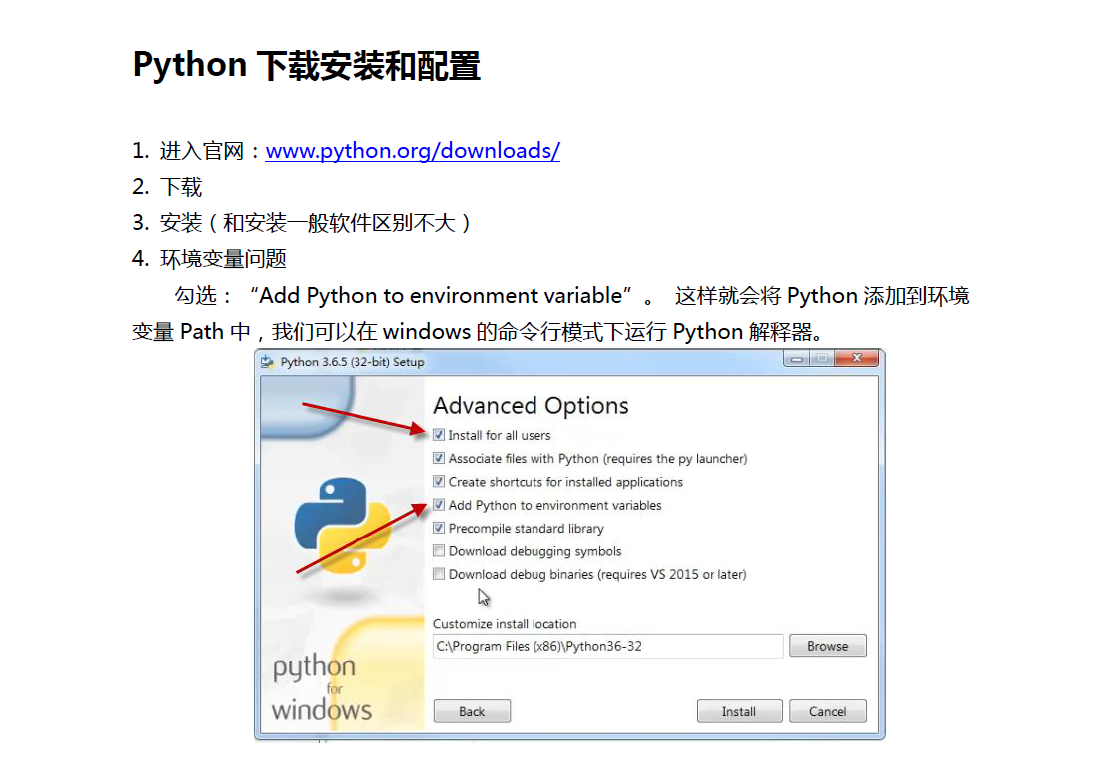
python的安装
python入门
python的第一个程序陀螺
import turtle
t=turtle.Pen()
'''
陀螺代码
'''
for x in range(360):
t.forward(x)
t.left(59)
python的第二个程序奥运五环
import turtle
turtle.width(10)
#设置圆圈的颜色
turtle.color("blue")
turtle.circle(50)
#把笔抬起来
turtle.penup()
#让笔到目标位子
turtle.goto(120,0)
#把笔放下
turtle.pendown()
turtle.color("black")
turtle.circle(50)
turtle.penup()
turtle.goto(240,0)
turtle.pendown()
turtle.color("red")
turtle.circle(50)
turtle.penup()
turtle.goto(60,-50)
turtle.pendown()
turtle.color("yellow")
turtle.circle(50)
turtle.penup()
turtle.goto(180,-50)
turtle.pendown()
turtle.color("green")
turtle.circle(50)
python的基础语法
1 python中的注释#,’''
注释是程序中会被Python 解释器忽略的一段文本。程序员可以通过注释记录任意想写的内 容,通常是关于代码的说明。 Python 中的注释只有单行注释,使用#开始知道行结束的部分。
注释是个好习惯,方便自己方便他人
a = [10,20,30] #生成一个列表对象,变量a 引用了这个变量
2、使用\行连接符
一行程序的长度是没有限制的,但是为了可读性更强通常将一行比较长的程序分为多行。这 是,我们可以使用\行连接符,把它放在行结束的地方。Python 解释器仍然将它们解释为同 一行。
>>> a = [10,20,30,40,\
50,60,70,\
80,90,100]
>>> a
[10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
>>> a = 'abcdefghijklmnopqrstuvwxyz'
>>> b = 'abcdefg\
hijklmn\
opqrst\
uvwxyz'
>>> a
'abcdefghijklmnopqrstuvwxyz'
>>> b
'abcdefghijklmnopqrstuvwxyz'
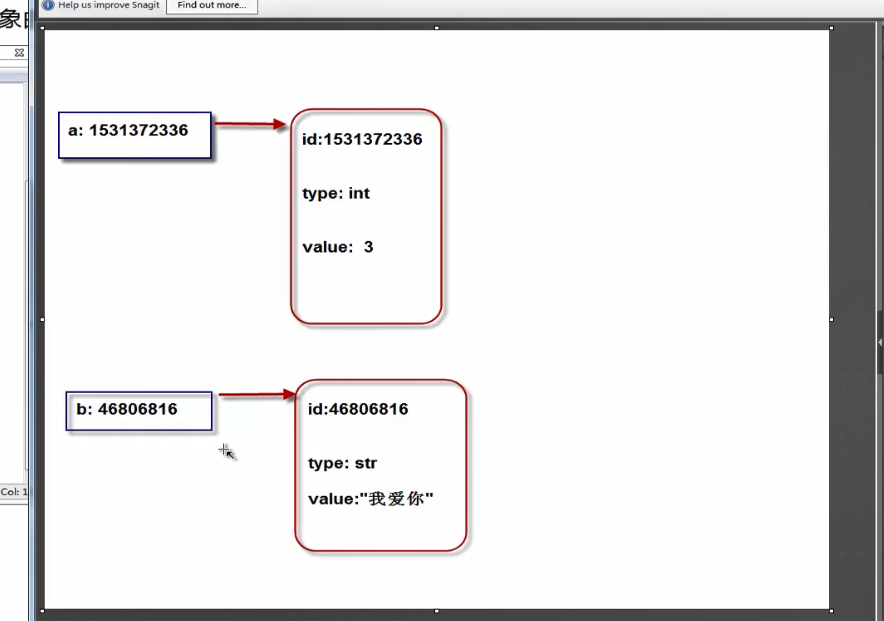
3、 python对象的定义
a = "asdfsadfaf"
print(a)
print(id(a))
print(type(a))
python把每一个数据都定义为一个对象,里面包含着各种信息
4 python的赋值操作
链式赋值
链式赋值用于同一个对象赋值给多个变量
x=y=123 相当于:x=123;y=123
系列解包赋值
系列数据赋值给对应相同个数的变量(个数必须保持一致)
a,b,c = 4,5,6 相当于a=4;b=5;c=6
使用系列解包赋值实现变量互换
a,b = 1,2
a,b = b,a
print(a,b)
5 python最基本内置数据类型介绍


6 其他类型转换成整数
使用int()实现类型转换
1、浮点型直接舍去小数部分。如int(9.9) = 9
2、布尔值True转为1,False转为0,如int(True)结果是1
3、字符串符合整数格式(浮点数格式不行)则直接转换为对应整数,否则报错
自动转型:
整数和浮点数混合运算时,表达式结果自动转型成浮点数。比如2+8.0 = 10.0
7 浮点数类型转换和四舍五入

1. 类似于int(),我们也可以使用float()将其他类型转化成浮点数。
- 整数和浮点数混合运算时,表达式结果自动转型成浮点数。比如:2+8.0 的结果是10.0
- round(value)可以返回四舍五入的值 注:但不会改变原有值,而是产生新的值
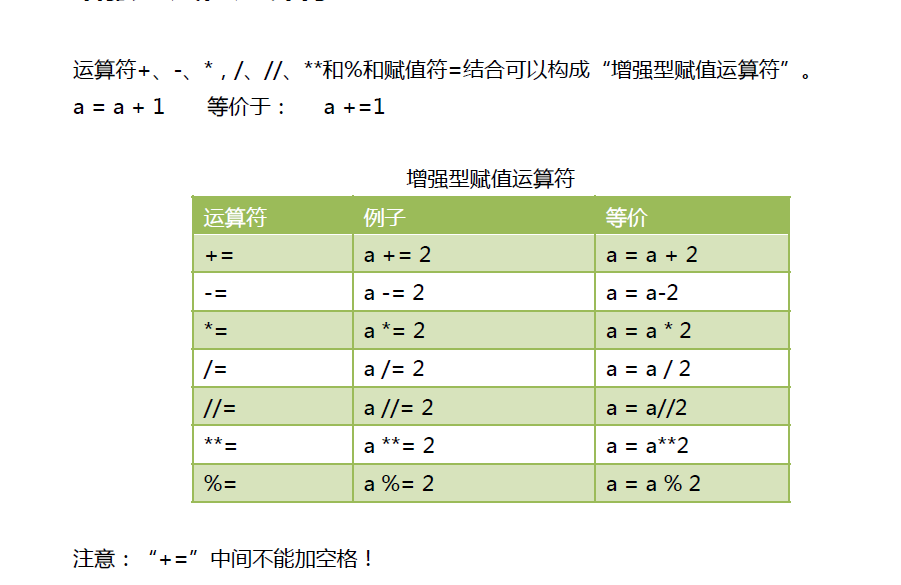
8 增强型赋值预算符
9 python运算符
9.1 比较运算符

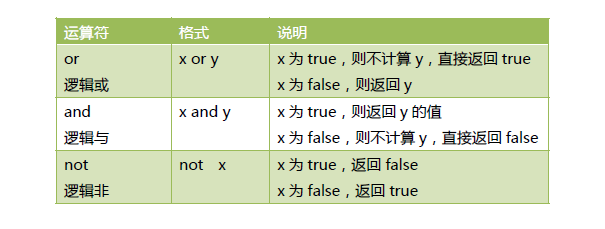
逻辑运算符
同一运算符

整数缓存问题

python字符串
10.1 创建字符串
我们可以通过单引号或双引号创建字符串。例如:a=’abc’; b=”sxt” 使用两种引号的好处是可以创建本身就包含引号的字符串,而不用使用转义字符。例如:
我们可以通过单引号或双引号创建字符串。例如:a=’abc’; b=”sxt”
使用两种引号的好处是可以创建本身就包含引号的字符串,而不用使用转义字符。例如:
>>> a = "I'm a teacher!"
>>> print(a)
I'm a teacher!
>>> b = 'my_name is "TOM"'
>>> print(b)
my_name is "TOM"
连续三个单引号或三个双引号,可以帮助我们创建多行字符串。例如:
>>> resume = ''' name="gaoqi"
company="sxt" age=18
lover="Tom"'''
>>> print(resume)
name="gaoqi"
company="sxt" age=18
lover="Tom"
10.2 空字符串与len()函数
Python 允许空字符串的存在,不包含任何字符且长度为0。例如:
Python 允许空字符串的存在,不包含任何字符且长度为0。例如:
>>> c = ''
>>> len(c)
0
len()用于计算字符串含有多少字符。例如:
>>> d = 'abc 尚学堂'
>>> len(d)
6
10.3 转义字符
我们可以使用“+特殊字符”,实现某些难以用字符表示的效果。比如:换行等。常见的 转义字符有这些:
| 转义字符 | 描述 |
|---|---|
| \(在行尾时) | 续航符 |
| \\ | 反斜杠符号 |
| \' | 单引号 |
| \'' | 双引号 |
| \b | 退格(Backspace) |
| \n | 换行 |
| \t | 横向制表符 |
| \r | 回车 |
10.4 字符串的拼接
- 可以使用+将多个字符串拼接起来。例如:’aa’+ ’bb’ ==>’aabb’。 (1) 如果+两边都是字符串,则拼接。 (2) 如果+两边都是数字,则加法运算。 (3) 如果+两边类型不同,则抛出异常。
- 可以将多个字面字符串直接放到一起实现拼接。例如:’aa’’bb’==>’aabb’
10.5 字符串的复制
使用*可以实现字符串复制。
【操作】字符串复制操作
>>> a = 'Sxt'*3
>>> a
'SxtSxtSxt'
10.6 字符串不换行打印
我们前面调用print 时,会自动打印一个换行符。有时,我们不想换行,不想自动添加换行 符。我们可以自己通过参数end = “任意字符串”。实现末尾添加任何内容: 建立源文件mypy_06.py:
print("sxt",end=' ')
print("sxt",end='##')
print("sxt")
运行结果:
sxt sxt##sxt
10.7 从控制台读取字符串
我们可以使用input()从控制台读取键盘输入的内容
>>> myname = input("请输入名字:")
请输入名字:高淇
>>> myname
'高淇'
10.8 str()实现数字转型为字符串
str()可以帮助我们将其他数据类型转换为字符串。例如: str(5.20) ==> ‘5.20’ str(3.14e2)==>’314.0’ str(True) ==> ‘True’ 当我们调用print()函数时,解释器自动调用了str()将非字符串的对象转成了字符串。我们 在面向对象章节中详细讲解这部分内容。
10.9 使用【】提取字符
字符串的本质就是字符序列,我们可以通过在字符串后面添加[],在[]里面指定偏移量, 可以提取该位置的单个字符。 正向搜索: 最左侧第一个字符,偏移量是0,第二个偏移量是1,以此类推。直到len(str)-1 为止。 反向搜索: 最右侧第一个字符,偏移量是-1,倒数第二个偏移量是-2,以此类推,直到-len(str) 为止。
>>> a = 'abcdefghijklmnopqrstuvwxyz'
>>> a
'abcdefghijklmnopqrstuvwxyz'
>>> a[0]
'a'
>>> a[3]
'd'
>>> a[26-1]
'z'
>>> a[-1]
'z'
>>> a[-26]
'a'
>>> a[-30]
Traceback (most recent call last):
File "<pyshell#91>", line 1, in <module>
a[-30]
IndexError: string index out of range
10.10 replace()实现字符串的替换
字符串是“不可改变”的,我们通过[]可以获取字符串指定位置的字符,但是我们不能改变
字符串。我们尝试改变字符串中某个字符,发现报错了:
>>> a = 'abcdefghijklmnopqrstuvwxyz'
>>> a
'abcdefghijklmnopqrstuvwxyz'
>>> a[3]='高'
Traceback (most recent call last):
File "<pyshell#94>", line 1, in <module>
a[3]='高'
TypeError: 'str' object does not support item assignment
字符串不可改变。但是,我们确实有时候需要替换某些字符。这时,只能通过创建新的字符
串来实现。
>>> a = 'abcdefghijklmnopqrstuvwxyz'
>>> a
'abcdefghijklmnopqrstuvwxyz'
>>> a = a.replace('c','高')
'ab 高defghijklmnopqrstuvwxyz'
整个过程中,实际上我们是创建了新的字符串对象,并指向了变量a,而不是修改了以前的
字符串
10.11 字符串切片slice操作
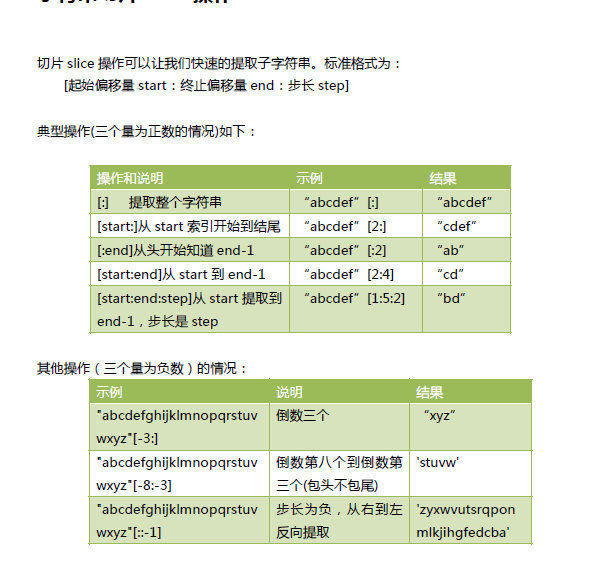
切片操作时,起始偏移量和终止偏移量不在[0,字符串长度-1]这个范围,也不会报错。起始
偏移量小于0 则会当做0,终止偏移量大于“长度-1”会被当成-1。例如:
>>> "abcdefg"[3:50]
'defg'
我们发现正常输出了结果,没有报错。
10.12 字符串split()分割和join()合并
split()可以基于指定分隔符将字符串分隔成多个子字符串(存储到列表中)。如果不指定分隔 符,则默认使用空白字符(换行符/空格/制表符)。示例代码如下:
>>> a = "to be or not to be"
>>> a.split()
['to', 'be', 'or', 'not', 'to', 'be']
>>> a.split('be')
['to ', ' or not to ', '']
join()的作用和split()作用刚好相反,用于将一系列字符串连接起来,实例代码如下:
>>> a = ['sxt','sxt100','sxt200']
>>> '*'.join(a)
'sxt*sxt100*sxt200'
拼接字符串要点: 使用字符串拼接符+,会生成新的字符串对象,因此不推荐使用+来拼接字符串。推荐 使用join 函数,因为join 函数在拼接字符串之前会计算所有字符串的长度,然后逐一拷贝, 仅新建一次对象。
10.13 字符串驻留机制和字符串比较
字符串驻留:拼接字符串要点: 使用字符串拼接符+,会生成新的字符串对象,因此不推荐使用+来拼接字符串。推荐 使用join 函数,因为join 函数在拼接字符串之前会计算所有字符串的长度,然后逐一拷贝, 仅新建一次对象。
10.14 in/not in 关键字,判断某个字符(子字符串)是否存在于字符串中
10.15 字符串常用方法汇总
常用查找方法
我们以一段文本作为测试: a=‘‘‘我是高淇,今年18 岁了,我在北京尚学堂科技上班。我的儿子叫高洛希,他6 岁了。我 是一个编程教育的普及者,希望影响6000 万学习编程的中国人。我儿子现在也开始学习编 程,希望他18 岁的时候可以超过我’’’
方法和使用示例 说明 结果 len(a) 字符串长度 96 a.startswith(‘我是高淇’) 以指定字符串开头 True a.endswith(‘过我’) 以指定字符串结尾 True a.find(‘高’) 第一次出现指定字符串的位置 2 a.rfind(‘高’) 最后一次出现指定字符串的位置 29 a.count(“编程”) 指定字符串出现了几次 3 a.isalnum() 所有字符全是字母或数字 False
去除首尾信息
我们可以通过strip()去除字符串首尾指定信息。通过lstrip()去除字符串左边指定信息, rstrip()去除字符串右边指定信息。
【操作】去除字符串首尾信息
>>> "*s*x*t*".strip("*")
's*x*t'
>>> "*s*x*t*".lstrip("*")
's*x*t*'
>>> "*s*x*t*".rstrip("*")
'*s*x*t'
>>> " sxt ".strip()
'sxt'
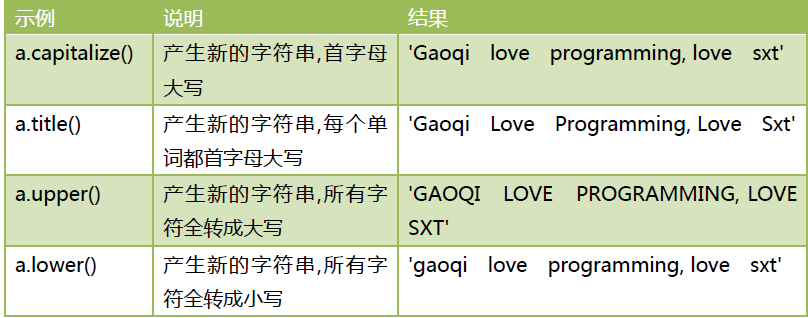
大小写转换

格式排版
center()、ljust()、rjust()这三个函数用于对字符串实现排版。示例如下:
>>> a="SXT"
>>> a.center(10,"*")
'***SXT****'
>>> a.center(10)
' SXT '
>>> a.ljust(10,"*")
'SXT*******'
其他方法
- isalnum() 是否为字母或数字
- isalpha() 检测字符串是否只由字母组成(含汉字)。
- isdigit() 检测字符串是否只由数字组成。
- isspace() 检测是否为空白符
- isupper() 是否为大写字母
- islower() 是否为小写字母
>>> "sxt100".isalnum()
True
>>> "sxt 尚学堂".isalpha()
True
>>> "234.3".isdigit()
False
>>> "23423".isdigit()
True
>>> "aB".isupper()
False
>>> "A".isupper()
True
>>> "\t\n".isspace()
True
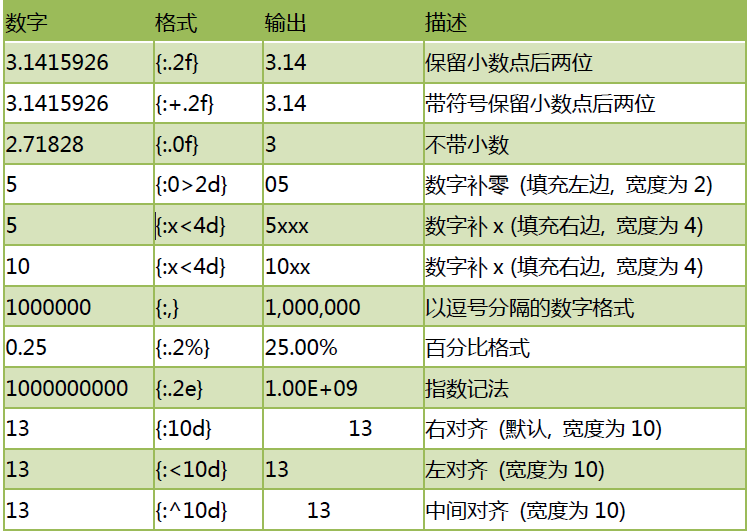
字符串格式化
format()基本用法
Python2.6 开始,新增了一种格式化字符串的函数str.format(),它增强了字符串格式化的 功能。 基本语法是通过{} 和: 来代替以前的% 。 format 函数可以接受不限个参数,位置可以不按顺序。 我们通过示例进行格式化的学习。
>>> a = "名字是:{0},年龄是:{1}"
>>> a.format("高淇",18)
'名字是:高淇,年龄是:18'
>>> a.format("高希希",6)
'名字是:高希希,年龄是:6'
>>> b = "名字是:{0},年龄是{1}。{0}是个好小伙"
>>> b.format("高淇",18)
'名字是:高淇,年龄是18。高淇是个好小伙'
>>> c = "名字是{name},年龄是{age}"
>>> c.format(age=19,name='高淇')
'名字是高淇,年龄是19'
我们可以通过{索引}/{参数名},直接映射参数值,实现对字符串的格式化,非常方便。
填充和对齐
填充常跟对齐一起使用 ^、<、>分别是居中、左对齐、右对齐,后面带宽度 :号后面带填充的字符,只能是一个字符,不指定的话默认是用空格填充
>>> "{:*>8}".format("245")
'*****245'
>>> "我是{0},我喜欢数字{1:*^8}".format("高淇","666")
'我是高淇,我喜欢数字**666***'
数字格式化
浮点型通过f,整数通过d进行需要的格式化。案例如下:
>>> a = "我是{0},我的存款有{1:.2f}"
>>> a.format("高淇",3888.234342)
'我是高淇,我的存款有3888.23'
10.16 可变字符串
在Python 中,字符串属于不可变对象,不支持原地修改,如果需要修改其中的值,智 能创建新的字符串对象。但是,经常我们确实需要原地修改字符串,可以使用io.StringIO 对象或array 模块。
>>> import io
>>> s = "hello, sxt"
>>> sio = io.StringIO(s)
>>> sio
<_io.StringIO object at 0x02F462B0>
>>> sio.getvalue()
'hello, sxt'
>>> sio.seek(7)
7
>>> sio.write("g")
1
>>> sio.getvalue()
'hello, gxt'
python数据类型
1 列表
1.1 列表的常用方法
列表:用于存储任意数目,任意类型的数据集合
列表是内置可变序列,是包含多个元素的有序连续的内存空间。列表定义的
标准语法格式: a = [10,20,30,40]
其中,10,20,30,40这些称为:列表a的元素
列表中的元素可以各不相同,可以是任意类型。比如:a = [10,20,‘abc’,True]
列表对象的常用方法汇总如下,方便大家学习和查阅
| 方法 | 要点 | 描述 |
|---|---|---|
| list.append(x) | 增加元素 | 将元素x增加到列表list尾部 |
| list.extend(aList) | 增加元素 | 将列表alist所有元素加到列表list尾部 |
| list.insert(index,x) | 增加元素 | 在列表list指定位置index处插入元素x |
| list.remove(x) | 删除元素 | 在列表list中删除首次出现的指定元素x |
| list.pop([index]) | 删除元素 | 删除并返回列表list指定为止index处的元素,默认是最后一个元素 |
| list.clear() | 删除所有元素 | 删除列表所有元素,并不是删除列表对象 |
| list.index(x) | 访问元素 | 返回第一个x的索引位置,若不存在元素抛出异常 |
| list.count(x) | 计数 | 返回指定元素x在列表list中出现的次数 |
| len(list) | 列表长度 | 返回列表中包含元素的个数 |
| list.reverse() | 翻转列表 | 所有元素原地翻转 |
| list.sort() | 排序 | 所有元素原地排序 |
| list.copy() | 浅拷贝 | 返回列表对象的浅拷贝 |
Python 的列表大小可变,根据需要随时增加或缩小。 字符串和列表都是序列类型,一个字符串是一个字符序列,一个列表是任何元素的序列。我 们前面学习的很多字符串的方法,在列表中也有类似的用法,几乎一模一样。
1.2 列表的创建
基本语法【】创建
a = [10,20,‘gao’,‘sxt’]
a=[] #创建一个空列表对象
list()创建
list()创建
使用list()可以将任何可迭代的数据转化成列表。
>>> a = list() #创建一个空的列表对象
>>> a = list(range(10))
>>> a
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> a = list("gaoqi,sxt")
>>> a
['g', 'a', 'o', 'q', 'i', ',', 's', 'x', 't']
range()创建整数列表
range()可以帮助我们非常方便的创建整数列表,这在开发中及其有用。语法格式为: range([start,] end [,step]) start 参数:可选,表示起始数字。默认是0 end 参数:必选,表示结尾数字。 step 参数:可选,表示步长,默认为1 python3 中range()返回的是一个range 对象,而不是列表。我们需要通过list()方法将其 转换成列表对象。
>>> list(range(3,15,2))
[3, 5, 7, 9, 11, 13]
>>> list(range(15,3,-1))
[15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4]
>>> list(range(3,-10,-1))
[3, 2, 1, 0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
1.3 列表元素的增加
当列表增加和删除元素时,列表会自动进行内存管理,大大减少了程序员的负担。但这 个特点涉及列表元素的大量移动,效率较低。除非必要,我们一般只在列表的尾部添加元素 或删除元素,这会大大提高列表的操作效率。
append()方法
原地修改列表对象,是真正的列表尾部添加新的元素,速度最快,推荐使用。
>>> a = [20,40]
>>> a.append(80)
>>> a
[20, 40, 80]
extend()方法
将目标列表的所有元素添加到本列表的尾部,属于原地操作,不创建新的列表对象。
>>> a = [20,40]
>>> id(a)
46016072
>>> a.extend([50,60])
>>> id(a)
46016072
insert()插入元素
将目标列表的所有元素添加到本列表的尾部,属于原地操作,不创建新的列表对象。
>>> a = [20,40]
>>> id(a)
46016072
>>> a.extend([50,60])
>>> id(a)
46016072
乘法扩展
使用乘法扩展列表,生成一个新列表,新列表元素时原列表元素的多次重复。
>>> a = ['sxt',100]
>>> b = a*3
>>> a
['sxt', 100]
>>> b
['sxt', 100, 'sxt', 100, 'sxt', 100]
适用于乘法操作的,还有:字符串、元组。例如:
>>> c = 'sxt'
>>> d = c*3
>>> c
'sxt'
>>> d
'sxtsxtsxt'
1.4 列表元素的删除
del 删除(效率较低)
删除列表指定位置的元素。
>>> a = [100,200,888,300,400]
>>> del a[1]
>>> a
[100,200,300,400]
pop()方法
pop()删除并返回指定位置元素,如果未指定位置则默认操作列表最后一个元素。
>>> a = [10,20,30,40,50]
>>> a.pop()
50
>>> a
[10, 20, 30, 40]
>>> a.pop(1)
20
>>> a
[10, 30, 40]
remove()方法(注意python是首次出现)
删除首次出现的指定元素,若不存在该元素抛出异常。
>>> a = [10,20,30,40,50,20,30,20,30]
>>> a.remove(20)
>>> a
[10, 30, 40, 50, 20, 30, 20, 30]
>>> a.remove(100)
Traceback (most recent call last):
File "<pyshell#208>", line 1, in <module>
a.remove(100)
ValueError: list.remove(x): x not in list
1.5 列表访问和计数
通过索引直接访问
我们可以通过索引直接访问元素。索引的区间在[0, 列表长度-1]这个范围。超过这个范围则
会抛出异常。
>>> a = [10,20,30,40,50,20,30,20,30]
>>> a[2]
30
>>> a[10]
Traceback (most recent call last):
File "<pyshell#211>", line 1, in <module>
a[10]
IndexError: list index out of range
index()获取指定元素在列表中首次出现的位置
index()可以获取指定元素首次出现的索引位置。语法是:index(value,[start,[end]])。其中,
start 和end 指定了搜索的范围。
>>> a = [10,20,30,40,50,20,30,20,30]
>>> a.index(20)
1
>>> a.index(20,3)
5
>>> a.index(20,3) #从索引位置3 开始往后搜索的第一个20
5
>>> a.index(30,5,7) #从索引位置5 到7 这个区间,第一次出现30 元素的位置
6
count()获取指定元素在列表中出现的次数
count()可以返回指定元素在列表中出现的次数。
>>> a = [10,20,30,40,50,20,30,20,30]
>>> a.count(20)
3
len() 返回列表的长度
len()返回列表长度,即列表中包含元素的个数。
>>> a = [10,20,30]
>>> len(a)
3
成员资格判断
判断列表中是否存在指定的元素,我们可以使用count()方法,返回0 则表示不存在,返回
大于0 则表示存在。但是,一般我们会使用更加简洁的in 关键字来判断,直接返回True
或False。
>>> a = [10,20,30,40,50,20,30,20,30]
>>> 20 in a
True
>>> 100 not in a
True
>>> 30 not in a
False
1.6 切片操作
我们在前面学习字符串时,学习过字符串的切片操作,对于列表的切片操作和字符串类似。 切片是Python 序列及其重要的操作,适用于列表、元组、字符串等等。切片的格式如下: 切片slice 操作可以让我们快速提取子列表或修改。标准格式为: [起始偏移量start:终止偏移量end[:步长step]] 注:当步长省略时顺便可以省略第二个冒号
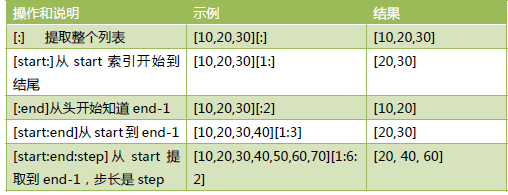

切片操作时,起始偏移量和终止偏移量不在[0,字符串长度-1]这个范围,也不会报错。起始
偏移量小于0 则会当做0,终止偏移量大于“长度-1”会被当成”长度-1”。例如:
>>> [10,20,30,40][1:30]
[20, 30, 40]
我们发现正常输出了结果,没有报错。
1.7 列表的遍历
for obj in listObj: print(obj)
1.8 复制列表的所有的元素到新 列表对象
如下代码实现列表元素的复制了吗? list1 = [30,40,50] list2 = list1 只是将list2 也指向了列表对象,也就是说list2 和list2 持有地址值是相同的,列表对象本 身的元素并没有复制。 我们可以通过如下简单方式,实现列表元素内容的复制: list1 = [30,40,50] list2 = [] + list1 注:我们后面也会学习copy 模块,使用浅复制或深复制实现我们的复制操作。
1.9 列表排序
修改原列表,不建新列表排序
>>> a = [20,10,30,40]
>>> id(a)
46017416
>>> a.sort() #默认是升序排列
>>> a
[10, 20, 30, 40]
>>> a = [10,20,30,40]
>>> a.sort(reverse=True) #降序排列
>>> a
[40, 30, 20, 10]
>>> import random
>>> random.shuffle(a) #打乱顺序
>>> a
[20, 40, 30, 10]
建新列表的排序
我们也可以通过内置函数sorted()进行排序,这个方法返回新列表,不对原列表做修改。
>>> a = [20,10,30,40]
>>> id(a)
46016008
>>> a = sorted(a) #默认升序
>>> a
[10, 20, 30, 40]
>>> id(a)
45907848
>>> a = [20,10,30,40]
>>> id(a)
45840584
>>> b = sorted(a)
北京尚学堂·百战程序员实战系统好教育
>>> b
[10, 20, 30, 40]
>>> id(a)
45840584
>>> id(b)
46016072
>>> c = sorted(a,reverse=True) #降序
>>> c
[40, 30, 20, 10]
通过上面操作,我们可以看出,生成的列表对象b 和c 都是完全新的列表对象。
reversed()返回迭代器对象
内置函数reversed()也支持进行逆序排列,与列表对象reverse()方法不同的是,内置函数
reversed()不对原列表做任何修改,只是返回一个逆序排列的迭代器对象。
>>> a = [20,10,30,40]
>>> c = reversed(a)
>>> c
<list_reverseiterator object at 0x0000000002BCCEB8>
>>> list(c)
[40, 30, 10, 20]
>>> list(c)
[]
我们打印输出c 发现提示是:list_reverseiterator。也就是一个迭代对象。同时,我们使用
list(c)进行输出,发现只能使用一次。第一次输出了元素,第二次为空。那是因为迭代对象
在第一次时已经遍历结束了,第二次不能再使用。
注:关于迭代对象的使用,后续章节会进行详细讲解。
1.10 列表相关的其他内置函数汇总
max和min
用于返回列表中最大和最小值。
[40, 30, 20, 10]
>>> a = [3,10,20,15,9]
>>> max(a)
20
>>> min(a)
3
sum
对数值型列表的所有元素进行求和操作,对非数值型列表运算则会报错。
>>> a = [3,10,20,15,9]
>>> sum(a)
57
1.11 多维列表
二维列表
a = [
["高小一",18,30000,"北京"],
["高小二",19,20000,"上海"],
["高小一",20,10000,"深圳"],
]
for m in range(3):
for n in range(4):
print(a[m][n],end="\t")
print() #打印完一行,换行
运行结果:
高小一18 30000 北京
高小二19 20000 上海
高小一20 10000 深圳
2 元组tuple
列表属于可变序列,可以任意修改列表中的元素。元组属于不可变序列,不能修改元组中的元素。因此,元组没有增加元素,修改元素,删除元素相关的方法
因此,我们只选哟学习元组的创建和删除,元组中的元素的访问和计数即可。元组支持以下操作
1 索引访问
2 切片操作
3 连接操作
4 成员关系操作
5 比较运算操作
6 计数:元组长度len()、最大值max()、最小值min()、求和sum()等
元组的创建
1. 通过()创建元组。小括号可以省略。
a = (10,20,30) 或者a = 10,20,30
如果元组只有一个元素,则必须后面加逗号。这是因为解释器会把(1)解释为整数1,(1,)
解释为元组。
>>> a = (1)
>>> type(a)
<class 'int'>
>>> a = (1,) #或者a = 1,
>>> type(a)
<class 'tuple'>
2. 通过tuple()创建元组
tuple(可迭代的对象)
例如:
b = tuple() #创建一个空元组对象
b = tuple("abc")
b = tuple(range(3))
b = tuple([2,3,4])
总结:
tuple()可以接收列表、字符串、其他序列类型、迭代器等生成元组。
list()可以接收元组、字符串、其他序列类型、迭代器等生成列表。
元组的元素访问和计数
1、元组的元素不能修改
的元素不能修改
>>> a = (20,10,30,9,8)
>>> a[3]=33
Traceback (most recent call last):
File "<pyshell#313>", line 1, in <module>
a[3]=33
TypeError: 'tuple' object does not support item assignment
2、元组的元素访问和列表一样,只不过返回的仍然是元组对象
>>> a = (20,10,30,9,8)
>>> a[1]
10
>>> a[1:3]
(10, 30)
>>> a[:4]
(20, 10, 30, 9)
3、元组的排序
列表关于排序的方法list.sorted()是修改原列表对象,元组没有该方法。如果要对元组排序,只能使用内置函数sorted(tupleObj),并生成新的列表对象
>>> a = (20,10,30,9,8)
>>> sorted(a)
[8, 9, 10, 20, 30]
zip
zip(列表1,列表2,….)将多个列表对应位置的元素组合成为元组,并返回这个zip对象
>>> a = [10,20,30]
>>> b = [40,50,60]
>>> c = [70,80,90]
>>> d = zip(a,b,c)
>>> list(d)
[(10, 40, 70), (20, 50, 80), (30, 60, 90)]
生成器推导式创建元组
从形式上看,生成器推导式与列表推导式类似,只是生成器推导式使用小括号。列表推 导式直接生成列表对象,生成器推导式生成的不是列表也不是元组,而是一个生成器对象。 我们可以通过生成器对象,转化成列表或者元组。也可以使用生成器对象的__next__() 方法进行遍历,或者直接作为迭代器对象来使用。不管什么方式使用,元素访问结束后,如 果需要重新访问其中的元素,必须重新创建该生成器对象。
>>> s = (x*2 for x in range(5))
>>> s
<generator object <genexpr> at 0x0000000002BDEB48>
>>> tuple(s)
(0, 2, 4, 6, 8)
>>> list(s) #只能访问一次元素。第二次就为空了。需要再生成一次
[]
>>> s
<generator object <genexpr> at 0x0000000002BDEB48>
>>> tuple(s)
()
>>> s = (x*2 for x in range(5))
>>> s.__next__()
0
>>> s.__next__()
2
>>> s.__next__()
4
元组总结
1. 元组的核心特点是:不可变序列。
- 元组的访问和处理速度比列表快。
- 与整数和字符串一样,元组可以作为字典的键,列表则永远不能作为字典的键使用。
3 字典
字典是“键值对”的无序可变序列,字典中的每个元素都是一个“键值对”,包含:“键 对象”和“值对象”。可以通过“键对象”实现快速获取、删除、更新对应的“值对象”。 列表中我们通过“下标数字”找到对应的对象。字典中通过“键对象”找到对应的“值 对象”。“键”是任意的不可变数据,比如:整数、浮点数、字符串、元组。但是:列表、 字典、集合这些可变对象,不能作为“键”。并且“键”不可重复。 “值”可以是任意的数据,并且可重复。 一个典型的字典的定义方式: a = {’name’:‘gaoqi’,‘age’:18,‘job’:‘programmer’}
字典的创建
- 我们可以通过{}、dict()来创建字典对象。
>>> a = {'name':'gaoqi','age':18,'job':'programmer'}
>>> b = dict(name='gaoqi',age=18,job='programmer')
>>> a = dict([("name","gaoqi"),("age",18)])
>>> c = {} #空的字典对象
>>> d = dict() #空的字典对象
-
通过zip()创建字典对象
>>> k = ['name','age','job'] >>> v = ['gaoqi',18,'techer'] >>> d = dict(zip(k,v)) >>> d {'name': 'gaoqi', 'age': 18, 'job': 'techer'}3.通过fromkeys创建值为空的字典
>>> a = dict.fromkeys(['name','age','job'])
>>> a
{'name': None, 'age': None, 'job': None}
字典元素的访问
1 . 通过【键】获取“值”,若键不存在,则抛出异常
>>> a = {'name':'gaoqi','age':18,'job':'programmer'}
>>> a['name']
'gaoqi'
>>> a['age']
18
>>> a['sex']
Traceback (most recent call last):
File "<pyshell#374>", line 1, in <module>
a['sex']
KeyError: 'sex'
2 .通过get()方法获得“值”,推荐使用。优点是:指定键不存在,返回None;也可以设定指定键不存在时默认返回的对象,推荐使用get()获取“值对象”
>>> a.get('name')
'gaoqi'
>>> a.get('sex')
>>> a.get('sex','一个男人')
'一个男人'
3 .列出所有的键值对
>>> a.items()
dict_items([('name', 'gaoqi'), ('age', 18), ('job', 'programmer')])
4 .列出所有的键,列出所有的值
>>> a.keys()
dict_keys(['name', 'age', 'job'])
>>> a.values()
dict_values(['gaoqi', 18, 'programmer'])
5 .len()键值对的个数
6 . 检测一个“键”是否在字典中
>>> a = {"name":"gaoqi","age":18}
>>> "name" in a
True
字典元素添加、修改、删除
1. 给字典新增“键值对”。如果“键”已经存在,则覆盖旧的键值对;如果“键”不存在,
则新增“键值对”。
>>>a = {'name':'gaoqi','age':18,'job':'programmer'}
>>> a['address']='西三旗1 号院'
>>> a['age']=16
>>> a
{'name': 'gaoqi', 'age': 16, 'job': 'programmer', 'address': '西三旗1 号院'}
2. 使用update()将新字典中所有键值对全部添加到旧字典对象上。如果key 有重复,则直
接覆盖。
>>> a = {'name':'gaoqi','age':18,'job':'programmer'}
>>> b = {'name':'gaoxixi','money':1000,'sex':'男的'}
>>> a.update(b)
>>> a
{'name': 'gaoxixi', 'age': 18, 'job': 'programmer', 'money': 1000, 'sex': '男的'}
3. 字典中元素的删除,可以使用del()方法;或者clear()删除所有键值对;pop()删除指定
键值对,并返回对应的“值对象”;
>>> a = {'name':'gaoqi','age':18,'job':'programmer'}
>>> del(a['name'])
>>> a
{'age': 18, 'job': 'programmer'}
>>> b = a.pop('age')
>>> b
18
4. popitem() :随机删除和返回该键值对。字典是“无序可变序列”,因此没有第一个元
素、最后一个元素的概念;popitem 弹出随机的项,因为字典并没有"最后的元素"或者其
他有关顺序的概念。若想一个接一个地移除并处理项,这个方法就非常有效(因为不用首先
北京尚学堂·百战程序员实战系统好教育
获取键的列表)。
>>> a = {'name':'gaoqi','age':18,'job':'programmer'}
>>> a.popitem()
('job', 'programmer')
>>> a
{'name': 'gaoqi', 'age': 18}
>>> a.popitem()
('age', 18)
>>> a
{'name': 'gaoqi'}
4 序列解包
序列解包可以用于元组、列表、字典。序列解包可以让我们方便的对多个变量赋值。
>>> x,y,z=(20,30,10)
>>> x
20
>>> y
30
>>> z
10
>>> (a,b,c)=(9,8,10)
>>> a
9
>>> [a,b,c]=[10,20,30]
>>> a
10
>>> b
20
序列解包用于字典时,默认是对“键”进行操作; 如果需要对键值对操作,则需要使用 items();如果需要对“值”进行操作,则需要使用values();
>>> s = {'name':'gaoqi','age':18,'job':'teacher'}
>>> name,age,job=s #默认对键进行操作
>>> name
'name'
>>> name,age,job=s.items() #对键值对进行操作
>>> name
('name', 'gaoqi')
>>> name,age,job=s.values() #对值进行操作
>>> name
'gaoqi'
5 表格数据使用字典和列表存储,并实现访问
r1 = {"name":"高小一","age":18,"salary":30000,"city":"北京"}
r2 = {"name":"高小二","age":19,"salary":20000,"city":"上海"}
r3 = {"name":"高小五","age":20,"salary":10000,"city":"深圳"}
tb = [r1,r2,r3]
#获得第二行的人的薪资
print(tb[1].get("salary"))
#打印表中所有的的薪资
for i in range(len(tb)): # i -->0,1,2
print(tb[i].get("salary"))
#打印表的所有数据
for i in range(len(tb)):
print(tb[i].get("name"),tb[i].get("age"),tb[i].get("salary"),tb[i].get("city"))
6 集合
集合是无序可变,元素不能重复。实际上,集合底层是字典实现,集合的所有元素都是字典 中的“键对象”,因此是不能重复的且唯一的
1. 使用{}创建集合对象,并使用add()方法添加元素
>>> a = {3,5,7}
>>> a
{3, 5, 7}
>>> a.add(9)
>>> a
{9, 3, 5, 7}
2. 使用set(),将列表、元组等可迭代对象转成集合。如果原来数据存在重复数据,则只保
留一个。
>>> a = ['a','b','c','b']
>>> b = set(a)
>>> b
{'b', 'a', 'c'}
3. remove()删除指定元素;clear()清空整个集合
>>> a = {10,20,30,40,50}
>>> a.remove(20)
>>> a
{10, 50, 30}
集合的相关操作
像数学中概念一样,Python 对集合也提供了并集、交集、差集等运算。我们给出示例:
>>> a = {1,3,'sxt'}
>>> b = {'he','it','sxt'}
>>> a|b #并集
{1, 3, 'sxt', 'he', 'it'}
>>> a&b #交集
{'sxt'}
>>> a-b #差集
{1, 3}
>>> a.union(b) #并集
{1, 3, 'sxt', 'he', 'it'}
>>> a.intersection(b) #交集
{'sxt'}
>>> a.difference(b) #差集
{1, 3}
python控制语句
1 单分支选择结构
if 语句单分支结构的语法形式如下: if 条件表达式: 语句/语句块 其中: 1 .条件表达式:可以是逻辑表达式、关系表达式、算术表达式等等。 2 .语句/语句块:可以是一条语句,也可以是多条语句。多条语句,缩进必须对齐一致。
在选择和循环结构中,条件表达式的值为False 的情况如下: False、0、0.0、空值None、空序列对象(空列表、空元祖、空集合、空字典、空字 符串)、空range 对象、空迭代对象。 其他情况,均为True。这么看来,Python 所有的合法表达式都可以看做条件表达式,甚至 包括函数调用的表达式。
if 3: #整数作为条件表达式
print("ok")
a = [] #列表作为条件表达式,由于为空列表,是False
if a:
print("空列表,False")
s = "False" #非空字符串,是True
if s:
print("非空字符串,是True")
c = 9
if 3<c<20:
print("3<c<20")
if 3<c and c<20:
print("3<c and c<20")
if True: #布尔值
print("True")
2 双分支选择结构
双分支结构的语法格式如下: if 条件表达式: 语句1/语句块1 else: 语句2/语句块2
3 三元条件运算符
Python 提供了三元运算符,用来在某些简单双分支赋值情况。三元条件运算符语法格式如 下: 条件为真时的值if (条件表达式) else 条件为假时的值 上一个案例代码,可以用三元条件运算符实现: num = input(“请输入一个数字”) print( num if int(num)<10 else “数字太大”) 可以看到,这种写法更加简洁,易读。
4 多分支选择结构
多分支选择结构的语法格式如下: if 条件表达式1 : 语句1/语句块1 elif 条件表达式2: 语句2/语句块2 . . . elif 条件表达式n : 语句n/语句块n [else: 语句n+1/语句块n+1 ]
score = int(input("请输入分数"))
grade = ''
if score<60 :
grade = "不及格"
elif score<80 :
grade = "及格"
elif score<90 :
grade = "良好"
elif score<=100:
grade = "优秀"
print("分数是{0},等级是{1}".format(score,grade))
5 while循环和for循环
while 循环的语法格式如下: while 条件表达式: 循环体语句 我们通过一些简单的练习,来慢慢熟悉while 循环。
利用while循环打印从0-10的数字
num = 0
while num<=10:
print(num)
num += 1
for 循环通常用于可迭代对象的遍历。for 循环的语法格式如下: for 变量in 可迭代对象: 循环体语句 【操作】遍历一个元组或列表
for x in (20,30,40):
print(x*3)
6 python可迭代对象
Python 包含以下几种可迭代对象:
- 序列。包含:字符串、列表、元组
- 字典
- 迭代器对象(iterator)
- 生成器函数(generator)
- 文件对象
d = {'name':'gaoqi','age':18,'address':'西三旗001 号楼'}
for x in d: #遍历字典所有的key
print(x)
for x in d.keys():#遍历字典所有的key
print(x)
for x in d.values():#遍历字典所有的value
print(x)
for x in d.items():#遍历字典所有的"键值对"
print(x)
7 range 对象
range 对象是一个迭代器对象,用来产生指定范围的数字序列。格式为: range(start, end [,step]) 生成的数值序列从start 开始到end 结束(不包含end)。若没有填写start,则默认从0 开始。step 是可选的步长,默认为1。如下是几种典型示例: for i in range(10) 产生序列:0 1 2 3 4 5 6 7 8 9 for i in range(3,10) 产生序列:3 4 5 6 7 8 9 for i in range(3,10,2) 产生序列:3 5 7 9
sum_all = 0 #1-100 所有数的累加和
sum_even = 0 #1-100 偶数的累加和
sum_odd = 0 #1-100 奇数的累加和
for num in range(101):
sum_all += num
北京尚学堂·百战程序员实战系统好教育
if num%2==0:sum_even += num
else:sum_odd += num
print("1-100 累加总和{0},奇数和{1},偶数和{2}".format(sum_all,sum_odd,sum_even))
8 使用zip()并行迭代
我们可以通过zip()函数对多个序列进行并行迭代,zip()函数在最短序列“用完”时就会停 止。
【操作】测试zip()并行迭代
names = ("高淇","高老二","高老三","高老四")
ages = (18,16,20,25)
jobs = ("老师","程序员","公务员")
for name,age,job in zip(names,ages,jobs):
print("{0}--{1}--{2}".format(name,age,job))
执行结果:
高淇--18--老师
高老二--16--程序员
高老三--20--公务员
9 推导式创建序列
推导式是从一个或者多个迭代器快速创建序列的一种方法。它可以将循环和条件判断结合, 从而避免冗长的代码。推导式是典型的Python 风格,会使用它代表你已经超过Python 初 学者的水平。
列表推导式
列表推导式生成列表对象,语法如下: [表达式for item in 可迭代对象] 或者:{表达式for item in 可迭代对象if 条件判断}
>>> [x for x in range(1,5)]
[1, 2, 3, 4]
>>> [x*2 for x in range(1,5)]
[2, 4, 6, 8]
>>> [x*2 for x in range(1,20) if x%5==0 ]
[10, 20, 30]
>>> [a for a in "abcdefg"]
['a', 'b', 'c', 'd', 'e', 'f', 'g']
>>> cells = [(row,col) for row in range(1,10) for col in range(1,10)] #可以使用两个循环
>>> for cell in cells:
print(cell)
(1, 1) (1, 2) (1, 3) (1, 4) (1, 5) (1, 6) (1, 7) (1, 8) (1, 9) (2, 1) (2, 2) (2, 3) (2, 4) (2, 5) (2, 6) (2, 7) (2, 8) (2, 9) (3, 1) (3, 2) (3, 3) (3, 4) (3, 5) (3, 6) (3, 7) (3, 8) (3, 9) (4, 1) (4, 2) (4, 3) (4, 4) (4, 5) (4, 6) (4, 7) (4, 8) (4, 9) (5, 1) (5, 2) (5, 3) (5, 4) (5, 5) (5, 6) (5, 7) (5, 8) (5, 9) (6, 1) (6, 2) (6, 3) (6, 4) (6, 5) (6, 6) (6, 7) (6, 8) (6, 9) (7, 1) (7, 2) (7, 3) (7, 4) (7, 5) (7, 6) (7, 7) (7, 8) (7, 9) (8, 1) (8, 2) (8, 3) (8, 4) (8, 5) (8, 6) (8, 7) (8, 8) (8, 9) (9, 1) (9, 2) (9, 3) (9, 4) (9, 5)
相当于for语句嵌套赋值
字典推导式
字典的推导式生成字典对象,格式如下:
{key_expression : value_expression for 表达式in 可迭代对象}
类似于列表推导式,字典推导也可以增加if 条件判断、多个for 循环。
统计文本中字符出现的次数:
>>> my_text = ' i love you, i love sxt, i love gaoqi'
>>> char_count = {c:my_text.count(c) for c in my_text}
>>> char_count
{' ': 9, 'i': 4, 'l': 3, 'o': 5, 'v': 3, 'e': 3, 'y': 1, 'u': 1, ',': 2, 's': 1, 'x': 1, 't': 1, 'g': 1, 'a': 1, 'q': 1}
集合推导式
集合推导式生成集合,和列表推导式的语法格式类似:
{表达式for item in 可迭代对象}
或者:{表达式for item in 可迭代对象if 条件判断}
>>> {x for x in range(1,100) if x%9==0}
{99, 36, 72, 9, 45, 81, 18, 54, 90, 27, 63}
生成器推导式(生成元组)
很多同学可能会问:“都有推导式,元组有没有?”,能不能用小括号呢?
>>> (x for x in range(1,100) if x%9==0)
<generator object <genexpr> at 0x0000000002BD3048>
我们发现提示的是“一个生成器对象”。显然,元组是没有推导式的。
北京尚学堂·百战程序员实战系统好教育
一个生成器只能运行一次。第一次迭代可以得到数据,第二次迭代发现数据已经没有了。
>>> gnt = (x for x in range(1,100) if x%9==0)
>>> for x in gnt:
print(x,end=' ')
9 18 27 36 45 54 63 72 81 90 99
>>> for x in gnt:
print(x,end=' ')
>>>
python函数
Python 中函数分为如下几类:
- 内置函数 我们前面使用的str()、list()、len()等这些都是内置函数,我们可以拿来直接使用。
- 标准库函数 我们可以通过import 语句导入库,然后使用其中定义的函数
- 第三方库函数 Python 社区也提供了很多高质量的库。下载安装这些库后,也是通过import 语句导 入,然后可以使用这些第三方库的函数
- 用户自定义函数 用户自己定义的函数,显然也是开发中适应用户自身需求定义的函数。今天我们学习的 就是如何自定义函数。
1 函数的定义和调用
Python 中,定义函数的语法如下: def 函数名([参数列表]) : ‘‘‘文档字符串’’’ 函数体/若干语句
要点:
- 我们使用def 来定义函数,然后就是一个空格和函数名称; (1) Python 执行def 时,会创建一个函数对象,并绑定到函数名变量上。
- 参数列表 (1) 圆括号内是形式参数列表,有多个参数则使用逗号隔开 (2) 形式参数不需要声明类型,也不需要指定函数返回值类型 (3) 无参数,也必须保留空的圆括号 (4) 实参列表必须与形参列表一一对应
- return 返回值 (1) 如果函数体中包含return 语句,则结束函数执行并返回值; (2) 如果函数体中不包含return 语句,则返回None 值。 北京尚学堂·百战程序员实战系统好教育
- 调用函数之前,必须要先定义函数,即先调用def 创建函数对象 (1) 内置函数对象会自动创建 (2) 标准库和第三方库函数,通过import 导入模块时,会执行模块中的def 语句 我们通过实际定义函数来学习函数的定义方式。
2 函数也是对象
Python 中,“一切都是对象”。实际上,执行def 定义函数后,系统就创建了相应的函数
对象。我们执行如下程序,然后进行解释:
def print_star(n):
print("*"*n)
print(print_star)
print(id(print_star))
c = print_star
c(3)
执行结果:
<function print_star at 0x0000000002BB8620>
45844000
***
3 在函数里面使用全局变量
【操作】全局变量的作用域测试
a = 100 #全局变量
def f1():
global a #如果要在函数内改变全局变量的值,增加global 关键字声明
print(a) #打印全局变量a 的值
a = 300
f1()
print(a)
执行结果:
100
300
4 参数的传递
函数的参数传递本质上就是:从实参到形参的赋值操作。Python 中“一切皆对象”, 所有的赋值操作都是“引用的赋值”。所以,Python 中参数的传递都是“引用传递”,不 是“值传递”。具体操作时分为两类:
-
对“可变对象”进行“写操作”,直接作用于原对象本身。
-
对“不可变对象”进行“写操作”,会产生一个新的“对象空间”,并用新的值填 充这块空间。(起到其他语言的“值传递”效果,但不是“值传递”) 可变对象有: 字典、列表、集合、自定义的对象等 不可变对象有: 数字、字符串、元组、function 等
传递可变对象的引用
传递参数是可变对象(例如:列表、字典、自定义的其他可变对象等),实际传递的还是对
象的引用。在函数体中不创建新的对象拷贝,而是可以直接修改所传递的对象。
【操作】参数传递:传递可变对象的引用
b = [10,20]
def f2(m):
print("m:",id(m)) #b 和m 是同一个对象
m.append(30) #由于m 是可变对象,不创建对象拷贝,直接修改这个对象
f2(b)
print("b:",id(b))
print(b)
执行结果:
m: 45765960
北京尚学堂·百战程序员实战系统好教育
b: 45765960
[10, 20, 30]
传递不可变对象的引用
传递参数是不可变对象(例如:int、float、字符串、元组、布尔值),实际传递的还是对
象的引用。在”赋值操作”时,由于不可变对象无法修改,系统会新创建一个对象。
【操作】参数传递:传递不可变对象的引用
a = 100
def f1(n):
print("n:",id(n)) #传递进来的是a 对象的地址
n = n+200 #由于a 是不可变对象,因此创建新的对象n
print("n:",id(n)) #n 已经变成了新的对象
print(n)
f1(a)
print("a:",id(a))
执行结果:
n: 1663816464
n: 46608592
300
a: 1663816464
显然,通过id 值我们可以看到n 和a 一开始是同一个对象。给n 赋值后,n 是新的对象。
5 浅拷贝和深拷贝
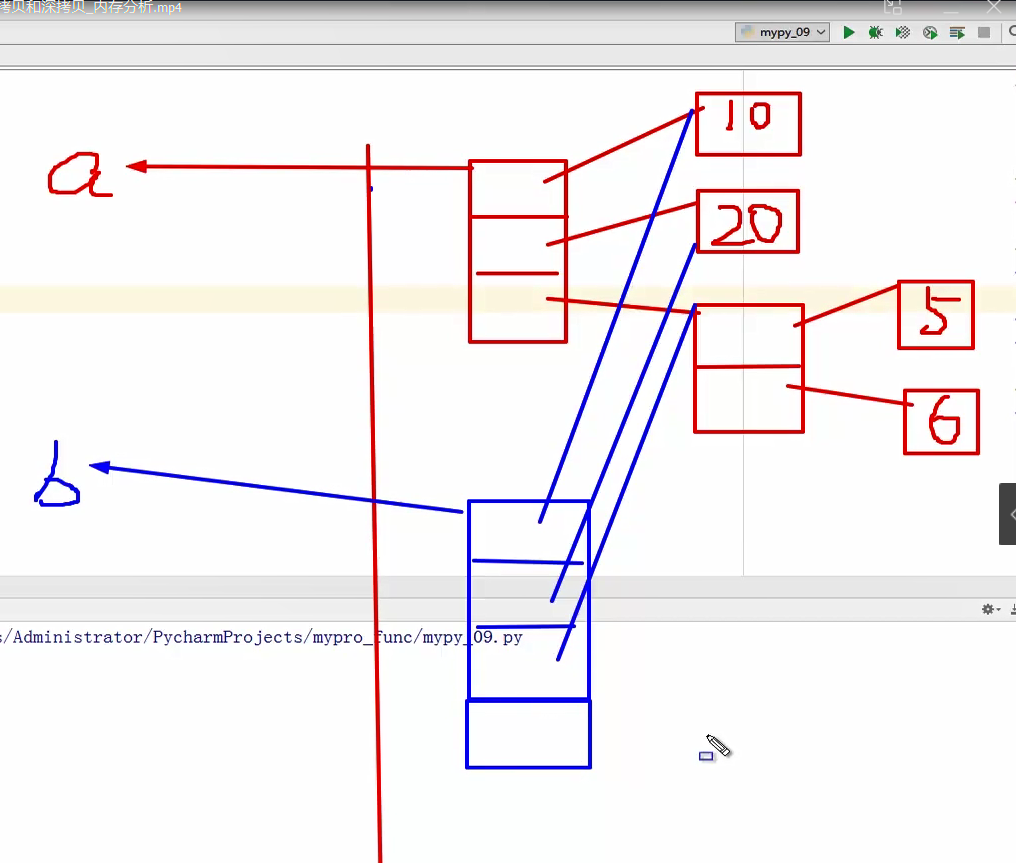
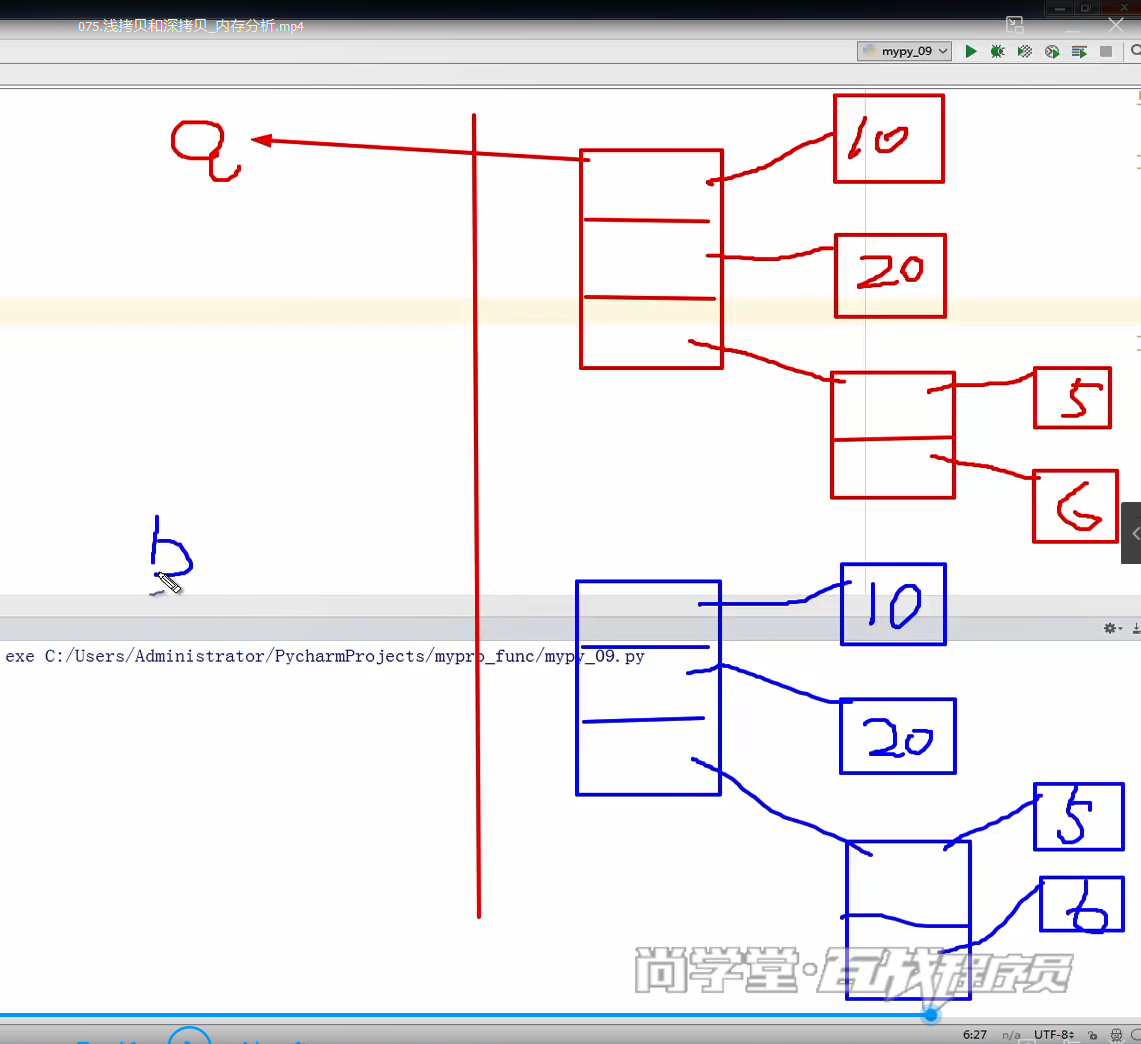
为了更深入的了解参数传递的底层原理,我们需要讲解一下“浅拷贝和深拷贝”。我们可以 使用内置函数:copy(浅拷贝)、deepcopy(深拷贝)。 浅拷贝:不拷贝子对象的内容,只是拷贝子对象的引用。 深拷贝:会连子对象的内存也全部拷贝一份,对子对象的修改不会影响源对象
#测试浅拷贝和深拷贝
import copy
def testCopy():
'''测试浅拷贝'''
a = [10, 20, [5, 6]]
b = copy.copy(a)
print("a", a)
print("b", b)
b.append(30)
b[2].append(7)
print("浅拷贝......")
print("a", a)
print("b", b)
def testDeepCopy():
'''测试深拷贝'''
a = [10, 20, [5, 6]]
b = copy.deepcopy(a)
print("a", a)
print("b", b)
b.append(30)
b[2].append(7)
print("深拷贝......")
print("a", a)
print("b", b)
testCopy()
print("*************")
testDeepCopy()
运行结果:
a [10, 20, [5, 6]]
b [10, 20, [5, 6]]
浅拷贝......
a [10, 20, [5, 6, 7]]
b [10, 20, [5, 6, 7], 30]
*************
北京尚学堂·百战程序员实战系统好教育
a [10, 20, [5, 6]]
b [10, 20, [5, 6]]
深拷贝......
a [10, 20, [5, 6]]
b [10, 20, [5, 6, 7], 30]
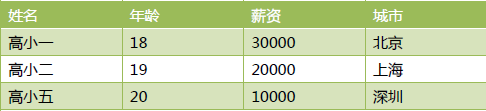
浅拷贝(但是如果b[1] = 1也不会改变a因为数字是不可变对象,重新创建一个新数字指向这个对象)
深拷贝(相当于完全复制了一份,对原来没有任何影响)
6 参数的几种类型
位置参数
函数调用时,实参默认按位置顺序传递,需要个数和形参匹配。按位置传递参数,称为:位置参数
def f1(a,b,c):
print(a,b,c)
f1(2,3,4)
f1(2,3) #报错,位置参数不匹配
执行结果:
2 3 4
Traceback (most recent call last):
File "E:\PythonExec\if_test01.py", line 5, in <module>
f1(2,3)
TypeError: f1() missing 1 required positional argument: 'c'
默认值参数
我们可以为某些参数设置默认值,这样这些参数在传递时就是可选的,称为默认值参数,默认值参数放到位置参数后面
def f1(a,b,c=10,d=20): #默认值参数必须位于普通位置参数后面
print(a,b,c,d)
f1(8,9)
f1(8,9,19)
f1(8,9,19,29)
执行结果:
8 9 10 20
8 9 19 20
8 9 19 29
命名参数
我们也可以按照形参的名称传递参数,称为“命名参数”,也称“关键字参数”
测试命名参数
def f1(a,b,c):
print(a,b,c)
f1(8,9,19) #位置参数
f1(c=10,a=20,b=30) #命名参数
执行结果:
8 9 19
20 30 10
可变参数
可变参数指的是“可变数量的参数”。分两种情况:
1 *param(一个星号),将多个参数收集到一个“元组”对象中。
2 **param(两个星号),将多个参数收集到一个“字典”对象中。
def f1(a,b,*c):
print(a,b,c)
f1(8,9,19,20)
def f2(a,b,**c):
print(a,b,c)
北京尚学堂·百战程序员实战系统好教育
f2(8,9,name='gaoqi',age=18)
def f3(a,b,*c,**d):
print(a,b,c,d)
f3(8,9,20,30,name='gaoqi',age=18)
执行结果:
8 9 (19, 20)
8 9 {'name': 'gaoqi', 'age': 18}
8 9 (20, 30) {'name': 'gaoqi', 'age': 18}
强制命名参数
在带星号的“可变参数”后面增加新的参数,必须在调用的时候“强制命名参数”
【操作】强制命名参数的使用
def f1(*a,b,c):
print(a,b,c)
#f1(2,3,4) #会报错。由于a 是可变参数,将2,3,4 全部收集。造成b 和c 没有赋值。
f1(2,b=3,c=4)
执行结果:
(2,) 3 4