位 28归还了车位,剩余1个车位 29归还了车位,剩余0个车位 36抢夺了车位,剩余0个车位 40抢夺了车位,剩余0个车位 34归还了车位,剩余0个车位 35归还了车位,剩余1个车位 36归还了车位,剩余2个车位 21抢夺了车位,剩余1个车位 41抢夺了车位,剩余0个车位 42抢夺了车位,剩余0个车位 41归还了车位,剩余0个车位 46抢夺了车位,剩余0个车位 40归还了车位,剩余0个车位 21归还了车位,剩余1个车位 47抢夺了车位,剩余0个车位 48抢夺了车位,剩余0个车位 42归还了车位,剩余0个车位 46归还了车位,剩余0个车位 52抢夺了车位,剩余0个车位 47归还了车位,剩余0个车位 53抢夺了车位,剩余0个车位 54抢夺了车位,剩余0个车位 52归还了车位,剩余0个车位 53归还了车位,剩余1个车位 58抢夺了车位,剩余0个车位 59抢夺了车位,剩余0个车位 48归还了车位,剩余0个车位 59归还了车位,剩余1个车位 60抢夺了车位,剩余0个车位 58归还了车位,剩余0个车位 54归还了车位,剩余1个车位 65抢夺了车位,剩余0个车位 64抢夺了车位,剩余0个车位 66抢夺了车位,剩余0个车位 64归还了车位,剩余0个车位 65归还了车位,剩余1个车位 60归还了车位,剩余2个车位 25抢夺了车位,剩余1个车位 26抢夺了车位,剩余0个车位 66归还了车位,剩余1个车位 27抢夺了车位,剩余0个车位 26归还了车位,剩余1个车位 25归还了车位,剩余1个车位 31抢夺了车位,剩余1个车位 32抢夺了车位,剩余0个车位 33抢夺了车位,剩余0个车位 27归还了车位,剩余0个车位 32归还了车位,剩余2个车位 31归还了车位,剩余2个车位 39抢夺了车位,剩余0个车位 38抢夺了车位,剩余1个车位 39归还了车位,剩余2个车位 37抢夺了车位,剩余1个车位 43抢夺了车位,剩余0个车位 38归还了车位,剩余2个车位 33归还了车位,剩余1个车位 44抢夺了车位,剩余0个车位 44归还了车位,剩余3个车位 50抢夺了车位,剩余1个车位 45抢夺了车位,剩余2个车位 37归还了车位,剩余3个车位 43归还了车位,剩余3个车位 49抢夺了车位,剩余0个车位 50归还了车位,剩余2个车位 51抢夺了车位,剩余1个车位 45归还了车位,剩余2个车位 55抢夺了车位,剩余0个车位 49归还了车位,剩余1个车位 57抢夺了车位,剩余0个车位 56抢夺了车位,剩余0个车位 61抢夺了车位,剩余1个车位 51归还了车位,剩余1个车位 55归还了车位,剩余1个车位 57归还了车位,剩余0个车位 62抢夺了车位,剩余0个车位 61归还了车位,剩余2个车位 63抢夺了车位,剩余1个车位 62归还了车位,剩余2个车位 67抢夺了车位,剩余0个车位 56归还了车位,剩余1个车位 68抢夺了车位,剩余0个车位 68归还了车位,剩余1个车位 67归还了车位,剩余1个车位 69抢夺了车位,剩余0个车位 73抢夺了车位,剩余0个车位 74抢夺了车位,剩余0个车位 63归还了车位,剩余1个车位 69归还了车位,剩余2个车位 75抢夺了车位,剩余0个车位 73归还了车位,剩余2个车位 70抢夺了车位,剩余0个车位 74归还了车位,剩余1个车位 71抢夺了车位,剩余0个车位 70归还了车位,剩余2个车位 71归还了车位,剩余0个车位 78抢夺了车位,剩余0个车位 77抢夺了车位,剩余1个车位 76抢夺了车位,剩余2个车位 75归还了车位,剩余2个车位 78归还了车位,剩余2个车位 77归还了车位,剩余0个车位 76归还了车位,剩余2个车位 83抢夺了车位,剩余0个车位 7抢夺了车位,剩余1个车位 82抢夺了车位,剩余1个车位 83归还了车位,剩余2个车位 84抢夺了车位,剩余0个车位 79抢夺了车位,剩余0个车位 82归还了车位,剩余2个车位 7归还了车位,剩余0个车位 80抢夺了车位,剩余0个车位 84归还了车位,剩余2个车位 79归还了车位,剩余1个车位 88抢夺了车位,剩余0个车位 81抢夺了车位,剩余1个车位 89抢夺了车位,剩余0个车位 80归还了车位,剩余1个车位 88归还了车位,剩余1个车位 89归还了车位,剩余2个车位 86抢夺了车位,剩余1个车位 85抢夺了车位,剩余0个车位 81归还了车位,剩余1个车位 87抢夺了车位,剩余0个车位 87归还了车位,剩余0个车位 85归还了车位,剩余1个车位 90抢夺了车位,剩余0个车位 91抢夺了车位,剩余0个车位 86归还了车位,剩余1个车位 92抢夺了车位,剩余0个车位 94抢夺了车位,剩余0个车位 92归还了车位,剩余2个车位 91归还了车位,剩余1个车位 90归还了车位,剩余2个车位 95抢夺了车位,剩余1个车位 96抢夺了车位,剩余0个车位 95归还了车位,剩余2个车位 96归还了车位,剩余2个车位 94归还了车位,剩余3个车位 93抢夺了车位,剩余2个车位 97抢夺了车位,剩余1个车位 98抢夺了车位,剩余0个车位 99抢夺了车位,剩余0个车位 98归还了车位,剩余0个车位 97归还了车位,剩余1个车位 93归还了车位,剩余2个车位 99归还了车位,剩余3个车位
发现不会超过三个也不会小于0个
抢到了信号量才会执行下面的语句
11.ReadWriteLockDemo
class MyCache {
//volatile:,保证可见性,不保证原子性,一个线程修改后,通知更新
private volatile Map<String, Object> map = new HashMap<>();
private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
public void put(String key, Object value) {
readWriteLock.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "\t--写入数据" + key);
//暂停一会线程
try {
TimeUnit.MICROSECONDS.sleep(300);
} catch (Exception e) {
e.printStackTrace();
}
map.put(key, value);
System.out.println(Thread.currentThread().getName() + "\t--写入完成");
} catch (Exception e) {
e.printStackTrace();
} finally {
readWriteLock.writeLock().unlock();
}
}
public void get(String key) {
readWriteLock.readLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "\t读取数据");
Object result = map.get(key);
System.out.println(Thread.currentThread().getName() + "\t读取完成" + result);
} catch (Exception e) {
e.printStackTrace();
} finally {
readWriteLock.readLock().unlock();
}
}
}
/**
* 多个线程同时读一个资源类没有任何问题,所以为了满足并发量,读取共享资源应该可以同时进行。
* 但是,如果有一个线程想去写共享资源来,就不应该再有其他线程可以对改资源进行读或写
* 小总结:
* 读-读能共存
* 读-写不能共存
* 写-写不能共存
*/
public class ReadWriteLockDemo11 {
public static void main(String[] args) {
MyCache myCache = new MyCache();
for (int i = 1; i <= 5; i++) {
final int tempInt = i;
new Thread(()->{
myCache.put(tempInt+"",tempInt+"");
},String.valueOf(i)).start();
}
for (int i = 1; i <= 5; i++) {
final int tempInt = i;
new Thread(()->{
myCache.get(tempInt+"");
},String.valueOf(i)).start();
}
}
}
0进行了写入
0写入完成
1进行了写入
1写入完成
2进行了写入
2写入完成
3进行了写入
3写入完成
4进行了写入
4写入完成
5进行了写入
5写入完成
6进行了读取操作
7进行了读取操作
8进行了读取操作
9进行了读取操作
10进行了读取操作
11进行了读取操作
11读取完成
7读取完成
8读取完成
9读取完成
6读取完成
10读取完成
/**
- 多个线程同时读一个资源类没有任何问题,所以为了满足并发量,读取共享资源应该可以同时进行。
- 但是,如果有一个线程想去写共享资源来,就不应该再有其他线程可以对改资源进行读或写
- 小总结:
-
**读-读能共存** -
**读-写不能共存** -
**写-写不能共存**
*/
12.BlockingQueue种类
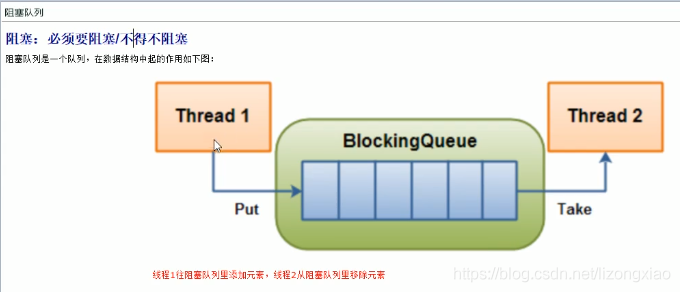

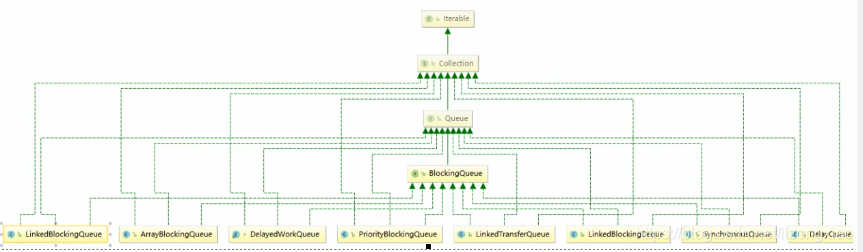
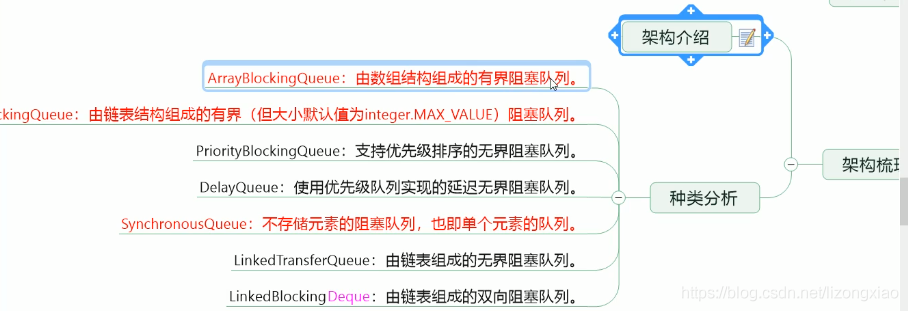
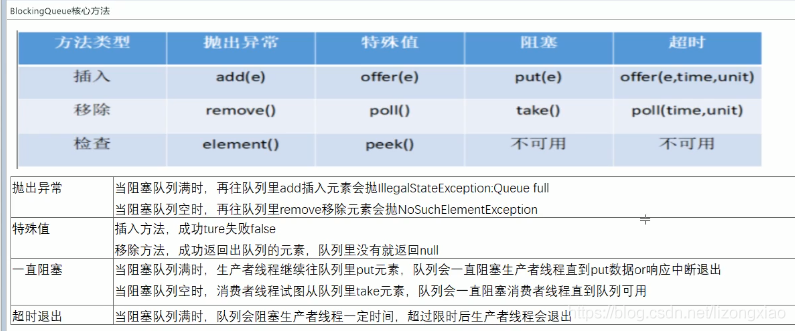
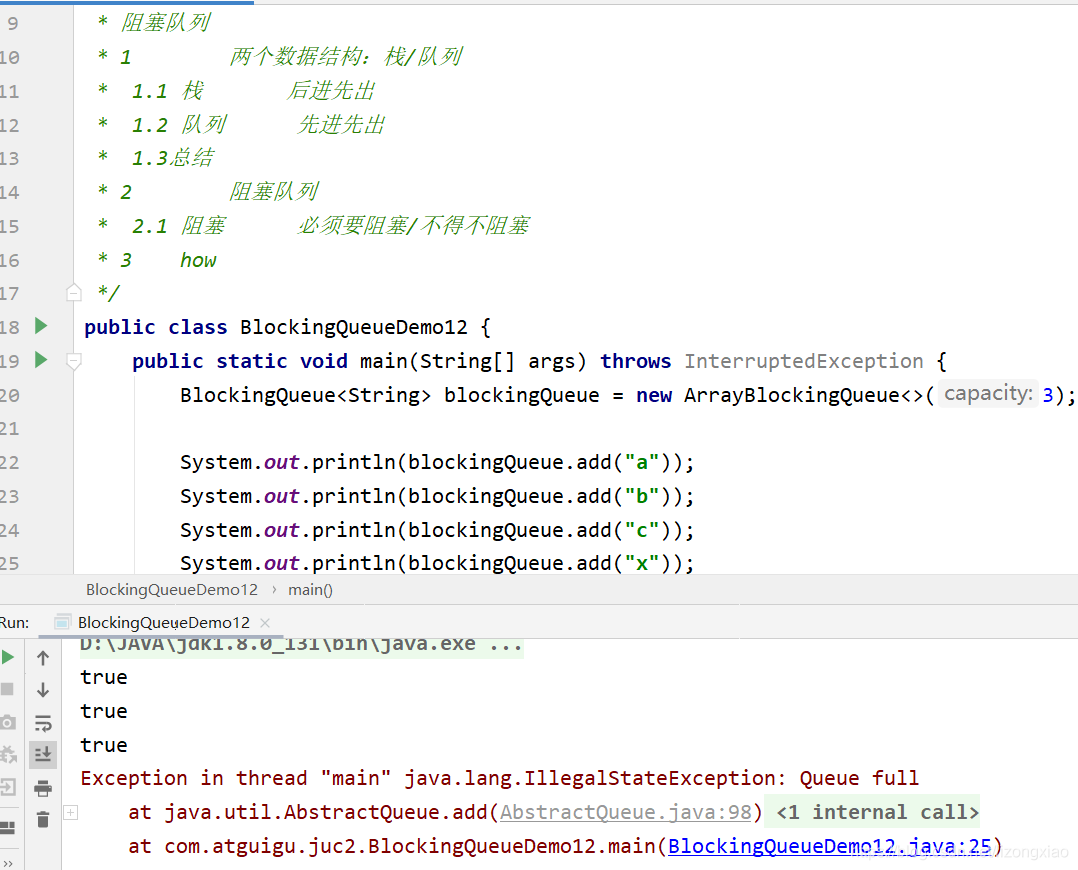
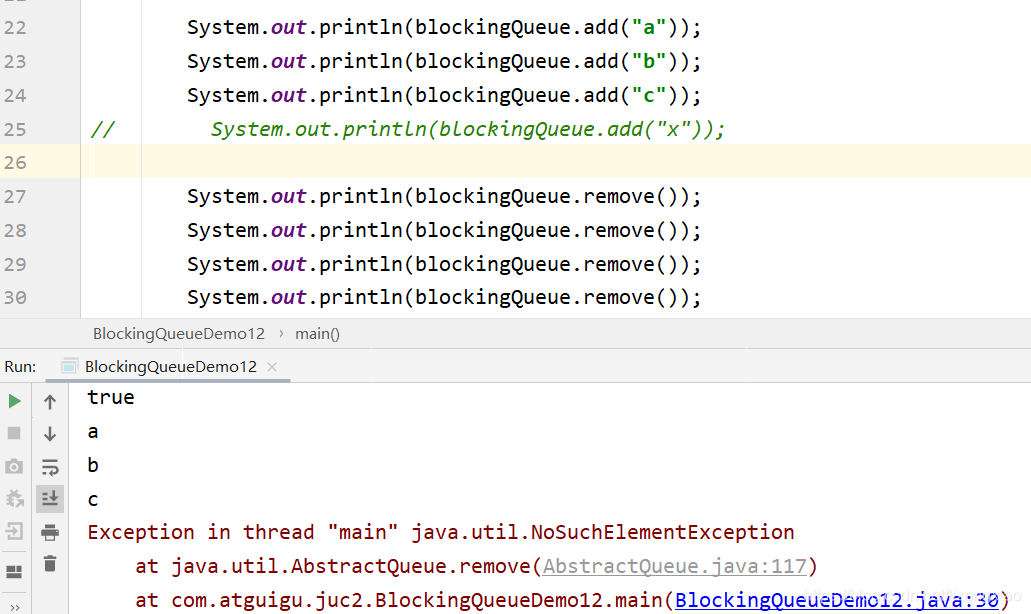
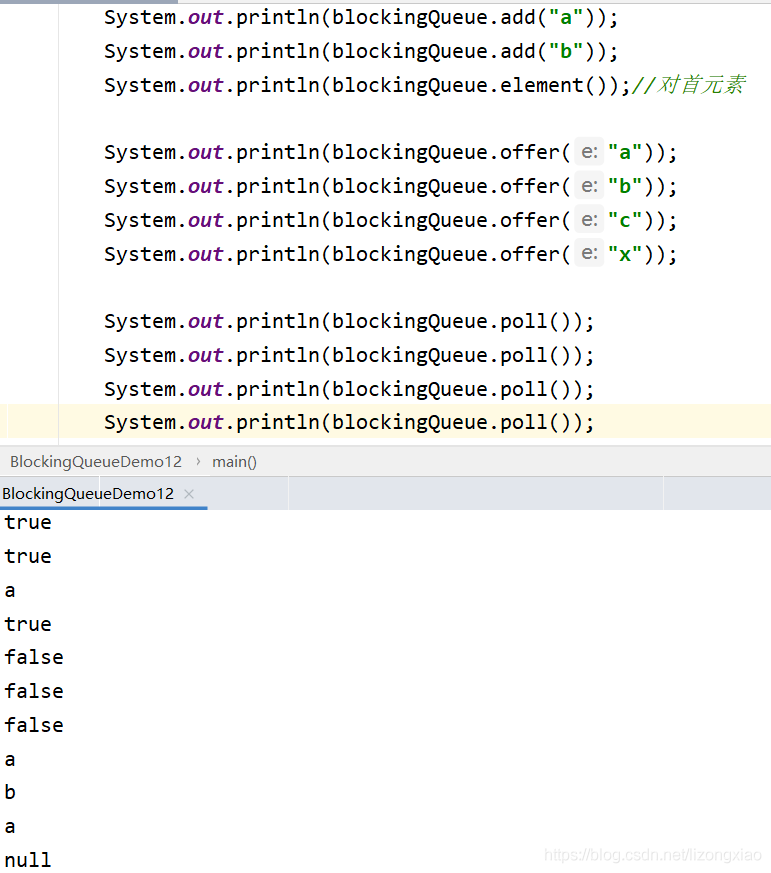
14.线程池

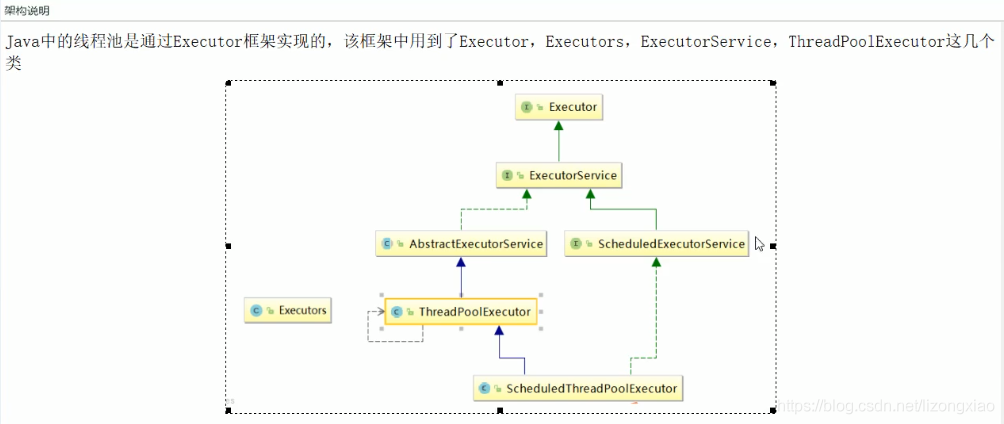
第一种

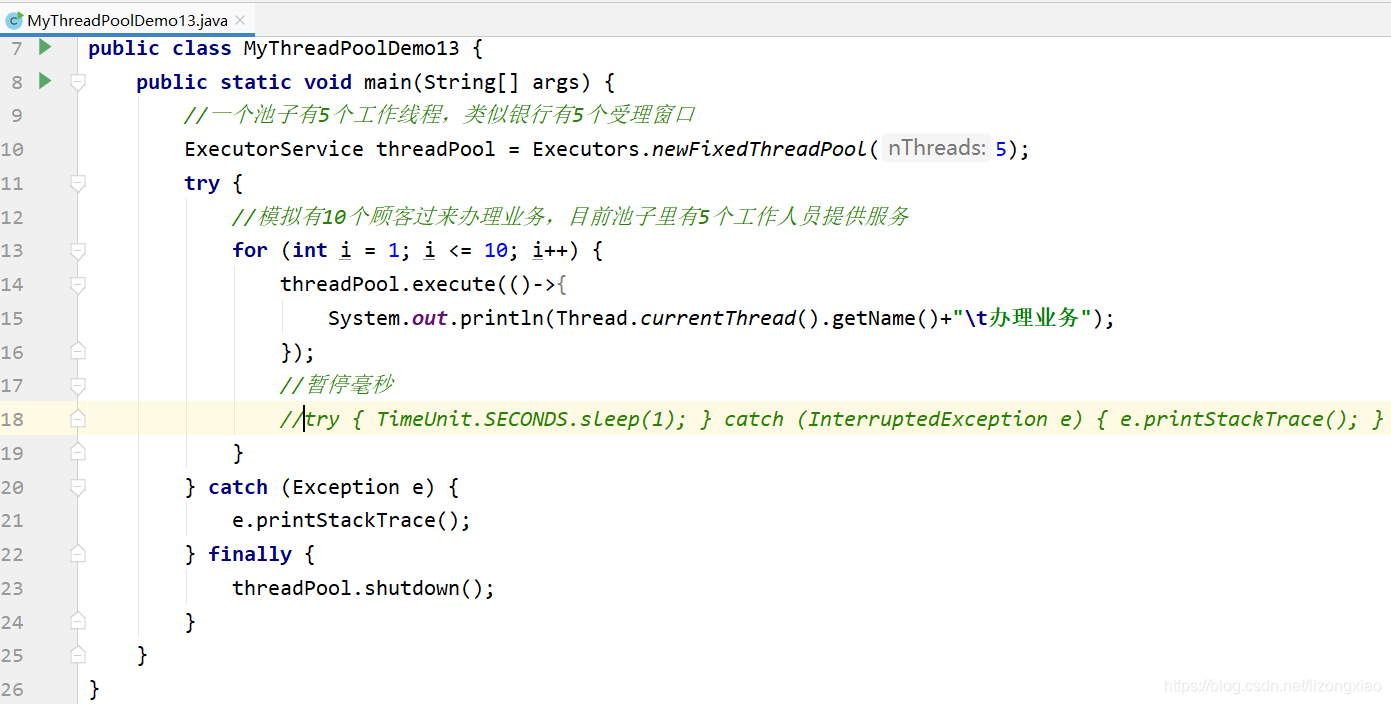

第二种

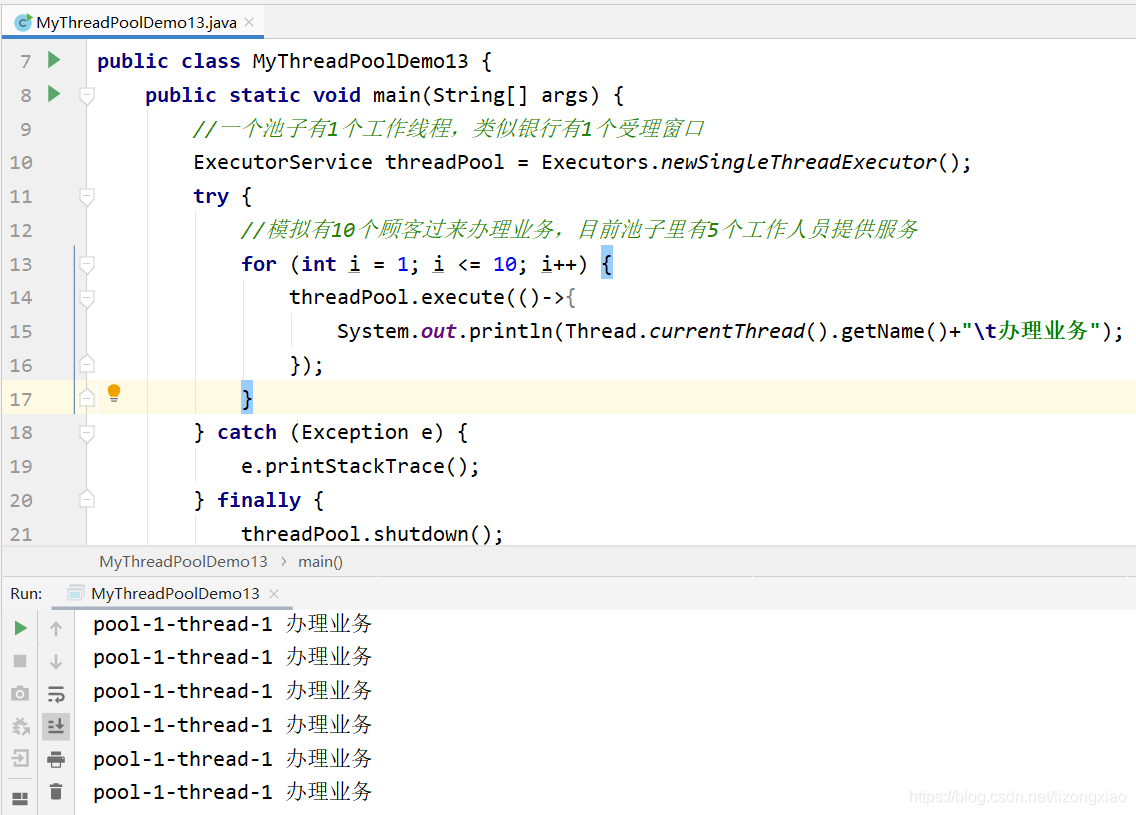
第三种

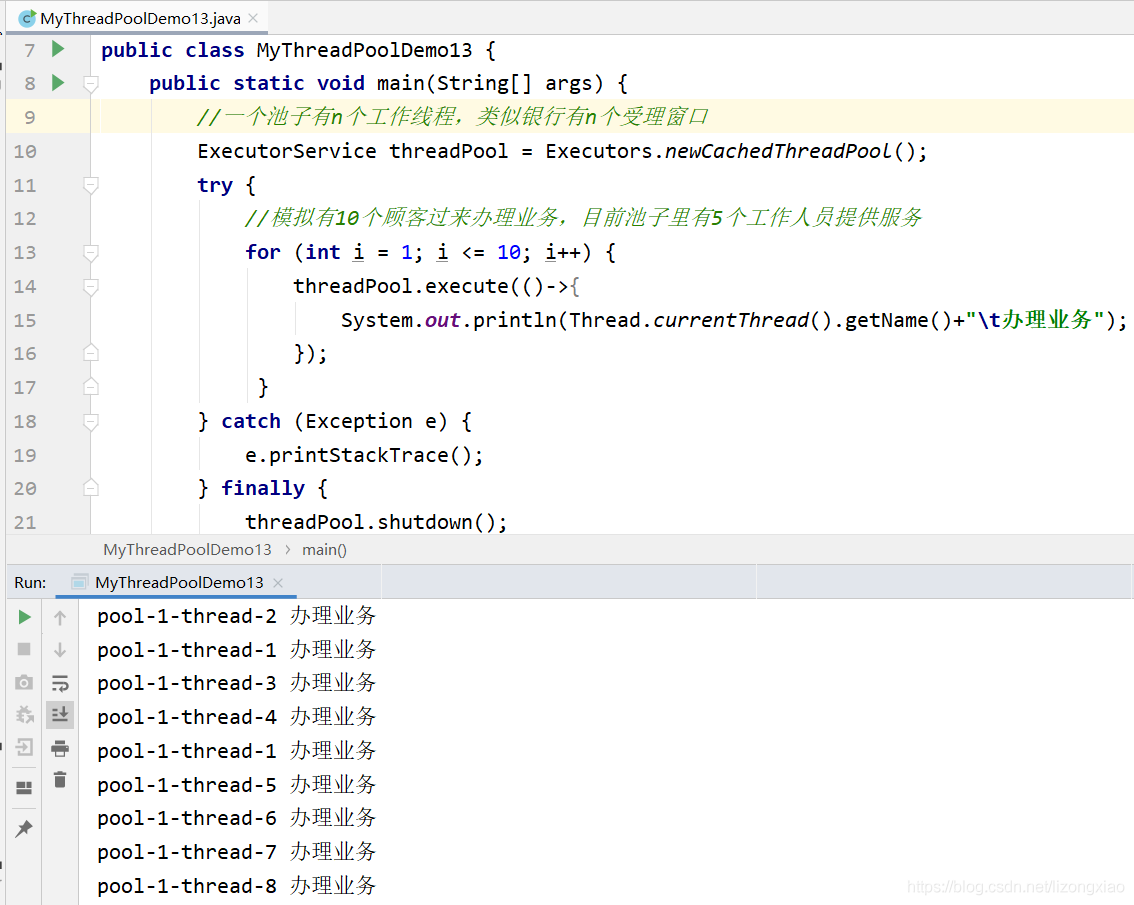
每次创建线程暂停300毫秒,发现
for (int i = 0; i < 10; i++) {
try {
Thread.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
executorService.execute(()->{
System.out.println(Thread.currentThread().getName()+"创建了线程");
});
}
newCachedThreadPool()随着一瞬间的创建的线程数自己发生变化,
15.ThreadPoolExecutor底层原理
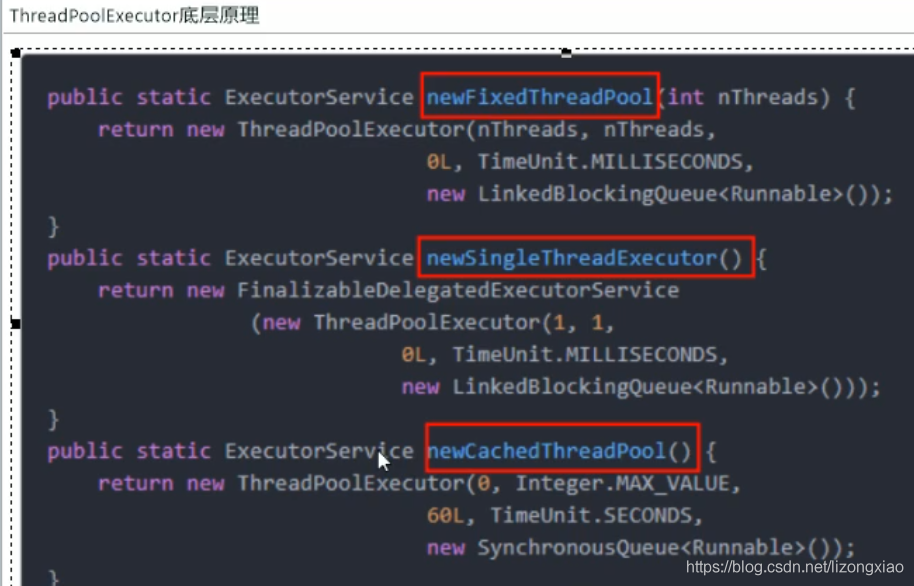
16.线程池里7大参数

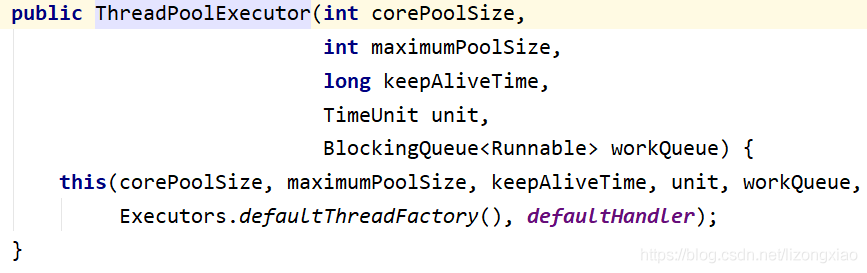

public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
17.线程池底层工作原理
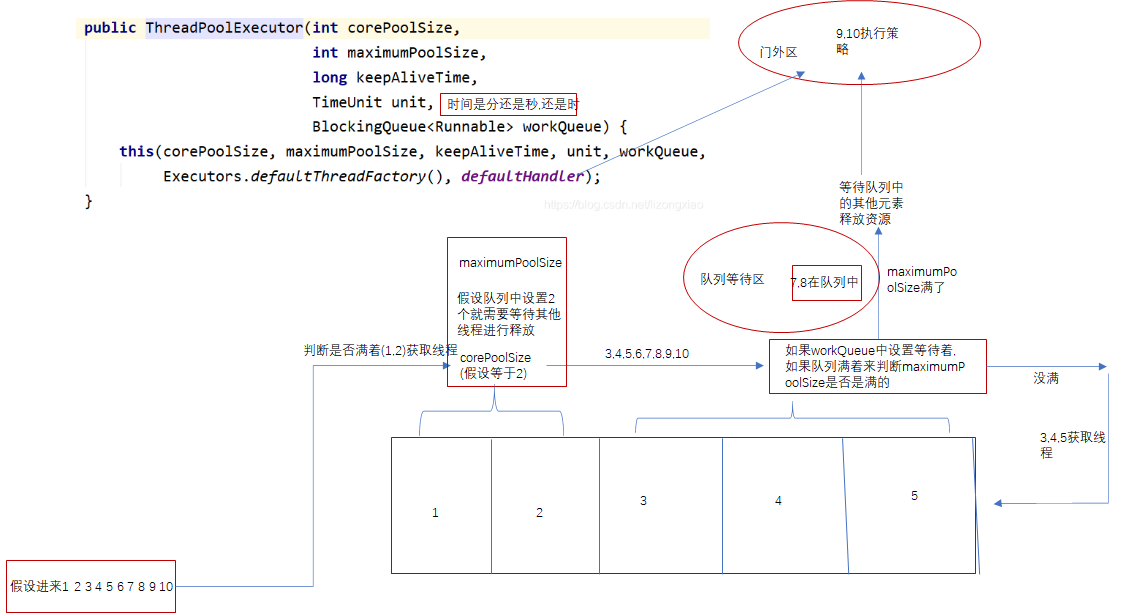
keepAliveTime是表示maximumPoolSize里面的线程池的有多少空余时间就 释放
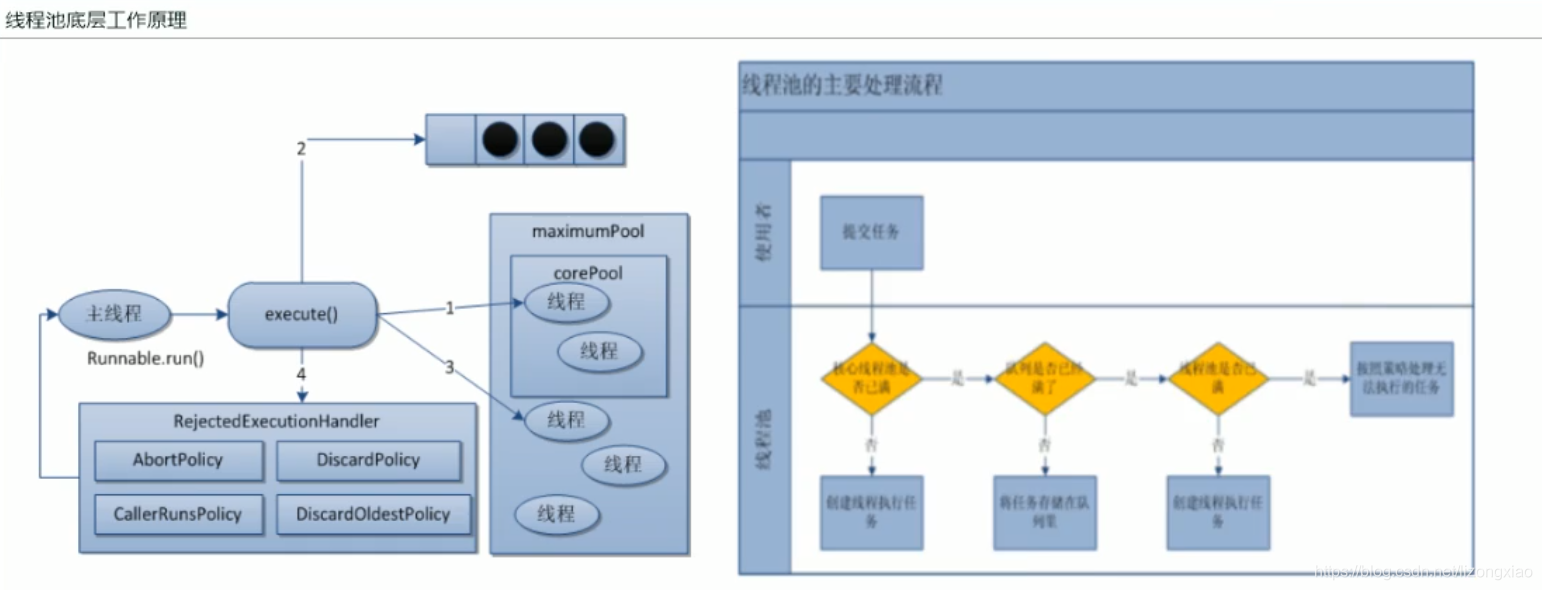
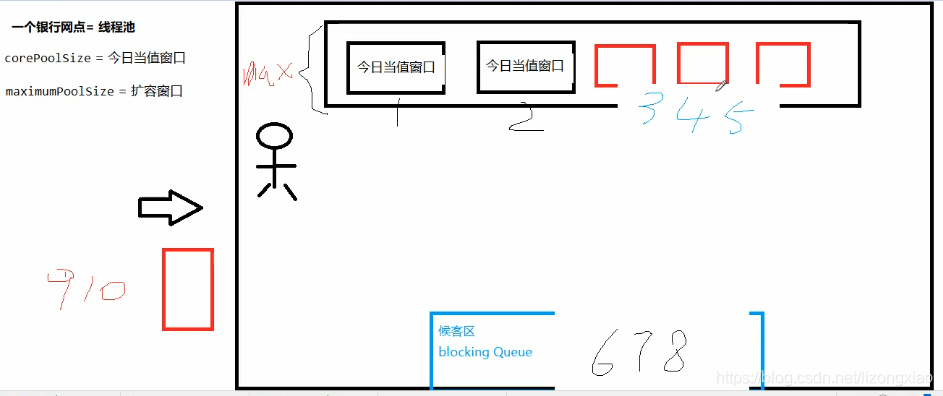

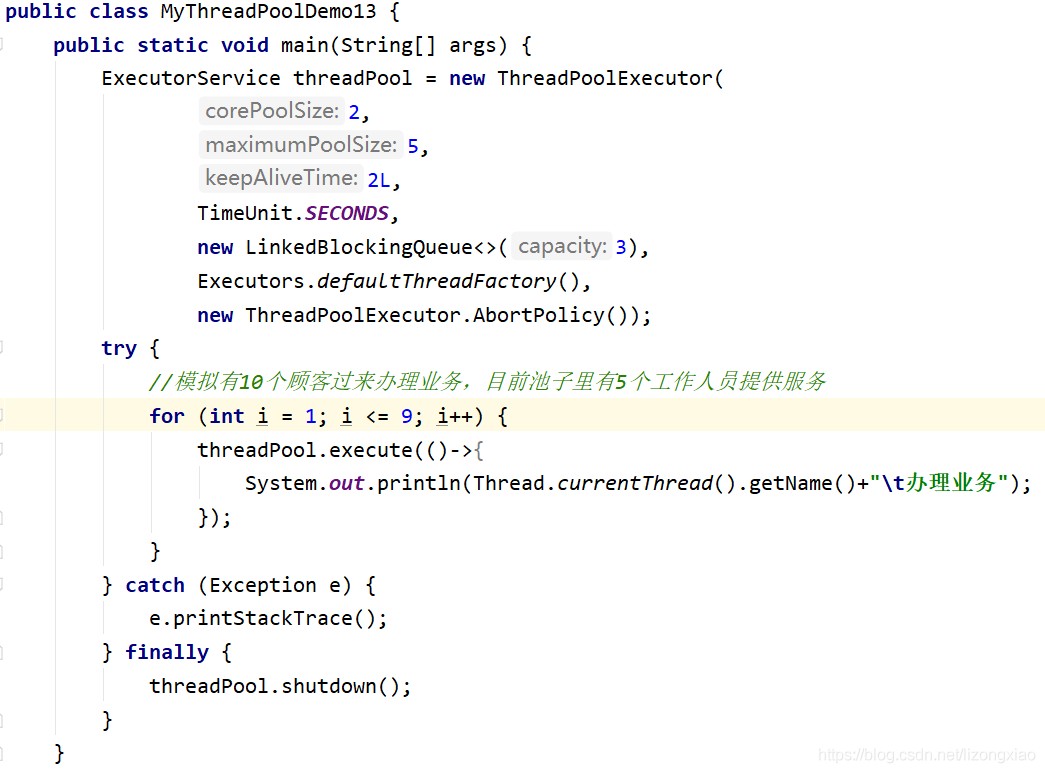

处理策略
callerRunsPolicy会让主线程去执行
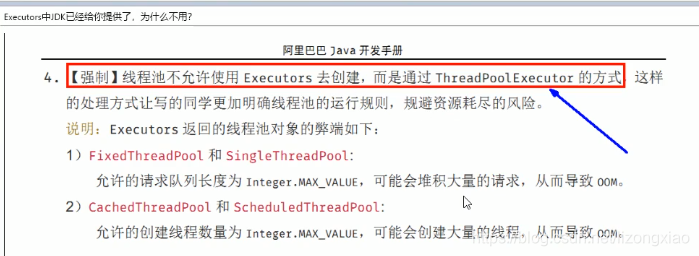

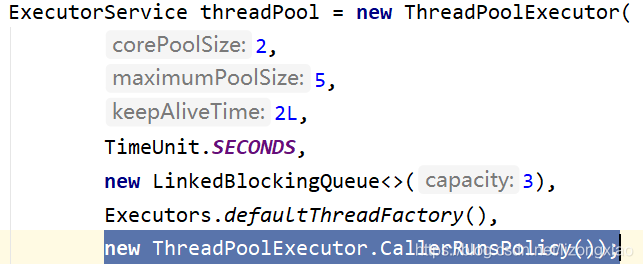

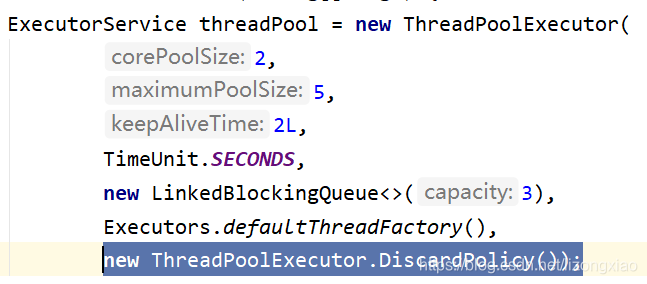

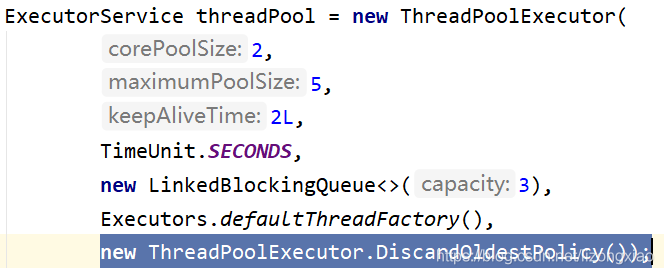

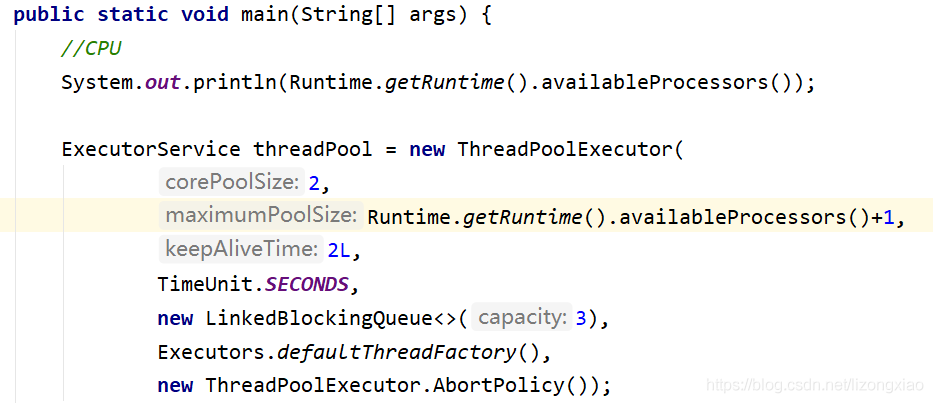
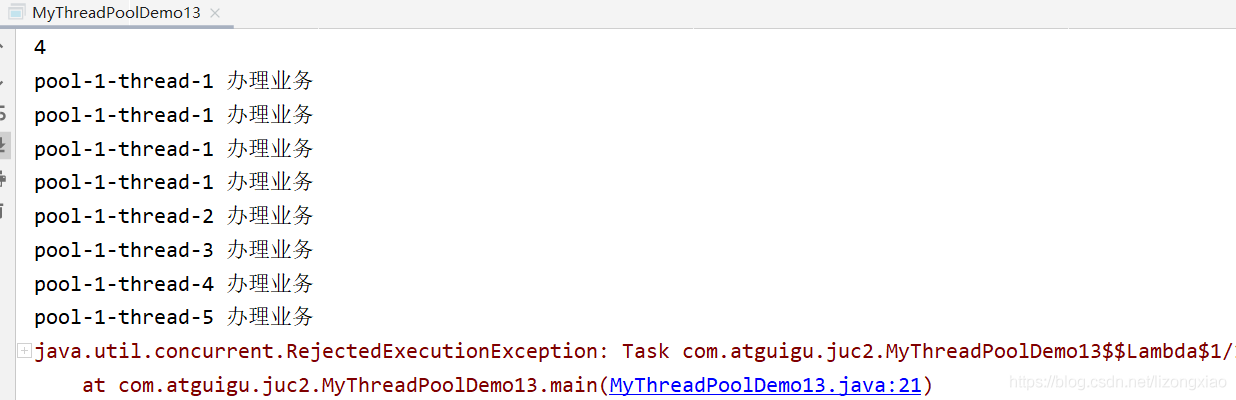
import java.util.concurrent.*;
/**
* @author 10185
* @create 4/18/2021 10:42 AM
*/
public class ThreadPool {
public static void main(String[] args) {
ThreadPoolExecutor executorService = new ThreadPoolExecutor(2, 5, 2L, TimeUnit.SECONDS, new LinkedBlockingQueue<>(3), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy());
try {
for (int i = 0; i < 10; i++) {
/* try {
Thread.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}*/
executorService.execute(()->{
System.out.println(Thread.currentThread().getName()+"创建了线程");
});
}
} catch (Exception e) {
e.printStackTrace();
}finally {
executorService.shutdown();
}
}
}
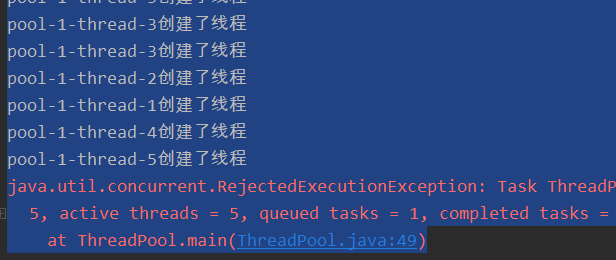
18.四大函数式接口
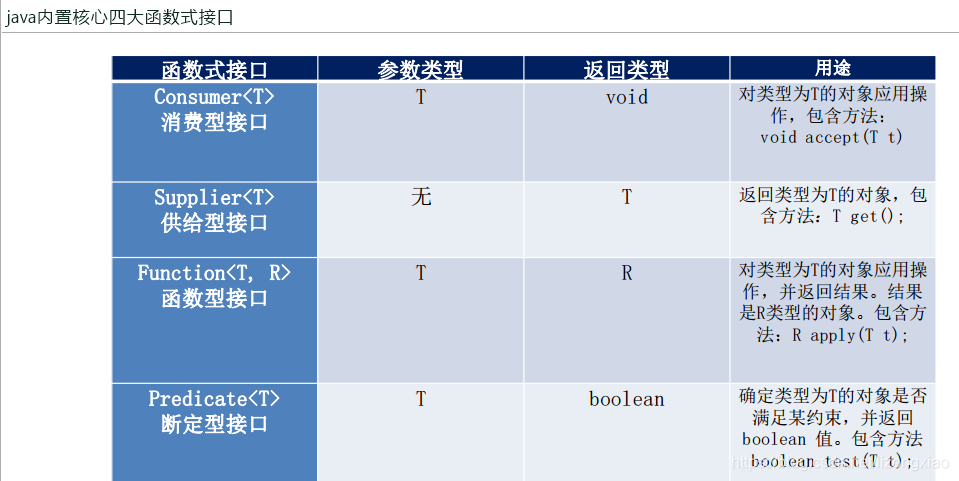
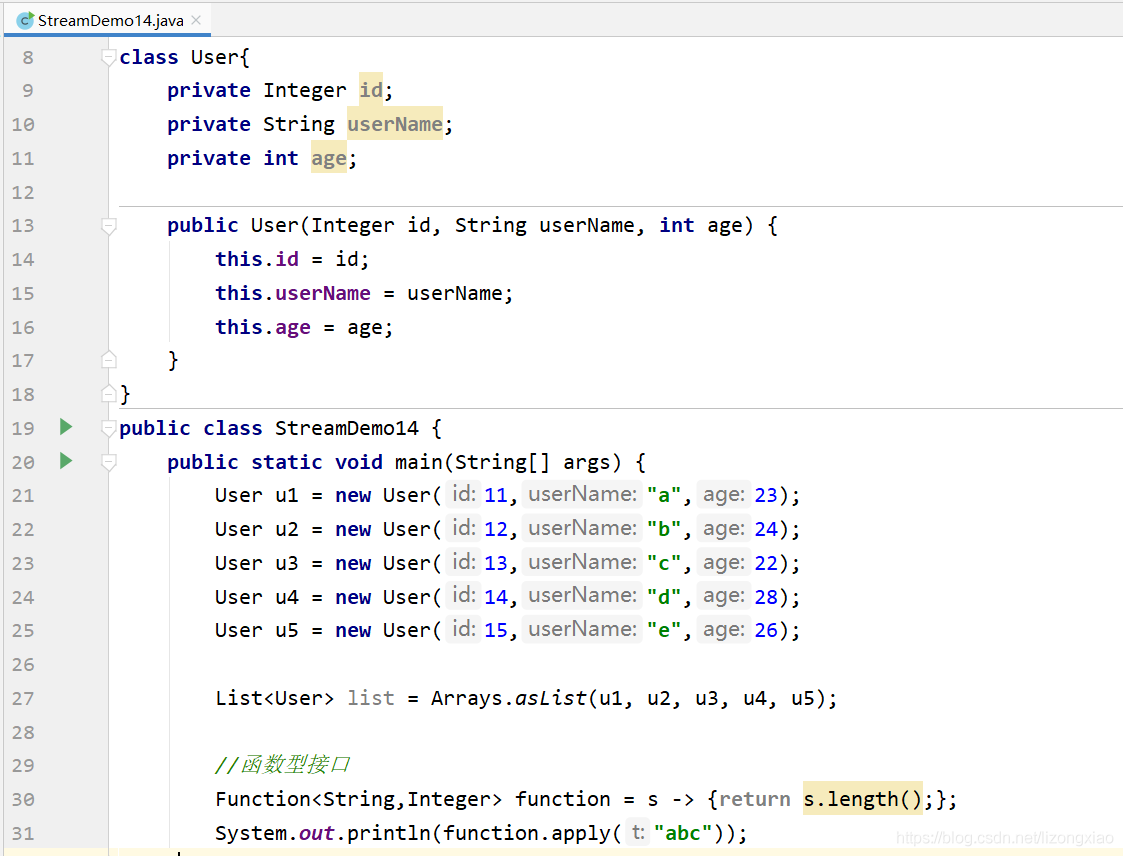
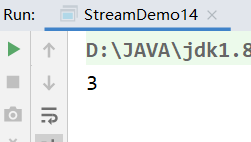
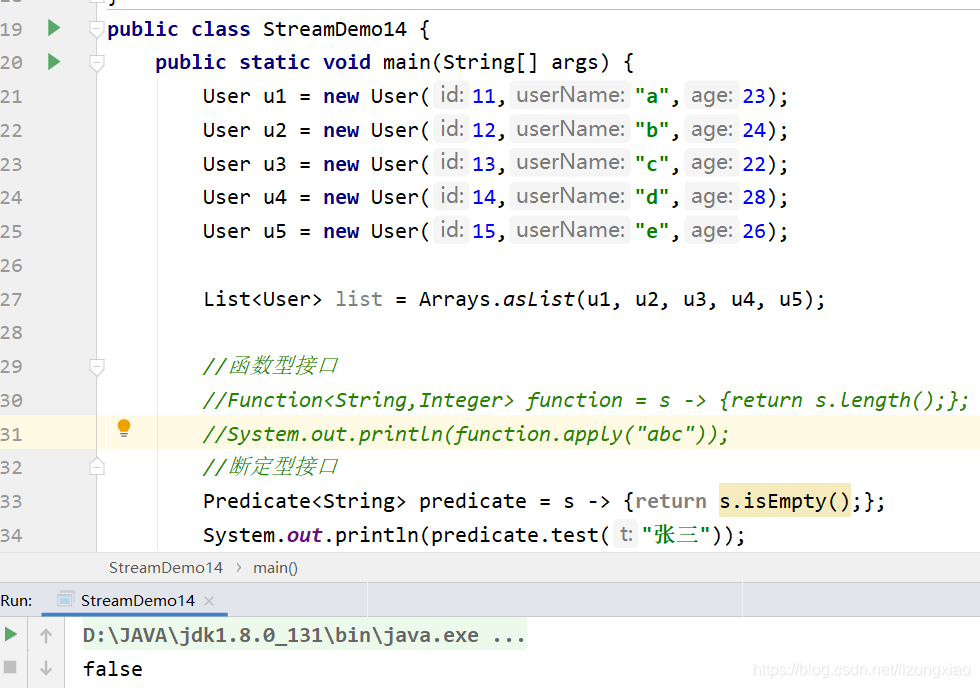
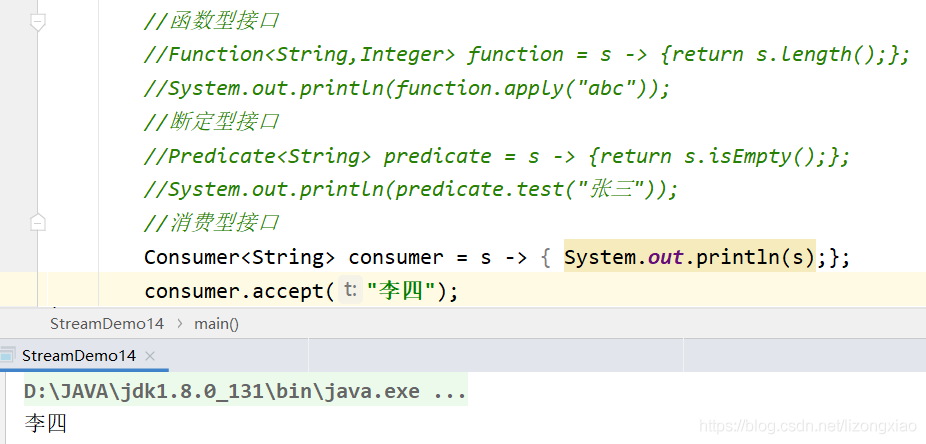
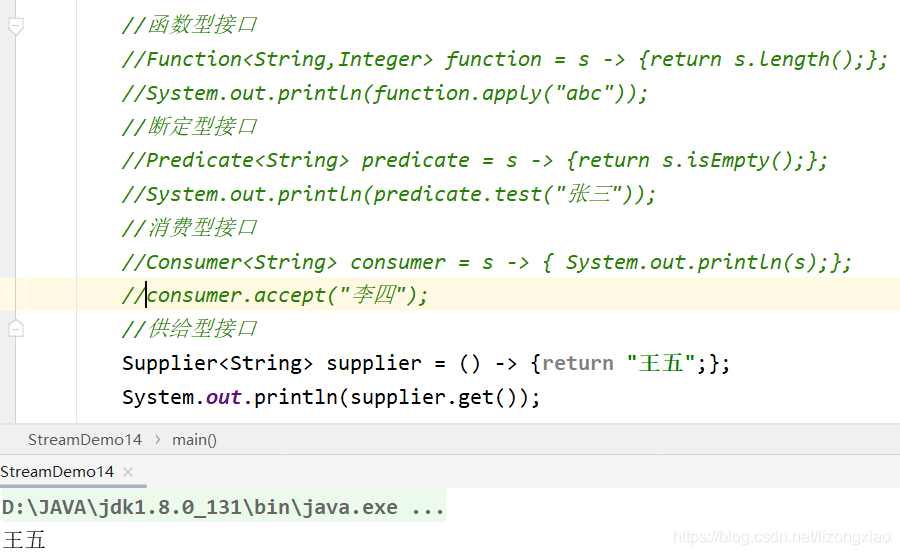
19.Stream流式计算
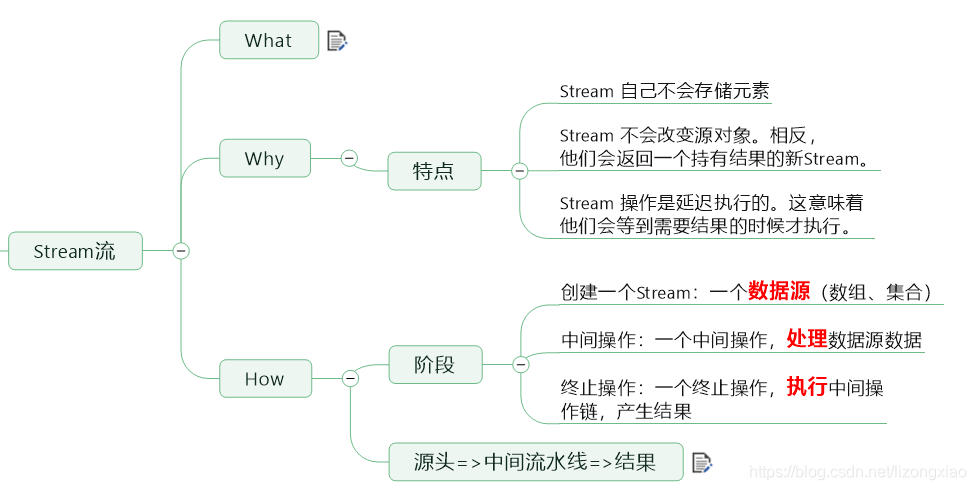

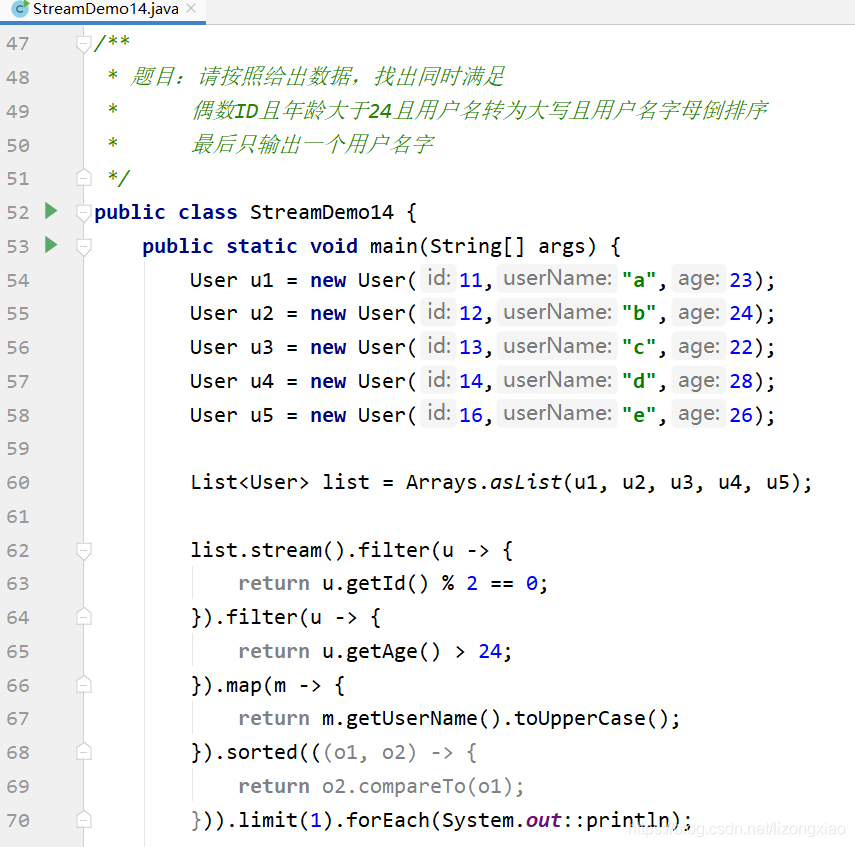
20.ForkJoinDemo(分支执行)
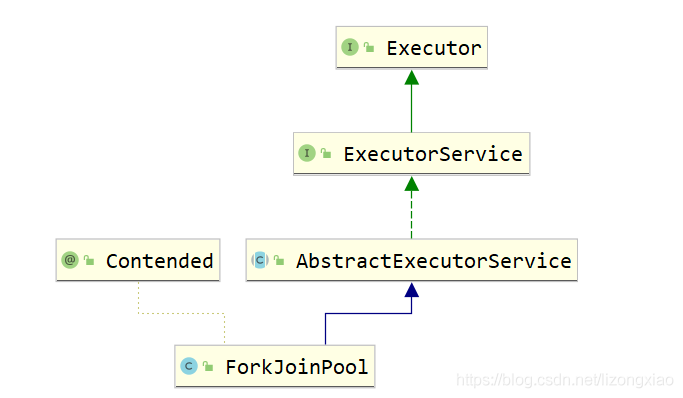
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
/**
* @author 10185
* @create 4/18/2021 3:45 PM
*/
public class ForkJoinDemo extends RecursiveTask<Integer> {
//定义一个常用,只要超过这个常量就会进行分线程执行
private static final Integer JOIN_NUMBER = 10;
private int begin;
private int end;
public ForkJoinDemo(int begin, int end) {
this.begin = begin;
this.end = end;
}
private Integer sum(Integer begin, Integer end) {
int result = 0;
for (int i = begin; i < end ; i++) {
result += i;
}
return result;
}
@Override
protected Integer compute() {
if (end - begin <= JOIN_NUMBER) {
return sum(begin, end);
} else {
ForkJoinDemo forkJoinDemo = new ForkJoinDemo(begin, begin + JOIN_NUMBER);
ForkJoinDemo forkJoinDemo1 = new ForkJoinDemo(begin + JOIN_NUMBER, end);
//启动两个线程
forkJoinDemo.fork();
forkJoinDemo1.fork();
//调用join方法,里面调用的是compute函数
return forkJoinDemo.join()+forkJoinDemo1.join();
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
ForkJoinDemo forkJoinDemo = new ForkJoinDemo(0, 100);
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Integer> submit = forkJoinPool.submit(forkJoinDemo);
System.out.println(submit.get());
forkJoinPool.shutdown();
}
}
结果
4950
21.CompletableFutureDemo

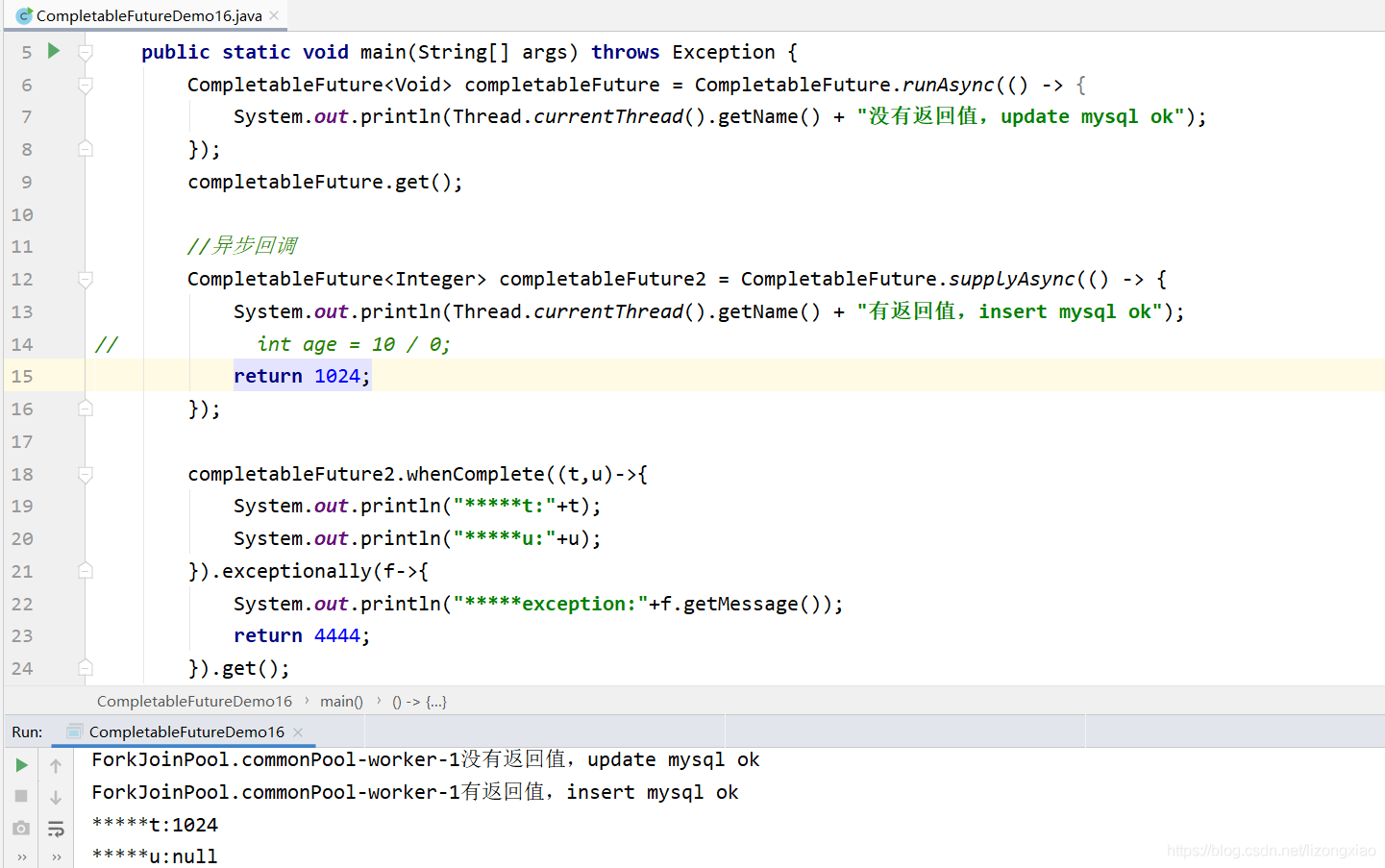
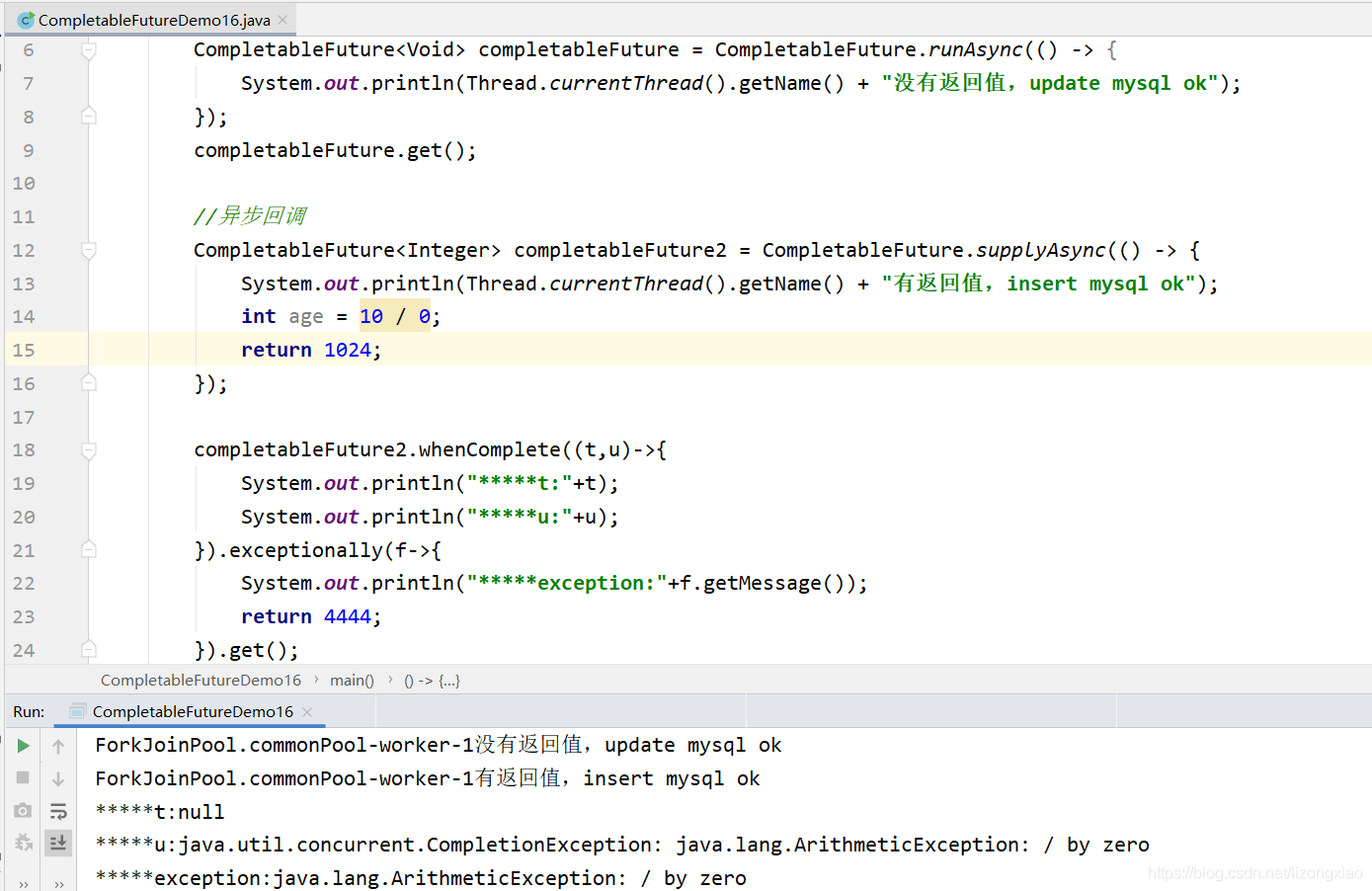
类似于ajax异步执行
Docker
第一章 Docker简介
是什么?
问题:为什么会有 docker 的出现
一款产品从开发到上线,从操作系统,到运行环境,再到应用配置。作为开发+运维之间的协作我们需要关心很多东西,这也是很多互联网公司都不得不面对的问题,特别是各种版本的迭代之后,不同版本环境的兼容,对运维人员都是考验 Docker 之所以发展如此迅速,也是因为它对此给出了一个标准化的解决方案。 环境配置如此麻烦,换一台机器,就要重来一次,费力费时。很多人想到,能不能从根本上解决问题,软件可以带环境安装也就是说,安装的时候,把原始环境一模一样地复制过来。开发人员利用Docker可以消除协作编码时“在我的机器上可正常工作”的问题。
之前在服务器配置一个应用的运行环境,要安装各种软件,就拿尚硅谷电商项目的环境来说吧,Java/TomcatMySQL/JDBC驱动包等。安装和配置这些东西有多麻烦就不说了,它还不能跨平台。假如我们是在Windows上安装的这些环境,到了Linux 又得重新装。况且就算不跨操作系统,换另一台同样操作系统的服务器,要移植应用也是非常麻烦的。
传统上认为,软件编码开发/测试结束后,所产出的成果即是程序或是能够编译执行的二进制字节码等java为例)。而为了让这程序可以顺利执行,开发团队也得准备完整的部署文件,让维运团队得以部署应用程式,开发需要清楚的告诉运维部署团队,用的全部配置文件+所有软件环境。不过,即便如此,仍然常常发生部署失败的状况。Docker镜 像的设计,使得Docker得以打过去「程序即应用」的观念。透过镜像(images)将作业系统核心除外,运作应用程式所需要的系统环境,由下而上打包,达到应用程式跨平台间的无缝接轨运.作。
docker理念
Docker是基于Go语言实现的云开源项目。 Docker的主要目标是“Build, Ship[ and Run Any App,Anywhere",也就是通过对应用组件的封装、分发、部署、运行等生命期的管理,使用户的APP (可以是一个WEB应用或数据库应用等等)及其运行环境能够做到“一次封装,到处运行”。
Linux容器技术的出现就解决了这样一 一个问题,而Docker就是在它的基础上发展过来的。将应用运行在Docker容器上面,而Docker容器在任何操作系统上都是一-致的,这就实现了跨平台、跨服务器。只需要一次配置好环境,换到别的机子上就可以一键部署好,大大简化了操作
一句话
解决了运行环境和配置问题的软件容器,方便做持续集成并有助于整体发布的容器虚拟化技术
能干嘛
之前的虚拟机技术
虚拟机**(virtual machine)**就是带环境安装的一种解决方案。
它可以在一种操作系统里面运行另一种作系统,比如在Windows系统里面运行Linux系统。应用程序对此毫无感知,因为虚拟机看上去跟真实系统一模一样,而对于底层系统来说,虚拟机就是一个普通文件,不需要了就删掉,对其他部分毫无影响。这类虚拟机完美的运行了另一套系统,能够使应用程序,操作系统和硬件三者之间的逻辑不变。
虚拟机的缺点:
1、资源占用多
2、冗余步骤多
3、启动慢
容器虚拟化技术
由于前面虛拟机存在这些缺点,Linux 发展出了另一种虚拟化技术: Linux 容器(Linux Containers,缩为LXC)。
Linux容器不是模拟一个完整的操作系统,而是对进程进行隔离。有了容器,就可以将软件运行所的所有资源打包到一个隔离的容器中。容器与虚拟机不同,不需要捆绑一整套操作系统,只需要软件工作所需的库资源和设置。系统因此而变得高效轻量并保证部署在任何环境中的软件都能始终如一地运行。.
比较了Docker和传统虚拟化方式的不同之处:
1、传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;
2、而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机为轻便。
3、每个容器之间互相隔离,每个容器有自己的文件系统,容器之间进程不会相互影响,能区分计算资源。
开发/运维(DevOps)
一次构建、随处运行,
更快速的应用交付和部署
传统的应用开发完成后,需要提供一堆安装程序和配置说明文档,安装部署后需根据配置文档进行繁杂的配置才能正常运行。Docker化
之后只需要交付少量容器镜像文件,在正式生产环境加载镜像并运行即可,应用安装配置在镜像里已经内置好,大大节省部署配置和测 试验证时间。
更便捷的升级和扩缩容
随着微服务架构和Docker的发展,大量的应用会通过微服务方式架构,应用的开发构建将变成搭乐高积木一样,每个Docker容器将变成-块“积木”,应用的升级将变得非常容易。当现有的容器不足以支撑业务处理时,可通过镜像运行新的容器进行快速扩容,使应用系统的扩容从原先的天级变成分钟级甚至秒级。
更简单的系统运维
应用容器化运行后,生产环境运行的应用可与开发、测试环境的应用高度--致,容器会将应用程序相关的环境和状态完全封装起来,不会因为底层基础架构和操作系统的不一致性给应用带来影响,产生新的BUG。当出现程序异常时,也可以通过测试环境的相同容器进行快速定位和修复。
更高效的计算资源利用
**Docker是内核级虚拟化**,其不像传统的虚拟化技术一样 需要额外的Hypervisor支持,所以在-台物理机上可以运行很多个容器实例,可大大提升物理服务器的CPU和内存的利用率。
企业级
新浪

美团
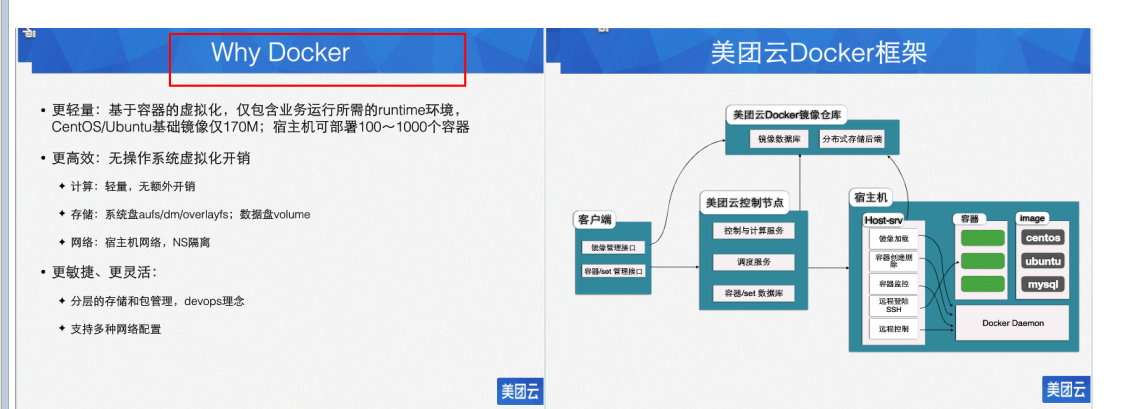
蘑菇街

去哪下
1、官网
docker官网: https://www.docker.com/
docker中文网站: https://www.docker-cn.com/
2、仓库
Docker Hub官网:https://hub.docker.com/
第二章 Docker安装
前提说明
CentOS Docker安装 Docker支持以下的CentOS版本: CentOS 7 (64-bit) CentOS 6.5 (64-bit)或更高的版本
前提条件 目前,CentOS 仅发行版本中的内核支持Docker。 Docker运行在CentOS 7.上,要求系统为64位、系统内核版本为3.10以上。 Docker运行在CentOS-6.5或更高的版本的CentOS上,要求系统为64位、系统内核版本为2.6.32-431或者更高版本。

Docker 的基本组成
docker架构图

Client本地 ==》Docker_host服务器 ==》远程库 ==》镜像 或者 容器 ==》本地pull
镜像( image )
Docker镜像(lmage)就是一个只读的模板不能修改。镜像可以用来创建Docker容器,一个镜像可以创建很多容器
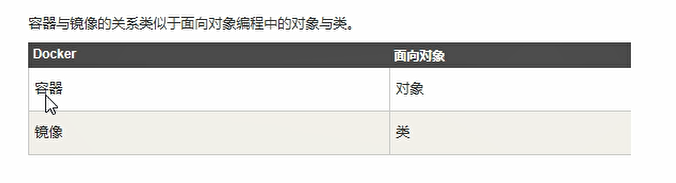
容器( container)
Docker利用容器(Container) 独立运行的一个或一组应用。容器是用镜像创建的运行实例。 它可以被启动、开始、停止、删除。每个容器都是相互隔离的、保证安全的平台。 可以把容器看做是一个简 易版的Linux环境(包括root用户权限、进程空间、用户空间和网络空间等)和运行在其中的应用程序。 容器的定义和镜像几乎一模一样,也是一堆层的统一视角, 唯一区别在于容器的最上面那-层是可读可写的。
仓库( repository)
仓库(Repository) 是集中存放镜像文件的场所。 仓库(Repository)和仓库注册服务器(Registry) 是有区别的。仓库注册服务器上往往存放着多个仓库,每个仓库中又包含了多镜像,每个镜像有不同的标签(tag) 。仓库分为公开仓库(Public) 和私有仓库(Private) 两种形式。 最大的公开仓库是Docker Hub(ttps://hub. docker.com/) 存放了数量庞大的镜像供用户下载。国内的公开仓库包括阿里云、网易云等
小总结 ()
需要正确的理解仓储/镜像/容器这几个概念:
Docker本身是一个容器运行载体或称之为管理引擎。我们把应用程序和配置依赖打包好形成一-个可交付的运行环境,这个打好的运行环境就似乎image镜像文件。只有通过这个镜像文件才能生成Docker容器。image文件可以看作是容器的模板。Docker根据image文件生成容器的实例。同一个image文件,可以生成多个同时运行的容器实例。
image文件生成的容器实例,本身也是一一个文件,称为镜像文件。
一个容器运行一种服务,当我们需要的时候,就可以通过docker客户端创建一-个对应的运行实例,也就是我们的容器至于仓储,就是放了一堆镜像的地方,我们可以把镜像发布到仓储中,需要的时候从仓储中拉下来就可以了。|
安装步骤
Centos6.8安装Docker
1、yum install -y epel-release
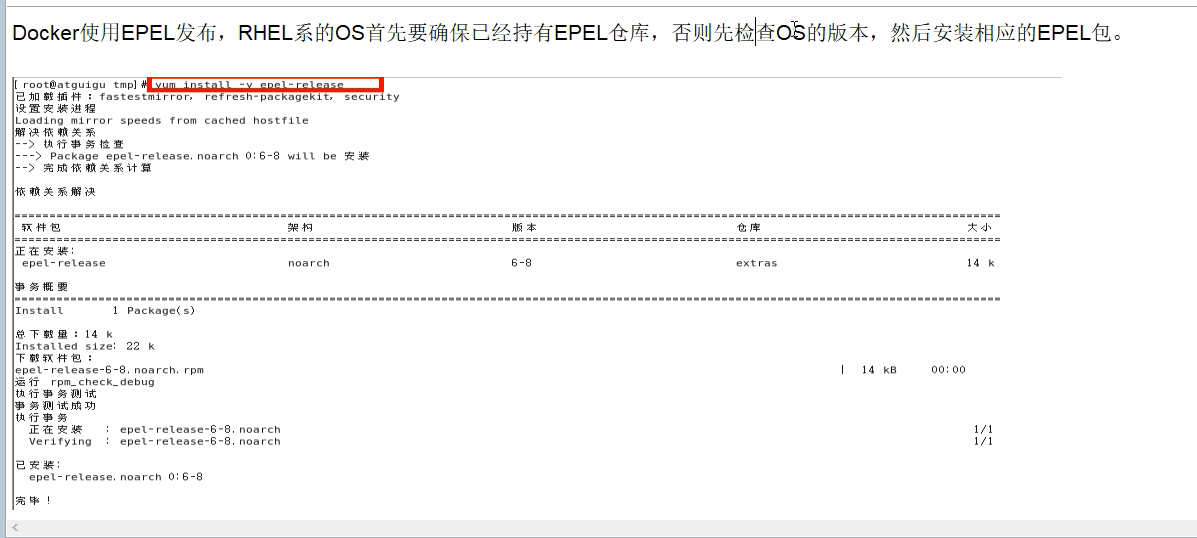
2、yum install -y docker-io

3、安装后的配置文件: etc/sysconfig/docker
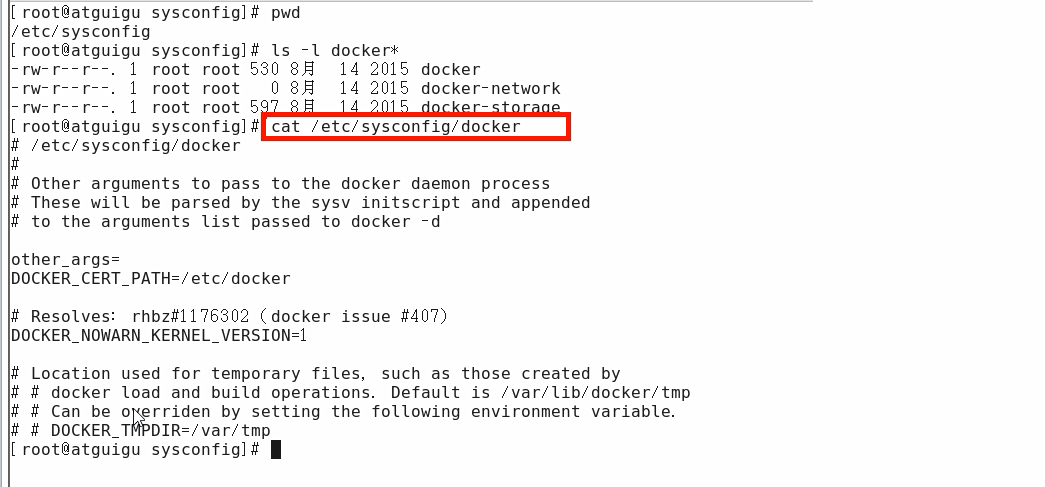
4、启动 Docker后台服务: service docker start
5、docker version 验证
Centos7.0安装Docker
https://docs.docker.com/engine/install/centos/
1 卸载当前有的docker
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
2 安装仓库
$ sudo yum install -y yum-utils
$ sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
3 安装docker容器
sudo yum install docker-ce docker-ce-cli containerd.io
4 启动docker
sudo systemctl start docker
5 测试helloworld
sudo docker run hello-world
阿里云镜像加速
是什么
配置镜像加速器 针对Docker客户端版本大于 1.10.0 的用户
您可以通过修改daemon配置文件/etc/docker/daemon.json来使用加速器
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://dafzi05e.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
查看是否配置成功
docker info

run干了什么
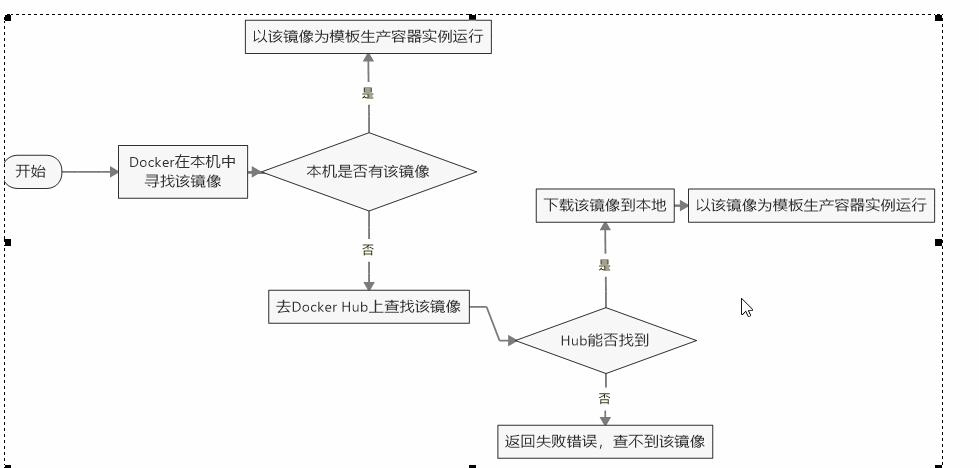
底层原理
Docker是怎样工作的
Docker是一个Client-Server结构的系统,Docker守 护进程运行在主机上,然后通过Socket连 接从客户端访问,守护进程从客户端接受命令并管理运行在主机上的容器。容器,是一个运行时环境,就是我们前面说到的集装箱。
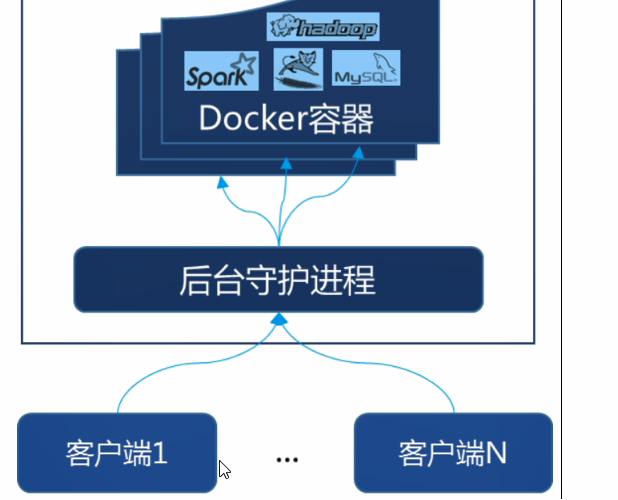
为什么Docker比较比vm快
1、docker有着比虚拟机更少的抽象层。由亍docker不需要Hypervisor实现硬件资源虚拟化,运行在docker容器上的程序直接使用的都是实际物理机的硬件资源。因此在CPU、内存利用率上docker将会在效率上有明显优势。 2、docker利用的是宿主机的内核,而不需要Guest OS。因此,当新建一个 容器时,docker不需要和虚拟机一样 重新加载- - 个操作系统内核仍而避免引寻、加载操作系统内核返个比较费时费资源的过程,当新建–个虚拟机时,虚拟机软件需要加载GuestOS,返个新建过程是分钟级别的。而docker由于直接利用宿主机的操作系统,则省略了返个过程,因此新建一-个docker容器只需要几秒钟。

第三章 Docker常用命令
帮助命令
docker version
docker info
docker --help
自己查看官网解释,高手都是自己练出来的,百度上只不过是翻译了下,加了点例子
镜像命令
docker images 列出本机上的镜像
 OPTIONS
OPTIONS
-a 列出本地所有的镜像(含中间映射层)
-q 只显示镜像ID
--digests 显示镜像的摘要信息
--no-trunc 显示完整的镜像信息
docker search 某个XXX镜像的名字(老版本)
网站 www.dockerhub.com
docker search [OPTIONS] 镜像名字
OPTIONS 说明
--no-trun 显示完整的镜像描述
-s 列出收藏数不小于指定值的镜像
--automated 只列出 automated build类型的镜像
docker search 新版本
OPTIONS(新版本)

docker search [OPTIONS] 镜像名字
docker search --no-trunc tomcat #显示详细信息
docker search [root@localhost docker]# docker search --filter=stars=30 tomcat
#表示stars标签大于30的被取出来

docker pull 某个镜像的名字
下载镜像
docker pull 镜像名字[:TAG]
docker pull tomcat 等价于 docker pull tomcat : latest
docker rmi 某个XXX镜像的名字ID
删除镜像
删除单个 docker rmi -f 镜像ID/镜像名
docker rmi -f hello-world
删除多个 docker rmi -f 镜像名1:TAG 镜像名2:TAG
删除多个 docker rmi -f $(docker images -qa) #$() 表示先执行$()里面的语句
docker rmi -f hello-world 62d49f9bab67
容器命令
有镜像才能创建容器,这是根本前提(下载一个Centos镜像演示)
docker pull centos
新建并启动容器
docker run [OPTIONS] IMAGE [COMMAND][ARG]
OPTIONS 说明
OPTIONS说明(常用) :有些是一个减号,有些是两个减号
--name="容器新名字":为容器指定一个名称;
-d:后台运行容器,并返回容器ID, 也即启动守护式容器;
-i:以交互模式运行容器,通常与-t同时使用;
-t:为容器重新分配一个伪输入终端,通常与-i同时使用;
-P:随机端口映射;
-p:指定端口映射,有以下四种格式
ip:hostPort:containerPort
ip::containerPort
hostPort:containerPort
containerPort
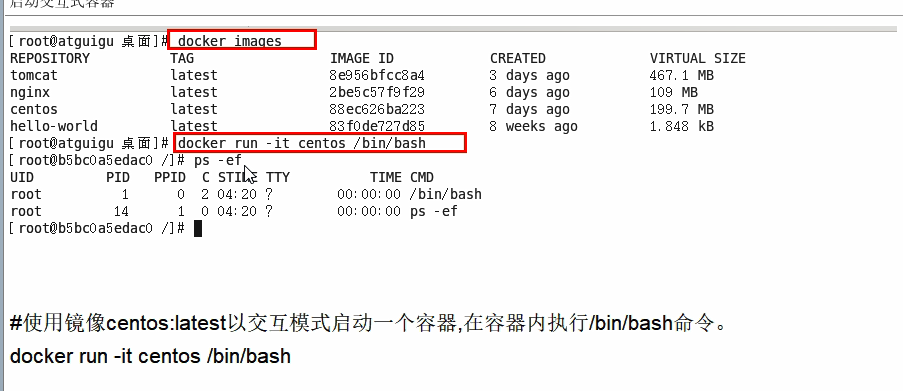
列出当前所有正在运行的容器
docker ps [OPTIONS]
OPTIONS说明(常用) :
-a :列出当前所有正在运行的容器+历史上运行过的
-|:显示最近创建的容器。
-n:显示最近n个创建的容器。
-q :静默模式,只显示容器编号。
--no-trunc :不截断输出。
退出容器
两种退出方式
exit 容器停止退出
ctrl+P+Q 容器不停止退出
启动容器
启动docker: docker start 容器ID或容器签名
重启容器
docker restart 容器ID或容器签名
停止容器
docker stop 容器ID或容器签名
强制停止容器
docker kill 容器ID或容器签名
删除已停止的容器
docker rm 容器ID -f
一次性删除多个容器
docker rm -f $(docker ps -a -q)
docker ps -a -q | xargs docker rm
###重要使用镜像centos:latest以后台模式启动一个容器
docker run -d centos
问题:然后docker ps -a进行查看,会发现容器已经退出 很重要的要说明的一点: Docker容器后台运行,就必须有一个前台进程. 容器运行的命令如果不是那些一直挂起的命令 (比如运行top,tail) ,就是会自动退出的。 这个是docker的机制问题,比如你的web容器,我们以nginx为例,正常情况下,我们配置启动服务只需要启动响应的service即可。例如 service nginx start 但是,这样做,nginx为后台进程模式运行,就导致docker前台没有运行的应用,这样的容器后台启动后,会立即自杀因为他觉得他没事可做了.所以,最佳的解决方案是将你要运行的程序以前台进程的形式运行
查看容器日志
docker logs -f -t –tail=数字 容器ID
-t 是加入时间戳
-f 跟随最新的日志打印
--tail 数字显示最后多少条
查看容器内的进程
docker top 容器ID
查看容器内部细节(返回json字符串)
docker inspect 容器ID
进入正在运行的容器并以命令行交互
docker exec -it 容器ID /bin/bash
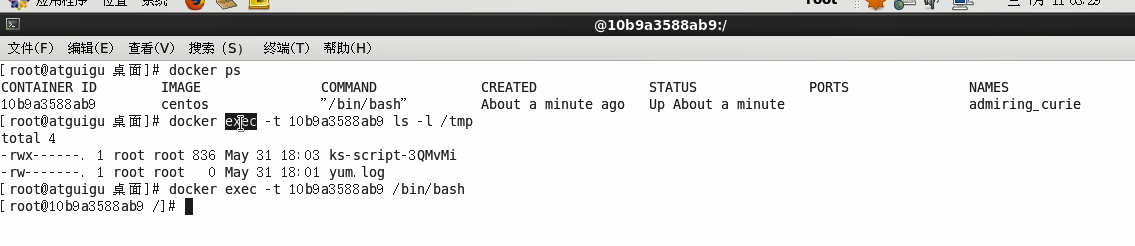
重新进入docker attach 容器ID
上述两个区别
attach 直接进入容器启动命令的终端,不会启动新的进程
exec 实在容器中打开新的终端,并且可以可以启动 那个新的进程
从容器内拷贝文件到主机上
docker cp 容器ID:容器内路径 目的主机路径

小总结
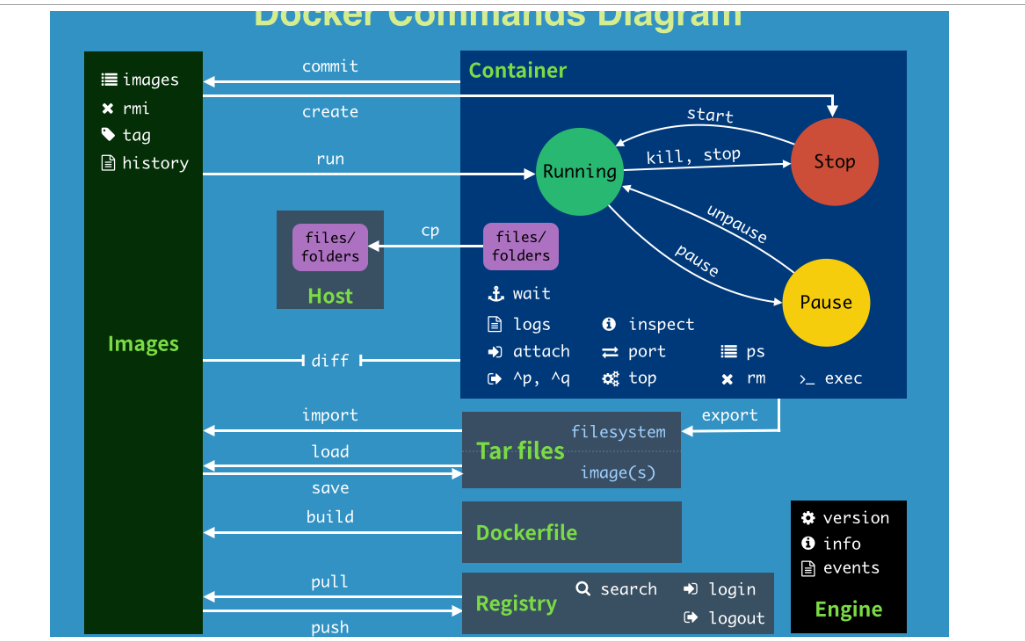

第四章 Docket镜像
镜像是一种轻量级、可执行的独立软件包,用来打包软件运行环境和基于运行环境开发的软件,它包含运行某个软件所需的有内容,包括代码、运行时、库、环境变量和配置文件。
UnionFS(联合文件系统)
UnionFS (状节又件示统) UnionFS (联合文件系统) : Union文件系统(UnionFS)是一一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修作为一 次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下(unite several directories into a singlevirtualfilesystem)。Union文件系统是Docker镜像的基础。镜像可以通过分层来进行继承,基于基础镜像(没有父镜像)可以制作各种具.体的应用镜像。
特性:一次同时加载多个文件系统,但从外面看起来,只能看到一个文件系统,联合加载会把各层文件系统叠加起来,这样最终的文 件系统会包含所有底层的文件和目录
Docker镜像加载原理
Docker镜像加载原理: docker的镜像实际上由一层一层的文件系统组成,这种层级的文件系统UnionFS。
botfs(boot file system)主要包含bootloader和kernel, bootloader主 要是引导加载kernel, Linux刚启动时会加载bootfs文件系统,在Docker镜像的最底层是bootfs。这一-层与我们典型的Linux/Unix系统是- - -样的,包含boot加载器和内核。当boot加载完成之 后整个内核就都在内存中了,此时内存的使用权己由bootfs转交给内核,此时系统也会卸载bootfs。
rootfs (root file system),在bootfs之 上。 包含的就是典型Linux系统中的**/dev, /proc, /bin, /etc等标准目录和文件。rootfs就 是各种不同的操作系统发行版,比如Ubuntu**,Centos等等。
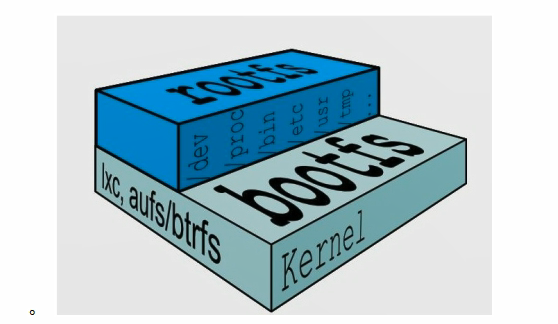
平时我们安装的虚拟机的Centos都是好几个G ,为什么docker这里才要200m

对于一个精简的OS, rootfs可 以很小,只需要包括最基本的命令、工具和程序库就可以了,因为底层直接用Host的kernel,自只需要提供rootfs就行了。由此可见对于不同的linux发行版, bootfs基本是一致的, rootfs会有差别,因此不同的发行版可以公用bootfs。
分层的镜像
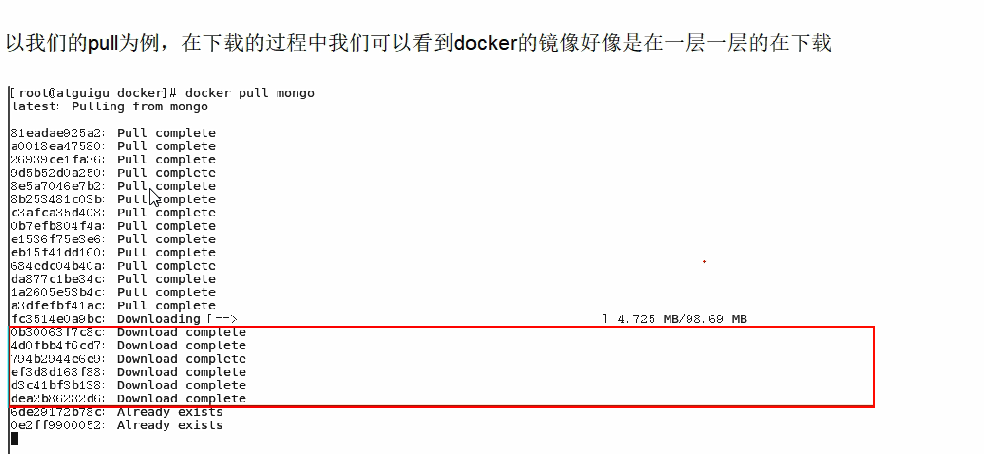
分层的镜像
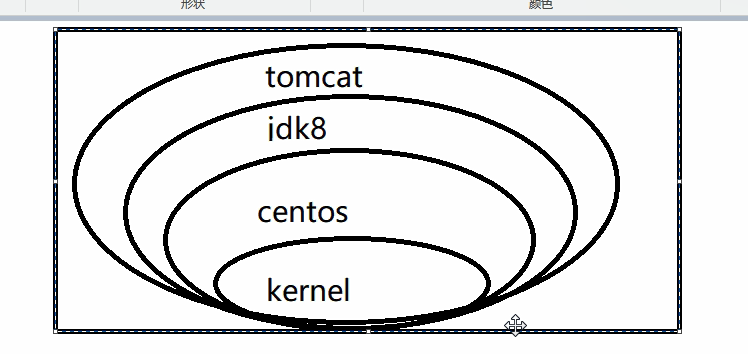
为什么 Docker纪念馆想要采用这种分层结构
最大的一个好处就是-共享资源 比如:有多个镜像都从相同的base镜像构建而来,那么宿主机只需在磁盘上保存一份base镜像, 同时内存中也只需加载一份base镜像,就可以为所有容器服务了。而且镜像的每一层都可以被共享。
特点
Docker镜像都是只读的,当容器启动时,一个新的可写层被加载到镜像的顶部,这一层通常被称为容器层,容器层之下都叫镜像层
Docker镜像Commit操作
docker commit 提交容器副本使之称为一个新的镜像
docker commit -m=“提交的描述信息” -a=“作者” 容器ID 要创建的目标镜像名:[标签名]
案例演示:
1、从Hub上下载tomcat镜像
2、启动
docker run -d -p 8888:8080 tomcat
发现启动成功但是访问http://192.168.241.125:8888/发现没有文件 进入docker 下面的tomcat
docker exec -it tomcat 73cdb4685037 /bin/bash

移除原来的webapps
然后把下面的webapps.dist重命名为webapps
重新进行访问发现访问成功
http://192.168.241.125:8888/
docker run -d -p 8080:8080 tomcat
-p主机端口:docker容器端口
-P:随机分配端口
i:交互
t:终端
2、故意删除上一步镜像生产tomcat容器的文档
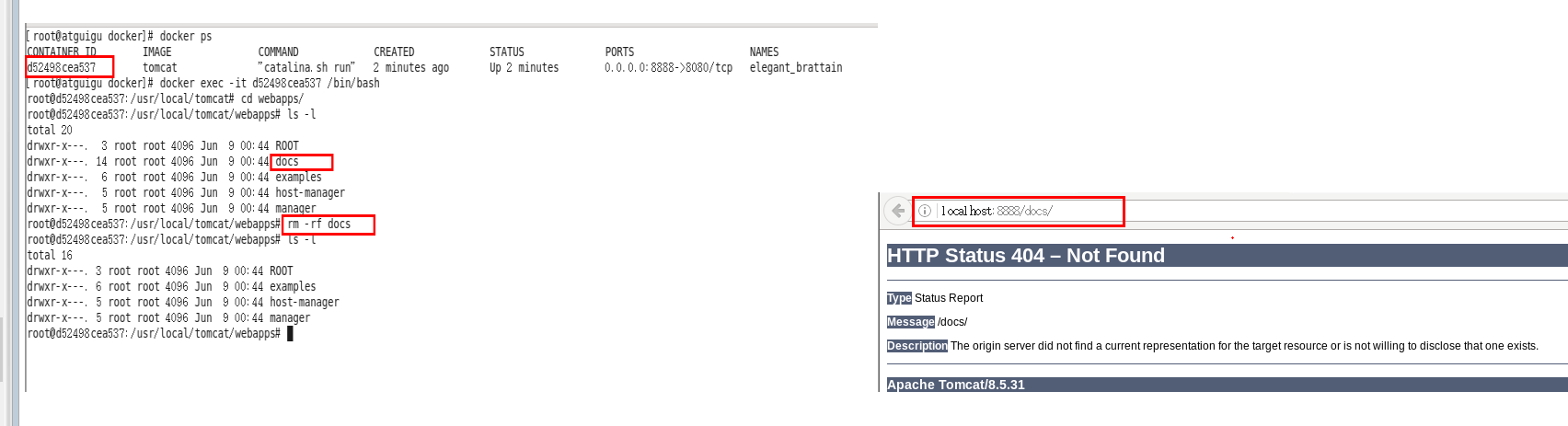
3、也即当前的tomcat运行实例是一个没有文档内容的容器,以他为模板commit一个没有doc的tomcat新镜像 atguigu/tomcat02

docker commit -a=“xiaodidi” -m=“修复tomcatwebapps默认显示,同时删除tomcat docs” 02f8a6a79dcc atguigu/tomcat02:1.2
[root@localhost opt]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE atguigu/tomcat02 1.5 496bc0ee8598 3 minutes ago 669MB nginx latest 62d49f9bab67 6 days ago 133MB tomcat latest bd431ca8553c 9 days ago 667MB centos latest 300e315adb2f 4 months ago 209MB
4、启动我们的新镜像并和原来的对比
docker run -d -p 8888:8080 496bc0ee8598
启动atuigu/tomcat02 没有doc
启动原来tomcat他有doc
第 五 章 Docker容器数据卷
是什么
先来看看Docker的理念: *将运用与运行的环境打包形成容器运行,运行可以伴随着容器,但是我们对数据的要求希望是持久化的 *容器之间希望有可能共享数据 Docker容器产生的数据,如果不通过docker commit生成新的镜像,使得数据做为镜像的一部分保存下来, 那么当容器删除后,数据自然也就没有了。 为了能保存数据在docker中我们使用卷。|
一句话:有点类似我们Redis里面的rdb和aof文件
能干嘛
卷就是目录或文件,存在于一个或多个容器中,由docker挂载到容器,但不属于联合文件系统,因此能够绕过Union FileSystem提供一些用于持续存储或共享数据的特性: 卷的设计目的就是数据的持久化,完全独立于容器的生存周期,因此Docker不 会在容器删除时删除其挂载的数据卷
特点: 1:数据卷可在容器之间共享或重用数据 2:卷中的更改可以直接生效 3:数据卷中的更改不会包含在镜像的更新中 4:数据卷的生命周期一直持续到没有容器使用它为止
容器的持久化
容器间继承+共享数据
数据卷
容器内添加
直接命令添加
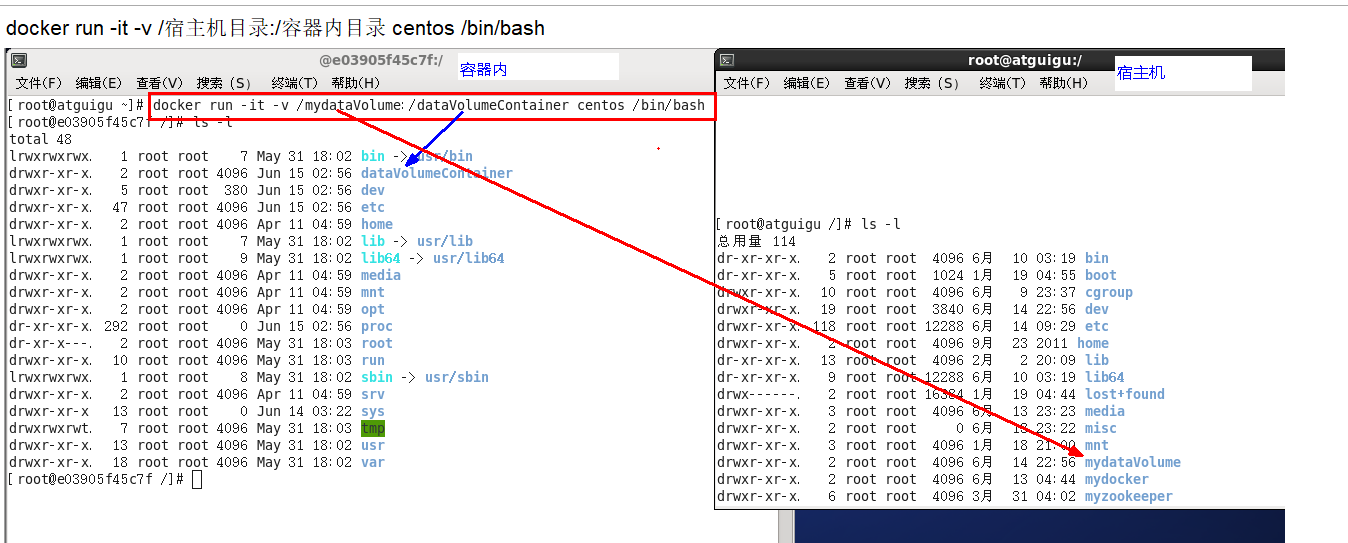
docker run -it -v /mydataVolume:/dataVolumeContainer centos /bin/bash
docker run -it -v /宿主机绝对路径目录:/容器内目录 镜像名 /bin/bash
d
查看数据卷是否挂载成功
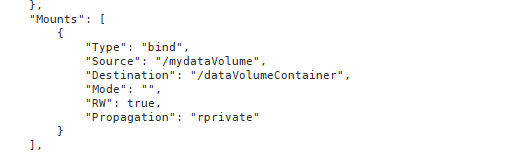
容器和宿主机之间数据共享
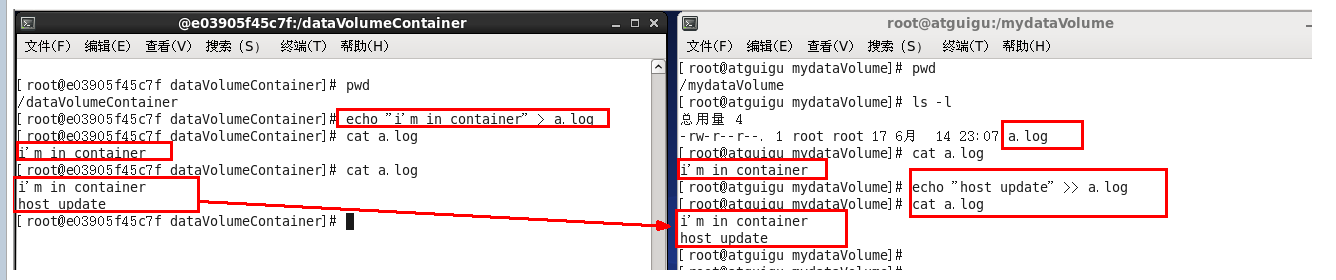
容器停止退出后,主机修改后的数据是否同步
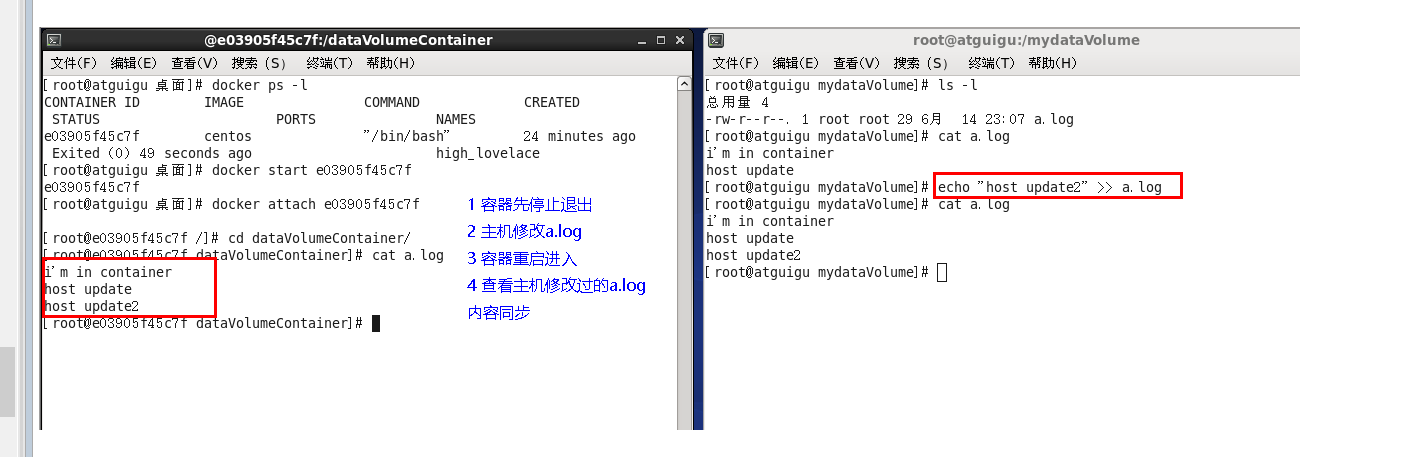
命令(带权限)
docker run -it -v /宿主机绝对路径目录:/容器内目录:ro 镜像名
docker run -it -v /mydataVolume:/dataVolumeContainer:ro centos /bin/bash
docker inspect
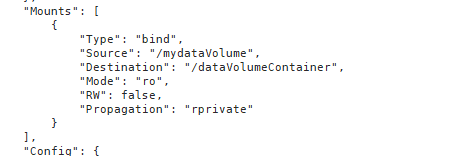
DockerFile添加
根目录下新建mydocker文件夹并进入
可在Dockerfile中使用VOLUME指令来给镜像添加一个或多个数据卷

File构建
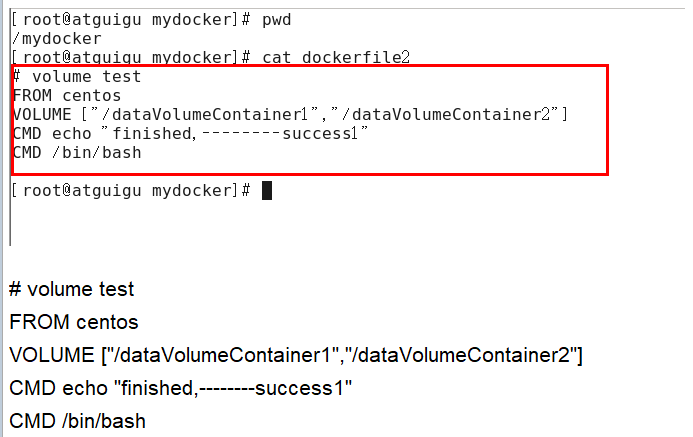
注意#一定要加,这个代表可执行语句的标志
#volume test
from centos
VOLUME ["/dataVolum1","/dataVolum2"]
cmd echo "finished,----------success1"
cmd /bin/bash
build后生成镜像
docker build -f /mydocker/dockerfile2 -t xiao/centos .
注意:后边有一个点
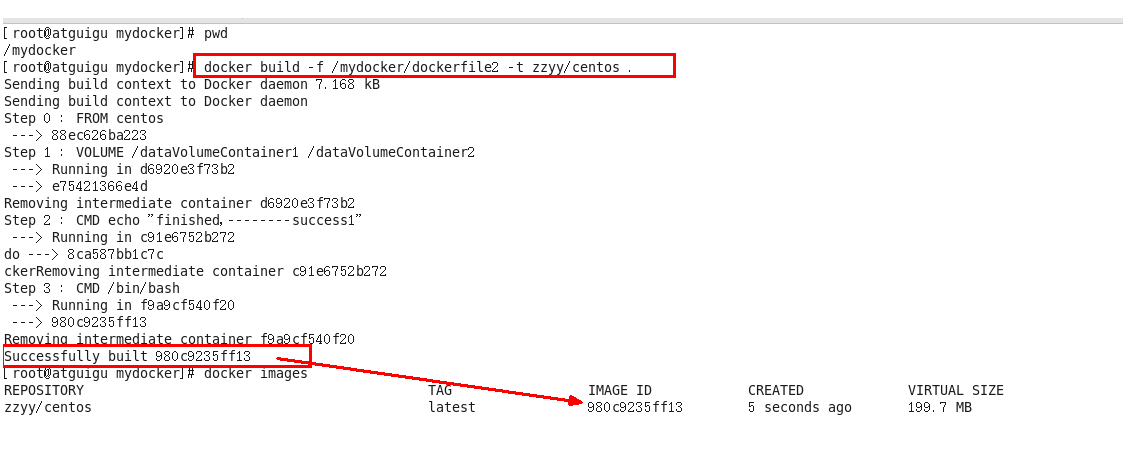
获得一个新镜像zzyy/centos
run容器
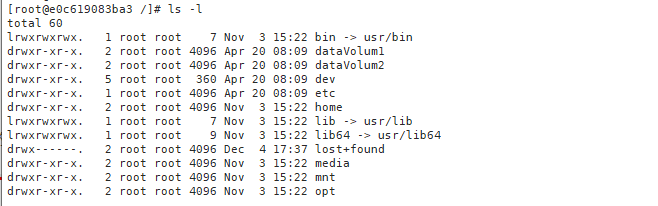
通过上述步骤,容器内的卷目录地址已经知道,对应的主机目录在哪
docker inspect e0c619083ba3
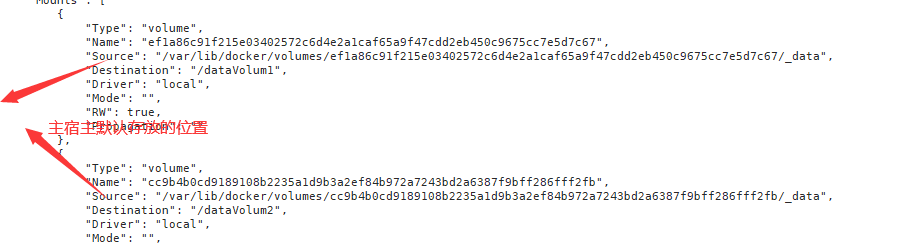
主机对应默认地址

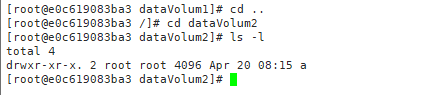
备注
Docker挂载主机目录Docker访问出现cannot open directory . Permission denied 解决办法:在挂载目录后多加一个–privileged=true参数即可
数据卷容器
是什么
命名的容器挂载数据卷,其它容器通过挂载这个(父容器)实现数据共享,挂载数据卷的容器,称之为数据卷容器.
总体介绍
以上一步新建的zzyy/centos为模板并运行容器 doc1/doc2/doc3
他们已经具有容器卷
/dataVolume1
/dataVolume2
容器间传递共享(–volumes -from)
先启动一个父容器doc1
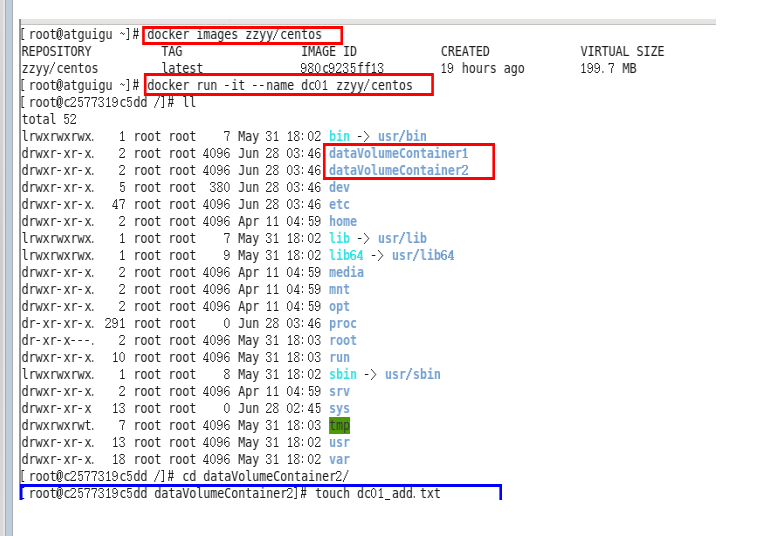
启动后在 dataVolumeContainer1中新增内容
doc2/doc3 继承doc1
--volumes -from
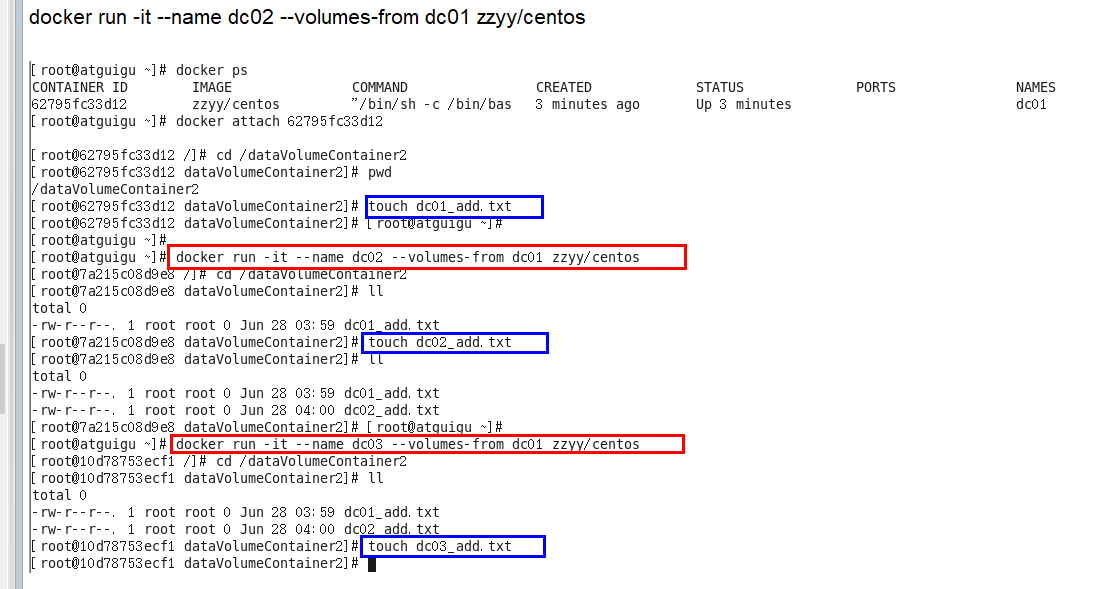
doc2/doc3 分别在dataVolumeContainer2各自新增内容
回到doc1可以看到02/03各自添加的都能共享了
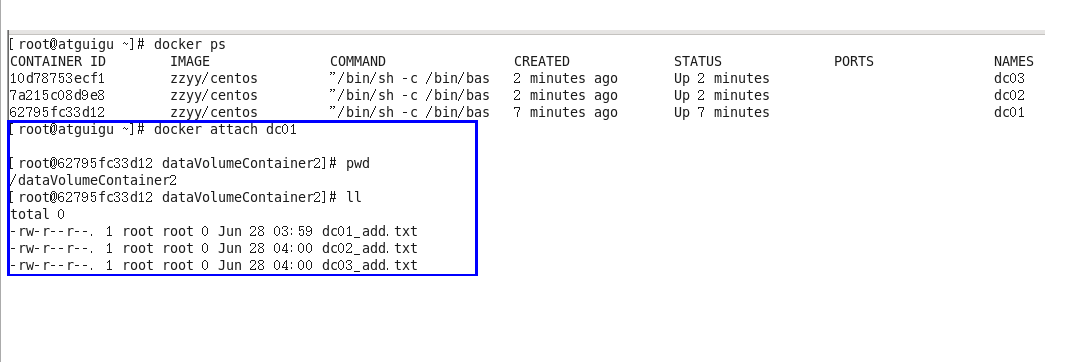
删除doc1 doc2修改后doc3是否可以访问
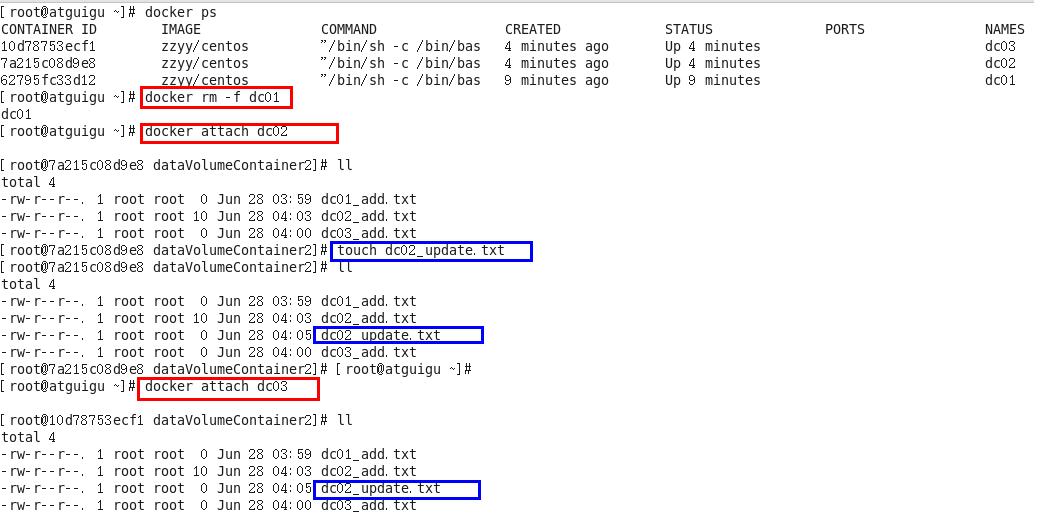
删除doc02后doc3是否访问
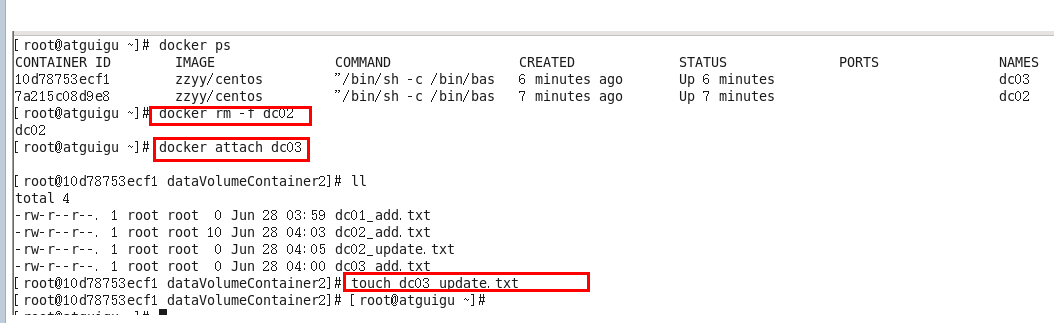
在进一步
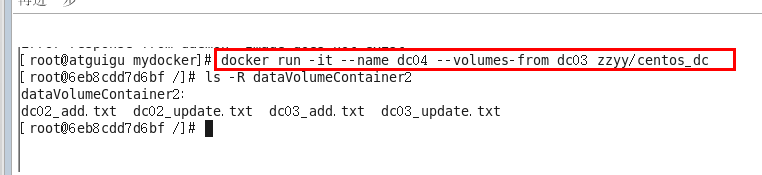
新建doc04继承doc03 然后删除doc03
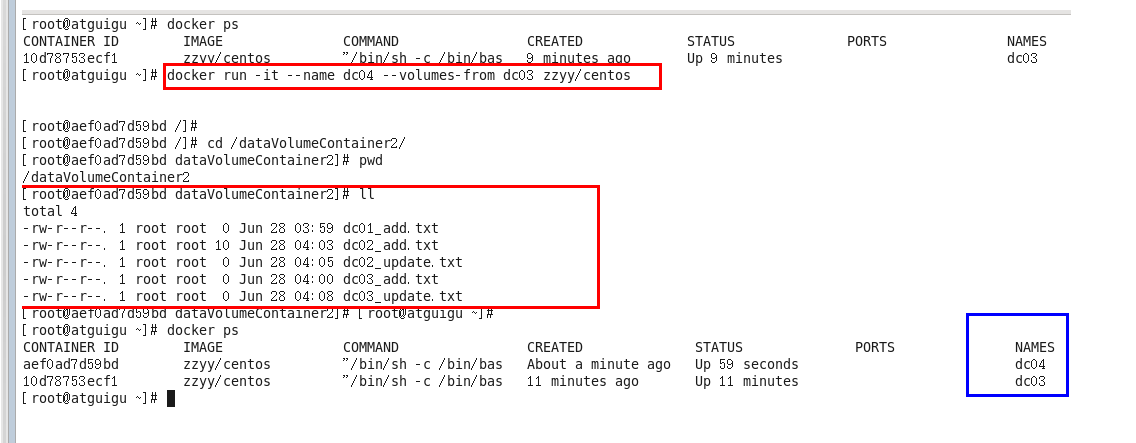
结论:容器之间配置信息的传递,数据卷的生命周期一直持续到没有容器使用它为止
第 六 章 DockerFile解析
是什么
Dockerfile是用来构建Docker镜像的构建文件,由一系列命令和参数构成的脚本
构建三步骤
编写Dockerfile文件
docker build
docker run
文件什么样???
熟悉的Centos为例
http://hub.docker.com/_/centos
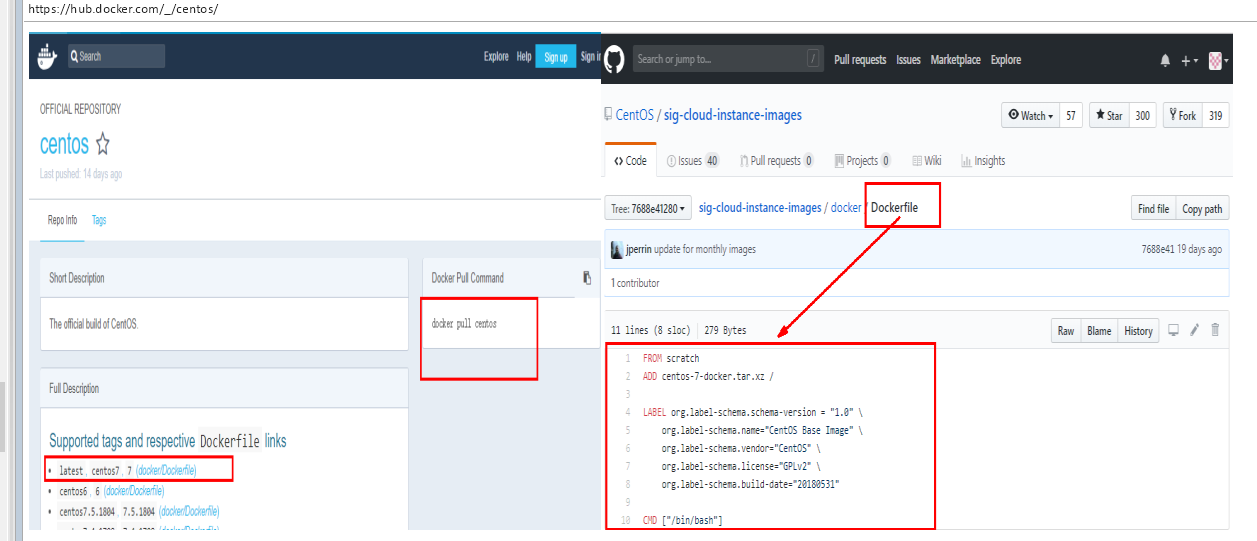
DockerFile构建过程解析
Dockerfile内容基础知识
1、每条保留字指令都必须为大写字母且后面要跟随至少一个参数 2、 指令按照从.上到下,顺序执行 3、#表示注释 4、每条指令都会创建一个新的镜像层,并对镜像进行提交
Docker执行Dockerfile的大致流程
1、 docker 从基础镜像运行一个容器 2、执行一-条指令并对容器作出修改 3、执行类似docker commit的操作提交- -个新的镜像层 4、docker再基 于刚提交的镜像运行一一个新容器 5、执行dockerfile中的 下一条指令直到所有指令都执行完成
小总结
从应用软件的角度来看,Dockerfile、 Docker镜像与Docker容器分别代表软件的三个不同阶段, Dockerfile是软件的原材料 Docker镜像是软件的交付品 Docker容器则可以认为是软件的运行态。 Dockerfile面向开发,Docker镜 像成为交付标准,Docker容 器则涉及部署与运维,三者缺- -不可,合力充当Docker体系的基石。

1、Dockerfile,需要定义一个Dockerfile,Dockerfile定 义了进程需要的一切东西。Dockerfile涉 及的内容包括执行代码或者是文件、环境变量、依赖包、运行时环境、动态链接库、操作系统的发行版、服务进程和内核进程(当应用进程需要和系统服务和内核进程打交道,这时需要考虑如何设计namespace的权限控制)等等; 2、Docker镜像,在用Dockerfile定义一文件之后,docker build时会产生- -个Docker镜像,当运行Docker镜像时,会真正开始提供服务; 3、Docker容器,容器是直接提供服务的。
DockerFile体系结构(保留字指令)

小总结
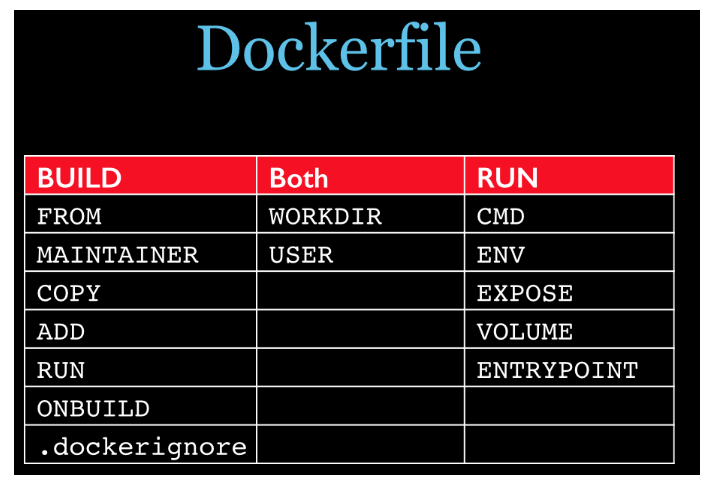
案例
Base 镜像(scratch)
Docker Hub中 99%的镜像都是通过在base镜像中安装和配置需要的软件构建出来的
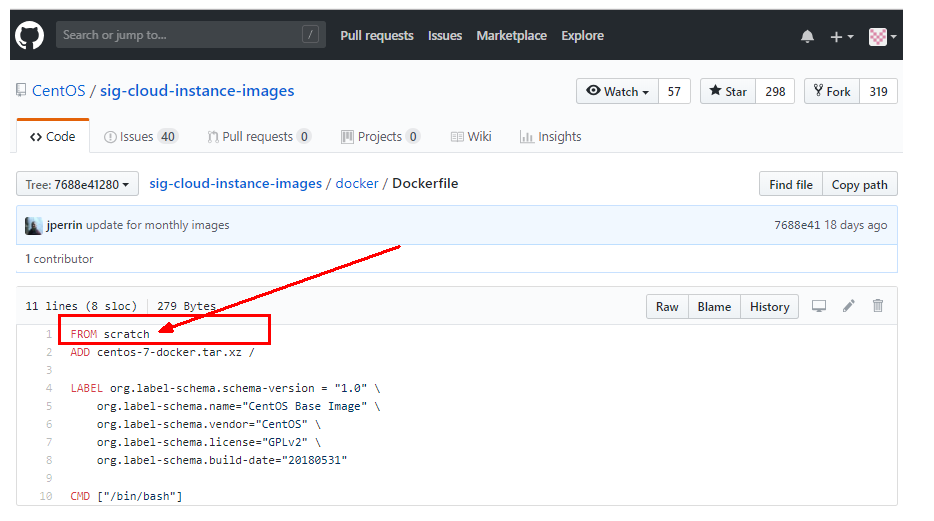
自定义镜像mycentos
1、编写
Hub默认Centos镜像是什么情况
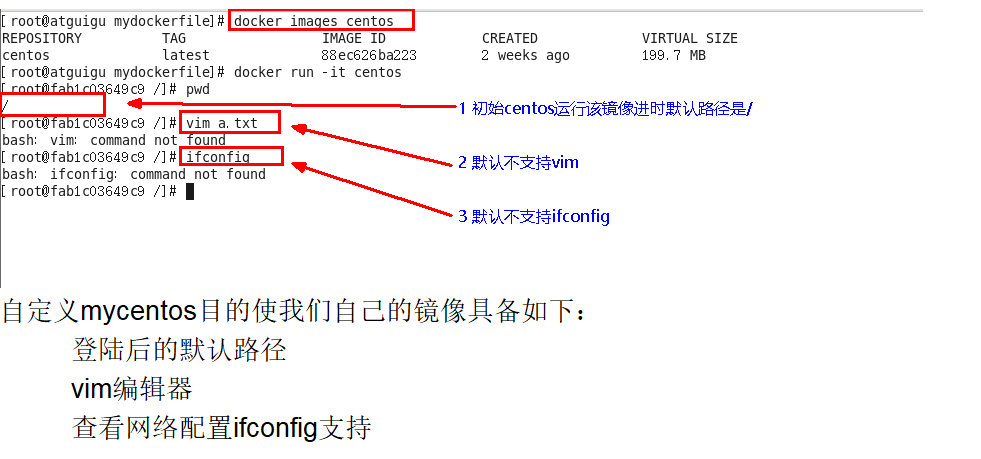
准备Dockerfile文件
myCentOS内容Dockerfile

FROM centos
ENV mypath /tmp
WORKDIR $mypath
RUN yum -y install vim
RUN yum -y install net-tools
EXPOSE 80
CMD /bin/bash
#自定义mycentos目的使我们自己的镜像具备如下:
#登录后的默认路径
#vim编辑器
#查看网络配置ifconfig支持
#从xiao/centos中获取,继承xiao/centos
FROM xiao/centos
#设置镜像维护者姓名
MAINTAINER xiao<xiao@qq.com
#设置一登陆进去转移到的位置
#先设置一个变量,等下用来调用
ENV path /usr/local
WORKDIR $path
#设置从yum拉去这两个命令
RUN yum -y install vim
RUN yum -y install net-tools
#对外暴露80端口
EXPOSE 80
CMD echo $path
CMD echo "成功完成"
CMD /bin/bash
2、构建
docker build -t 新镜像名字:TAG .
docker build -f /mydocker/dockerfile3 -t xiao/centos:2.0 .
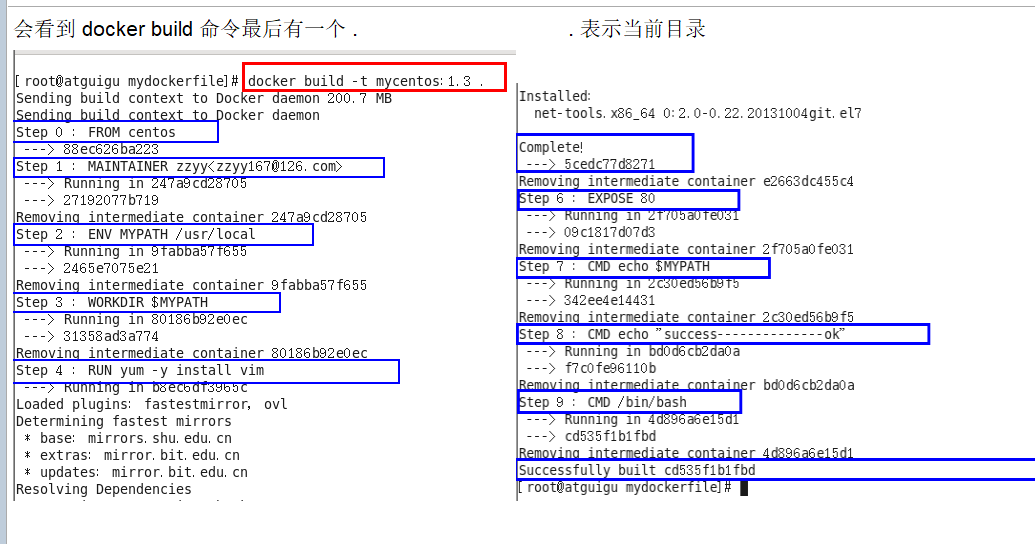
3、运行
docker run -it 新镜像名字:TAG
docker run -it xiaodidi/centos:2.0
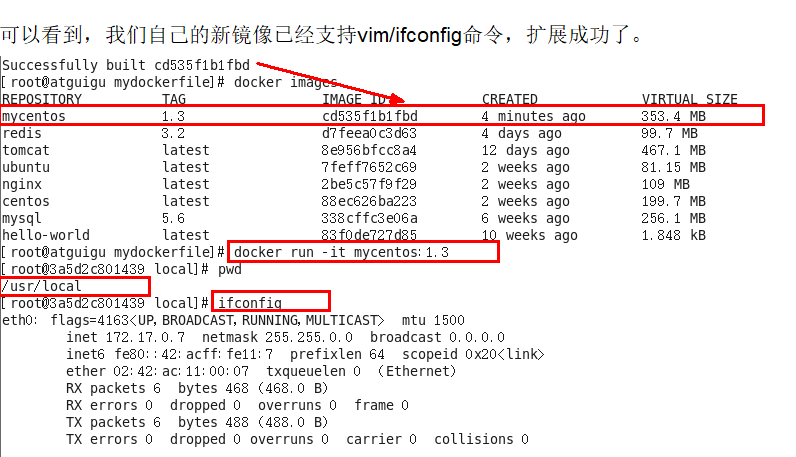
4、列出镜像的变更历史
docker history 镜像名
CMD/ENTRYPOINT 镜像案例
都是指定一个容器启动时要运行的命令
CMD
Dockerfile中可以有多个CMD指令,但只有最后一个生效,CMD会被dockerrun之后的参数替换
Case
tomcat的讲解演示 docker run -it -p 8080:8080 tomcat ls -l
ENTRYPOINT
docker run 之后的参数会被当做参数传递给 ENTRYPOINT 之后形成新的命令组合
Case

制作CMD版可以查询IP信息的容器
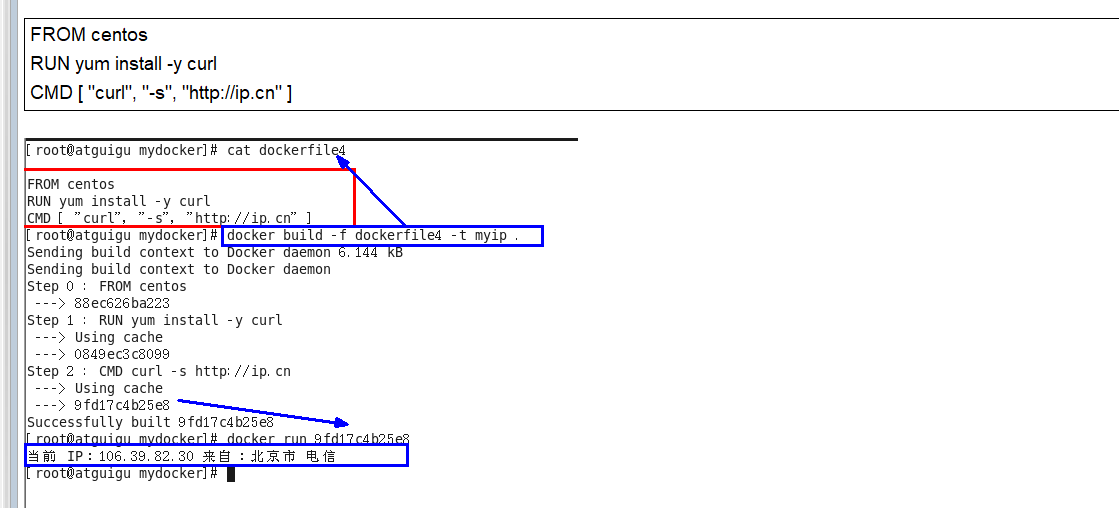
curl的命令解释
curl命令可以用来执行下载、发送各种HTTP请求,指定HTTP头部等操作。
如果系统没有curl可以使用yum install curl安装,也可以下载安装。 curl是将下载文件输出到stdout 使用命令: curl http://www .baidu.com 执行后,www.baidu.com的html就会显示在屏幕上了
这是最简单的使用方法。用这个命令获得了htp://curl.haxx.se指向的页面,同样,如果这里的URL指向的是–个文件或者一幅图都可以直接下载到本地。如果下载的是HTML文档,那么缺省的将只显示文件头部,即HTML文档的header。要全部显示,请加参数-i
WHY
我们可以看到可执行文件找不到的报错,executable file not found。 之前我们说过,跟在镜像名后面的是command,运行时会替换CMD的默认值。 因此这里的-i替换了原来的CMD,而不是添加在原来的curl -s htp://ip.cn后面。而-i 根本不是命令,所以自然找不到。 那么如果我们希望加入-i这参数,我们就必须重新完整的输入这个命令: $ docker run myip curl -s http://ip.cn -i
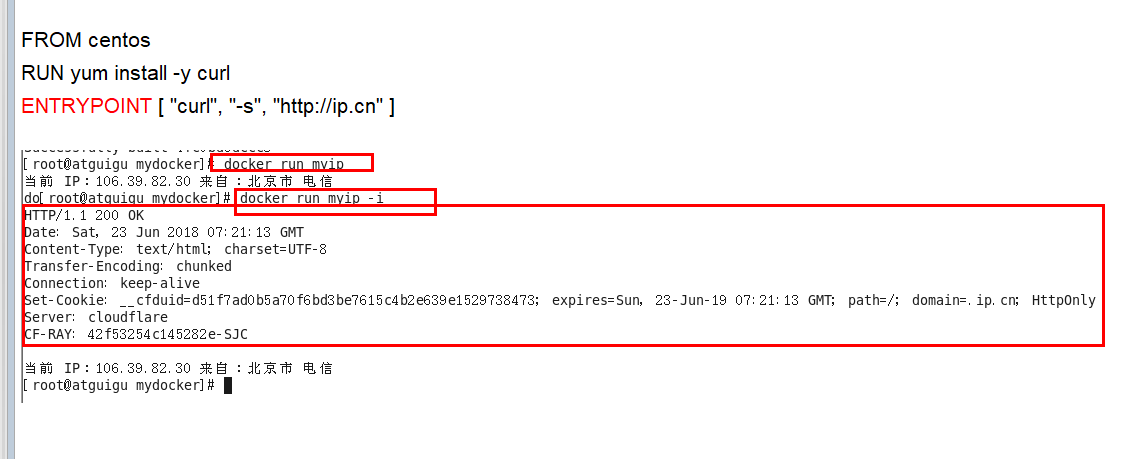
ONBUILD触发器
创建一个文件
dockerfile4
from centos
ONBUILD RUN echo "我是触发器,进行了触发"
docker build -f /mydocker/dockerfile4 -t buildtest .
创建dockerfile5
from buildtest
docker build -f /mydocker/dockerfile5 -t buildtest1 .
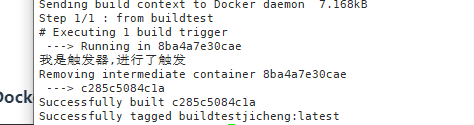
自定义镜像Tomcat
1、mkdir -p /zzyy/mydockerfile/tomcat9
2、在上述目录下 touch c.txt
3、将jdk和tomcat安装的压缩包拷贝进上一步目录
4、在zzyyuse/mydockerfile/tomcat9目录下新建Dockerfile文件
FROM centos
MAINTAINER xiaodidi<10123@qq.com>
#设置落脚点
WORKDIR /usr/local
COPY test /usr/local/cincontainer.txt
RUN yum -y install vim
#暴露8080端口
EXPOSE 8080
#加入安装包到镜像中去
ADD apache-tomcat-7.0.70.tar.gz /usr/local
ADD jdk-8u152-linux-x64.tar.gz /usr/local
#定义环境变量
ENV JAVA_HOME /usr/local/jdk1.8.0_152
ENV CLASSPATH $JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
ENV CATALINA_HOME /usr/local/apache-tomcat-7.0.70
ENV CATALINA_BASE /usr/local/apache-tomcat-7.0.70
ENV PATH $PATH:$JAVA_HOME/bin:$CATALINA_HOME/lib:$CATALINA_HOME/bin
#启动时运行tomcat
# ENTRYPOINT ["/usrl/local/apache-tomcat-9.0.8/bin/startup.sh" ]
# CMD ["/usr/local/apache-tomcat-9.0.8/bin/catalina.sh","run"]
CMD /usr/local/apache-tomcat-7.0.70/bin/startup.sh && tail -F /usr/local/apache-tomcat-7.0.70/logs/catalina.out
目录内容
5、构建
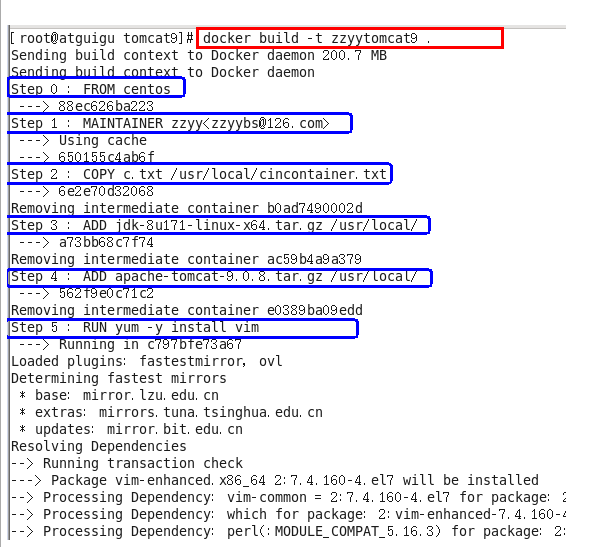
构建完成
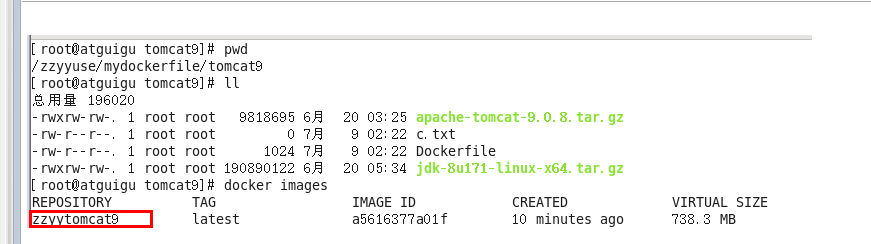
6、run
docker run -d -p 8080:8080 --name myt10 -v /mydocker/mytomcat9/test01:/usr/local/apache-tomcat-7.0.70/webapps/test -v /mydocker/mytomcat9/tomcat9logs:/usr/local/apache-tomcat-7.0.70/logs --privileged=true tomcat9
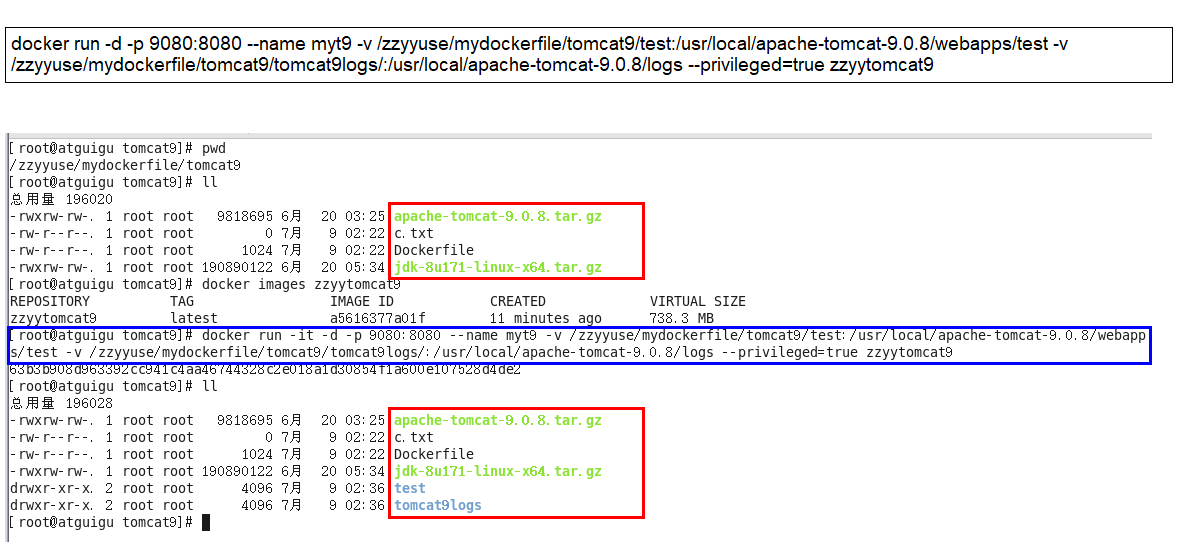
备注
Docker挂载主机目录Docker访问出现cannot open directory : Permission denied解决办法:在挂载目录后多加一个–privileged=true参数即可
7、验证
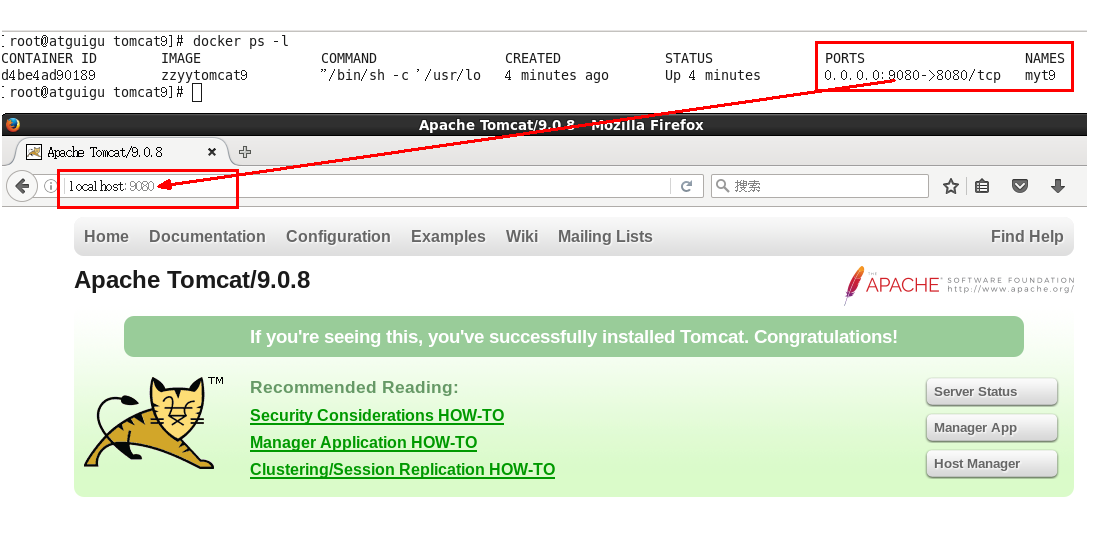
8、综合前 述容器卷测试的web服务test发布
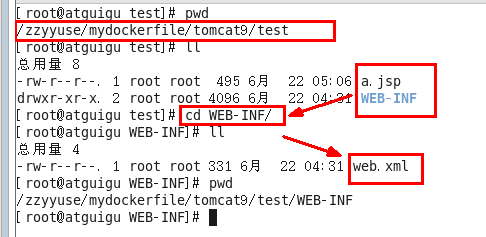
web.xml
<?xml version="1 .0" encoding="UTF-8"?>
<web-app xmIns:xsi="http://www.w3.org/2001/XML Schema-instance"
xmIns="http://java sun.com/xm/ns/javaee"
xsi:schemaL ocation="http://java. sun.com/xml/ns/javaee htp:/:/java. sun.com/xml/ns/javaee/web-app_ 2_ _5.xsd"
id="WebApp_ ID" version="2.5">
<display-name>test</display-name>
</web-app>
a.jsp
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
<!DOCTYPE html PUBLIC“//W3C//DTD HTML 4.01 Transitional//EN" http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Insert title here </title>
</head>
<body>
welcome-
<%="i am in docker tomcat self "%>
<br>
<br>
<%System.out.println("==========docker tomcat self");%>
</body>
</htmI>
测试

小总结
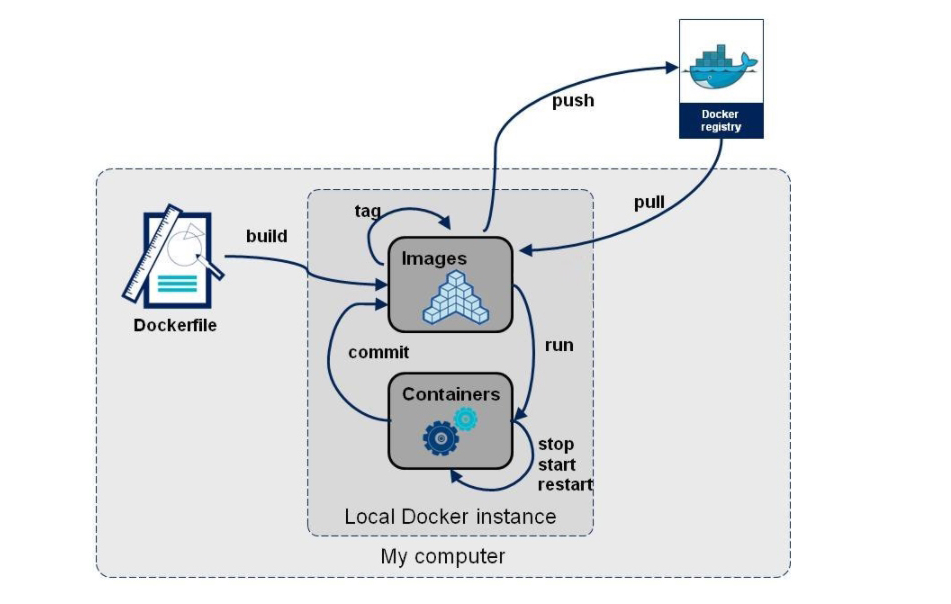
第 七 章 Docker常用安装
总体步骤
搜索镜像
拉取镜像
查看镜像
启动镜像
停止容器
移除容器
安装Mysql
docker hub 上查找mysql镜像
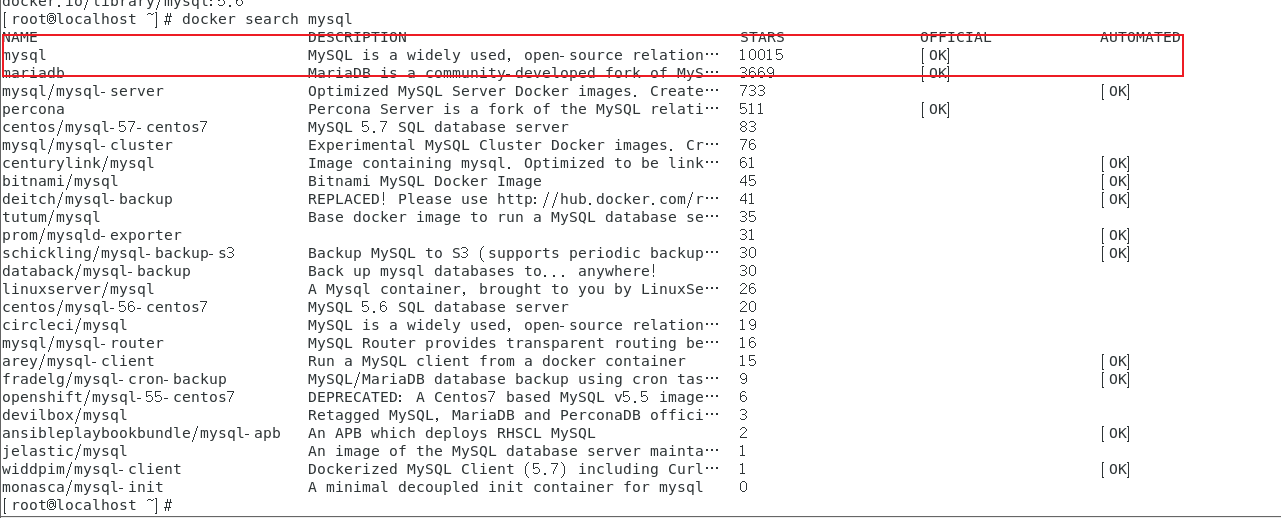
从 docker hub(阿里云加速器)拉取mysql镜像到本地标签为5.6
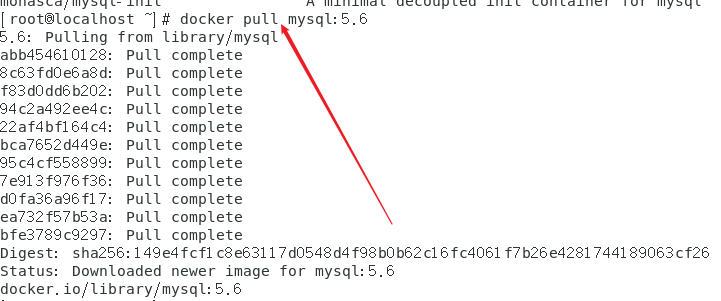
使用mysql5.6镜像创建容器(也叫运行镜像)
使用mysql镜像
docker run -p 12345:3306 --name mysql
-v /ggcc/mysql/conf:/etc/mysql/conf.d
-v /ggcc/mysql/logs:/logs
-v /ggcc/mysql/data:/var/lib/mysql
-e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.6
----------------------------------------------
命令说明:
-p 12345:3306:将主机的12345端口映射到docker容器的3306端口。
-name mysq:运行服务名字
-V /ggcc/mysql/conf:/etc/mysql/conf.d :将主机/zzyyuse/mysq|录下的conf/my.cnf挂载到容器的/etc/mysql/conf.d
-v /ggcc/mysqlogs/logs: 将主机/zzyyuse/mysq|目 录下的logs 目录挂载到容器的/logs。
-V /ggcc/mysqldata:/var/lib/mysql :将主机lzzyyuse/mysql目录下的data目录挂载到容器的/var/lib/mysql .
-e MYSQL_ ROOT_ PASSWORD=123456: 初始化root用户的密码。.
-d mysql:5.6:后台程序运行mysql5.6
----------------------------------------------
docker exec -it Mysql运行成功后的容器ID /bin/bash
----------------------------------------------
数据备份小测试
docker exec mysql服务容器ID sh -c 'exec mysqldump --all-databases -uroot -p"123456"' >/ggcc/all-database.sql
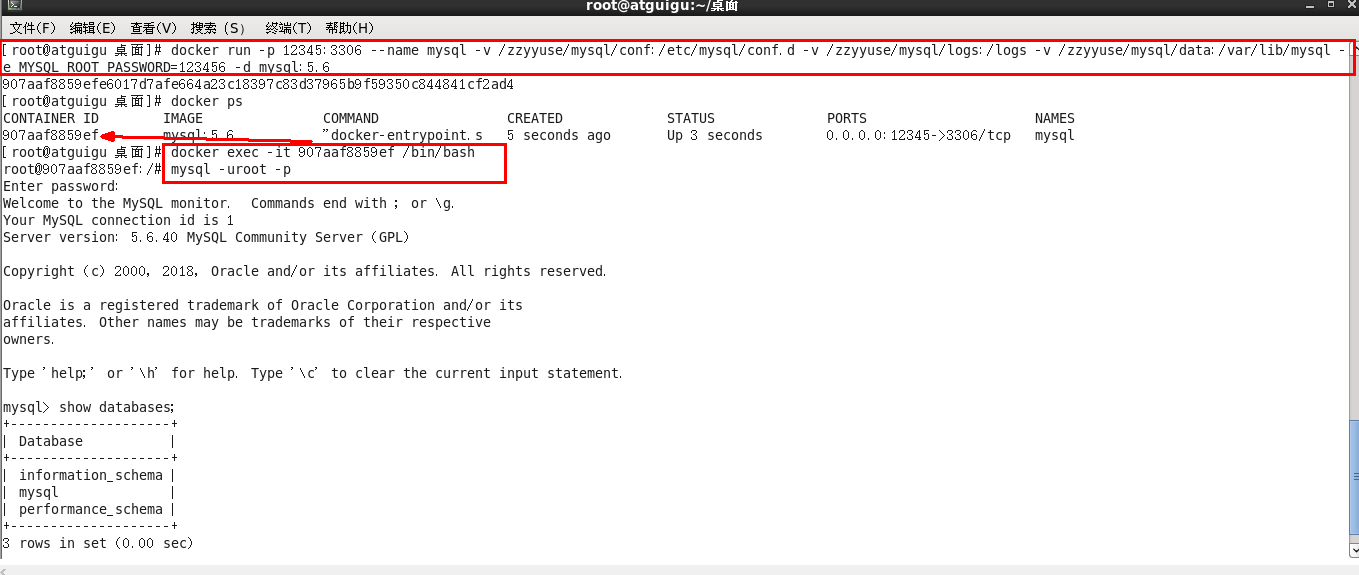
数据备份测试
安装Redis
从docker hu上(阿里云加速器)拉取redis镜像到本地标签为:3.2

使用redis3.2镜像创建容器(也叫运行镜像)
使用镜像
docker run -p 6379:6379 -v /ggcc/myredis/data:/data -v /ggcc/myredis/conf/redis.conf:/usr/local/etc/redis/redis.conf -d redis redis-server /usr/local/etc/redis/redis.conf --appendonly yes
测试 redis-cli连接上来
docker exec -it 运行着redis服务容器的ID redis-cli
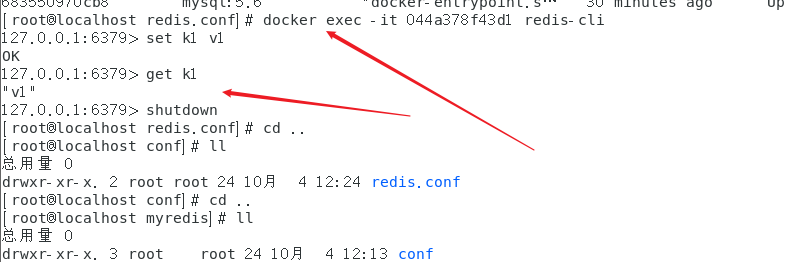
测试持久化文件生成
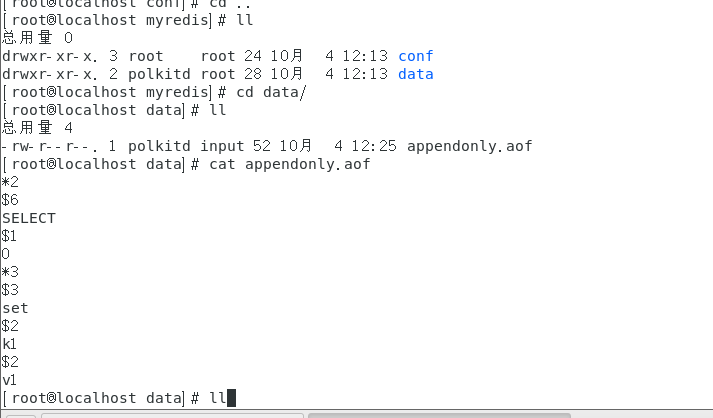
第 8 章 将镜像推送到阿里云
本地镜像发布到阿里云流程
镜像生成方法
1、前面的Dockerfile
2、从容器中创建一个新的镜像
docker commit [OPTIONS] 容器ID [REPOSITORY[:TAG]]
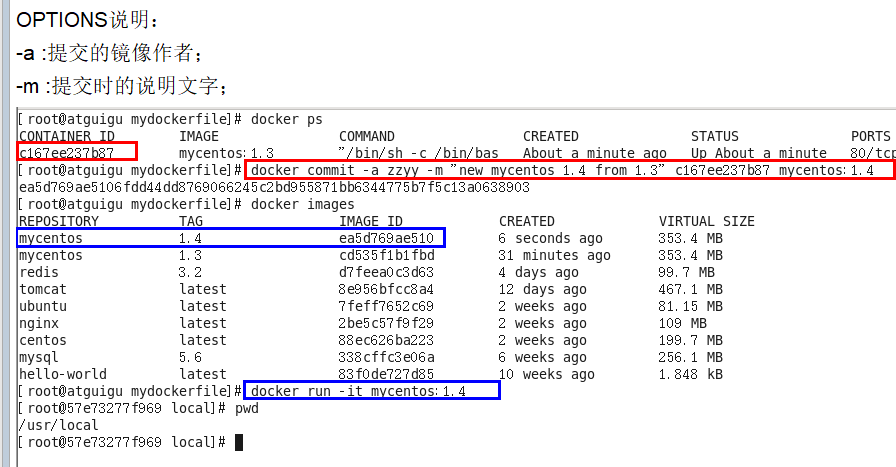
将本地镜像推送到阿里云
1、本地镜像素材原型

2、阿里云开发者平台
https://promotion.aliyun.com/ntms/act/kubernetes.html
进入容器镜像服务
https://cr.console.aliyun.com/cn-hangzhou/instances
3、创建镜像仓库
命名空间
仓库名称
4、将镜像推送到registry
sudo docker login --username=xiaodidi314141 registry.cn-hangzhou.aliyuncs.com
$ sudo docker tag [ImageId] registry.cn-shenzhen.aliyuncs.com/ggccqq/mycentos:[镜像版本号] (镜像版本号随便写)
$ sudo docker push registry.cn-shenzhen.aliyuncs.com/ggccqq/mycentos:[镜像版本号]
其中[ImageId][镜像版本]自己填写
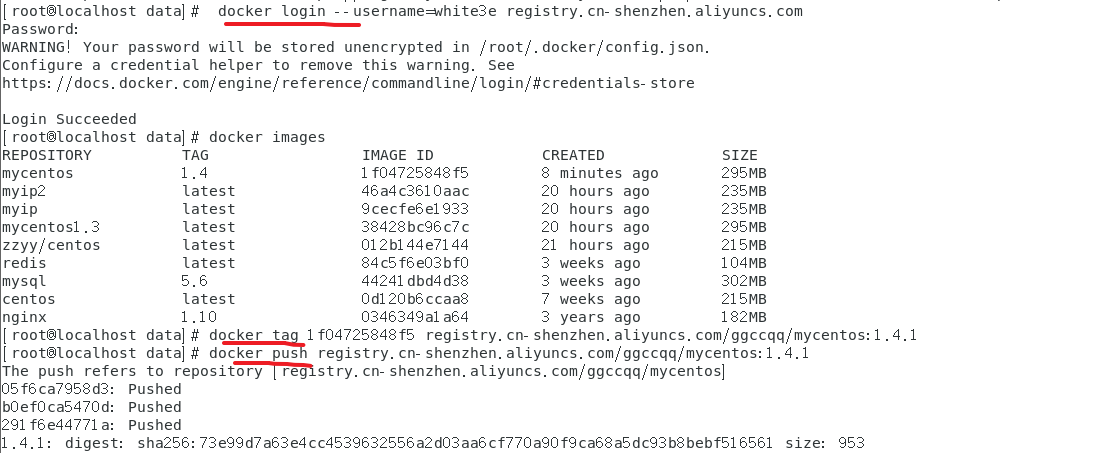
5、公有云可以查询得到

6、查看详情
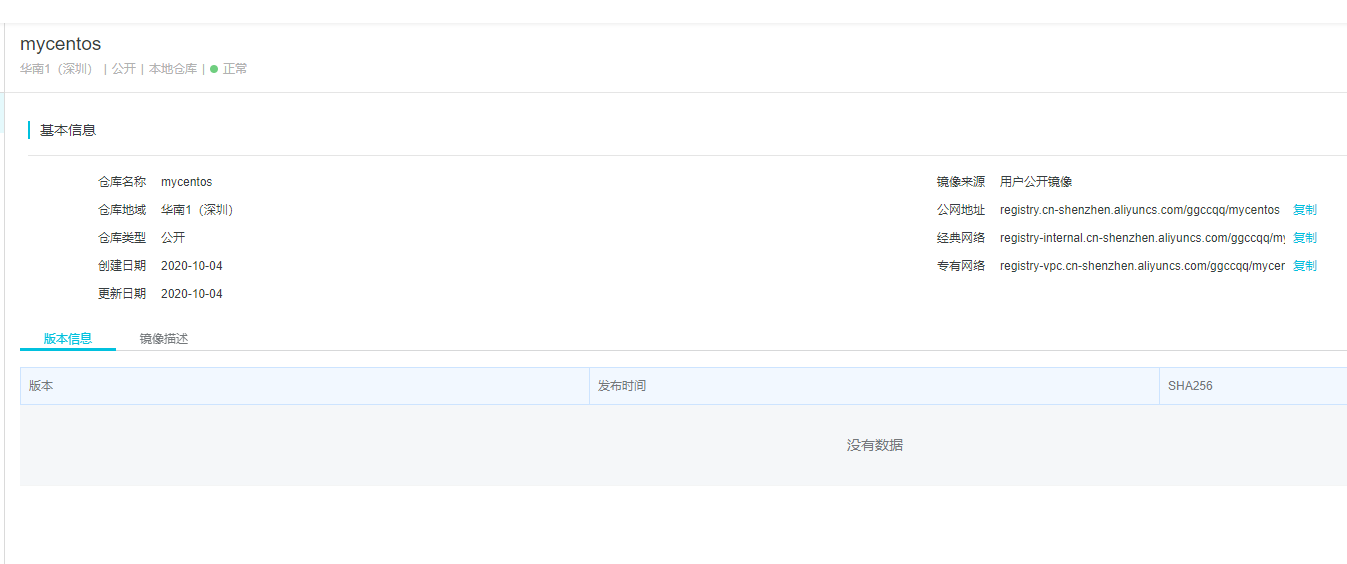
将阿里云上的镜像下载到本地
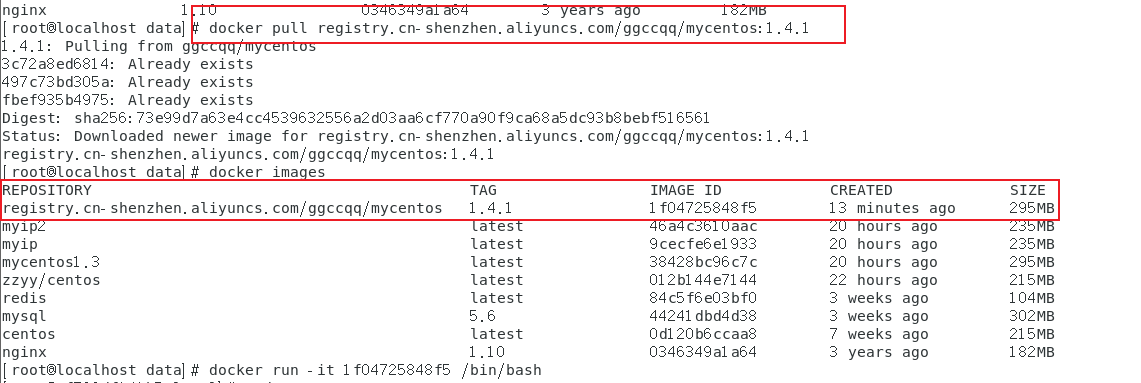
rabbitMQ
文章目录
- 1. 消息中间件概述
- 2. 安装及配置RabbitMQ
- 3. RabbitMQ入门
- 4. AMQP
- 5. RabbitMQ工作模式
- 5. Spring 整合RabbitMQ
- 6. Spring Boot整合RabbitMQ
- 3.RabbitMQ集群搭建
学习目标
- 能够说出什么是消息中间件
- 能够安装RabbitMQ
- 能够编写RabbitMQ的入门程序
- 能够说出RabbitMQ的5种模式特征
- 能够使用Spring整合RabbitMQ
1. 消息中间件概述
1.1. 什么是消息中间件
MQ全称为Message Queue,消息队列是应用程序和应用程序之间的通信方法。多用于分布式系统之间进行通信。
如下图,要进行远程通信有两种方式:l直接远程调用 和 借助第三方 完成间接通信
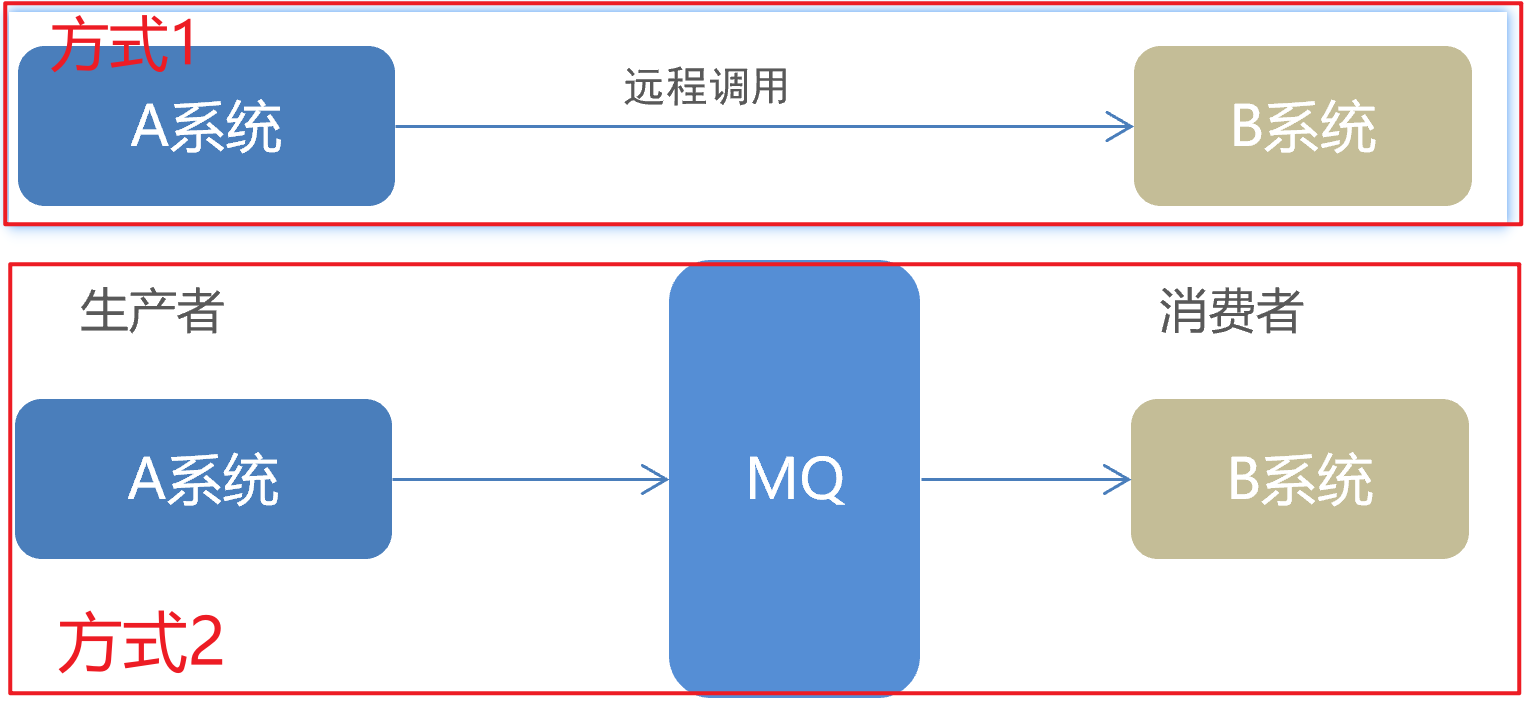
-
为什么使用MQ
在项目中,可将一些无需即时返回且耗时的操作提取出来,进行异步处理,而这种异步处理的方式大大的节省了服务器的请求响应时间,从而提高了系统的吞吐量。
-
开发中消息队列通常有如下应用场景:
1、任务异步处理
将不需要同步处理的并且耗时长的操作由消息队列通知消息接收方进行异步处理。提高了应用程序的响应时间。
2、应用程序解耦合
MQ相当于一个中介,生产方通过MQ与消费方交互,它将应用程序进行解耦合。
比如订单系统要远程调用库存系统、支付系统、物流系统,这样会耦合,修改参数时候麻烦。
使用消息队列后,订单系统给消息MQ发送一条消息就算成功了
3、削峰填谷
如订单系统,在下单的时候就会往数据库写数据。但是数据库只能支撑每秒1000左右的并发写入,并发量再高就容易宕机。低峰期的时候并发也就100多个,但是在高峰期时候,并发量会突然激增到5000以上,这个时候数据库肯定卡死了。
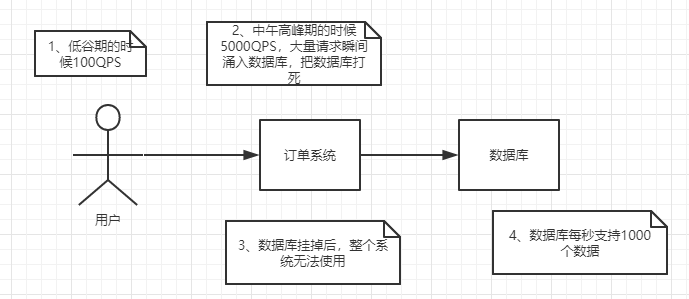
消息被MQ保存起来了,然后系统就可以按照自己的消费能力来消费,比如每秒1000个数据,这样慢慢写入数据库,这样就不会卡死数据库了。
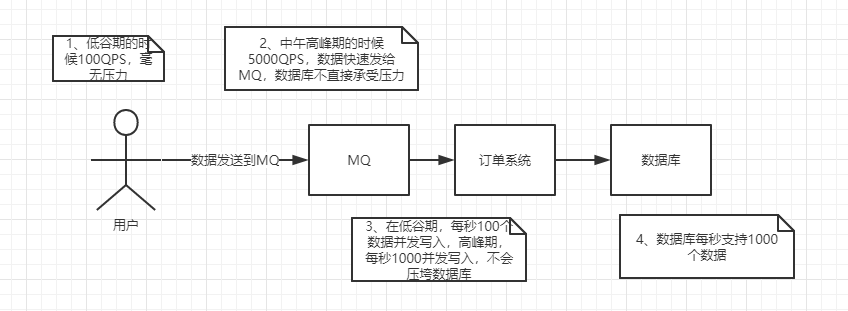
但是使用了MQ之后,限制消费消息的速度为1000,但是这样一来,高峰期产生的数据势必会被积压在MQ中,高峰就被“削”掉了。但是因为消息积压,在高峰期过后的一段时间内,消费消息的速度还是会维持在1000QPS,直到消费完积压的消息,这就叫做“填谷”
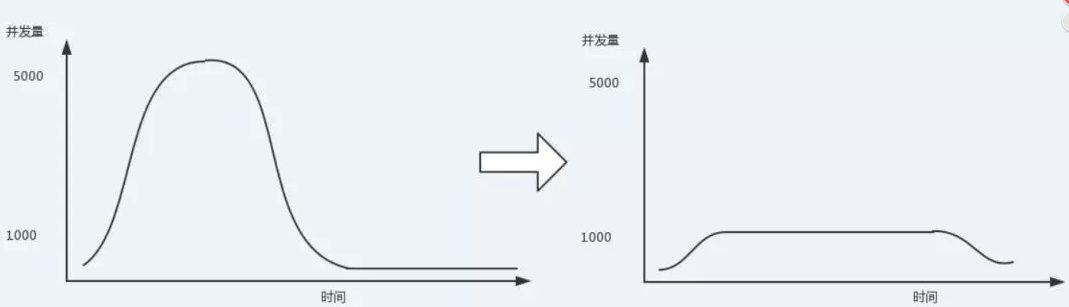
1.2. AMQP 和 JMS
MQ是消息通信的模型;实现MQ的大致有两种主流方式:AMQP、JMS。
1.2.1. AMQP
AMQP,即 Advanced Message Queuing Protocol(高级消息队列协议),是一个网络协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。2006年,AMQP 规范发布。类比HTTP。
AMQP是一种协议,更准确的说是一种binary wire-level protocol(链接协议)。这是其和JMS的本质差别,AMQP不从API层进行限定,而是直接定义网络交换的数据格式。
1.2.2. JMS
JMS即Java消息服务(JavaMessage Service)应用程序接口,是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信。
1.2.3. AMQP 与 JMS 区别
- JMS是定义了统一的接口,来对消息操作进行统一;AMQP是通过规定协议来统一数据交互的格式
- JMS限定了必须使用Java语言;AMQP只是协议,不规定实现方式,因此是跨语言的。
- JMS规定了两种消息模式;而AMQP的消息模式更加丰富
1.3. 消息队列产品
市场上常见的消息队列有如下:
- ActiveMQ:基于JMS
- ZeroMQ:基于C语言开发
- RabbitMQ:基于AMQP协议,erlang语言开发,稳定性好
- RocketMQ:基于JMS,阿里巴巴产品
- Kafka:类似MQ的产品;分布式消息系统,高吞吐量
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义 | 自定义协议,社区封装了http协议支持 |
| 客户端支持语言 | 官方支持Erlang,Java,Ruby等,社区产出多种API,几乎支持所有语言 | Java,C,C++,Python,PHP,Perl,.net等 | Java,C++(不成熟) | 官方支持Java,社区产出多种API,如PHP,Python等 |
| 单机吞吐量 | 万级(其次) | 万级(最差) | 十万级(最好) | 十万级(次之) |
| 消息延迟 | 微妙级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 功能特性 | 并发能力强,性能极其好,延时低,社区活跃,管理界面丰富 | 老牌产品,成熟度高,文档较多 | MQ功能比较完备,扩展性佳 | 只支持主要的MQ功能,毕竟是为大数据领域准备的。 |
1.4. RabbitMQ
RabbitMQ是由erlang语言开发,基于AMQP(Advanced Message Queue 高级消息队列协议)协议实现的消息队列,它是一种应用程序之间的通信方法,消息队列在分布式系统开发中应用非常广泛。
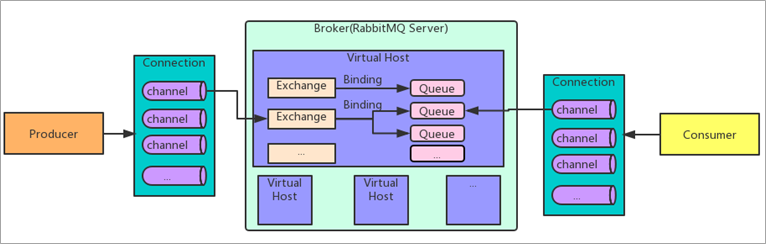
RabbitMQ官方地址:http://www.rabbitmq.com/
RabbitMQ提供了6种模式:简单模式,work模式,Publish/Subscribe发布与订阅模式,Routing路由模式,Topics主题模式,RPC远程调用模式(远程调用,不太算MQ;暂不作介绍);
官网对应模式介绍:https://www.rabbitmq.com/getstarted.html
2. 安装及配置RabbitMQ
详细查看 资料/软件/安装RabbitMQ.md 文档。
3. RabbitMQ入门
3.1. 搭建示例工程
创建工程
添加依赖
往pom.xml文件中添加如下依赖:
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.6.0</version>
</dependency>
3.2. 编写生产者
编写消息生产者Producer
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class Producer {
static final String QUEUE_NAME = "simple_queue";
public static void main(String[] args) throws Exception {
//创建连接工厂
ConnectionFactory connectionFactory = new ConnectionFactory();
//主机地址;默认为 localhost
connectionFactory.setHost("localhost");
//连接端口;默认为 5672
connectionFactory.setPort(5672);
//虚拟主机名称;默认为 /
connectionFactory.setVirtualHost("/itcast");
//连接用户名;默认为guest
connectionFactory.setUsername("heima");
//连接密码;默认为guest
connectionFactory.setPassword("heima");
//创建连接
Connection connection = connectionFactory.newConnection();
// 创建频道
Channel channel = connection.createChannel();
// 声明(创建)队列
/**
* 参数1:队列名称
* 参数2:是否定义持久化队列
* 参数3:是否独占本次连接
* 参数4:是否在不使用的时候自动删除队列
* 参数5:队列其它参数
*/
channel.queueDeclare(QUEUE_NAME, true, false, false, null);
// 要发送的信息
String message = "你好;小兔子!";
/**
* 参数1:交换机名称,如果没有指定则使用默认Default Exchage
* 参数2:路由key,简单模式可以传递队列名称
* 参数3:消息其它属性
* 参数4:消息内容
*/
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println("已发送消息:" + message);
// 关闭资源
channel.close();
connection.close();
}
}
在执行上述的消息发送之后;可以登录rabbitMQ的管理控制台,可以发现队列和其消息:选择Queues选项卡后,可以看到simole-queue。再点击Get Message(s)可以看到消息
3.3. 编写消费者
抽取创建connection的工具类ConnectionUtil
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class ConnectionUtil {
public static Connection getConnection() throws Exception {
//创建连接工厂
ConnectionFactory connectionFactory = new ConnectionFactory();
//主机地址;默认为 localhost
connectionFactory.setHost("localhost");
//连接端口;默认为 5672
connectionFactory.setPort(5672);
//虚拟主机名称;默认为 /
connectionFactory.setVirtualHost("/itcast");
//连接用户名;默认为guest
connectionFactory.setUsername("heima");
//连接密码;默认为guest
connectionFactory.setPassword("heima");
//创建连接
return connectionFactory.newConnection();
}
}
编写消息的消费者Consumer
import com.itheima.rabbitmq.util.ConnectionUtil;
import com.rabbitmq.client.*;
import java.io.IOException;
public class Consumer {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
// 创建频道
Channel channel = connection.createChannel();
// 声明(创建)队列
/**
* 参数1:队列名称
* 参数2:是否定义持久化队列
* 参数3:是否独占本次连接
* 参数4:是否在不使用的时候自动删除队列
* 参数5:队列其它参数
*/
channel.queueDeclare(Producer.QUEUE_NAME, true, false, false, null);
//创建消费者;并设置消息处理
DefaultConsumer consumer = new DefaultConsumer(channel){
@Override
/**
* consumerTag 消息者标签,在channel.basicConsume时候可以指定
* envelope 消息包的内容,可从中获取消息id,消息routingkey,交换机,消息和重传标志(收到消息失败后是否需要重新发送)
* properties 属性信息
* body 消息
*/
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
//路由key
System.out.println("路由key为:" + envelope.getRoutingKey());
//交换机
System.out.println("交换机为:" + envelope.getExchange());
//消息id
System.out.println("消息id为:" + envelope.getDeliveryTag());
//收到的消息
System.out.println("接收到的消息为:" + new String(body, "utf-8"));
}
};
//监听消息
/**
* 参数1:队列名称
* 参数2:是否自动确认,设置为true为表示消息接收到自动向mq回复接收到了,mq接收到回复会删除消息,设置为false则需要手动确认
* 参数3:消息接收到后回调
*/
channel.basicConsume(Producer.QUEUE_NAME, true, consumer);
//不关闭资源,应该一直监听消息
//channel.close();
//connection.close();
}
}
3.4. 小结
上述的入门案例中中其实使用的是如下的简单模式:

在上图的模型中,有以下概念:
- P:生产者,也就是要发送消息的程序
- C:消费者:消息的接受者,会一直等待消息到来。
- queue:消息队列,图中红色部分。类似一个邮箱,可以缓存消息;生产者向其中投递消息,消费者从其中取出消息。
4. AMQP
4.1. 相关概念介绍
AMQP 一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。
AMQP是一个二进制协议,拥有一些现代化特点:多信道、协商式,异步,安全,扩平台,中立,高效。
RabbitMQ是AMQP协议的Erlang的实现。
| 概念 | 说明 |
|---|---|
| 连接Connection | 一个网络连接,比如TCP/IP套接字连接。 |
| 会话Session | 端点之间的命名对话。在一个会话上下文中,保证“恰好传递一次”。 |
| 信道Channel | 多路复用连接中的一条独立的双向数据流通道。为会话提供物理传输介质。 |
| 客户端Client | AMQP连接或者会话的发起者。AMQP是非对称的,客户端生产和消费消息,服务器存储和路由这些消息。 |
| 服务节点Broker | 消息中间件的服务节点;一般情况下可以将一个RabbitMQ Broker看作一台RabbitMQ 服务器。 |
| 端点 | AMQP对话的任意一方。一个AMQP连接包括两个端点(一个是客户端,一个是服务器)。 |
| 消费者Consumer | 一个从消息队列里请求消息的客户端程序。 |
| 生产者Producer | 一个向交换机发布消息的客户端应用程序。 |
4.2. RabbitMQ运转流程
在入门案例中:
- 生产者发送消息
- 生产者创建连接(Connection),开启一个信道(Channel),连接到RabbitMQ Broker;
- 声明队列并设置属性;如是否排它,是否持久化,是否自动删除;
- 将路由键(空字符串)与队列绑定起来;
- 发送消息至RabbitMQ Broker;
- 关闭信道;
- 关闭连接;
- 消费者接收消息
- 消费者创建连接(Connection),开启一个信道(Channel),连接到RabbitMQ Broker
- 向Broker 请求消费相应队列中的消息,设置相应的回调函数;
- 等待Broker回应闭关投递响应队列中的消息,消费者接收消息;
- 确认(ack,自动确认)接收到的消息;
- RabbitMQ从队列中删除相应已经被确认的消息;
- 关闭信道;
- 关闭连接;
4.3. 生产者流转过程说明
- 客户端与代理服务器Broker建立连接。会调用newConnection() 方法,这个方法会进一步封装Protocol Header 0-9-1 的报文头发送给Broker ,以此通知Broker 本次交互采用的是AMQPO-9-1 协议,紧接着Broker 返回Connection.Start 来建立连接,在连接的过程中涉及Connection.Start/.Start-OK 、Connection.Tune/.Tune-Ok ,Connection.Open/ .Open-Ok 这6 个命令的交互。
- 客户端调用connection.createChannel方法。此方法开启信道,其包装的channel.open命令发送给Broker,等待channel.basicPublish方法,对应的AMQP命令为Basic.Publish,这个命令包含了content Header 和content Body()。content Header 包含了消息体的属性,例如:投递模式,优先级等,content Body 包含了消息体本身。
- 客户端发送完消息需要关闭资源时,涉及到Channel.Close和Channl.Close-Ok 与Connetion.Close和Connection.Close-Ok的命令交互。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QcAgBkKR-1614701356653)(F:\12-消息中间件-RabbitMQ\day01_RabbitMQ基础入门\讲义\assets/生产者流转过程图.bmp)]
4.4. 消费者流转过程说明
- 消费者客户端与代理服务器Broker建立连接。会调用newConnection() 方法,这个方法会进一步封装Protocol Header 0-9-1 的报文头发送给Broker ,以此通知Broker 本次交互采用的是AMQPO-9-1 协议,紧接着Broker 返回Connection.Start 来建立连接,在连接的过程中涉及Connection.Start/.Start-OK 、Connection.Tune/.Tune-Ok ,Connection.Open/ .Open-Ok 这6 个命令的交互。
- 消费者客户端调用connection.createChannel方法。和生产者客户端一样,协议涉及Channel . Open/Open-Ok命令。
- 在真正消费之前,消费者客户端需要向Broker 发送Basic.Consume 命令(即调用channel.basicConsume 方法〉将Channel 置为接收模式,之后Broker 回执Basic . Consume - Ok 以告诉消费者客户端准备好消费消息。
- Broker 向消费者客户端推送(Push) 消息,即Basic.Deliver 命令,这个命令和Basic.Publish 命令一样会携带Content Header 和Content Body。
- 消费者接收到消息并正确消费之后,向Broker 发送确认,即Basic.Ack 命令。
- 客户端发送完消息需要关闭资源时,涉及到Channel.Close和Channl.Close-Ok 与Connetion.Close和Connection.Close-Ok的命令交互。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-65ItkMln-1614701356655)(F:\12-消息中间件-RabbitMQ\day01_RabbitMQ基础入门\讲义\assets/消费者流转过程图.bmp)]
5. RabbitMQ工作模式
4.1. Work queues工作队列模式
4.1.1. 模式说明
Work Queues与入门程序的简单模式相比,多了一个或一些消费端,多个消费端共同消费同一个队列中的消息。
应用场景:对于 任务过重或任务较多情况使用工作队列可以提高任务处理的速度。
4.1.2. 代码
Work Queues与入门程序的简单模式的代码是几乎一样的;可以完全复制,并复制多一个消费者进行多个消费者同时消费消息的测试。
1)生产者
import com.itheima.rabbitmq.util.ConnectionUtil;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class Producer {
static final String QUEUE_NAME = "work_queue";
public static void main(String[] args) throws Exception {
//创建连接
Connection connection = ConnectionUtil.getConnection();
// 创建频道
Channel channel = connection.createChannel();
// 声明(创建)队列
/**
* 参数1:队列名称
* 参数2:是否定义持久化队列
* 参数3:是否独占本次连接
* 参数4:是否在不使用的时候自动删除队列
* 参数5:队列其它参数
*/
channel.queueDeclare(QUEUE_NAME, true, false, false, null);
for (int i = 1; i <= 30; i++) {
// 发送信息
String message = "你好;小兔子!work模式--" + i;
/**
* 参数1:交换机名称,如果没有指定则使用默认Default Exchage
* 参数2:路由key,简单模式可以传递队列名称
* 参数3:消息其它属性
* 参数4:消息内容
*/
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println("已发送消息:" + message);
}
// 关闭资源
channel.close();
connection.close();
}
}
2)消费者1
import com.itheima.rabbitmq.util.ConnectionUtil;
import com.rabbitmq.client.*;
import java.io.IOException;
public class Consumer1 {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
// 创建频道
Channel channel = connection.createChannel();
// 声明(创建)队列
/**
* 参数1:队列名称
* 参数2:是否定义持久化队列
* 参数3:是否独占本次连接
* 参数4:是否在不使用的时候自动删除队列
* 参数5:队列其它参数
*/
channel.queueDeclare(Producer.QUEUE_NAME, true, false, false, null);
//一次只能接收并处理一个消息
channel.basicQos(1);
//创建消费者;并设置消息处理
DefaultConsumer consumer = new DefaultConsumer(channel){
@Override
/**
* consumerTag 消息者标签,在channel.basicConsume时候可以指定
* envelope 消息包的内容,可从中获取消息id,消息routingkey,交换机,消息和重传标志(收到消息失败后是否需要重新发送)
* properties 属性信息
* body 消息
*/
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
try {
//路由key
System.out.println("路由key为:" + envelope.getRoutingKey());
//交换机
System.out.println("交换机为:" + envelope.getExchange());
//消息id
System.out.println("消息id为:" + envelope.getDeliveryTag());
//收到的消息
System.out.println("消费者1-接收到的消息为:" + new String(body, "utf-8"));
Thread.sleep(1000);
//确认消息
channel.basicAck(envelope.getDeliveryTag(), false);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
//监听消息
/**
* 参数1:队列名称
* 参数2:是否自动确认,设置为true为表示消息接收到自动向mq回复接收到了,mq接收到回复会删除消息,设置为false则需要手动确认
* 参数3:消息接收到后回调
*/
channel.basicConsume(Producer.QUEUE_NAME, false, consumer);
}
}
3)消费者2
和消费者1一模一样,复制一份改名Consumer2.java即可
4.1.3. 测试
启动两个消费者,然后再启动生产者发送消息;到IDEA的两个消费者对应的控制台查看是否竞争性的接收到消息。
- 消费者1:接收到消息 1 3 5
- 消费者2:接收到消息 2 4 6
4.1.4. 小结
在一个队列中如果有多个消费者,那么消费者之间对于同一个消息的关系是竞争的关系。
4.2. 订阅模式类型
订阅模式示例图:
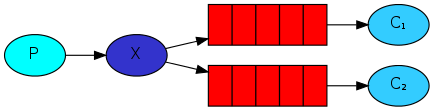
前面2个案例中,只有3个角色:
- P:生产者,也就是要发送消息的程序
- C:消费者:消息的接受者,会一直等待消息到来。
- queue:消息队列,图中红色部分
而在订阅模型中,多了一个exchange角色,而且过程略有变化:
- P:生产者,也就是要发送消息的程序,但是不再发送到队列中,而是发给X(交换机)
- C:消费者,消息的接受者,会一直等待消息到来。
- Queue:消息队列,接收消息、缓存消息。
- Exchange:交换机,图中的X。一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。Exchange有常见以下3种类型:
Fanout:广播,将消息交给所有绑定到交换机的队列Direct:定向,把消息交给符合指定routing key 的队列Topic:通配符,把消息交给符合routing pattern(路由模式) 的队列
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
4.3. Publish/Subscribe发布与订阅模式
4.3.1. 模式说明
Sending messages to many consumers at once
发布订阅模式:
1、每个消费者监听自己的队列。
2、生产者将消息发给broker,由交换机将消息转发到绑定此交换机的每个队列,每个绑定交换机的队列都将接收到消息
4.3.2. 代码
1)生产者
package com.itheima.rabbitmq.ps;
import com.itheima.rabbitmq.util.ConnectionUtil;
import com.rabbitmq.client.BuiltinExchangeType;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
/**
* 发布与订阅使用的交换机类型为:fanout
*/
public class Producer {
//交换机名称
static final String FANOUT_EXCHAGE = "fanout_exchange";
//队列名称
static final String FANOUT_QUEUE_1 = "fanout_queue_1";
//队列名称
static final String FANOUT_QUEUE_2 = "fanout_queue_2";
public static void main(String[] args) throws Exception {
//创建连接
Connection connection = ConnectionUtil.getConnection();
// 创建频道
Channel channel = connection.createChannel();
/**
* 声明交换机
* 参数1:交换机名称
* 参数2:交换机类型,fanout、topic、direct、headers
*/
channel.exchangeDeclare(FANOUT_EXCHAGE, BuiltinExchangeType.FANOUT);
// 声明(创建)队列
/**
* 参数1:队列名称
* 参数2:是否定义持久化队列
* 参数3:是否独占本次连接
* 参数4:是否在不使用的时候自动删除队列
* 参数5:队列其它参数
*/
channel.queueDeclare(FANOUT_QUEUE_1, true, false, false, null);
channel.queueDeclare(FANOUT_QUEUE_2, true, false, false, null);
//队列绑定交换机
channel.queueBind(FANOUT_QUEUE_1, FANOUT_EXCHAGE, "");
channel.queueBind(FANOUT_QUEUE_2, FANOUT_EXCHAGE, "");
for (int i = 1; i <= 10; i++) {
// 发送信息
String message = "你好;小兔子!发布订阅模式--" + i;
/**
* 参数1:交换机名称,如果没有指定则使用默认Default Exchage
* 参数2:路由key,简单模式可以传递队列名称
* 参数3:消息其它属性
* 参数4:消息内容
*/
channel.basicPublish(FANOUT_EXCHAGE, "", null, message.getBytes());
System.out.println("已发送消息:" + message);
}
// 关闭资源
channel.close();
connection.close();
}
}
2)消费者1
public class Consumer1 {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
// 创建频道
Channel channel = connection.createChannel();
//声明交换机
channel.exchangeDeclare(Producer.FANOUT_EXCHAGE, BuiltinExchangeType.FANOUT);
// 声明(创建)队列
/**
* 参数1:队列名称
* 参数2:是否定义持久化队列
* 参数3:是否独占本次连接
* 参数4:是否在不使用的时候自动删除队列
* 参数5:队列其它参数
*/
channel.queueDeclare(Producer.FANOUT_QUEUE_1, true, false, false, null);
//队列绑定交换机
channel.queueBind(Producer.FANOUT_QUEUE_1, Producer.FANOUT_EXCHAGE, "");
//创建消费者;并设置消息处理
DefaultConsumer consumer = new DefaultConsumer(channel){
@Override
/**
* consumerTag 消息者标签,在channel.basicConsume时候可以指定
* envelope 消息包的内容,可从中获取消息id,消息routingkey,交换机,消息和重传标志(收到消息失败后是否需要重新发送)
* properties 属性信息
* body 消息
*/
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
//路由key
System.out.println("路由key为:" + envelope.getRoutingKey());
//交换机
System.out.println("交换机为:" + envelope.getExchange());
//消息id
System.out.println("消息id为:" + envelope.getDeliveryTag());
//收到的消息
System.out.println("消费者1-接收到的消息为:" + new String(body, "utf-8"));
}
};
//监听消息
/**
* 参数1:队列名称
* 参数2:是否自动确认,设置为true为表示消息接收到自动向mq回复接收到了,mq接收到回复会删除消息,设置为false则需要手动确认
* 参数3:消息接收到后回调
*/
channel.basicConsume(Producer.FANOUT_QUEUE_1, true, consumer);
}
}
3)消费者2
指定不同的队列名称而已
import com.itheima.rabbitmq.util.ConnectionUtil;
import com.rabbitmq.client.*;
import java.io.IOException;
public class Consumer2 {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
// 创建频道
Channel channel = connection.createChannel();
//声明交换机
channel.exchangeDeclare(Producer.FANOUT_EXCHAGE, BuiltinExchangeType.FANOUT);
// 声明(创建)队列
/**
* 参数1:队列名称
* 参数2:是否定义持久化队列
* 参数3:是否独占本次连接
* 参数4:是否在不使用的时候自动删除队列
* 参数5:队列其它参数
*/
channel.queueDeclare(Producer.FANOUT_QUEUE_2, true, false, false, null);
//队列绑定交换机
channel.queueBind(Producer.FANOUT_QUEUE_2, Producer.FANOUT_EXCHAGE, "");
//创建消费者;并设置消息处理
DefaultConsumer consumer = new DefaultConsumer(channel){
@Override
/**
* consumerTag 消息者标签,在channel.basicConsume时候可以指定
* envelope 消息包的内容,可从中获取消息id,消息routingkey,交换机,消息和重传标志(收到消息失败后是否需要重新发送)
* properties 属性信息
* body 消息
*/
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
//路由key
System.out.println("路由key为:" + envelope.getRoutingKey());
//交换机
System.out.println("交换机为:" + envelope.getExchange());
//消息id
System.out.println("消息id为:" + envelope.getDeliveryTag());
//收到的消息
System.out.println("消费者2-接收到的消息为:" + new String(body, "utf-8"));
}
};
//监听消息
/**
* 参数1:队列名称
* 参数2:是否自动确认,设置为true为表示消息接收到自动向mq回复接收到了,mq接收到回复会删除消息,设置为false则需要手动确认
* 参数3:消息接收到后回调
*/
channel.basicConsume(Producer.FANOUT_QUEUE_2, true, consumer);
}
}
4.3.3. 测试
启动所有消费者,然后使用生产者发送消息;在每个消费者对应的控制台可以查看到生产者发送的所有消息;到达广播的效果。
在执行完测试代码后,其实到RabbitMQ的管理后台找到Exchanges选项卡,点击 fanout_exchange 的交换机,可以查看到如下的绑定:
- fanout-queue-1
- fanout-queue-2
4.3.4. 小结
交换机需要与队列进行绑定,绑定之后;一个消息可以被多个消费者都收到。
发布订阅模式与工作队列模式的区别
1、工作队列模式不用定义交换机,而发布/订阅模式需要定义交换机。
2、发布/订阅模式的生产方是面向交换机发送消息,工作队列模式的生产方是面向队列发送消息(底层使用默认交换机)。
3、发布/订阅模式需要设置队列和交换机的绑定,工作队列模式不需要设置,实际上工作队列模式会将队列绑 定到默认的交换机 。
4.4. Routing路由模式
4.4.1. 模式说明
路由模式特点:
- 队列与交换机的绑定,不能是任意绑定了,而是要指定一个
RoutingKey(路由key) - 消息的发送方在 向 Exchange发送消息时,也必须指定消息的
RoutingKey。 - Exchange不再把消息交给每一个绑定的队列,而是根据消息的
Routing Key进行判断,只有队列的Routingkey与消息的Routing key完全一致,才会接收到消息
Receiving messages selectively。下图代表不同级别的日志怎么处理,比如C1是文件,C2是控制台
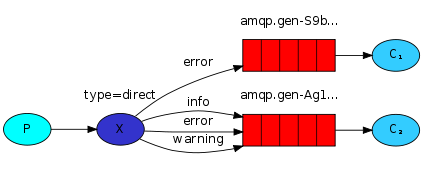
图解:
- P:生产者,向Exchange发送消息,发送消息时,会指定一个routing key。
- X:Exchange(交换机),接收生产者的消息,然后把消息递交给 与routing key完全匹配的队列
- C1:消费者,其所在队列指定了需要routing key 为 error 的消息
- C2:消费者,其所在队列指定了需要routing key 为 info、error、warning 的消息
发送的路由key和绑定的路由key一致时才匹配
4.4.2. 代码
在编码上与 Publish/Subscribe发布与订阅模式 的区别是交换机的类型为:Direct,还有队列绑定交换机的时候需要指定routing key。
1)生产者
/**
* 路由模式的交换机类型为:direct
*/
public class Producer {
//交换机名称
static final String DIRECT_EXCHAGE = "direct_exchange";
//队列名称
static final String DIRECT_QUEUE_INSERT = "direct_queue_insert";
//队列名称
static final String DIRECT_QUEUE_UPDATE = "direct_queue_update";
public static void main(String[] args) throws Exception {
//创建连接
Connection connection = ConnectionUtil.getConnection();
// 创建频道
Channel channel = connection.createChannel();
/**
* 声明交换机
* 参数1:交换机名称
* 参数2:交换机类型,fanout、topic、direct、headers
*/
channel.exchangeDeclare(DIRECT_EXCHAGE, BuiltinExchangeType.DIRECT);
// 声明(创建)队列
/**
* 参数1:队列名称
* 参数2:是否定义持久化队列
* 参数3:是否独占本次连接
* 参数4:是否在不使用的时候自动删除队列
* 参数5:队列其它参数
*/
channel.queueDeclare(DIRECT_QUEUE_INSERT, true, false, false, null);
channel.queueDeclare(DIRECT_QUEUE_UPDATE, true, false, false, null);
//队列绑定交换机
channel.queueBind(DIRECT_QUEUE_INSERT, DIRECT_EXCHAGE, "insert");
channel.queueBind(DIRECT_QUEUE_UPDATE, DIRECT_EXCHAGE, "update");
// 发送信息
String message = "新增了商品。路由模式;routing key 为 insert " ;
/**
* 参数1:交换机名称,如果没有指定则使用默认Default Exchage
* 参数2:路由key,简单模式可以传递队列名称
* 参数3:消息其它属性
* 参数4:消息内容
*/
channel.basicPublish(DIRECT_EXCHAGE, "insert", null, message.getBytes());
System.out.println("已发送消息:" + message);
// 发送信息
message = "修改了商品。路由模式;routing key 为 update" ;
/**
* 参数1:交换机名称,如果没有指定则使用默认Default Exchage
* 参数2:路由key,简单模式可以传递队列名称
* 参数3:消息其它属性
* 参数4:消息内容
*/
channel.basicPublish(DIRECT_EXCHAGE, "update", null, message.getBytes());
System.out.println("已发送消息:" + message);
// 关闭资源
channel.close();
connection.close();
}
}
2)消费者1
public class Consumer1 {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
// 创建频道
Channel channel = connection.createChannel();
//声明交换机
channel.exchangeDeclare(Producer.DIRECT_EXCHAGE, BuiltinExchangeType.DIRECT);
// 声明(创建)队列
/**
* 参数1:队列名称
* 参数2:是否定义持久化队列
* 参数3:是否独占本次连接
* 参数4:是否在不使用的时候自动删除队列
* 参数5:队列其它参数
*/
channel.queueDeclare(Producer.DIRECT_QUEUE_INSERT, true, false, false, null);
//队列绑定交换机
channel.queueBind(Producer.DIRECT_QUEUE_INSERT, Producer.DIRECT_EXCHAGE, "insert");
//创建消费者;并设置消息处理
DefaultConsumer consumer = new DefaultConsumer(channel){
@Override
/**
* consumerTag 消息者标签,在channel.basicConsume时候可以指定
* envelope 消息包的内容,可从中获取消息id,消息routingkey,交换机,消息和重传标志(收到消息失败后是否需要重新发送)
* properties 属性信息
* body 消息
*/
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
//路由key
System.out.println("路由key为:" + envelope.getRoutingKey());
//交换机
System.out.println("交换机为:" + envelope.getExchange());
//消息id
System.out.println("消息id为:" + envelope.getDeliveryTag());
//收到的消息
System.out.println("消费者1-接收到的消息为:" + new String(body, "utf-8"));
}
};
//监听消息
/**
* 参数1:队列名称
* 参数2:是否自动确认,设置为true为表示消息接收到自动向mq回复接收到了,mq接收到回复会删除消息,设置为false则需要手动确认
* 参数3:消息接收到后回调
*/
channel.basicConsume(Producer.DIRECT_QUEUE_INSERT, true, consumer);
}
}
3)消费者2
public class Consumer2 {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
// 创建频道
Channel channel = connection.createChannel();
//声明交换机
channel.exchangeDeclare(Producer.DIRECT_EXCHAGE, BuiltinExchangeType.DIRECT);
// 声明(创建)队列
/**
* 参数1:队列名称
* 参数2:是否定义持久化队列
* 参数3:是否独占本次连接
* 参数4:是否在不使用的时候自动删除队列
* 参数5:队列其它参数
*/
channel.queueDeclare(Producer.DIRECT_QUEUE_UPDATE, true, false, false, null);
//队列绑定交换机
channel.queueBind(Producer.DIRECT_QUEUE_UPDATE, Producer.DIRECT_EXCHAGE, "update");
//创建消费者;并设置消息处理
DefaultConsumer consumer = new DefaultConsumer(channel){
@Override
/**
* consumerTag 消息者标签,在channel.basicConsume时候可以指定
* envelope 消息包的内容,可从中获取消息id,消息routingkey,交换机,消息和重传标志(收到消息失败后是否需要重新发送)
* properties 属性信息
* body 消息
*/
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
//路由key
System.out.println("路由key为:" + envelope.getRoutingKey());
//交换机
System.out.println("交换机为:" + envelope.getExchange());
//消息id
System.out.println("消息id为:" + envelope.getDeliveryTag());
//收到的消息
System.out.println("消费者2-接收到的消息为:" + new String(body, "utf-8"));
}
};
//监听消息
/**
* 参数1:队列名称
* 参数2:是否自动确认,设置为true为表示消息接收到自动向mq回复接收到了,mq接收到回复会删除消息,设置为false则需要手动确认
* 参数3:消息接收到后回调
*/
channel.basicConsume(Producer.DIRECT_QUEUE_UPDATE, true, consumer);
}
}
4.4.3. 测试
启动所有消费者,然后使用生产者发送消息;在消费者对应的控制台可以查看到生产者发送对应routing key对应队列的消息;到达按照需要接收的效果。
在执行完测试代码后,其实到RabbitMQ的管理后台找到Exchanges选项卡,点击 direct_exchange 的交换机,可以查看到如下的绑定:
- direct-queue-insert:insert
- direct-queue-update:update
4.4.4. 小结
Routing模式要求队列在绑定交换机时要指定routing key,消息会转发到符合routing key的队列。
4.5. Topics通配符模式
4.5.1. 模式说明
Topic类型与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型Exchange可以让队列在绑定Routing key 的时候使用通配符!
Routingkey 一般都是有一个或多个单词组成,多个单词之间以”.”分割,例如: item.insert
通配符规则:
#:匹配一个或多个词
*:匹配不多不少恰好1个词
举例:
item.#:能够匹配item.insert.abc 或者 item.insert
item.*:只能匹配item.insert
Receiving messages based on a pattern (topics)
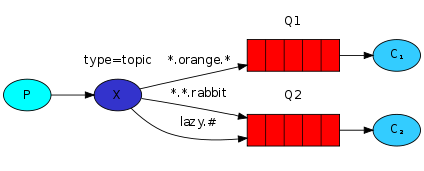
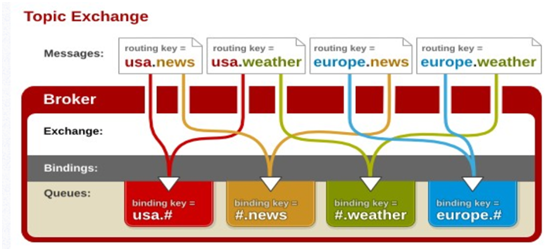
图解:
- 红色Queue:绑定的是
usa.#,因此凡是以usa.开头的routing key都会被匹配到 - 黄色Queue:绑定的是
#.news,因此凡是以.news结尾的routing key都会被匹配
4.5.2. 代码
1)生产者
使用topic类型的Exchange,发送消息的routing key有3种: item.insert、item.update、item.delete:
/**
* 通配符Topic的交换机类型为:topic
*/
public class Producer {
//交换机名称
static final String TOPIC_EXCHAGE = "topic_exchange";
//队列名称
static final String TOPIC_QUEUE_1 = "topic_queue_1";
//队列名称
static final String TOPIC_QUEUE_2 = "topic_queue_2";
public static void main(String[] args) throws Exception {
//创建连接
Connection connection = ConnectionUtil.getConnection();
// 创建频道
Channel channel = connection.createChannel();
/**
* 声明交换机
* 参数1:交换机名称
* 参数2:交换机类型,fanout、topic、topic、headers
*/
channel.exchangeDeclare(TOPIC_EXCHAGE, BuiltinExchangeType.TOPIC);
// 发送信息
String message = "新增了商品。Topic模式;routing key 为 item.insert " ;
channel.basicPublish(TOPIC_EXCHAGE, "item.insert", null, message.getBytes());
System.out.println("已发送消息:" + message);
// 发送信息
message = "修改了商品。Topic模式;routing key 为 item.update" ;
channel.basicPublish(TOPIC_EXCHAGE, "item.update", null, message.getBytes());
System.out.println("已发送消息:" + message);
// 发送信息
message = "删除了商品。Topic模式;routing key 为 item.delete" ;
channel.basicPublish(TOPIC_EXCHAGE, "item.delete", null, message.getBytes());
System.out.println("已发送消息:" + message);
// 关闭资源
channel.close();
connection.close();
}
}
2)消费者1
接收两种类型的消息:更新商品和删除商品
public class Consumer1 {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
// 创建频道
Channel channel = connection.createChannel();
//声明交换机
channel.exchangeDeclare(Producer.TOPIC_EXCHAGE, BuiltinExchangeType.TOPIC);
// 声明(创建)队列
/**
* 参数1:队列名称
* 参数2:是否定义持久化队列
* 参数3:是否独占本次连接
* 参数4:是否在不使用的时候自动删除队列
* 参数5:队列其它参数
*/
channel.queueDeclare(Producer.TOPIC_QUEUE_1, true, false, false, null);
//队列绑定交换机
channel.queueBind(Producer.TOPIC_QUEUE_1, Producer.TOPIC_EXCHAGE, "item.update");
channel.queueBind(Producer.TOPIC_QUEUE_1, Producer.TOPIC_EXCHAGE, "item.delete");
//创建消费者;并设置消息处理
DefaultConsumer consumer = new DefaultConsumer(channel){
@Override
/**
* consumerTag 消息者标签,在channel.basicConsume时候可以指定
* envelope 消息包的内容,可从中获取消息id,消息routingkey,交换机,消息和重传标志(收到消息失败后是否需要重新发送)
* properties 属性信息
* body 消息
*/
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
//路由key
System.out.println("路由key为:" + envelope.getRoutingKey());
//交换机
System.out.println("交换机为:" + envelope.getExchange());
//消息id
System.out.println("消息id为:" + envelope.getDeliveryTag());
//收到的消息
System.out.println("消费者1-接收到的消息为:" + new String(body, "utf-8"));
}
};
//监听消息
/**
* 参数1:队列名称
* 参数2:是否自动确认,设置为true为表示消息接收到自动向mq回复接收到了,mq接收到回复会删除消息,设置为false则需要手动确认
* 参数3:消息接收到后回调
*/
channel.basicConsume(Producer.TOPIC_QUEUE_1, true, consumer);
}
}
3)消费者2
接收所有类型的消息:新增商品,更新商品和删除商品。
public class Consumer2 {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionUtil.getConnection();
// 创建频道
Channel channel = connection.createChannel();
//声明交换机
channel.exchangeDeclare(Producer.TOPIC_EXCHAGE, BuiltinExchangeType.TOPIC);
// 声明(创建)队列
/**
* 参数1:队列名称
* 参数2:是否定义持久化队列
* 参数3:是否独占本次连接
* 参数4:是否在不使用的时候自动删除队列
* 参数5:队列其它参数
*/
channel.queueDeclare(Producer.TOPIC_QUEUE_2, true, false, false, null);
//队列绑定交换机
channel.queueBind(Producer.TOPIC_QUEUE_2, Producer.TOPIC_EXCHAGE, "item.*");
//创建消费者;并设置消息处理
DefaultConsumer consumer = new DefaultConsumer(channel){
@Override
/**
* consumerTag 消息者标签,在channel.basicConsume时候可以指定
* envelope 消息包的内容,可从中获取消息id,消息routingkey,交换机,消息和重传标志(收到消息失败后是否需要重新发送)
* properties 属性信息
* body 消息
*/
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
//路由key
System.out.println("路由key为:" + envelope.getRoutingKey());
//交换机
System.out.println("交换机为:" + envelope.getExchange());
//消息id
System.out.println("消息id为:" + envelope.getDeliveryTag());
//收到的消息
System.out.println("消费者2-接收到的消息为:" + new String(body, "utf-8"));
}
};
//监听消息
/**
* 参数1:队列名称
* 参数2:是否自动确认,设置为true为表示消息接收到自动向mq回复接收到了,mq接收到回复会删除消息,设置为false则需要手动确认
* 参数3:消息接收到后回调
*/
channel.basicConsume(Producer.TOPIC_QUEUE_2, true, consumer);
}
}
4.5.3. 测试
启动所有消费者,然后使用生产者发送消息;在消费者对应的控制台可以查看到生产者发送对应routing key对应队列的消息;到达按照需要接收的效果;并且这些routing key可以使用通配符。
在执行完测试代码后,其实到RabbitMQ的管理后台找到Exchanges选项卡,点击 topic_exchange 的交换机,可以查看到如下的绑定:
4.5.4. 小结
Topic主题模式可以实现 Publish/Subscribe发布与订阅模式 和 Routing路由模式 的功能;只是Topic在配置routing key 的时候可以使用通配符,显得更加灵活。
4.6. 模式总结
RabbitMQ工作模式:
1、简单模式 HelloWorld
一个生产者、一个消费者,不需要设置交换机(使用默认的交换机)
2、工作队列模式 Work Queue
一个生产者、多个消费者(竞争关系),不需要设置交换机(使用默认的交换机)
3、发布订阅模式 Publish/subscribe
需要设置类型为fanout的交换机,并且交换机和队列进行绑定,当发送消息到交换机后,交换机会将消息发送到绑定的队列
4、路由模式 Routing
需要设置类型为direct的交换机,交换机和队列进行绑定,并且指定routing key,当发送消息到交换机后,交换机会根据routing key将消息发送到对应的队列
5、通配符模式 Topic
需要设置类型为topic的交换机,交换机和队列进行绑定,并且指定通配符方式的routing key,当发送消息到交换机后,交换机会根据routing key将消息发送到对应的队列
5. Spring 整合RabbitMQ
5.1. 搭建生产者工程
5.1.1. 创建工程
修改pom.xml文件内容为如下:
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
<version>2.1.8.RELEASE</version>
</dependency>
5.1.2. 配置整合
-
创建`\resources\properties\rabbitmq.properties`连接参数等配置文件;
rabbitmq.host=192.168.12.135
rabbitmq.port=5672
rabbitmq.username=heima
rabbitmq.password=heima
rabbitmq.virtual-host=/itcast
-
创建 `\resources\spring\spring-rabbitmq.xml` 整合配置文件;
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:rabbit="http://www.springframework.org/schema/rabbit"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
https://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/rabbit
http://www.springframework.org/schema/rabbit/spring-rabbit.xsd">
<!--加载配置文件-->
<context:property-placeholder location="classpath:properties/rabbitmq.properties"/>
<!-- 定义rabbitmq connectionFactory -->
<rabbit:connection-factory id="connectionFactory" host="${rabbitmq.host}"
port="${rabbitmq.port}"
username="${rabbitmq.username}"
password="${rabbitmq.password}"
virtual-host="${rabbitmq.virtual-host}"/>
<!--定义管理交换机、队列-->
<rabbit:admin connection-factory="connectionFactory"/>
<!--定义持久化队列,不存在则自动创建;不绑定到交换机则绑定到默认交换机
默认交换机类型为direct,名字为:"",路由键为队列的名称
-->
<rabbit:queue id="spring_queue" name="spring_queue" auto-declare="true"/>
<!-- ~~~~~~~~~~~~~~~~~~~~~~~~~~~~广播;所有队列都能收到消息~~~~~~~~~~~~~~~~~~~~~~~~~~~~ -->
<!--定义广播交换机中的持久化队列,不存在则自动创建-->
<rabbit:queue id="spring_fanout_queue_1" name="spring_fanout_queue_1" auto-declare="true"/>
<!--定义广播交换机中的持久化队列,不存在则自动创建-->
<rabbit:queue id="spring_fanout_queue_2" name="spring_fanout_queue_2" auto-declare="true"/>
<!--定义广播类型交换机;并绑定上述两个队列-->
<rabbit:fanout-exchange id="spring_fanout_exchange" name="spring_fanout_exchange" auto-declare="true">
<rabbit:bindings>
<rabbit:binding queue="spring_fanout_queue_1"/>
<rabbit:binding queue="spring_fanout_queue_2"/>
</rabbit:bindings>
</rabbit:fanout-exchange>
<!-- ~~~~~~~~~~~~~~~~~~~~~~~~~~~~通配符;*匹配一个单词,#匹配多个单词 ~~~~~~~~~~~~~~~~~~~~~~~~~~~~ -->
<!--定义广播交换机中的持久化队列,不存在则自动创建-->
<rabbit:queue id="spring_topic_queue_star" name="spring_topic_queue_star" auto-declare="true"/>
<!--定义广播交换机中的持久化队列,不存在则自动创建-->
<rabbit:queue id="spring_topic_queue_well" name="spring_topic_queue_well" auto-declare="true"/>
<!--定义广播交换机中的持久化队列,不存在则自动创建-->
<rabbit:queue id="spring_topic_queue_well2" name="spring_topic_queue_well2" auto-declare="true"/>
<rabbit:topic-exchange id="spring_topic_exchange" name="spring_topic_exchange" auto-declare="true">
<rabbit:bindings>
<rabbit:binding pattern="heima.*" queue="spring_topic_queue_star"/>
<rabbit:binding pattern="heima.#" queue="spring_topic_queue_well"/>
<rabbit:binding pattern="itcast.#" queue="spring_topic_queue_well2"/>
</rabbit:bindings>
</rabbit:topic-exchange>
<!--定义rabbitTemplate对象操作可以在代码中方便发送消息-->
<rabbit:template id="rabbitTemplate" connection-factory="connectionFactory"/>
</beans>
5.1.3. 发送消息
创建测试文件 ProducerTest.java
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:spring/spring-rabbitmq.xml")
public class ProducerTest {
@Autowired
private RabbitTemplate rabbitTemplate;
/**
* 只发队列消息
* 默认交换机类型为 direct
* 交换机的名称为空,路由键为队列的名称
*/
@Test
public void queueTest(){
//路由键与队列同名
rabbitTemplate.convertAndSend("spring_queue", "只发队列spring_queue的消息。");
}
/**
* 发送广播
* 交换机类型为 fanout
* 绑定到该交换机的所有队列都能够收到消息
*/
@Test
public void fanoutTest(){
/**
* 参数1:交换机名称
* 参数2:路由键名(广播设置为空)
* 参数3:发送的消息内容
*/
rabbitTemplate.convertAndSend("spring_fanout_exchange", "", "发送到spring_fanout_exchange交换机的广播消息");
}
/**
* 通配符
* 交换机类型为 topic
* 匹配路由键的通配符,*表示一个单词,#表示多个单词
* 绑定到该交换机的匹配队列能够收到对应消息
*/
@Test
public void topicTest(){
/**
* 参数1:交换机名称
* 参数2:路由键名
* 参数3:发送的消息内容
*/
rabbitTemplate.convertAndSend("spring_topic_exchange", "heima.bj", "发送到spring_topic_exchange交换机heima.bj的消息");
rabbitTemplate.convertAndSend("spring_topic_exchange", "heima.bj.1", "发送到spring_topic_exchange交换机heima.bj.1的消息");
rabbitTemplate.convertAndSend("spring_topic_exchange", "heima.bj.2", "发送到spring_topic_exchange交换机heima.bj.2的消息");
rabbitTemplate.convertAndSend("spring_topic_exchange", "itcast.cn", "发送到spring_topic_exchange交换机itcast.cn的消息");
}
}
5.2. 搭建消费者工程
5.2.1. 创建工程
修改pom.xml文件内容为如下:
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
<version>2.1.8.RELEASE</version>
</dependency>
5.2.2. 配置整合
-
创建`spring-rabbitmq-consumer\src\main\resources\properties\rabbitmq.properties`连接参数等配置文件;
rabbitmq.host=192.168.12.135
rabbitmq.port=5672
rabbitmq.username=heima
rabbitmq.password=heima
rabbitmq.virtual-host=/itcast
-
创建 `\resources\spring\spring-rabbitmq.xml` 整合配置文件;
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:rabbit="http://www.springframework.org/schema/rabbit"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
https://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/rabbit
http://www.springframework.org/schema/rabbit/spring-rabbit.xsd">
<!--加载配置文件-->
<context:property-placeholder location="classpath:properties/rabbitmq.properties"/>
<!-- 定义rabbitmq connectionFactory -->
<rabbit:connection-factory id="connectionFactory" host="${rabbitmq.host}"
port="${rabbitmq.port}"
username="${rabbitmq.username}"
password="${rabbitmq.password}"
virtual-host="${rabbitmq.virtual-host}"/>
<bean id="springQueueListener" class="com.itheima.rabbitmq.listener.SpringQueueListener"/>
<bean id="fanoutListener1" class="com.itheima.rabbitmq.listener.FanoutListener1"/>
<bean id="fanoutListener2" class="com.itheima.rabbitmq.listener.FanoutListener2"/>
<bean id="topicListenerStar" class="com.itheima.rabbitmq.listener.TopicListenerStar"/>
<bean id="topicListenerWell" class="com.itheima.rabbitmq.listener.TopicListenerWell"/>
<bean id="topicListenerWell2" class="com.itheima.rabbitmq.listener.TopicListenerWell2"/>
<rabbit:listener-container connection-factory="connectionFactory" auto-declare="true">
<rabbit:listener ref="springQueueListener" queue-names="spring_queue"/>
<rabbit:listener ref="fanoutListener1" queue-names="spring_fanout_queue_1"/>
<rabbit:listener ref="fanoutListener2" queue-names="spring_fanout_queue_2"/>
<rabbit:listener ref="topicListenerStar" queue-names="spring_topic_queue_star"/>
<rabbit:listener ref="topicListenerWell" queue-names="spring_topic_queue_well"/>
<rabbit:listener ref="topicListenerWell2" queue-names="spring_topic_queue_well2"/>
</rabbit:listener-container>
</beans>
5.2.3. 消息监听器
1)队列监听器
创建 listener\SpringQueueListener.java
public class SpringQueueListener implements MessageListener {
public void onMessage(Message message) {
try {
String msg = new String(message.getBody(), "utf-8");
System.out.printf("接收路由名称为:%s,路由键为:%s,队列名为:%s的消息:%s \n",
message.getMessageProperties().getReceivedExchange(),
message.getMessageProperties().getReceivedRoutingKey(),
message.getMessageProperties().getConsumerQueue(),
msg);
} catch (Exception e) {
e.printStackTrace();
}
}
}
2)广播监听器1
创建 listener\FanoutListener1.java
public class FanoutListener1 implements MessageListener {
public void onMessage(Message message) {
try {
String msg = new String(message.getBody(), "utf-8");
System.out.printf("广播监听器1:接收路由名称为:%s,路由键为:%s,队列名为:%s的消息:%s \n",
message.getMessageProperties().getReceivedExchange(),
message.getMessageProperties().getReceivedRoutingKey(),
message.getMessageProperties().getConsumerQueue(),
msg);
} catch (Exception e) {
e.printStackTrace();
}
}
}
3)广播监听器2
创建 listener\FanoutListener2.java
public class FanoutListener2 implements MessageListener {
public void onMessage(Message message) {
try {
String msg = new String(message.getBody(), "utf-8");
System.out.printf("广播监听器2:接收路由名称为:%s,路由键为:%s,队列名为:%s的消息:%s \n",
message.getMessageProperties().getReceivedExchange(),
message.getMessageProperties().getReceivedRoutingKey(),
message.getMessageProperties().getConsumerQueue(),
msg);
} catch (Exception e) {
e.printStackTrace();
}
}
}
4)星号通配符监听器
创建 spring-rabbitmq-consumer\src\main\java\com\itheima\rabbitmq\listener\TopicListenerStar.java
public class TopicListenerStar implements MessageListener {
public void onMessage(Message message) {
try {
String msg = new String(message.getBody(), "utf-8");
System.out.printf("通配符*监听器:接收路由名称为:%s,路由键为:%s,队列名为:%s的消息:%s \n",
message.getMessageProperties().getReceivedExchange(),
message.getMessageProperties().getReceivedRoutingKey(),
message.getMessageProperties().getConsumerQueue(),
msg);
} catch (Exception e) {
e.printStackTrace();
}
}
}
5)井号通配符监听器
创建 spring-rabbitmq-consumer\src\main\java\com\itheima\rabbitmq\listener\TopicListenerWell.java
public class TopicListenerWell implements MessageListener {
public void onMessage(Message message) {
try {
String msg = new String(message.getBody(), "utf-8");
System.out.printf("通配符#监听器:接收路由名称为:%s,路由键为:%s,队列名为:%s的消息:%s \n",
message.getMessageProperties().getReceivedExchange(),
message.getMessageProperties().getReceivedRoutingKey(),
message.getMessageProperties().getConsumerQueue(),
msg);
} catch (Exception e) {
e.printStackTrace();
}
}
}
6)井号通配符监听器2
创建 spring-rabbitmq-consumer\src\main\java\com\itheima\rabbitmq\listener\TopicListenerWell2.java
public class TopicListenerWell2 implements MessageListener {
public void onMessage(Message message) {
try {
String msg = new String(message.getBody(), "utf-8");
System.out.printf("通配符#监听器2:接收路由名称为:%s,路由键为:%s,队列名为:%s的消息:%s \n",
message.getMessageProperties().getReceivedExchange(),
message.getMessageProperties().getReceivedRoutingKey(),
message.getMessageProperties().getConsumerQueue(),
msg);
} catch (Exception e) {
e.printStackTrace();
}
}
}
6. Spring Boot整合RabbitMQ
6.1. 简介
在Spring项目中,可以使用Spring-Rabbit去操作RabbitMQ
https://github.com/spring-projects/spring-amqp
尤其是在spring boot项目中只需要引入对应的amqp启动器依赖即可,方便的使用RabbitTemplate发送消息,使用注解接收消息。
一般在开发过程中:
生产者工程:
-
application.yml文件配置RabbitMQ相关信息;
-
在生产者工程中编写配置类,用于创建交换机和队列,并进行绑定
-
注入RabbitTemplate对象,通过RabbitTemplate对象发送消息到交换机
消费者工程:
-
application.yml文件配置RabbitMQ相关信息
-
创建消息处理类,用于接收队列中的消息并进行处理
5.2. 搭建生产者工程
5.2.1. 创建工程
创建生产者工程springboot-rabbitmq-producer
修改pom.xml文件内容为如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
5.2.2. 启动类
@SpringBootApplication
public class ProducerApplication {
public static void main(String[] args) {
SpringApplication.run(ProducerApplication.class);
}
}
5.2.3. 配置RabbitMQ
1)配置文件
创建application.yml,内容如下:
spring:
rabbitmq:
host: localhost
port: 5672
virtual-host: /itcast
username: heima
password: heima
2)绑定交换机和队列
创建RabbitMQ队列与交换机绑定的配置类config.RabbitMQConfig
@Configuration
public class RabbitMQConfig {
//交换机名称
public static final String ITEM_TOPIC_EXCHANGE = "item_topic_exchange";
//队列名称
public static final String ITEM_QUEUE = "item_queue";
//声明交换机
@Bean("itemTopicExchange")
public Exchange topicExchange(){
return ExchangeBuilder.topicExchange(ITEM_TOPIC_EXCHANGE).durable(true).build();
}
//声明队列
@Bean("itemQueue")
public Queue itemQueue(){
return QueueBuilder.durable(ITEM_QUEUE).build();
}
//绑定队列和交换机
@Bean
public Binding itemQueueExchange(@Qualifier("itemQueue") Queue queue,
@Qualifier("itemTopicExchange") Exchange exchange){
return BindingBuilder.bind(queue).to(exchange).with("item.#").noargs();
}
}
5.3. 搭建消费者工程
5.3.1. 创建工程
创建消费者工程springboot-rabbitmq-consumer
修改pom.xml文件内容为如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
5.3.2. 启动类
@SpringBootApplication
public class ConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(ConsumerApplication.class);
}
}
5.3.3. 配置RabbitMQ
创建application.yml,内容如下:
spring:
rabbitmq:
host: localhost
port: 5672
virtual-host: /itcast
username: heima
password: heima
5.3.4. 消息监听处理类
编写消息监听器com.itheima.rabbitmq.listener.MyListener
@Component
public class MyListener {
/**
* 监听某个队列的消息
* @param message 接收到的消息
*/
@RabbitListener(queues = "item_queue")
public void myListener1(String message){
System.out.println("消费者接收到的消息为:" + message);
}
}
5.4. 测试
在生产者工程springboot-rabbitmq-producer中创建测试类,发送消息:
@RunWith(SpringRunner.class)
@SpringBootTest
public class RabbitMQTest {
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void test(){
rabbitTemplate.convertAndSend(RabbitMQConfig.ITEM_TOPIC_EXCHANGE, "item.insert", "商品新增,routing key 为item.insert");
rabbitTemplate.convertAndSend(RabbitMQConfig.ITEM_TOPIC_EXCHANGE, "item.update", "商品修改,routing key 为item.update");
rabbitTemplate.convertAndSend(RabbitMQConfig.ITEM_TOPIC_EXCHANGE, "item.delete", "商品删除,routing key 为item.delete");
}
}
先运行上述测试程序(交换机和队列才能先被声明和绑定),然后启动消费者;在消费者工程springboot-rabbitmq-consumer中控制台查看是否接收到对应消息。
另外;也可以在RabbitMQ的管理控制台中查看到交换机与队列的绑定:
RabbitMQ****高级特性
?消息可靠性投递:生产者到MQ中间件
?Consumer ACK:MQ中间件到消费端
?消费端限流
?TTL
?死信队列
?延迟队列
?日志与监控
?消息可靠性分析与追踪
?管理
RabbitMQ应用问题
?消息可靠性保障
?消息幂等性处理
RabbitMQ集群搭建
?RabbitMQ高可用集群
1. RabbitMQ 高级特性
1.1 消息的可靠投递
在使用 RabbitMQ 的时候,作为消息发送方希望杜绝任何消息丢失或者投递失败场景。RabbitMQ 为我们提供了两种方式用来控制消息的投递可靠性模式。
- confirm 确认模式
- return 退回模式
rabbitmq 整个消息投递的路径为:
producer—>rabbitmq-broker—>exchange—>queue—>consumer
- 生产:消息从 producer 到 exchange 则会返回一个
confirmCallback()。都会执行,返回false就失败 - 内部:消息从 exchange–>queue 投递失败则会返回一个
returnCallback()。
我们将利用这两个 callback 控制消息的可靠性投递
确认
<!-- 定义rabbitmq connectionFactory -->
<rabbit:connection-factory id="connectionFactory" host="${rabbitmq.host}"
port="${rabbitmq.port}"
username="${rabbitmq.username}"
password="${rabbitmq.password}"
virtual-host="${rabbitmq.virtual-host}"
publisher-confirms="true"
/>
@Autowired
private RabbitTemplate rabbitTemplate;
/**
* 确认模式:
* 步骤:
* 1. 确认模式开启:ConnectionFactory中开启publisher-confirms="true"
* 2. 在rabbitTemplate定义ConfirmCallBack回调函数
*/
@Test
public void testConfirm() {
//2. 定义回调
rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() {
/**
* @param correlationData 相关配置信息
* @param ack exchange交换机 是否成功收到了消息。true 成功,false代表失败
* @param cause 失败原因
*/
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
if (ack) { //接收成功
System.out.println("接收成功消息" + cause);
} else { //接收失败。如何失败:交换机等配置错误
System.out.println("接收失败消息" + cause);
//做一些处理,让消息再次发送。
}
}
});
//3. 发送消息
rabbitTemplate.convertAndSend("test_exchange_confirm111", "confirm", "message confirm....");
}
回退:
<!-- 定义rabbitmq connectionFactory -->
<rabbit:connection-factory id="connectionFactory" host="${rabbitmq.host}"
port="${rabbitmq.port}"
username="${rabbitmq.username}"
password="${rabbitmq.password}"
virtual-host="${rabbitmq.virtual-host}"
publisher-confirms="true"
publisher-returns="true"
/>
先设置rabbitTemplate.setMandatory(true);
然后处理消息回调的replyText
@Autowired
private RabbitTemplate rabbitTemplate;
/**
* 回退模式: 当消息发送给Exchange后,Exchange路由到Queue失败是 才会执行 ReturnCallBack
* 步骤:
* 1. 开启回退模式:publisher-returns="true"
* 2. 设置ReturnCallBack
* 3. 设置Exchange处理消息的模式:
* 1. 如果消息没有路由到Queue,则丢弃消息(默认)
* 2. 如果消息没有路由到Queue,返回给消息发送方ReturnCallBack
*/
@Test
public void testReturn() {
//设置交换机处理失败消息的模式
rabbitTemplate.setMandatory(true);
//2.设置ReturnCallBack
rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() {
/**
* @param message 消息对象
* @param replyCode 错误码
* @param replyText 错误信息
* @param exchange 交换机
* @param routingKey 路由键
*/
@Override
public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
System.out.println("return 执行了....");
System.out.println(message);
System.out.println(replyCode);
System.out.println(replyText);
System.out.println(exchange);
System.out.println(routingKey);
//处理
}
});
//3. 发送消息
rabbitTemplate.convertAndSend("test_exchange_confirm", "confirm", "message confirm....");
}
消息的可靠投递小结
- 设置ConnectionFactory的
publisher-confirms="true"开启 确认模式。 - 使用
rabbitTemplate.setConfirmCallback设置回调函数。当消息发送到exchange后回调confirm方法。在方法中判断ack,如果为true,则发送成功,如果为false,则发送失败,需要处理。 - 设置ConnectionFactory的
publisher-returns="true"开启 退回模式。 - 使用
rabbitTemplate.setReturnCallback设置退回函数,当消息从exchange路由到queue失败后,如果设置了rabbitTemplate.setMandatory(true)参数,则会将消息退回给producer。并执行回调函数returnedMessage。 - 在RabbitMQ中也提供了事务机制,但是性能较差,此处不做讲解。
使用channel下列方法,完成事务控制:
txSelect():用于将当前channel设置成transaction模式txCommit():用于提交事务txRollback():用于回滚事务
1.2 Consumer Ack
ack指Acknowledge,确认。 表示消费端收到消息后的确认方式。
有三种确认方式:
- 自动确认:
acknowledge="none"。不管处理成功与否,业务处理异常也不管 - 手动确认:
acknowledge="manual"。可以解决业务异常的情况 - 根据异常情况确认:
acknowledge="auto",(这种方式使用麻烦,不作讲解)
其中自动确认是指,当消息一旦被Consumer接收到,则自动确认收到,并将相应 message 从 RabbitMQ 的消息缓存中移除。但是在实际业务处理中,很可能消息接收到,业务处理出现异常,那么该消息就会丢失。如果设置了手动确认方式,则需要在业务处理成功后,调用channel.basicAck(),手动签收,如果出现异常,则调用channel.basicNack()方法,让其自动重新发送消息。
小结:
- 在
rabbit:listener-container标签中设置acknowledge属性,设置ack方式none:自动确认,manual:手动确认 - 如果在消费端没有出现异常,则调用
channel.basicAck(deliveryTag,false);方法确认签收消息 - 如果出现异常,则在catch中调用 basicNack或 basicReject,拒绝消息,让MQ重新发送消息。
AckListener
什么都不设置就是自动签收。下面讲解的是手动签收
<!--定义监听器容器-->
<rabbit:listener-container connection-factory="connectionFactory"
acknowledge="manual" >
<rabbit:listener ref="ackListener" queue-names="test_queue_confirm"></rabbit:listener>
</rabbit:listener-container>
/**
* Consumer ACK机制:
* 1. 设置手动签收。acknowledge="manual"
* 2. 让监听器类实现ChannelAwareMessageListener接口
* 3. 如果消息成功处理,则调用channel的 basicAck()签收
* 4. 如果消息处理失败,则调用channel的basicNack()拒绝签收,broker重新发送给consumer
*/
@Component
public class AckListener implements ChannelAwareMessageListener {
@Override
public void onMessage(Message message, Channel channel) throws Exception {
long deliveryTag = message.getMessageProperties().getDeliveryTag();
try {
//1.接收转换消息
System.out.println(new String(message.getBody()));
//2. 处理业务逻辑
System.out.println("处理业务逻辑...");
int i = 3/0;//出现错误
//3. 手动签收
channel.basicAck(deliveryTag,true);
} catch (Exception e) {
//e.printStackTrace();
//4.拒绝签收
/*
第三个参数:requeue:重回队列。如果设置为true,则消息重新回到queue,broker会重新发送该消息给消费端
*/
channel.basicNack(deliveryTag,true,true);
//channel.basicReject(deliveryTag,true);
}
}
}
<!--定义监听器容器-->
<rabbit:listener-container connection-factory="connectionFactory" acknowledge="manual" prefetch="1" >
<!-- <rabbit:listener ref="ackListener" queue-names="test_queue_confirm"></rabbit:listener>-->
<!-- <rabbit:listener ref="qosListener" queue-names="test_queue_confirm"></rabbit:listener>-->
<!--定义监听器,监听正常队列-->
<!--<rabbit:listener ref="dlxListener" queue-names="test_queue_dlx"></rabbit:listener>-->
<!--延迟队列效果实现: 一定要监听的是 死信队列!!!-->
<rabbit:listener ref="orderListener" queue-names="order_queue_dlx"></rabbit:listener>
</rabbit:listener-container>
@Component
public class DlxListener implements ChannelAwareMessageListener {
@Override
public void onMessage(Message message, Channel channel) throws Exception {
long deliveryTag = message.getMessageProperties().getDeliveryTag();
try {
//1.接收转换消息
System.out.println(new String(message.getBody()));
//2. 处理业务逻辑
System.out.println("处理业务逻辑...");
int i = 3/0;//出现错误
//3. 手动签收
channel.basicAck(deliveryTag,true);
} catch (Exception e) {
//e.printStackTrace();
System.out.println("出现异常,拒绝接受");
//4.拒绝签收,不重回队列 requeue=false
channel.basicNack(deliveryTag,true,false);
}
}
}
@Component
public class OrderListener implements ChannelAwareMessageListener {
@Override
public void onMessage(Message message, Channel channel) throws Exception {
long deliveryTag = message.getMessageProperties().getDeliveryTag();
try {
//1.接收转换消息
System.out.println(new String(message.getBody()));
//2. 处理业务逻辑
System.out.println("处理业务逻辑...");
System.out.println("根据订单id查询其状态...");
System.out.println("判断状态是否为支付成功");
System.out.println("取消订单,回滚库存....");
//3. 手动签收
channel.basicAck(deliveryTag,true);
} catch (Exception e) {
//e.printStackTrace();
System.out.println("出现异常,拒绝接受");
//4.拒绝签收,不重回队列 requeue=false
channel.basicNack(deliveryTag,true,false);
}
}
}
消息可靠性总结:
1.持久化
- exchange要持久化
- queue要持久化
- message要持久化
2.生产方确认Confirm
3.消费方确认Ack
4.Broker高可用
1.3 消费端限流
- 在
<rabbit:listener-container>中配置 prefetch属性设置消费端一次拉取多少消息 - 消费端的确认模式一定为手动确认。acknowledge=“manual”
<!--定义监听器容器-->
<rabbit:listener-container connection-factory="connectionFactory"
acknowledge="manual"
prefetch="1" >
<rabbit:listener ref="qosListener" queue-names="test_queue_confirm"></rabbit:listener>
</rabbit:listener-container>
/**
* Consumer 限流机制
* 1. 确保ack机制为手动确认。
* 2. listener-container配置属性
* perfetch = 1,表示消费端每次从mq拉去一条消息来消费,直到手动确认消费完毕后,才会继续拉去下一条消息。
*/
@Component
public class QosListener implements ChannelAwareMessageListener {
@Override
public void onMessage(Message message, Channel channel) throws Exception {
Thread.sleep(1000);
//1.获取消息
System.out.println(new String(message.getBody()));
//2. 处理业务逻辑
//3. 签收
channel.basicAck(message.getMessageProperties().getDeliveryTag(),true);
}
}
1.4 TTL
- TTL 全称 Time To Live(存活时间/过期时间)。
- 当消息到达存活时间后,还没有被消费,会被自动清除。
- RabbitMQ可以对消息设置过期时间,也可以对整个队列(Queue)设置过期时间。
可以在管理台新建队列、交换机,绑定
- 设置队列过期时间使用参数:
x-message-ttl,单位:ms(毫秒),会对整个队列消息统一过期。 - 设置消息过期时间使用参数:
expiration。单位:ms(毫秒),当该消息在队列头部时(消费时),会单独判断这一消息是否过期。 - 如果两者都进行了设置,以时间短的为准。
<!--ttl-->
<rabbit:queue name="test_queue_ttl" id="test_queue_ttl">
<!--设置queue的参数-->
<rabbit:queue-arguments>
<!--x-message-ttl指队列的过期时间-->
<entry key="x-message-ttl" value="100000" value-type="java.lang.Integer"></entry>
</rabbit:queue-arguments>
</rabbit:queue>
<rabbit:topic-exchange name="test_exchange_ttl" >
<rabbit:bindings>
<rabbit:binding pattern="ttl.#" queue="test_queue_ttl"></rabbit:binding>
</rabbit:bindings>
</rabbit:topic-exchange>
/**
* TTL:过期时间
* 1. 队列统一过期
* 2. 消息单独过期
*
* 如果设置了消息的过期时间,也设置了队列的过期时间,它以时间短的为准。
* 队列过期后,会将队列所有消息全部移除。
* 消息过期后,只有消息在队列顶端,才会判断其是否过期(移除掉)
*/
@Test
public void testTtl() {
/* for (int i = 0; i < 10; i++) {
// 发送消息
rabbitTemplate.convertAndSend("test_exchange_ttl", "ttl.hehe", "message ttl....");
}*/
// 消息后处理对象,设置一些消息的参数信息
MessagePostProcessor messagePostProcessor = new MessagePostProcessor() {
@Override
public Message postProcessMessage(Message message) throws AmqpException {
//1.设置message的信息
message.getMessageProperties().setExpiration("5000");//消息的过期时间
//2.返回该消息
return message;
}
};
//消息单独过期
for (int i = 0; i < 10; i++) {
if(i == 5){
//消息单独过期
rabbitTemplate.convertAndSend("test_exchange_ttl", "ttl.hehe", "message ttl....",messagePostProcessor);
}else{
//不过期的消息
rabbitTemplate.convertAndSend("test_exchange_ttl", "ttl.hehe", "message ttl....");
}
}
}
1.5 死信队列
死信队列,英文缩写:DLX 。Dead Letter Exchange(死信交换机,因为其他MQ产品中没有交换机的概念),当消息成为Dead message后,可以被重新发送到另一个交换机,这个交换机就是DLX。
比如消息队列的消息过期,如果绑定了死信交换器,那么该消息将发送给死信交换机
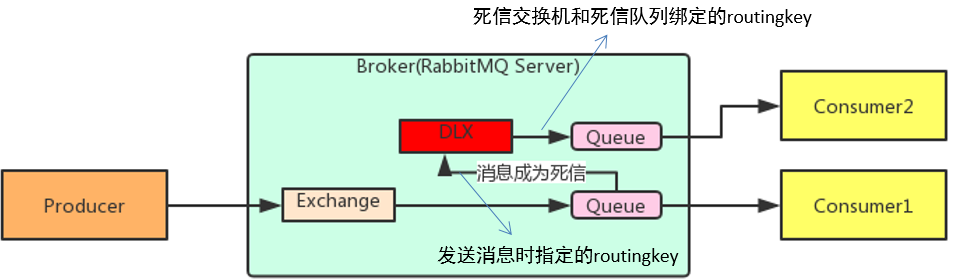
消息成为死信的三种情况:
- \1. 队列消息长度到达限制;
- \2. 消费者拒接消费消息,
basicNack/basicReject,并且不把消息重新放入原目标队列,requeue=false; - \3. 原队列存在消息过期设置,消息到达超时时间未被消费;
队列绑定死信交换机:
给队列设置参数: x-dead-letter-exchange 和 x-dead-letter-routing-key
小结:
- \1. 死信交换机和死信队列和普通的没有区别
- \2. 当消息成为死信后,如果该队列绑定了死信交换机,则消息会被死信交换机重新路由到死信队列
- \3. 消息成为死信的三种情况:
- \1. 队列消息长度到达限制;
- \2. 消费者拒接消费消息,并且不重回队列;
- \3. 原队列存在消息过期设置,消息到达超时时间未被消费;
<!--
死信队列:
1. 声明正常的队列(test_queue_dlx)和交换机(test_exchange_dlx)
2. 声明死信队列(queue_dlx)和死信交换机(exchange_dlx)
3. 正常队列绑定死信交换机
设置两个参数:
* x-dead-letter-exchange:死信交换机名称
* x-dead-letter-routing-key:发送给死信交换机的routingkey
-->
<!--
1. 声明正常的队列(test_queue_dlx)和交换机(test_exchange_dlx)
-->
<rabbit:queue name="test_queue_dlx" id="test_queue_dlx">
<!--3. 正常队列绑定死信交换机-->
<rabbit:queue-arguments>
<!--3.1 x-dead-letter-exchange:死信交换机名称-->
<entry key="x-dead-letter-exchange" value="exchange_dlx" />
<!--3.2 x-dead-letter-routing-key:发送给死信交换机的routingkey-->
<entry key="x-dead-letter-routing-key" value="dlx.hehe" />
<!--4.1 设置队列的过期时间 ttl-->
<entry key="x-message-ttl" value="10000" value-type="java.lang.Integer" />
<!--4.2 设置队列的长度限制 max-length -->
<entry key="x-max-length" value="10" value-type="java.lang.Integer" />
</rabbit:queue-arguments>
</rabbit:queue>
<rabbit:topic-exchange name="test_exchange_dlx">
<rabbit:bindings>
<rabbit:binding pattern="test.dlx.#" queue="test_queue_dlx"></rabbit:binding>
</rabbit:bindings>
</rabbit:topic-exchange>
<!--
2. 声明死信队列(queue_dlx)和死信交换机(exchange_dlx)
-->
<rabbit:queue name="queue_dlx" id="queue_dlx"></rabbit:queue>
<rabbit:topic-exchange name="exchange_dlx">
<rabbit:bindings>
<rabbit:binding pattern="dlx.#" queue="queue_dlx"></rabbit:binding>
</rabbit:bindings>
</rabbit:topic-exchange>
/**
* 发送测试死信消息:
* 1. 过期时间
* 2. 长度限制
* 3. 消息拒收
*/
@Test
public void testDlx(){
//1. 测试过期时间,死信消息
//rabbitTemplate.convertAndSend("test_exchange_dlx","test.dlx.haha","我是一条消息,我会死吗?");
//2. 测试长度限制后,消息死信
/* for (int i = 0; i < 20; i++) {
rabbitTemplate.convertAndSend("test_exchange_dlx","test.dlx.haha","我是一条消息,我会死吗?");
}*/
//3. 测试消息拒收
rabbitTemplate.convertAndSend("test_exchange_dlx","test.dlx.haha","我是一条消息,我会死吗?");
}
1.6 延迟队列
延迟队列,即消息进入队列后不会立即被消费,只有到达指定时间后,才会被消费。
需求:
- \1. 下单后,30分钟未支付,取消订单,回滚库存。
- \2. 新用户注册成功7天后,发送短信问候。

实现方式:
- \1. 定时器
- \2. 延迟队列
很可惜,在RabbitMQ中并未提供延迟队列功能。
但是可以使用:TTL+死信队列 组合实现延迟队列的效果。
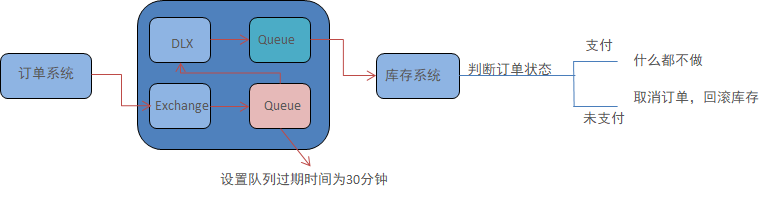
小结:
- \1. 延迟队列 指消息进入队列后,可以被延迟一定时间,再进行消费。
- \2. RabbitMQ没有提供延迟队列功能,但是可以使用 : TTL + DLX 来实现延迟队列效果。
<!--
延迟队列:
1. 定义正常交换机(order_exchange)和队列(order_queue)
2. 定义死信交换机(order_exchange_dlx)和队列(order_queue_dlx)
3. 绑定,设置正常队列过期时间为30分钟
-->
<!-- 1. 定义正常交换机(order_exchange)和队列(order_queue)-->
<rabbit:queue id="order_queue" name="order_queue">
<!-- 3. 绑定,设置正常队列过期时间为30分钟-->
<rabbit:queue-arguments>
<entry key="x-dead-letter-exchange" value="order_exchange_dlx" />
<entry key="x-dead-letter-routing-key" value="dlx.order.cancel" />
<entry key="x-message-ttl" value="10000" value-type="java.lang.Integer" />
</rabbit:queue-arguments>
</rabbit:queue>
<rabbit:topic-exchange name="order_exchange">
<rabbit:bindings>
<rabbit:binding pattern="order.#" queue="order_queue"></rabbit:binding>
</rabbit:bindings>
</rabbit:topic-exchange>
<!-- 2. 定义死信交换机(order_exchange_dlx)和队列(order_queue_dlx)-->
<rabbit:queue id="order_queue_dlx" name="order_queue_dlx"></rabbit:queue>
<rabbit:topic-exchange name="order_exchange_dlx">
<rabbit:bindings>
<rabbit:binding pattern="dlx.order.#" queue="order_queue_dlx"></rabbit:binding>
</rabbit:bindings>
</rabbit:topic-exchange>
@Test
public void testDelay() throws InterruptedException {
//1.发送订单消息。 将来是在订单系统中,下单成功后,发送消息
rabbitTemplate.convertAndSend("order_exchange","order.msg","订单信息:id=1,time=2019年8月17日16:41:47");
/*//2.打印倒计时10秒
for (int i = 10; i > 0 ; i--) {
System.out.println(i+"...");
Thread.sleep(1000);
}*/
}
1.7 日志与监控
1.7.1 RabbitMQ日志
RabbitMQ默认日志存放路径: /var/log/rabbitmq/rabbit@xxx.log
日志包含了RabbitMQ的版本号、Erlang的版本号、RabbitMQ服务节点名称、cookie的hash值、RabbitMQ配置文件地址、内存限制、磁盘限制、默认账户guest的创建以及权限配置等等。
1.7.2 web管控台监控
1.7.3 rabbitmqctl管理和监控
## 查看队列
rabbitmqctl list_queues
## 查看exchanges
rabbitmqctl list_exchanges
## 查看用户
rabbitmqctl list_users
## 查看连接
rabbitmqctl list_connections
## 查看消费者信息
rabbitmqctl list_consumers
## 查看环境变量
rabbitmqctl environment
## 查看未被确认的队列
rabbitmqctl list_queues name messages_unacknowledged
## 查看单个队列的内存使用
rabbitmqctl list_queues name memory
## 查看准备就绪的队列
rabbitmqctl list_queues name messages_ready
1.8 消息追踪
在使用任何消息中间件的过程中,难免会出现某条消息异常丢失的情况。对于RabbitMQ而言,可能是因为生产者或消费者与RabbitMQ断开了连接,而它们与RabbitMQ又采用了不同的确认机制;也有可能是因为交换器与队列之间不同的转发策略;甚至是交换器并没有与任何队列进行绑定,生产者又不感知或者没有采取相应的措施;另外RabbitMQ本身的集群策略也可能导致消息的丢失。这个时候就需要有一个较好的机制跟踪记录消息的投递过程,以此协助开发和运维人员进行问题的定位。
在RabbitMQ中可以使用Firehose和rabbitmq_tracing插件功能来实现消息追踪。
1.8 消息追踪-Firehose
firehose的机制是将生产者投递给rabbitmq的消息,rabbitmq投递给消费者的消息按照指定的格式发送到默认的exchange上。这个默认的exchange的名称为amq.rabbitmq.trace,它是一个topic类型的exchange。发送到这个exchange上的消息的routing key为 publish.exchangename 和 deliver.queuename。其中exchangename和queuename为实际exchange和queue的名称,分别对应生产者投递到exchange的消息,和消费者从queue上获取的消息。
注意:打开 trace 会影响消息写入功能,适当打开后请关闭。
- rabbitmqctl trace_on:开启Firehose命令
- rabbitmqctl trace_off:关闭Firehose命令
1.8 消息追踪-rabbitmq_tracing
rabbitmq_tracing和Firehose在实现上如出一辙,只不过rabbitmq_tracing的方式比Firehose多了一层GUI的包装,更容易使用和管理。
启用插件:rabbitmq-plugins enable rabbitmq_tracing
2. RabbitMQ 应用问题
RabbitMQ应用问题
\1. 消息可靠性保障
?消息补偿机制
\2. 消息幂等性保障
?乐观锁解决方案
2.1 消息可靠性保障
需求:100%确保消息发送成功
消息补偿:
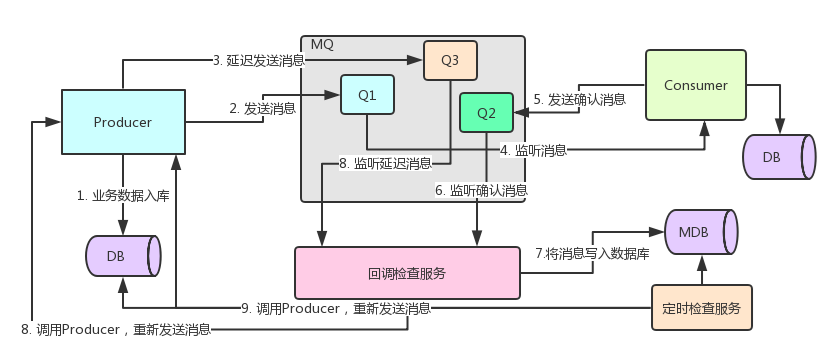
2发送正常消息,3过会再发一条相同的消息
2发送的消息在Q1中被正常消费到写入DB,发送ack给Q2。回调检查服务监听到Q2的消息,将消息写入MDB
如果1成功2失败,因为3页发送了消息放入Q3。此时回调检查服务也监听到了Q3,要去比对MDB是否一致,如果一致则代表消费过。如果MDB中不存在,就代表2失败了,就走8让生产者重新发。
如果2个都发送失败了,有MDB的定时检查服务,比对业务数据库DB与消息数据库MDB,就能发现差异
2.2 消息幂等性保障
幂等性指一次和多次请求某一个资源,对于资源本身应该具有同样的结果。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
在MQ中指,消费多条相同的消息,得到与消费该消息一次相同的结果。
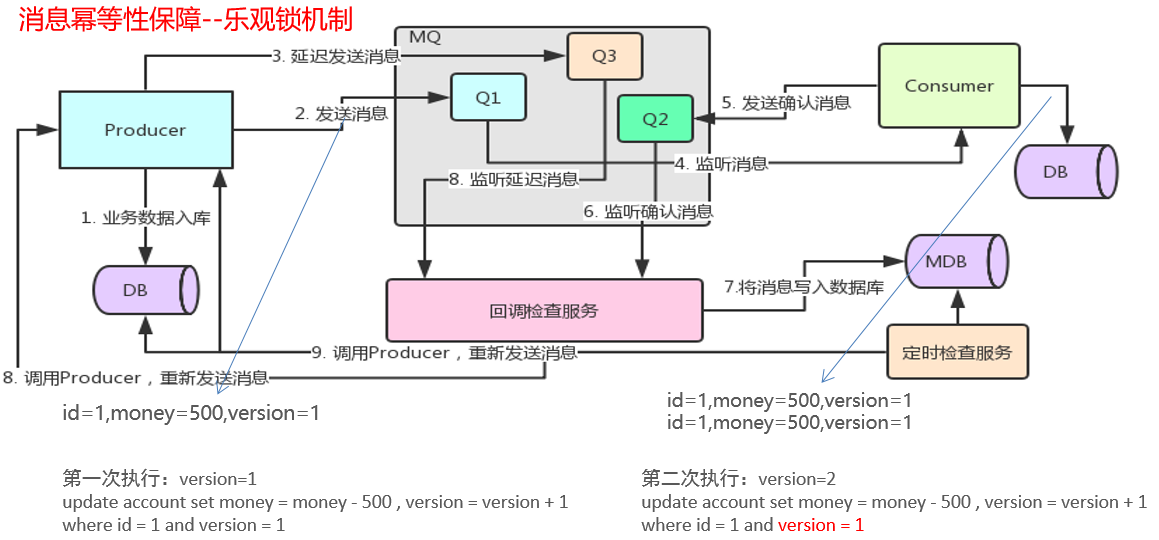
生产
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:spring-rabbitmq-producer.xml")
public class ProducerTest {
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void testSend() {
for (int i = 0; i < 10; i++) {
// 发送消息
rabbitTemplate.convertAndSend("test_exchange_confirm", "confirm", "message confirm....");
}
}
}
消费
/**
* 发送消息
*/
public class HelloWorld {
public static void main(String[] args) throws IOException, TimeoutException {
//1.创建连接工厂
ConnectionFactory factory = new ConnectionFactory();
//2. 设置参数
factory.setHost("172.16.98.133");//ip HaProxy的ip
factory.setPort(5672); //端口 HaProxy的监听的端口
//3. 创建连接 Connection
Connection connection = factory.newConnection();
//4. 创建Channel
Channel channel = connection.createChannel();
//5. 创建队列Queue
channel.queueDeclare("hello_world",true,false,false,null);
String body = "hello rabbitmq~~~";
//6. 发送消息
channel.basicPublish("","hello_world",null,body.getBytes());
//7.释放资源
channel.close();
connection.close();
System.out.println("send success....");
}
}
3.RabbitMQ集群搭建
摘要:实际生产应用中都会采用消息队列的集群方案,如果选择RabbitMQ那么有必要了解下它的集群方案原理
一般来说,如果只是为了学习RabbitMQ或者验证业务工程的正确性那么在本地环境或者测试环境上使用其单实例部署就可以了,但是出于MQ中间件本身的可靠性、并发性、吞吐量和消息堆积能力等问题的考虑,在生产环境上一般都会考虑使用RabbitMQ的集群方案。
3.1 集群方案的原理
RabbitMQ这款消息队列中间件产品本身是基于Erlang编写,Erlang语言天生具备分布式特性(通过同步Erlang集群各节点的magic cookie来实现)。因此,RabbitMQ天然支持Clustering。这使得RabbitMQ本身不需要像ActiveMQ、Kafka那样通过ZooKeeper分别来实现HA方案和保存集群的元数据。集群是保证可靠性的一种方式,同时可以通过水平扩展以达到增加消息吞吐量能力的目的。
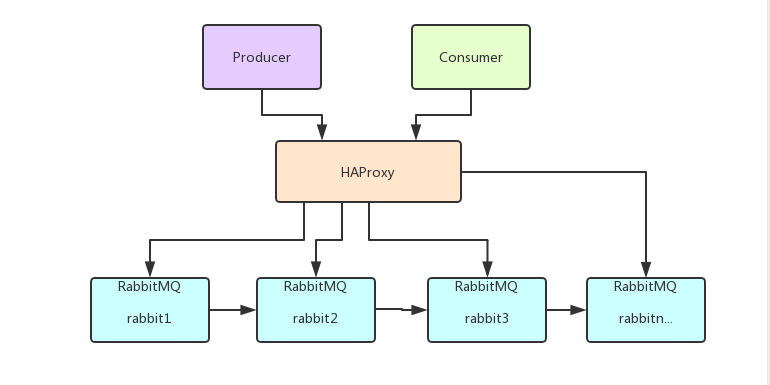
3.2 单机多实例部署
由于某些因素的限制,有时候你不得不在一台机器上去搭建一个rabbitmq集群,这个有点类似zookeeper的单机版。真实生成环境还是要配成多机集群的。有关怎么配置多机集群的可以参考其他的资料,这里主要论述如何在单机中配置多个rabbitmq实例。
主要参考官方文档:https://www.rabbitmq.com/clustering.html
首先确保RabbitMQ运行没有问题
[root@super ~]# rabbitmqctl status
Status of node rabbit@super ...
[{pid,10232},
{running_applications,
[{rabbitmq_management,"RabbitMQ Management Console","3.6.5"},
{rabbitmq_web_dispatch,"RabbitMQ Web Dispatcher","3.6.5"},
{webmachine,"webmachine","1.10.3"},
{mochiweb,"MochiMedia Web Server","2.13.1"},
{rabbitmq_management_agent,"RabbitMQ Management Agent","3.6.5"},
{rabbit,"RabbitMQ","3.6.5"},
{os_mon,"CPO CXC 138 46","2.4"},
{syntax_tools,"Syntax tools","1.7"},
{inets,"INETS CXC 138 49","6.2"},
{amqp_client,"RabbitMQ AMQP Client","3.6.5"},
{rabbit_common,[],"3.6.5"},
{ssl,"Erlang/OTP SSL application","7.3"},
{public_key,"Public key infrastructure","1.1.1"},
{asn1,"The Erlang ASN1 compiler version 4.0.2","4.0.2"},
{ranch,"Socket acceptor pool for TCP protocols.","1.2.1"},
{mnesia,"MNESIA CXC 138 12","4.13.3"},
{compiler,"ERTS CXC 138 10","6.0.3"},
{crypto,"CRYPTO","3.6.3"},
{xmerl,"XML parser","1.3.10"},
{sasl,"SASL CXC 138 11","2.7"},
{stdlib,"ERTS CXC 138 10","2.8"},
{kernel,"ERTS CXC 138 10","4.2"}]},
{os,{unix,linux}},
{erlang_version,
"Erlang/OTP 18 [erts-7.3] [source] [64-bit] [async-threads:64] [hipe] [kernel-poll:true]\n"},
{memory,
[{total,56066752},
{connection_readers,0},
{connection_writers,0},
{connection_channels,0},
{connection_other,2680},
{queue_procs,268248},
{queue_slave_procs,0},
{plugins,1131936},
{other_proc,18144280},
{mnesia,125304},
{mgmt_db,921312},
{msg_index,69440},
{other_ets,1413664},
{binary,755736},
{code,27824046},
{atom,1000601},
{other_system,4409505}]},
{alarms,[]},
{listeners,[{clustering,25672,"::"},{amqp,5672,"::"}]},
{vm_memory_high_watermark,0.4},
{vm_memory_limit,411294105},
{disk_free_limit,50000000},
{disk_free,13270233088},
{file_descriptors,
[{total_limit,924},{total_used,6},{sockets_limit,829},{sockets_used,0}]},
{processes,[{limit,1048576},{used,262}]},
{run_queue,0},
{uptime,43651},
{kernel,{net_ticktime,60}}]
停止rabbitmq服务
[root@super sbin]# service rabbitmq-server stop
Stopping rabbitmq-server: rabbitmq-server.
启动第一个节点:
[root@super sbin]# RABBITMQ_NODE_PORT=5673 RABBITMQ_NODENAME=rabbit1 rabbitmq-server start
RabbitMQ 3.6.5. Copyright (C) 2007-2016 Pivotal Software, Inc.
## ## Licensed under the MPL. See http://www.rabbitmq.com/
## ##
########## Logs: /var/log/rabbitmq/rabbit1.log
###### ## /var/log/rabbitmq/rabbit1-sasl.log
##########
Starting broker...
completed with 6 plugins.
启动第二个节点:
web管理插件端口占用,所以还要指定其web插件占用的端口号。
[root@super ~]# RABBITMQ_NODE_PORT=5674 RABBITMQ_SERVER_START_ARGS="-rabbitmq_management listener [{port,15674}]" RABBITMQ_NODENAME=rabbit2 rabbitmq-server start
RabbitMQ 3.6.5. Copyright (C) 2007-2016 Pivotal Software, Inc.
## ## Licensed under the MPL. See http://www.rabbitmq.com/
## ##
########## Logs: /var/log/rabbitmq/rabbit2.log
###### ## /var/log/rabbitmq/rabbit2-sasl.log
##########
Starting broker...
completed with 6 plugins.
结束命令:
rabbitmqctl -n rabbit1 stop
rabbitmqctl -n rabbit2 stop
rabbit1操作作为主节点:
[root@super ~]# rabbitmqctl -n rabbit1 stop_app
Stopping node rabbit1@super ...
[root@super ~]# rabbitmqctl -n rabbit1 reset
Resetting node rabbit1@super ...
[root@super ~]# rabbitmqctl -n rabbit1 start_app
Starting node rabbit1@super ...
[root@super ~]#
rabbit2操作为从节点:
[root@super ~]# rabbitmqctl -n rabbit2 stop_app
Stopping node rabbit2@super ...
[root@super ~]# rabbitmqctl -n rabbit2 reset
Resetting node rabbit2@super ...
[root@super ~]# rabbitmqctl -n rabbit2 join_cluster rabbit1@'super' ###''内是主机名换成自己的
Clustering node rabbit2@super with rabbit1@super ...
[root@super ~]# rabbitmqctl -n rabbit2 start_app
Starting node rabbit2@super ...
查看集群状态:
[root@super ~]# rabbitmqctl cluster_status -n rabbit1
Cluster status of node rabbit1@super ...
[{nodes,[{disc,[rabbit1@super,rabbit2@super]}]},
{running_nodes,[rabbit2@super,rabbit1@super]},
{cluster_name,<<"rabbit1@super">>},
{partitions,[]},
{alarms,[{rabbit2@super,[]},{rabbit1@super,[]}]}]
web监控:
- rabbit1@super
- rabbit2@super
3.3 集群管理
rabbitmqctl join_cluster {cluster_node} [–ram]
将节点加入指定集群中。在这个命令执行前需要停止RabbitMQ应用并重置节点。
rabbitmqctl cluster_status
显示集群的状态。
rabbitmqctl change_cluster_node_type {disc|ram}
修改集群节点的类型。在这个命令执行前需要停止RabbitMQ应用。
rabbitmqctl forget_cluster_node [–offline]
将节点从集群中删除,允许离线执行。
rabbitmqctl update_cluster_nodes {clusternode}
在集群中的节点应用启动前咨询clusternode节点的最新信息,并更新相应的集群信息。这个和join_cluster不同,它不加入集群。考虑这样一种情况,节点A和节点B都在集群中,当节点A离线了,节点C又和节点B组成了一个集群,然后节点B又离开了集群,当A醒来的时候,它会尝试联系节点B,但是这样会失败,因为节点B已经不在集群中了。
rabbitmqctl cancel_sync_queue [-p vhost] {queue}
取消队列queue同步镜像的操作。
rabbitmqctl set_cluster_name {name}
设置集群名称。集群名称在客户端连接时会通报给客户端。Federation和Shovel插件也会有用到集群名称的地方。集群名称默认是集群中第一个节点的名称,通过这个命令可以重新设置。
3.4 RabbitMQ镜像集群配置
上面已经完成RabbitMQ默认集群模式,但并不保证队列的高可用性,尽管交换机、绑定这些可以复制到集群里的任何一个节点,但是队列内容不会复制。虽然该模式解决一项目组节点压力,但队列节点宕机直接导致该队列无法应用,只能等待重启,所以要想在队列节点宕机或故障也能正常应用,就要复制队列内容到集群里的每个节点,必须要创建镜像队列。
镜像队列是基于普通的集群模式的,然后再添加一些策略,所以你还是得先配置普通集群,然后才能设置镜像队列,我们就以上面的集群接着做。
设置的镜像队列可以通过开启的网页的管理端Admin->Policies,也可以通过命令。
rabbitmqctl set_policy my_ha “^” ‘{“ha-mode”:“all”}’
在管理台点击Add/update a policy
- Name:策略名称 my_ha
- Pattern:匹配的规则,如果是匹配所有的队列,是^
- Definition:使用ha-mode模式中的all,也就是同步所有匹配的队列。问号链接帮助文档。
- apply-to:Exchanges and queues
3.5 负载均衡-HAProxy
HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案,包括Twitter,Reddit,StackOverflow,GitHub在内的多家知名互联网公司在使用。HAProxy实现了一种事件驱动、单一进程模型,此模型支持非常大的并发连接数。
3.5.1 安装HAProxy
//下载依赖包
yum install gcc vim wget
//上传haproxy源码包
//解压
tar -zxvf haproxy-1.6.5.tar.gz -C /usr/local
//进入目录、进行编译、安装
cd /usr/local/haproxy-1.6.5
make TARGET=linux31 PREFIX=/usr/local/haproxy
make install PREFIX=/usr/local/haproxy
mkdir /etc/haproxy
//赋权
groupadd -r -g 149 haproxy
useradd -g haproxy -r -s /sbin/nologin -u 149 haproxy
//创建haproxy配置文件
mkdir /etc/haproxy
vim /etc/haproxy/haproxy.cfg
3.5.2 配置HAProxy
配置文件路径:/etc/haproxy/haproxy.cfg
##logging options
global
log 127.0.0.1 local0 info
maxconn 5120
chroot /usr/local/haproxy
uid 99
gid 99
daemon
quiet
nbproc 20
pidfile /var/run/haproxy.pid
defaults
log global
mode tcp
option tcplog
option dontlognull
retries 3
option redispatch
maxconn 2000
contimeout 5s
clitimeout 60s
srvtimeout 15s
##front-end IP for consumers and producters
listen rabbitmq_cluster
bind 0.0.0.0:5672
mode tcp
#balance url_param userid
#balance url_param session_id check_post 64
#balance hdr(User-Agent)
#balance hdr(host)
#balance hdr(Host) use_domain_only
#balance rdp-cookie
#balance leastconn
#balance source //ip
balance roundrobin
server node1 127.0.0.1:5673 check inter 5000 rise 2 fall 2
server node2 127.0.0.1:5674 check inter 5000 rise 2 fall 2
listen stats
bind 172.16.98.133:8100
mode http
option httplog
stats enable
stats uri /rabbitmq-stats
stats refresh 5s
启动HAproxy负载
/usr/local/haproxy/sbin/haproxy -f /etc/haproxy/haproxy.cfg
//查看haproxy进程状态
ps -ef | grep haproxy
访问如下地址对mq节点进行监控
http://172.16.98.133:8100/rabbitmq-stats
代码中访问mq集群地址,则变为访问haproxy地址:5672
activeMQ
0 课程的大纲
1. 入门概述
1.1 MQ的产品种类和对比
MQ就是消息中间件。MQ是一种理念,ActiveMQ是MQ的落地产品。不管是哪款消息中间件,都有如下一些技术维度:
(1) kafka
编程语言:scala。
大数据领域的主流MQ。
(2) rabbitmq
编程语言:erlang
基于erlang语言,不好修改底层,不要查找问题的原因,不建议选用。
(3) rocketmq
编程语言:java
适用于大型项目。适用于集群。
(4) activemq
编程语言:java
适用于中小型项目。
1.2 MQ的产生背景
系统之间直接调用存在的问题?
微服务架构后,链式调用是我们在写程序时候的一般流程,为了完成一个整体功能会将其拆分成多个函数(或子模块),比如模块A调用模块B,模块B调用模块C,模块C调用模块D。但在大型分布式应用中,系统间的RPC交互繁杂,一个功能背后要调用上百个接口并非不可能,从单机架构过渡到分布式微服务架构的通例。这些架构会有哪些问题?
(1) 系统之间接口耦合比较严重
每新增一个下游功能,都要对上游的相关接口进行改造;
举个例子:如果系统A要发送数据给系统B和系统C,发送给每个系统的数据可能有差异,因此系统A对要发送给每个系统的数据进行了组装,然后逐一发送;
当代码上线后又新增了一个需求:把数据也发送给D,新上了一个D系统也要接受A系统的数据,此时就需要修改A系统,让他感知到D系统的存在,同时把数据处理好再给D。在这个过程你会看到,每接入一个下游系统,都要对系统A进行代码改造,开发联调的效率很低。其整体架构如下图:
(1) 面对大流量并发时,容易被冲垮
每个接口模块的吞吐能力是有限的,这个上限能力如果是堤坝,当大流量(洪水)来临时,容易被冲垮。
举个例子秒杀业务:上游系统发起下单购买操作,就是下单一个操作,很快就完成。然而,下游系统要完成秒杀业务后面的所有逻辑(读取订单,库存检查,库存冻结,余额检查,余额冻结,订单生产,余额扣减,库存减少,生成流水,余额解冻,库存解冻)。
(2) 等待同步存在性能问题
RPC接口上基本都是同步调用,整体的服务性能遵循“木桶理论”,即整体系统的耗时取决于链路中最慢的那个接口。比如A调用B/C/D都是50ms,但此时B又调用了B1,花费2000ms,那么直接就拖累了整个服务性能。
根据上述的几个问题,在设计系统时可以明确要达到的目标:
1,要做到系统解耦,当新的模块接进来时,可以做到代码改动最小;能够解耦
2,设置流量缓冲池,可以让后端系统按照自身吞吐能力进行消费,不被冲垮;能削峰
3,强弱依赖梳理能将非关键调用链路的操作异步化并提升整体系统的吞吐能力;能够异步
1.3 MQ的主要作用
(1) 异步。调用者无需等待。
(2) 解耦。解决了系统之间耦合调用的问题。
(3) 消峰。抵御洪峰流量,保护了主业务。
1.4 MQ的定义
面向消息的中间件(message-oriented middleware)MOM能够很好的解决以上问题。是指利用高效可靠的消息传递机制与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息排队模型在分布式环境下提供应用解耦,弹性伸缩,冗余存储、流量削峰,异步通信,数据同步等功能。
大致的过程是这样的:发送者把消息发送给消息服务器,消息服务器将消息存放在若干队列/主题topic中,在合适的时候,消息服务器回将消息转发给接受者。在这个过程中,发送和接收是异步的,也就是发送无需等待,而且发送者和接受者的生命周期也没有必然的关系;尤其在发布pub/订阅sub模式下,也可以完成一对多的通信,即让一个消息有多个接受者。
1.5 MQ的特点
(1)采用异步处理模式
消息发送者可以发送一个消息而无须等待响应。消息发送者将消息发送到一条虚拟的通道(主题或者队列)上;
消息接收者则订阅或者监听该爱通道。一条消息可能最终转发给一个或者多个消息接收者,这些消息接收者都无需对消息发送者做出同步回应。整个过程都是异步的。
案例:
也就是说,一个系统跟另一个系统之间进行通信的时候,假如系统A希望发送一个消息给系统B,让他去处理。但是系统A不关注系统B到底怎么处理或者有没有处理好,所以系统A把消息发送给MQ,然后就不管这条消息的“死活了”,接着系统B从MQ里面消费出来处理即可。至于怎么处理,是否处理完毕,什么时候处理,都是系统B的事儿,与系统A无关。
(1) 应用系统之间解耦合
发送者和接受者不必了解对方,只需要确认消息。
发送者和接受者不必同时在线。
(2) 整体架构
(1) MQ的缺点
两个系统之间不能同步调用,不能实时回复,不能响应某个调用的回复。
2 ActiveMQ安装和控制台
2 ActiveMQ安装和控制台
2.1 ActiveMQ安装
(1)官网下载
官网地址: http://activemq.apache.org/
2.2 安装步骤
2.3.1 安装java环境
2.3.2 通过文件传输,把文件传输到虚拟机
2.3.3 进入activemq的安装包./activemq start/stop 进行开启
2.3.4 启动时指定日志输出文件(重要)
activemq日志默认的位置是在:%activemq安装目录%/data/activemq.log
这是我们启动时指定日志输出文件:
[root@VM_0_14_centos raohao]# service activemq start > /opt/activemq.log
2.3.5 查看程序是否成功的三种方式
2.3 查看ActiveMQ控制台
http://192.168.241.168:8161 (账号admin 密码 admin)
3 入门案例
3.1 pom的导入
<dependencies>
<!-- activemq 所需要的jar 包-->
<dependency>
<groupId>org.apache.activemq</groupId>
<artifactId>activemq-all</artifactId>
<version>5.15.9</version>
</dependency>
<!-- activemq 和 spring 整合的基础包 -->
<dependency>
<groupId>org.apache.xbean</groupId>
<artifactId>xbean-spring</artifactId>
<version>3.16</version>
</dependency>
</dependencies>
3.2 JMS编码的总体规范
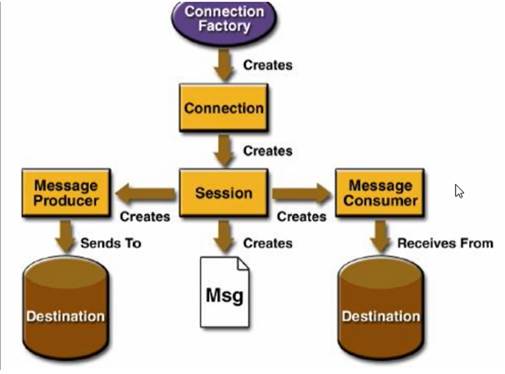
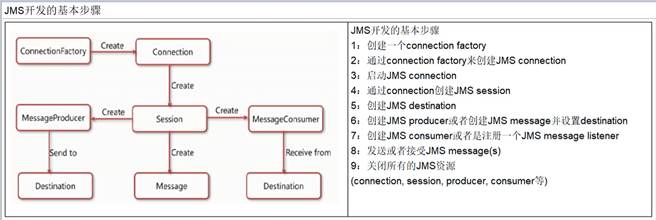
3.3 Destination简介
Destination是目的地。下面拿jvm和mq,做个对比。目的地,我们可以理解为是数据存储的地方。

Destination分为两种:队列和主题。下图介绍:
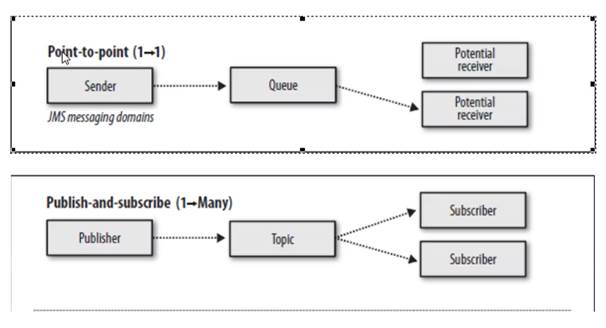
3.4 队列消费者的入门案例
public static void main(String[] args) throws JMSException {
//默认的是tcp://localhost:61616
String activeMqHost = "tcp://192.168.241.125:61616";
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(activeMqHost);
//使用工厂进行创建连接
Connection connection = activeMQConnectionFactory.createConnection();
connection.start();
// 3 创建会话session 。第一参数是是否开启事务, 第二参数是消息签收的方式
Session session = connection.createSession(false,Session.AUTO_ACKNOWLEDGE);
//创建一个队列用来发送消息
Queue xiaodidi = session.createQueue("xiaodidi");
MessageProducer producer = session.createProducer(xiaodidi);
//发送消息的消息内容,等下通过生产者发送
TextMessage textMessage = session.createTextMessage("我是一个小天才");
producer.send(textMessage);
connection.close();
producer.close();
session.close();
System.out.println("发送成功");
}
}
3.5 ActiveMQ控制台之队列
运行上面代码,控制台显示如下:
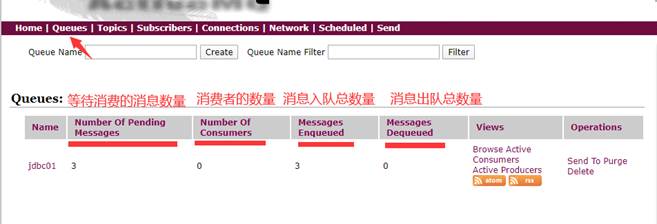
Number Of Pending Messages:
等待消费的消息,这个是未出队列的数量,公式=总接收数-总出队列数。
Number Of Consumers:
消费者数量,消费者端的消费者数量。
Messages Enqueued:
进队消息数,进队列的总消息量,包括出队列的。这个数只增不减。
Messages Dequeued:
出队消息数,可以理解为是消费者消费掉的数量。
总结:
当有一个消息进入这个队列时,等待消费的消息是1,进入队列的消息是1。
当消息消费后,等待消费的消息是0,进入队列的消息是1,出队列的消息是1。
当再来一条消息时,等待消费的消息是1,进入队列的消息就是2。
3.6 队列生产者案例
package com.xiaodidi;
import org.apache.activemq.ActiveMQConnectionFactory;
import javax.jms.*;
/**
* @author 10185
* @create 2021/4/23 19:43
*/
public class ConsumerActiveMq {
public static void main(String[] args) throws JMSException {
String host = "tcp://192.168.241.125:61616";
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(host);
Connection connection = activeMQConnectionFactory.createConnection();
connection.start();
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Queue xiaodidi = session.createQueue("xiaodidi");
MessageConsumer consumer = session.createConsumer(xiaodidi);
while (true) {
//强制转换成TextMessage,因为有5种形式去接受,发送什么形式,就要接受什么形式
//如果receive没有参数,代表一直等待,如果有时间限制,代表超时直接走人返回结果null
TextMessage receive = (TextMessage) consumer.receive(4000L);
System.out.println(receive.getText());
//如果接受到bye,就退出
if ("bye".equals(receive.getText())) {
break;
}
}
connection.close();
session.close();
consumer.close();
}
}
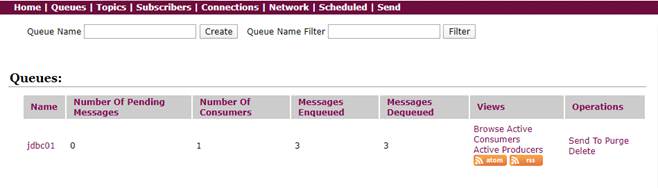
3.7 异步监听式消费者(MessageListener)
package com.xiaodidi;
import org.apache.activemq.ActiveMQConnectionFactory;
import javax.jms.*;
import java.io.IOException;
/**
* @author 10185
* @create 2021/4/23 21:11
*/
public class ConsumerByAsynchronous {
/**
* @author 10185
* @create 2021/4/23 19:43
*/
public static void main(String[] args) throws JMSException, IOException {
String host = "tcp://192.168.241.125:61616";
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(host);
Connection connection = activeMQConnectionFactory.createConnection();
connection.start();
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Queue xiaodidi = session.createQueue("xiaodidi");
MessageConsumer consumer = session.createConsumer(xiaodidi);
//通过监听器实现监听
consumer.setMessageListener((message -> {
if (message instanceof TextMessage) {
TextMessage message1 = (TextMessage) message;
try {
System.out.println(message1.getText());
} catch (JMSException e) {
e.printStackTrace();
}
}
}));
//不让控制台关闭,因为监听器是新起一个线程用来监听
System.in.read();
connection.close();
session.close();
consumer.close();
}
}
3.8 队列消息的总结
(1)两种消费方式
同步阻塞方式(receive)
订阅者或接收者抵用MessageConsumer的receive()方法来接收消息,receive方法在能接收到消息之前(或超时之前)将一直阻塞。
异步非阻塞方式(监听器onMessage())
订阅者或接收者通过MessageConsumer的setMessageListener(MessageListener listener)注册一个消息监听器,当消息到达之后,系统会自动调用监听器MessageListener的onMessage(Message message)方法。
(2)队列的特点
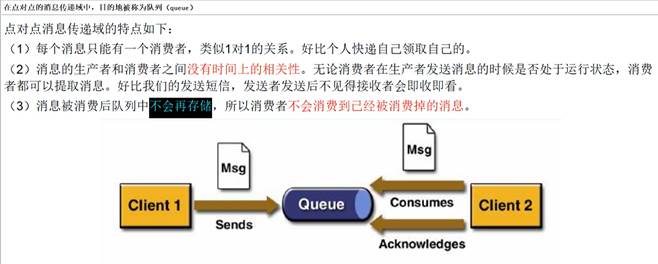
(3)消息的消费情况
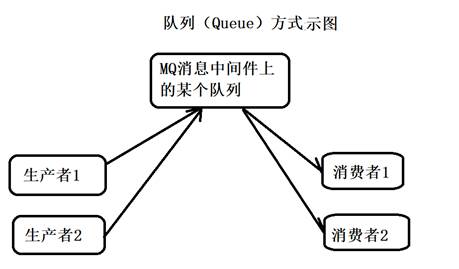
情况1:只启动消费者1。
结果:消费者1会消费所有的数据。
情况2:先启动消费者1,再启动消费者2。
结果:消费者1消费所有的数据。消费者2不会消费到消息。
情况3:生产者发布6条消息,在此之前已经启动了消费者1和消费者2。
结果:消费者1和消费者2平摊了消息。各自消费3条消息。
疑问:怎么去将消费者1和消费者2不平均分摊呢?而是按照各自的消费能力去消费。我觉得,现在activemq就是这样的机制。
3.9 Topic介绍,入门案例,控制台
(1)topic介绍
在发布订阅消息传递域中,目的地被称为主题(topic)
发布/订阅消息传递域的特点如下:
(1)生产者将消息发布到topic中,每个消息可以有多个消费者,属于1:N的关系;
(2)生产者和消费者之间有时间上的相关性。订阅某一个主题的消费者只能消费自它订阅之后发布的消息。
(3)生产者生产时,topic不保存消息它是无状态的不落地,假如无人订阅就去生产,那就是一条废消息,所以,一般先启动消费者再启动生产者。
默认情况下如上所述,但是JMS规范允许客户创建持久订阅,这在一定程度上放松了时间上的相关性要求。持久订阅允许消费者消费它在未处于激活状态时发送的消息。一句话,好比我们的微信公众号订阅
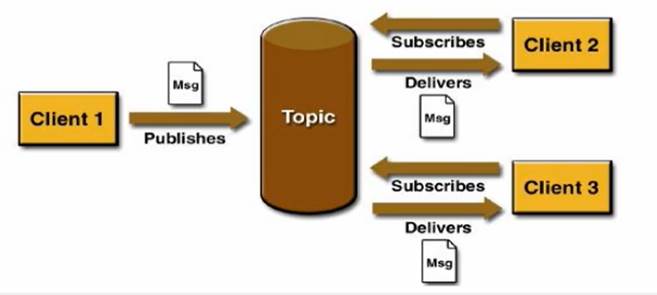
3.10 topic生产者案例
package com.xiaodidi;
import org.apache.activemq.ActiveMQConnectionFactory;
import javax.jms.*;
import java.util.Scanner;
/**
* @author 10185
* @create 2021/4/23 12:14
*/
public class ActiveMqByTopic {
public static void main(String[] args) throws JMSException {
Scanner scanner = new Scanner(System.in);
//默认的是tcp://localhost:61616
String activeMqHost = "tcp://192.168.241.125:61616";
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(activeMqHost);
//使用工厂进行创建连接
Connection connection = activeMQConnectionFactory.createConnection();
connection.start();
// 3 创建会话session 。第一参数是是否开启事务, 第二参数是消息签收的方式
Session session = connection.createSession(false,Session.AUTO_ACKNOWLEDGE);
//创建一个队列用来发送消息
Topic xiaodidiTopic = session.createTopic("xiaodidiTopic");
MessageProducer producer = session.createProducer(xiaodidiTopic);
//发送消息的消息内容,等下通过生产者发送
while (true) {
System.out.println("请输入你要发送的消息:");
String s = scanner.nextLine();
TextMessage textMessage = session.createTextMessage(s);
producer.send(textMessage);
System.out.println("发送成功");
if ("bye".equals(s)) {
break;
}
}
connection.close();
producer.close();
session.close();
}
}
3.11 topic消费者案例
package com.xiaodidi;
import org.apache.activemq.ActiveMQConnectionFactory;
import javax.jms.*;
import java.io.IOException;
/**
* @author 10185
* @create 2021/4/23 22:18
*/
public class ConsumerActiveMqByTopic {
public static void main(String[] args) throws JMSException, IOException {
String host = "tcp://192.168.241.125:61616";
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(host);
Connection connection = activeMQConnectionFactory.createConnection();
connection.start();
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Topic xiaodidiTopic = session.createTopic("xiaodidiTopic");
MessageConsumer consumer = session.createConsumer(xiaodidiTopic);
//通过监听器实现监听
consumer.setMessageListener((message -> {
if (message instanceof TextMessage) {
TextMessage message1 = (TextMessage) message;
try {
System.out.println(message1.getText());
} catch (JMSException e) {
e.printStackTrace();
}
}
}));
//不让控制台关闭,因为监听器是新起一个线程用来监听
System.in.read();
connection.close();
session.close();
consumer.close();
}
}
发现开启三个消费者,三个消费者都可以接受到消息,群发
3.12 topic和queue对比
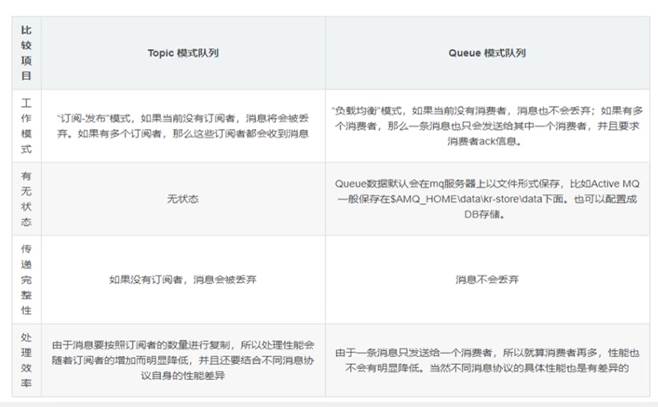
4 JMS规范
4.1 JMS是什么
什么是Java消息服务?
Java消息服务指的是两个应用程序之间进行异步通信的API,它为标准协议和消息服务提供了一组通用接口,包括创建、发送、读取消息等,用于支持Java应用程序开发。在JavaEE中,当两个应用程序使用JMS进行通信时,它们之间不是直接相连的,而是通过一个共同的消息收发服务组件关联起来以达到解耦/异步削峰的效果
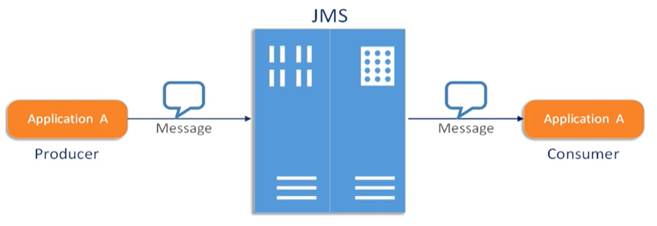
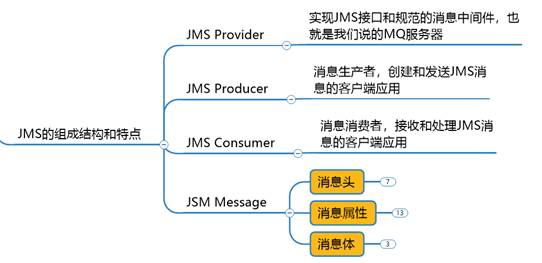
4.2 消息头
JMS的消息头有哪些属性:
JMSDestination:消息目的地
JMDDeliveryMode:消息持久化模式
JMSExpiration:消息过期时间
JMSPriority:消息的优先级
JMSMessageID:消息的唯一标识符.后面我们会介绍如何解决幂等性
消息的生产者可以set这些属性,消息的消费者可以get这些属性
这些属性在send方法里面也可以设置
package com.at.activemq.topic;
import org.apache.activemq.ActiveMQConnectionFactory;
import javax.jms.*;
public class JmsProduce_topic {
public static final String ACTIVEMQ_URL = "tcp://118.24.20.3:61626";
public static final String TOPIC_NAME = "topic01";
public static void main(String[] args) throws Exception{
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(ACTIVEMQ_URL);
Connection connection = activeMQConnectionFactory.createConnection();
connection.start();
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Topic topic = session.createTopic(TOPIC_NAME);
MessageProducer messageProducer = session.createProducer(topic);
for (int i = 1; i < 4 ; i++) {
TextMessage textMessage = session.createTextMessage("topic_name--" + i);
// 这里可以指定每个消息的目的地
textMessage.setJMSDestination(topic);
/*
持久模式和非持久模式。
一条持久性的消息:应该被传送“一次仅仅一次”,这就意味着如果JMS提供者出现故障,该消息并不会丢失,它会在服务器恢复之后再次传递。
一条非持久的消息:最多会传递一次,这意味着服务器出现故障,该消息将会永远丢失。
*/
textMessage.setJMSDeliveryMode(0);
/*
可以设置消息在一定时间后过期,默认是永不过期。
消息过期时间,等于Destination的send方法中的timeToLive值加上发送时刻的GMT时间值。
如果timeToLive值等于0,则JMSExpiration被设为0,表示该消息永不过期。
如果发送后,在消息过期时间之后还没有被发送到目的地,则该消息被清除。
*/
textMessage.setJMSExpiration(1000);
/* 消息优先级,从0-9十个级别,0-4是普通消息5-9是加急消息。
JMS不要求MQ严格按照这十个优先级发送消息但必须保证加急消息要先于普通消息到达。默认是4级。
*/
textMessage.setJMSPriority(10);
// 唯一标识每个消息的标识。MQ会给我们默认生成一个,我们也可以自己指定。
textMessage.setJMSMessageID("ABCD");
// 上面有些属性在send方法里也能设置
messageProducer.send(textMessage);
}
messageProducer.close();
session.close();
connection.close();
System.out.println(" **** TOPIC_NAME消息发送到MQ完成 ****");
}
}
4.3 消息体


MapMessage的用法,生产者模式
MapMessage mapMessage = session.createMapMessage();
mapMessage.setString(**"name"**, **"张三"**+i);
mapMessage.setInt(**"age"**, 18+i);
消费者模式
if (null != message && message instanceof MapMessage){
MapMessage mapMessage = (MapMessage)message;
try {
System.out.println("****消费者的map消息:"+mapMessage.getString("name"));
System.out.println("****消费者的map消息:"+mapMessage.getInt("age"));
}catch (JMSException e) {
4.4 消息属性
如果需要除消息头字段之外的值,那么可以使用消息属性。他是识别/去重/重点标注等操作,非常有用的方法。
他们是以属性名和属性值对的形式制定的。可以将属性是为消息头得扩展,属性指定一些消息头没有包括的附加信息,比如可以在属性里指定消息选择器。消息的属性就像可以分配给一条消息的附加消息头一样。它们允许开发者添加有关消息的不透明附加信息。它们还用于暴露消息选择器在消息过滤时使用的数据。
下图是设置消息属性的API:
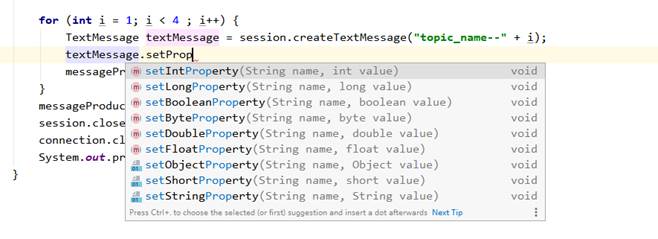
生产者模式代码
for (int i = 1; i < 4 ; i++) {
TextMessage textMessage = session.createTextMessage("topic_name--" + i);
// 调用Message的set*Property()方法,就能设置消息属性。根据value的数据类型的不同,有相应的API。
textMessage.setStringProperty("From","ZhangSan@qq.com");
textMessage.setByteProperty("Spec", (byte) 1);
textMessage.setBooleanProperty("Invalide",true);
messageProducer.send(textMessage);
}
消费者模式代码
if (null != message && message instanceof TextMessage){
TextMessage textMessage = (TextMessage)message;
try {
System.out.println("消息体:"+textMessage.getText());
System.out.println("消息属性:"+textMessage.getStringProperty("From"));
System.out.println("消息属性:"+textMessage.getByteProperty("Spec"));
System.out.println("消息属性:"+textMessage.getBooleanProperty("Invalide"));
}catch (JMSException e) {
}
}
4.5 消息的持久化与订阅者模式
什么是持久化的消息?
保证消息只被传送一次和成功使用一次,在持久化消息传送至目标时,消息服务将其放入持久化进行存储,如果消息服务由于莫种原因导致失败,他可以恢复此消息并将此消息传送至相应的消费者,虽然增加了消息传送的开销,但却增加了消息可靠性
如果是queue模式,默认持久化就是打开的,不用像订阅者一样先进行注册,
如果是topic模式,默认持久化是关闭的,如果要接受到以前的消息,一定要先进行注册
注意要先设置持久化,然后在开启连接
订阅者模式需要设置 创建一个topic订阅者对象。一参是topic,二参是订阅者名称在开启连接,类似
Connection connection = activeMQConnectionFactory.createConnection();
//订阅者模式需要连接有一个独立的id
connection.setClientID("marry1");
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Topic xiaodidiTopic = session.createTopic("xiaodidiTopic");
TopicSubscriber subscriber = session.createDurableSubscriber(xiaodidiTopic, "订阅者1号");
connection.start();
queue消息非持久和持久
默认是持久化的
queue非持久,当服务器宕机,消息不存在(消息丢失了)。即便是非持久,消费者在不在线的话,消息也不会丢失,等待消费者在线,还是能够收到消息的。
queue持久化,当服务器宕机,消息依然存在。queue消息默认是持久化的。
持久化消息,保证这些消息只被传送一次和成功使用一次。对于这些消息,可靠性是优先考虑的因素。
可靠性的另一个重要方面是确保持久性消息传送至目标后,消息服务在向消费者传送它们之前不会丢失这些消息。

| 非持久化的消费者,和之前的代码一样。下面演示非持久化的生产者。下面除灰色背景代码外,其他都和之前一样。 运行结果证明:当生产者成功发布消息之后,MQ服务端宕机重启,消息生产者就收不到该消息了 |
|---|
package com.at.activemq.queue;
import org.apache.activemq.ActiveMQConnectionFactory;
import javax.jms.*;
public class JmsProduce {
public static final String ACTIVEMQ_URL = "tcp://118.24.20.3:61626";
public static final String QUEUE_NAME = "jdbc01";
public static void main(String[] args) throws Exception{
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(ACTIVEMQ_URL);
Connection connection = activeMQConnectionFactory.createConnection();
connection.start();
Session session = connection.createSession(false,Session.AUTO_ACKNOWLEDGE);
Queue queue = session.createQueue(QUEUE_NAME);
MessageProducer messageProducer = session.createProducer(queue);
// 非持久化
messageProducer.setDeliveryMode(DeliveryMode.NON_PERSISTENT);
for (int i = 1; i < 4 ; i++) {
TextMessage textMessage = session.createTextMessage("---MessageListener---" + i);
messageProducer.send(textMessage);
}
messageProducer.close();
session.close();
connection.close();
System.out.println(" **** 消息发送到MQ完成 ****");
}
}
| 持久化的消费者,和之前的代码一样。下面演示持久化的生产者。下面除灰色背景代码外,其他都和之前一样。 运行结果证明:当生产者成功发布消息之后,MQ服务端宕机重启,消息生产者仍然能够收到该消息 |
|---|
package com.at.activemq.queue;
import org.apache.activemq.ActiveMQConnectionFactory;
import javax.jms.*;
public class JmsProduce {
public static final String ACTIVEMQ_URL = "tcp://118.24.20.3:61626";
public static final String QUEUE_NAME = "jdbc01";
public static void main(String[] args) throws Exception{
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(ACTIVEMQ_URL);
Connection connection = activeMQConnectionFactory.createConnection();
connection.start();
Session session = connection.createSession(false,Session.AUTO_ACKNOWLEDGE);
Queue queue = session.createQueue(QUEUE_NAME);
MessageProducer messageProducer = session.createProducer(queue);
messageProducer.setDeliveryMode(DeliveryMode.PERSISTENT);
for (int i = 1; i < 4 ; i++) {
TextMessage textMessage = session.createTextMessage("---MessageListener---" + i);
messageProducer.send(textMessage);
}
messageProducer.close();
session.close();
connection.close();
System.out.println(" **** 消息发送到MQ完成 ****");
}
}
topic消息持久化
默认是非持久化的
因为生产者生产消息时,消费者也要在线,这样消费者才能消费到消息。
topic消息持久化,只要消费者向MQ服务器注册过,所有生产者发布成功的消息,该消费者都能收到,不管是MQ服务器宕机还是消费者不在线。
注意:
\1. 一定要先运行一次消费者,等于向MQ注册,类似我订阅了这个主题。
\2. 然后再运行生产者发送消息。
\3. 之后无论消费者是否在线,都会收到消息。如果不在线的话,下次连接的时候,会把没有收过的消息都接收过来。
持久化topic生产者代码。下面除灰色背景代码外,其他都和之前一样。
package com.at.activemq.topic;
import org.apache.activemq.ActiveMQConnectionFactory;
import javax.jms.*;
// 持久化topic 的消息生产者
public class JmsProduce_persistence {
public static final String ACTIVEMQ_URL = "tcp://192.168.17.3:61616";
public static final String TOPIC_NAME = "topic01";
public static void main(String[] args) throws Exception{
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(ACTIVEMQ_URL);
javax.jms.Connection connection = activeMQConnectionFactory.createConnection();
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Topic topic = session.createTopic(TOPIC_NAME);
MessageProducer messageProducer = session.createProducer(topic);
// 设置持久化topic
messageProducer.setDeliveryMode(DeliveryMode.PERSISTENT);
// 设置持久化topic之后再,启动连接
connection.start();
for (int i = 1; i < 4 ; i++) {
TextMessage textMessage = session.createTextMessage("topic_name--" + i);
messageProducer.send(textMessage);
MapMessage mapMessage = session.createMapMessage();
}
messageProducer.close();
session.close();
connection.close();
System.out.println(" **** TOPIC_NAME消息发送到MQ完成 ****");
}
}
持久化topic消费者代码
package com.at.activemq.topic;
import org.apache.activemq.ActiveMQConnectionFactory;
import javax.jms.*;
// 持久化topic 的消息消费者
public class JmsConsummer_persistence {
public static final String ACTIVEMQ_URL = "tcp://192.168.17.3:61616";
public static final String TOPIC_NAME = "topic01";
public static void main(String[] args) throws Exception{
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(ACTIVEMQ_URL);
Connection connection = activeMQConnectionFactory.createConnection();
// 设置客户端ID。向MQ服务器注册自己的名称
connection.setClientID("marrry");
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Topic topic = session.createTopic(TOPIC_NAME);
// 创建一个topic订阅者对象。一参是topic,二参是订阅者名称
TopicSubscriber topicSubscriber = session.createDurableSubscriber(topic,"remark...");
// 之后再开启连接
connection.start();
Message message = topicSubscriber.receive();
while (null != message){
TextMessage textMessage = (TextMessage)message;
System.out.println(" 收到的持久化 topic :"+textMessage.getText());
message = topicSubscriber.receive();
}
session.close();
connection.close();
}
}
控制台介绍:
topic页面还是和之前的一样。另外在subscribers页面也会显示。如下:
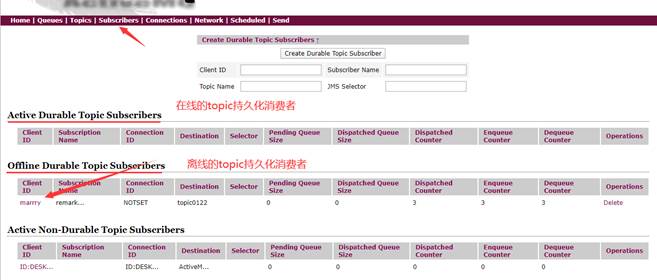
4.6 消息的事务性

(1) 生产者开启事务后,执行commit方法,这批消息才真正的被提交。不执行commit方法,这批消息不会提交。执行rollback方法,之前的消息会回滚掉。生产者的事务机制,要高于签收机制,当生产者开启事务,签收机制不再重要。
(2) 消费者开启事务后,执行commit方法,这批消息才算真正的被消费。不执行commit方法,这些消息不会标记已消费,下次还会被消费。执行rollback方法,是不能回滚之前执行过的业务逻辑,但是能够回滚之前的消息,回滚后的消息,下次还会被消费。消费者利用commit和rollback方法,甚至能够违反一个消费者只能消费一次消息的原理。(如果开启事务,但是没有commit,会重复读取之前的内容)
(3) 问:消费者和生产者需要同时操作事务才行吗?
答:消费者和生产者的事务,完全没有关联,各自是各自的事务。
理解:如果生产者开启事务,但是没有提交,那么就一直为0000的形式,如果消费者开启事务没有提交,那么就一直获取消息,重复获取,不会进行签收
Session session = connection.createSession(true,Session.AUTO_ACKNOWLEDGE);
4.7 消息的签收机制
一、签收的几种方式
① 自动签收(Session.AUTO_ACKNOWLEDGE):该方式是默认的。该种方式,无需我们程序做任何操作,框架会帮我们自动签收收到的消息。
② 手动签收(Session.CLIENT_ACKNOWLEDGE):手动签收。该种方式,需要我们手动调用Message.acknowledge(),来签收消息。如果不签收消息,该消息会被我们反复消费,只到被签收。
③ 允许重复消息(Session.DUPS_OK_ACKNOWLEDGE):多线程或多个消费者同时消费到一个消息,因为线程不安全,可能会重复消费。该种方式很少使用到。
④ 事务下的签收(Session.SESSION_TRANSACTED):开始事务的情况下,可以使用该方式。该种方式很少使用到。
二 事务和签收的关系
① 在事务性会话中,当一个事务被成功提交则消息被自动签收。如果事务回滚,则消息会被再次传送。事务优先于签收,开始事务后,签收机制不再起任何作用。
② 非事务性会话中,消息何时被确认取决于创建会话时的应答模式。
③ 生产者事务开启,只有commit后才能将全部消息变为已消费。
④ 事务偏向生产者,签收偏向消费者。也就是说,生产者使用事务更好点,消费者使用签收机制更好点。
理解:生产者不进行签收,因此无关
消费者如果开启了事务,不管签收的方式,只要提交都自动进行签收
如果消费者开启了事务,但是没有提交,就算acknowledge()也没用,因为没有提交,下次启动消费者还是会把没有签收的所有信息读取出来
消费者没有开启事务,如果手动签收,一定要使用receive.acknowledge();来进行消息的签收
package com.xiaodidi;
import org.apache.activemq.ActiveMQConnectionFactory;
import javax.jms.*;
/**
* @author 10185
* @create 2021/4/24 9:36
*/
public class ConsumerSubscriber {
public static void main(String[] args) throws Exception{
String host = "tcp://192.168.241.125:61616";
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(host);
Connection connection = activeMQConnectionFactory.createConnection();
//订阅者模式需要连接有一个独立的id
connection.setClientID("marry1");
Session session = connection.createSession(false, Session.CLIENT_ACKNOWLEDGE);
Topic xiaodidiTopic = session.createTopic("xiaodidiTopic");
TopicSubscriber subscriber = session.createDurableSubscriber(xiaodidiTopic, "订阅者1号");
connection.start();
while (true) {
Message receive = subscriber.receive();
if (receive instanceof TextMessage) {
TextMessage receive1 = (TextMessage) receive;
System.out.println(receive1.getText());
receive.acknowledge();
}
}
}
}
5 ActiveMQ的broker
(1)broker是什么
相当于一个ActiveMQ服务器实例。说白了,Broker其实就是实现了用代码的形式启动ActiveMQ将MQ嵌入到Java代码中,以便随时用随时启动,在用的时候再去启动这样能节省了资源,也保证了可用性。这种方式,我们实际开发中很少采用,因为他缺少太多了东西,如:日志,数据存储等等。
(2)启动broker时执行配置文件
启动broker时指定配置文件,可以帮助我们在一台服务器上启动多个broker。实际工作中一般一台服务器只启动一个broker
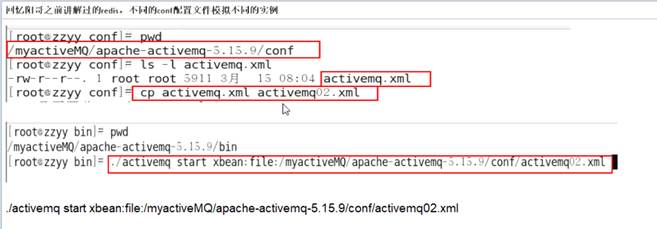
(3)嵌入式的broker启动
用ActiveMQ Broker作为独立的消息服务器来构建Java应用。
ActiveMQ也支持在vm中通信基于嵌入的broker,能够无缝的集成其他java应用。
| 下面演示如何启动嵌入式broker |
|---|
| pom.xml添加一个依赖 |
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.10.1</version>
</dependency>
嵌入式broker的启动类
package com.xiaodidi;
import org.apache.activemq.broker.BrokerService;
/**
* @author 10185
* @create 2021/4/24 12:24
*/
public class ActiveStart {
public static void main(String[] args) throws Exception {
BrokerService brokerService = new BrokerService();
brokerService.setPopulateJMSXUserID(true);
brokerService.addConnector("tcp://localhost:61616");
brokerService.start();
}
}
6 Spring整合ActiveMq
下面我们将Spring和SpringBoot整合ActiveMQ也重要,他给我们提供了一个模板,简化了我们工作中遇到坑,能够满足开发中90%以上的功能
6.1 pom.xml添加依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu</groupId>
<artifactId>activeMq</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- activemq 所需要的jar 包-->
<dependency>
<groupId>org.apache.activemq</groupId>
<artifactId>activemq-all</artifactId>
<version>5.15.9</version>
</dependency>
<!-- activemq 和 spring 整合的基础包 -->
<dependency>
<groupId>org.apache.xbean</groupId>
<artifactId>xbean-spring</artifactId>
<version>3.16</version>
</dependency>
<!--嵌入式activemq和databind的基础包,用来进行小型的activeMq-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.10.1</version>
</dependency>
<!-- spring支持jms的包 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jms</artifactId>
<version>4.3.23.RELEASE</version>
</dependency>
<!--activeMq连接池-->
<dependency>
<groupId>org.apache.activemq</groupId>
<artifactId>activemq-pool</artifactId>
<version>5.15.10</version>
</dependency>
<!-- Spring核心依赖 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>4.3.23.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.3.23.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aop</artifactId>
<version>4.3.23.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>4.3.23.RELEASE</version>
</dependency>
</dependencies>
</project>
6.2 Spring的ActiveMQ配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<!--设置扫描包的地方-->
<context:component-scan base-package="com.xiaodidi"/>
<!--配置activeMq环境-->
<bean id="connectionFactory" class="org.apache.activemq.pool.PooledConnectionFactory" destroy-method="stop">
<property name="connectionFactory">
<!--真正可以生产Connection的ConnectionFactory,由对应的JMS服务商提供-->
<bean class="org.apache.activemq.ActiveMQConnectionFactory">
<property name="brokerURL" value="tcp://localhost:61616"/>
</bean>
</property>
<property name="maxConnections" value="100"/>
</bean>
<!--这个是队列目的地,点对点Queue-->
<bean id="destinationQueue" class="org.apache.activemq.command.ActiveMQQueue">
<!--通过构造注入Queue名-->
<constructor-arg index="0" value="spring-active-queue"/>
</bean>
<bean id="destinationTopic" class="org.apache.activemq.command.ActiveMQTopic">
<constructor-arg index="0" value="spring-active-topic"/>
</bean>
<bean id="jmsTemplate" class="org.springframework.jms.core.JmsTemplate">
<!--把上面定义的通常传入模板中-->
<property name="connectionFactory" ref="connectionFactory"/>
<!--把上面定义的目地的方式传入模板属性中去-->
<property name="defaultDestination" ref="destinationQueue"/>
<!--配置消息自动转换器-->
<property name="messageConverter">
<bean class="org.springframework.jms.support.converter.SimpleMessageConverter"/>
</property>
</bean>
</beans>
6.3 队列生产者
package com.xiaodidi;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.jms.core.JmsTemplate;
import org.springframework.jms.core.MessageCreator;
import org.springframework.stereotype.Service;
import javax.jms.JMSException;
import javax.jms.Message;
import javax.jms.Session;
import javax.jms.TextMessage;
/**
* @author 10185
* @create 2021/4/24 13:28
*/
@Service
public class SpringActiveMqProducer {
@Autowired
JmsTemplate jmsTemplate;
public static void main(String[] args) {
//把spring容器注入进来
ClassPathXmlApplicationContext classPathXmlApplicationContext = new ClassPathXmlApplicationContext("classpath:myspringConfig.xml");
//获取当前类用来调用jmsTemplate
SpringActiveMqProducer springActiveMqConsumer = (SpringActiveMqProducer) classPathXmlApplicationContext.getBean("springActiveMqProducer");
springActiveMqConsumer.jmsTemplate.send(session -> {
TextMessage textMessage = session.createTextMessage("****spring和ActiveMq的整合demo");
return textMessage;
});
System.out.println("发送成功");
}
}
6.4 队列消费者
package com.xiaodidi;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.jms.core.JmsTemplate;
import org.springframework.stereotype.Service;
import javax.jms.JMSException;
import javax.jms.Message;
import javax.jms.TextMessage;
/**
* @author 10185
* @create 2021/4/24 13:37
*/
@Service
public class SpringActiveMqConsumer {
@Autowired
JmsTemplate jmsTemplate;
public static void main(String[] args) throws JMSException {
ClassPathXmlApplicationContext classPathXmlApplicationContext = new ClassPathXmlApplicationContext("classpath:myspringConfig.xml");
SpringActiveMqConsumer springActiveMqConsumer = (SpringActiveMqConsumer) classPathXmlApplicationContext.getBean("springActiveMqConsumer");
//Message receive = springActiveMqConsumer.jmsTemplate.receive();
// TextMessage receive1 = (TextMessage) receive;
//也可以通过receiveAndConvert();
//会自动帮你进行转换
String s = (String) springActiveMqConsumer.jmsTemplate.receiveAndConvert();
System.out.println(s);
}
}
6.5 主题消费者生产者
在配置文件中把对队列的引用转换成对主题的引用
<bean id="destinationTopic" class="org.apache.activemq.command.ActiveMQTopic">
<constructor-arg index="0" value="spring-active-topic"/>
</bean>
<bean id="jmsTemplate" class="org.springframework.jms.core.JmsTemplate">
<!--把上面定义的通常传入模板中-->
<property name="connectionFactory" ref="connectionFactory"/>
<!--把上面定义的目地的方式传入模板属性中去-->
<property name="defaultDestination" ref="destinationTopic"/>
<!--配置消息自动转换器-->
<property name="messageConverter">
<bean class="org.springframework.jms.support.converter.SimpleMessageConverter"/>
</property>
</bean>
6.6 配置消费者的监听类
package com.xiaodidi;
import org.springframework.stereotype.Component;
import javax.jms.JMSException;
import javax.jms.Message;
import javax.jms.MessageListener;
import javax.jms.TextMessage;
/**
* @author 10185
* @create 2021/4/24 14:05
*/
//加入容器注解,不用在配置文件中自己写了,直接可以引用
@Component
public class MyMessageListener implements MessageListener {
@Override
public void onMessage(Message message) {
if (message instanceof TextMessage) {
TextMessage message1 = (TextMessage) message;
try {
System.out.println(message1.getText());
} catch (JMSException e) {
e.printStackTrace();
}
}
}
}
配置文件中进行配置
<bean id="jmsContainer" class="org.springframework.jms.listener.DefaultMessageListenerContainer">
<property name="connectionFactory" ref="connectionFactory"/>
<property name="destination" ref="destinationTopic"/>
<property name="messageListener" ref="myMessageListener"/>
</bean>
重新启动生产者,发现可以进行监听

7 springBoot整合ActiveMQ
7.1 queue生产者(包含topic,queue)
1 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>springbootActiveMqConsumer</artifactId>
<version>1.0-SNAPSHOT</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.8.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!--spring boot整合activemq的jar包-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-activemq</artifactId>
<version>2.2.8.RELEASE</version>
</dependency>
</dependencies>
</project>
2 application.yml
server:
port: 8888
spring:
activemq:
broker-url: tcp://192.168.241.125:61616
user: admin #登录密码
password: admin
jms:
pub-sub-domain: true #false(默认)=quene #true=topic
myqueue: xiaodidi #自定义队列名称,在acitiveMQ配置类中可以进行获取
mytopic: xiaogege
3 ActiveConfig(配置队列或者主题)
package com.xiaodidi;
import org.apache.activemq.command.ActiveMQQueue;
import org.apache.activemq.command.ActiveMQTopic;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.jms.annotation.EnableJms;
import org.springframework.stereotype.Component;
/**
* 配置目的地的bean
*
* @author 10185
* @create 2021/4/24 14:36
*/
@Component
//开启jms适配
@EnableJms
public class ActiveConfig {
/* @Value("${myqueue}")
String queueName;
@Bean
public ActiveMQQueue queue() {
return new ActiveMQQueue(queueName);
}*/
@Value("${mytopic}")
String mytopic;
@Bean
public ActiveMQTopic topic(){
return new ActiveMQTopic(mytopic);
}
}
4 配置主启动类
package com.xiaodidi;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.EnableScheduling;
@SpringBootApplication
// 是否开启定时任务调度功能
@EnableScheduling
public class MainApp_Consumer {
public static void main(String[] args) {
SpringApplication.run(MainApp_Consumer.class,args);
}
}
5 生产者发送消息类
package com.xiaodidi;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jms.core.JmsMessagingTemplate;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import javax.jms.Queue;
import javax.jms.Topic;
/**
* @author 10185
* @create 2021/4/24 14:41
*/
@Component
public class QueueProduce {
@Autowired
private JmsMessagingTemplate jmsMessagingTemplate;
/* @Autowired
private Queue queue;*/
@Autowired
private Topic topic;
public void produceMessage() {
jmsMessagingTemplate.convertAndSend(topic,"我是一个人");
}
//演示定时任务.每3秒执行一次,非必须代码,为演示
@Scheduled(fixedDelay = 3000)
public void produceMessageScheduled(){
produceMessage();
}
}
6 测试类
package com.xiaodidi;
import org.junit.jupiter.api.Test;
import org.springframework.aop.scope.ScopedProxyUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
/**
* @author 10185
* @create 2021/4/24 14:44
*/
@SpringBootTest
public class activeMqTest {
@Autowired
QueueProduce queueProduce;
@Test
public void producer() throws IOException {
queueProduce.produceMessage();
System.out.println("发送成功");
System.in.read();
}
}
7.2 queue消费者(包含topic,queue)
1 复制生产者工程
2 更改yml项目启动端口号
3 删除生产者发送消息类
4 增加监听消息类
package com.xiaodidi;
import org.springframework.jms.annotation.JmsListener;
import org.springframework.stereotype.Component;
import javax.jms.JMSException;
import javax.jms.TextMessage;
/**
* @author 10185
* @create 2021/4/24 15:12
*/
@Component
public class QueueConsumer {
@JmsListener(destination = "${mytopic}")
public void receive(TextMessage textMessage) throws JMSException {
System.out.println("****消费者接受到消息****"+textMessage.getText());
}
}
7.3 topic更改成queue需要干嘛
1 yml新增myqueue或者mytopic名字
myqueue: xiaodidi #自定义队列名称,在acitiveMQ配置类中可以进行获取
mytopic: xiaogege
2 yml 更改
jms:
pub-sub-domain: true #false(默认)=quene #true=topic
3 更改配置类
@Component
//开启jms适配
@EnableJms
public class ActiveConfig {
/* @Value("${myqueue}")
String queueName;
@Bean
public ActiveMQQueue queue() {
return new ActiveMQQueue(queueName);
}*/
@Value("${mytopic}")
String mytopic;
@Bean
public ActiveMQTopic topic(){
return new ActiveMQTopic(mytopic);
}
}
4 生产者发送消息类
@Autowired
private JmsMessagingTemplate jmsMessagingTemplate;
/* @Autowired
private Queue queue;*/
@Autowired
private Topic topic;
public void produceMessage() {
jmsMessagingTemplate.convertAndSend(topic,"我是一个人");
}
5 消费者接受消息类
@Component
public class QueueConsumer {
@JmsListener(destination = "${mytopic}")
public void receive(TextMessage textMessage) throws JMSException {
System.out.println("****消费者接受到消息****"+textMessage.getText());
}
}
8 ActiveMQ的传输协议
8.1 简介
ActiveMQ支持的client-broker通讯协议有:TVP、NIO、UDP、SSL、Http(s)、VM。其中配置Transport Connector的文件在ActiveMQ安装目录的conf/activemq.xml中的标签之内。
activemq传输协议的官方文档:http://activemq.apache.org/configuring-version-5-transports.html
| 这些协议参见文件:%activeMQ安装目录%/conf/activemq.xml,下面是文件的重要的内容 |
|---|
<transportConnectors>
<!-- DOS protection, limit concurrent connections to 1000 and frame size to 100MB -->
<transportConnector name="openwire" uri="tcp://0.0.0.0:61616?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<transportConnector name="amqp" uri="amqp://0.0.0.0:5672?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<transportConnector name="stomp" uri="stomp://0.0.0.0:61613?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<transportConnector name="mqtt" uri="mqtt://0.0.0.0:1883?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<transportConnector name="ws" uri="ws://0.0.0.0:61614?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
在上文给出的配置信息中,URI描述信息的头部都是采用协议名称:例如
描述amqp协议的监听端口时,采用的URI描述格式为“amqp://······”;
描述Stomp协议的监听端口时,采用URI描述格式为“stomp://······”;
唯独在进行openwire协议描述时,URI头却采用的“tcp://······”。这是因为ActiveMQ中默认的消息协议就是openwire
8.2 支持的传输协议
个人说明:除了tcp和nio协议,其他的了解就行。各种协议有各自擅长该协议的中间件,工作中一般不会使用activemq去实现这些协议。如: mqtt是物联网专用协议,采用的中间件一般是mosquito。ws是websocket的协议,是和前端对接常用的,一般在java代码中内嵌一个基站(中间件)。stomp好像是邮箱使用的协议的,各大邮箱公司都有基站(中间件)。
注意:协议不同,我们的代码都会不同。

1 TCP协议
(1) Transmission Control Protocol(TCP)是默认的。TCP的Client监听端口61616
(2) 在网络传输数据前,必须要先序列化数据,消息是通过一个叫wire protocol的来序列化成字节流。
(3) TCP连接的URI形式如:tcp://HostName:port?key=value&key=value,后面的参数是可选的。
(4) TCP传输的的优点:
TCP协议传输可靠性高,稳定性强
高效率:字节流方式传递,效率很高
有效性、可用性:应用广泛,支持任何平台
(5) 关于Transport协议的可选配置参数可以参考官网http://activemq.apache.org/tcp-transport-reference
2 NIO协议
(1) New I/O API Protocol(NIO)
(2) NIO协议和TCP协议类似,但NIO更侧重于底层的访问操作。它允许开发人员对同一资源可有更多的client调用和服务器端有更多的负载。
(3) 适合使用NIO协议的场景:
可能有大量的Client去连接到Broker上,一般情况下,大量的Client去连接Broker是被操作系统的线程所限制的。因此,NIO的实现比TCP需要更少的线程去运行,所以建议使用NIO协议。
可能对于Broker有一个很迟钝的网络传输,NIO比TCP提供更好的性能。
(4) NIO连接的URI形式:nio://hostname:port?key=value&key=value
(5) 关于Transport协议的可选配置参数可以参考官网http://activemq.apache.org/configuring-version-5-transports.html
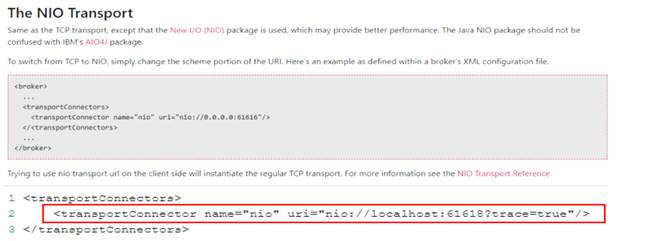
3 AMQP协议
4 STOMP协议


5 MQTT协议
8.3 NIO协议案例
ActiveMQ这些协议传输的底层默认都是使用BIO网络的IO模型。只有当我们指定使用nio才使用NIO的IO模型。
1 修改配置文件activemq.xml
<transportConnectors>
<!-- DOS protection, limit concurrent connections to 1000 and frame size to 100MB -->
<transportConnector name="openwire" uri="tcp://0.0.0.0:61616?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<transportConnector name="amqp" uri="amqp://0.0.0.0:5672?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<transportConnector name="stomp" uri="stomp://0.0.0.0:61613?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<transportConnector name="mqtt" uri="mqtt://0.0.0.0:1883?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<transportConnector name="ws" uri="ws://0.0.0.0:61614?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<transportConnector name="nio" uri="nio://0.0.0.0:61618?trace=true"/>
</transportConnectors>
① 修改配置文件activemq.xml在 节点下添加如下内容:
② 修改完成后重启activemq:
service activemq restart
③ 查看管理后台,可以看到页面多了nio
2 修改连接地址nio://192.168.241.125:61618
String host = "nio://192.168.241.125:61618";
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(host);
Connection connection = activeMQConnectionFactory.createConnection();
8.4 NIO协议案例增强
1 目的
上面是Openwire协议传输底层使用NIO网络IO模型。 如何让其他协议传输底层也使用NIO网络IO模型呢?


从5.13.0版本开始,ActiveMQ支持wire format协议检测,可以自动检测OpenWire,STOMP,AMQP和MQTT,允许为这4种类型的客户端共享一个传输。要通过NIO TCP连接配置ActiveMQ自动wire format检测,使用 auto+nio传输前缀。
原始NIO传输是使用OpenWire协议的tcp传输的替代品。其他网络协议,如AMQP,MQTT,Stomp等也有自己的NIO传输实现。它通常通过在协议前缀中添加“+ nio”后缀来配置
<transportConnector name="openwire" uri="tcp://0.0.0.0:61616?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<transportConnector name="amqp" uri="amqp://0.0.0.0:5672?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<transportConnector name="stomp" uri="stomp://0.0.0.0:61613?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<transportConnector name="mqtt" uri="mqtt://0.0.0.0:1883?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<transportConnector name="ws" uri="ws://0.0.0.0:61614?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<transportConnector name="nio" uri="nio://0.0.0.0:61618?trace=true"/>
<transportConnector name="auto+nio" uri="auto+nio://0.0.0.0:61608?maximumConnections=1000&wireFormat.maxFrameSize=104857600&org.apache.activemq.transport.nio.SelectorManager.corePoolSize=20&org.apache.activemq.transport.nio.Se1ectorManager.maximumPoo1Size=50"/>
</transportConnectors>
auto : 针对所有的协议,他会识别我们是什么协议。
nio :使用NIO网络IO模型
修改配置文件后重启activemq。
String activeMqHost = "tcp://192.168.241.125:61608";
9 ActiveMQ的消息存储和持久化
9.1 介绍
(1)此处持久化和之前的持久化的区别
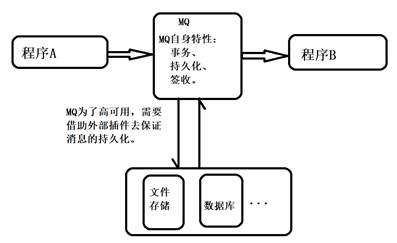
MQ高可用:事务、可持久、签收,是属于MQ自身特性,自带的。这里的持久化是外力,是外部插件。之前讲的持久化是MQ的外在表现,现在讲的的持久是是底层实现。
(2)是什么:
官网文档:http://activemq.apache.org/persistence
持久化是什么?一句话就是:ActiveMQ宕机了,消息不会丢失的机制。
说明:为了避免意外宕机以后丢失信息,需要做到重启后可以恢复消息队列,消息系统一半都会采用持久化机制。ActiveMQ的消息持久化机制有JDBC,AMQ,KahaDB和LevelDB,无论使用哪种持久化方式,消息的存储逻辑都是一致的。就是在发送者将消息发送出去后,消息中心首先将消息存储到本地数据文件、内存数据库或者远程数据库等。再试图将消息发给接收者,成功则将消息从存储中删除,失败则继续尝试尝试发送。消息中心启动以后,要先检查指定的存储位置是否有未成功发送的消息,如果有,则会先把存储位置中的消息发出去。
9.2 有哪些
(1) AMQ Message Store
基于文件的存储机制,是以前的默认机制,现在不再使用。
AMQ是一种文件存储形式,它具有写入速度快和容易恢复的特点。消息存储再一个个文件中文件的默认大小为32M,当一个文件中的消息已经全部被消费,那么这个文件将被标识为可删除,在下一个清除阶段,这个文件被删除。AMQ适用于ActiveMQ5.3之前的版本
(2) kahaDB
现在默认的。下面我们再详细介绍。
(3) JDBC****消息存储
下面我们再详细介绍。
(4) LevelDB****消息存储
过于新兴的技术,现在有些不确定。
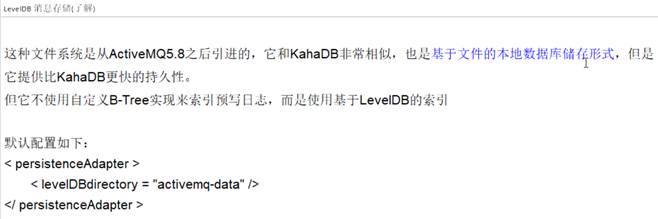
9.3 kahaDB消息存储
(1)介绍
基于日志文件,从ActiveMQ5.4(含)开始默认的持久化插件。
官网文档:http://activemq.aache.org/kahadb
官网上还有一些其他配置参数。
| 配置文件activemq.xml中,如下 |
|---|
<persistenceAdapter>
<kahaDB directory="${activemq.data}/kahadb"/>
</persistenceAdapter>
日志文件的存储目录在:%activemq安装目录%/data/kahadb
(2)说明
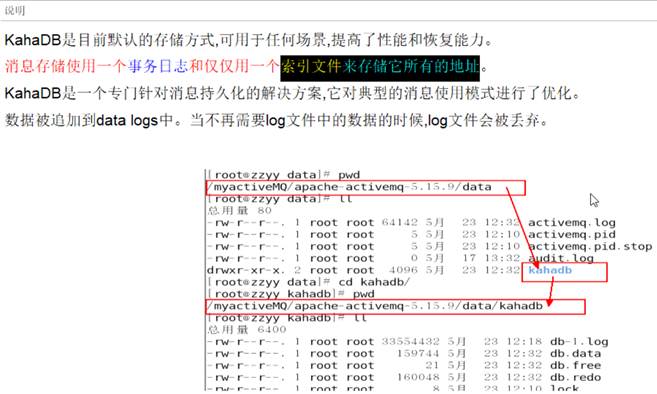
(3)kahaDB的存储原理
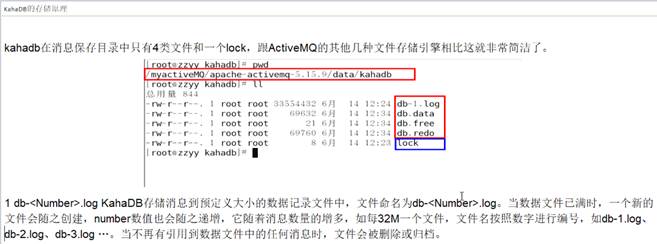
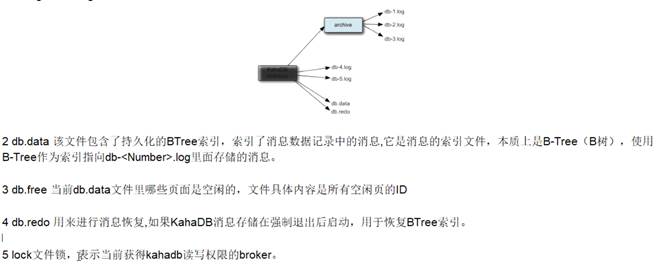
9.4 JDBC消息存储
(1)原理图
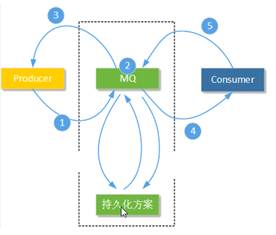
(2)添加mysql数据库的驱动包到lib文件夹
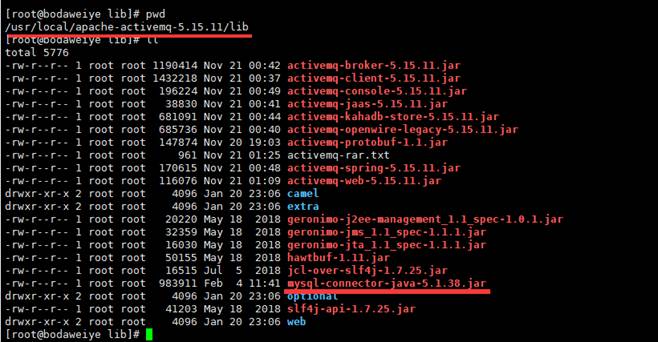
(3)jdbcPersistenceAdapter配置
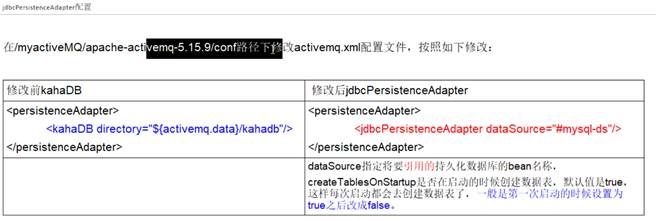
修改配置文件activemq.xml。将之前的替换为jdbc的配置。如下:
<!--
<persistenceAdapter>
<kahaDB directory="${activemq.data}/kahadb"/>
</persistenceAdapter>
-->
<persistenceAdapter>
<jdbcPersistenceAdapter dataSource="#mysql-ds" createTablesOnStartup="true"/>
</persistenceAdapter>
(4)数据库连接池配置
需要我们准备一个mysql数据库,并创建一个名为activemq的数据库。
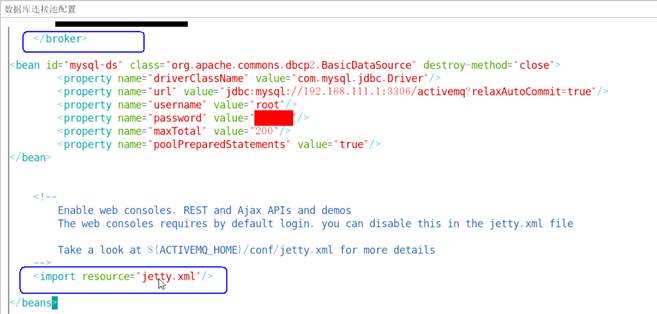
<bean id="mysql-ds" class="org.apache.commons.dbcp2.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://mysql数据库URL/activemq?relaxAutoCommit=true"/>
<property name="username" value="mysql数据库用户名"/>
<property name="password" value="mysql数据库密码"/>
<property name="poolPreparedStatements" value="true"/>
</bean>
默认是的dbcp数据库连接池,如果要换成其他数据库连接池,需要将该连接池jar包,也放到lib目录下。
(5)建表
重启activemq
如果配置了createTablesOnStartup选项,默认会建好表了
建好表了记得把配置文件中createTablesOnStartup选项进行重置
如果没有生成,可以选择自己进行建表
-- auto-generated definition
create table ACTIVEMQ_ACKS
(
CONTAINER varchar(250) not null comment '消息的Destination',
SUB_DEST varchar(250) null comment '如果使用的是Static集群,这个字段会有集群其他系统的信息',
CLIENT_ID varchar(250) not null comment '每个订阅者都必须有一个唯一的客户端ID用以区分',
SUB_NAME varchar(250) not null comment '订阅者名称',
SELECTOR varchar(250) null comment '选择器,可以选择只消费满足条件的消息,条件可以用自定义属性实现,可支持多属性AND和OR操作',
LAST_ACKED_ID bigint null comment '记录消费过消息的ID',
PRIORITY bigint default 5 not null comment '优先级,默认5',
XID varchar(250) null,
primary key (CONTAINER, CLIENT_ID, SUB_NAME, PRIORITY)
)
comment '用于存储订阅关系。如果是持久化Topic,订阅者和服务器的订阅关系在这个表保存';
create index ACTIVEMQ_ACKS_XIDX
on ACTIVEMQ_ACKS (XID);
-- auto-generated definition
create table ACTIVEMQ_LOCK
(
ID bigint not null
primary key,
TIME bigint null,
BROKER_NAME varchar(250) null
);
-- auto-generated definition
create table ACTIVEMQ_MSGS
(
ID bigint not null
primary key,
CONTAINER varchar(250) not null,
MSGID_PROD varchar(250) null,
MSGID_SEQ bigint null,
EXPIRATION bigint null,
MSG blob null,
PRIORITY bigint null,
XID varchar(250) null
);
create index ACTIVEMQ_MSGS_CIDX
on ACTIVEMQ_MSGS (CONTAINER);
create index ACTIVEMQ_MSGS_EIDX
on ACTIVEMQ_MSGS (EXPIRATION);
create index ACTIVEMQ_MSGS_MIDX
on ACTIVEMQ_MSGS (MSGID_PROD, MSGID_SEQ);
create index ACTIVEMQ_MSGS_PIDX
on ACTIVEMQ_MSGS (PRIORITY);
create index ACTIVEMQ_MSGS_XIDX
on ACTIVEMQ_MSGS (XID);
ACTIVEMQ_MSGS****数据表:
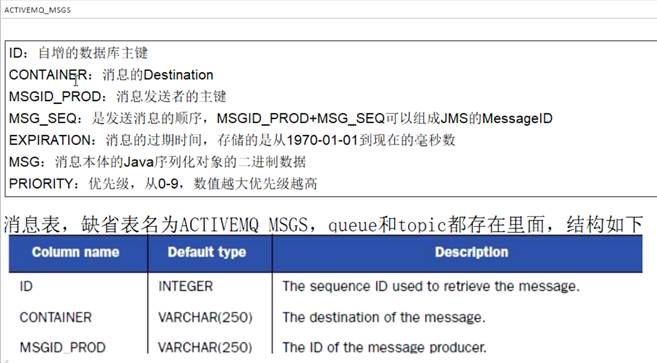
ACTIVEMQ_ACKS****数据表:
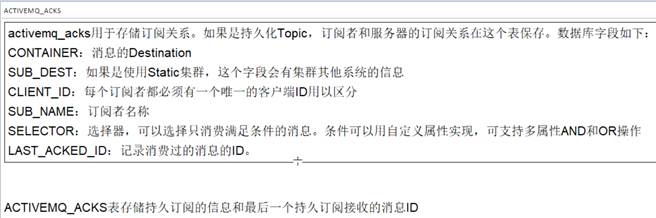
ACTIVEMQ_LOCK****数据表:

(6)测试
测试queue
只启动生产者,不启动消费者,发现数据保存到了数据库中去


启动消费者,消费了所有的消息后,发现数据表的数据消失了。
测试topic持久化

我们启动持久化生产者发布3个数据,ACTIVEMQ_MSGS数据表新增3条数据,消费者消费所有的数据后,ACTIVEMQ_MSGS数据表的数据并没有消失。持久化topic的消息不管是否被消费,是否有消费者,产生的数据永远都存在,且只存储一条。这个是要注意的,持久化的topic大量数据后可能导致性能下降。这里就像公总号一样,消费者消费完后,消息还会保留。
(7)总结
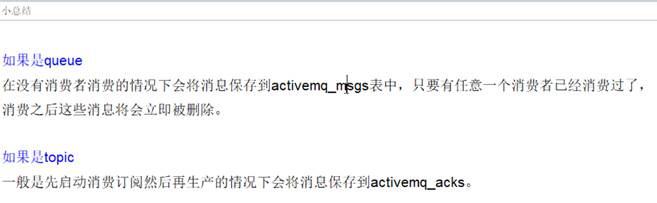

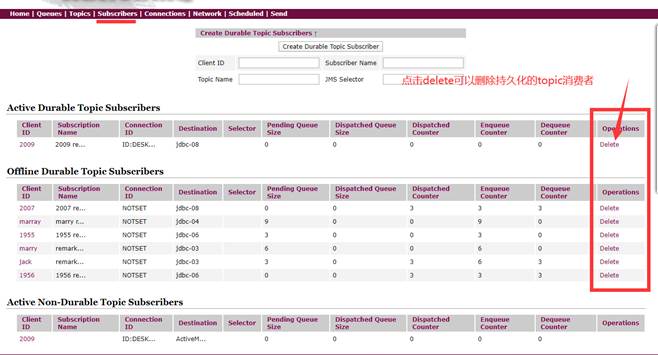
9.5 JDBC Message Store with ActiveMQ Journal
(1) 说明
这种方式克服了JDBC Store的不足,JDBC每次消息过来,都需要去写库读库。ActiveMQ Journal,使用高速缓存写入技术,大大提高了性能。当消费者的速度能够及时跟上生产者消息的生产速度时,journal文件能够大大减少需要写入到DB中的消息。
举个例子:生产者生产了1000条消息,这1000条消息会保存到journal文件,如果消费者的消费速度很快的情况下,在journal文件还没有同步到DB之前,消费者已经消费了90%的以上消息,那么这个时候只需要同步剩余的10%的消息到DB。如果消费者的速度很慢,这个时候journal文件可以使消息以批量方式写到DB。
为了高性能,这种方式使用日志文件存储+数据库存储。先将消息持久到日志文件,等待一段时间再将未消费的消息持久到数据库。该方式要比JDBC性能要高。
(2)配置
下面是基于上面JDBC配置,再做一点修改:

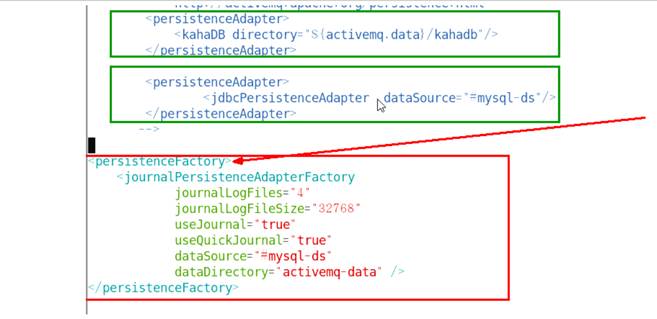
<persistenceFactory>
<journalPersistenceAdapterFactory
journalLogFiles="4"
journalLogFileSize="32768"
useJournal="true"
useQuickJournal="true"
dataSource="#mysql-ds"
dataDirectory="activemq-data"/>
</persistenceFactory>
10 levelDB以及集群的配置
确保zookeeper集群搭建完成,具体可以查看大数据/zookeeper
集群部署规划列表
| 主机 | Zookeeper集群端口 | AMQ集群bind端口 | AMQ消息tcp端口 | 管理控制台端口 | AMQ节点安装目录 |
|---|---|---|---|---|---|
| hadoop102 | 2161 | bind=“top://0.0.0.0:63631” | 61616 | 8161 | /opt/module/apache-activemq-5.15.14 |
| hadoop103 | 2161 | bind=“top://0.0.0.0:63632” | 61617 | 8162 | /opt/module/apache-activemq-5.15.14 |
| hadoop104 | 2161 | bind=“top://0.0.0.0:63633” | 61618 | 8163 | /opt/module/apache-activemq-5.15.14 |
修改主机名字映射(已经变成102,103,104)了
修改管理控制台端口(多机器可以不用变化)
修改各节点消息端口(tcp)
ActiveMQ集群配置
按顺序启动3个ActiveMQ节点
1 更改activemq.xml
hostname三个机器不同
bind三个机器不同
<replicatedLevelDB
directory="{activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:63632"
<!--代表连接客户端的端口号,默认就是2181-->
zkAddress="hapoop102:2181,hadoop103:2181,hadoop103:2181"
zkPassword="123456"
sync="local_disk"
zkPath="/activemq/leveldb-stores"
hostname="hadoop103"
/>
</persistenceAdapter>
三个机器改成同一个名字
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="zzyymq" dataDirectory="${activemq.data}">

2 更改jetty.xml
改控制台端口,由于我这个是三个机器不用进行修改
3 测试
查看我的三个节点: 我的分别是 0…… 3 …… 4 …… 5
查看我的节点状态
get /activemq/leveldb-stores/00000000003
此次验证表明 00000003 的节点状态是master (即为63631 的那个mq 服务) 而其余的(00000004 00000005) activemq 的节点是 slave
如此集群顺利搭建成功 !
此次测试表明只有 8161 的端口可以使用 经测试只有 61 可以使用,也就是61 代表的就是master
测试集群可用性:
首先:
修改代码
public static final String ACTIVEMQ_URL = “failover:(tcp://192.168.17.3:61616,tcp://192.168.17.3:61617, tcp://192.168.17.3:61618)?randomize=false”; public static final String QUEUE_NAME = “queue_cluster”;
测试:
测试通过连接上集群的 61616
MQ服务收到三条消息:
消息接收
MQ 服务也将消息出队
以上代表集群可以正常使用
此时真正的可用性测试:
杀死 8061 端口的进程 !!!
刷新页面后 8161 端口宕掉,但是 8162 端口又激活了
当 61616 宕机,代码不变发消息 自动连接到 61617 了
这样! 集群的可用性测试成功!
11 高级特性
11.1 异步投递
(1)异步投递是什么

总结
① 异步发送可以让生产者发的更快。
② 如果异步投递不需要保证消息是否发送成功,发送者的效率会有所提高。如果异步投递还需要保证消息是否成功发送,并采用了回调的方式,发送者的效率提高不多,这种就有些鸡肋。
(2)代码实现
官网上面可以用这三种方式实现

package com.activemq.demo;
import org.apache.activemq.ActiveMQConnection;
import org.apache.activemq.ActiveMQConnectionFactory;
import javax.jms.*;
public class Jms_TX_Producer {
// 方式1。3种方式任选一种
private static final String ACTIVEMQ_URL = "tcp://118.24.20.3:61626?jms.useAsyncSend=true";
private static final String ACTIVEMQ_QUEUE_NAME = "Async";
public static void main(String[] args) throws JMSException {
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(ACTIVEMQ_URL);
// 方式2
activeMQConnectionFactory.setUseAsyncSend(true);
Connection connection = activeMQConnectionFactory.createConnection();
// 方式3
((ActiveMQConnection)connection).setUseAsyncSend(true);
connection.start();
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Queue queue = session.createQueue(ACTIVEMQ_QUEUE_NAME);
MessageProducer producer = session.createProducer(queue);
try {
for (int i = 0; i < 3; i++) {
TextMessage textMessage = session.createTextMessage("tx msg--" + i);
producer.send(textMessage);
}
System.out.println("消息发送完成");
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.close();
session.close();
connection.close();
}
}
}
(3)异步发送如何确定发送成功
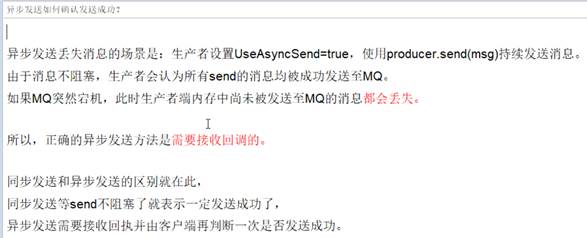
代码实现
package com.xiaodidi;
import org.apache.activemq.ActiveMQConnectionFactory;
import org.apache.activemq.ActiveMQMessageProducer;
import org.apache.activemq.AsyncCallback;
import javax.jms.*;
import java.util.UUID;
/**
* @author 10185
* @create 2021/4/25 12:40
*/
public class ActiveMqAsyncSend {
private static final String ACTIVEMQ_URL = "tcp://192.168.241.125:61616";
private static final String ACTIVEMQ_QUEUE_NAME = "Async";
public static void main(String[] args) throws JMSException {
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(ACTIVEMQ_URL);
//设置异步发送,可以加快速度
activeMQConnectionFactory.setUseAsyncSend(true);
Connection connection = activeMQConnectionFactory.createConnection();
connection.start();
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Queue queue = session.createQueue(ACTIVEMQ_QUEUE_NAME);
//转换成ActiveMQMessageProducer,以便可以使用异步回调函数
ActiveMQMessageProducer activeMQMessageProducer = (ActiveMQMessageProducer)session.createProducer(queue);
try {
for (int i = 0; i < 3; i++) {
TextMessage textMessage = session.createTextMessage("tx msg--" + i);
textMessage.setJMSMessageID(UUID.randomUUID().toString()+"orderAtguigu");
final String msgId = textMessage.getJMSMessageID();
activeMQMessageProducer.send(textMessage, new AsyncCallback() {
@Override
public void onSuccess() {
System.out.println("成功发送消息Id:"+msgId);
}
@Override
public void onException(JMSException e) {
System.out.println("失败发送消息Id:"+msgId);
}
});
}
System.out.println("消息发送完成");
} catch (Exception e) {
e.printStackTrace();
} finally {
activeMQMessageProducer.close();
session.close();
connection.close();
}
}
}
控制台观察发送消息的信息
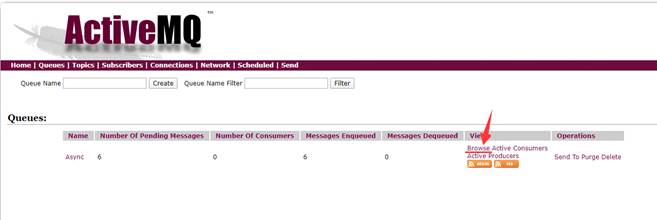
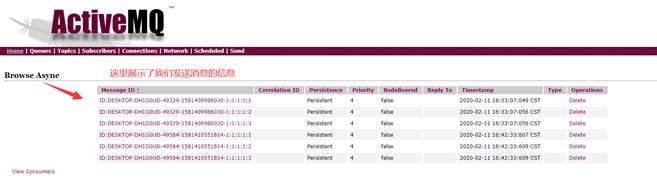
11.2 延迟投递和定时投递
(1)介绍
官网文档:http://activemq.apache.org/delay-and-schedule-message-delivery.html
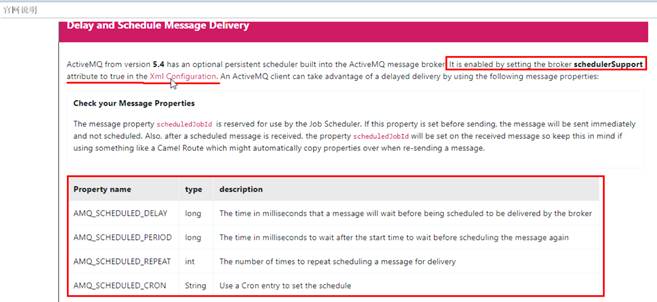
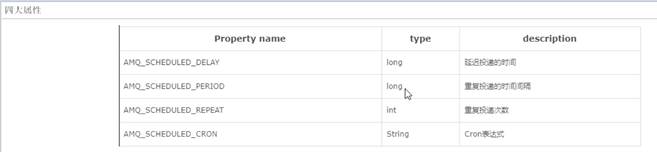
(2)修改配置文件并重启
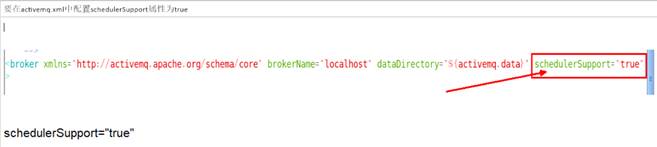
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="localhost" dataDirectory="${activemq.data}" schedulerSupport="true">
重启activemq
(3)代码实现
生产者代码
package com.xiaodidi;
import org.apache.activemq.ActiveMQConnectionFactory;
import org.apache.activemq.ScheduledMessage;
import javax.jms.*;
/**
* @author 10185
* @create 2021/4/25 12:56
*/
public class DelayedDelivery {
private static final String ACTIVEMQ_URL = "tcp://192.168.241.125:61616";
private static final String ACTIVEMQ_QUEUE_NAME = "Schedule01";
public static void main(String[] args) throws JMSException {
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(ACTIVEMQ_URL);
Connection connection = activeMQConnectionFactory.createConnection();
connection.start();
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Queue queue = session.createQueue(ACTIVEMQ_QUEUE_NAME);
MessageProducer messageProducer = session.createProducer(queue);
//代表延迟1秒钟然后在进行发送
long delay = 1*1000;
//代表间隔1秒钟在进行发送
long period = 1*1000;
//代表这条消息之后在重复发送2次,间隔period秒
//消费者一共接受到3条消息
int repeat = 2 ;
try {
for (int i = 0; i < 3; i++) {
TextMessage textMessage = session.createTextMessage("tx msg--" + i);
// 延迟的时间
textMessage.setLongProperty(ScheduledMessage.AMQ_SCHEDULED_DELAY, delay);
// 重复投递的时间间隔
textMessage.setLongProperty(ScheduledMessage.AMQ_SCHEDULED_PERIOD, period);
// 重复投递的次数
textMessage.setIntProperty(ScheduledMessage.AMQ_SCHEDULED_REPEAT, repeat);
// 此处的意思:该条消息,等待1秒,之后每1秒发送一次,重复发送2次,一共3次
messageProducer.send(textMessage);
System.out.println(textMessage.getText()+"发送成功");
}
System.out.println("消息发送完成");
} catch (Exception e) {
e.printStackTrace();
} finally {
messageProducer.close();
session.close();
connection.close();
}
}
}
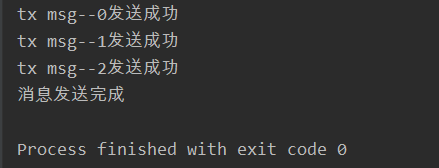
这个进程直接结束,activemq会在后台进行发送
消费者代码
package com.xiaodidi;
import org.apache.activemq.ActiveMQConnectionFactory;
import javax.jms.*;
import java.io.IOException;
/**
* @author 10185
* @create 2021/4/25 13:00
*/
public class DelayedDeliveryConsumer {
private static final String ACTIVEMQ_URL = "tcp://192.168.241.125:61616";
private static final String ACTIVEMQ_QUEUE_NAME = "Schedule01";
public static void main(String[] args) throws JMSException, IOException {
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(ACTIVEMQ_URL);
Connection connection = activeMQConnectionFactory.createConnection();
connection.start();
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Queue queue = session.createQueue(ACTIVEMQ_QUEUE_NAME);
MessageConsumer messageConsumer = session.createConsumer(queue);
messageConsumer.setMessageListener(new MessageListener() {
@Override
public void onMessage(Message message) {
if (message instanceof TextMessage) {
try {
TextMessage textMessage = (TextMessage) message;
System.out.println("***消费者接收到的消息: " + textMessage.getText());
textMessage.acknowledge();
} catch (Exception e) {
System.out.println("出现异常,消费失败,放弃消费");
}
}
}
});
System.in.read();
messageConsumer.close();
session.close();
connection.close();
}
}
后台代码
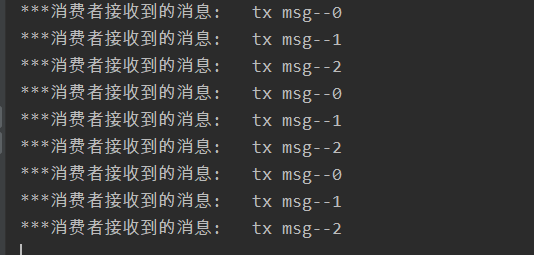
可以看出tx msg 0/1/2 重复发送了3次
11.3 消息消费的重试机制
(1)是什么
官网文档:http://activemq.apache.org/redelivery-policy
是什么: 消费者收到消息,之后出现异常了,没有告诉broker确认收到该消息,broker会尝试再将该消息发送给消费者。尝试n次,如果消费者还是没有确认收到该消息,那么该消息将被放到死信队列重,之后broker不会再将该消息发送给消费者。
(2)具体哪些情况会引发消息重发
① Client用了transactions且再session中调用了rollback
② Client用了transactions且再调用commit之前关闭或者没有commit
③ Client再CLIENT_ACKNOWLEDGE的传递模式下,session中调用了recover
(3)请说说消息重发时间间隔和重发次数
间隔:1
次数:6
如果超过6次,就把消息放到ack中
(4)有毒消息Poison ACK
一个消息被redelivedred超过默认的最大重发次数(默认6次)时,消费的回个MQ发一个“poison ack”表示这个消息有毒,告诉broker不要再发了。这个时候broker会把这个消息放到DLQ(私信队列)。
(5)属性说明

(6)代码验证
| 生产者。发送3条数据。代码省略….. |
|---|
| 消费者。开启事务,却没有commit。重启消费者,前6次都能收到消息,到第7次,不会再收到消息。代码: |
package com.xiaodidi;
import org.apache.activemq.ActiveMQConnectionFactory;
import javax.jms.*;
/**
* @author 10185
* @create 2021/4/23 19:43
*/
public class ConsumerActiveMq {
public static void main(String[] args) throws JMSException {
String host = "nio://192.168.241.125:61608";
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(host);
Connection connection = activeMQConnectionFactory.createConnection();
Session session = connection.createSession(true, Session.AUTO_ACKNOWLEDGE);
Queue xiaodidi = session.createQueue("xiaodidi");
MessageConsumer consumer = session.createConsumer(xiaodidi);
connection.start();
while (true) {
//强制转换成TextMessage,因为有5种形式去接受,发送什么形式,就要接受什么形式
//如果receive没有参数,代表一直等待,如果有时间限制,代表超时直接走人返回结果null
TextMessage receive = (TextMessage) consumer.receive();
System.out.println(receive.getText());
//如果接受到bye,就退出
if ("bye".equals(receive.getText())) {
break;
}
}
connection.close();
session.close();
consumer.close();
}
}

(7)代码修改默认参数
消费者。除灰色背景外,其他代码都和之前一样。修改重试次数为3。更多的设置请参考官网文档
//在connection.start();之前进行修改
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(ACTIVEMQ_URL);
// 修改默认参数,设置消息消费重试3次
RedeliveryPolicy redeliveryPolicy = new RedeliveryPolicy();
redeliveryPolicy.setMaximumRedeliveries(3);
activeMQConnectionFactory.setRedeliveryPolicy(redeliveryPolicy);
Connection connection = activeMQConnectionFactory.createConnection();
connection.start();
(8)整合spring
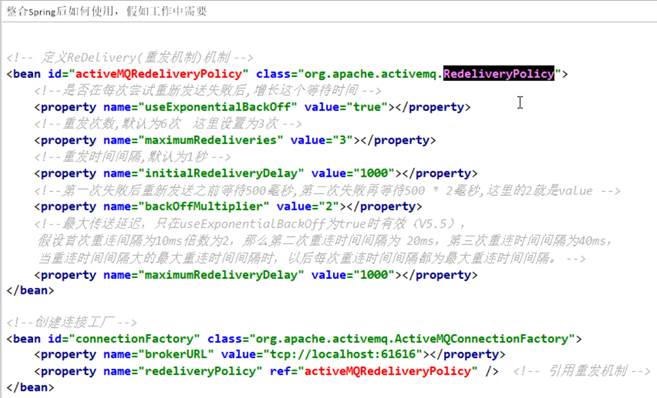
11.4 死信队列
承接上个标题的内容。
(1) 是什么
官网文档: http://activemq.apache.org/redelivery-policy
死信队列:异常消息规避处理的集合,主要处理失败的消息。
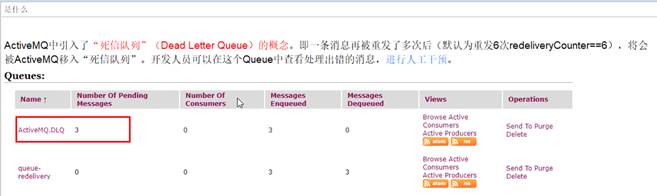
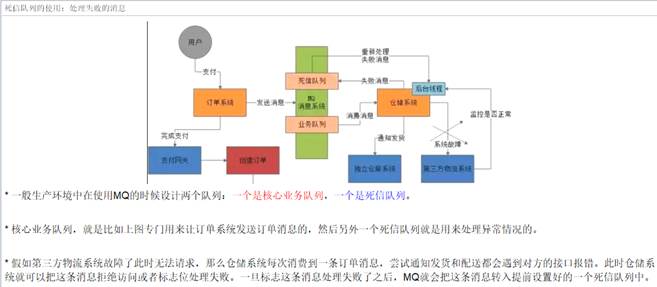

(2) 死信队列的配置(一般采用默认)
1. sharedDeadLetterStrategy
不管是queue还是topic,失败的消息都放到这个队列中。下面修改activemq.xml的配置,可以达到修改队列的名字。
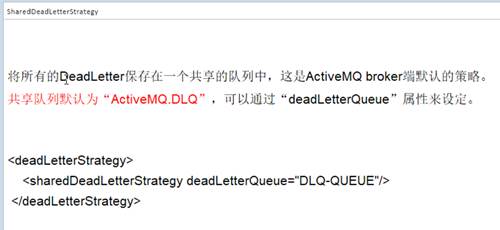
2. individualDeadLetterStrategy
可以为queue和topic单独指定两个死信队列。还可以为某个话题,单独指定一个死信队列。
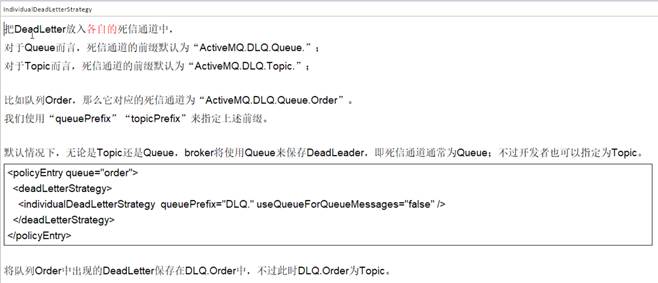
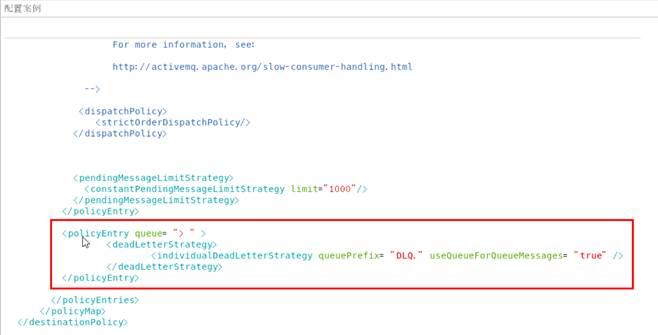
3. 自动删除过期消息
过期消息是值生产者指定的过期时间,超过这个时间的消息。
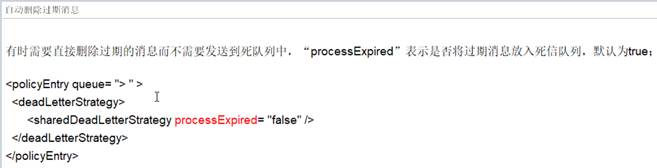
4. 存放非持久消息到死信队列中

11.5 消息不被重复消费,幂等性
如何保证消息不被重复消费呢?幕等性问题你谈谈

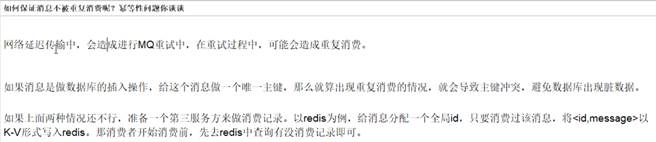
幂等性如何解决,根据messageid去查这个消息是否被消费了,如果已经插入了,就不进行重复提交,解决了重复消费的问题。
幂等 就是重复提交表单系统不会变了,因为都是操作同一个id值
像es中put请求操作的是id,表单重复提交,操作的对象都是同一个,执行成功把版本号提升一级
post请求操作的是新的数据库,因此系统会发生变化,因此不是幂等性的
Elasticsearch
第1章 Elasticsearch概述
01-开篇
结构化数据
非结构化数据
半结构化数据
02-技术选型
Elasticsearch 是什么
The Elastic Stack, 包括 Elasticsearch、 Kibana、 Beats 和 Logstash(也称为 ELK Stack)。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。
Elaticsearch,简称为 ES, ES 是一个开源的高扩展的分布式全文搜索引擎, 是整个 ElasticStack 技术栈的核心。
它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
elastic
英 [??l?st?k] 美 [??l?st?k]
n. 橡皮圈(或带);松紧带
adj. 橡皮圈(或带)的;有弹性的;有弹力的;灵活的;可改变的;可伸缩的
全文搜索引擎
Google,百度类的网站搜索,它们都是根据网页中的关键字生成索引,我们在搜索的时候输入关键字,它们会将该关键字即索引匹配到的所有网页返回;还有常见的项目中应用日志的搜索等等。对于这些非结构化的数据文本,关系型数据库搜索不是能很好的支持。
一般传统数据库,全文检索都实现的很鸡肋,因为一般也没人用数据库存文本字段。进行全文检索需要扫描整个表,如果数据量大的话即使对 SQL 的语法优化,也收效甚微。建立了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。
基于以上原因可以分析得出,在一些生产环境中,使用常规的搜索方式,性能是非常差的:
- 搜索的数据对象是大量的非结构化的文本数据。
- 文件记录量达到数十万或数百万个甚至更多。
- 支持大量基于交互式文本的查询。
- 需求非常灵活的全文搜索查询。
- 对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足。
- 对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况。为了解决结构化数据搜索和非结构化数据搜索性能问题,我们就需要专业,健壮,强大的全文搜索引擎 。
这里说到的全文搜索引擎指的是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
Elasticsearch 应用案例
- GitHub: 2013 年初,抛弃了 Solr,采取 Elasticsearch 来做 PB 级的搜索。 “GitHub 使用Elasticsearch 搜索 20TB 的数据,包括 13 亿文件和 1300 亿行代码”。
- 维基百科:启动以 Elasticsearch 为基础的核心搜索架构
- 百度:目前广泛使用 Elasticsearch 作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部 20 多个业务线(包括云分析、网盟、预测、文库、直达号、钱包、 风控等),单集群最大 100 台机器, 200 个 ES 节点,每天导入 30TB+数据。
- 新浪:使用 Elasticsearch 分析处理 32 亿条实时日志。
- 阿里:使用 Elasticsearch 构建日志采集和分析体系。
- Stack Overflow:解决 Bug 问题的网站,全英文,编程人员交流的网站。
03-教学大纲
- 第1章 Elasticsearch概述
- 第2章 Elasticsearch入门
- 第3章 Elasticsearch环境
- 第4章 Elasticsearch进阶
- 第5章 Elasticsearch集成
- 第6章 Elasticsearch优化
- 第7章 Elasticsearch面试题
04-环境准备
Windows 版的 Elasticsearch 压缩包,解压即安装完毕,解压后的 Elasticsearch 的目录结构如下 :
| 目录 | 含义 |
|---|---|
| bin | 可执行脚本目录 |
| config | 配置目录 |
| jdk | 内置 JDK 目录 |
| lib | 类库 |
| logs | 日志目录 |
| modules | 模块目录 |
| plugins | 插件目录 |
解压后,进入 bin 文件目录,点击 elasticsearch.bat 文件启动 ES 服务 。
注意: 9300 端口为 Elasticsearch 集群间组件的通信端口, 9200 端口为浏览器访问的 http协议 RESTful 端口。
打开浏览器,输入地址: http://localhost:9200,测试返回结果,返回结果如下:
{
"name" : "DESKTOP-LNJQ0VF",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "nCZqBhfdT1-pw8Yas4QU9w",
"version" : {
"number" : "7.8.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "757314695644ea9a1dc2fecd26d1a43856725e65",
"build_date" : "2020-06-14T19:35:50.234439Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
05 RESTful & JSON
REST 指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是 RESTful。 Web 应用程序最重要的 REST 原则是,客户端和服务器之间的交互在请求之间是无状态的。从客户端到服务器的每个请求都必须包含理解请求所必需的信息。如果服务器在请求之间的任何时间点重启,客户端不会得到通知。此外,无状态请求可以由任何可用服务器回答,这十分适合云计算之类的环境。客户端可以缓存数据以改进性能。
在服务器端,应用程序状态和功能可以分为各种资源。资源是一个有趣的概念实体,它向客户端公开。资源的例子有:应用程序对象、数据库记录、算法等等。每个资源都使用 URI(Universal Resource Identifier) 得到一个唯一的地址。所有资源都共享统一的接口,以便在客户端和服务器之间传输状态。使用的是标准的 HTTP 方法,比如 GET、 PUT、 POST 和DELETE。
在 REST 样式的 Web 服务中,每个资源都有一个地址。资源本身都是方法调用的目
标,方法列表对所有资源都是一样的。这些方法都是标准方法,包括 HTTP GET、 POST、PUT、 DELETE,还可能包括 HEAD 和 OPTIONS。简单的理解就是,如果想要访问互联网上的资源,就必须向资源所在的服务器发出请求,请求体中必须包含资源的网络路径, 以及对资源进行的操作(增删改查)。
REST 样式的 Web 服务若有返回结果,大多数以JSON字符串形式返回。
06 Postman客户端工具
如果直接通过浏览器向 Elasticsearch 服务器发请求,那么需要在发送的请求中包含
HTTP 标准的方法,而 HTTP 的大部分特性且仅支持 GET 和 POST 方法。所以为了能方便地进行客户端的访问,可以使用 Postman 软件Postman 是一款强大的网页调试工具,提供功能强大的 Web API 和 HTTP 请求调试。
软件功能强大,界面简洁明晰、操作方便快捷,设计得很人性化。 Postman 中文版能够发送任何类型的 HTTP 请求 (GET, HEAD, POST, PUT…),不仅能够表单提交,且可以附带任意类型请求体。
07 倒排索引
正排索引(传统)
| id | content |
|---|---|
| 1001 | my name is zhang san |
| 1002 | my name is li si |
倒排索引
| keyword | id |
|---|---|
| name | 1001, 1002 |
| zhang | 1001 |
08 对Elasticsearch的理解,以及类比mysql

Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。 为了方便大家理解,我们将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比
ES 里的 Index 可以看做一个库,而 Types 相当于表, Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化, Elasticsearch 6.X 中,一个 index 下已经只能包含一个type, Elasticsearch 7.X 中, Type 的概念已经被删除了。
第2章 HTTP的一些操作
2.1 索引-创建
对比关系型数据库,创建索引就等同于创建数据库。
在 Postman 中,向 ES 服务器发 PUT 请求 : http://127.0.0.1:9200/shopping
请求后,服务器返回响应:
{
"acknowledged": true,//响应结果
"shards_acknowledged": true,//分片结果
"index": "shopping"//索引名称
}
后台日志:
[2021-04-08T13:57:06,954][INFO ][o.e.c.m.MetadataCreateIndexService] [DESKTOP-LNJQ0VF] [shopping] creating index, cause [api], templates [], shards [1]/[1], mappings []
如果重复发 PUT 请求 : http://127.0.0.1:9200/shopping 添加索引,会返回错误信息 :
{
"error": {
"root_cause": [
{
"type": "resource_already_exists_exception",
"reason": "index [shopping/J0WlEhh4R7aDrfIc3AkwWQ] already exists",
"index_uuid": "J0WlEhh4R7aDrfIc3AkwWQ",
"index": "shopping"
}
],
"type": "resource_already_exists_exception",
"reason": "index [shopping/J0WlEhh4R7aDrfIc3AkwWQ] already exists",
"index_uuid": "J0WlEhh4R7aDrfIc3AkwWQ",
"index": "shopping"
},
"status": 400
}
2.2 索引-查询 & 删除
查看所有索引
在 Postman 中,向 ES 服务器发 GET 请求 : http://127.0.0.1:9200/_cat/indices?v
这里请求路径中的_cat 表示查看的意思, indices 表示索引,所以整体含义就是查看当前 ES服务器中的所有索引,就好像 MySQL 中的 show tables 的感觉,服务器响应结果如下 :
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open shopping J0WlEhh4R7aDrfIc3AkwWQ 1 1 0 0 208b 208b
| 表头 | 含义 |
|---|---|
| health | 当前服务器健康状态: green(集群完整) yellow(单点正常、集群不完整) red(单点不正常) |
| status | 索引打开、关闭状态 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主分片数量 |
| rep | 副本数量 |
| docs.count | 可用文档数量 |
| docs.deleted | 文档删除状态(逻辑删除) |
| store.size | 主分片和副分片整体占空间大小 |
| pri.store.size | 主分片占空间大小 |
查看单个索引
在 Postman 中,向 ES 服务器发 GET 请求 : http://127.0.0.1:9200/shopping
返回结果如下:
{
"shopping": {//索引名
"aliases": {},//别名
"mappings": {},//映射
"settings": {//设置
"index": {//设置 - 索引
"creation_date": "1617861426847",//设置 - 索引 - 创建时间
"number_of_shards": "1",//设置 - 索引 - 主分片数量
"number_of_replicas": "1",//设置 - 索引 - 主分片数量
"uuid": "J0WlEhh4R7aDrfIc3AkwWQ",//设置 - 索引 - 主分片数量
"version": {//设置 - 索引 - 主分片数量
"created": "7080099"
},
"provided_name": "shopping"//设置 - 索引 - 主分片数量
}
}
}
}
删除索引
在 Postman 中,向 ES 服务器发 DELETE 请求 : http://127.0.0.1:9200/shopping
返回结果如下:
{
"acknowledged": true
}
再次查看所有索引,GET http://127.0.0.1:9200/_cat/indices?v,返回结果如下:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
成功删除。
2.3 文档-创建(Put & Post)
此处需要注意:如果增加数据时明确数据主键,那么请求方式才可以为 PUT。
假设索引已经创建好了,接下来我们来创建文档,并添加数据。这里的文档可以类比为关系型数据库中的表数据,添加的数据格式为 JSON 格式
在 Postman 中,向 ES 服务器发 POST 请求 : http://127.0.0.1:9200/shopping/_doc,请求体JSON内容为:
{
"title":"小米手机",
"category":"小米",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}
注意,此处发送请求的方式必须为 POST,不能是 PUT,否则会发生错误 。
返回结果:
{
"_index": "shopping",//索引
"_type": "_doc",//类型-文档
"_id": "ANQqsHgBaKNfVnMbhZYU",//唯一标识,可以类比为 MySQL 中的主键,随机生成
"_version": 1,//版本
"result": "created",//结果,这里的 created 表示创建成功
"_shards": {//
"total": 2,//分片 - 总数
"successful": 1,//分片 - 总数
"failed": 0//分片 - 总数
},
"_seq_no": 0,
"_primary_term": 1
}
上面的数据创建后,由于没有指定数据唯一性标识(ID),默认情况下, ES 服务器会随机生成一个。
如果想要自定义唯一性标识,需要在创建时指定: http://127.0.0.1:9200/shopping/_doc/1,请求体JSON内容为:
注意:其中1为你指定的唯一id,如果id重复会进行覆盖
{
"title":"小米手机",
"category":"小米",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}
返回结果如下:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",//<------------------自定义唯一性标识
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
此处需要注意:如果增加数据时明确数据主键,那么请求方式也可以为 PUT。
2.4 查询-主键查询 & 全查询
查看文档时,需要指明文档的唯一性标识,类似于 MySQL 中数据的主键查询
在 Postman 中,向 ES 服务器发 GET 请求 : http://127.0.0.1:9200/shopping/_doc/1 。
返回结果如下:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_seq_no": 1,
"_primary_term": 1,
"found": true,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
}
查找不存在的内容,向 ES 服务器发 GET 请求 : http://127.0.0.1:9200/shopping/_doc/1001。
返回结果如下:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"found": false
}
查看索引下所有数据,向 ES 服务器发 GET 请求 : http://127.0.0.1:9200/shopping/_search。
返回结果如下:
{
"took": 133,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
}
]
}
}
2.5 全量修改 & 局部修改 & 删除
全量修改
和新增文档一样,输入相同的 URL 地址请求,如果请求体变化,会将原有的数据内容覆盖
在 Postman 中,向 ES 服务器发 POST/PUT 请求 : http://127.0.0.1:9200/shopping/_doc/1
请求体JSON内容为:
{
"title":"华为手机",
"category":"华为",
"images":"http://www.gulixueyuan.com/hw.jpg",
"price":1999.00
}
修改成功后,服务器响应结果:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_version": 2,
"result": "updated",//<-----------updated 表示数据被更新
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}
局部修改
修改数据时,也可以只修改某一给条数据的局部信息
在 Postman 中,向 ES 服务器发 POST 请求 : http://127.0.0.1:9200/shopping/_update/1。
请求体JSON内容为:
{
"doc": {
"title":"小米手机",
"category":"小米"
}
}
返回结果如下:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_version": 3,
"result": "updated",//<-----------updated 表示数据被更新
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_doc/1,查看修改内容:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_version": 3,
"_seq_no": 3,
"_primary_term": 1,
"found": true,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/hw.jpg",
"price": 1999
}
}
删除
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
在 Postman 中,向 ES 服务器发 DELETE 请求 : http://127.0.0.1:9200/shopping/_doc/1
返回结果:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_version": 4,
"result": "deleted",//<---删除成功
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 1
}
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_doc/1,查看是否删除成功:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"found": false
}
2.6 条件查询 & 分页查询 & 查询排序
条件查询
假设有以下文档内容,(在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search):
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": 1,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": 1,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": 1,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
}
}
URL带参查询
查找category为小米的文档,在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search?q=category:小米,返回结果如下:
{
"took": 94,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1.3862942,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 1.3862942,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": 1.3862942,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
}
}
上述为URL带参数形式查询,这很容易让不善者心怀恶意,或者参数值出现中文会出现乱码情况。为了避免这些情况,我们可用使用带JSON请求体请求进行查询。
请求体带参查询
接下带JSON请求体,还是查找category为小米的文档,在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"query":{
"match":{
"category":"小米"
}
}
}
返回结果如下:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1.3862942,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 1.3862942,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": 1.3862942,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
}
}
带请求体方式的查找所有内容
查找所有文档内容,也可以这样,在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"query":{
"match_all":{}
}
}
则返回所有文档内容:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": 1,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": 1,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": 1,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
}
}
查询指定字段
如果你想查询指定字段,在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"query":{
"match_all":{}
},
"_source":["title"]
}
代表只查询title其他的不进行显示
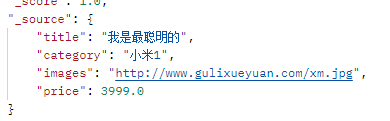

返回结果如下:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1,
"_source": {
"title": "小米手机"
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 1,
"_source": {
"title": "小米手机"
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": 1,
"_source": {
"title": "小米手机"
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": 1,
"_source": {
"title": "华为手机"
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": 1,
"_source": {
"title": "华为手机"
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": 1,
"_source": {
"title": "华为手机"
}
}
]
}
}
分页查询
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
(页数-1)*每页显示的数量
{
"query":{
"match_all":{}
},
"from":0,
"size":2
}
返回结果如下:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
}
}
查询排序
如果你想通过排序查出价格最高的手机,在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"query":{
"match_all":{}
},
"sort":{
"price":{
"order":"desc"
#升序ASC
}
}
}
返回结果如下:
{
"took": 96,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": null,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
},
"sort": [
3999
]
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": null,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
},
"sort": [
1999
]
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": null,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
},
"sort": [
1999
]
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": null,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
},
"sort": [
1999
]
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": null,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
},
"sort": [
1999
]
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": null,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
},
"sort": [
1999
]
}
]
}
}
2.7 多条件查询 & 范围查询
多条件查询
假设想找出小米牌子,价格为3999元的。(must相当于数据库的&&)
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"query":{
"bool":{
"must":[{
"match":{
"category":"小米"
}
},{
"match":{
"price":3999.00
}
}]
}
}
}
返回结果如下:
{
"took": 134,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.3862944,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 2.3862944,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
}
]
}
}
假设想找出小米和华为的牌子。(should相当于数据库的||)
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"query":{
"bool":{
"should":[{
"match":{
"category":"小米"
}
},{
"match":{
"category":"华为"
}
}]
}
}
}
返回结果如下:
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1.3862942,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 1.3862942,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": 1.3862942,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": 1.3862942,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": 1.3862942,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": 1.3862942,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
}
}
范围查询
假设想找出小米和华为的牌子,价格大于2000元的手机。
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"query": {
"bool": {
"should": [
{
"match": {
"category": "小米"
}
},
{
"match": {
"category": "华为"
}
}
],
"filter": {
"range": {
"price": {
"gt": 2000
}
}
}
}
}
}
返回结果如下:
{
"took": 72,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1.3862942,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
}
]
}
}
2.8 全文检索 & 完全匹配 & 高亮查询
全文检索
这功能像搜索引擎那样,如品牌输入“小华”,返回结果带回品牌有“小米”和华为的。
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"query":{
"match":{
"category" : "小华"
}
}
}
返回结果如下:
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 0.6931471,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 0.6931471,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 0.6931471,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": 0.6931471,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": 0.6931471,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": 0.6931471,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": 0.6931471,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
}
}
完全匹配(就是查询的结果一定要包含这个字段)
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"query":{
"match_phrase":{
"category" : "为"
}
}
}
返回结果如下:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 0.6931471,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": 0.6931471,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": 0.6931471,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": 0.6931471,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
}
}
高亮查询
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"query":{
"match_phrase":{
"category" : "为"
}
},
"highlight":{
"fields":{
"category":{}//<----高亮这字段
}
}
}
返回结果如下:
{
"took": 100,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 0.6931471,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": 0.6931471,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
},
"highlight": {
"category": [
"华<em>为</em>"//<------高亮一个为字。
]
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": 0.6931471,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
},
"highlight": {
"category": [
"华<em>为</em>"
]
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": 0.6931471,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
},
"highlight": {
"category": [
"华<em>为</em>"
]
}
}
]
}
}
2.9 聚合查询
聚合允许使用者对 es 文档进行统计分析,类似与关系型数据库中的 group by,当然还有很多其他的聚合,例如取最大值max、平均值avg等等。
接下来按price字段进行分组:
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"aggs":{//聚合操作
"price_group":{//名称,随意起名
"terms":{//分组
"field":"price"//分组字段
}
}
}
}
返回结果如下:
{
"took": 63,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "ANQqsHgBaKNfVnMbhZYU",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "A9R5sHgBaKNfVnMb25Ya",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BNR5sHgBaKNfVnMb7pal",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "BtR6sHgBaKNfVnMbX5Y5",
"_score": 1,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "B9R6sHgBaKNfVnMbZpZ6",
"_score": 1,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "CdR7sHgBaKNfVnMbsJb9",
"_score": 1,
"_source": {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 1999
}
}
]
},
"aggregations": {
"price_group": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 1999,
"doc_count": 5
},
{
"key": 3999,
"doc_count": 1
}
]
}
}
}
上面返回结果会附带原始数据的。若不想要不附带原始数据的结果,在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"aggs":{
"price_group":{
"terms":{
"field":"price"
}
}
},
"size":0
}
返回结果如下:
{
"took": 60,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"price_group": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 1999,
"doc_count": 5
},
{
"key": 3999,
"doc_count": 1
}
]
}
}
}
若想对所有手机价格求平均值。
在 Postman 中,向 ES 服务器发 GET请求 : http://127.0.0.1:9200/shopping/_search,附带JSON体如下:
{
"aggs":{
"price_avg":{//名称,随意起名
"avg":{//求平均
"field":"price"
}
}
},
"size":0
}
返回结果如下:
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"price_avg": {
"value": 2332.3333333333335
}
}
}
2.10 映射关系
有了索引库,等于有了数据库中的 database。
接下来就需要建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)。
创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。
先创建一个索引:
## PUT http://127.0.0.1:9200/user
返回结果:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "user"
}
创建映射
## PUT http://127.0.0.1:9200/user/_mapping
{
"properties": {
"name":{
"type": "text",
"index": true
},
"sex":{
"type": "keyword",
"index": true
},
"tel":{
"type": "keyword",
"index": false
}
}
}
返回结果如下:
{
"acknowledged": true
}
查询映射
##GET http://127.0.0.1:9200/user/_mapping
返回结果如下:
{
"user": {
"mappings": {
"properties": {
"name": {
"type": "text"
},
"sex": {
"type": "keyword"
},
"tel": {
"type": "keyword",
"index": false
}
}
}
}
}
增加数据
##PUT http://127.0.0.1:9200/user/_create/1001
{
"name":"小米",
"sex":"男的",
"tel":"1111"
}
返回结果如下:
{
"_index": "user",
"_type": "_doc",
"_id": "1001",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
查找name含有”小“数据:
##GET http://127.0.0.1:9200/user/_search
{
"query":{
"match":{
"name":"小"
}
}
}
返回结果如下:
{
"took": 495,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "user",
"_type": "_doc",
"_id": "1001",
"_score": 0.2876821,
"_source": {
"name": "小米",
"sex": "男的",
"tel": "1111"
}
}
]
}
}
查找sex含有”男“数据:(keyword类型的映射只能完全匹配才能查询出来)
##GET http://127.0.0.1:9200/user/_search
{
"query":{
"match":{
"sex":"男"
}
}
}
返回结果如下:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}
找不想要的结果,只因创建映射时"sex"的类型为"keyword"。
“sex"只能完全为”男的“,才能得出原数据。
##GET http://127.0.0.1:9200/user/_search
{
"query":{
"match":{
"sex":"男的"
}
}
}
返回结果如下:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "user",
"_type": "_doc",
"_id": "1001",
"_score": 0.2876821,
"_source": {
"name": "小米",
"sex": "男的",
"tel": "1111"
}
}
]
}
}
查询电话
## GET http://127.0.0.1:9200/user/_search
{
"query":{
"match":{
"tel":"11"
}
}
}
返回结果如下:
{
"error": {
"root_cause": [
{
"type": "query_shard_exception",
"reason": "failed to create query: Cannot search on field [tel] since it is not indexed.",
"index_uuid": "ivLnMfQKROS7Skb2MTFOew",
"index": "user"
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "user",
"node": "4P7dIRfXSbezE5JTiuylew",
"reason": {
"type": "query_shard_exception",
"reason": "failed to create query: Cannot search on field [tel] since it is not indexed.",
"index_uuid": "ivLnMfQKROS7Skb2MTFOew",
"index": "user",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Cannot search on field [tel] since it is not indexed."
}
}
}
]
},
"status": 400
}
报错只因创建映射时"tel"的"index"为false。
2.11 ES的批量操作——bulk
匹配导入数据
POST http://192.168.56.10:9200/customer/external/_bulk
两行为一个整体
{"index":{"_id":"1"}}
{"name":"a"}
{"index":{"_id":"2"}}
{"name":"b"}
注意格式json和text均不可,要去kibana里Dev Tools
语法格式:
{action:{metadata}}\n
{request body }\n
{action:{metadata}}\n
{request body }\n
这里的批量操作,当发生某一条执行发生失败时,其他的数据仍然能够接着执行,也就是说彼此之间是独立的。
bulk api以此按顺序执行所有的action(动作)。如果一个单个的动作因任何原因失败,它将继续处理它后面剩余的动作。当bulk api返回时,它将提供每个动作的状态(与发送的顺序相同),所以您可以检查是否一个指定的动作是否失败了。
实例1: 执行多条数据
POST /customer/external/_bulk
{"index":{"_id":"1"}}
{"name":"John Doe"}
{"index":{"_id":"2"}}
{"name":"John Doe"}
执行结果
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated.
{
"took" : 318, 花费了多少ms
"errors" : false, 没有发生任何错误
"items" : [ 每个数据的结果
{
"index" : { 保存
"_index" : "customer", 索引
"_type" : "external", 类型
"_id" : "1", 文档
"_version" : 1, 版本
"result" : "created", 创建
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201 新建完成
}
},
{
"index" : { 第二条记录
"_index" : "customer",
"_type" : "external",
"_id" : "2",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
}
]
}
实例2:对于整个索引执行批量操作
POST /_bulk
{"delete":{"_index":"website","_type":"blog","_id":"123"}}
{"create":{"_index":"website","_type":"blog","_id":"123"}}
{"title":"my first blog post"}
{"index":{"_index":"website","_type":"blog"}}
{"title":"my second blog post"}
{"update":{"_index":"website","_type":"blog","_id":"123"}}
{"doc":{"title":"my updated blog post"}}
运行结果:
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated.
{
"took" : 304,
"errors" : false,
"items" : [
{
"delete" : { 删除
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 1,
"result" : "not_found", 没有该记录
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 404 没有该
}
},
{
"create" : { 创建
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 2,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : { 保存
"_index" : "website",
"_type" : "blog",
"_id" : "5sKNvncBKdY1wAQmeQNo",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
},
{
"update" : { 更新
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1,
"status" : 200
}
}
]
}
2.12 样本测试数据
准备了一份顾客银行账户信息的虚构的JSON文档样本。每个文档都有下列的schema(模式)。
{
"account_number": 1,
"balance": 39225,
"firstname": "Amber",
"lastname": "Duke",
"age": 32,
"gender": "M",
"address": "880 Holmes Lane",
"employer": "Pyrami",
"email": "amberduke@pyrami.com",
"city": "Brogan",
"state": "IL"
}
https://github.com/elastic/elasticsearch/blob/master/docs/src/test/resources/accounts.json ,导入测试数据,
POST bank/account/_bulk
上面的数据
http://192.168.56.10:9200/_cat/indices
刚导入了1000条
yellow open bank 99m64ElxRuiH46wV7RjXZA 1 1 1000 0 427.8kb 427.8kb
第三章 javaapi的一些操作
3.1 环境准备
新建Maven工程。
添加依赖:
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch 的客户端 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch 依赖 2.x 的 log4j -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.9</version>
</dependency>
<!-- junit 单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
HelloElasticsearch
import java.io.IOException;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
public class HelloElasticsearch {
public static void main(String[] args) throws IOException {
// 创建客户端对象
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
// ...
System.out.println(client);
// 关闭客户端连接
client.close();
}
}
3.2 索引-创建
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.create.CreateIndexRequest;
import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import java.io.IOException;
public class CreateIndex {
public static void main(String[] args) throws IOException {
// 创建客户端对象
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
// 创建索引 - 请求对象
CreateIndexRequest request = new CreateIndexRequest("user2");
// 发送请求,获取响应
CreateIndexResponse response = client.indices().create(request,
RequestOptions.DEFAULT);
boolean acknowledged = response.isAcknowledged();
// 响应状态
System.out.println("操作状态 = " + acknowledged);
// 关闭客户端连接
client.close();
}
}
后台打印:
四月 09, 2021 2:12:08 下午 org.elasticsearch.client.RestClient logResponse
警告: request [PUT http://localhost:9200/user2?master_timeout=30s&include_type_name=true&timeout=30s] returned 1 warnings: [299 Elasticsearch-7.8.0-757314695644ea9a1dc2fecd26d1a43856725e65 "[types removal] Using include_type_name in create index requests is deprecated. The parameter will be removed in the next major version."]
操作状态 = true
Process finished with exit code 0
3.3 索引-查询 & 删除
查询
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.GetIndexResponse;
import java.io.IOException;
public class SearchIndex {
public static void main(String[] args) throws IOException {
// 创建客户端对象
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
// 查询索引 - 请求对象
GetIndexRequest request = new GetIndexRequest("user2");
// 发送请求,获取响应
GetIndexResponse response = client.indices().get(request,
RequestOptions.DEFAULT);
System.out.println("aliases:"+response.getAliases());
System.out.println("mappings:"+response.getMappings());
System.out.println("settings:"+response.getSettings());
client.close();
}
}
后台打印:
aliases:{user2=[]}
mappings:{user2=org.elasticsearch.cluster.metadata.MappingMetadata@ad700514}
settings:{user2={"index.creation_date":"1617948726976","index.number_of_replicas":"1","index.number_of_shards":"1","index.provided_name":"user2","index.uuid":"UGZ1ntcySnK6hWyP2qoVpQ","index.version.created":"7080099"}}
Process finished with exit code 0
删除
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import java.io.IOException;
public class DeleteIndex {
public static void main(String[] args) throws IOException {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
// 删除索引 - 请求对象
DeleteIndexRequest request = new DeleteIndexRequest("user2");
// 发送请求,获取响应
AcknowledgedResponse response = client.indices().delete(request,RequestOptions.DEFAULT);
// 操作结果
System.out.println("操作结果 : " + response.isAcknowledged());
client.close();
}
}
后台打印:
操作结果 : true
Process finished with exit code 0
3.4 文档-新增 & 修改
重构
上文由于频繁使用以下连接Elasticsearch和关闭它的代码,于是个人对它进行重构。
public class SomeClass {
public static void main(String[] args) throws IOException {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
...
client.close();
}
}
重构后的代码:
import org.elasticsearch.client.RestHighLevelClient;
public interface ElasticsearchTask {
void doSomething(RestHighLevelClient client) throws Exception;
}
public class ConnectElasticsearch{
public static void connect(ElasticsearchTask task){
// 创建客户端对象
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
try {
task.doSomething(client);
// 关闭客户端连接
client.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
接下来,如果想让Elasticsearch完成一些操作,就编写一个lambda式即可。
public class SomeClass {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
//do something
});
}
}
新增
import com.fasterxml.jackson.databind.ObjectMapper;
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.model.User;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.common.xcontent.XContentType;
public class InsertDoc {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
// 新增文档 - 请求对象
IndexRequest request = new IndexRequest();
// 设置索引及唯一性标识
request.index("user").id("1001");
// 创建数据对象
User user = new User();
user.setName("zhangsan");
user.setAge(30);
user.setSex("男");
ObjectMapper objectMapper = new ObjectMapper();
String productJson = objectMapper.writeValueAsString(user);
// 添加文档数据,数据格式为 JSON 格式
request.source(productJson, XContentType.JSON);
// 客户端发送请求,获取响应对象
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
3.打印结果信息
System.out.println("_index:" + response.getIndex());
System.out.println("_id:" + response.getId());
System.out.println("_result:" + response.getResult());
});
}
}
后台打印:
_index:user
_id:1001
_result:UPDATED
Process finished with exit code 0
修改
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.common.xcontent.XContentType;
public class UpdateDoc {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
// 修改文档 - 请求对象
UpdateRequest request = new UpdateRequest();
// 配置修改参数
request.index("user").id("1001");
// 设置请求体,对数据进行修改
//注意,这个要更改的数据是成对出现的
request.doc(XContentType.JSON, "sex", "女");
// 客户端发送请求,获取响应对象
UpdateResponse response = client.update(request, RequestOptions.DEFAULT);
System.out.println("_index:" + response.getIndex());
System.out.println("_id:" + response.getId());
System.out.println("_result:" + response.getResult());
});
}
}
后台打印:
_index:user
_id:1001
_result:UPDATED
Process finished with exit code 0
3.5 文档-查询 & 删除
查询
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.client.RequestOptions;
public class GetDoc {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
//1.创建请求对象
GetRequest request = new GetRequest().index("user").id("1001");
//2.客户端发送请求,获取响应对象
GetResponse response = client.get(request, RequestOptions.DEFAULT);
3.打印结果信息
System.out.println("_index:" + response.getIndex());
System.out.println("_type:" + response.getType());
System.out.println("_id:" + response.getId());
System.out.println("source:" + response.getSourceAsString());
});
}
}
后台打印:
_index:user
_type:_doc
_id:1001
source:{"name":"zhangsan","age":30,"sex":"男"}
Process finished with exit code 0
删除
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.client.RequestOptions;
public class DeleteDoc {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
//创建请求对象
DeleteRequest request = new DeleteRequest().index("user").id("1001");
//客户端发送请求,获取响应对象
DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);
//打印信息
System.out.println(response.toString());
});
}
}
后台打印:
DeleteResponse[index=user,type=_doc,id=1001,version=16,result=deleted,shards=ShardInfo{total=2, successful=1, failures=[]}]
Process finished with exit code 0
3.6 文档-批量新增 & 批量删除
批量新增
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.common.xcontent.XContentType;
public class BatchInsertDoc {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
//创建批量新增请求对象
BulkRequest request = new BulkRequest();
//注意,这个要修改的数据是成对出现的
request.add(new
IndexRequest().index("user").id("1001").source(XContentType.JSON, "name",
"zhangsan"));
request.add(new
IndexRequest().index("user").id("1002").source(XContentType.JSON, "name",
"lisi"));
request.add(new
IndexRequest().index("user").id("1003").source(XContentType.JSON, "name",
"wangwu"));
//客户端发送请求,获取响应对象
BulkResponse responses = client.bulk(request, RequestOptions.DEFAULT);
//打印结果信息
//获取运行时间
System.out.println("took:" + responses.getTook());
//获取对象
System.out.println("items:" + responses.getItems());
});
}
}
后台打印
took:294ms
items:[Lorg.elasticsearch.action.bulk.BulkItemResponse;@2beee7ff
Process finished with exit code 0
批量删除
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.client.RequestOptions;
public class BatchDeleteDoc {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
//创建批量删除请求对象
BulkRequest request = new BulkRequest();
request.add(new DeleteRequest().index("user").id("1001"));
request.add(new DeleteRequest().index("user").id("1002"));
request.add(new DeleteRequest().index("user").id("1003"));
//客户端发送请求,获取响应对象
BulkResponse responses = client.bulk(request, RequestOptions.DEFAULT);
//打印结果信息
System.out.println("took:" + responses.getTook());
System.out.println("items:" + responses.getItems());
});
}
}
后台打印
took:108ms
items:[Lorg.elasticsearch.action.bulk.BulkItemResponse;@7b02881e
Process finished with exit code 0
3.7 高级查询-全量查询
先批量增加数据
public class BatchInsertDoc {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
//创建批量新增请求对象
BulkRequest request = new BulkRequest();
request.add(new IndexRequest().index("user").id("1001").source(XContentType.JSON, "name", "zhangsan", "age", "10", "sex","女"));
request.add(new IndexRequest().index("user").id("1002").source(XContentType.JSON, "name", "lisi", "age", "30", "sex","女"));
request.add(new IndexRequest().index("user").id("1003").source(XContentType.JSON, "name", "wangwu1", "age", "40", "sex","男"));
request.add(new IndexRequest().index("user").id("1004").source(XContentType.JSON, "name", "wangwu2", "age", "20", "sex","女"));
request.add(new IndexRequest().index("user").id("1005").source(XContentType.JSON, "name", "wangwu3", "age", "50", "sex","男"));
request.add(new IndexRequest().index("user").id("1006").source(XContentType.JSON, "name", "wangwu4", "age", "20", "sex","男"));
//客户端发送请求,获取响应对象
BulkResponse responses = client.bulk(request, RequestOptions.DEFAULT);
//打印结果信息
System.out.println("took:" + responses.getTook());
System.out.println("items:" + responses.getItems());
});
}
}
后台打印
took:168ms
items:[Lorg.elasticsearch.action.bulk.BulkItemResponse;@2beee7ff
Process finished with exit code 0
查询所有索引数据
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
public class QueryDoc {
public static void main(String[] args) {
ConnectElasticsearch.connect(client -> {
// 创建搜索请求对象
SearchRequest request = new SearchRequest();
request.indices("user");
// 构建查询的请求体
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 查询所有数据
sourceBuilder.query(QueryBuilders.matchAllQuery());
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 查询匹配
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//输出每条查询的结果信息
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
});
}
}
后台打印
took:2ms
timeout:false
total:6 hits
MaxScore:1.0
hits========>>
{"name":"zhangsan","age":"10","sex":"女"}
{"name":"lisi","age":"30","sex":"女"}
{"name":"wangwu1","age":"40","sex":"男"}
{"name":"wangwu2","age":"20","sex":"女"}
{"name":"wangwu3","age":"50","sex":"男"}
{"name":"wangwu4","age":"20","sex":"男"}
<<========
Process finished with exit code 0
3.8 高级查询-分页查询 & 条件查询 & 查询排序
条件查询
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_BY_CONDITION = client -> {
// 创建搜索请求对象
SearchRequest request = new SearchRequest();
request.indices("user");
// 构建查询的请求体
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//匹配年龄等于30的数据
sourceBuilder.query(QueryBuilders.termQuery("age", "30"));
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 查询匹配
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//输出每条查询的结果信息
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
};
public static void main(String[] args) {
ConnectElasticsearch.connect(SEARCH_BY_CONDITION);
}
}
后台打印
took:1ms
timeout:false
total:1 hits
MaxScore:1.0
hits========>>
{"name":"lisi","age":"30","sex":"女"}
<<========
分页查询
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_BY_PAGING = client -> {
// 创建搜索请求对象
SearchRequest request = new SearchRequest();
request.indices("user");
// 构建查询的请求体
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchAllQuery());
// 分页查询
// 当前页其实索引(第一条数据的顺序号), from
sourceBuilder.from(0);
// 每页显示多少条 size
sourceBuilder.size(2);
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 查询匹配
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//输出每条查询的结果信息
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
};
public static void main(String[] args) {
ConnectElasticsearch.connect(SEARCH_BY_CONDITION);
}
}
后台打印
took:1ms
timeout:false
total:6 hits
MaxScore:1.0
hits========>>
{"name":"zhangsan","age":"10","sex":"女"}
{"name":"lisi","age":"30","sex":"女"}
<<========
查询排序
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_WITH_ORDER = client -> {
// 创建搜索请求对象
SearchRequest request = new SearchRequest();
request.indices("user");
// 构建查询的请求体
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchAllQuery());
// 排序
sourceBuilder.sort("age", SortOrder.ASC);
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 查询匹配
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//输出每条查询的结果信息
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
};
public static void main(String[] args) {
ConnectElasticsearch.connect(SEARCH_WITH_ORDER);
}
}
后台打印
took:1ms
timeout:false
total:6 hits
MaxScore:NaN
hits========>>
{"name":"zhangsan","age":"10","sex":"女"}
{"name":"wangwu2","age":"20","sex":"女"}
{"name":"wangwu4","age":"20","sex":"男"}
{"name":"lisi","age":"30","sex":"女"}
{"name":"wangwu1","age":"40","sex":"男"}
{"name":"wangwu3","age":"50","sex":"男"}
<<========
3.9 高级查询-组合查询 & 范围查询
组合查询
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_BY_BOOL_CONDITION = client -> {
// 创建搜索请求对象
SearchRequest request = new SearchRequest();
request.indices("user");
// 构建查询的请求体
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 必须包含
boolQueryBuilder.must(QueryBuilders.matchQuery("age", "30"));
// 一定不含
boolQueryBuilder.mustNot(QueryBuilders.matchQuery("name", "zhangsan"));
// 可能包含
boolQueryBuilder.should(QueryBuilders.matchQuery("sex", "男"));
sourceBuilder.query(boolQueryBuilder);
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 查询匹配
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//输出每条查询的结果信息
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
};
public static void main(String[] args) {
ConnectElasticsearch.connect(SEARCH_BY_BOOL_CONDITION);
}
}
后台打印
took:28ms
timeout:false
total:1 hits
MaxScore:1.0
hits========>>
{"name":"lisi","age":"30","sex":"女"}
<<========
Process finished with exit code 0
范围查询
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.RangeQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_BY_RANGE = client -> {
// 创建搜索请求对象
SearchRequest request = new SearchRequest();
request.indices("user");
// 构建查询的请求体
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
RangeQueryBuilder rangeQuery = QueryBuilders.rangeQuery("age");
// 大于等于
//rangeQuery.gte("30");
// 小于等于
rangeQuery.lte("40");
sourceBuilder.query(rangeQuery);
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 查询匹配
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//输出每条查询的结果信息
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
};
public static void main(String[] args) {
ConnectElasticsearch.connect(SEARCH_BY_RANGE);
}
}
后台打印
took:1ms
timeout:false
total:5 hits
MaxScore:1.0
hits========>>
{"name":"zhangsan","age":"10","sex":"女"}
{"name":"lisi","age":"30","sex":"女"}
{"name":"wangwu1","age":"40","sex":"男"}
{"name":"wangwu2","age":"20","sex":"女"}
{"name":"wangwu4","age":"20","sex":"男"}
<<========
Process finished with exit code 0
3.10 高级查询-模糊查询 & 高亮查询
模糊查询
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.common.unit.Fuzziness;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.RangeQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_BY_FUZZY_CONDITION = client -> {
// 创建搜索请求对象
SearchRequest request = new SearchRequest();
request.indices("user");
// 构建查询的请求体
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//表示name等于wangwu,或者可以等于wangwu1,wangwu2,可以相差一个字符
sourceBuilder.query(QueryBuilders.fuzzyQuery("name","wangwu").fuzziness(Fuzziness.ONE));
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 查询匹配
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//输出每条查询的结果信息
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
};
public static void main(String[] args) {
// ConnectElasticsearch.connect(SEARCH_ALL);
// ConnectElasticsearch.connect(SEARCH_BY_CONDITION);
// ConnectElasticsearch.connect(SEARCH_BY_PAGING);
// ConnectElasticsearch.connect(SEARCH_WITH_ORDER);
// ConnectElasticsearch.connect(SEARCH_BY_BOOL_CONDITION);
// ConnectElasticsearch.connect(SEARCH_BY_RANGE);
ConnectElasticsearch.connect(SEARCH_BY_FUZZY_CONDITION);
}
}
后台打印
took:152ms
timeout:false
total:4 hits
MaxScore:1.2837042
hits========>>
{"name":"wangwu1","age":"40","sex":"男"}
{"name":"wangwu2","age":"20","sex":"女"}
{"name":"wangwu3","age":"50","sex":"男"}
{"name":"wangwu4","age":"20","sex":"男"}
<<========
Process finished with exit code 0
高亮查询
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.common.unit.Fuzziness;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.RangeQueryBuilder;
import org.elasticsearch.index.query.TermsQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortOrder;
import java.util.Map;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_WITH_HIGHLIGHT = client -> {
// 高亮查询
SearchRequest request = new SearchRequest().indices("user");
//2.创建查询请求体构建器
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//构建查询方式:高亮查询
TermsQueryBuilder termsQueryBuilder =
QueryBuilders.termsQuery("name","zhangsan");
//设置查询方式
sourceBuilder.query(termsQueryBuilder);
//构建高亮字段
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<font color='red'>");//设置标签前缀
highlightBuilder.postTags("</font>");//设置标签后缀
highlightBuilder.field("name");//设置高亮字段
//设置高亮构建对象
sourceBuilder.highlighter(highlightBuilder);
//设置请求体
request.source(sourceBuilder);
//3.客户端发送请求,获取响应对象
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.打印响应结果
SearchHits hits = response.getHits();
System.out.println("took::"+response.getTook());
System.out.println("time_out::"+response.isTimedOut());
System.out.println("total::"+hits.getTotalHits());
System.out.println("max_score::"+hits.getMaxScore());
System.out.println("hits::::>>");
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
//打印高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
System.out.println(highlightFields);
}
System.out.println("<<::::");
};
public static void main(String[] args) {
ConnectElasticsearch.connect(SEARCH_WITH_HIGHLIGHT);
}
}
后台打印
took::672ms
time_out::false
total::1 hits
max_score::1.0
hits::::>>
{"name":"zhangsan","age":"10","sex":"女"}
{name=[name], fragments[[<font color='red'>zhangsan</font>]]}
<<::::
Process finished with exit code 0
3.11 高级查询-最大值查询 & 分组查询
最大值查询
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.common.unit.Fuzziness;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.RangeQueryBuilder;
import org.elasticsearch.index.query.TermsQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortOrder;
import java.util.Map;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_WITH_MAX = client -> {
// 高亮查询
SearchRequest request = new SearchRequest().indices("user");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.aggregation(AggregationBuilders.max("maxAge").field("age"));
//设置请求体
request.source(sourceBuilder);
//3.客户端发送请求,获取响应对象
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.打印响应结果
SearchHits hits = response.getHits();
System.out.println(response);
};
public static void main(String[] args) {
ConnectElasticsearch.connect(SEARCH_WITH_MAX);
}
}
后台打印
{"took":16,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":6,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"user","_type":"_doc","_id":"1001","_score":1.0,"_source":{"name":"zhangsan","age":"10","sex":"女"}},{"_index":"user","_type":"_doc","_id":"1002","_score":1.0,"_source":{"name":"lisi","age":"30","sex":"女"}},{"_index":"user","_type":"_doc","_id":"1003","_score":1.0,"_source":{"name":"wangwu1","age":"40","sex":"男"}},{"_index":"user","_type":"_doc","_id":"1004","_score":1.0,"_source":{"name":"wangwu2","age":"20","sex":"女"}},{"_index":"user","_type":"_doc","_id":"1005","_score":1.0,"_source":{"name":"wangwu3","age":"50","sex":"男"}},{"_index":"user","_type":"_doc","_id":"1006","_score":1.0,"_source":{"name":"wangwu4","age":"20","sex":"男"}}]},"aggregations":{"max#maxAge":{"value":50.0}}}
Process finished with exit code 0
分组查询
import com.lun.elasticsearch.hello.ConnectElasticsearch;
import com.lun.elasticsearch.hello.ElasticsearchTask;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.common.unit.Fuzziness;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.RangeQueryBuilder;
import org.elasticsearch.index.query.TermsQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortOrder;
import java.util.Map;
public class QueryDoc {
public static final ElasticsearchTask SEARCH_WITH_GROUP = client -> {
SearchRequest request = new SearchRequest().indices("user");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.aggregation(AggregationBuilders.terms("age_groupby").field("age"));
//设置请求体
request.source(sourceBuilder);
//3.客户端发送请求,获取响应对象
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.打印响应结果
SearchHits hits = response.getHits();
System.out.println(response);
};
public static void main(String[] args) {
ConnectElasticsearch.connect(SEARCH_WITH_GROUP);
}
}
后台打印
{"took":10,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":6,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"user","_type":"_doc","_id":"1001","_score":1.0,"_source":{"name":"zhangsan","age":"10","sex":"女"}},{"_index":"user","_type":"_doc","_id":"1002","_score":1.0,"_source":{"name":"lisi","age":"30","sex":"女"}},{"_index":"user","_type":"_doc","_id":"1003","_score":1.0,"_source":{"name":"wangwu1","age":"40","sex":"男"}},{"_index":"user","_type":"_doc","_id":"1004","_score":1.0,"_source":{"name":"wangwu2","age":"20","sex":"女"}},{"_index":"user","_type":"_doc","_id":"1005","_score":1.0,"_source":{"name":"wangwu3","age":"50","sex":"男"}},{"_index":"user","_type":"_doc","_id":"1006","_score":1.0,"_source":{"name":"wangwu4","age":"20","sex":"男"}}]},"aggregations":{"lterms#age_groupby":{"doc_count_error_upper_bound":0,"sum_other_doc_count":0,"buckets":[{"key":20,"doc_count":2},{"key":10,"doc_count":1},{"key":30,"doc_count":1},{"key":40,"doc_count":1},{"key":50,"doc_count":1}]}}}
Process finished with exit code 0
第四章 Elasticsearch环境
29-环境-简介
单机 & 集群
单台 Elasticsearch 服务器提供服务,往往都有最大的负载能力,超过这个阈值,服务器
性能就会大大降低甚至不可用,所以生产环境中,一般都是运行在指定服务器集群中。
除了负载能力,单点服务器也存在其他问题:
- 单台机器存储容量有限
- 单服务器容易出现单点故障,无法实现高可用
- 单服务的并发处理能力有限
配置服务器集群时,集群中节点数量没有限制,大于等于 2 个节点就可以看做是集群了。一
般出于高性能及高可用方面来考虑集群中节点数量都是 3 个以上
总之,集群能提高性能,增加容错。
集群 Cluster
**一个集群就是由一个或多个服务器节点组织在一起,共同持有整个的数据,并一起提供索引和搜索功能。**一个 Elasticsearch 集群有一个唯一的名字标识,这个名字默认就是”elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。
节点 Node
集群中包含很多服务器, 一个节点就是其中的一个服务器。 作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于 Elasticsearch 集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运
行任何 Elasticsearch 节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的
集群。
30-环境-Windows集群部署
部署集群
一、创建 elasticsearch-cluster 文件夹
创建 elasticsearch-7.8.0-cluster 文件夹,在内部复制三个 elasticsearch 服务。
二、修改集群文件目录中每个节点的 config/elasticsearch.yml 配置文件
node-1001 节点
##节点 1 的配置信息:
##集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
##节点名称,集群内要唯一
node.name: node-1001
node.master: true
node.data: true
##ip 地址
network.host: localhost
##http 端口
http.port: 1001
##tcp 监听端口
transport.tcp.port: 9301
##discovery.seed_hosts: ["localhost:9301", "localhost:9302","localhost:9303"]
##discovery.zen.fd.ping_timeout: 1m
##discovery.zen.fd.ping_retries: 5
##集群内的可以被选为主节点的节点列表
##cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
##跨域配置
##action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
node-1002 节点
##节点 2 的配置信息:
##集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
##节点名称,集群内要唯一
node.name: node-1002
node.master: true
node.data: true
##ip 地址
network.host: localhost
##http 端口
http.port: 1002
##tcp 监听端口
transport.tcp.port: 9302
discovery.seed_hosts: ["localhost:9301"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
##集群内的可以被选为主节点的节点列表
##cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
##跨域配置
##action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
node-1003 节点
##节点 3 的配置信息:
##集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
##节点名称,集群内要唯一
node.name: node-1003
node.master: true
node.data: true
##ip 地址
network.host: localhost
##http 端口
http.port: 1003
##tcp 监听端口
transport.tcp.port: 9303
##候选主节点的地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["localhost:9301", "localhost:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
##集群内的可以被选为主节点的节点列表
##cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
##跨域配置
##action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
三、如果有必要,删除每个节点中的 data 目录中所有内容 。
启动集群
分别依次双击执行节点的bin/elasticsearch.bat, 启动节点服务器(可以编写一个脚本启动),启动后,会自动加入指定名称的集群。
测试集群
一、用Postman,查看集群状态
GET http://127.0.0.1:1001/_cluster/healthGET http://127.0.0.1:1002/_cluster/healthGET http://127.0.0.1:1003/_cluster/health
返回结果皆为如下:
{
"cluster_name": "my-application",
"status": "green",
"timed_out": false,
"number_of_nodes": 3,
"number_of_data_nodes": 3,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100.0
}
status字段指示着当前集群在总体上是否工作正常。它的三种颜色含义如下:
- green:所有的主分片和副本分片都正常运行。
- yellow:所有的主分片都正常运行,但不是所有的副本分片都正常运行。
- red:有主分片没能正常运行。
二、用Postman,在一节点增加索引,另一节点获取索引
向集群中的node-1001节点增加索引:
##PUT http://127.0.0.1:1001/user
返回结果:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "user"
}
向集群中的node-1003节点获取索引:
##GET http://127.0.0.1:1003/user
返回结果:
{
"user": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"creation_date": "1617993035885",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "XJKERwQlSJ6aUxZEN2EV0w",
"version": {
"created": "7080099"
},
"provided_name": "user"
}
}
}
}
如果在1003创建索引,同样在1001也能获取索引信息,这就是集群能力。
31-环境-Linux单节点部署
软件安装
一、下载软件
二、解压软件
## 解压缩
tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz -C /opt/module
## 改名
mv elasticsearch-7.8.0 es
三、创建用户
因为安全问题, Elasticsearch 不允许 root 用户直接运行,所以要创建新用户,在 root 用户中创建新用户。
useradd es #新增 es 用户
passwd es #为 es 用户设置密码
userdel -r es #如果错了,可以删除再加
chown -R es:es /opt/module/es #文件夹所有者
四、修改配置文件
修改/opt/module/es/config/elasticsearch.yml文件。
## 加入如下配置
cluster.name: elasticsearch
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"]
修改/etc/security/limits.conf
## 在文件末尾中增加下面内容
## 每个进程可以打开的文件数的限制
es soft nofile 65536
es hard nofile 65536
修改/etc/security/limits.d/20-nproc.conf
## 在文件末尾中增加下面内容
## 每个进程可以打开的文件数的限制
es soft nofile 65536
es hard nofile 65536
## 操作系统级别对每个用户创建的进程数的限制
* hard nproc 4096
## 注: * 带表 Linux 所有用户名称
修改/etc/sysctl.conf
## 在文件中增加下面内容
## 一个进程可以拥有的 VMA(虚拟内存区域)的数量,默认值为 65536
vm.max_map_count=655360
重新加载
sysctl -p
启动软件
使用 ES 用户启动
cd /opt/module/es/
##启动
bin/elasticsearch
##后台启动
bin/elasticsearch -d
启动时,会动态生成文件,如果文件所属用户不匹配,会发生错误,需要重新进行修改用户和用户组
关闭防火墙
##暂时关闭防火墙
systemctl stop firewalld
##永久关闭防火墙
systemctl enable firewalld.service #打开防火墙永久性生效,重启后不会复原
systemctl disable firewalld.service #关闭防火墙,永久性生效,重启后不会复原
测试软件
浏览器中输入地址: http://linux1:9200/

32-环境-Linux集群部署
软件安装
一、下载软件
二、解压软件
## 解压缩
tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz -C /opt/module
## 改名
mv elasticsearch-7.8.0 es-cluster
将软件分发到其他节点: linux2, linux3
三、创建用户
因为安全问题, Elasticsearch 不允许 root 用户直接运行,所以要创建新用户,在 root 用户中创建新用户。
useradd es #新增 es 用户
passwd es #为 es 用户设置密码
userdel -r es #如果错了,可以删除再加
chown -R es:es /opt/module/es #文件夹所有者
四、修改配置文件
修改/opt/module/es/config/elasticsearch.yml 文件,分发文件。
## 加入如下配置
##集群名称
cluster.name: cluster-es
##节点名称, 每个节点的名称不能重复
node.name: node-1
##ip 地址, 每个节点的地址不能重复
network.host: linux1
##是不是有资格主节点
node.master: true
node.data: true
http.port: 9200
## head 插件需要这打开这两个配置
http.cors.allow-origin: "*"
http.cors.enabled: true
http.max_content_length: 200mb
##es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master
cluster.initial_master_nodes: ["node-1"]
##es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["linux1:9300","linux2:9300","linux3:9300"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
##集群内同时启动的数据任务个数,默认是 2 个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
##添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个
cluster.routing.allocation.node_concurrent_recoveries: 16
##初始化数据恢复时,并发恢复线程的个数,默认 4 个
cluster.routing.allocation.node_initial_primaries_recoveries: 16
修改/etc/security/limits.conf ,分发文件
## 在文件末尾中增加下面内容
es soft nofile 65536
es hard nofile 65536
修改/etc/security/limits.d/20-nproc.conf,分发文件
## 在文件末尾中增加下面内容
es soft nofile 65536
es hard nofile 65536
* hard nproc 4096
## 注: * 带表 Linux 所有用户名称
修改/etc/sysctl.conf
## 在文件中增加下面内容
vm.max_map_count=655360
重新加载
sysctl -p
启动软件
分别在不同节点上启动 ES 软件
cd /opt/module/es-cluster
##启动
bin/elasticsearch
##后台启动
bin/elasticsearch -d
其他节点更改
node.name: node-1(启动es的名字)
network.host: linux1(当前虚拟机的地址)
测试集群

第4章 Elasticsearch进阶
33-进阶-核心概念
索引Index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除(CRUD)的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
能搜索的数据必须索引,这样的好处是可以提高查询速度,比如:新华字典前面的目录就是索引的意思,目录可以提高查询速度。
Elasticsearch 索引的精髓:一切设计都是为了提高搜索的性能。
类型Type
在一个索引中,你可以定义一种或多种类型。
一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具
有一组共同字段的文档定义一个类型。不同的版本,类型发生了不同的变化。
| 版本 | Type |
|---|---|
| 5.x | 支持多种 type |
| 6.x | 只能有一种 type |
| 7.x | 默认不再支持自定义索引类型(默认类型为: _doc) |
文档Document
一个文档是一个可被索引的基础信息单元,也就是一条数据。
比如:你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以 JSON(Javascript Object Notation)格式来表示,而 JSON 是一个到处存在的互联网数据交互格式。
在一个 index/type 里面,你可以存储任意多的文档。
字段Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识。
映射Mapping
mapping 是处理数据的方式和规则方面做一些限制,如:某个字段的数据类型、默认值、分析器、是否被索引等等。这些都是映射里面可以设置的,其它就是处理 ES 里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
分片Shards
一个索引可以存储超出单个节点硬件限制的大量数据。比如,一个具有 10 亿文档数据
的索引占据 1TB 的磁盘空间,而任一节点都可能没有这样大的磁盘空间。 或者单个节点处理搜索请求,响应太慢。为了解决这个问题,**Elasticsearch 提供了将索引划分成多份的能力,每一份就称之为分片。**当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片很重要,主要有两方面的原因:
- 允许你水平分割 / 扩展你的内容容量。
- 允许你在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合和搜索请求,是完全由 Elasticsearch 管理的,对于作为用户的你来说,这些都是透明的,无需过分关心。
被混淆的概念是,一个 Lucene 索引 我们在 Elasticsearch 称作 分片 。 一个Elasticsearch 索引 是分片的集合。 当 Elasticsearch 在索引中搜索的时候, 他发送查询到每一个属于索引的分片(Lucene 索引),然后合并每个分片的结果到一个全局的结果集。
Lucene 是 Apache 软件基金会 Jakarta 项目组的一个子项目,提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在 Java 开发环境里 Lucene 是一个成熟的免费开源工具。就其本身而言, Lucene 是当前以及最近几年最受欢迎的免费 Java 信息检索程序库。但 Lucene 只是一个提供全文搜索功能类库的核心工具包,而真正使用它还需要一个完善的服务框架搭建起来进行应用。
目前市面上流行的搜索引擎软件,主流的就两款: Elasticsearch 和 Solr,这两款都是基于 Lucene 搭建的,可以独立部署启动的搜索引擎服务软件。由于内核相同,所以两者除了服务器安装、部署、管理、集群以外,对于数据的操作 修改、添加、保存、查询等等都十分类似。
副本Replicas
在一个网络 / 云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于
离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的, Elasticsearch 允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片(副本)。
复制分片之所以重要,有两个主要原因:
- 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
- 扩展你的搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。
总之,每个索引可以被分成多个分片。一个索引也可以被复制 0 次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。
分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
默认情况下,Elasticsearch 中的每个索引被分片 1 个主分片和 1 个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有 1 个主分片和另外 1 个复制分片(1 个完全拷贝),这样的话每个索引总共就有 2 个分片, 我们需要根据索引需要确定分片个数。
分配Allocation
将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。这个过程是由 master 节点完成的。
34-进阶-系统架构-简介
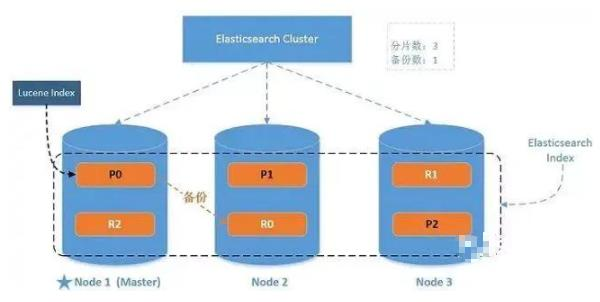
一个运行中的 Elasticsearch 实例称为一个节点,而集群是由一个或者多个拥有相同
cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
当一个节点被选举成为主节点时, 它将负责管理集群范围内的所有变更,例如增加、
删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。 任何节点都可以成为主节点。我们的示例集群就只有一个节点,所以它同时也成为了主节点。
作为用户,我们可以将请求发送到集群中的任何节点 ,包括主节点。 每个节点都知道
任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。
35-进阶-单节点集群
我们在包含一个空节点的集群内创建名为 users 的索引,为了演示目的,我们将分配 3个主分片和一份副本(每个主分片拥有一个副本分片)。
##PUT http://127.0.0.1:1001/users
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
集群现在是拥有一个索引的单节点集群。所有 3 个主分片都被分配在 node-1 。

通过 elasticsearch-head 插件(一个Chrome插件)查看集群情况 。
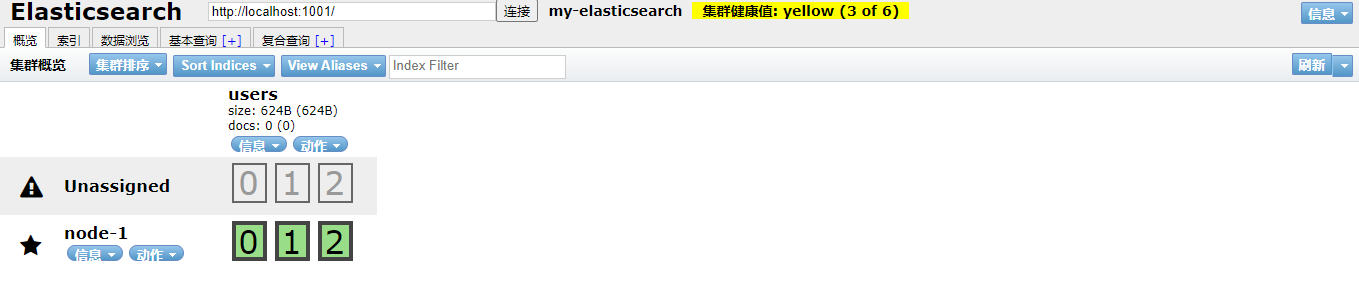
- 集群健康值:yellow( 3 of 6 ):表示当前集群的全部主分片都正常运行,但是副本分片没有全部处在正常状态。
 :3 个主分片正常。
:3 个主分片正常。 :3 个副本分片都是 Unassigned,它们都没有被分配到任何节点。 在同 一个节点上既保存原始数据又保存副本是没有意义的,因为一旦失去了那个节点,我们也将丢失该节点 上的所有副本数据。
:3 个副本分片都是 Unassigned,它们都没有被分配到任何节点。 在同 一个节点上既保存原始数据又保存副本是没有意义的,因为一旦失去了那个节点,我们也将丢失该节点 上的所有副本数据。
当前集群是正常运行的,但存在丢失数据的风险。
elasticsearch-head chrome插件安装
插件获取网址,下载压缩包,解压后将内容放入自定义命名为elasticsearch-head文件夹。
接着点击Chrome右上角选项->工具->管理扩展(或则地址栏输入chrome://extensions/),选择打开“开发者模式”,让后点击“加载已解压得扩展程序”,选择elasticsearch-head/_site,即可完成chrome插件安装。
36-进阶-故障转移
当集群中只有一个节点在运行时,意味着会有一个单点故障问题——没有冗余。 幸运的是,我们只需再启动一个节点即可防止数据丢失。当你在同一台机器上启动了第二个节点时,只要它和第一个节点有同样的 cluster.name 配置,它就会自动发现集群并加入到其中。但是在不同机器上启动节点的时候,为了加入到同一集群,你需要配置一个可连接到的单播主机列表。之所以配置为使用单播发现,以防止节点无意中加入集群。只有在同一台机器上
运行的节点才会自动组成集群。
如果启动了第二个节点,集群将会拥有两个节点 : 所有主分片和副本分片都已被分配 。
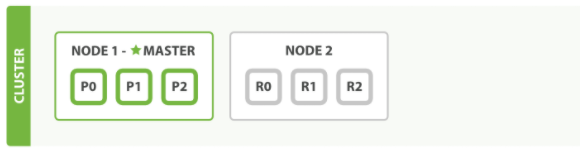
通过 elasticsearch-head 插件查看集群情况
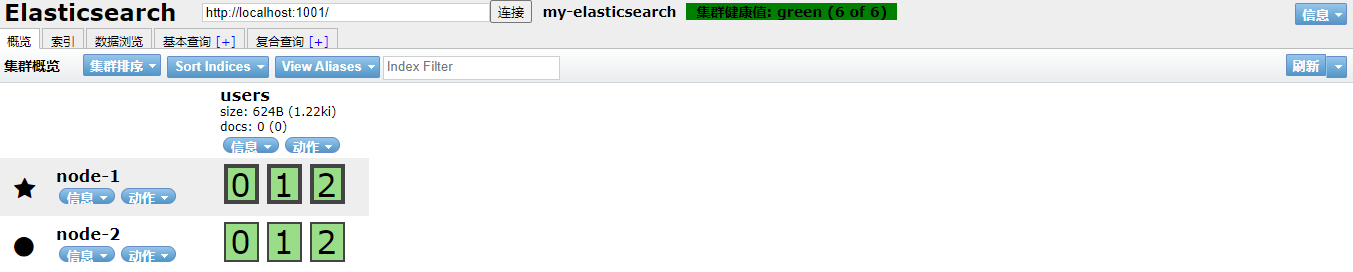
- 集群健康值:green( 3 of 6 ):表示所有 6 个分片(包括 3 个主分片和 3 个副本分片)都在正常运行。
 :3 个主分片正常。
:3 个主分片正常。- :第二个节点加入到集群后, 3 个副本分片将会分配到这个节点上——每 个主分片对应一个副本分片。这意味着当集群内任何一个节点出现问题时,我们的数据都完好无损。所 有新近被索引的文档都将会保存在主分片上,然后被并行的复制到对应的副本分片上。这就保证了我们 既可以从主分片又可以从副本分片上获得文档。
37-进阶-水平扩容
怎样为我们的正在增长中的应用程序按需扩容呢?当启动了第三个节点,我们的集群将会拥有三个节点的集群 : 为了分散负载而对分片进行重新分配 。
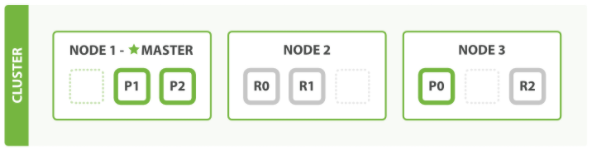
通过 elasticsearch-head 插件查看集群情况。
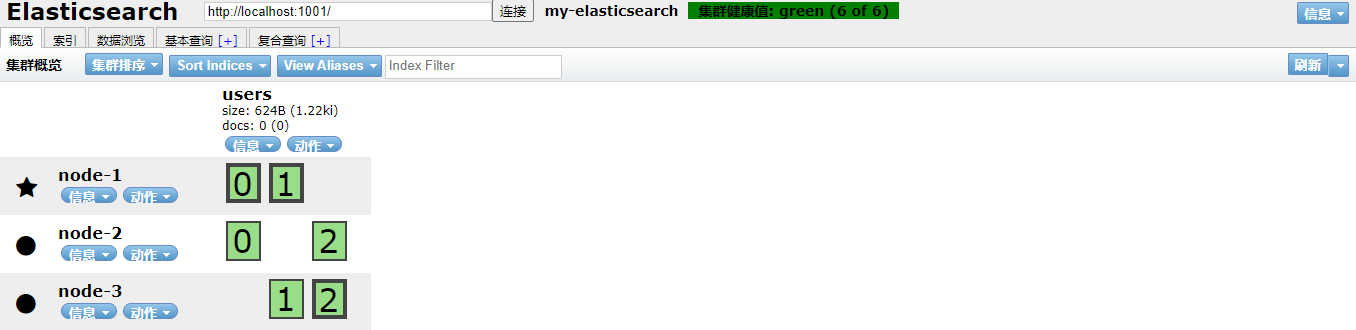
- 集群健康值:green( 3 of 6 ):表示所有 6 个分片(包括 3 个主分片和 3 个副本分片)都在正常运行。
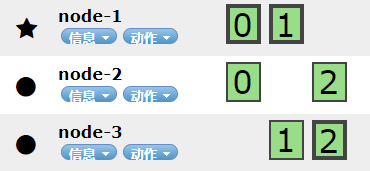 Node 1 和 Node 2 上各有一个分片被迁移到了新的 Node 3 节点,现在每个节点上都拥有 2 个分片, 而不是之前的 3 个。 这表示每个节点的硬件资源(CPU, RAM, I/O)将被更少的分片所共享,每个分片 的性能将会得到提升。
Node 1 和 Node 2 上各有一个分片被迁移到了新的 Node 3 节点,现在每个节点上都拥有 2 个分片, 而不是之前的 3 个。 这表示每个节点的硬件资源(CPU, RAM, I/O)将被更少的分片所共享,每个分片 的性能将会得到提升。
分片是一个功能完整的搜索引擎,它拥有使用一个节点上的所有资源的能力。 我们这个拥有 6 个分 片(3 个主分片和 3 个副本分片)的索引可以最大扩容到 6 个节点,每个节点上存在一个分片,并且每个 分片拥有所在节点的全部资源。
但是如果我们想要扩容超过 6 个节点怎么办呢?
主分片的数目在索引创建时就已经确定了下来。实际上,这个数目定义了这个索引能够
存储 的最大数据量。(实际大小取决于你的数据、硬件和使用场景。) 但是,读操作——
搜索和返回数据——可以同时被主分片 或 副本分片所处理,所以当你拥有越多的副本分片
时,也将拥有越高的吞吐量。
在运行中的集群上是可以动态调整副本分片数目的,我们可以按需伸缩集群。让我们把
副本数从默认的 1 增加到 2。
##PUT http://127.0.0.1:1001/users/_settings
{
"number_of_replicas" : 2
}
users 索引现在拥有 9 个分片: 3 个主分片和 6 个副本分片。 这意味着我们可以将集群
扩容到 9 个节点,每个节点上一个分片。相比原来 3 个节点时,集群搜索性能可以提升 3 倍。
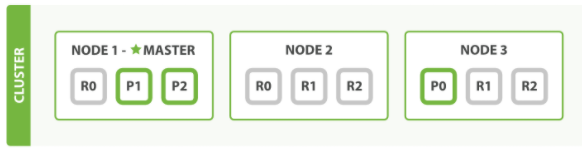
通过 elasticsearch-head 插件查看集群情况:
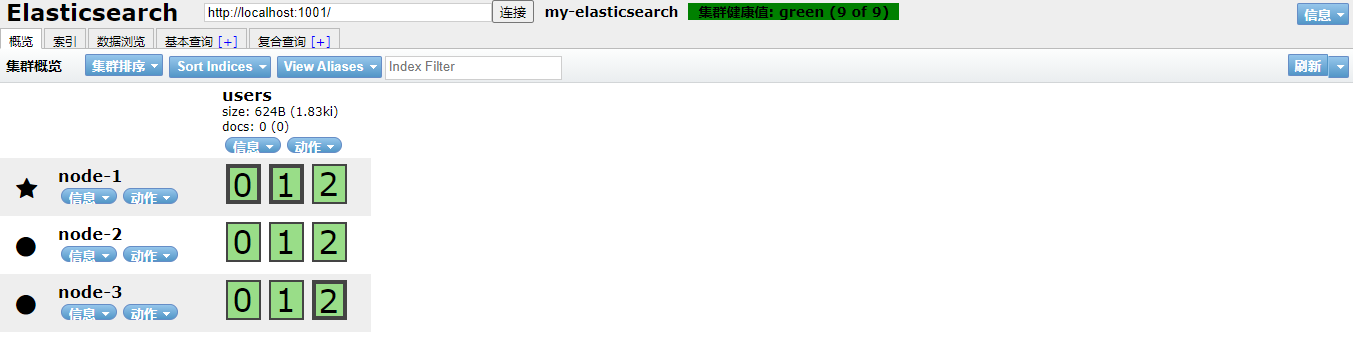
当然,如果只是在相同节点数目的集群上增加更多的副本分片并不能提高性能,因为每
个分片从节点上获得的资源会变少。 你需要增加更多的硬件资源来提升吞吐量。
但是更多的副本分片数提高了数据冗余量:按照上面的节点配置,我们可以在失去 2 个节点
的情况下不丢失任何数据。
38-进阶-应对故障
我们关闭第一个节点,这时集群的状态为:关闭了一个节点后的集群。
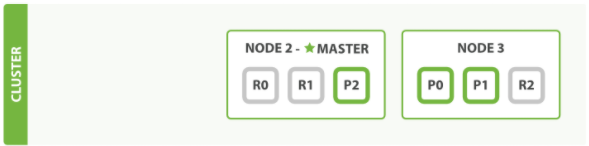
我们关闭的节点是一个主节点。而集群必须拥有一个主节点来保证正常工作,所以发生
的第一件事情就是选举一个新的主节点: Node 2 。在我们关闭 Node 1 的同时也失去了主
分片 1 和 2 ,并且在缺失主分片的时候索引也不能正常工作。 如果此时来检查集群的状况,我们看到的状态将会为 red :不是所有主分片都在正常工作。
幸运的是,在其它节点上存在着这两个主分片的完整副本, 所以新的主节点立即将这些分片在 Node 2 和 Node 3 上对应的副本分片提升为主分片, 此时集群的状态将会为yellow。这个提升主分片的过程是瞬间发生的,如同按下一个开关一般。
为什么我们集群状态是 yellow 而不是 green 呢?
虽然我们拥有所有的三个主分片,但是同时设置了每个主分片需要对应 2 份副本分片,而此
时只存在一份副本分片。 所以集群不能为 green 的状态,不过我们不必过于担心:如果我
们同样关闭了 Node 2 ,我们的程序 依然 可以保持在不丢任何数据的情况下运行,因为
Node 3 为每一个分片都保留着一份副本。
如果想回复原来的样子,要确保Node-1的配置文件有如下配置:
discovery.seed_hosts: ["localhost:9302", "localhost:9303"]
集群可以将缺失的副本分片再次进行分配,那么集群的状态也将恢复成之前的状态。 如果 Node 1 依然拥有着之前的分片,它将尝试去重用它们,同时仅从主分片复制发生了修改的数据文件。和之前的集群相比,只是 Master 节点切换了。

39-进阶-路由计算 & 分片控制
路由计算
当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个
文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 1 还是分片 2 中呢?首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
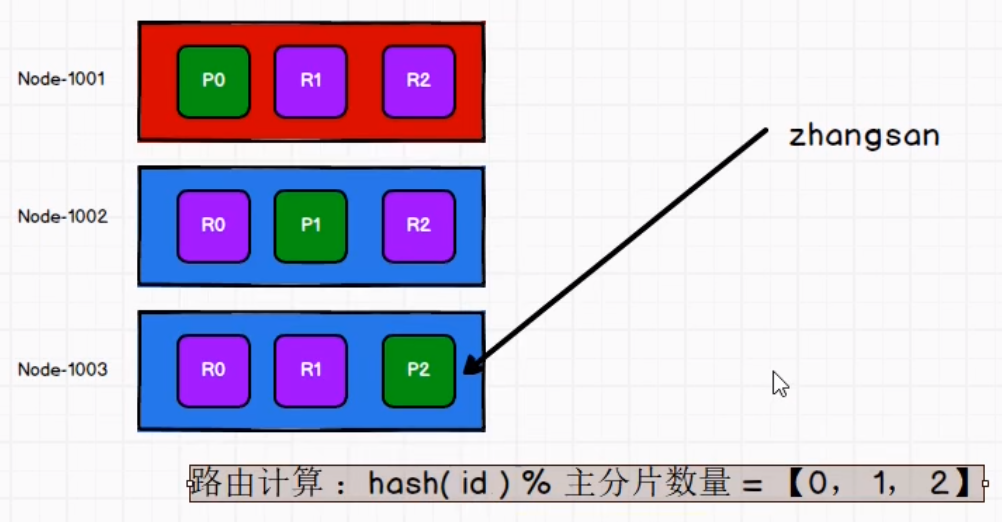
这就解释了为什么我们要在创建索引的时候就确定好主分片的数量并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
所有的文档API ( get . index . delete 、 bulk , update以及 mget )都接受一个叫做routing 的路由参数,通过这个参数我们可以自定义文档到分片的映射。一个自定义的路由参数可以用来确保所有相关的文档—一例如所有属于同一个用户的文档——都被存储到同一个分片中。
分片控制
我们可以发送请求到集群中的任一节点。每个节点都有能力处理任意请求。每个节点都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上。在下面的例子中,如果将所有的请求发送到Node 1001,我们将其称为协调节点coordinating node。
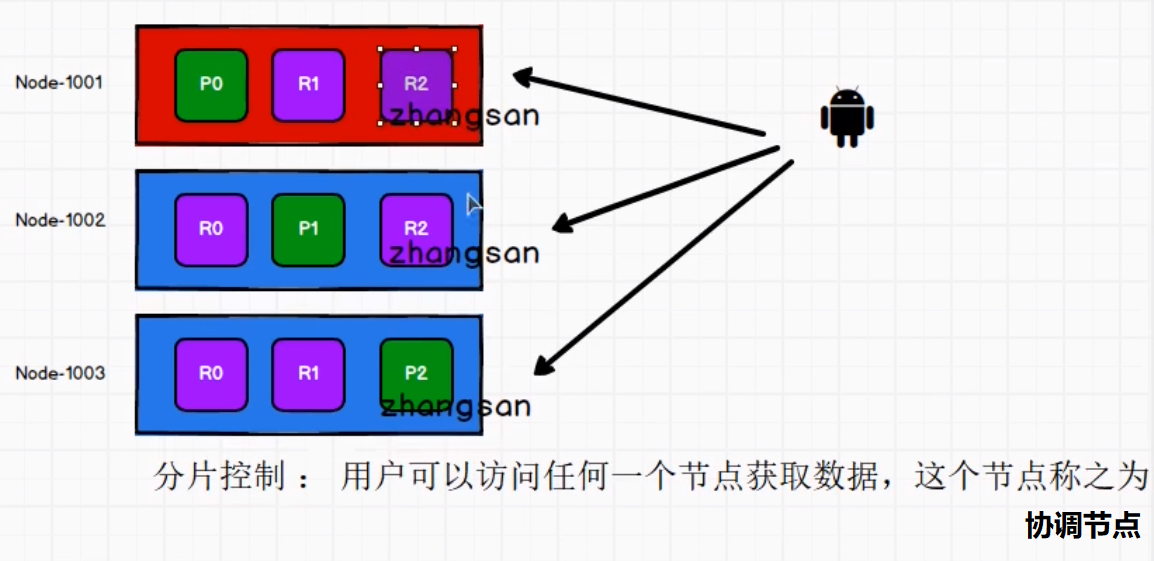
当发送请求的时候, 为了扩展负载,更好的做法是轮询集群中所有的节点。
40-进阶-数据写流程
新建、索引和删除请求都是写操作, 必须在主分片上面完成之后才能被复制到相关的副本分片。
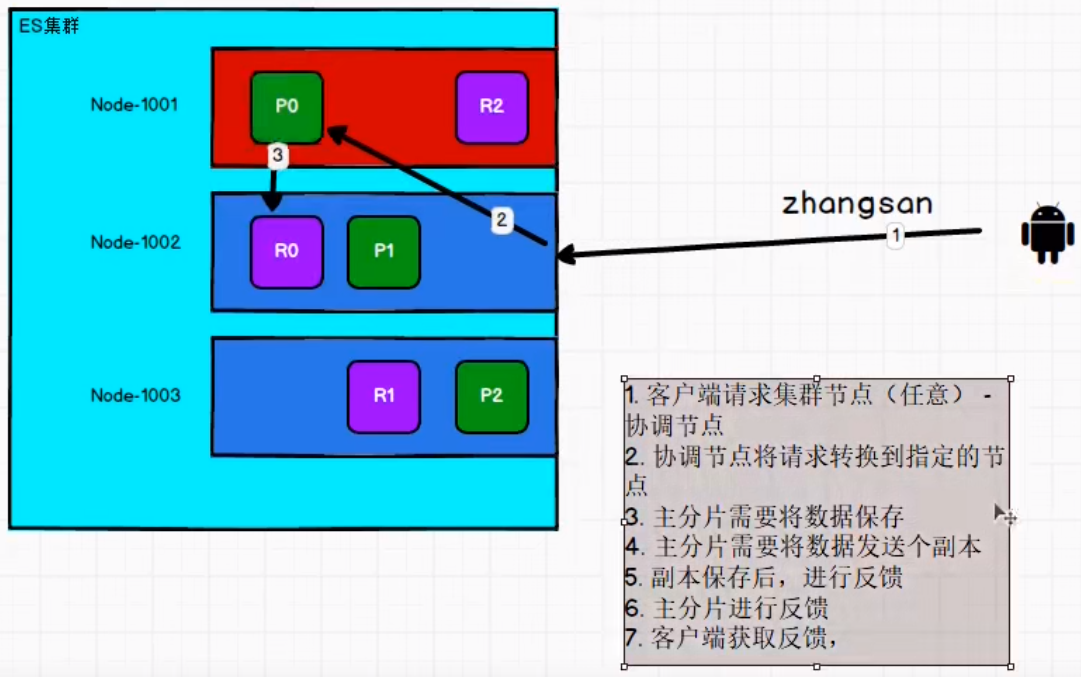
在客户端收到成功响应时,文档变更已经在主分片和所有副本分片执行完成,变更是安全的。有一些可选的请求参数允许您影响这个过程,可能以数据安全为代价提升性能。这些选项很少使用,因为 Elasticsearch 已经很快,但是为了完整起见, 请参考下文:
- consistency
- 即一致性。在默认设置下,即使仅仅是在试图执行一个写操作之前,主分片都会要求必须要有规定数量quorum(或者换种说法,也即必须要有大多数)的分片副本处于活跃可用状态,才会去执行写操作(其中分片副本 可以是主分片或者副本分片)。这是为了避免在发生网络分区故障(network partition)的时候进行写操作,进而导致数据不一致。 规定数量即: int((primary + number_of_replicas) / 2 ) + 1
- consistency 参数的值可以设为:
- one :只要主分片状态 ok 就允许执行写操作。
- all:必须要主分片和所有副本分片的状态没问题才允许执行写操作。
- quorum:默认值为quorum , 即大多数的分片副本状态没问题就允许执行写操作。
- 注意,规定数量的计算公式中number_of_replicas指的是在索引设置中的设定副本分片数,而不是指当前处理活动状态的副本分片数。如果你的索引设置中指定了当前索引拥有3个副本分片,那规定数量的计算结果即:int((1 primary + 3 replicas) / 2) + 1 = 3,如果此时你只启动两个节点,那么处于活跃状态的分片副本数量就达不到规定数量,也因此您将无法索引和删除任何文档。
- timeout
- 如果没有足够的副本分片会发生什么?Elasticsearch 会等待,希望更多的分片出现。默认情况下,它最多等待 1 分钟。 如果你需要,你可以使用timeout参数使它更早终止:100是100 毫秒,30s是30秒。
新索引默认有1个副本分片,这意味着为满足规定数量应该需要两个活动的分片副本。 但是,这些默认的设置会阻止我们在单一节点上做任何事情。为了避免这个问题,要求只有当number_of_replicas 大于1的时候,规定数量才会执行。
41-进阶-数据读流程
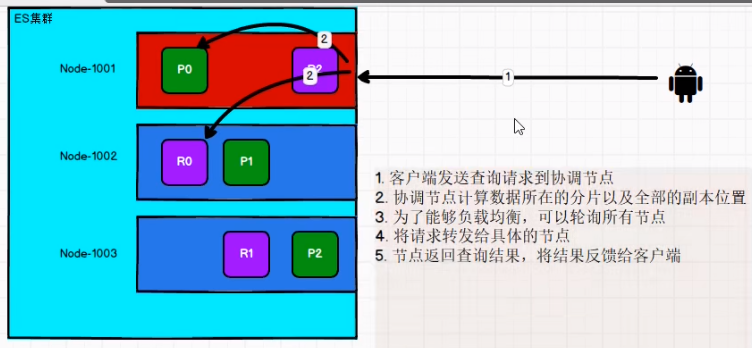
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。在文档被检索时,已经被索引的文档可能已经存在于主分片上但是还没有复制到副本分片。 在这种情况下,副本分片可能会报告文档不存在,但是主分片可能成功返回文档。 一旦索引请求成功返回给用户,文档在主分片和副本分片都是可用的。
42-进阶-更新流程 & 批量操作流程
更新流程
部分更新一个文档结合了先前说明的读取和写入流程:
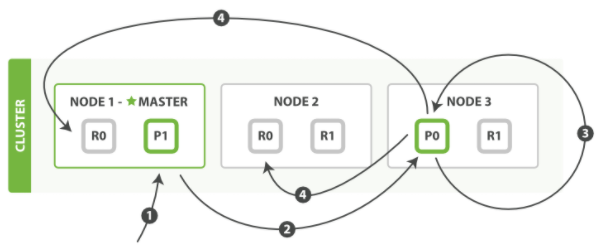
部分更新一个文档的步骤如下:
- 客户端向Node 1发送更新请求。
- 它将请求转发到主分片所在的Node 3 。
- Node 3从主分片检索文档,修改_source字段中的JSON,并且尝试重新索引主分片的文档。如果文档已经被另一个进程修改,它会重试步骤3 ,超过retry_on_conflict次后放弃。
- 如果 Node 3成功地更新文档,它将新版本的文档并行转发到Node 1和 Node 2上的副本分片,重新建立索引。一旦所有副本分片都返回成功,Node 3向协调节点也返回成功,协调节点向客户端返回成功。
当主分片把更改转发到副本分片时, 它不会转发更新请求。 相反,它转发完整文档的新版本。请记住,这些更改将会异步转发到副本分片,并且不能保证它们以发送它们相同的顺序到达。 如果 Elasticsearch 仅转发更改请求,则可能以错误的顺序应用更改,导致得到损坏的文档。
批量操作流程
**mget和 bulk API的模式类似于单文档模式。**区别在于协调节点知道每个文档存在于哪个分片中。它将整个多文档请求分解成每个分片的多文档请求,并且将这些请求并行转发到每个参与节点。
协调节点一旦收到来自每个节点的应答,就将每个节点的响应收集整理成单个响应,返回给客户端。
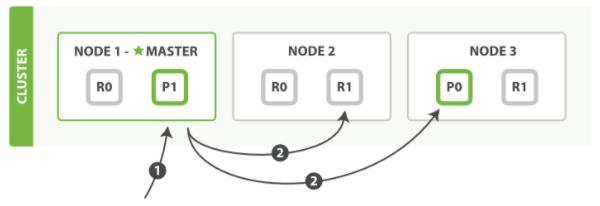
用单个 mget 请求取回多个文档所需的步骤顺序:
- 客户端向 Node 1 发送 mget 请求。
- Node 1为每个分片构建多文档获取请求,然后并行转发这些请求到托管在每个所需的主分片或者副本分片的节点上。一旦收到所有答复,Node 1 构建响应并将其返回给客户端。
可以对docs数组中每个文档设置routing参数。
bulk API, 允许在单个批量请求中执行多个创建、索引、删除和更新请求。
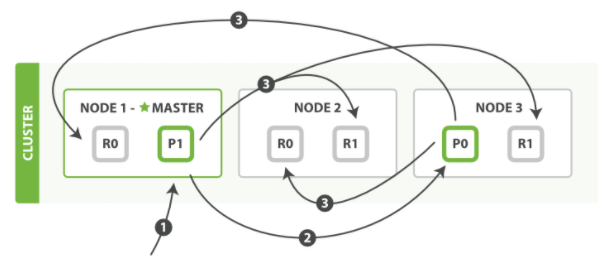
bulk API 按如下步骤顺序执行:
- 客户端向Node 1 发送 bulk请求。
- Node 1为每个节点创建一个批量请求,并将这些请求并行转发到每个包含主分片的节点主机。
- 主分片一个接一个按顺序执行每个操作。当每个操作成功时,主分片并行转发新文档(或删除)到副本分片,然后执行下一个操作。一旦所有的副本分片报告所有操作成功,该节点将向协调节点报告成功,协调节点将这些响应收集整理并返回给客户端。
43-进阶-倒排索引
分片是Elasticsearch最小的工作单元。但是究竟什么是一个分片,它是如何工作的?
传统的数据库每个字段存储单个值,但这对全文检索并不够。文本字段中的每个单词需要被搜索,对数据库意味着需要单个字段有索引多值的能力。最好的支持是一个字段多个值需求的数据结构是倒排索引。
倒排索引原理
Elasticsearch使用一种称为倒排索引的结构,它适用于快速的全文搜索。
见其名,知其意,有倒排索引,肯定会对应有正向索引。正向索引(forward index),反向索引(inverted index)更熟悉的名字是倒排索引。
所谓的正向索引,就是搜索引擎会将待搜索的文件都对应一个文件ID,搜索时将这个ID和搜索关键字进行对应,形成K-V对,然后对关键字进行统计计数。(统计??下文有解释)
但是互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
倒排索引的例子
一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。例如,假设我们有两个文档,每个文档的content域包含如下内容:
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
为了创建倒排索引,我们首先将每个文档的content域拆分成单独的词(我们称它为词条或tokens ),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。结果如下所示:

现在,如果我们想搜索 quick brown ,我们只需要查找包含每个词条的文档:

两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单相似性算法,那么我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
但是,我们目前的倒排索引有一些问题:
-
Quick和quick以独立的词条出现,然而用户可能认为它们是相同的词。 -
fox和foxes非常相似,就像dog和dogs;他们有相同的词根。 -
jumped和leap,尽管没有相同的词根,但他们的意思很相近。他们是同义词。
使用前面的索引搜索+Quick +fox不会得到任何匹配文档。(记住,+前缀表明这个词必须存在)。
只有同时出现Quick和fox 的文档才满足这个查询条件,但是第一个文档包含quick fox ,第二个文档包含Quick foxes 。
我们的用户可以合理的期望两个文档与查询匹配。我们可以做的更好。
如果我们将词条规范为标准模式,那么我们可以找到与用户搜索的词条不完全一致,但具有足够相关性的文档。例如:
Quick可以小写化为quick。foxes可以词干提取变为词根的格式为fox。类似的,dogs可以为提取为dog。jumped和leap是同义词,可以索引为相同的单词jump。
现在索引看上去像这样:

这还远远不够。我们搜索+Quick +fox 仍然会失败,因为在我们的索引中,已经没有Quick了。但是,如果我们对搜索的字符串使用与content域相同的标准化规则,会变成查询+quick +fox,这样两个文档都会匹配!分词和标准化的过程称为分析,这非常重要。你只能搜索在索引中出现的词条,所以索引文本和查询字符串必须标准化为相同的格式。
44-进阶-文档搜索
不可改变的倒排索引
早期的全文检索会为整个文档集合建立一个很大的倒排索引并将其写入到磁盘。 一旦新的索引就绪,旧的就会被其替换,这样最近的变化便可以被检索到。
倒排索引被写入磁盘后是不可改变的:它永远不会修改。
-
不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
-
一旦索引被读入内核的文件系统缓存,便会留在哪里,由于其不变性。只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升。
-
其它缓存(像filter缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为数据不会变化。
-
写入单个大的倒排索引允许数据被压缩,减少磁盘IO和需要被缓存到内存的索引的使用量。
当然,一个不变的索引也有不好的地方。主要事实是它是不可变的! 你不能修改它。如果你需要让一个新的文档可被搜索,你需要重建整个索引。这要么对一个索引所能包含的数据量造成了很大的限制,要么对索引可被更新的频率造成了很大的限制。
动态更新索引
如何在保留不变性的前提下实现倒排索引的更新?
答案是:用更多的索引。通过增加新的补充索引来反映新近的修改,而不是直接重写整个倒排索引。每一个倒排索引都会被轮流查询到,从最早的开始查询完后再对结果进行合并。
Elasticsearch基于Lucene,这个java库引入了按段搜索的概念。每一段本身都是一个倒排索引,但索引在 Lucene 中除表示所有段的集合外,还增加了提交点的概念—一个列出了所有已知段的文件。
按段搜索会以如下流程执行:
一、新文档被收集到内存索引缓存。
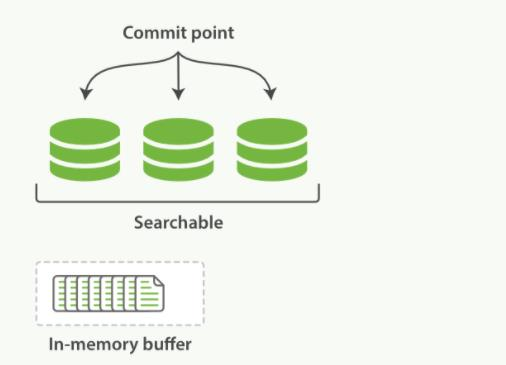
二、不时地, 缓存被提交。
- 一个新的段,一个追加的倒排索引,被写入磁盘。
- 一个新的包含新段名字的提交点被写入磁盘。
- 磁盘进行同步,所有在文件系统缓存中等待的写入都刷新到磁盘,以确保它们被写入物理文件
三、新的段被开启,让它包含的文档可见以被搜索。
四、内存缓存被清空,等待接收新的文档。
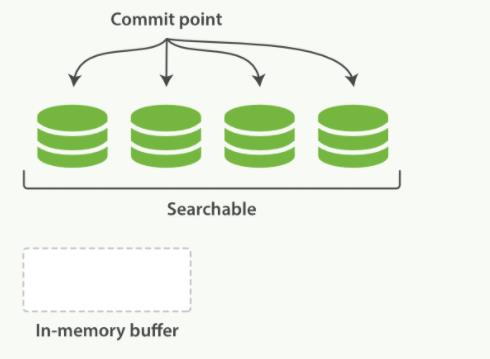
当一个查询被触发,所有已知的段按顺序被查询。词项统计会对所有段的结果进行聚合,以保证每个词和每个文档的关联都被准确计算。这种方式可以用相对较低的成本将新文档添加到索引。
段是不可改变的,所以既不能从把文档从旧的段中移除,也不能修改旧的段来进行反映文档的更新。取而代之的是,每个提交点会包含一个.del 文件,文件中会列出这些被删除文档的段信息。
当一个**文档被“删除”**时,它实际上只是在 .del 文件中被标记删除。一个被标记删除的文档仍然可以被查询匹配到,但它会在最终结果被返回前从结果集中移除。
文档更新也是类似的操作方式:当一个文档被更新时,旧版本文档被标记删除,文档的新版本被索引到一个新的段中。可能两个版本的文档都会被一个查询匹配到,但被删除的那个旧版本文档在结果集返回前就已经被移除。
45-进阶-文档刷新 & 文档刷写 & 文档合并
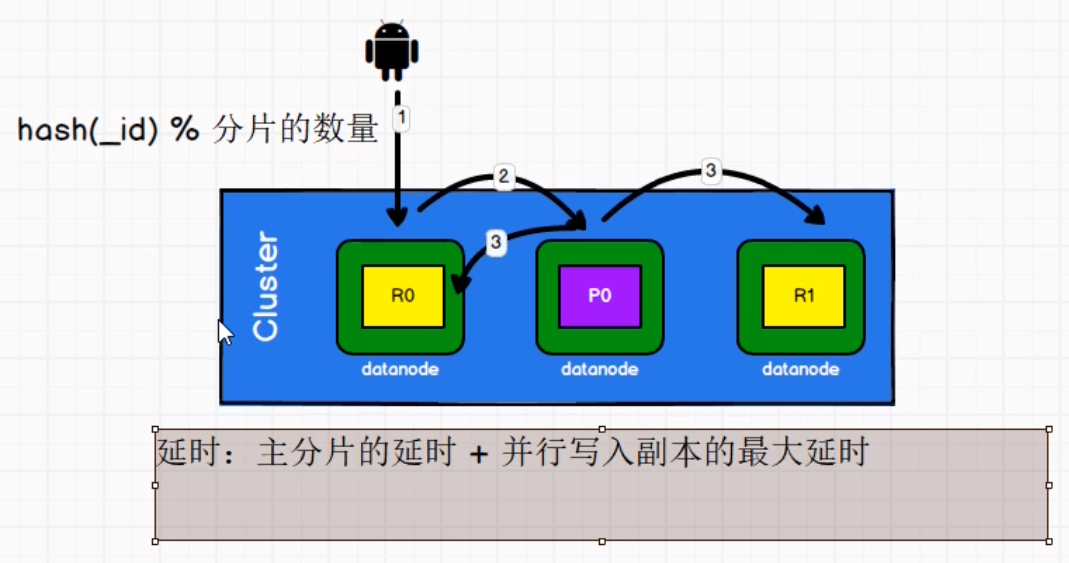
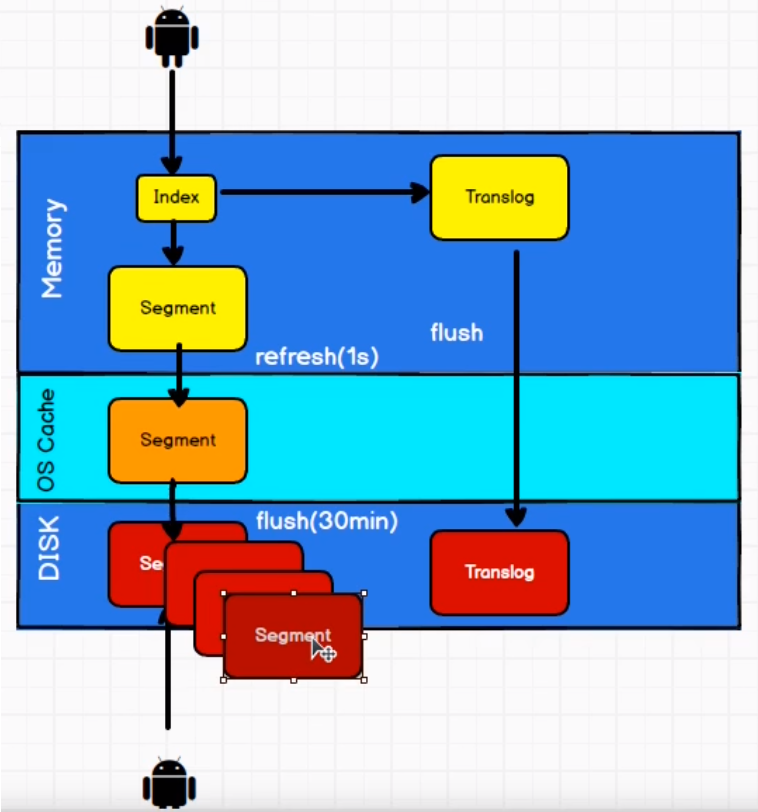
近实时搜索
随着按段(per-segment)搜索的发展,一个新的文档从索引到可被搜索的延迟显著降低了。新文档在几分钟之内即可被检索,但这样还是不够快。磁盘在这里成为了瓶颈。提交(Commiting)一个新的段到磁盘需要一个fsync来确保段被物理性地写入磁盘,这样在断电的时候就不会丢失数据。但是fsync操作代价很大;如果每次索引一个文档都去执行一次的话会造成很大的性能问题。
我们需要的是一个更轻量的方式来使一个文档可被搜索,这意味着fsync要从整个过程中被移除。在Elasticsearch和磁盘之间是文件系统缓存。像之前描述的一样,在内存索引缓冲区中的文档会被写入到一个新的段中。但是这里新段会被先写入到文件系统缓存—这一步代价会比较低,稍后再被刷新到磁盘—这一步代价比较高。不过只要文件已经在缓存中,就可以像其它文件一样被打开和读取了。
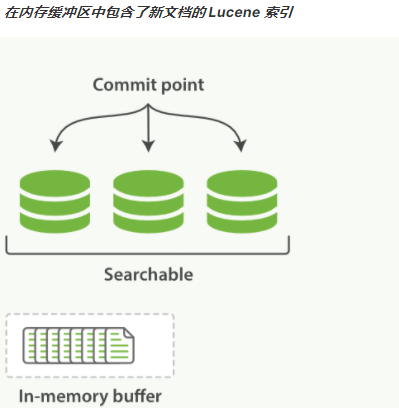
Lucene允许新段被写入和打开,使其包含的文档在未进行一次完整提交时便对搜索可见。这种方式比进行一次提交代价要小得多,并且在不影响性能的前提下可以被频繁地执行。
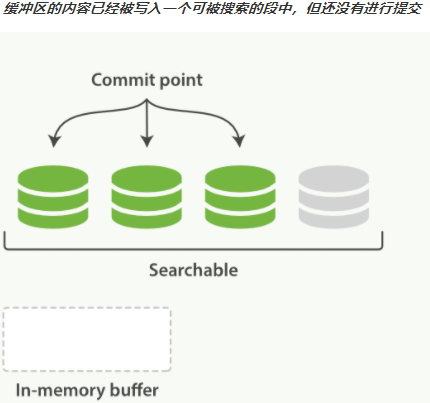
在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做refresh。默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch是近实时搜索:文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
这些行为可能会对新用户造成困惑:他们索引了一个文档然后尝试搜索它,但却没有搜到。这个问题的解决办法是用refresh API执行一次手动刷新:/usersl_refresh
尽管刷新是比提交轻量很多的操作,它还是会有性能开销。当写测试的时候,手动刷新很有用,但是不要在生产环境下每次索引一个文档都去手动刷新。相反,你的应用需要意识到Elasticsearch 的近实时的性质,并接受它的不足。
并不是所有的情况都需要每秒刷新。可能你正在使用Elasticsearch索引大量的日志文件,你可能想优化索引速度而不是近实时搜索,可以通过设置refresh_interval ,降低每个索引的刷新频率
{
"settings": {
"refresh_interval": "30s"
}
}
refresh_interval可以在既存索引上进行动态更新。在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来。
## 关闭自动刷新
PUT /users/_settings
{ "refresh_interval": -1 }
## 每一秒刷新
PUT /users/_settings
{ "refresh_interval": "1s" }
持久化变更
如果没有用fsync把数据从文件系统缓存刷(flush)到硬盘,我们不能保证数据在断电甚至是程序正常退出之后依然存在。为了保证Elasticsearch 的可靠性,需要确保数据变化被持久化到磁盘。在动态更新索引,我们说一次完整的提交会将段刷到磁盘,并写入一个包含所有段列表的提交点。Elasticsearch 在启动或重新打开一个索引的过程中使用这个提交点来判断哪些段隶属于当前分片。
即使通过每秒刷新(refresh)实现了近实时搜索,我们仍然需要经常进行完整提交来确保能从失败中恢复。但在两次提交之间发生变化的文档怎么办?我们也不希望丢失掉这些数据。Elasticsearch 增加了一个translog ,或者叫事务日志,在每一次对Elasticsearch进行操作时均进行了日志记录。
整个流程如下:
一、一个文档被索引之后,就会被添加到内存缓冲区,并且追加到了 translog
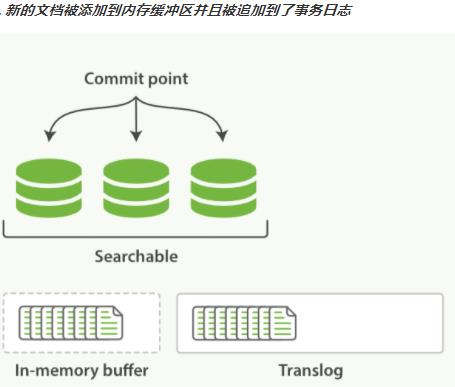
二、刷新(refresh)使分片每秒被刷新(refresh)一次:
- 这些在内存缓冲区的文档被写入到一个新的段中,且没有进行fsync操作。
- 这个段被打开,使其可被搜索。
- 内存缓冲区被清空。
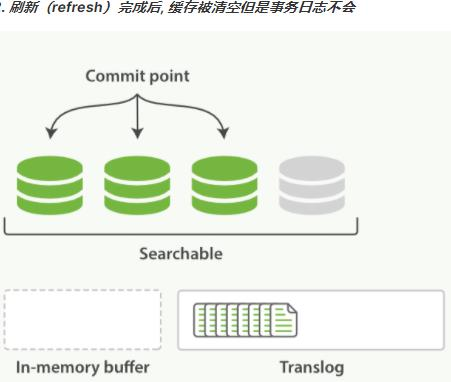
三、这个进程继续工作,更多的文档被添加到内存缓冲区和追加到事务日志。
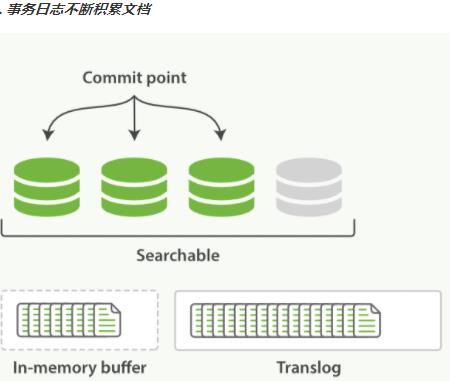
四、每隔一段时间—例如translog变得越来越大,索引被刷新(flush);一个新的translog被创建,并且一个全量提交被执行。
-
所有在内存缓冲区的文档都被写入一个新的段。
-
缓冲区被清空。
-
一个提交点被写入硬盘。
-
文件系统缓存通过fsync被刷新(flush) 。
-
老的translog被删除。
translog 提供所有还没有被刷到磁盘的操作的一个持久化纪录。当Elasticsearch启动的时候,它会从磁盘中使用最后一个提交点去恢复己知的段,并且会重放translog 中所有在最后一次提交后发生的变更操作。
translog 也被用来提供实时CRUD。当你试着通过ID查询、更新、删除一个文档,它会在尝试从相应的段中检索之前,首先检查 translog任何最近的变更。这意味着它总是能够实时地获取到文档的最新版本。
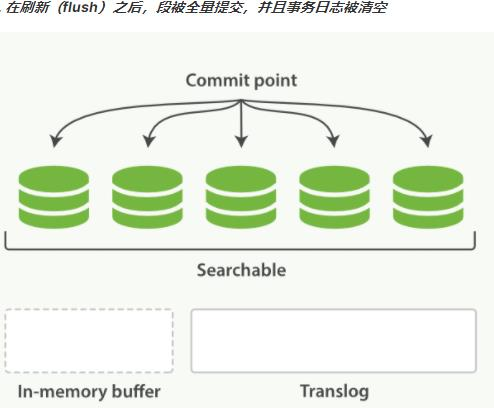
执行一个提交并且截断translog 的行为在 Elasticsearch被称作一次flush。分片每30分钟被自动刷新(flush),或者在 translog 太大的时候也会刷新。
你很少需要自己手动执行flush操作,通常情况下,自动刷新就足够了。这就是说,在重启节点或关闭索引之前执行 flush有益于你的索引。当Elasticsearch尝试恢复或重新打开一个索引,它需要重放translog中所有的操作,所以如果日志越短,恢复越快。
translog 的目的是保证操作不会丢失,在文件被fsync到磁盘前,被写入的文件在重启之后就会丢失。默认translog是每5秒被fsync刷新到硬盘,或者在每次写请求完成之后执行(e.g. index, delete, update, bulk)。这个过程在主分片和复制分片都会发生。最终,基本上,这意味着在整个请求被fsync到主分片和复制分片的translog之前,你的客户端不会得到一个200 OK响应。
在每次请求后都执行一个fsync会带来一些性能损失,尽管实践表明这种损失相对较小(特别是 bulk 导入,它在一次请求中平摊了大量文档的开销)。
但是对于一些大容量的偶尔丢失几秒数据问题也并不严重的集群,使用异步的 fsync还是比较有益的。比如,写入的数据被缓存到内存中,再每5秒执行一次 fsync 。如果你决定使用异步translog 的话,你需要保证在发生 crash 时,丢失掉 sync_interval时间段的数据也无所谓。请在决定前知晓这个特性。如果你不确定这个行为的后果,最好是使用默认的参数{“index.translog.durability”: “request”}来避免数据丢失。
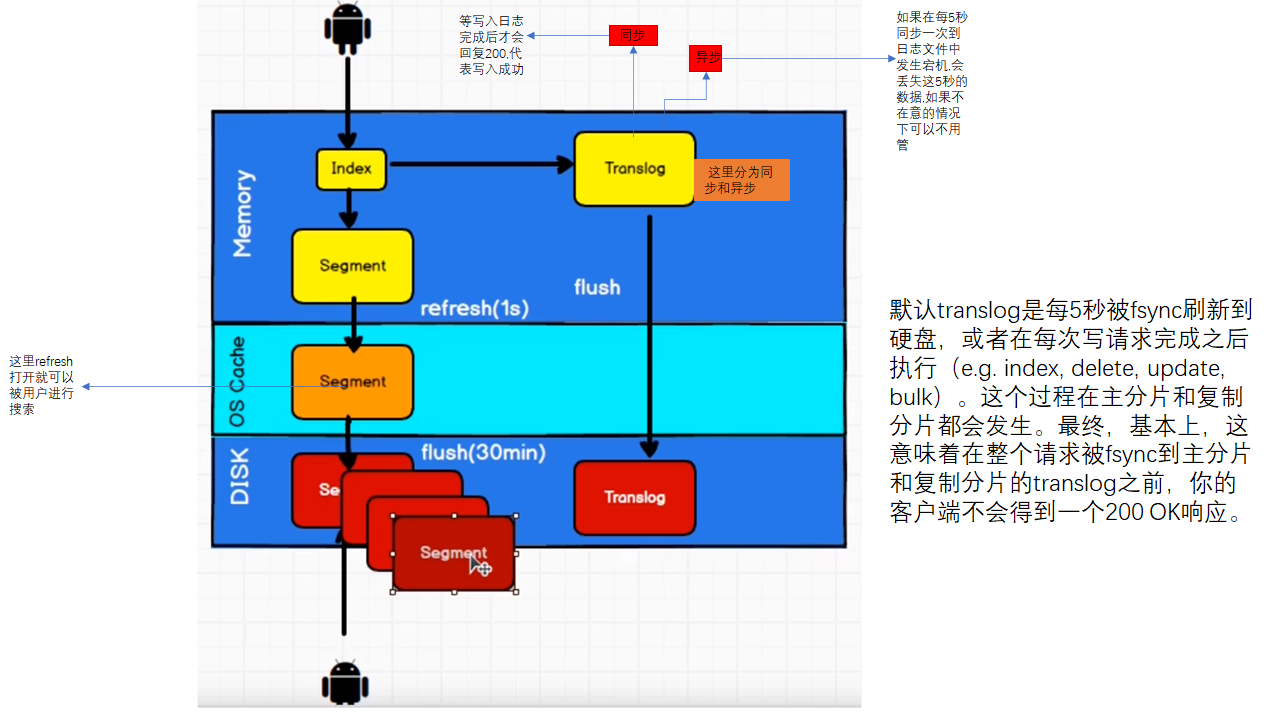
段合并
由于自动刷新流程每秒会创建一个新的段,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。每一个段都会消耗文件句柄、内存和 cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
Elasticsearch通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。
段合并的时候会将那些旧的已删除文档从文件系统中清除。被删除的文档(或被更新文档的旧版本)不会被拷贝到新的大段中。
启动段合并不需要你做任何事。进行索引和搜索时会自动进行。
一、当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用。
二、合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中。这并不会中断索引和搜索。
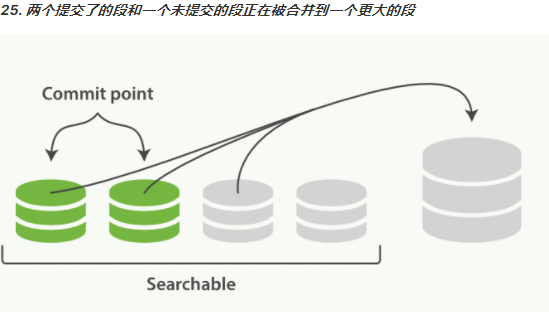
三、一旦合并结束,老的段被删除
- 新的段被刷新(flush)到了磁盘。
- 写入一个包含新段且排除旧的和较小的段的新提交点。
- 新的段被打开用来搜索。老的段被删除。
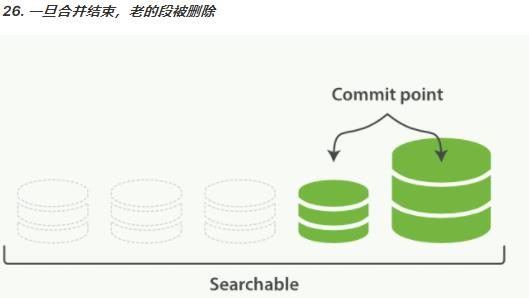
合并大的段需要消耗大量的 I/O 和 CPU 资源,如果任其发展会影响搜索性能。 Elasticsearch在默认情况下会对合并流程进行资源限制,所以搜索仍然有足够的资源很好地执行。
46-进阶-文档分析
分析包含下面的过程:
- 将一块文本分成适合于倒排索引的独立的词条。
- 将这些词条统一化为标准格式以提高它们的“可搜索性”,或者recall。
分析器执行上面的工作。分析器实际上是将三个功能封装到了一个包里:
- 字符过滤器:首先,字符串按顺序通过每个 字符过滤器 。他们的任务是在分词前整理字符串。一个字符过滤器可以用来去掉 HTML,或者将 & 转化成 and。
- 分词器:其次,字符串被分词器分为单个的词条。一个简单的分词器遇到空格和标点的时候,可能会将文本拆分成词条。
- Token 过滤器:最后,词条按顺序通过每个 token 过滤器 。这个过程可能会改变词条(例如,小写化Quick ),删除词条(例如, 像 a, and, the 等无用词),或者增加词条(例如,像jump和leap这种同义词)
内置分析器
Elasticsearch还附带了可以直接使用的预包装的分析器。接下来我们会列出最重要的分析器。为了证明它们的差异,我们看看每个分析器会从下面的字符串得到哪些词条:
"Set the shape to semi-transparent by calling set_trans(5)"
- 标准分析器
标准分析器是Elasticsearch 默认使用的分析器。它是分析各种语言文本最常用的选择。它根据Unicode 联盟定义的单词边界划分文本。删除绝大部分标点。最后,将词条小写。它会产生:
set, the, shape, to, semi, transparent, by, calling, set_trans, 5
- 简单分析器
简单分析器在任何不是字母的地方分隔文本,将词条小写。它会产生:
set, the, shape, to, semi, transparent, by, calling, set, trans
- 空格分析器
空格分析器在空格的地方划分文本。它会产生:
Set, the, shape, to, semi-transparent, by, calling, set_trans(5)
- 语言分析器
特定语言分析器可用于很多语言。它们可以考虑指定语言的特点。例如,英语分析器附带了一组英语无用词(常用单词,例如and或者the ,它们对相关性没有多少影响),它们会被删除。由于理解英语语法的规则,这个分词器可以提取英语单词的词干。
英语分词器会产生下面的词条:
set, shape, semi, transpar, call, set_tran, 5
注意看transparent、calling和 set_trans已经变为词根格式。
分析器使用场景
当我们索引一个文档,它的全文域被分析成词条以用来创建倒排索引。但是,当我们在全文域搜索的时候,我们需要将查询字符串通过相同的分析过程,以保证我们搜索的词条格式与索引中的词条格式一致。
全文查询,理解每个域是如何定义的,因此它们可以做正确的事:
-
当你查询一个全文域时,会对查询字符串应用相同的分析器,以产生正确的搜索词条列表。
-
当你查询一个精确值域时,不会分析查询字符串,而是搜索你指定的精确值。
测试分析器
有些时候很难理解分词的过程和实际被存储到索引中的词条,特别是你刚接触Elasticsearch。为了理解发生了什么,你可以使用analyze API来看文本是如何被分析的。在消息体里,指定分析器和要分析的文本。
##GET http://localhost:9200/_analyze
{
"analyzer": "standard",
"text": "Text to analyze"
}
结果中每个元素代表一个单独的词条:
{
"tokens": [
{
"token": "text",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "to",
"start_offset": 5,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "analyze",
"start_offset": 8,
"end_offset": 15,
"type": "<ALPHANUM>",
"position": 3
}
]
}
- token是实际存储到索引中的词条。
- start_ offset 和end_ offset指明字符在原始字符串中的位置。
- position指明词条在原始文本中出现的位置。
指定分析器
当Elasticsearch在你的文档中检测到一个新的字符串域,它会自动设置其为一个全文字符串域,使用 标准 分析器对它进行分析。你不希望总是这样。可能你想使用一个不同的分析器,适用于你的数据使用的语言。有时候你想要一个字符串域就是一个字符串域,不使用分析,直接索引你传入的精确值,例如用户 ID 或者一个内部的状态域或标签。要做到这一点,我们必须手动指定这些域的映射。
(细粒度指定分析器)
IK分词器
首先通过 Postman 发送 GET 请求查询分词效果
## GET http://localhost:9200/_analyze
{
"text":"测试单词"
}
ES 的默认分词器无法识别中文中测试、 单词这样的词汇,而是简单的将每个字拆完分为一个词。
{
"tokens": [
{
"token": "测",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "试",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "单",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "词",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
}
]
}
这样的结果显然不符合我们的使用要求,所以我们需要下载 ES 对应版本的中文分词器。
将解压后的后的文件夹放入 ES 根目录下的 plugins 目录下,重启 ES 即可使用。
我们这次加入新的查询参数"analyzer”:“ik_max_word”。
## GET http://localhost:9200/_analyze
{
"text":"测试单词",
"analyzer":"ik_max_word"
}
- ik_max_word:会将文本做最细粒度的拆分。
- ik_smart:会将文本做最粗粒度的拆分。
使用中文分词后的结果为:
{
"tokens": [
{
"token": "测试",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "单词",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
}
]
}
ES 中也可以进行扩展词汇,首先查询
##GET http://localhost:9200/_analyze
{
"text":"弗雷尔卓德",
"analyzer":"ik_max_word"
}
仅仅可以得到每个字的分词结果,我们需要做的就是使分词器识别到弗雷尔卓德也是一个词语。
{
"tokens": [
{
"token": "弗",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "雷",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "尔",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 2
},
{
"token": "卓",
"start_offset": 3,
"end_offset": 4,
"type": "CN_CHAR",
"position": 3
},
{
"token": "德",
"start_offset": 4,
"end_offset": 5,
"type": "CN_CHAR",
"position": 4
}
]
}
-
首先进入 ES 根目录中的 plugins 文件夹下的 ik 文件夹,进入 config 目录,创建 custom.dic文件,写入“弗雷尔卓德”。 -
同时打开 IKAnalyzer.cfg.xml 文件,将新建的 custom.dic 配置其中。 -
重启 ES 服务器 。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
扩展后再次查询
## GET http://localhost:9200/_analyze
{
"text":"测试单词",
"analyzer":"ik_max_word"
}
返回结果如下:
{
"tokens": [
{
"token": "弗雷尔卓德",
"start_offset": 0,
"end_offset": 5,
"type": "CN_WORD",
"position": 0
}
]
}
自定义分析器
虽然Elasticsearch带有一些现成的分析器,然而在分析器上Elasticsearch真正的强大之处在于,你可以通过在一个适合你的特定数据的设置之中组合字符过滤器、分词器、词汇单元过滤器来创建自定义的分析器。在分析与分析器我们说过,一个分析器就是在一个包里面组合了三种函数的一个包装器,三种函数按照顺序被执行:
字符过滤器
字符过滤器用来整理一个尚未被分词的字符串。例如,如果我们的文本是HTML格式的,它会包含像<p>或者<div>这样的HTML标签,这些标签是我们不想索引的。我们可以使用html清除字符过滤器来移除掉所有的HTML标签,并且像把Á转换为相对应的Unicode字符? 这样,转换HTML实体。一个分析器可能有0个或者多个字符过滤器。
分词器
一个分析器必须有一个唯一的分词器。分词器把字符串分解成单个词条或者词汇单元。标准分析器里使用的标准分词器把一个字符串根据单词边界分解成单个词条,并且移除掉大部分的标点符号,然而还有其他不同行为的分词器存在。
例如,关键词分词器完整地输出接收到的同样的字符串,并不做任何分词。空格分词器只根据空格分割文本。正则分词器根据匹配正则表达式来分割文本。
词单元过滤器
经过分词,作为结果的词单元流会按照指定的顺序通过指定的词单元过滤器。词单元过滤器可以修改、添加或者移除词单元。我们已经提到过lowercase和stop词过滤器,但是在Elasticsearch 里面还有很多可供选择的词单元过滤器。词干过滤器把单词遏制为词干。ascii_folding过滤器移除变音符,把一个像"très”这样的词转换为“tres”。
ngram和 edge_ngram词单元过滤器可以产生适合用于部分匹配或者自动补全的词单元。
自定义分析器例子
接下来,我们看看如何创建自定义的分析器:
##PUT http://localhost:9200/my_index
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": [
"&=> and "
]
}
},
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": [
"the",
"a"
]
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [
"html_strip",
"&_to_and"
],
"tokenizer": "standard",
"filter": [
"lowercase",
"my_stopwords"
]
}
}
}
}
}
索引被创建以后,使用 analyze API 来 测试这个新的分析器:
## GET http://127.0.0.1:9200/my_index/_analyze
{
"text":"The quick & brown fox",
"analyzer": "my_analyzer"
}
返回结果为:
{
"tokens": [
{
"token": "quick",
"start_offset": 4,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "and",
"start_offset": 10,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "brown",
"start_offset": 12,
"end_offset": 17,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "fox",
"start_offset": 18,
"end_offset": 21,
"type": "<ALPHANUM>",
"position": 4
}
]
}
47-进阶-文档控制
文档冲突
当我们使用index API更新文档,可以一次性读取原始文档,做我们的修改,然后重新索引整个文档。最近的索引请求将获胜:无论最后哪一个文档被索引,都将被唯一存储在 Elasticsearch 中。如果其他人同时更改这个文档,他们的更改将丢失。
很多时候这是没有问题的。也许我们的主数据存储是一个关系型数据库,我们只是将数据复制到Elasticsearch中并使其可被搜索。也许两个人同时更改相同的文档的几率很小。或者对于我们的业务来说偶尔丢失更改并不是很严重的问题。
但有时丢失了一个变更就是非常严重的。试想我们使用Elasticsearch 存储我们网上商城商品库存的数量,每次我们卖一个商品的时候,我们在 Elasticsearch 中将库存数量减少。有一天,管理层决定做一次促销。突然地,我们一秒要卖好几个商品。假设有两个web程序并行运行,每一个都同时处理所有商品的销售。
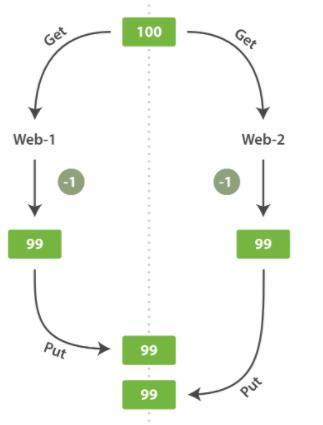
web_1 对stock_count所做的更改已经丢失,因为 web_2不知道它的 stock_count的拷贝已经过期。结果我们会认为有超过商品的实际数量的库存,因为卖给顾客的库存商品并不存在,我们将让他们非常失望。
变更越频繁,读数据和更新数据的间隙越长,也就越可能丢失变更。在数据库领域中,有两种方法通常被用来确保并发更新时变更不会丢失:
- 悲观并发控制:这种方法被关系型数据库广泛使用,它假定有变更冲突可能发生,因此阻塞访问资源以防止冲突。一个典型的例子是读取一行数据之前先将其锁住,确保只有放置锁的线程能够对这行数据进行修改。
- 乐观并发控制:Elasticsearch 中使用的这种方法假定冲突是不可能发生的,并且不会阻塞正在尝试的操作。然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何解决冲突。例如,可以重试更新、使用新的数据、或者将相关情况报告给用户。
乐观并发控制
Elasticsearch是分布式的。当文档创建、更新或删除时,新版本的文档必须复制到集群中的其他节点。Elasticsearch也是异步和并发的,这意味着这些复制请求被并行发送,并且到达目的地时也许顺序是乱的。Elasticsearch需要一种方法确保文档的旧版本不会覆盖新的版本。
当我们之前讨论index , GET和DELETE请求时,我们指出每个文档都有一个_version(版本号),当文档被修改时版本号递增。Elasticsearch使用这个version号来确保变更以正确顺序得到执行。如果旧版本的文档在新版本之后到达,它可以被简单的忽略。
我们可以利用version号来确保应用中相互冲突的变更不会导致数据丢失。我们通过指定想要修改文档的 version号来达到这个目的。如果该版本不是当前版本号,我们的请求将会失败。
老的版本es使用version,但是新版本不支持了,会报下面的错误,提示我们用if_seq _no和if _primary_term
创建索引
##PUT http://127.0.0.1:9200/shopping/_create/1001
返回结果
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 10,
"_primary_term": 15
}
更新数据
##POST http://127.0.0.1:9200/shopping/_update/1001
{
"doc":{
"title":"华为手机"
}
}
返回结果:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 11,
"_primary_term": 15
}
旧版本使用的防止冲突更新方法:
##POST http://127.0.0.1:9200/shopping/_update/1001?version=1
{
"doc":{
"title":"华为手机2"
}
}
返回结果:
{
"error": {
"root_cause": [
{
"type": "action_request_validation_exception",
"reason": "Validation Failed: 1: internal versioning can not be used for optimistic concurrency control. Please use `if_seq_no` and `if_primary_term` instead;"
}
],
"type": "action_request_validation_exception",
"reason": "Validation Failed: 1: internal versioning can not be used for optimistic concurrency control. Please use `if_seq_no` and `if_primary_term` instead;"
},
"status": 400
}
新版本使用的防止冲突更新方法:
##POST http://127.0.0.1:9200/shopping/_update/1001?if_seq_no=11&if_primary_term=15
{
"doc":{
"title":"华为手机2"
}
}
返回结果:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 12,
"_primary_term": 16
}
外部系统版本控制
一个常见的设置是使用其它数据库作为主要的数据存储,使用Elasticsearch做数据检索,这意味着主数据库的所有更改发生时都需要被复制到Elasticsearch,如果多个进程负责这一数据同步,你可能遇到类似于之前描述的并发问题。
如果你的主数据库已经有了版本号,或一个能作为版本号的字段值比如timestamp,那么你就可以在 Elasticsearch 中通过增加 version_type=extermal到查询字符串的方式重用这些相同的版本号,版本号必须是大于零的整数,且小于9.2E+18,一个Java中 long类型的正值。
外部版本号的处理方式和我们之前讨论的内部版本号的处理方式有些不同,Elasticsearch不是检查当前_version和请求中指定的版本号是否相同,而是检查当前_version是否小于指定的版本号。如果请求成功,外部的版本号作为文档的新_version进行存储。
##POST http://127.0.0.1:9200/shopping/_doc/1001?version=300&version_type=external
{
"title":"华为手机2"
}
返回结果:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_version": 300,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 13,
"_primary_term": 16
}
48-进阶-文档展示-Kibana
Kibana是一个免费且开放的用户界面,能够让你对Elasticsearch 数据进行可视化,并让你在Elastic Stack 中进行导航。你可以进行各种操作,从跟踪查询负载,到理解请求如何流经你的整个应用,都能轻松完成。
一、解压缩下载的 zip 文件。
二、修改 config/kibana.yml 文件。
## 默认端口
server.port: 5601
## ES 服务器的地址
elasticsearch.hosts: ["http://localhost:9200"]
## 索引名
kibana.index: ".kibana"
## 支持中文
i18n.locale: "zh-CN"
三、Windows 环境下执行 bin/kibana.bat 文件。(首次启动有点耗时)
四、通过浏览器访问:http://localhost:5601。
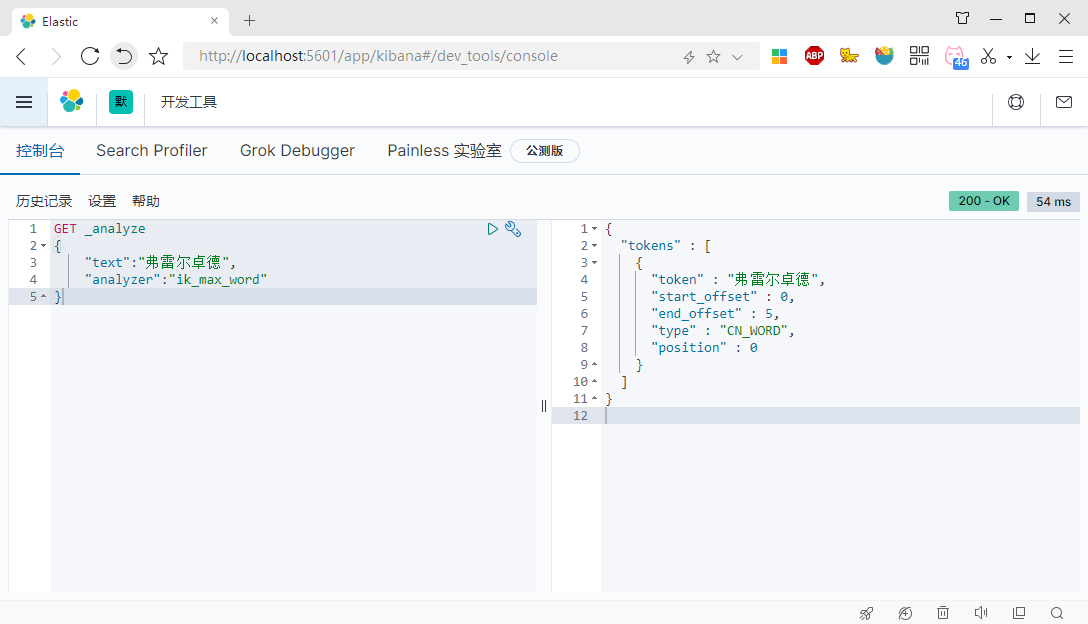
第5章 Elasticsearch集成
49-框架集成-SpringData-整体介绍
Spring Data是一个用于简化数据库、非关系型数据库、索引库访问,并支持云服务的开源框架。其主要目标是使得对数据的访问变得方便快捷,并支持 map-reduce框架和云计算数据服务。Spring Data可以极大的简化JPA(Elasticsearch…)的写法,可以在几乎不用写实现的情况下,实现对数据的访问和操作。除了CRUD 外,还包括如分页、排序等一些常用的功能。
Spring Data 常用的功能模块如下:
- Spring Data JDBC
- Spring Data JPA
- Spring Data LDAP
- Spring Data MongoDB
- Spring Data Redis
- Spring Data R2DBC
- Spring Data REST
- Spring Data for Apache Cassandra
- Spring Data for Apache Geode
- Spring Data for Apache Solr
- Spring Data for Pivotal GemFire
- Spring Data Couchbase
- Spring Data Elasticsearch
- Spring Data Envers
- Spring Data Neo4j
- Spring Data JDBC Extensions
- Spring for Apache Hadoop
Spring Data Elasticsearch 介绍
Spring Data Elasticsearch基于Spring Data API简化 Elasticsearch 操作,将原始操作Elasticsearch 的客户端API进行封装。Spring Data为Elasticsearch 项目提供集成搜索引擎。Spring Data Elasticsearch POJO的关键功能区域为中心的模型与Elastichsearch交互文档和轻松地编写一个存储索引库数据访问层。
50-框架集成-SpringData-代码功能集成
一、创建Maven项目。
二、修改pom文件,增加依赖关系。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.6.RELEASE</version>
<relativePath/>
</parent>
<groupId>com.lun</groupId>
<artifactId>SpringDataWithES</artifactId>
<version>1.0.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-test</artifactId>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
</dependency>
</dependencies>
</project>
三、增加配置文件。
在 resources 目录中增加application.properties文件
## es 服务地址
elasticsearch.host=127.0.0.1
## es 服务端口
elasticsearch.port=9200
## 配置日志级别,开启 debug 日志
logging.level.com.atguigu.es=debug
四、Spring Boot 主程序。
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class MainApplication {
public static void main(String[] args) {
SpringApplication.run(MainApplication.class, args);
}
}
五、数据实体类。
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
@Document(indexName = "shopping", shards = 3, replicas = 1)
public class Product {
//必须有 id,这里的 id 是全局唯一的标识,等同于 es 中的"_id"
@Id
private Long id;//商品唯一标识
/**
* type : 字段数据类型
* analyzer : 分词器类型
* index : 是否索引(默认:true)
* Keyword : 短语,不进行分词
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String title;//商品名称
@Field(type = FieldType.Keyword)
private String category;//分类名称
@Field(type = FieldType.Double)
private Double price;//商品价格
@Field(type = FieldType.Keyword, index = false)
private String images;//图片地址
}
六、配置类
- ElasticsearchRestTemplate是spring-data-elasticsearch项目中的一个类,和其他spring项目中的 template类似。
- 在新版的spring-data-elasticsearch 中,ElasticsearchRestTemplate 代替了原来的ElasticsearchTemplate。
- 原因是ElasticsearchTemplate基于TransportClient,TransportClient即将在8.x 以后的版本中移除。所以,我们推荐使用ElasticsearchRestTemplate。
- ElasticsearchRestTemplate基于RestHighLevelClient客户端的。需要自定义配置类,继承AbstractElasticsearchConfiguration,并实现elasticsearchClient()抽象方法,创建RestHighLevelClient对象。
AbstractElasticsearchConfiguration源码:
package org.springframework.data.elasticsearch.config;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.data.elasticsearch.core.ElasticsearchOperations;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.convert.ElasticsearchConverter;
/**
* @author Christoph Strobl
* @author Peter-Josef Meisch
* @since 3.2
* @see ElasticsearchConfigurationSupport
*/
public abstract class AbstractElasticsearchConfiguration extends ElasticsearchConfigurationSupport {
//需重写本方法
public abstract RestHighLevelClient elasticsearchClient();
@Bean(name = { "elasticsearchOperations", "elasticsearchTemplate" })
public ElasticsearchOperations elasticsearchOperations(ElasticsearchConverter elasticsearchConverter) {
return new ElasticsearchRestTemplate(elasticsearchClient(), elasticsearchConverter);
}
}
需要自定义配置类,继承AbstractElasticsearchConfiguration,并实现elasticsearchClient()抽象方法,创建RestHighLevelClient对象。
import lombok.Data;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.config.AbstractElasticsearchConfiguration;
@ConfigurationProperties(prefix = "elasticsearch")
@Configuration
@Data
public class ElasticsearchConfig extends AbstractElasticsearchConfiguration{
private String host ;
private Integer port ;
//重写父类方法
@Override
public RestHighLevelClient elasticsearchClient() {
RestClientBuilder builder = RestClient.builder(new HttpHost(host, port));
RestHighLevelClient restHighLevelClient = new
RestHighLevelClient(builder);
return restHighLevelClient;
}
}
七、DAO 数据访问对象
import com.lun.model.Product;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface ProductDao extends ElasticsearchRepository<Product, Long>{
}
51-框架集成-SpringData-集成测试-索引操作
import com.lun.model.Product;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringDataESIndexTest {
//注入 ElasticsearchRestTemplate
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
//创建索引并增加映射配置
@Test
public void createIndex(){
//创建索引,系统初始化会自动创建索引
//创建@Document(indexName = "shopping", shards = 3, replicas = 1)
//public class Product {//自动创建shopping
System.out.println("创建索引");
}
@Test
public void deleteIndex(){
//创建索引,系统初始化会自动创建索引
boolean flg = elasticsearchRestTemplate.deleteIndex(Product.class);
System.out.println("删除索引 = " + flg);
}
}
用Postman 检测有没有创建和删除。
##GET http://localhost:9200/_cat/indices?v
52-框架集成-SpringData-集成测试-文档操作
import com.lun.dao.ProductDao;
import com.lun.model.Product;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Sort;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.ArrayList;
import java.util.List;
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringDataESProductDaoTest {
@Autowired
private ProductDao productDao;
/**
* 新增
*/
@Test
public void save(){
Product product = new Product();
product.setId(2L);
product.setTitle("华为手机");
product.setCategory("手机");
product.setPrice(2999.0);
product.setImages("http://www.atguigu/hw.jpg");
productDao.save(product);
}
//POSTMAN, GET http://localhost:9200/product/_doc/2
//修改
@Test
public void update(){
Product product = new Product();
product.setId(2L);
product.setTitle("小米 2 手机");
product.setCategory("手机");
product.setPrice(9999.0);
product.setImages("http://www.atguigu/xm.jpg");
productDao.save(product);
}
//POSTMAN, GET http://localhost:9200/product/_doc/2
//根据 id 查询
@Test
public void findById(){
Product product = productDao.findById(2L).get();
System.out.println(product);
}
@Test
public void findAll(){
Iterable<Product> products = productDao.findAll();
for (Product product : products) {
System.out.println(product);
}
}
//删除
@Test
public void delete(){
Product product = new Product();
product.setId(2L);
productDao.delete(product);
}
//POSTMAN, GET http://localhost:9200/product/_doc/2
//批量新增
@Test
public void saveAll(){
List<Product> productList = new ArrayList<>();
for (int i = 0; i < 10; i++) {
Product product = new Product();
product.setId(Long.valueOf(i));
product.setTitle("["+i+"]小米手机");
product.setCategory("手机");
product.setPrice(1999.0 + i);
product.setImages("http://www.atguigu/xm.jpg");
productList.add(product);
}
productDao.saveAll(productList);
}
//分页查询
@Test
public void findByPageable(){
//设置排序(排序方式,正序还是倒序,排序的 id)
Sort sort = Sort.by(Sort.Direction.DESC,"id");
int currentPage=0;//当前页,第一页从 0 开始, 1 表示第二页
int pageSize = 5;//每页显示多少条
//设置查询分页
PageRequest pageRequest = PageRequest.of(currentPage, pageSize,sort);
//分页查询
Page<Product> productPage = productDao.findAll(pageRequest);
for (Product Product : productPage.getContent()) {
System.out.println(Product);
}
}
}
53-框架集成-SpringData-集成测试-文档搜索
import com.lun.dao.ProductDao;
import com.lun.model.Product;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.PageRequest;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringDataESSearchTest {
@Autowired
private ProductDao productDao;
/**
* term 查询
* search(termQueryBuilder) 调用搜索方法,参数查询构建器对象
*/
@Test
public void termQuery(){
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", "小米");
Iterable<Product> products = productDao.search(termQueryBuilder);
for (Product product : products) {
System.out.println(product);
}
}
/**
* term 查询加分页
*/
@Test
public void termQueryByPage(){
int currentPage= 0 ;
int pageSize = 5;
//设置查询分页
PageRequest pageRequest = PageRequest.of(currentPage, pageSize);
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", "小米");
Iterable<Product> products =
productDao.search(termQueryBuilder,pageRequest);
for (Product product : products) {
System.out.println(product);
}
}
}
54-框架集成-SparkStreaming-集成
Spark Streaming 是Spark core API的扩展,支持实时数据流的处理,并且具有可扩展,高吞吐量,容错的特点。数据可以从许多来源获取,如Kafka, Flume,Kinesis或TCP sockets,并且可以使用复杂的算法进行处理,这些算法使用诸如 map,reduce,join和 window等高级函数表示。最后,处理后的数据可以推送到文件系统,数据库等。实际上,您可以将Spark的机器学习和图形处理算法应用于数据流。
一、创建Maven项目。
二、修改 pom 文件,增加依赖关系。
<?xml version="1.0" encoding="utf-8"?>
<project
xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.lun.es</groupId>
<artifactId>sparkstreaming-elasticsearch</artifactId>
<version>1.0</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch 的客户端 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch 依赖 2.x 的 log4j -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<!-- <dependency>-->
<!-- <groupId>com.fasterxml.jackson.core</groupId>-->
<!-- <artifactId>jackson-databind</artifactId>-->
<!-- <version>2.11.1</version>-->
<!-- </dependency>-->
<!-- <!– junit 单元测试 –>-->
<!-- <dependency>-->
<!-- <groupId>junit</groupId>-->
<!-- <artifactId>junit</artifactId>-->
<!-- <version>4.12</version>-->
<!-- </dependency>-->
</dependencies>
</project>
三、功能实现
import org.apache.http.HttpHost
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.elasticsearch.action.index.IndexRequest
import org.elasticsearch.client.indices.CreateIndexRequest
import org.elasticsearch.client.{RequestOptions, RestClient, RestHighLevelClient}
import org.elasticsearch.common.xcontent.XContentType
import java.util.Date
object SparkStreamingESTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("ESTest")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val ds: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999)
ds.foreachRDD(
rdd => {
println("*************** " + new Date())
rdd.foreach(
data => {
val client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));
// 新增文档 - 请求对象
val request = new IndexRequest();
// 设置索引及唯一性标识
val ss = data.split(" ")
println("ss = " + ss.mkString(","))
request.index("sparkstreaming").id(ss(0));
val productJson =
s"""
| { "data":"${ss(1)}" }
|""".stripMargin;
// 添加文档数据,数据格式为 JSON 格式
request.source(productJson,XContentType.JSON);
// 客户端发送请求,获取响应对象
val response = client.index(request,
RequestOptions.DEFAULT);
System.out.println("_index:" + response.getIndex());
System.out.println("_id:" + response.getId());
System.out.println("_result:" + response.getResult());
client.close()
}
)
}
)
ssc.start()
ssc.awaitTermination()
}
}
55-框架集成-Flink-集成
Apache Spark是一-种基于内存的快速、通用、可扩展的大数据分析计算引擎。Apache Spark掀开了内存计算的先河,以内存作为赌注,贏得了内存计算的飞速发展。但是在其火热的同时,开发人员发现,在Spark中,计算框架普遍存在的缺点和不足依然没有完全解决,而这些问题随着5G时代的来临以及决策者对实时数据分析结果的迫切需要而凸显的更加明显:
- 乱序数据,迟到数据
- 低延迟,高吞吐,准确性
- 容错性
- 数据精准一次性处理(Exactly-Once)
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。在Spark火热的同时,也默默地发展自己,并尝试着解决其他计算框架的问题。慢慢地,随着这些问题的解决,Flink 慢慢被绝大数程序员所熟知并进行大力推广,阿里公司在2015年改进Flink,并创建了内部分支Blink,目前服务于阿里集团内部搜索、推荐、广告和蚂蚁等大量核心实时业务。
一、创建Maven项目。
二、修改 pom 文件,增加相关依赖类库。
<?xml version="1.0" encoding="UTF-8"?>
<project
xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.lun.es</groupId>
<artifactId>flink-elasticsearch</artifactId>
<version>1.0</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_2.11</artifactId>
<version>1.12.0</version>
</dependency>
<!-- jackson -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.11.1</version>
</dependency>
</dependencies>
</project>
三、功能实现
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.apache.flink.streaming.connectors.elasticsearch7.ElasticsearchSink;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class FlinkElasticsearchSinkTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.socketTextStream("localhost", 9999);
List<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("127.0.0.1", 9200, "http"));
//httpHosts.add(new HttpHost("10.2.3.1", 9200, "http"));
// use a ElasticsearchSink.Builder to create an ElasticsearchSink
ElasticsearchSink.Builder<String> esSinkBuilder = new ElasticsearchSink.Builder<>(httpHosts,
new ElasticsearchSinkFunction<String>() {
public IndexRequest createIndexRequest(String element) {
Map<String, String> json = new HashMap<>();
json.put("data", element);
return Requests.indexRequest()
.index("my-index")
//.type("my-type")
.source(json);
}
@Override
public void process(String element, RuntimeContext ctx, RequestIndexer indexer) {
indexer.add(createIndexRequest(element));
}
}
);
// configuration for the bulk requests; this instructs the sink to emit after every element, otherwise they would be buffered
esSinkBuilder.setBulkFlushMaxActions(1);
// provide a RestClientFactory for custom configuration on the internally createdREST client
// esSinkBuilder.setRestClientFactory(
// restClientBuilder -> {
// restClientBuilder.setDefaultHeaders(...)
// restClientBuilder.setMaxRetryTimeoutMillis(...)
// restClientBuilder.setPathPrefix(...)
// restClientBuilder.setHttpClientConfigCallback(...)
// }
// );
source.addSink(esSinkBuilder.build());
env.execute("flink-es");
}
}
第6章 Elasticsearch优化
56-优化-硬件选择
Elasticsearch 的基础是 Lucene,所有的索引和文档数据是存储在本地的磁盘中,具体的路径可在 ES 的配置文件…/config/elasticsearch.yml中配置,如下:
##
## Path to directory where to store the data (separate multiple locations by comma):
##
path.data: /path/to/data
##
## Path to log files:
##
path.logs: /path/to/logs
磁盘在现代服务器上通常都是瓶颈。Elasticsearch重度使用磁盘,你的磁盘能处理的吞吐量越大,你的节点就越稳定。这里有一些优化磁盘I/O的技巧:
- 使用SSD就像其他地方提过的,他们比机械磁盘优秀多了。
- 使用RAID0。条带化RAID会提高磁盘IO,代价显然就是当一块硬盘故障时整个就故障了。不要使用镜像或者奇偶校验RAID,因为副本已经提供了这个功能。
- 另外,使用多块硬盘,并允许Elasticsearch 通过多个path data目录配置把数据条带化分配到它们上面。
- 不要使用远程挂载的存储,比如NFS或者SMB/CIFS。这个引入的延迟对性能来说完全是背道而驰的。
57-优化-分片策略
合理设置分片数
分片和副本的设计为 ES 提供了支持分布式和故障转移的特性,但并不意味着分片和副本是可以无限分配的。而且索引的分片完成分配后由于索引的路由机制,我们是不能重新修改分片数的。
可能有人会说,我不知道这个索引将来会变得多大,并且过后我也不能更改索引的大小,所以为了保险起见,还是给它设为 1000 个分片吧。但是需要知道的是,一个分片并不是没有代价的。需要了解:
-
一个分片的底层即为一个 Lucene 索引,会消耗一定文件句柄、内存、以及 CPU运转。
-
每一个搜索请求都需要命中索引中的每一个分片,如果每一个分片都处于不同的节点还好, 但如果多个分片都需要在同一个节点上竞争使用相同的资源就有些糟糕了。
-
用于计算相关度的词项统计信息是基于分片的。如果有许多分片,每一个都只有很少的数据会导致很低的相关度。
一个业务索引具体需要分配多少分片可能需要架构师和技术人员对业务的增长有个预先的判断,横向扩展应当分阶段进行。为下一阶段准备好足够的资源。 只有当你进入到下一个阶段,你才有时间思考需要作出哪些改变来达到这个阶段。一般来说,我们遵循一些原则:
- 控制每个分片占用的硬盘容量不超过 ES 的最大 JVM 的堆空间设置(一般设置不超过 32G,参考下文的 JVM 设置原则),因此,如果索引的总容量在 500G 左右,那分片大小在 16 个左右即可;当然,最好同时考虑原则 2。
- 考虑一下 node 数量,一般一个节点有时候就是一台物理机,如果分片数过多,大大超过了节点数,很可能会导致一个节点上存在多个分片,一旦该节点故障,即使保持了 1 个以上的副本,同样有可能会导致数据丢失,集群无法恢复。所以, 一般都设置分片数不超过节点数的 3 倍。
- 主分片,副本和节点最大数之间数量,我们分配的时候可以参考以下关系:
节点数<=主分片数 *(副本数+1)
推迟分片分配
对于节点瞬时中断的问题,默认情况,集群会等待一分钟来查看节点是否会重新加入,如果这个节点在此期间重新加入,重新加入的节点会保持其现有的分片数据,不会触发新的分片分配。这样就可以减少 ES 在自动再平衡可用分片时所带来的极大开销。
通过修改参数 delayed_timeout ,可以延长再均衡的时间,可以全局设置也可以在索引级别进行修改:
##PUT /_all/_settings
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "5m"
}
}
58-优化-路由选择
当我们查询文档的时候, Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?它其实是通过下面这个公式来计算出来:
shard = hash(routing) % number_of_primary_shards
routing 默认值是文档的 id,也可以采用自定义值,比如用户 id。
不带routing查询
在查询的时候因为不知道要查询的数据具体在哪个分片上,所以整个过程分为2个步骤
- 分发:请求到达协调节点后,协调节点将查询请求分发到每个分片上。
- 聚合:协调节点搜集到每个分片上查询结果,在将查询的结果进行排序,之后给用户返回结果。
带routing查询
查询的时候,可以直接根据routing 信息定位到某个分配查询,不需要查询所有的分配,经过协调节点排序。向上面自定义的用户查询,如果routing 设置为userid 的话,就可以直接查询出数据来,效率提升很多。
59-优化-写入速度优化
ES 的默认配置,是综合了数据可靠性、写入速度、搜索实时性等因素。实际使用时,我们需要根据公司要求,进行偏向性的优化。
针对于搜索性能要求不高,但是对写入要求较高的场景,我们需要尽可能的选择恰当写优化策略。综合来说,可以考虑以下几个方面来提升写索引的性能:
- 加大Translog Flush,目的是降低Iops、Writeblock。
- 增加Index Refesh间隔,目的是减少Segment Merge的次数。
- 调整Bulk 线程池和队列。
- 优化节点间的任务分布。
- 优化Lucene层的索引建立,目的是降低CPU及IO。
优化存储设备
ES 是一种密集使用磁盘的应用,在段合并的时候会频繁操作磁盘,所以对磁盘要求较高,当磁盘速度提升之后,集群的整体性能会大幅度提高。
合理使用合并
Lucene 以段的形式存储数据。当有新的数据写入索引时, Lucene 就会自动创建一个新的段。
随着数据量的变化,段的数量会越来越多,消耗的多文件句柄数及 CPU 就越多,查询效率就会下降。
由于 Lucene 段合并的计算量庞大,会消耗大量的 I/O,所以 ES 默认采用较保守的策略,让后台定期进行段合并。
减少 Refresh 的次数
Lucene 在新增数据时,采用了延迟写入的策略,默认情况下索引的refresh_interval 为1 秒。
Lucene 将待写入的数据先写到内存中,超过 1 秒(默认)时就会触发一次 Refresh,然后 Refresh 会把内存中的的数据刷新到操作系统的文件缓存系统中。
如果我们对搜索的实效性要求不高,可以将 Refresh 周期延长,例如 30 秒。
这样还可以有效地减少段刷新次数,但这同时意味着需要消耗更多的 Heap 内存。
加大 Flush 设置
Flush 的主要目的是把文件缓存系统中的段持久化到硬盘,当 Translog 的数据量达到 512MB 或者 30 分钟时,会触发一次 Flush。
index.translog.flush_threshold_size 参数的默认值是 512MB,我们进行修改。
增加参数值意味着文件缓存系统中可能需要存储更多的数据,所以我们需要为操作系统的文件缓存系统留下足够的空间。
减少副本的数量
ES 为了保证集群的可用性,提供了 Replicas(副本)支持,然而每个副本也会执行分析、索引及可能的合并过程,所以 Replicas 的数量会严重影响写索引的效率。
当写索引时,需要把写入的数据都同步到副本节点,副本节点越多,写索引的效率就越慢。
如果我们需要大批量进行写入操作,可以先禁止Replica复制,设置
index.number_of_replicas: 0 关闭副本。在写入完成后, Replica 修改回正常的状态。
60-优化-内存设置
ES 默认安装后设置的内存是 1GB,对于任何一个现实业务来说,这个设置都太小了。如果是通过解压安装的 ES,则在 ES 安装文件中包含一个 jvm.option 文件,添加如下命令来设置 ES 的堆大小, Xms 表示堆的初始大小, Xmx 表示可分配的最大内存,都是 1GB。
确保 Xmx 和 Xms 的大小是相同的,其目的是为了能够在 Java 垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小而浪费资源,可以减轻伸缩堆大小带来的压力。
假设你有一个 64G 内存的机器,按照正常思维思考,你可能会认为把 64G 内存都给ES 比较好,但现实是这样吗, 越大越好?虽然内存对 ES 来说是非常重要的,但是答案是否定的!
因为 ES 堆内存的分配需要满足以下两个原则:
-
不要超过物理内存的 50%: Lucene 的设计目的是把底层 OS 里的数据缓存到内存中。Lucene 的段是分别存储到单个文件中的,这些文件都是不会变化的,所以很利于缓存,同时操作系统也会把这些段文件缓存起来,以便更快的访问。如果我们设置的堆内存过大, Lucene 可用的内存将会减少,就会严重影响降低 Lucene 的全文本查询性能。
-
堆内存的大小最好不要超过 32GB:在 Java 中,所有对象都分配在堆上,然后有一个 Klass Pointer 指针指向它的类元数据。这个指针在 64 位的操作系统上为 64 位, 64 位的操作系统可以使用更多的内存(2^64)。在 32 位
的系统上为 32 位, 32 位的操作系统的最大寻址空间为 4GB(2^32)。
但是 64 位的指针意味着更大的浪费,因为你的指针本身大了。浪费内存不算,更糟糕的是,更大的指针在主内存和缓存器(例如 LLC, L1 等)之间移动数据的时候,会占用更多的带宽。
最终我们都会采用 31 G 设置
- -Xms 31g
- -Xmx 31g
假设你有个机器有 128 GB 的内存,你可以创建两个节点,每个节点内存分配不超过 32 GB。也就是说不超过 64 GB 内存给 ES 的堆内存,剩下的超过 64 GB 的内存给 Lucene。
61-优化-重要配置
| 参数名 | 参数值 | 说明 |
|---|---|---|
| cluster.name | elasticsearch | 配置 ES 的集群名称,默认值是 ES,建议改成与所存数据相关的名称, ES 会自动发现在同一网段下的 集群名称相同的节点。 |
| node.name | node-1 | 集群中的节点名,在同一个集群中不能重复。节点 的名称一旦设置,就不能再改变了。当然,也可以 设 置 成 服 务 器 的 主 机 名 称 , 例 如 node.name:${HOSTNAME}。 |
| node.master | true | 指定该节点是否有资格被选举成为 Master 节点,默 认是 True,如果被设置为 True,则只是有资格成为 Master 节点,具体能否成为 Master 节点,需要通 过选举产生。 |
| node.data | true | 指定该节点是否存储索引数据,默认为 True。数据 的增、删、改、查都是在 Data 节点完成的。 |
| index.number_of_shards | 1 | 设置都索引分片个数,默认是 1 片。也可以在创建 索引时设置该值,具体设置为多大都值要根据数据 量的大小来定。如果数据量不大,则设置成 1 时效 率最高 |
| index.number_of_replicas | 1 | 设置默认的索引副本个数,默认为 1 个。副本数越 多,集群的可用性越好,但是写索引时需要同步的 数据越多。 |
| transport.tcp.compress | true | 设置在节点间传输数据时是否压缩,默认为 False, 不压缩 |
| discovery.zen.minimum_master_nodes | 1 | 设置在选举 Master 节点时需要参与的最少的候选 主节点数,默认为 1。如果使用默认值,则当网络 不稳定时有可能会出现脑裂。 合 理 的 数 值 为 (master_eligible_nodes/2)+1 , 其 中 master_eligible_nodes 表示集群中的候选主节点数 |
| discovery.zen.ping.timeout | 3s | 设置在集群中自动发现其他节点时 Ping 连接的超 时时间,默认为 3 秒。 在较差的网络环境下需要设置得大一点,防止因误 判该节点的存活状态而导致分片的转移 |
第7章 Elasticsearch面试题
62-面试题
为什么要使用 Elasticsearch?
系统中的数据, 随着业务的发展,时间的推移, 将会非常多, 而业务中往往采用模糊查询进行数据的搜索, 而模糊查询会导致查询引擎放弃索引,导致系统查询数据时都是全表扫描,在百万级别的数据库中,查询效率是非常低下的,而我们使用 ES 做一个全文索引,将经常查询的系统功能的某些字段,比如说电商系统的商品表中商品名,描述、价格还有 id 这些字段我们放入 ES 索引库里,可以提高查询速度。
Elasticsearch 的 master 选举流程?
- Elasticsearch的选主是ZenDiscovery模块负责的,主要包含Ping(节点之间通过这个RPC来发现彼此)
和Unicast(单播模块包含-一个主机列表以控制哪些节点需要ping通)这两部分。 - 对所有可以成为master的节点(node master: true)根据nodeId字典排序,每次选举每个节点都把自
己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。 - 如果对某个节点的投票数达到一定的值(可以成为master节点数n/2+1)并且该节点自己也选举自己,
那这个节点就是master。否则重新选举一直到满足上述条件。 - master节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data节点可以关闭http
功能。
Elasticsearch 集群脑裂问题?
“脑裂”问题可能的成因:
- 网络问题:集群间的网络延迟导致一些节点访问不到master, 认为master 挂掉了从而选举出新的master,并对master上的分片和副本标红,分配新的主分片。
- 节点负载:主节点的角色既为master又为data,访问量较大时可能会导致ES停止响应造成大面积延迟,此时其他节点得不到主节点的响应认为主节点挂掉了,会重新选取主节点。
- 内存回收:data 节点上的ES进程占用的内存较大,引发JVM的大规模内存回收,造成ES进程失去响应。
脑裂问题解决方案:
-
减少误判:discovery.zen ping_ timeout 节点状态的响应时间,默认为3s,可以适当调大,如果master在该响应时间的范围内没有做出响应应答,判断该节点已经挂掉了。调大参数(如6s,discovery.zen.ping_timeout:6),可适当减少误判。
-
选举触发:discovery.zen.minimum. _master_ nodes:1,该参數是用于控制选举行为发生的最小集群主节点数量。当备选主节点的个數大于等于该参数的值,且备选主节点中有该参数个节点认为主节点挂了,进行选举。官方建议为(n / 2) +1, n为主节点个数(即有资格成为主节点的节点个数)。
-
角色分离:即master节点与data节点分离,限制角色
- 主节点配置为:node master: true,node data: false
- 从节点配置为:node master: false,node data: true
Elasticsearch 索引文档的流程?
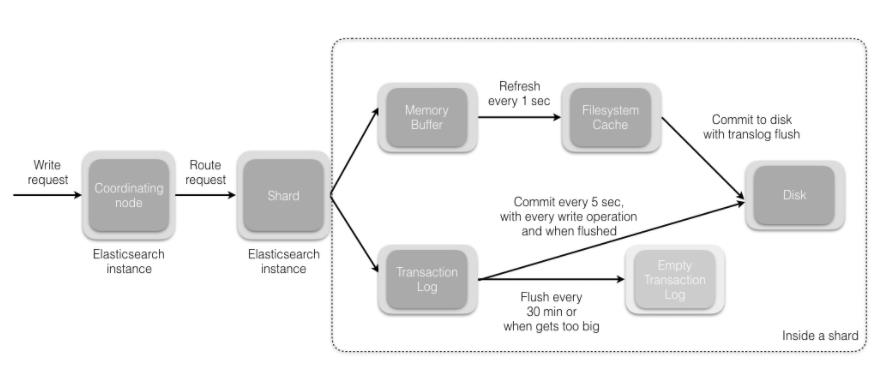
- 协调节点默认使用文档 ID 参与计算(也支持通过 routing),以便为路由提供合适的分片:shard = hash(document_id) % (num_of_primary_shards)
- 当分片所在的节点接收到来自协调节点的请求后,会将请求写入到 Memory Buffer,然后定时(默认是每隔 1 秒)写入到 Filesystem Cache,这个从 Memory Buffer 到 Filesystem Cache 的过程就叫做 refresh;
- 当然在某些情况下,存在 Momery Buffer 和 Filesystem Cache 的数据可能会丢失, ES 是通过 translog的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到 translog 中,当 Filesystemcache 中的数据写入到磁盘中时,才会清除掉,这个过程叫做 flush;
- 在 flush 过程中,内存中的缓冲将被清除,内容被写入一个新段,段的 fsync 将创建一个新的提交点,并将内容刷新到磁盘,旧的 translog 将被删除并开始一个新的 translog。
- flush 触发的时机是定时触发(默认 30 分钟)或者 translog 变得太大(默认为 512M)时;
Elasticsearch 更新和删除文档的流程?
- 删除和更新也都是写操作,但是 Elasticsearch 中的文档是不可变的,因此不能被删除或者改动以展示其变更;
- 磁盘上的每个段都有一个相应的.del 文件。当删除请求发送后,文档并没有真的被删除,而是在.del文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在.del 文件中被标记为删除的文档将不会被写入新段。
- 在新的文档被创建时, Elasticsearch 会为该文档指定一个版本号,当执行更新时,旧版本的文档在.del文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
Elasticsearch 搜索的流程?
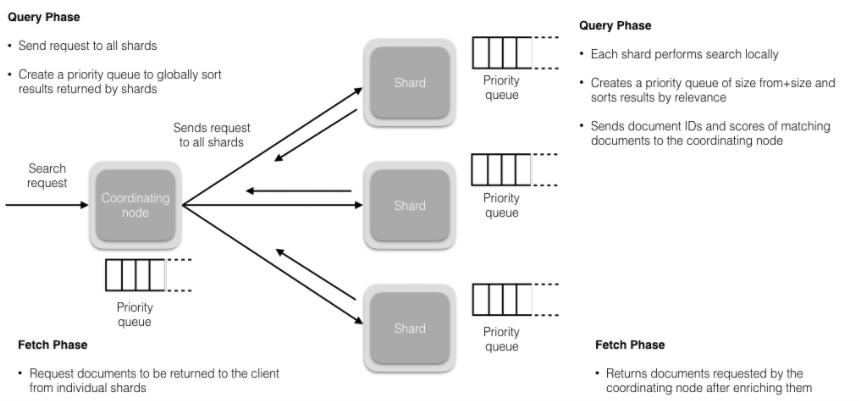
- 搜索被执行成一个两阶段过程,我们称之为 Query Then Fetch;
- 在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。 PS:在搜索的时候是会查询Filesystem Cache 的,但是有部分数据还在 Memory Buffer,所以搜索是近实时的。
- 每个分片返回各自优先队列中 所有文档的 ID 和排序值 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
- 接下来就是取回阶段, 协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并丰富文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
- Query Then Fetch 的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确, DFS Query Then Fetch 增加了一个预查询的处理,询问 Term 和 Document frequency,这个评分更准确,但是性能会变差。
Elasticsearch 在部署时,对 Linux 的设置有哪些优化方法?
-
64 GB 内存的机器是非常理想的, 但是 32 GB 和 16 GB 机器也是很常见的。少于 8 GB 会适得其反。
-
如果你要在更快的 CPUs 和更多的核心之间选择,选择更多的核心更好。多个内核提供的额外并发远胜过稍微快一点点的时钟频率。
-
如果你负担得起 SSD,它将远远超出任何旋转介质。 基于 SSD 的节点,查询和索引性能都有提升。如果你负担得起, SSD 是一个好的选择。
-
即使数据中心们近在咫尺,也要避免集群跨越多个数据中心。绝对要避免集群跨越大的地理距离。
-
请确保运行你应用程序的 JVM 和服务器的 JVM 是完全一样的。 在 Elasticsearch 的几个地方,使用 Java 的本地序列化。
-
通过设置 gateway.recover_after_nodes、 gateway.expected_nodes、 gateway.recover_after_time 可以在集群重启的时候避免过多的分片交换,这可能会让数据恢复从数个小时缩短为几秒钟。
-
Elasticsearch 默认被配置为使用单播发现,以防止节点无意中加入集群。只有在同一台机器上运行的节点才会自动组成集群。最好使用单播代替组播。
-
不要随意修改垃圾回收器(CMS)和各个线程池的大小。
-
把你的内存的(少于)一半给 Lucene(但不要超过 32 GB!),通过 ES_HEAP_SIZE 环境变量设置。
-
内存交换到磁盘对服务器性能来说是致命的。如果内存交换到磁盘上,一个 100 微秒的操作可能变成 10 毫秒。 再想想那么多 10 微秒的操作时延累加起来。 不难看出 swapping 对于性能是多么可怕。
-
Lucene 使用了大量的文件。同时, Elasticsearch 在节点和 HTTP 客户端之间进行通信也使用了大量的套接字。 所有这一切都需要足够的文件描述符。你应该增加你的文件描述符,设置一个很大的值,如 64,000。
GC 方面,在使用 Elasticsearch 时要注意什么?
倒排词典的索引需要常驻内存,无法 GC,需要监控 data node 上 segment memory 增长趋势。
各类缓存, field cache, filter cache, indexing cache, bulk queue 等等,要设置合理的大小,并且要应该根据最坏的情况来看 heap 是否够用,也就是各类缓存全部占满的时候,还有 heap 空间可以分配给其他任务吗?避免采用 clear cache 等“自欺欺人”的方式来释放内存。
避免返回大量结果集的搜索与聚合。确实需要大量拉取数据的场景,可以采用 scan & scroll api 来实现。
cluster stats 驻留内存并无法水平扩展,超大规模集群可以考虑分拆成多个集群通过 tribe node 连接。
想知道 heap 够不够,必须结合实际应用场景,并对集群的 heap 使用情况做持续的监控。
Elasticsearch 对于大数据量(上亿量级)的聚合如何实现?
Elasticsearch 提供的首个近似聚合是 cardinality 度量。它提供一个字段的基数,即该字段的 distinct或者 unique 值的数目。它是基于 HLL 算法的。 HLL 会先对我们的输入作哈希运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。其特点是:可配置的精度,用来控制内存的使用(更精确 = 更多内存);小的数据集精度是非常高的;我们可以通过配置参数,来设置去重需要的固定内存使用量。无论数千还是数十亿的唯一值,内存使用量只与你配置的精确度相关。
在并发情况下, Elasticsearch 如果保证读写一致?
-
可以通过版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
-
另外对于写操作,一致性级别支持 quorum/one/all,默认为 quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。
-
对于读操作,可以设置 replication 为 sync(默认),这使得操作在主分片和副本分片都完成后才会返回;如果设置 replication 为 async 时,也可以通过设置搜索请求参数_preference 为 primary 来查询主分片,确保文档是最新版本。
如何监控 Elasticsearch 集群状态?
- elasticsearch-head 插件。
- 通过 Kibana 监控 Elasticsearch。你可以实时查看你的集群健康状态和性能,也可以分析过去的集群、索引和节点指标
是否了解字典树?
字典树又称单词查找树, Trie 树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
Trie 的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。它有 3 个基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
对于中文的字典树,每个节点的子节点用一个哈希表存储,这样就不用浪费太大的空间,而且查询速度上可以保留哈希的复杂度 O(1)。
Elasticsearch 中的集群、节点、索引、文档、类型是什么?
- 集群是一个或多个节点(服务器)的集合,它们共同保存您的整个数据,并提供跨所有节点的联合索引和搜索功能。群集由唯一名 称标识,默认情况下为"elasticsearch"。此名称很重要,因为如果节点设置为按名称加入群集,则该节点只能是群集的一部分。
- 节点是属于集群一部分的单个服务器。它存储数据并参与群集索引和搜索功能。
- 索引就像关系数据库中的“数据库”。它有一个定义多种类型的映射。索引是逻辑名称空间,映射到一个或多个主分片,并且可以有零个或多个副本分片。MySQL =>数据库,Elasticsearch=>索引。
- 文档类似于关系数据库中的一行。不同之处在于索引中的每个文档可以具有不同的结构(字段),但是对于通用字段应该具有相同的数据类型。MySQL => Databases => Tables => Columns / Rows,Elasticsearch=> Indices => Types =>具有属性的文档Doc。
- 类型是索引的逻辑类别/分区,其语义完全取决于用户。
Elasticsearch 中的倒排索引是什么?
倒排索引是搜索引擎的核心。搜索引擎的主要目标是在查找发生搜索条件的文档时提供快速搜索。ES中的倒排索引其实就是 lucene 的倒排索引,区别于传统的正向索引, 倒排索引会再存储数据时将关键词和数据进行关联,保存到倒排表中,然后查询时,将查询内容进行分词后在倒排表中进行查询,最后匹配数据即可。
MyBatisPlus
0 快速开始
1.1 pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>spring-boot-starter-parent</artifactId>
<groupId>org.springframework.boot</groupId>
<version>2.3.4.RELEASE</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>mybatis-plusDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.2</version>
</dependency>
</dependencies>
</project>
1.2 application.yml
spring:
datasource:
url: jdbc:mysql://localhost:3306/mybatis-plus-demo
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
1.3 userMapper的编写
package com.xiaodidi.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.xiaodidi.demo.User;
import org.apache.ibatis.annotations.Mapper;
public interface UserMapper extends BaseMapper<User> {
}
1.4 主程序
package com.xiaodidi;
import org.mybatis.spring.annotation.MapperScan;
import org.mybatis.spring.annotation.MapperScans;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.xiaodidi.mapper")
public class MainApplication {
public static void main(String[] args) {
SpringApplication.run(MainApplication.class, args);
}
}
1.5 测试
package com.xiaodidi;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.xiaodidi.demo.User;
import com.xiaodidi.mapper.UserMapper;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import javax.annotation.Resource;
import java.util.List;
@RunWith(SpringRunner.class)
@SpringBootTest
public class TestDemo {
@Resource
UserMapper userMapper;
@Test
public void save() {
List<User> users = userMapper.selectList(null);
for (User user : users) {
System.out.println(user);
}
}
}
2.1 mybatis的主键(默认识别表中id字段为主键)
只要mybatis识别到主键,同时检测出来插入id为null,默认就自动使用了雪花算法,转换了然后在插入到数据库
有时数据库中的主键不是id也可以使用@TableId(“id”)指定主键
@TableId("id")//里面的id代表数据库中的字段
private Long uid;
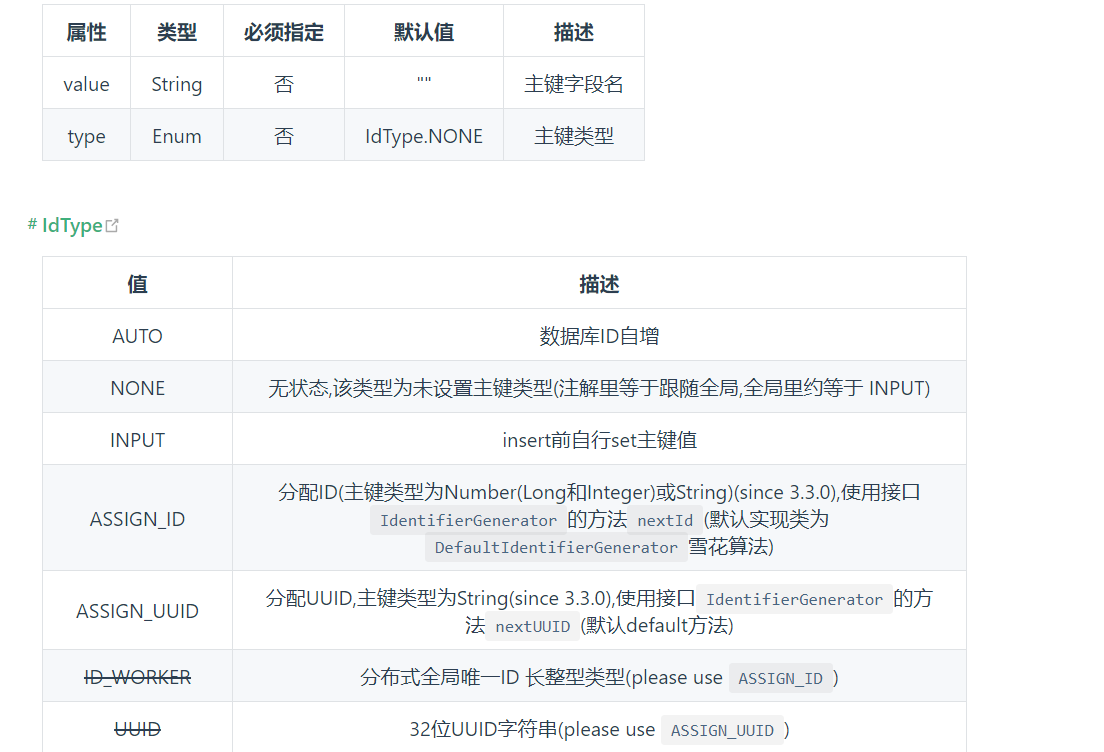
2.2 TableName
用来指定数据库中的名字,当数据库大的时候,通常使用t_user等标签来执行不同的服务,这是就需要通过TableName来执行表的名字,用来定位
2.3 @TableField
@TableField("name")
name代表数据库中的字段,用来进行对应,不过mybatisplus默认把user_number 转换成userNumber,可以自动进行识别
2.4 myBatisPlus设置createTime
第一种方式
通过更改数据库中的
更改默认为当地的时间戳
(一般不用,不允许更改数据库)
第二种方式
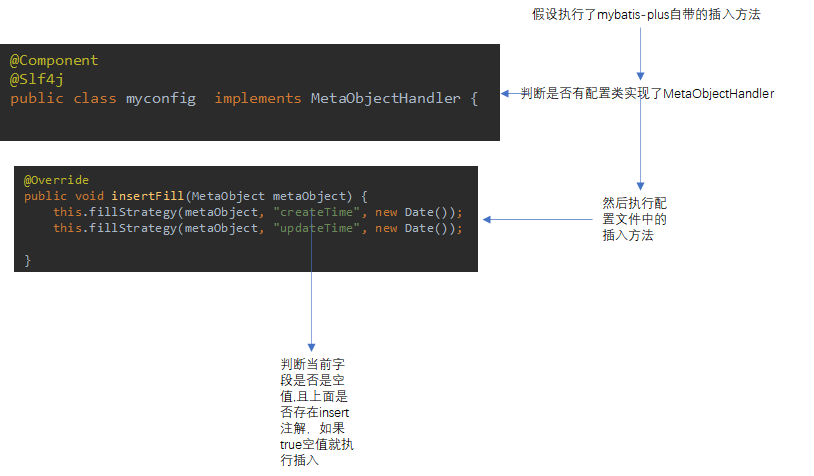
@TableField(fill = FieldFill.INSERT)
private Date createTime;
//更新时间
@TableField(fill = FieldFill.INSERT_UPDATE)
private Date updateTime;
package com.atguigu.boot.config;
import com.baomidou.mybatisplus.core.handlers.MetaObjectHandler;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.reflection.MetaObject;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.util.Date;
@Slf4j
@Component
public class MyMetaObjectHandler implements MetaObjectHandler {
//插入时候的填充策略
@Override
public void insertFill(MetaObject metaObject) {
log.info("start insert fill ...."); //日志
//设置字段的值(String fieldName字段名,Object fieldVal要传递的值,MetaObject metaObject)
this.fillStrategy(metaObject, "createTime", new Date());
this.fillStrategy(metaObject, "updateTime", new Date());
//this.strictInsertFill(metaObject, "createTime", LocalDateTime.class, LocalDateTime.now()); // 起始版本 3.3.0(推荐使用)
// this.fillStrategy(metaObject, "createTime", LocalDateTime.now()); // 也可以使用(3.3.0 该方法有bug请升级到之后的版本如`3.3.1.8-SNAPSHOT`)
/* 上面选其一使用,下面的已过时(注意 strictInsertFill 有多个方法,详细查看源码) */
//this.setFieldValByName("operator", "Jerry", metaObject);
//this.setInsertFieldValByName("operator", "Jerry", metaObject);
}
//更新时间的填充策略
@Override
public void updateFill(MetaObject metaObject) {
log.info("start update fill ....");
this.fillStrategy(metaObject, "updateTime", new Date());
//this.strictUpdateFill(metaObject, "updateTime", LocalDateTime.class, LocalDateTime.now()); // 起始版本 3.3.0(推荐使用)
// this.fillStrategy(metaObject, "updateTime", LocalDateTime.now()); // 也可以使用(3.3.0 该方法有bug请升级到之后的版本如`3.3.1.8-SNAPSHOT`)
/* 上面选其一使用,下面的已过时(注意 strictUpdateFill 有多个方法,详细查看源码) */
//this.setFieldValByName("operator", "Tom", metaObject);
//this.setUpdateFieldValByName("operator", "Tom", metaObject);
}
}
测试
@ResponseBody
@RequestMapping("/saveRole")
public String saveRole() {
Role role = new Role();
role.setName("小");
roleService.save(role);
return "成功";
}
//自动会加入时间戳
注意:这里面所有的操作都需要使用mybatisBaseMapper里面自带的方法,因此不能使用自己写的方法使用createTime
2.5 乐观锁
面试中经常会问到乐观锁,悲观锁
乐观锁:顾名思义十分乐观,它总是被认为不会出现问题,无论干什么都不去上锁!如果出现了问题,再次更新测试
悲观锁:顾名思义十分悲观,它总是出现问题,无论干什么都会上锁!再去操作!
乐观锁实现方式
取出记录是,获取当前version 更新时,带上这个version 执行更新事,set version=newVersion where version =oldVersion 如果version不对,就更新失败 乐观锁: 1、先查询,获得版本号 version=1
--A
update user set name ="shuishui" ,version =version+1
where id =2 and version=1
--B 如果线程抢先完成,这个时候version=2,会导致A修改失败
update user set name ="shuishui" ,version =version+1
where id =2 and version=1
使用乐观锁
1 在数据库中加入version字段
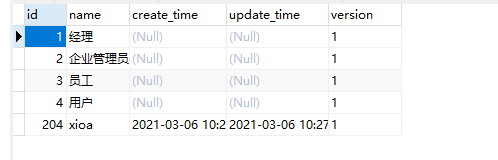
2 在pojo类中加入version字段
@Version
private String version;
3 加入配置
//开启事务
@EnableTransactionManagement
@Configuration
public class MybatisPlusConfig {
@Bean
public OptimisticLockerInterceptor optimisticLockerInterceptor() {
return new OptimisticLockerInterceptor();
}
}
2.6 查询操作
// 根据 ID 查询
T selectById(Serializable id);
// 根据 entity 条件,查询一条记录
T selectOne(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 查询(根据ID 批量查询)
List<T> selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
// 根据 entity 条件,查询全部记录
List<T> selectList(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 查询(根据 columnMap 条件)
List<T> selectByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
// 根据 Wrapper 条件,查询全部记录
List<Map<String, Object>> selectMaps(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录。注意: 只返回第一个字段的值
List<Object> selectObjs(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 entity 条件,查询全部记录(并翻页)
IPage<T> selectPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录(并翻页)
IPage<Map<String, Object>> selectMapsPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询总记录数
Integer selectCount(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
condition
@Test
public void queryTest() {
QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();
//查询所有名字中存在o的,同时年龄在16到20中的,如果不写就不进行判断
String likeName = "o";
Integer maxAge = 20;
Integer minAge = 16;
//如果第一个参数返回的是true就加入,如果返回的false那么就不进行加入
userQueryWrapper.like(StringUtils.isNotBlank(likeName), "name", likeName)
.gt(minAge!=null,"age",minAge)
.lt(maxAge!=null,"age",maxAge);
for (User user : userMapper.selectList(userQueryWrapper)) {
System.out.println(user);
}
}
优先级
@Test
public void queryTest2() {
QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();
//查润name中带o的,同时查找年龄大于16或者name=xiaodidi
userQueryWrapper.like("name","o").and(userQueryWrapper1 -> userQueryWrapper1.gt("age",16).or().eq("name","xiaodidi"));
List<User> users = userMapper.selectList(userQueryWrapper);
for (User user : users) {
System.out.println(user);
}
}
and中用消费型接口
LambdaQueryWrapper
@Test
public void queryTest2() throws IOException {
LambdaQueryWrapper<User> userQueryWrapper = new LambdaQueryWrapper<>();
//查润name中带o的,同时查找年龄大于16或者name=xiaodidi
userQueryWrapper.like((User::getUsername), "o").and(userQueryWrapper1 -> userQueryWrapper1.gt(User::getAge,16).or().eq(User::getUsername,"xiaodidi"));
List<User> users = userMapper.selectList(userQueryWrapper);
for (User user : users) {
System.out.println(user);
}
}

模拟实现
package com.xiaodidi;
import com.baomidou.mybatisplus.core.toolkit.support.SFunction;
import lombok.Data;
import net.minidev.json.JSONUtil;
import java.lang.invoke.SerializedLambda;
import java.lang.reflect.Method;
@Data
public class LambdaTest {
private String fieldA;
public static void main(String[] args) throws Exception {
SerializedLambda serializedLambda = doSFunction(LambdaTest::getFieldA);
System.out.println("方法名:" + serializedLambda.getImplMethodName());
System.out.println("类名:" + serializedLambda.getImplClass());
}
/*SerializedLambda对象了。 实际上序列化的对象是通过writeReplace方法产生的,那么我们要获取SerializedLambda对象没必要真的序列化和反序列化一遍。 反射调用writeReplace方法就可以了。*/
private static <T, R> java.lang.invoke.SerializedLambda doSFunction(SFunction<T, R> func) throws Exception {
// 直接调用writeReplace
Method writeReplace = func.getClass().getDeclaredMethod("writeReplace");
writeReplace.setAccessible(true);
//反射调用
Object sl = writeReplace.invoke(func);
java.lang.invoke.SerializedLambda serializedLambda = (java.lang.invoke.SerializedLambda) sl;
return serializedLambda;
}
}
2.7 myBatis-plus自带分页查询
放入分页的组件
@Bean
public PaginationInterceptor paginationInterceptor() {
PaginationInterceptor paginationInterceptor = new PaginationInterceptor();
//指定数据库类型,以防每次都要去适配数据库
paginationInterceptor.setDbType(DbType.MYSQL);
return paginationInterceptor;
}
@ResponseBody
@RequestMapping("/pageTest")
public List<Role> pageTest() {
Page<Role> rolePage = new Page<>(1, 5);
roleMapper.selectPage(rolePage, null);
return rolePage.getRecords();
}
自添加分页
IPage<User> getUsersgtAge(Page<User> page, @Param("age") Integer age);
<select id="getUsersgtAge" resultMap="userResultMap">
select * from user where age > #{age}
</select>
这样,也可以像别的分页一样进行操作
2.8 删除操作
// 根据 entity 条件,删除记录
int delete(@Param(Constants.WRAPPER) Wrapper<T> wrapper);
// 删除(根据ID 批量删除)
int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
// 根据 ID 删除
int deleteById(Serializable id);
// 根据 columnMap 条件,删除记录
int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
2.9 配置逻辑删除
在表中添加一个字段
同时在类中也加入相同
private String deleted;
mybatis3.3以前
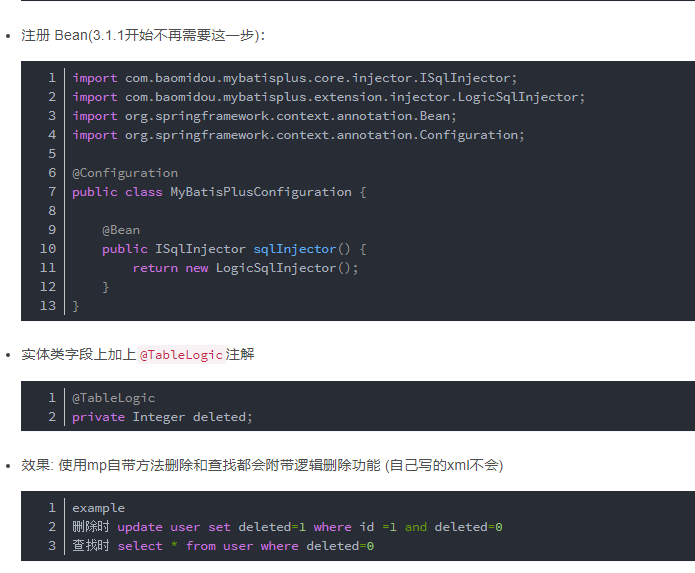
myBatis 3.3 以后
global-config:
db-config:
logic-delete-field: deleted
logic-delete-value: 1
logic-not-delete-value: 0
使用logic-delete-field:deleted 来指定全局的逻辑删除指标 相当于deleted
如果某个类全局逻辑指标要自己定义的时候添加
@TableLogic
private String deleted;
默认先从注解开始寻找,如果注解没有指定逻辑删除指标的时候,在从全局配置文件中寻找,如果都没有,那么就没有逻辑删除
注意:只针对myBatis-plus创建的sql有效,自己创建sql没有效果
2.10 代码自动生成器
代码自动生成器
dao、pojo、conrtroller、service自动生成
AutoGenerator 是 MyBatis-Plus 的代码生成器,通过 AutoGenerator 可以快速生成 Entity、 Mapper、Mapper XML、Service、Controller 等各个模块的代码,极大的提升了开发效率。
package com.kuang;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.annotation.FieldFill;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.generator.AutoGenerator;
import com.baomidou.mybatisplus.generator.config.DataSourceConfig;
import com.baomidou.mybatisplus.generator.config.GlobalConfig;
import com.baomidou.mybatisplus.generator.config.PackageConfig;
import com.baomidou.mybatisplus.generator.config.StrategyConfig;
import com.baomidou.mybatisplus.generator.config.po.TableFill;
import com.baomidou.mybatisplus.generator.config.rules.DateType;
import com.baomidou.mybatisplus.generator.config.rules.NamingStrategy;
import java.util.ArrayList;
// 代码自动生成器
public class KuangCode {
public static void main(String[] args) {
// 需要构建一个 代码自动生成器 对象
AutoGenerator mpg = new AutoGenerator();
// 配置策略
// 1、全局配置
GlobalConfig gc = new GlobalConfig();
String projectPath = System.getProperty("user.dir");
gc.setOutputDir(projectPath+"/src/main/java");
gc.setAuthor("狂神说");
gc.setOpen(false);
gc.setFileOverride(false); // 是否覆盖
gc.setServiceName("%sService"); // 去Service的I前缀
gc.setIdType(IdType.ID_WORKER);
gc.setDateType(DateType.ONLY_DATE);
gc.setSwagger2(true);
mpg.setGlobalConfig(gc);
//2、设置数据源
DataSourceConfig dsc = new DataSourceConfig();
dsc.setUrl("jdbc:mysql://localhost:3306/kuang_community? useSSL=false&useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8");
dsc.setDriverName("com.mysql.cj.jdbc.Driver");
dsc.setUsername("root");
dsc.setPassword("123456");
dsc.setDbType(DbType.MYSQL);
mpg.setDataSource(dsc);
//3、包的配置
PackageConfig pc = new PackageConfig();
pc.setModuleName("blog");
pc.setParent("com.kuang");
pc.setEntity("entity");
pc.setMapper("mapper");
pc.setService("service");
pc.setController("controller");
mpg.setPackageInfo(pc);
//4、策略配置
StrategyConfig strategy = new StrategyConfig();
strategy.setInclude("blog_tags","course","links","sys_settings","user_record"," user_say"); // 设置要映射的表名
strategy.setNaming(NamingStrategy.underline_to_camel);
strategy.setColumnNaming(NamingStrategy.underline_to_camel);
// 自动lombok
strategy.setEntityLombokModel(true);
strategy.setLogicDeleteFieldName("deleted");
// 自动填充配置
TableFill gmtCreate = new TableFill("gmt_create", FieldFill.INSERT);
TableFill gmtModified = new TableFill("gmt_modified", FieldFill.INSERT_UPDATE);
ArrayList<TableFill> tableFills = new ArrayList<>();
tableFills.add(gmtCreate);
tableFills.add(gmtModified);
strategy.setTableFillList(tableFills);
// 乐观锁
strategy.setVersionFieldName("version");
strategy.setRestControllerStyle(true);
strategy.setControllerMappingHyphenStyle(true);
// localhost:8080/hello_id_2
mpg.setStrategy(strategy);
mpg.execute();
//执行
}
}
————————————————
版权声明:本文为CSDN博主「?Handsome?」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zdsg45/article/details/105138493/
mycat
文章目录
- 第一章 入门概述
- 第二章 安装启动
- 第三章 搭建读写分离
- 第四章 垂直拆分——分库
- 第五章 水平拆分——分表
- 第六章 基于 HA 机制的 Mycat 高可用
- 第七章 Mycat 安全设置
- 第八章 Mycat 监控工具
第一章 入门概述
1.1 是什么
Mycat是数据库中间件
1、数据库中间件
中间件:是一类连接软件和应用的计算机软件,以便软件各部件之间的沟通。
例子:Tomcat, web中间件。
数据库中间件:连接java应用的应用程序和数据库。
2、为什么要用Mycat?
1 java与数据库紧耦合
2 高访问量高并发对数据库的压力
3 读写请求数据不一致
3、数据库中间件对比
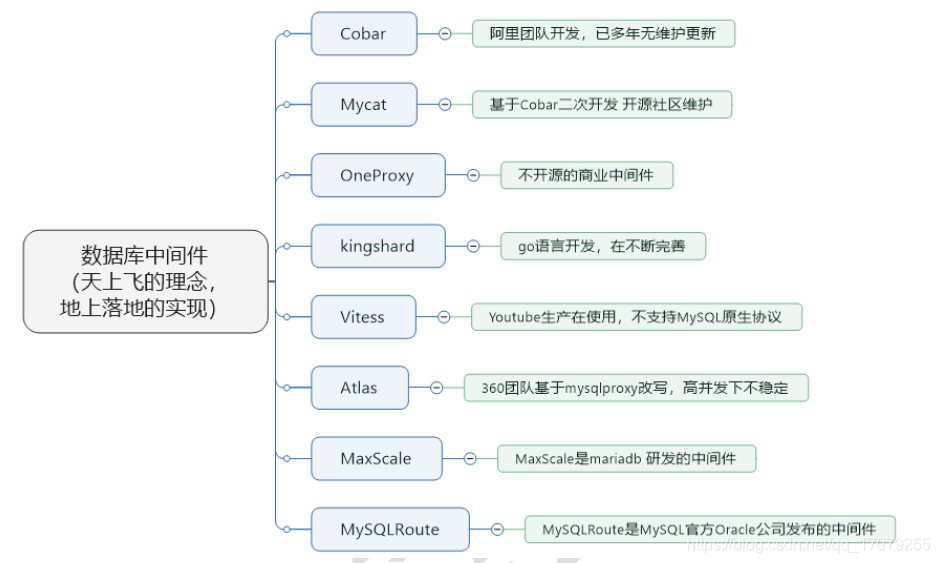
- Cobar属于阿里B2B事业群,始于2008年,在阿里服役3年多,接管3000+个MySQL数据库的schema,集群日处理在线SQL请求50亿次以上。由于Cobar发起人的离职, Cobar停止维护。
- Mycat是开源社区在阿里cobar基础上进行二次开发,解决了cobar存在的问题,并且加入了许多新的功能在其中。青出于蓝而胜于蓝。
- OneProxy基于MySQL官方的proxy思想利用c进行开发的, OneProxy是一款商业收费的中间件。舍弃了一些功能,专注在性能和稳定性上。
- kingshard由小团队用go语言开发,还需要发展,需要不断完善。
- Vitess是Youtube生产在使用, 架构很复杂。不支持MySQL原生协议,使用需要大量改造成本。
- Atlas是360团队基于mysql proxy改写,功能还需完善,高并发下不稳定。
- MaxScale是mariadb(MySQL原作者维护的一个版本) 研发的中间件
- MySQLRoute是MySQL官方Oracle公司发布的中间件
4、Mycat的官网
http://www.mycat.io/
1.2 干什么
1、读写分离
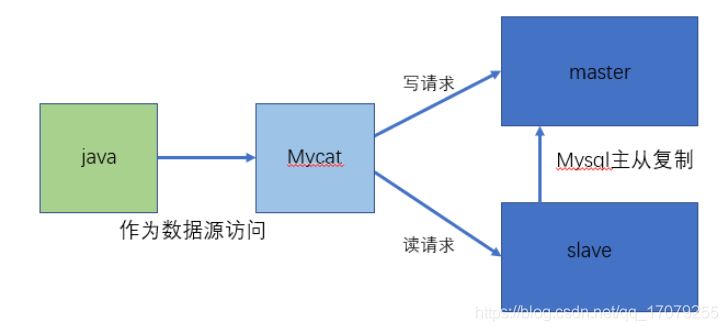
2、数据分片
垂直拆分(分库)、 水平拆分(分表)、 垂直+水平拆分(分库分表)
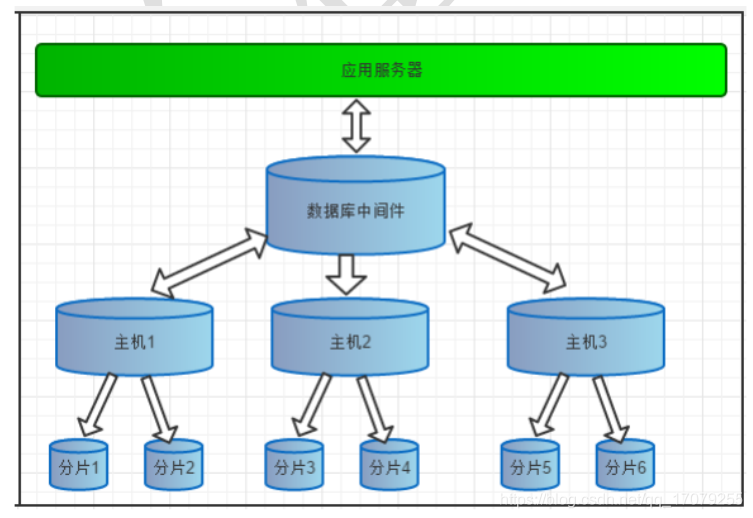
3、多数据源整合
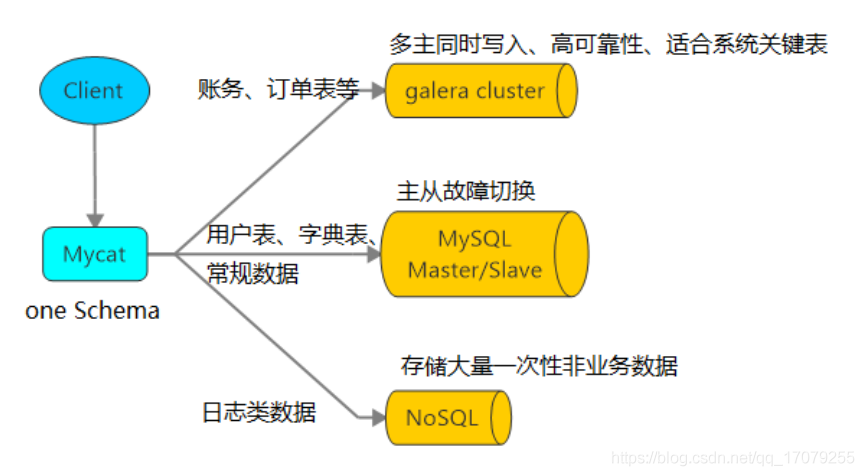
1.3 原理
Mycat 的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的 SQL 语句,首先对 SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此 SQL 发往后端的真实数据库, 并将返回的结果做适当的处理,最终再返回给用户。
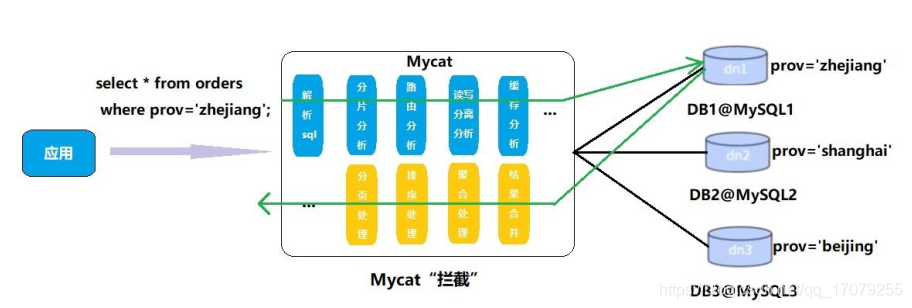
这种方式把数据库的分布式从代码中解耦出来,程序员察觉不出来后台使用 Mycat 还是MySQL。
第二章 安装启动
2.1 安装
1、 解压后即可使用
解压缩文件拷贝到 linux 下 /usr/local/
2、 三个配置文件
- schema.xml: 定义逻辑库,表、分片节点等内容
- rule.xml: 定义分片规则
- server.xml: 定义用户以及系统相关变量,如端口等
2.2 启动
1、 修改配置文件server.xml
修改用户信息,与MySQL区分, 如下:
…
<user name="mycat"> <!--原本是root,修改成mycat-->
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
</user>
…
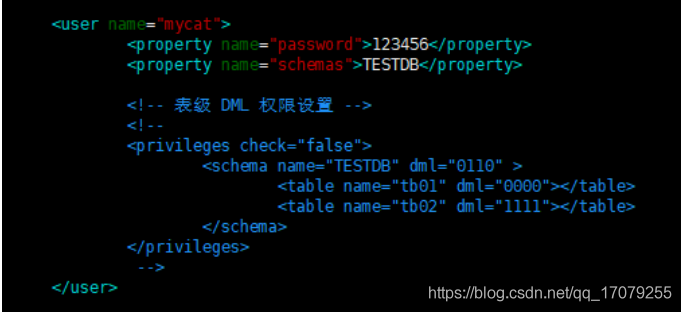
2、修改配置文件 schema.xml
删除标签间的表信息, 标签只留一个, 标签只留一个, 只留一对
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
</schema>
<!--testdb代表数据库的名字-->
<dataNode name="dn1" dataHost="host1" database="testdb" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<!--用192.168.241.102:3306需要给192.168.241.102这个地址一个权限,如果只给外部开放,自己是访问不了的,只能给自己一个权限,或者用
localhost:3306来进行装配 grant All privileges ON *.* TO 'root'@'192.168.241.102' IDENTIFIED BY '123456' WITH GRANT OPTION;
-->
<writeHost host="hostM1" url="192.168.241.102:3306" user="root"
password="123456">
<!-- can have multi read hosts -->
<readHost host="hostS1" url="192.168.241.103:3306" user="root"
password="123456" />
</writeHost>
</dataHost>
</mycat:schema>
3、 验证数据库访问情况
Mycat 作为数据库中间件要和数据库部署在不同机器上,所以要验证远程访问情况。
mysql -uroot -p123456 -h 192.168.241.102 -P 3306 //自己也访问以下,看看能不能通
mysql -uroot -p123456 -h 192.168.241.103 -P 3306
#如远程访问报错,请建对应用户
grant All privileges ON *.* TO 'root'@'192.168.241.102' IDENTIFIED BY '123456' WITH GRANT OPTION;
4、 启动程序
- 控制台启动 : 去 mycat/bin 目录下执行 ./mycat console
- 后台启动 :去 mycat/bin 目录下 ./mycat start
为了能第一时间看到启动日志,方便定位问题,我们选择①控制台启动。
5、 启动时可能出现报错
如果操作系统是 CentOS6.8, 可能会出现域名解析失败错误,如下图

可以按照以下步骤解决
① 用 vim 修改 /etc/hosts 文件, 在 127.0.0.1 后面增加你的机器名

② 修改后重新启动网络服务
2.3 登录
1、登录后台管理窗口
此登录方式用于管理维护 Mycat
mysql -umycat -p123456 -P 9066 -h 192.168.241.102
#常用命令如下:
show database
show @@help
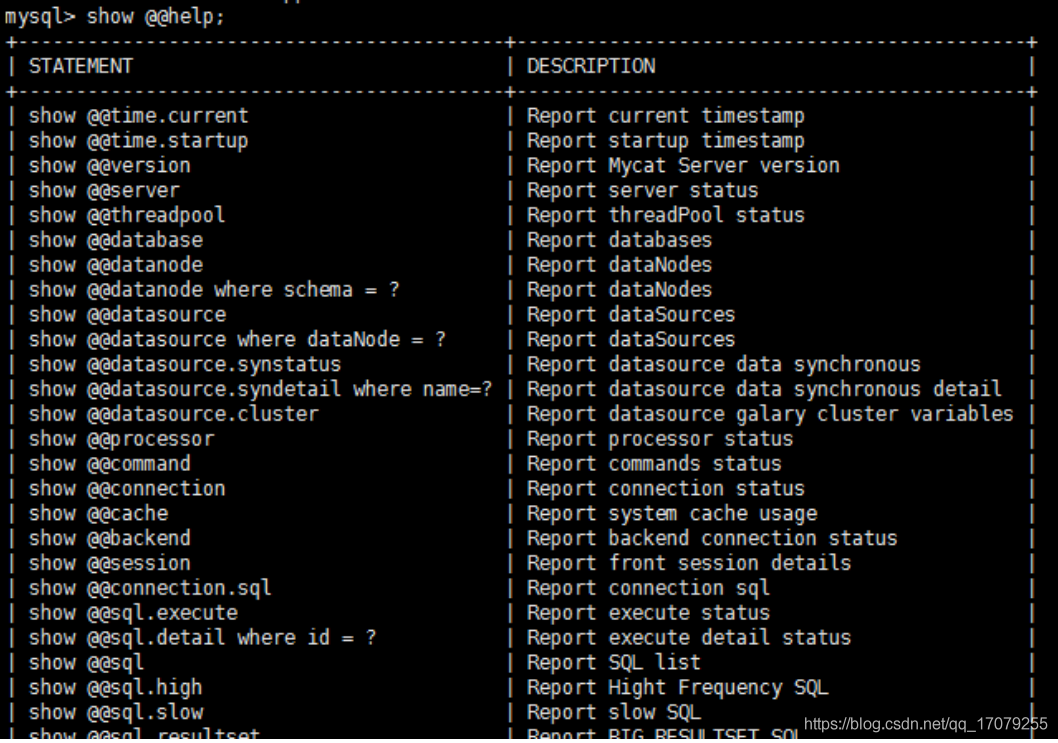
2、登录数据窗口
此登录方式用于通过 Mycat 查询数据,我们选择这种方式访问 Mycat
mysql -umycat -p123456 -P 8066 -h 192.168.241.102
第三章 搭建读写分离
我们通过 Mycat 和 MySQL 的主从复制配合搭建数据库的读写分离, 实现 MySQL 的高可用性。我们将搭建:一主一从、双主双从两种读写分离模式。
3.1 搭建一主一从
一个主机用于处理所有写请求,一台从机负责所有读请求,架构图如下
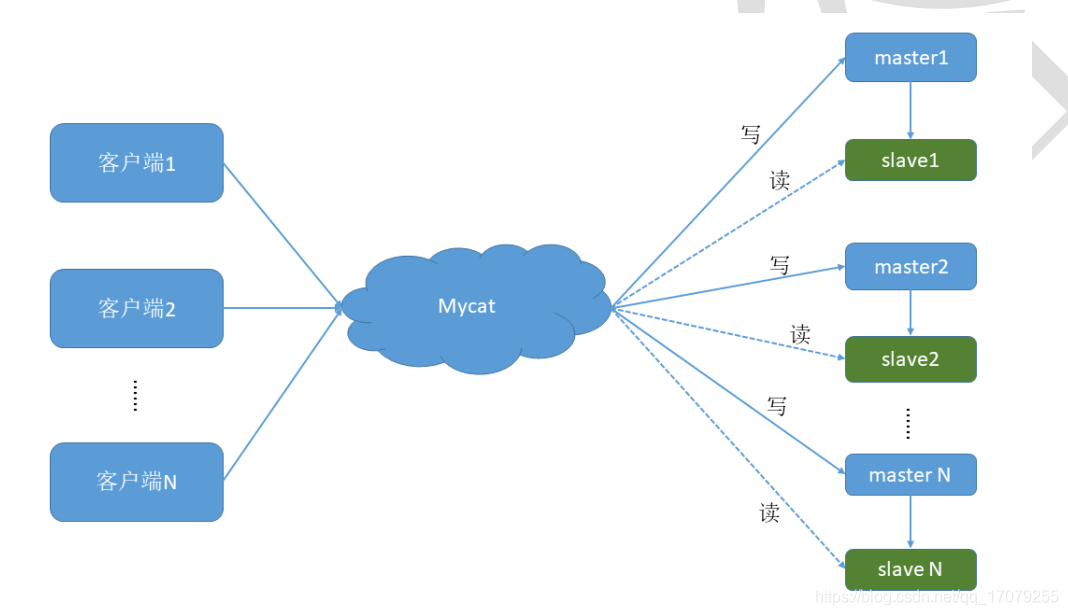
1、 搭建 MySQL 数据库主从复制
① MySQL 主从复制原理
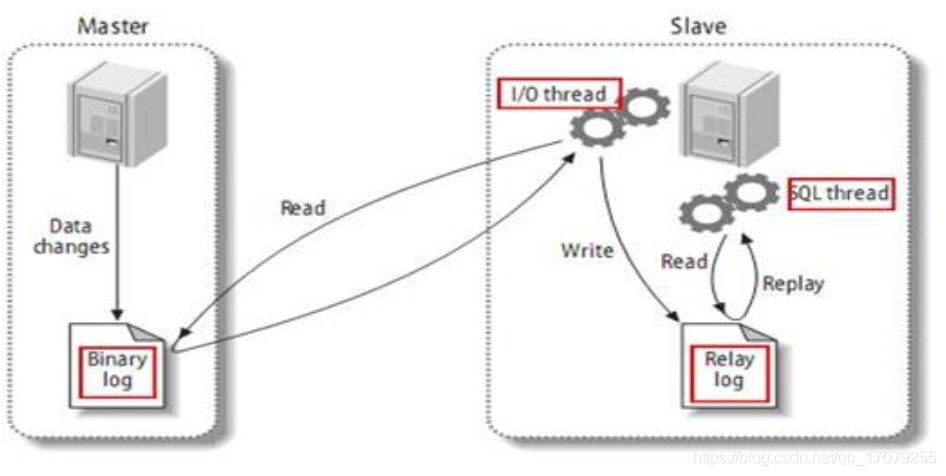
② 主机配置(host79)
修改配置文件: vim /etc/my.cnf
#主服务器唯一ID
server-id=1
#启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
#设置需要复制的数据库
binlog-do-db=需要复制的主数据库名字
#设置logbin格式
binlog_format=STATEMENT
binlog 日志三种格式
③ 从机配置(host80)
修改配置文件: vim /etc/my.cnf
#从服务器唯一ID
server-id=2
#启用中继日志
relay-log=mysql-relay
④ 主机、从机重启 MySQL 服务
⑤ 主机从机都关闭防火墙
⑥ 在主机上建立帐户并授权 slave
#在主机MySQL里执行授权命令
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY '123123';
#查询master的状态
show master status;

#记录下File和Position的值#执行完此步骤后不要再操作主服务器MySQL,防止主服务器状态值变化
⑦ 在从机上配置需要复制的主机(注意每次服务重启都要进行配置)
#复制主机的命令CHANGE MASTER TO MASTER_HOST='主机的IP地址',MASTER_USER='slave',MASTER_PASSWORD='123123',MASTER_LOG_FILE='mysql-bin.具体数字',MASTER_LOG_POS=具体值;

#启动从服务器复制功能start slave;#查看从服务器状态show slave status\G;
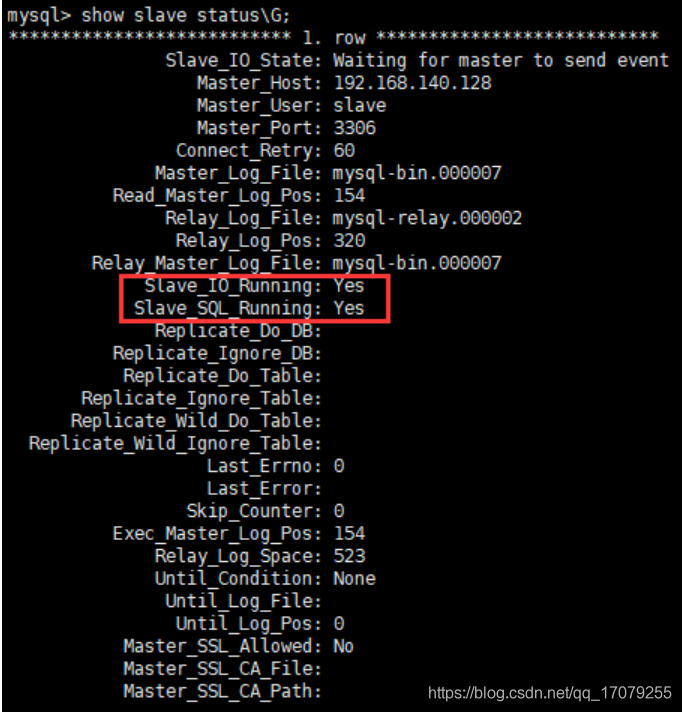
#下面两个参数都是Yes,则说明主从配置成功!# Slave_IO_Running: Yes# Slave_SQL_Running: Yes
⑧ 主机新建库、新建表、 insert 记录, 从机复制
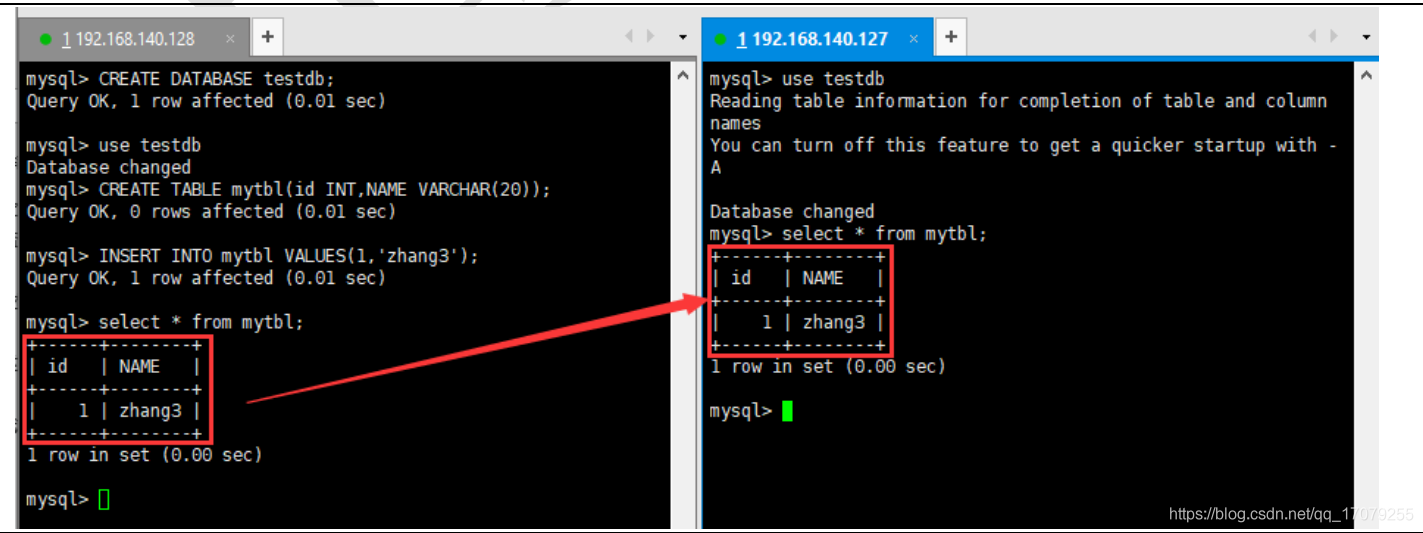
⑨ 如何停止从服务复制功能
stop slave;
⑩ 如何重新配置主从
stop slave;reset master;
2、 修改 Mycat 的配置文件 schema.xml
之前的配置已分配了读写主机,是否已实现读写分离?
验证读写分离(1) 在写主机插入: insert into mytbl values (1,@@hostname);主从主机数据不一致了(2) 在Mycat里查询: select * from mytbl;
修改的balance属性,通过此属性配置读写分离的类型
负载均衡类型,目前的取值有4 种:(1) balance="0", 不开启读写分离机制, 所有读操作都发送到当前可用的 writeHost 上。(2) balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1, M2->S2,并且 M1 与 M2 互为主备),正常情况下, M2,S1,S2 都参与 select 语句的负载均衡。(3) balance="2",所有读操作都随机的在 writeHost、 readhost 上分发。(4) balance="3",所有读请求随机的分发到 readhost 执行, writerHost 不负担读压力
为了能看到读写分离的效果,把balance设置成2, 会在两个主机间切换查询
…<dataHost name="host1" maxCon="1000" minCon="10" balance="2" writeType="0" dbType="mysql" dbDriver="native" switchType="1"slaveThreshold="100">…

3、 启动 Mycat
./mycat concole
mysql -umycat -p123456 -P 8066 -h 192.168.241.102
4、 验证读写分离
#(1) 在写主机数据库表mytbl中插入带系统变量数据, 造成主从数据不一致INSERT INTO mytbl VALUES(2,@@hostname);
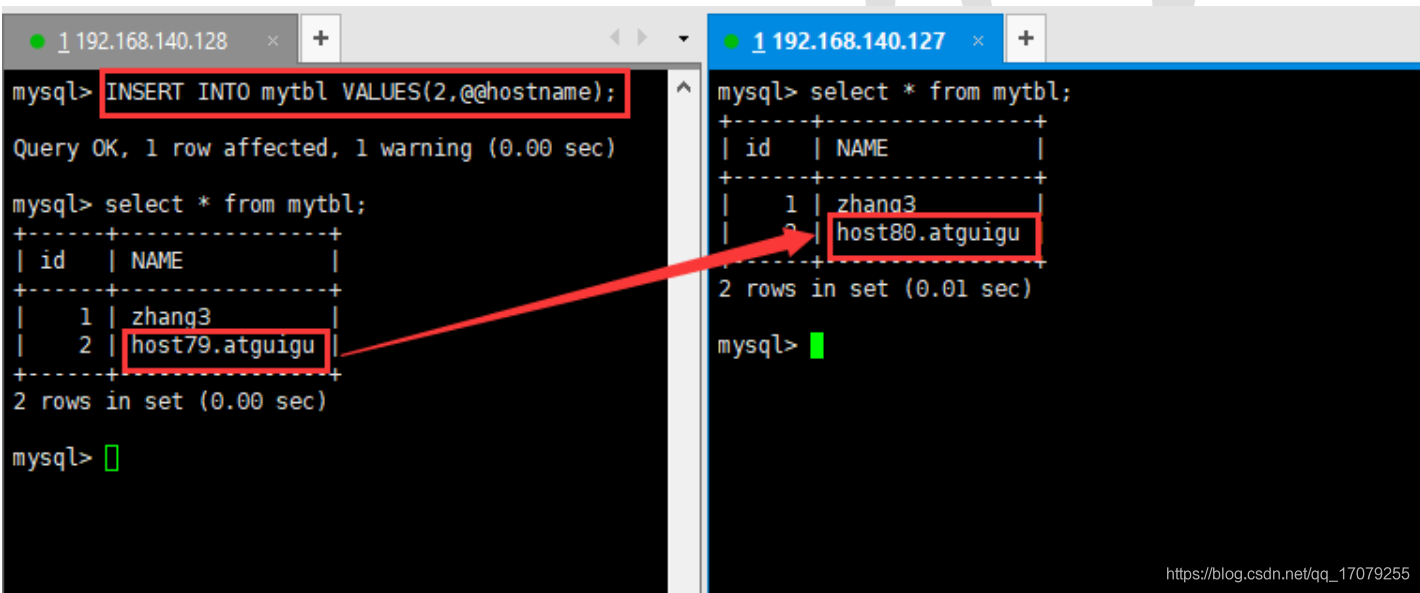
#(2) 在Mycat里查询mytbl表,可以看到查询语句在主从两个主机间切换,因为配置的是2 ,如果配置的是3就只能读取read的机器A
3.2 搭建双主双从
一个主机 m1 用于处理所有写请求, 它的从机 s1 和另一台主机 m2 还有它的从机 s2 负责所有读请求。当 m1 主机宕机后, m2 主机负责写请求, m1、 m2 互为备机。 架构图如下
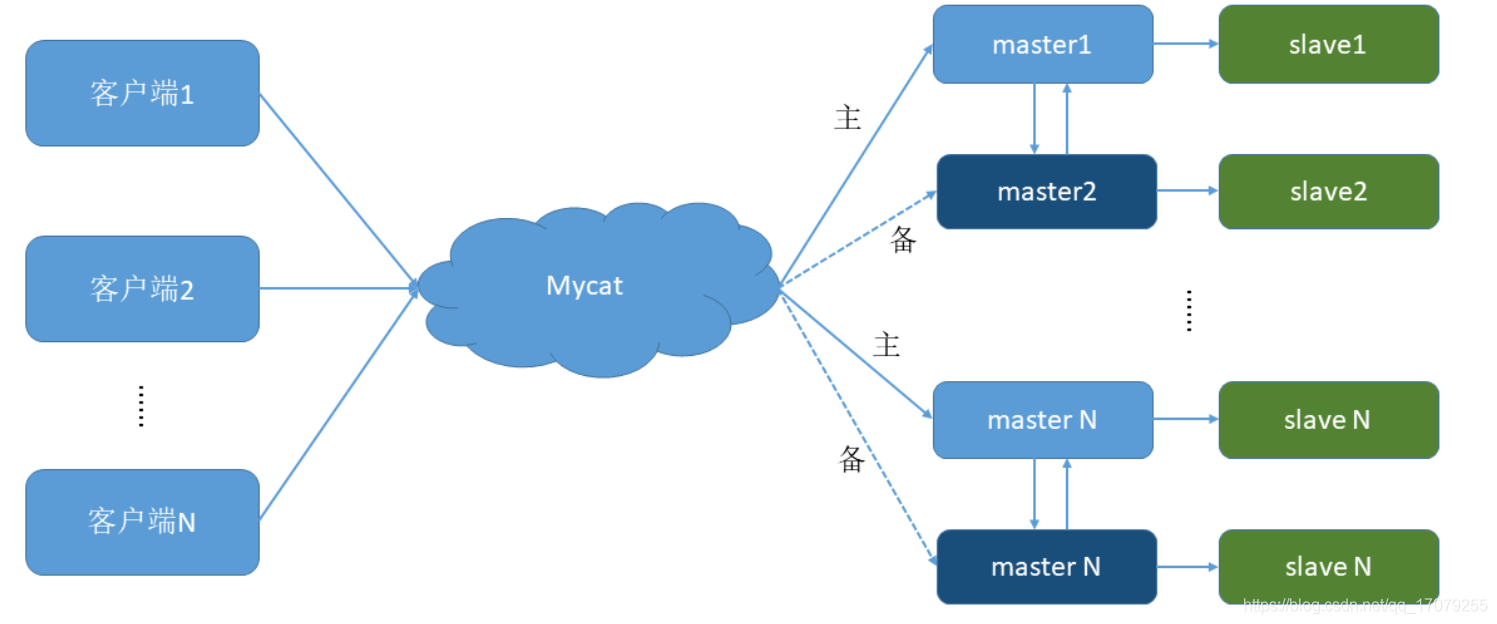
| 编号 | 角色 | IP 地址 | 机器名 |
|---|---|---|---|
| 1 | Master1 | 192.168.140.128 | host79.atguigu |
| 2 | Slave1 | 192.168.140.127 | host80.atguigu |
| 3 | Master2 | 192.168.140.126 | host81.atguigu |
| 4 | Slave2 | 192.168.140.125 | host82.atguigu |
1、 搭建 MySQL 数据库主从复制(双主双从)
① 双主机配置
Master1配置
修改配置文件: vim /etc/my.cnf#主服务器唯一IDserver-id=1#启用二进制日志log-bin=mysql-bin# 设置不要复制的数据库(可设置多个)binlog-ignore-db=mysqlbinlog-ignore-db=information_schema#设置需要复制的数据库binlog-do-db=需要复制的主数据库名字#设置logbin格式binlog_format=STATEMENT# 在作为从数据库的时候, 有写入操作也要更新二进制日志文件log-slave-updates#表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1, 取值范围是1 .. 65535auto-increment-increment=2# 表示自增长字段从哪个数开始,指字段一次递增多少,他的取值范围是1 .. 65535auto-increment-offset=1
Master2配置
修改配置文件: vim /etc/my.cnf#主服务器唯一IDserver-id=3#启用二进制日志log-bin=mysql-bin# 设置不要复制的数据库(可设置多个)binlog-ignore-db=mysqlbinlog-ignore-db=information_schema#设置需要复制的数据库binlog-do-db=需要复制的主数据库名字#设置logbin格式binlog_format=STATEMENT# 在作为从数据库的时候,有写入操作也要更新二进制日志文件log-slave-updates#表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1,取值范围是1 .. 65535auto-increment-increment=2# 表示自增长字段从哪个数开始,指字段一次递增多少,他的取值范围是1 .. 65535auto-increment-offset=2
② 双从机配置
Slave1配置
修改配置文件: vim /etc/my.cnf#从服务器唯一IDserver-id=2#启用中继日志relay-log=mysql-relay
Slave2配置
修改配置文件: vim /etc/my.cnf#从服务器唯一IDserver-id=4#启用中继日志relay-log=mysql-relay
③ 双主机、 双从机重启 mysql 服务
④ 主机从机都关闭防火墙
⑤ 在两台主机上建立帐户并授权 slave
#在主机MySQL里执行授权命令GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY '123123';#查询Master1的状态show master status;

#查询Master2的状态show master status;

#分别记录下File和Position的值#执行完此步骤后不要再操作主服务器MYSQL,防止主服务器状态值变化
⑥ 在从机上配置需要复制的主机
Slava1 复制 Master1, Slava2 复制 Master2
#复制主机的命令CHANGE MASTER TO MASTER_HOST='主机的IP地址',MASTER_USER='slave',MASTER_PASSWORD='123123',MASTER_LOG_FILE='mysql-bin.具体数字',MASTER_LOG_POS=具体值;Slava1的复制命令

Slava2的复制命令

#启动两台从服务器复制功能start slave;#查看从服务器状态show slave status\G;
#Slava1的复制Master1
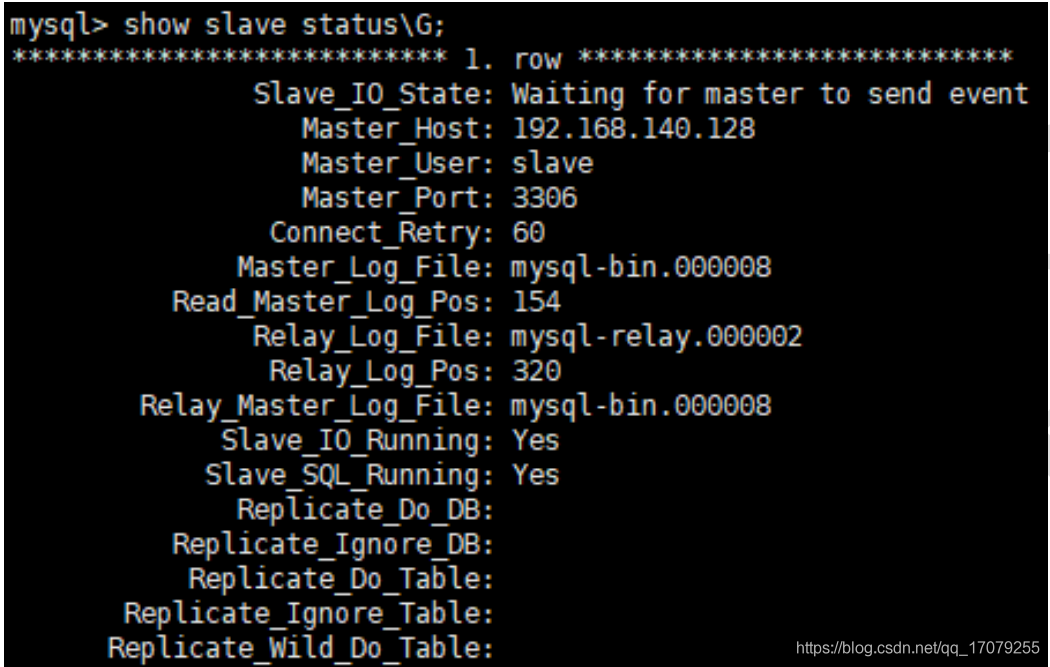
#Slava2的复制Master2
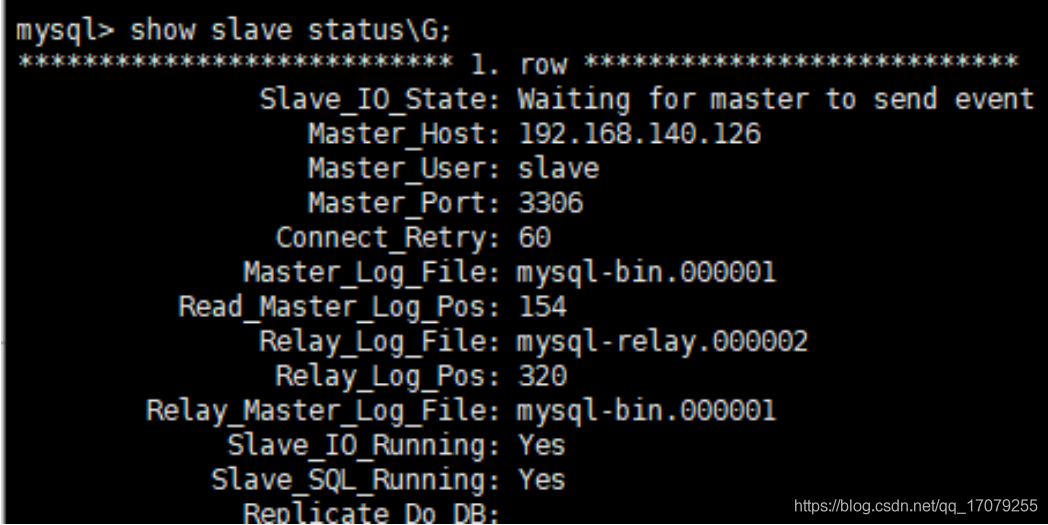
#下面两个参数都是Yes,则说明主从配置成功!# Slave_IO_Running: Yes# Slave_SQL_Running: Yes
⑦ 两个主机互相复制
Master2 复制 Master1, Master1 复制 Master2
# Master2的复制命令

# Master1的复制命令

#启动两台主服务器复制功能start slave;#查看从服务器状态show slave status\G;Master2的复制Master1
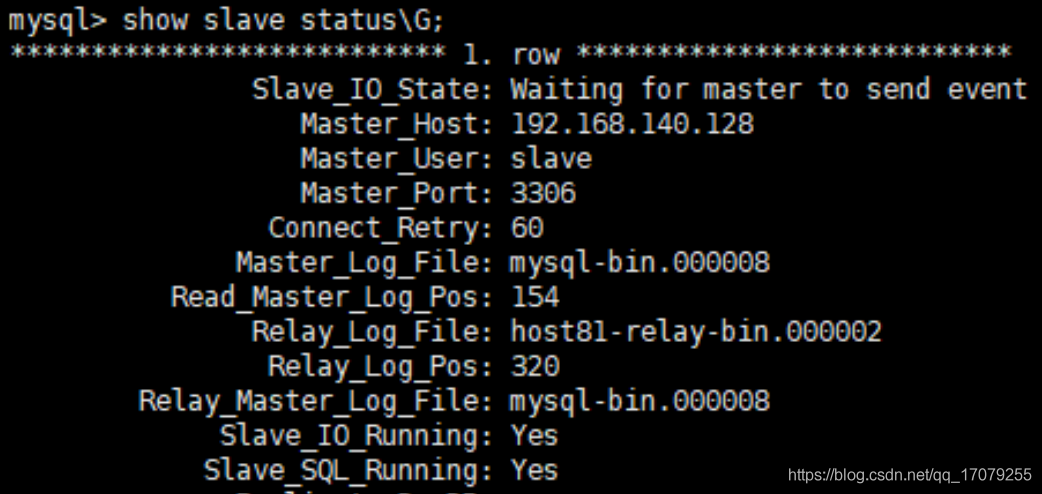
Master1的复制Master2
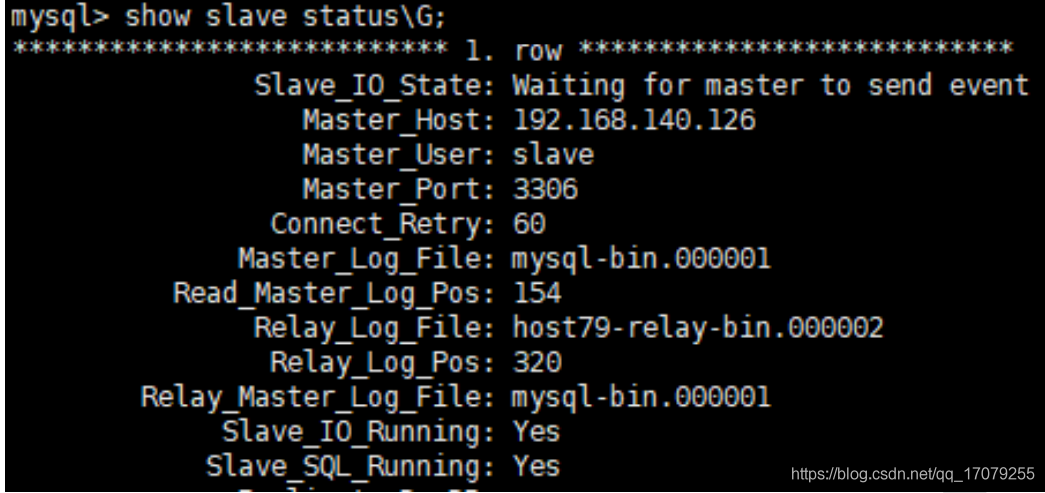
#下面两个参数都是Yes,则说明主从配置成功!# Slave_IO_Running: Yes# Slave_SQL_Running: Yes
⑧ Master1 主机新建库、新建表、 insert 记录, Master2 和从机复制
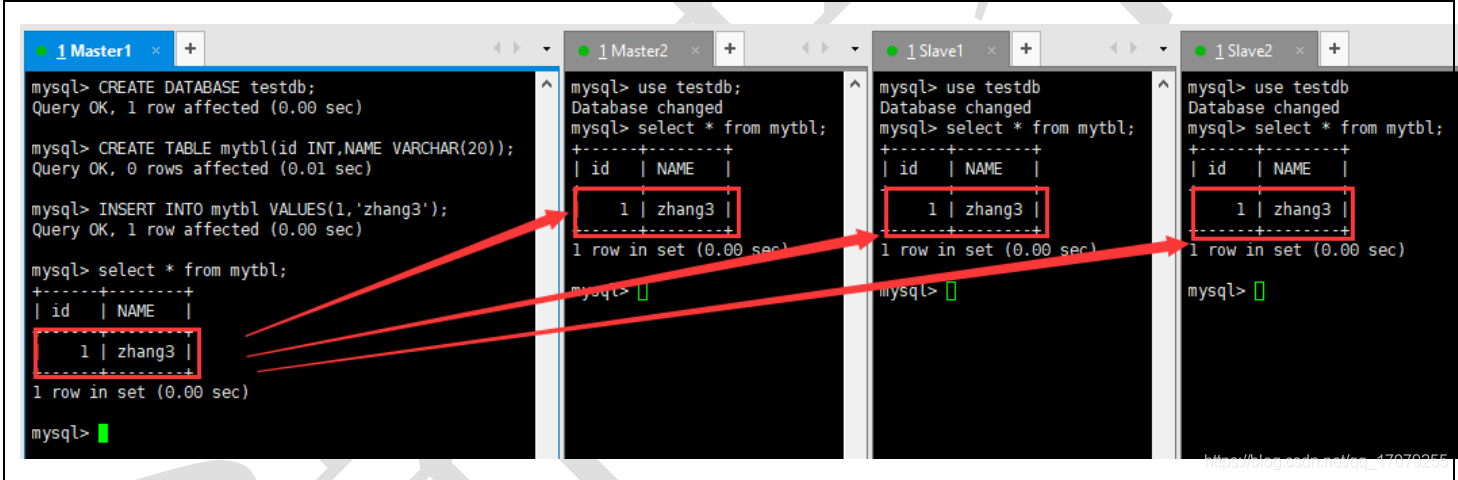
⑨ 如何停止从服务复制功能
stop slave;
⑩ 如何重新配置主从
stop slave;reset master;
2、 修改 Mycat 的配置文件 schema.xml
修改的balance属性,通过此属性配置读写分离的类型
负载均衡类型,目前的取值有4 种:(1) balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。(2) balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1, M2->S2,并且 M1 与 M2 互为主备),正常情况下, M2,S1,S2 都参与 select 语句的负载均衡。(3) balance="2",所有读操作都随机的在 writeHost、 readhost 上分发。(4) balance="3",所有读请求随机的分发到 readhost 执行, writerHost 不负担读压力
为了双主双从读写分离balance设置为1
…<dataNode name="dn1" dataHost="host1" database="testdb" /><dataHost name="host1" maxCon="1000" minCon="10" balance="1"writeType="0" dbType="mysql" dbDriver="native" switchType="1"slaveThreshold="100" ><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="hostM1" url="192.168.140.128:3306" user="root"password="123123"><!-- can have multi read hosts --><readHost host="hostS1" url="192.168.140.127:3306" user="root"password="123123" /></writeHost><writeHost host="hostM2" url="192.168.140.126:3306" user="root"password="123123"><!-- can have multi read hosts --><readHost host="hostS2" url="192.168.140.125:3306" user="root"password="123123" /></writeHost></dataHost>… #balance="1": 全部的readHost与stand by writeHost参与select语句的负载均衡。#writeType="0": 所有写操作发送到配置的第一个writeHost,第一个挂了切到还生存的第二个#writeType="1",所有写操作都随机的发送到配置的 writeHost, 1.5 以后废弃不推荐#writeHost,重新启动后以切换后的为准,切换记录在配置文件中:dnindex.properties 。#switchType="1": 1 默认值,自动切换。# -1 表示不自动切换# 2 基于 MySQL 主从同步的状态决定是否切换。
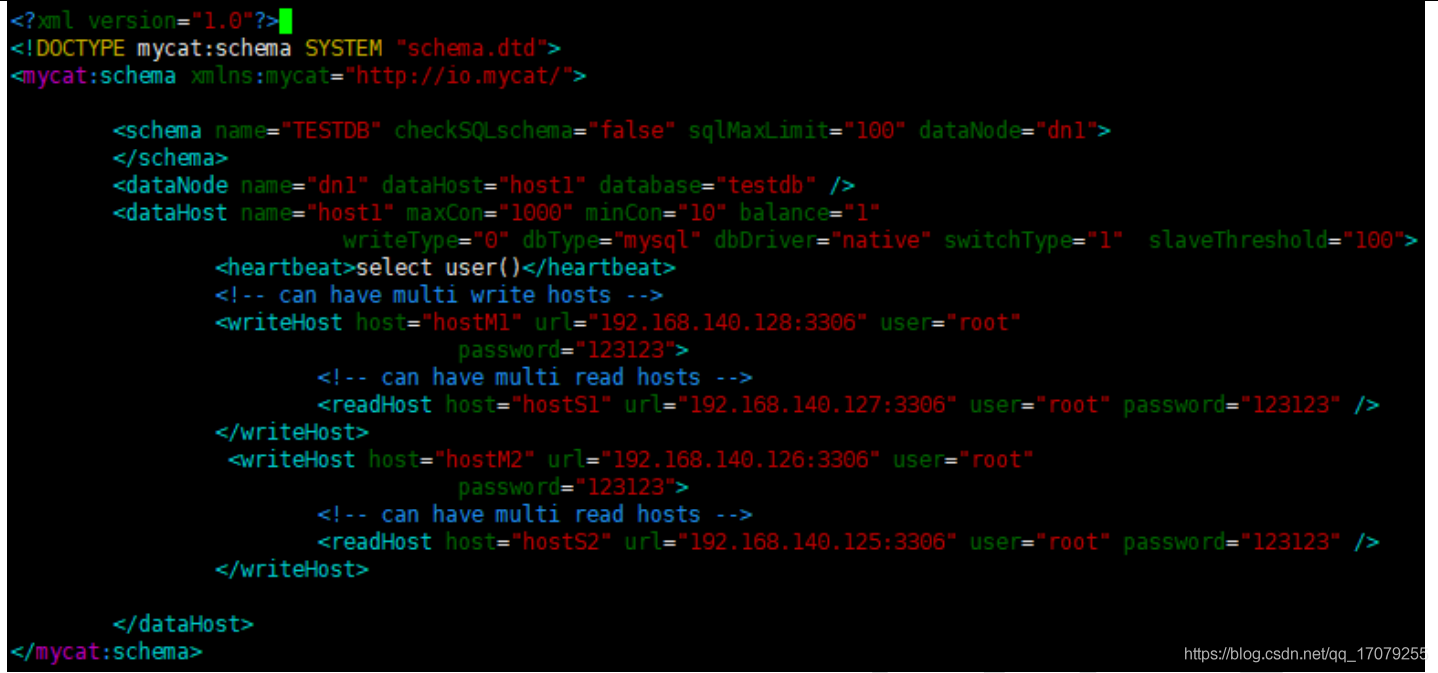
3、 启动 Mycat
4、 验证读写分离
#在写主机Master1数据库表mytbl中插入带系统变量数据, 造成主从数据不一致INSERT INTO mytbl VALUES(3,@@hostname);
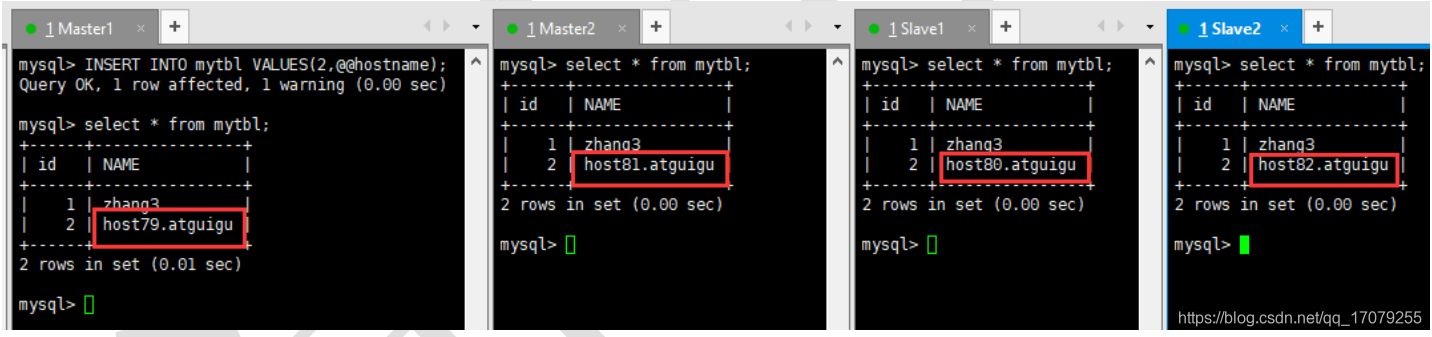
#在Mycat里查询mytbl表,可以看到查询语句在Master2(host81) 、 Slava1(host80) 、 Slava2(host82)主从三个主机间切换
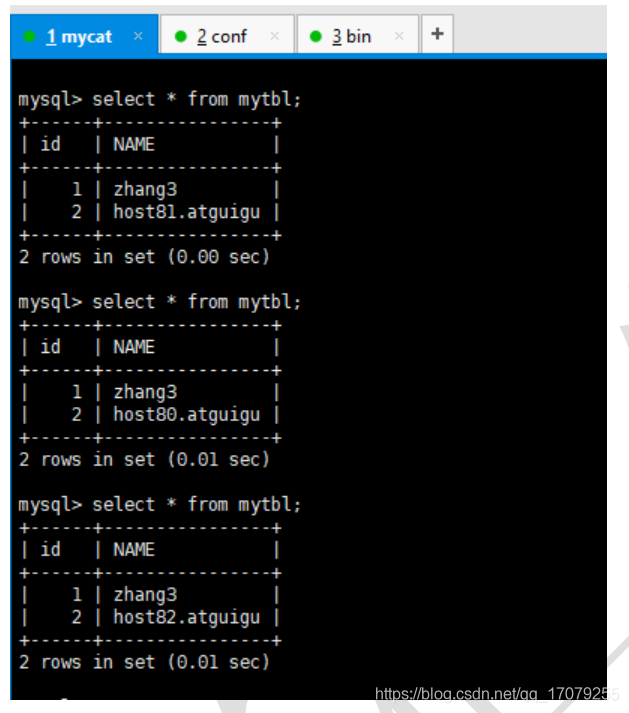
5、 抗风险能力
#停止数据库Master1
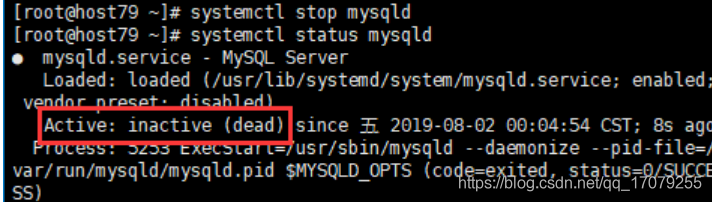
#在Mycat里插入数据依然成功, Master2自动切换为写主机INSERT INTO mytbl VALUES(3,@@hostname);
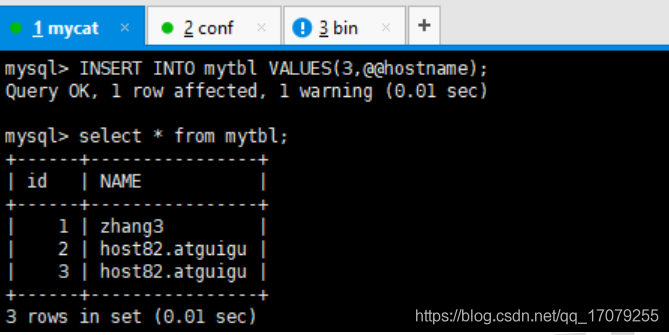
#启动数据库Master1
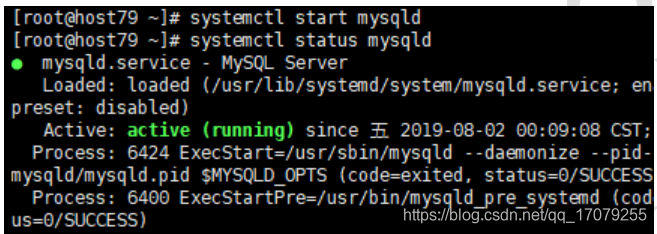
#在Mycat里查询mytbl表,可以看到查询语句在Master1(host79) 、 Slava1(host80) 、 Slava2(host82)主从三个主机间切换
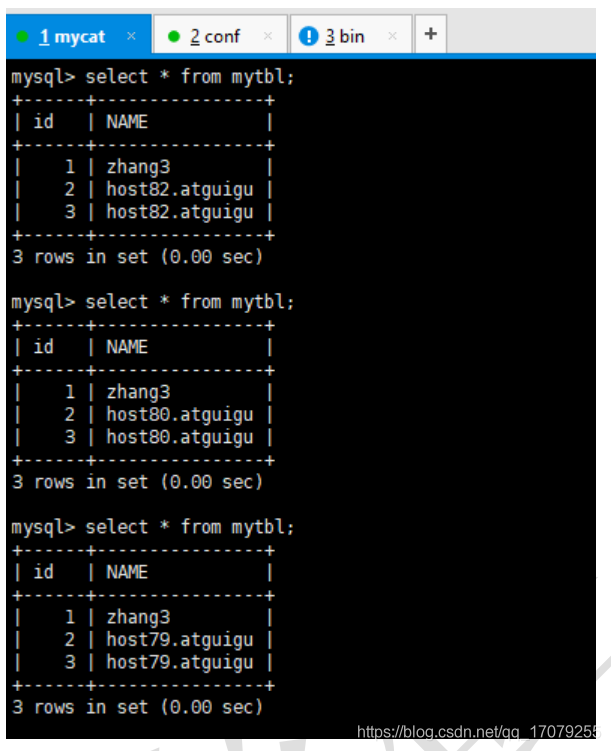
Master1、 Master2 互做备机,负责写的主机宕机,备机切换负责写操作,保证数据库读写分离高可用性。
第四章 垂直拆分——分库
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同 的数据库上面,这样也就将数据或者说压力分担到不同的库上面,如下图:
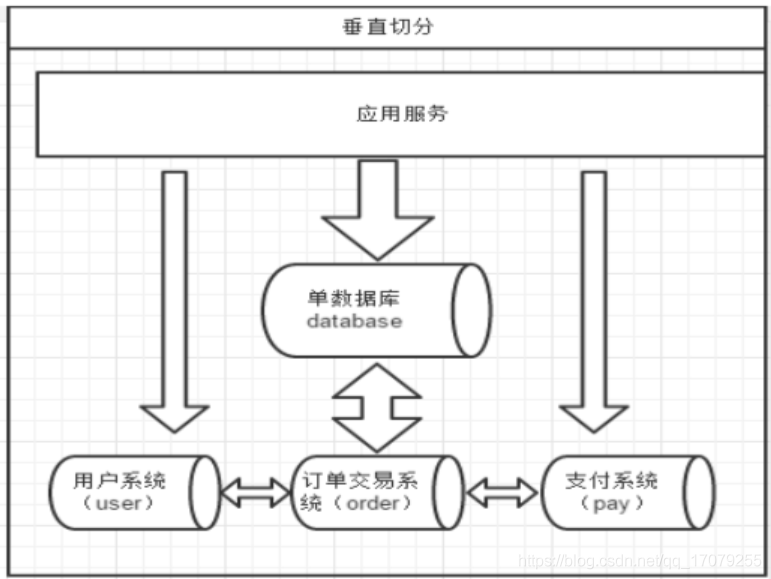
系统被切分成了,用户,订单交易,支付几个模块。
4.1 如何划分表
一个问题:在两台主机上的两个数据库中的表,能否关联查询?
答案:不可以关联查询
分库的原则: 有紧密关联关系的表应该在一个库里,相互没有关联关系的表可以分到不同的库里。
#客户表 rows:20万CREATE TABLE customer(id INT AUTO_INCREMENT,NAME VARCHAR(200),PRIMARY KEY(id));#订单表 rows:600万CREATE TABLE orders(id INT AUTO_INCREMENT,order_type INT,customer_id INT,amount DECIMAL(10,2),PRIMARY KEY(id));#订单详细表 rows:600万CREATE TABLE orders_detail(id INT AUTO_INCREMENT,detail VARCHAR(2000),order_id INT,PRIMARY KEY(id));#订单状态字典表 rows:20CREATE TABLE dict_order_type(id INT AUTO_INCREMENT,order_type VARCHAR(200),PRIMARY KEY(id));
以上四个表如何分库?客户表分在一个数据库,另外三张都需要关联查询,分在另外一个数据库。
4.2 实现分库
1、 修改 schema 配置文件
…<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"><table name="customer" dataNode="dn2" ></table></schema><dataNode name="dn1" dataHost="host1" database="orders" /><dataNode name="dn2" dataHost="host2" database="orders" /><dataHost name="host1" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="hostM1" url="192.168.140.128:3306" user="root"password="123123"></writeHost></dataHost><dataHost name="host2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="hostM2" url="192.168.140.127:3306" user="root"password="123123"></writeHost></dataHost>…#如下图
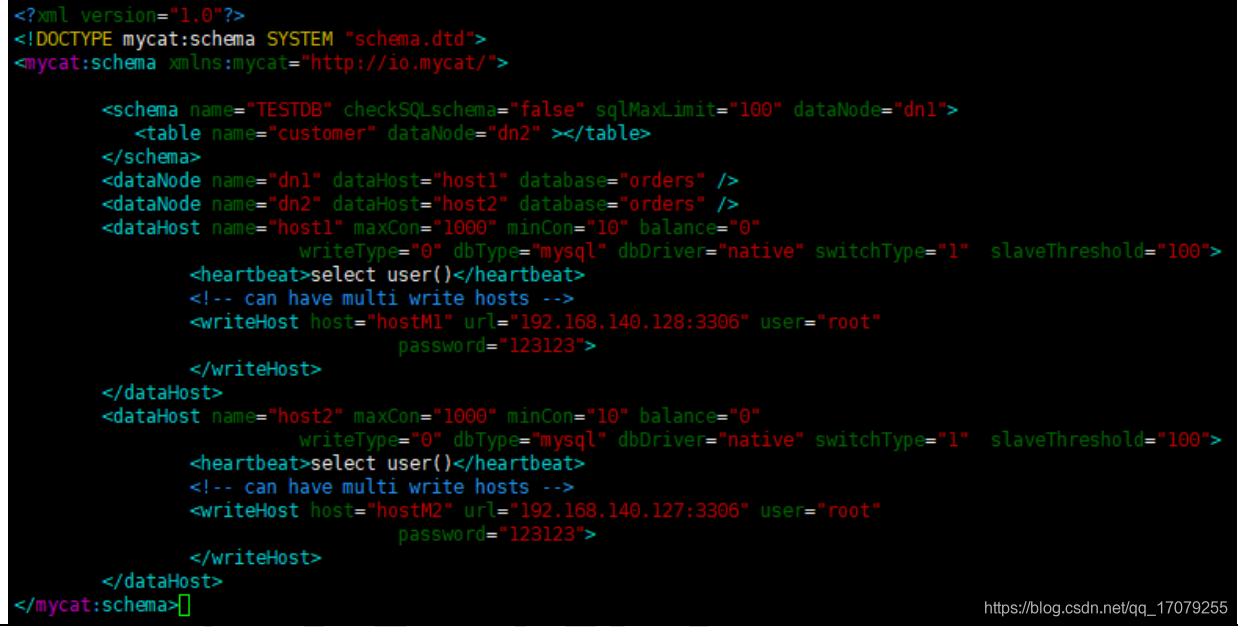

2、 新增两个空白库
分库操作不是在原来的老数据库上进行操作,需要准备两台机器分别安装新的数据库
#在数据节点 dn1、 dn2 上分别创建数据库 ordersCREATE DATABASE orders;
3、 启动 Mycat
./mycat console
4、 访问 Mycat 进行分库
#访问 Mycatmysql -umycat -p123456 -h 192.168.140.128 -P 8066#切换到 TESTDB#创建 4 张表#查看表信息,可以看到成功分库
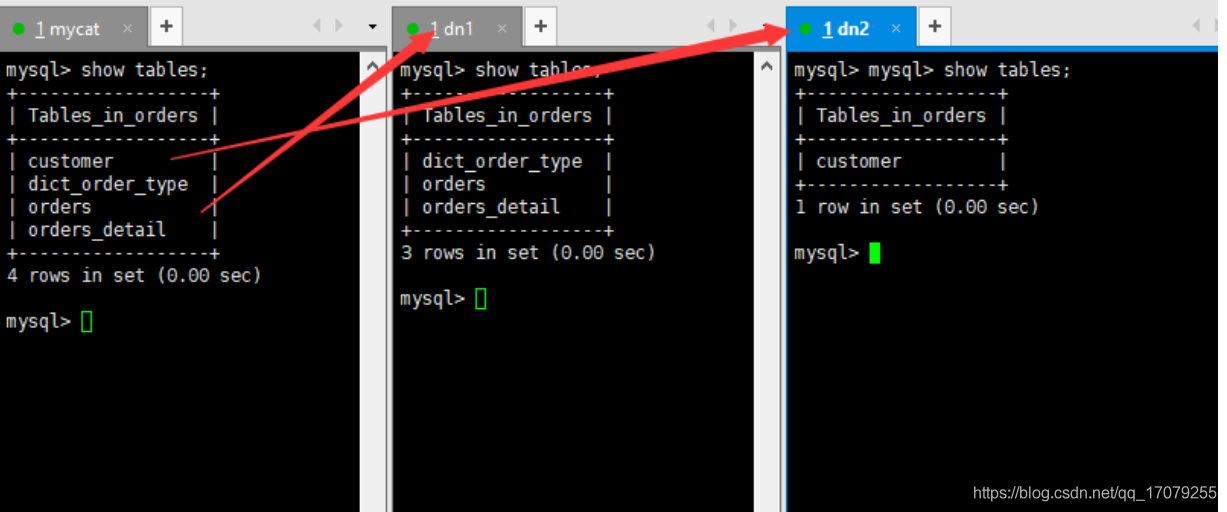
第五章 水平拆分——分表
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中 包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分 到一个数据库,而另外的某些行又切分到其他的数据库中,如图:
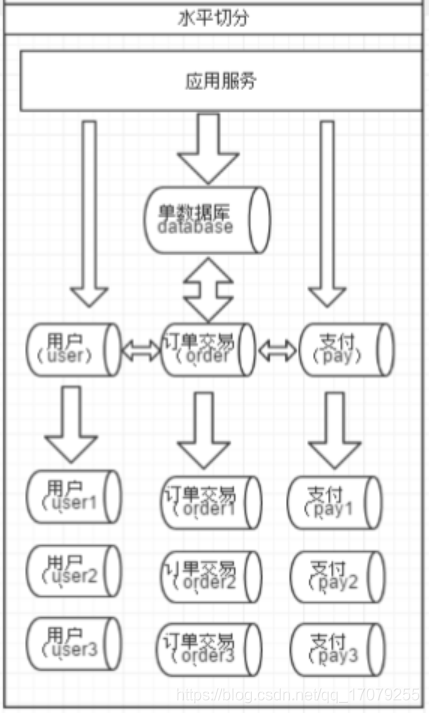
5.1 实现分表
1、 选择要拆分的表
MySQL 单表存储数据条数是有瓶颈的,单表达到 1000 万条数据就达到了瓶颈,会影响查询效率,需要进行水平拆分(分表) 进行优化。
例如:例子中的 orders、 orders_detail 都已经达到 600 万行数据,需要进行分表优化。
2、 分表字段
以 orders 表为例,可以根据不同自字段进行分表
| 编号 | 分表字段 | 效果 |
|---|---|---|
| 1 | id(主键、 或创建时间) | 查询订单注重时效,历史订单被查询的次数少,如此分片会造成一个节点访问多,一个访问少,不平均。 |
| 2 | customer_id(客户 id) | 根据客户 id 去分,两个节点访问平均,一个客户的所 有订单都在同一个节点 |
3、 修改配置文件 schema.xml
#为 orders 表设置数据节点为 dn1、 dn2, 并指定分片规则为 mod_rule(自定义的名字)<table name="orders" dataNode="dn1,dn2" rule="mod_rule" ></table>#如下图

4、 修改配置文件 rule.xml
#在 rule 配置文件里新增分片规则 mod_rule,并指定规则适用字段为 customer_id,#还有选择分片算法 mod-long(对字段求模运算) , customer_id 对两个节点求模,根据结果分片#配置算法 mod-long 参数 count 为 2,两个节点<tableRule name="mod_rule"><rule><columns>customer_id</columns><algorithm>mod-long</algorithm></rule></tableRule>…<function name="mod-long" class="io.mycat.route.function.PartitionByMod"><!-- how many data nodes --><property name="count">2</property></function>#如下图:
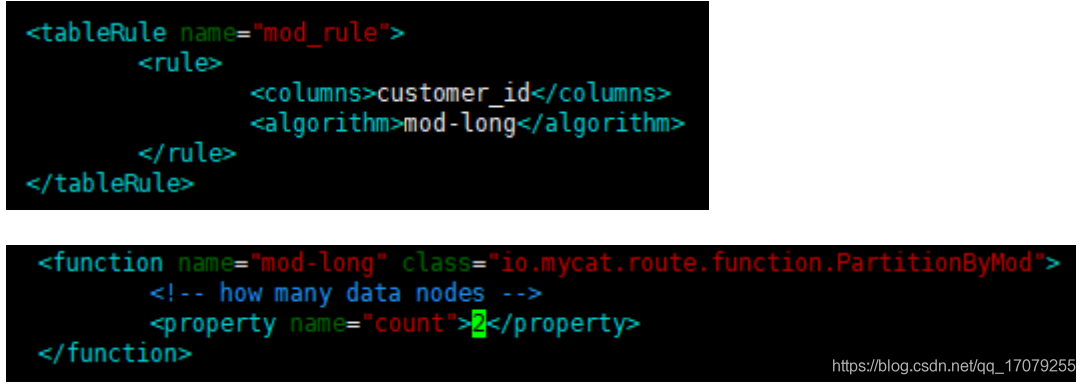
5、 在数据节点 dn2 上建 orders 表
6、 重启 Mycat,让配置生效
7、 访问 Mycat 实现分片
#在 mycat 里向 orders 表插入数据, INSERT 字段不能省略INSERT INTO orders(id,order_type,customer_id,amount) VALUES (1,101,100,100100);INSERT INTO orders(id,order_type,customer_id,amount) VALUES(2,101,100,100300);INSERT INTO orders(id,order_type,customer_id,amount) VALUES(3,101,101,120000);INSERT INTO orders(id,order_type,customer_id,amount) VALUES(4,101,101,103000);INSERT INTO orders(id,order_type,customer_id,amount) VALUES(5,102,101,100400);INSERT INTO orders(id,order_type,customer_id,amount) VALUES(6,102,100,100020);
#在mycat、 dn1、 dn2中查看orders表数据,分表成功
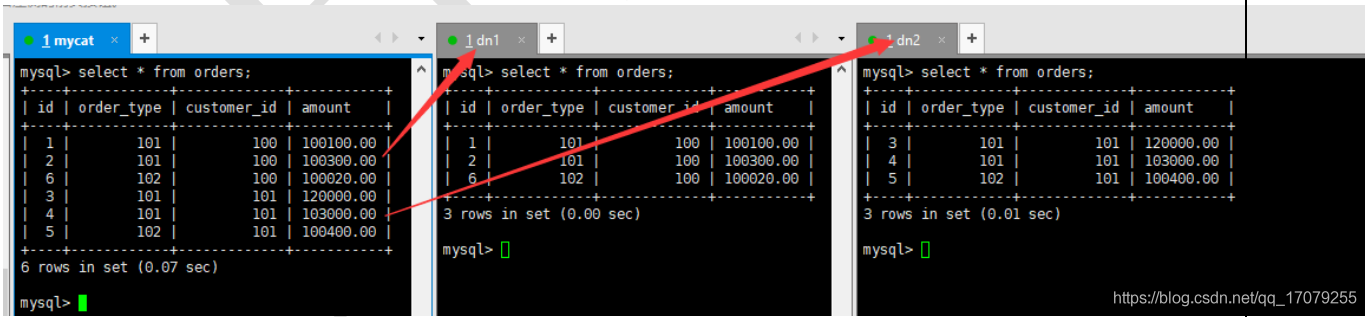
5.2 Mycat 的分片 “join”
Orders 订单表已经进行分表操作了,和它关联的 orders_detail 订单详情表如何进行 join 查询。我们要对 orders_detail 也要进行分片操作。 Join 的原理如下图:
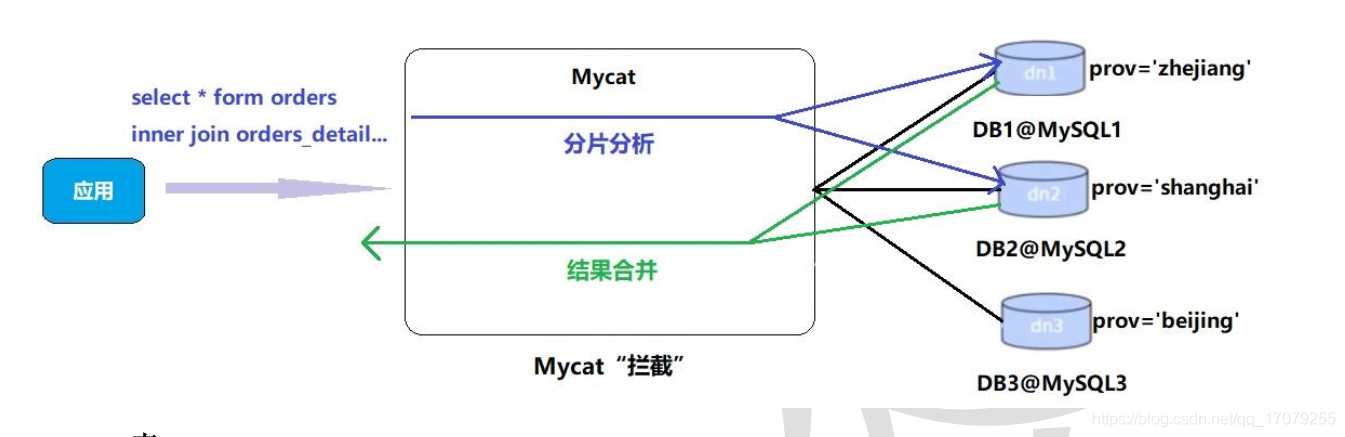
1、 ER 表
Mycat 借鉴了 NewSQL 领域的新秀 Foundation DB 的设计思路, Foundation DB 创新性的提出了 Table Group 的概念,其将子表的存储位置依赖于主表,并且物理上紧邻存放,因此彻底解决了JION 的效率和性能问 题,根据这一思路,提出了基于 E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上。
#修改 schema.xml 配置文件…<table name="orders" dataNode="dn1,dn2" rule="mod_rule" > <childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" /></table>…

#在dn2 创建 orders_detail 表#重启 Mycat#访问 Mycat 向 orders_detail 表插入数据INSERT INTO orders_detail(id,detail,order_id) values(1,'detail1',1);INSERT INTO orders_detail(id,detail,order_id) VALUES(2,'detail1',2);INSERT INTO orders_detail(id,detail,order_id) VALUES(3,'detail1',3);INSERT INTO orders_detail(id,detail,order_id) VALUES(4,'detail1',4);INSERT INTO orders_detail(id,detail,order_id) VALUES(5,'detail1',5);INSERT INTO orders_detail(id,detail,order_id) VALUES(6,'detail1',6);#在mycat、 dn1、 dn2中运行两个表join语句Select o.*,od.detail from orders o inner join orders_detail od on o.id=od.order_id;
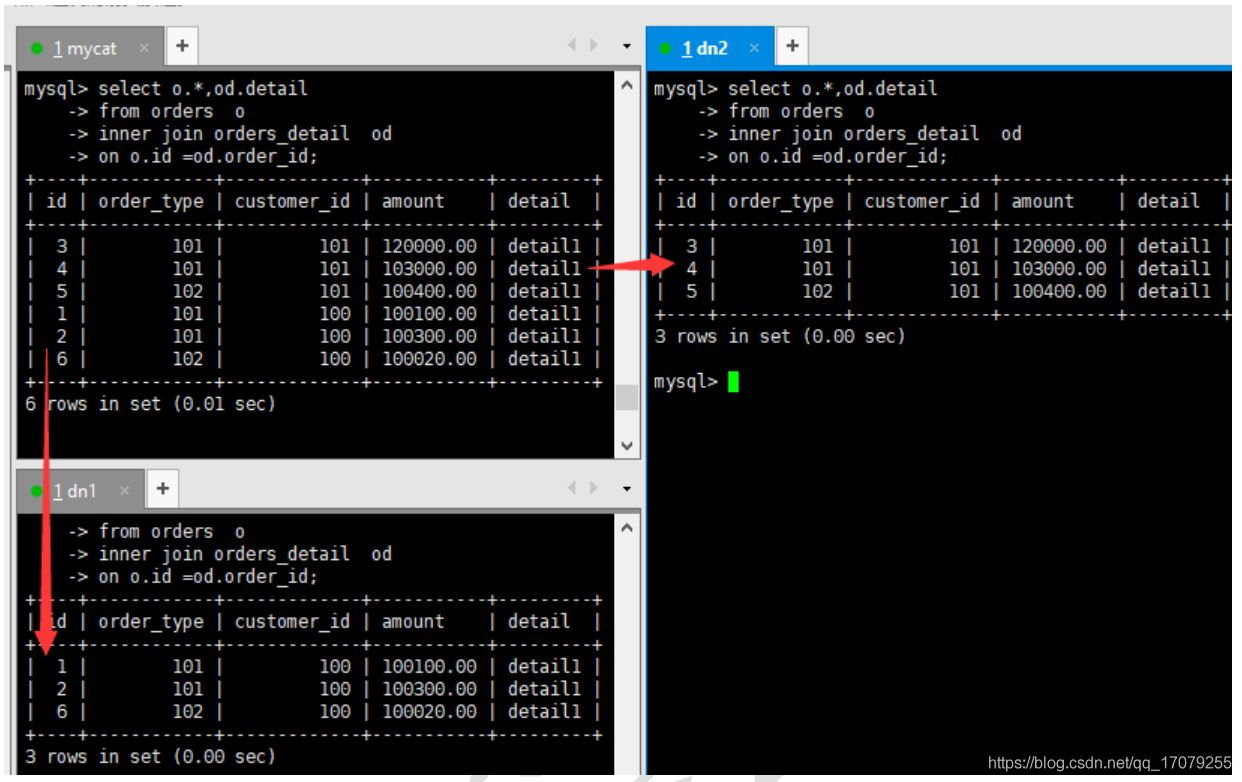
2、 全局表
在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较 棘手的问题,考虑到字典表具有以下几个特性:
① 变动不频繁
② 数据量总体变化不大
③ 数据规模不大,很少有超过数十万条记录
鉴于此, Mycat 定义了一种特殊的表,称之为“全局表”,全局表具有以下特性:
① 全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
② 全局表的查询操作,只从一个节点获取
③ 全局表可以跟任何一个表进行 JOIN 操作
将字典表或者符合字典表特性的一些表定义为全局表,则从另外一个方面,很好的解决了数据JOIN 的难题。 通过全局表+基于 E-R 关系的分片策略, Mycat 可以满足 80%以上的企业应用开发
#修改 schema.xml 配置文件…<table name="orders" dataNode="dn1,dn2" rule="mod_rule" ><childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" /></table><table name="dict_order_type" dataNode="dn1,dn2" type="global" ></table>…

#在dn2 创建 dict_order_type 表#重启 Mycat#访问 Mycat 向 dict_order_type 表插入数据INSERT INTO dict_order_type(id,order_type) VALUES(101,'type1');INSERT INTO dict_order_type(id,order_type) VALUES(102,'type2');#在Mycat、 dn1、 dn2中查询表数据
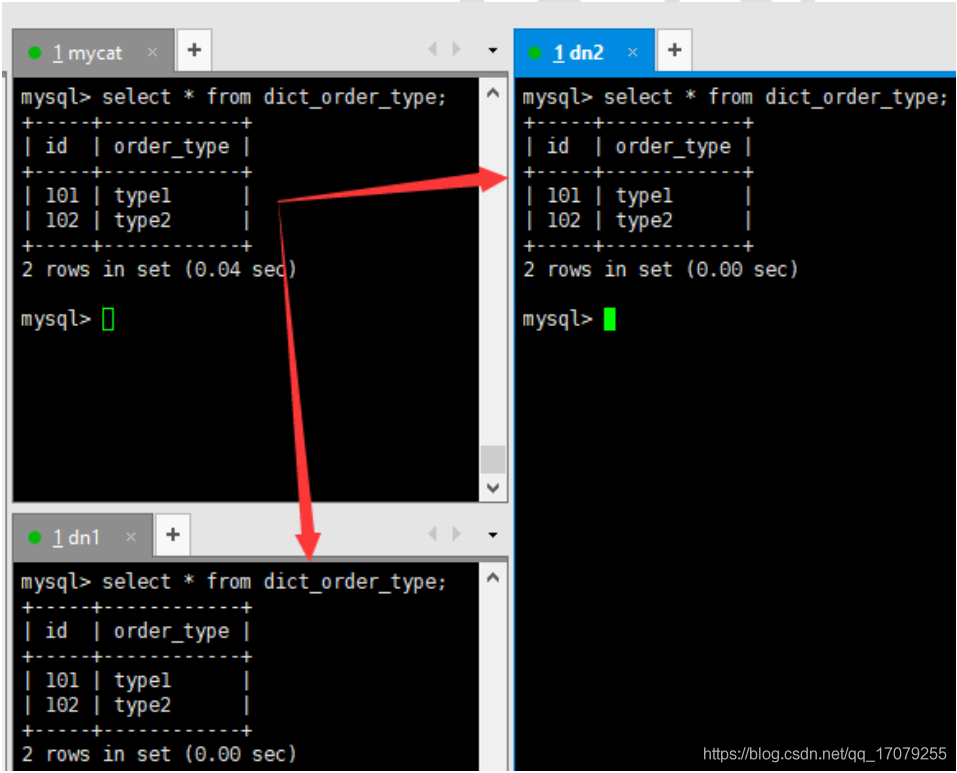
5.3 常用分片规则
1、 取模
此规则为对分片字段求摸运算。 也是水平分表最常用规则。 5.1 配置分表中, orders 表采用了此规则。
2、 分片枚举
通过在配置文件中配置可能的枚举 id,自己配置分片,本规则适用于特定的场景,比如有些业务需要按照省份或区县来做保存,而全国省份区县固定的,这类业务使用本条规则。
#(1) 修改schema.xml配置文件<table name="orders_ware_info" dataNode="dn1,dn2" rule="sharding_by_intfile" ></table>#(2) 修改rule.xml配置文件<tableRule name="sharding_by_intfile"><rule><columns>areacode</columns><algorithm>hash-int</algorithm></rule></tableRule>…<function name="hash-int"class="io.mycat.route.function.PartitionByFileMap"><property name="mapFile">partition-hash-int.txt</property><property name="type">1</property><property name="defaultNode">0</property></function># columns:分片字段, algorithm:分片函数# mapFile: 标识配置文件名称, type: 0为int型、 非0为String,#defaultNode: 默认节点:小于 0 表示不设置默认节点,大于等于 0 表示设置默认节点,# 设置默认节点如果碰到不识别的枚举值,就让它路由到默认节点,如不设置不识别就报错#(3) 修改partition-hash-int.txt配置文件110=0120=1#(4) 重启 Mycat#(5) 访问Mycat创建表#订单归属区域信息表CREATE TABLE orders_ware_info(`id` INT AUTO_INCREMENT comment '编号',`order_id` INT comment '订单编号',`address` VARCHAR(200) comment '地址',`areacode` VARCHAR(20) comment '区域编号',PRIMARY KEY(id));#(6) 插入数据INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (1,1,'北京','110');INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (2,2,'天津','120');#(7) 查询Mycat、 dn1、 dn2可以看到数据分片效果
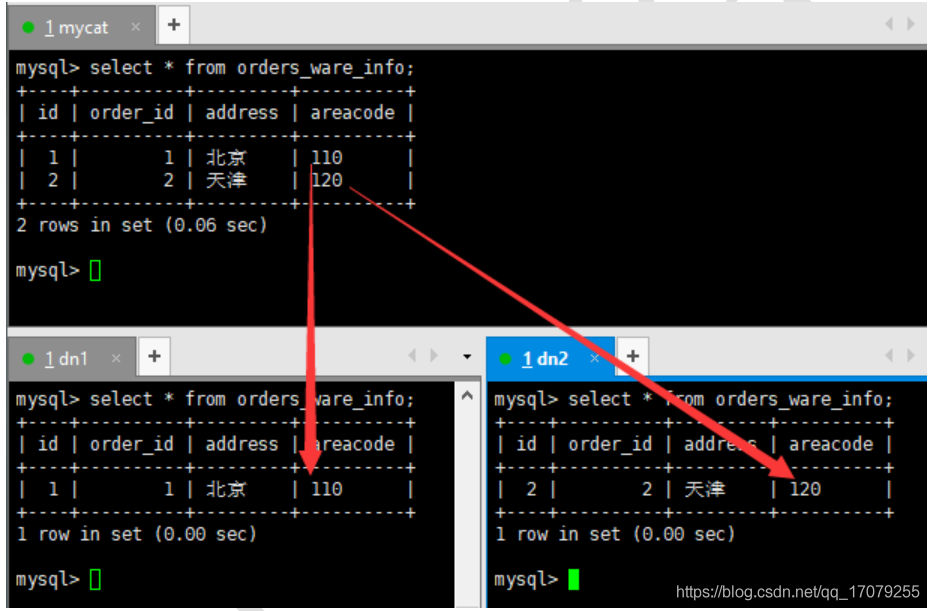
3、 范围约定
此分片适用于,提前规划好分片字段某个范围属于哪个分片。
#(1) 修改schema.xml配置文件<table name="payment_info" dataNode="dn1,dn2" rule="auto_sharding_long" ></table>#(2) 修改rule.xml配置文件<tableRule name="auto_sharding_long"><rule><columns>order_id</columns><algorithm>rang-long</algorithm></rule></tableRule>…<function name="rang-long"class="io.mycat.route.function.AutoPartitionByLong"><property name="mapFile">autopartition-long.txt</property><property name="defaultNode">0</property></function># columns:分片字段, algorithm:分片函数# mapFile: 标识配置文件名称#defaultNode: 默认节点:小于 0 表示不设置默认节点,大于等于 0 表示设置默认节点,# 设置默认节点如果碰到不识别的枚举值,就让它路由到默认节点,如不设置不识别就报错#(3) 修改autopartition-long.txt配置文件0-102=0103-200=1#(4) 重启 Mycat#(5) 访问Mycat创建表#支付信息表CREATE TABLE payment_info(`id` INT AUTO_INCREMENT comment '编号',`order_id` INT comment '订单编号',`payment_status` INT comment '支付状态',PRIMARY KEY(id));#(6) 插入数据INSERT INTO payment_info (id,order_id,payment_status) VALUES (1,101,0);INSERT INTO payment_info (id,order_id,payment_status) VALUES (2,102,1);INSERT INTO payment_info (id,order_id ,payment_status) VALUES (3,103,0);INSERT INTO payment_info (id,order_id,payment_status) VALUES (4,104,1);#(7) 查询Mycat、 dn1、 dn2可以看到数据分片效果
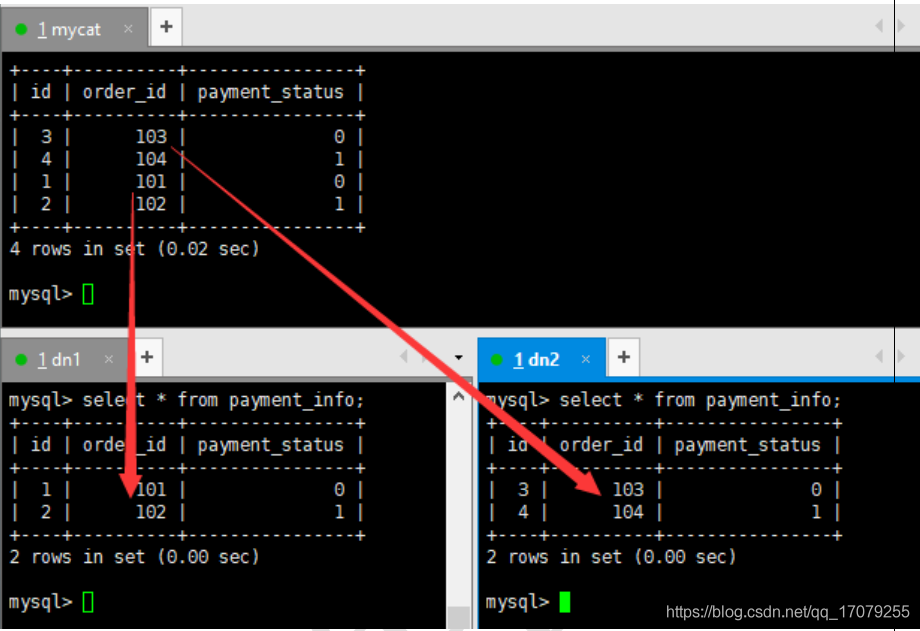
4、 按日期(天)分片
此规则为按天分片。 设定时间格式、范围
#(1) 修改schema.xml配置文件<table name="login_info" dataNode="dn1,dn2" rule="sharding_by_date" ></table>#(2) 修改rule.xml配置文件<tableRule name="sharding_by_date"><rule><columns>login_date</columns><algorithm>shardingByDate</algorithm></rule></tableRule>…<function name="shardingByDate" class="io.mycat.route.function.PartitionByDate"><property name="dateFormat">yyyy-MM-dd</property><property name="sBeginDate">2019-01-01</property><property name="sEndDate">2019-01-04</property><property name="sPartionDay">2</property></function># columns:分片字段, algorithm:分片函数#dateFormat :日期格式#sBeginDate :开始日期#sEndDate:结束日期,则代表数据达到了这个日期的分片后循环从开始分片插入#sPartionDay :分区天数,即默认从开始日期算起,分隔 2 天一个分区#(3) 重启 Mycat#(4) 访问Mycat创建表#用户信息表CREATE TABLE login_info(`id` INT AUTO_INCREMENT comment '编号',`user_id` INT comment '用户编号',`login_date` date comment '登录日期',PRIMARY KEY(id));#(6) 插入数据INSERT INTO login_info(id,user_id,login_date) VALUES (1,101,'2019-01-01');INSERT INTO login_info(id,user_id,login_date) VALUES (2,102,'2019-01-02');INSERT INTO login_info(id,user_id,login_date) VALUES (3,103,'2019-01-03');INSERT INTO login_info(id,user_id,login_date) VALUES (4,104,'2019-01-04');INSERT INTO login_info(id,user_id,login_date) VALUES (5,103,'2019-01-05');INSERT INTO login_info(id,user_id,login_date) VALUES (6,104,'2019-01-06');#(7) 查询Mycat、 dn1、 dn2可以看到数据分片效果
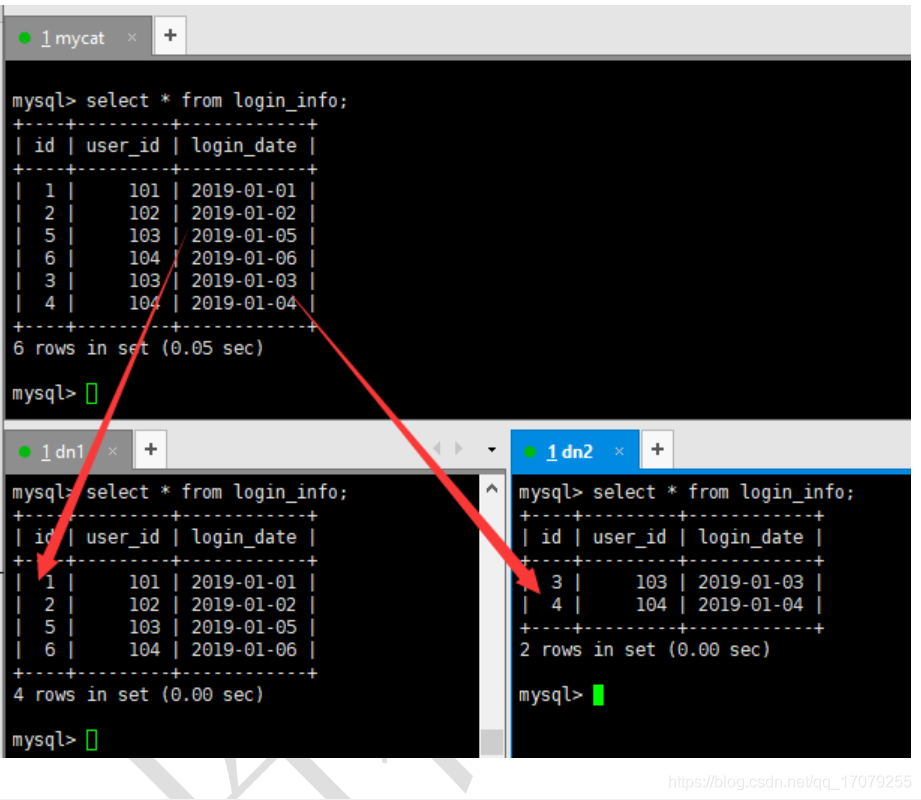
5.4 全局序列
在实现分库分表的情况下,数据库自增主键已无法保证自增主键的全局唯一。为此, Mycat 提供了全局 sequence,并且提供了包含本地配置和数据库配置等多种实现方式
1、 本地文件
此方式 Mycat 将 sequence 配置到文件中,当使用到 sequence 中的配置后, Mycat 会更下classpath 中的 sequence_conf.properties 文件中 sequence 当前的值。
① 优点: 本地加载,读取速度较快
② 缺点: 抗风险能力差, Mycat 所在主机宕机后,无法读取本地文件。
2、 数据库方式(推荐)
利用数据库一个表 来进行计数累加。但是并不是每次生成序列都读写数据库,这样效率太低。Mycat 会预加载一部分号段到 Mycat 的内存中,这样大部分读写序列都是在内存中完成的。如果内存中的号段用完了 Mycat 会再向数据库要一次。
问:那如果 Mycat 崩溃了 ,那内存中的序列岂不是都没了?
是的。如果是这样,那么 Mycat 启动后会向数据库申请新的号段,原有号段会弃用。
也就是说如果 Mycat 重启,那么损失是当前的号段没用完的号码,但是不会因此出现主键重复
① 建库序列脚本
#在 dn1 上创建全局序列表CREATE TABLE MYCAT_SEQUENCE (NAME VARCHAR(50) NOT NULL,current_value INT NOTNULL,increment INT NOT NULL DEFAULT 100, PRIMARY KEY(NAME)) ENGINE=INNODB;#创建全局序列所需函数DELIMITER $$CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)DETERMINISTICBEGINDECLARE retval VARCHAR(64);SET retval="-999999999,null";SELECT CONCAT(CAST(current_value AS CHAR),",",CAST(increment AS CHAR)) INTO retval FROMMYCAT_SEQUENCE WHERE NAME = seq_name;RETURN retval;END $$DELIMITER ;DELIMITER $$CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),VALUE INTEGER) RETURNSVARCHAR(64)DETERMINISTICBEGINUPDATE MYCAT_SEQUENCESET current_value = VALUEWHERE NAME = seq_name;RETURN mycat_seq_currval(seq_name);END $$DELIMITER ;DELIMITER $$CREATE FUNCTION mycat_seq_nextval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)DETERMINISTICBEGINUPDATE MYCAT_SEQUENCESET current_value = current_value + increment WHERE NAME = seq_name;RETURN mycat_seq_currval(seq_name);END $$DELIMITER ;#初始化序列表记录INSERT INTO MYCAT_SEQUENCE(NAME,current_value,increment) VALUES ('ORDERS', 400000,100);
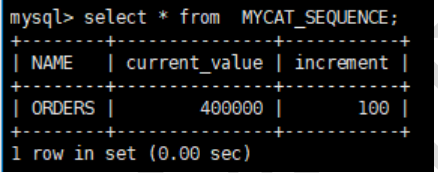
② 修改 Mycat 配置
#修改sequence_db_conf.propertiesvim sequence_db_conf.properties#意思是 ORDERS这个序列在dn1这个节点上,具体dn1节点是哪台机子,请参考schema.xml
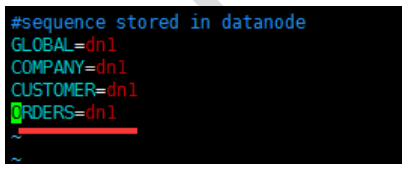
#修改server.xmlvim server.xml#全局序列类型: 0-本地文件, 1-数据库方式, 2-时间戳方式。此处应该修改成1。

#重启Mycat
③ 验证全局序列
#登录 Mycat,插入数据insert into orders(id,amount,customer_id,order_type) values(next value forMYCATSEQ_ORDERS,1000,101,102);#查询数据
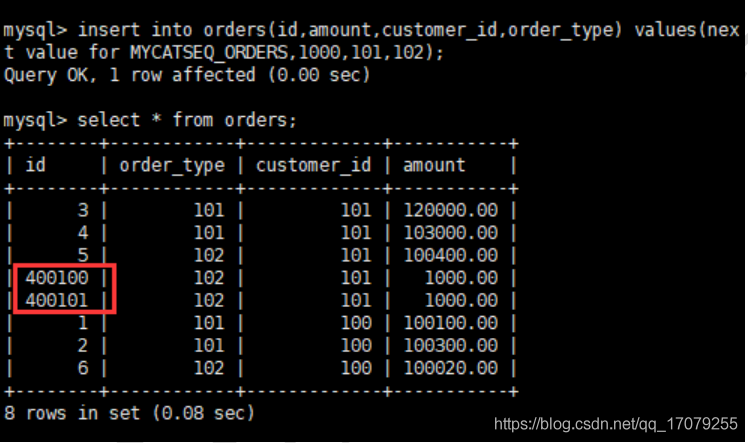
#重启Mycat后,再次插入数据,再查询
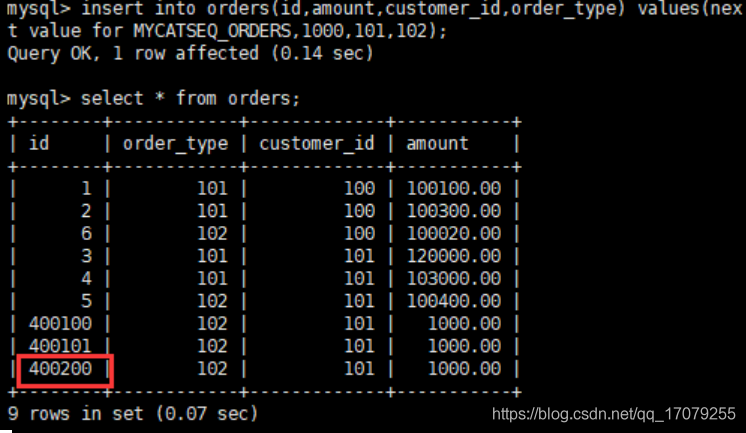
3、 时间戳方式
全局序列ID= 64 位二进制 (42(毫秒)+5(机器 ID)+5(业务编码)+12(重复累加) 换算成十进制为 18 位数的long 类型,每毫秒可以并发 12 位二进制的累加。
① 优点: 配置简单
② 缺点: 18 位 ID 过长
4、 自主生成全局序列
可在 java 项目里自己生成全局序列,如下:
① 根据业务逻辑组合
② 可以利用 redis 的单线程原子性 incr 来生成序列,但,自主生成需要单独在工程中用 java 代码实现, 还是推荐使用 Mycat 自带全局序列。
第六章 基于 HA 机制的 Mycat 高可用
在实际项目中, Mycat 服务也需要考虑高可用性,如果 Mycat 所在服务器出现宕机,或 Mycat 服务故障,需要有备机提供服务,需要考虑 Mycat 集群。
6.1 高可用方案
我们可以使用 HAProxy + Keepalived 配合两台 Mycat 搭起 Mycat 集群,实现高可用性。 HAProxy实现了 MyCat 多节点的集群高可用和负载均衡, 而 HAProxy 自身的高可用则可以通过 Keepalived 来实现。
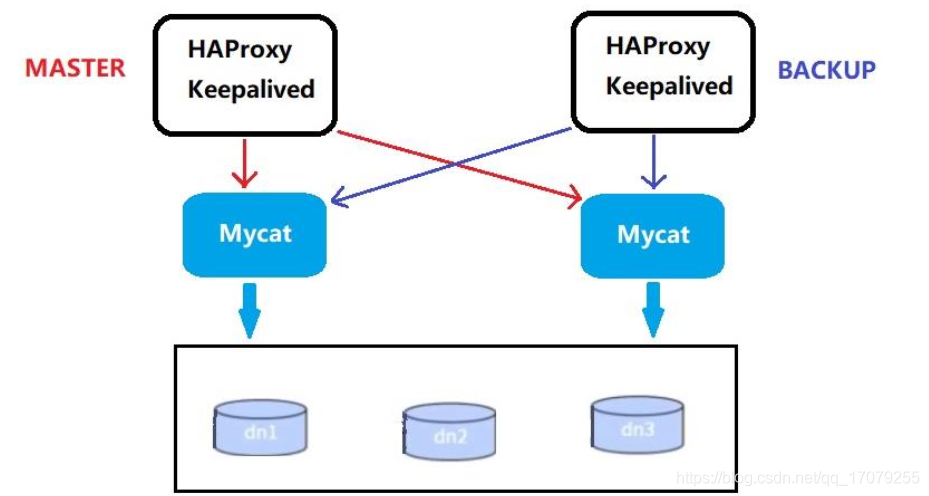
| 编号 | 角色 | IP 地址 | 机器名 |
|---|---|---|---|
| 1 | Mycat1 | 192.168.140.128 | host79.atguigu |
| 2 | Mycat2 | 192.168.140.127 | host80.atguigu |
| 3 | HAProxy(master) | 192.168.140.126 | host81.atguigu |
| 4 | Keepalived(master) | 192.168.140.126 | host81.atguigu |
| 5 | HAProxy(backup) | 192.168.140.125 | host82.atguigu |
| 6 | Keepalived(backup) | 192.168.140.125 | host82.atguigu |
6.2 安装配置 HAProxy
1、 安装 HAProxy
#1准备好HAProxy安装包,传到/opt目录下#2解压到/usr/local/srctar -zxvf haproxy-1.5.18.tar.gz -C /usr/local/src#3进入解压后的目录,查看内核版本, 进行编译cd /usr/local/src/haproxy-1.5.18uname -rmake TARGET=linux310 PREFIX=/usr/local/haproxy ARCH=x86_64# ARGET=linux310,内核版本,使用uname -r查看内核,如: 3.10.0-514.el7,此时该参数就为linux310;#ARCH=x86_64,系统位数;#PREFIX=/usr/local/haprpxy #/usr/local/haprpxy,为haprpxy安装路径。#4编译完成后,进行安装make install PREFIX=/usr/local/haproxy#5安装完成后, 创建目录、 创建HAProxy配置文件mkdir -p /usr/data/haproxy/vim /usr/local/haproxy/haproxy.conf#6向配置文件中插入以下配置信息,并保存global log 127.0.0.1 local0 #log 127.0.0.1 local1 notice #log loghost local0 info maxconn 4096 chroot /usr/local/haproxy pidfile /usr/data/haproxy/haproxy.pid uid 99 gid 99 daemon #debug #quiet defaults log global mode tcp option abortonclose option redispatch retries 3 maxconn 2000 timeout connect 5000 timeout client 50000 timeout server 50000 listen proxy_status bind :48066 mode tcp balance roundrobin server mycat_1 192.168.140.128:8066 check inter 10s server mycat_2 192.168.140.127:8066 check inter 10sfrontend admin_stats bind :7777 mode http stats enable option httplog maxconn 10 stats refresh 30s stats uri /admin stats auth admin:123123 stats hide-version stats admin if TRUE
2、 启动验证
#1启动HAProxy/usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/haproxy.conf#2查看HAProxy进程ps -ef|grep haproxy#3打开浏览器访问http://192.168.140.125:7777/admin#在弹出框输入用户名: admin密码: 123123#如果Mycat主备机均已启动,则可以看到如下图

#4验证负载均衡,通过HAProxy访问Mycatmysql -umycat -p123456 -h 192.168.140.126 -P 48066
6.3 配置 Keepalived
1、 安装 Keepalived
#1准备好Keepalived安装包,传到/opt目录下#2解压到/usr/local/srctar -zxvf keepalived-1.4.2.tar.gz -C /usr/local/src#3安装依赖插件yum install -y gcc openssl-devel popt-devel#3进入解压后的目录, 进行配置, 进行编译cd /usr/local/src/keepalived-1.4.2./configure --prefix=/usr/local/keepalived#4进行编译, 完成后进行安装make && make install#5运行前配置cp /usr/local/src/keepalived-1.4.2/keepalived/etc/init.d/keepalived /etc/init.d/mkdir /etc/keepalivedcp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/cp /usr/local/src/keepalived-1.4.2/keepalived/etc/sysconfig/keepalived /etc/sysconfig/cp /usr/local/keepalived/sbin/keepalived /usr/sbin/#6修改配置文件vim /etc/keepalived/keepalived.conf#修改内容如下! Configuration File for keepalivedglobal_defs { notification_email { xlcocoon@foxmail.com } notification_email_from keepalived@showjoy.com smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id LVS_DEVEL vrrp_skip_check_adv_addr vrrp_garp_interval 0 vrrp_gna_interval 0}vrrp_instance VI_1 { #主机配MASTER,备机配BACKUP state MASTER #所在机器网卡 interface ens33 virtual_router_id 51 #数值越大优先级越高 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { #虚拟IP 192.168.140.200 }}virtual_server 192.168.140.200 48066 { delay_loop 6 lb_algo rr lb_kind NAT persistence_timeout 50 protocol TCP real_server 192.168.140.125 48066 { weight 1 TCP_CHECK { connect_timeout 3 retry 3 delay_before_retry 3 } } real_server 192.168.140.126 48600 { weight 1 TCP_CHECK { connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } }}
2、 启动验证
#1启动Keepalivedservice keepalived start#2登录验证mysql -umycat -p123456 -h 192.168.140.200 -P 48066
6.4 测试高可用
1、 测试步骤
#1关闭mycat#2通过虚拟ip查询数据mysql -umycat -p123456 -h 192.168.140.200 -P 48066
第七章 Mycat 安全设置
7.1 权限配置
1、 user 标签权限控制
目前 Mycat 对于中间件的连接控制并没有做太复杂的控制,目前只做了中间件逻辑库级别的读写权限控制。是通过 server.xml 的 user 标签进行配置。
#server.xml配置文件user部分<user name="mycat"> <property name="password">123456</property> <property name="schemas">TESTDB</property></user><user name="user"> <property name="password">user</property> <property name="schemas">TESTDB</property> <property name="readOnly">true</property></user>#如下图
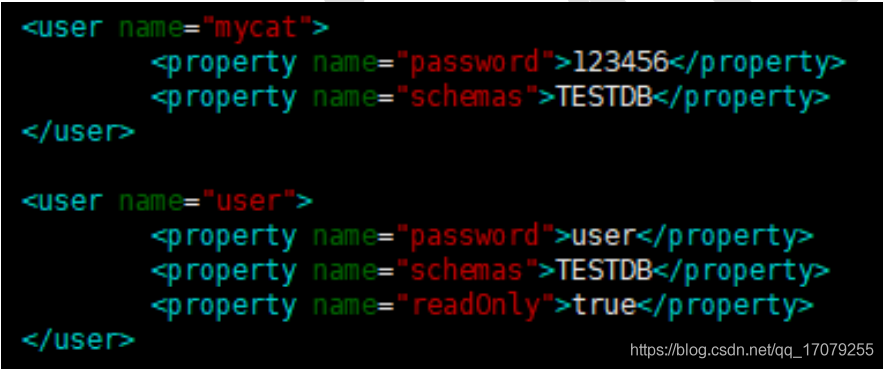
配置说明
| 标签属性 | 说明 |
|---|---|
| name | 应用连接中间件逻辑库的用户名 |
| password | 该用户对应的密码 |
| TESTDB | 应用当前连接的逻辑库中所对应的逻辑表。 schemas 中可以配置一个或多个 |
| readOnly | 应用连接中间件逻辑库所具有的权限。 true 为只读, false 为读写都有,默认为 false |
测试案例
#测试案例一# 使用user用户,权限为只读(readOnly: true)# 验证是否可以查询出数据, 验证是否可以写入数据#1、用user用户登录,运行命令如下:mysql -uuser -puser -h 192.168.140.128 -P8066#2、切换到TESTDB数据库,查询orders表数据,如下:use TESTDBselect * from orders;#3、可以查询到数据,如下图
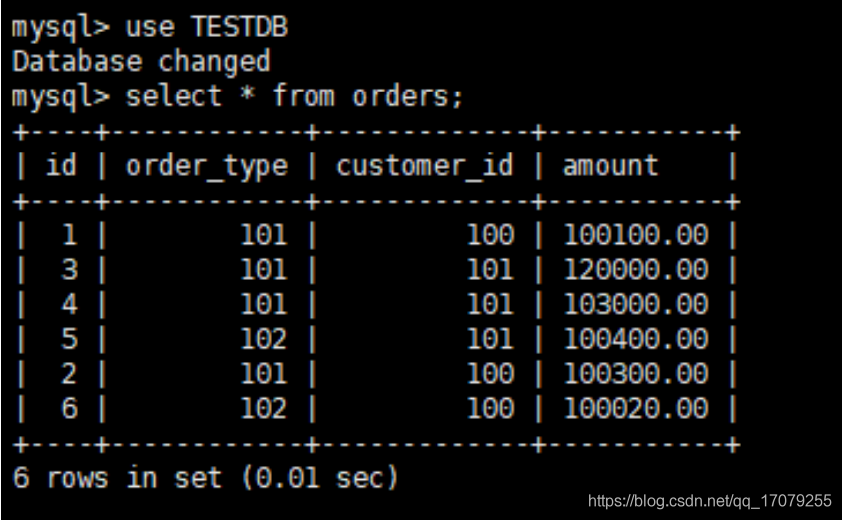
#4、执行插入数据sql,如下:insert into orders(id,order_type,customer_id,amount) values(7,101,101,10000);#5、 可看到运行结果,插入失败, 只有只读权限, 如下图:

#测试案例二# 使用mycat用户,权限为可读写(readOnly: false)# 验证是否可以查询出数据, 验证是否可以写入数据#1、用mycat用户登录,运行命令如下:mysql -umycat -p123456 -h 192.168.140.128 -P8066#2、切换到TESTDB数据库,查询orders表数据,如下:use TESTDBselect * from orders;#3、可以查询到数据,如下图
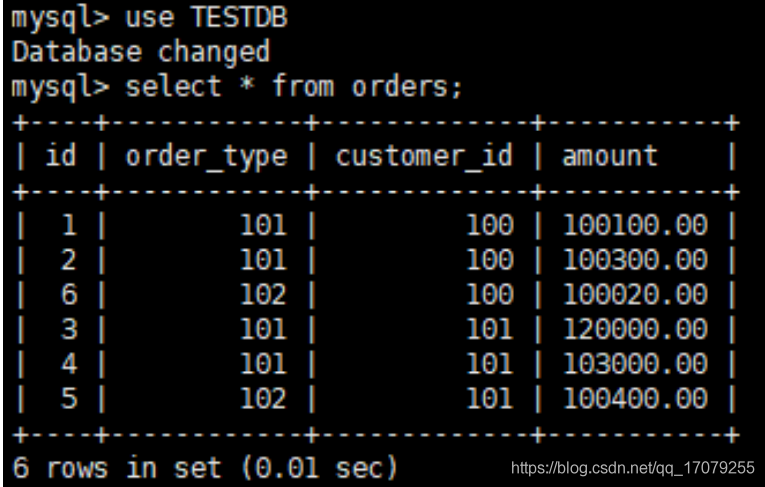
#4、执行插入数据sql,如下:insert into orders(id,order_type,customer_id,amount) values(7,101,101,10000);#5、 可看到运行结果,插入成功,如下图:

2、 privileges 标签权限控制
在 user 标签下的 privileges 标签可以对逻辑库(schema)、表(table)进行精细化的 DML 权限控制。
privileges 标签下的 check 属性,如为 true 开启权限检查,为 false 不开启,默认为 false。
由于 Mycat 一个用户的 schemas 属性可配置多个逻辑库(schema) ,所以 privileges 的下级节点 schema 节点同样可配置多个,对多库多表进行细粒度的 DML 权限控制。
#server.xml配置文件privileges部分#配置orders表没有增删改查权限<user name="mycat"> <property name="password">123456</property> <property name="schemas">TESTDB</property> <!-- 表级 DML 权限设置 --> <privileges check="true"> <schema name="TESTDB" dml="1111" > <table name="orders" dml="0000"></table> <!--<table name="tb02" dml="1111"></table>--> </schema> </privileges></user>#如下图
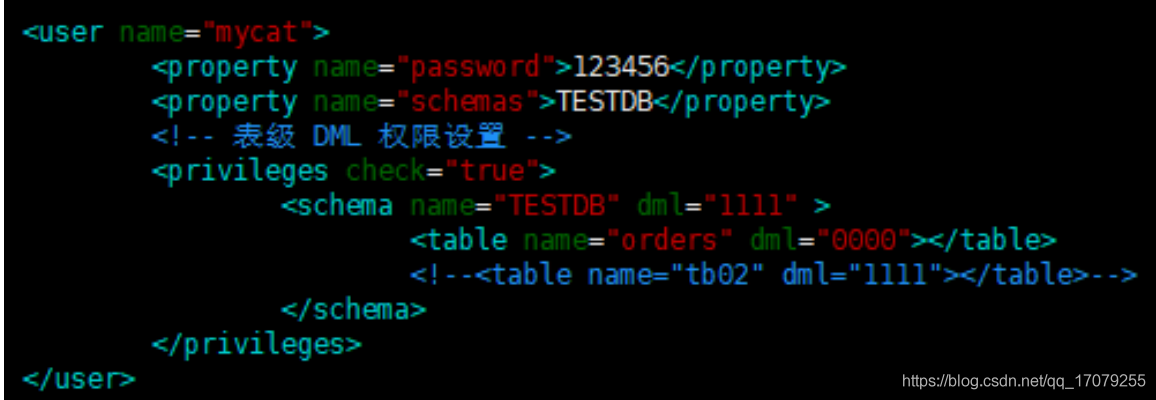
配置说明
| DML 权限 | 增加(insert) | 更新(update) | 查询(select) | 删除(select) |
|---|---|---|---|---|
| 0000 | 禁止 | 禁止 | 禁止 | 禁止 |
| 0010 | 禁止 | 禁止 | 可以 | 禁止 |
| 1110 | 可以 | 禁止 | 禁止 | 禁止 |
| 1111 | 可以 | 可以 | 可以 | 可以 |
测试案例
#测试案例一# 使用mycat用户, privileges配置orders表权限为禁止增删改查(dml="0000")# 验证是否可以查询出数据, 验证是否可以写入数据#1、 重启mycat, 用mycat用户登录,运行命令如下:mysql -umycat -p123456 -h 192.168.140.128 -P8066#2、切换到TESTDB数据库,查询orders表数据,如下:use TESTDBselect * from orders;#3、 禁止该用户查询数据,如下图

#4、执行插入数据sql,如下:insert into orders(id,order_type,customer_id,amount) values(8,101,101,10000);#5、 可看到运行结果, 禁止该用户插入数据, 如下图:

#测试案例二# 使用mycat用户, privileges配置orders表权限为可以增删改查(dml="1111")# 验证是否可以查询出数据, 验证是否可以写入数据#1、 重启mycat, 用mycat用户登录,运行命令如下:mysql -umycat -p123456 -h 192.168.140.128 -P8066#2、切换到TESTDB数据库,查询orders表数据,如下:use TESTDBselect * from orders;#3、可以查询到数据,如下图
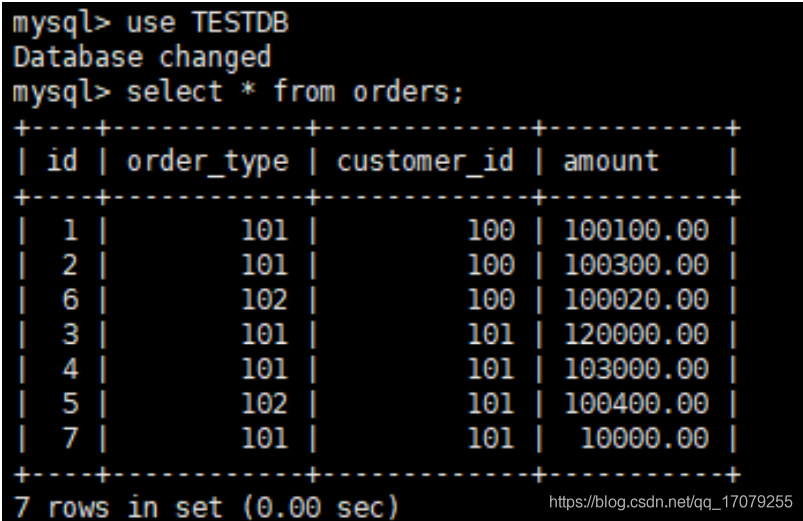
#4、执行插入数据sql,如下:insert into orders(id,order_type,customer_id,amount) values(8,101,101,10000);#5、 可看到运行结果,插入成功,如下图:

#4、执行插入数据sql,如下:delete from orders where id in (7,8);#5、 可看到运行结果,插入成功,如下图:

7.2 SQL 拦截
firewall 标签用来定义防火墙; firewall 下 whitehost 标签用来定义 IP 白名单 , blacklist 用来定义SQL 黑名单。
1、 白名单
可以通过设置白名单, 实现某主机某用户可以访问 Mycat,而其他主机用户禁止访问。
#设置白名单#server.xml配置文件firewall标签#配置只有192.168.140.128主机可以通过mycat用户访问<firewall> <whitehost> <host host="192.168.140.128" user="mycat"/> </whitehost></firewall>#如下图
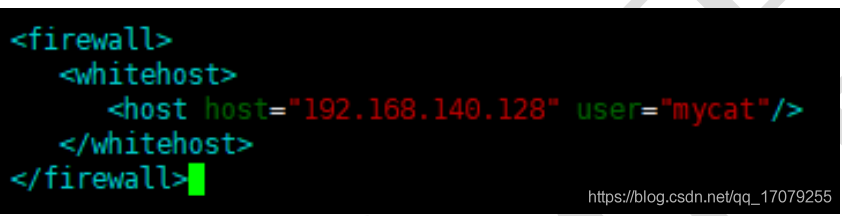
#重启Mycat后, 192.168.140.128主机使用mycat用户访问mysql -umycat -p123456 -h 192.168.140.128 -P 8066#可以正常访问, 如下图
#在此主机换user用户访问,禁止访问

#在192.168.140.127主机用mycat用户访问,禁止访问

2、 黑名单
可以通过设置黑名单, 实现 Mycat 对具体 SQL 操作的拦截, 如增删改查等操作的拦截。
#设置黑名单#server.xml配置文件firewall标签#配置禁止mycat用户进行删除操作<firewall> <whitehost> <host host="192.168.140.128" user="mycat"/> </whitehost> <blacklist check="true"> <property name="deleteAllow">false</property> </blacklist></firewall>#如下图
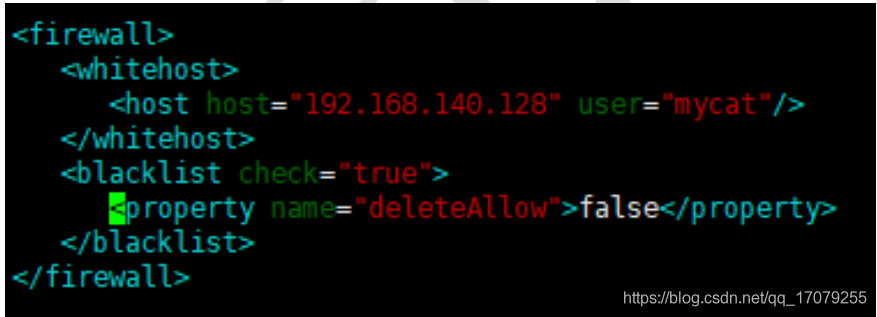
#重启Mycat后, 192.168.140.128主机使用mycat用户访问mysql -umycat -p123456 -h 192.168.140.128 -P 8066#可以正常访问, 如下图
#切换TESTDB数据库后,执行删除数据语句delete from orders where id=7;#运行后发现已禁止删除数据,如下图

可以设置的黑名单 SQL 拦截功能列表
| 配置项 | 缺省值 | 描述 |
|---|---|---|
| selelctAllow | true | 是否允许执行 SELECT 语句 |
| deleteAllow | true | 是否允许执行 DELETE 语句 |
| updateAllow | true | 是否允许执行 UPDATE 语句 |
| insertAllow | true | 是否允许执行 INSERT 语句 |
| createTableAllow | true | 是否允许创建表 |
| setAllow | true | 是否允许使用 SET 语法 |
| alterTableAllow | true | 是否允许执行 Alter Table 语句 |
| dropTableAllow | true | 是否允许修改表 |
| commitAllow | true | 是否允许执行 commit 操作 |
| rollbackAllow | true | 是否允许执行 roll back 操作 |
第八章 Mycat 监控工具
8.1 Mycat-web 简介
Mycat-web 是 Mycat 可视化运维的管理和监控平台,弥补了 Mycat 在监控上的空白。帮 Mycat 分担统计任务和配置管理任务。 Mycat-web 引入了 ZooKeeper 作为配置中心,可以管理多个节点。Mycat-web 主要管理和监控 Mycat 的流量、连接、活动线程和内存等,具备 IP 白名单、邮件告警等模块,还可以统计 SQL 并分析慢 SQL 和高频 SQL 等。为优化 SQL 提供依据。
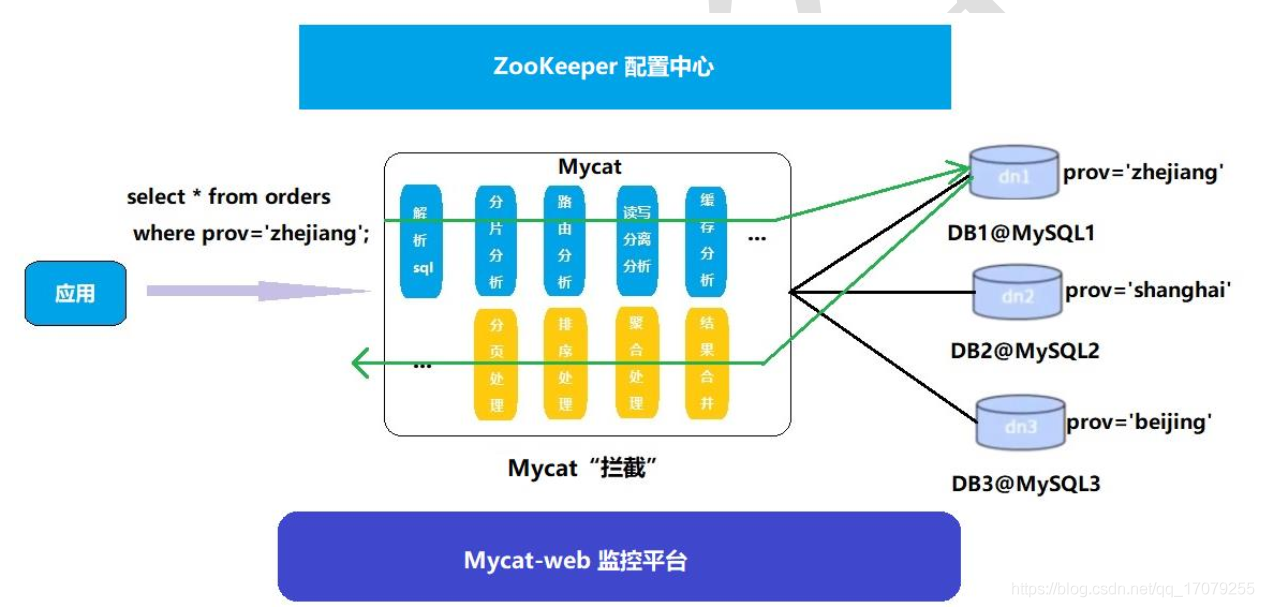
8.2 Mycat-web 配置使用
1、 ZooKeeper 安装
安装步骤如下:
#1下载安装包http://zookeeper.apache.org/#2 安装包拷贝到Linux系统/opt目录下,并解压tar -zxvf zookeeper-3.4.11.tar.gz

#3 进入ZooKeeper解压后的配置目录(conf) ,复制配置文件并改名cp zoo_sample.cfg zoo.cfg#4 进入ZooKeeper的命令目录(bin) ,运行启动命令./zkServer.sh start

#5 ZooKeeper服务端口为2181,查看服务已经启动netstat -ant | grep 2181
2、 Mycat-web 安装
安装步骤如下:
#1下载安装包http://www.mycat.io/#2 安装包拷贝到Linux系统/opt目录下,并解压tar -zxvf Mycat-web-1.0-SNAPSHOT-20170102153329-linux.tar.gz#3 拷贝mycat-web文件夹到/usr/local目录下cp -r mycat-web /usr/local#4 进入mycat-web的目录下运行启动命令cd /usr/local/mycat-web/./start.sh &
#5 Mycat-web服务端口为8082,查看服务已经启动netstat -ant | grep 8082

#6 通过地址访问服务http://192.168.140.127:8082/mycat/
3、 Mycat-web 配置
安装步骤如下:
#1 先在注册中心配置ZooKeeper地址,配置后刷新页面,可见
#2 新增Mycat监控实例
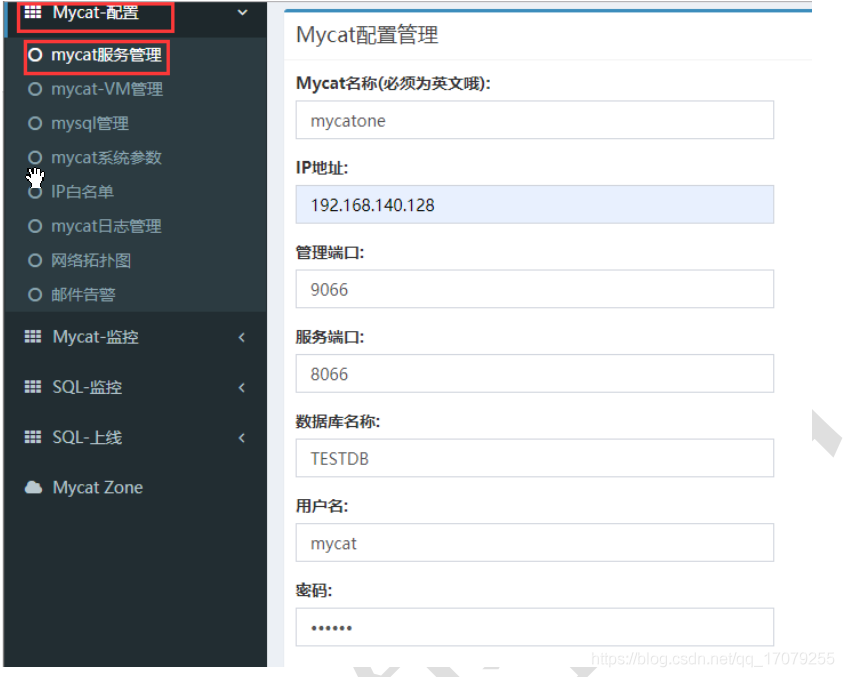
8.3 Mycat 性能监控指标
在 Mycat-web 上可以进行 Mycat 性能监控,例如:内存分享、流量分析、连接分析、活动线程分析等等。